
Track
dbt Fundamentals
8 hr
dbt is growing in popularity in the analytics field for its data transformation and testing functions. In this article, we’ll share what dbt is and how you can conduct some dbt tests to ensure data quality. If you’re just starting out with dbt, be sure to check out our Introduction to dbt course to learn more.
As we explore in our separate guide, dbt (data build tool) is a popular open-source tool used by data teams to transform raw data in their warehouse into clean, tested, documented, and analytics-ready datasets.
Unlike ETL tools, dbt focuses solely on the "T" (Transform) component of the data pipeline and operates on top of modern cloud data warehouses like BigQuery, Snowflake, Redshift, and Databricks.
One of dbt’s most powerful features is its built-in data testing framework, which allows data practitioners to write tests that validate assumptions about their data. This testing framework is not only helpful for catching issues early but is also crucial for maintaining data quality and trust in a growing, modular analytics codebase.
Testing is a foundational part of analytics engineering. As datasets grow and more stakeholders depend on data, the cost of undetected data issues rises. dbt’s testing capabilities help you:
In dbt, tests are SQL-based assertions that validate data assumptions. Tests in dbt fall into two main categories:
These tests are pre-defined by dbt and are applied declaratively in YAML files. Generic tests cover common constraints that are typically found in data modeling and data warehousing.
They are:
The four built-in generic test types include:
not_null: Ensures a column does not contain any NULL values.unique: Ensures a column’s values are distinct across rows (used commonly for primary keys).accepted_values: Restricts a column to a predefined set of allowed values.relationships: Validates referential integrity between tables, ensuring that foreign keys match values in another table.These tests are ideal for enforcing baseline data integrity, especially around keys, categorical fields, and core table relationships.
Generic tests work by automatically generating SQL under the hood.
For example, a not_null test on the customer_id column will generate SQL similar to:
SELECT *
FROM {{ ref('customers') }}
WHERE customer_id IS NULLIf this query returns any rows, the test fails.
Custom or singular tests are user-defined SQL queries saved as .sql files in the tests/ directory. These are used for:
Singular tests offer maximum flexibility. You can validate data in virtually any way, as long as your SQL query returns only rows that violate expectations.
For example:
Because of their flexibility, custom tests are ideal for analytics teams who want to enforce nuanced data quality contracts in production.
Macros included in dbt can also be used to test, such as the dbt-utils package.
In summary:
|
Feature |
Generic Tests |
Custom (Singular) Tests |
|
Defined in |
schema.yml |
.sql files in tests/ folder |
|
Coverage |
Common constraints (e.g. nulls, keys) |
Any logic expressible in SQL |
|
Complexity |
Simple |
Medium to complex |
|
Reusability |
High |
Low (usually case-specific) |
|
Flexibility |
Limited |
Unlimited (any SQL logic) |
Combining both types gives you the best of both worlds: some consistency and coverage from generic tests, and some precision from custom tests. Let’s explore each type in more detail.
Generic tests are predefined by dbt and used declaratively by adding them to your model’s schema.yml file.
These tests typically validate constraints like uniqueness, non-nullability, referential integrity, or values in a defined set.
Let’s explore a simple tutorial to try out generic tests in dbt.
In your model's corresponding schema.yml file, define tests under the columns: section:
version: 2
models:
- name: customers
description: "Customer dimension table"
columns:
- name: customer_id
description: "Unique customer identifier"
tests:
- not_null
- unique
- name: email
tests:
- not_nullyaml
columns:
- name: customer_id
tests:
- not_null
- uniqueThis test above ensures that customer_id is both present in every row and distinct. It's commonly used to enforce the assumption that customer_id is a primary key for the table.
columns:
- name: customer_type
tests:
- accepted_values:
values: ['new', 'returning', 'vip']This checks that the customer_type field only contains one of the three allowed strings: new, returning, or vip. This test is often used for categorical fields that must conform to a known set of values, such as enums or statuses.
columns:
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: idThis enforces a referential integrity constraint by verifying that every customer_id in the current model exists as an id in the customers table. It mimics a foreign key constraint in SQL, but at the analytics layer.
When built-in tests are insufficient for your use case, for instance, you want to validate complex business logic, you can write custom tests using SQL. These are known as singular tests.
1. Create a .sql file inside the tests/ directory in your dbt project.
2. Write a SQL query that returns rows that fail the test.
ordersIn the tests folder, create a file called no_future_dates.sql.
SELECT *
FROM {{ ref('orders') }}
WHERE order_date > current_dateThis test checks whether any records in the orders table have an order_date in the future. If rows are returned, the test fails, alerting you to invalid data that may be caused by timezone errors, ETL bugs, or incorrect source system entries.
-- File: tests/duplicate_emails_per_region.sql
SELECT email, region, COUNT(*) as occurrences
FROM {{ ref('customers') }}
GROUP BY email, region
HAVING COUNT(*) > 1This test ensures that each email is unique within a given region. This might reflect a business rule where the same person cannot register twice in the same region. Any row returned indicates a data quality violation.
This section walks through the practical steps to implement, configure, and run dbt tests within your project and deployment pipelines.
Before you begin writing tests or models, you need to have dbt installed and a new project initialized.
1. Create project folder:
Create a folder in a location of your choice.
2. Navigate into the project folder:
cd dbt-test-project3. Create virtual Python environment:
python3 -m venv dbt-envNext, activate the environment once it has been created.
dbt-venv\Scripts\activate4. Install dbt
pip dbt install5. Create .dbt folder
mkdir $home\.dbt6. Initialize dbt
dbt init7. Create profiles.yml file
Create a new file in your .dbt folder with the following contents:
austi:
target: dev
outputs:
dev:
type: sqlite
threads: 1
database: ./dbt_project.db
schema: main
schema_directory: ./schemas
schemas_and_paths:
main: ./dbt_project.dbYou can replace “austi” with the name of your user profile of your Windows computer.
8. Create dbt_project.yml file
Next, you’ll need to create another config file in the .dbt folder with the following contents.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseOnce again, replace “austi” with your user profile name.
9. Verify the project works:
dbt debugOnce setup is complete, you’re ready to begin creating datasets and building dbt models.
If you're working without access to a data warehouse, you can simulate dbt tests locally using CSV files and dbt's seed functionality.
1. Create CSV files: Place these inside a new /seeds folder of your dbt project.
Here’s how you should name it:
seeds/customers.csv
customer_id,name,email,customer_type
1,Alice Smith,alice@example.com,new
2,Bob Jones,bob@example.com,returning
3,Carol Lee,carol@example.com,vip
4,David Wu,david@example.com,new2. Create another file in the same directory:
Use this naming convention:
seeds/orders.csv
order_id,customer_id,order_date,order_total,order_status
1001,1,2023-12-01,150.00,shipped
1002,2,2023-12-03,200.00,delivered
1003,1,2023-12-05,175.00,cancelled
1004,3,2024-01-01,225.00,pending3. Create a config file to identify seeds:
Next, you’ll need to create a config file called dbt_project.yml.
Paste the following contents in the config file.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseChange the profile field to match the name of your user profile on your Windows computer.
4. Load seed data:
dbt seedThis command creates main.customers and main.orders tables from the CSV files. These are the seeds needed to replace a database.
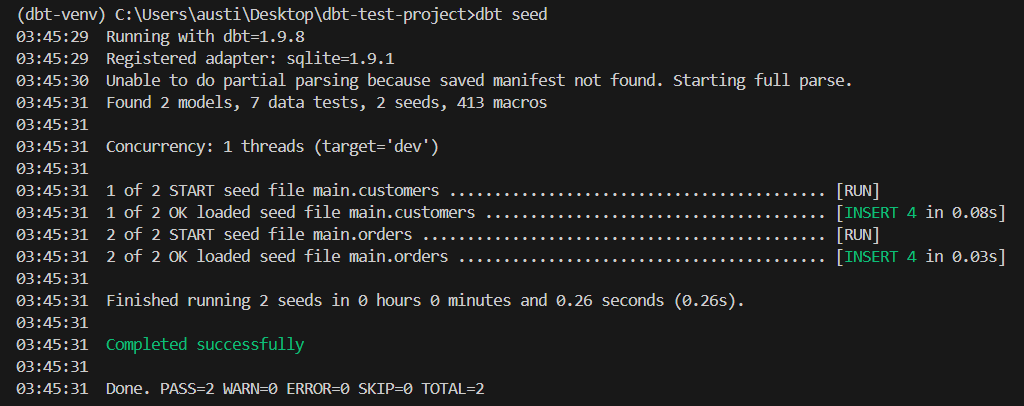
As you can see from the image above, two seeds have been found and have been loaded.
Now, we’ll create staging models to transform and test your raw data.
1. Create staging models:
Create a new folder called models in your project folder. In that folder, create a file called stg_customers.sql.
Paste the following code in the file:
SELECT
*
FROM {{ ref('customers') }}In another file called stg_orders.sql, paste the following code:
SELECT
*
FROM {{ ref('orders') }}2. Define schema tests:
Create a new file at the following location:
models/schema.yml
Paste the following into the file
version: 2
models:
- name: stg_customers
description: "Customer staging table"
columns:
- name: customer_id
description: "Unique identifier for each customer"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: email
description: "Email address of the customer"
tests:
- not_null
- name: stg_orders
description: "Orders staging table"
columns:
- name: order_id
description: "Unique identifier for each order"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: customer_id
description: "Foreign key to stg_customers"
tests:
- not_null:
tags: [critical]3. Run dbt to build staging models:
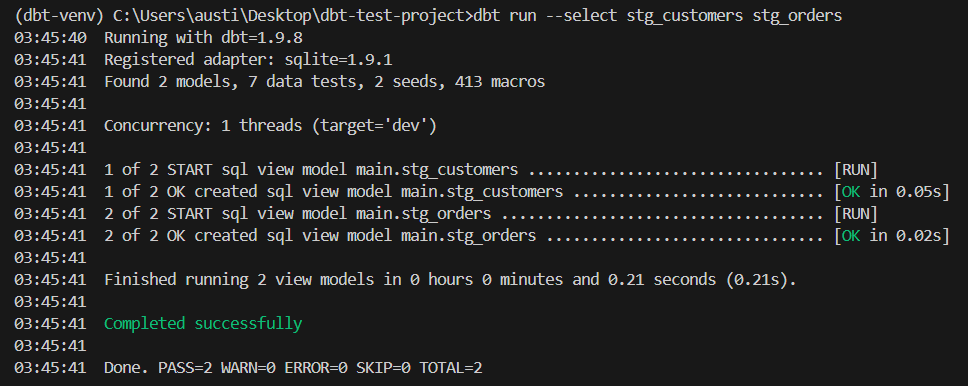
dbt run --select stg_customers stg_ordersThese staging models now act as the foundation for applying dbt tests using your locally seeded data.
An example output would be:
Now that your data is staged, let’s implement your first dbt test using the generic built-in testing framework.
1. Open the schema.yml file where your staging model is defined.
2. Under the columns: section of your model, define a test such as not_null or unique.
Example:
models:
- name: stg_customers
columns:
- name: customer_id
tests:
- not_null
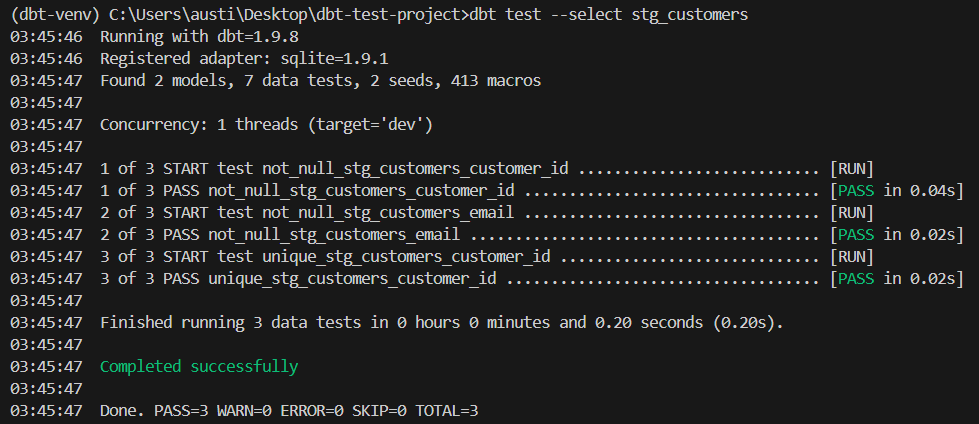
- uniquedbt test --select stg_customersHere’s an expected result:
When your needs go beyond built-in tests, you can create custom tests using SQL.
1. Create a new file in the tests/ folder, for example: tests/no_future_orders.sql
2. Add SQL logic that returns failing rows:
SELECT *
FROM {{ ref('stg_orders') }}
WHERE order_date > current_date3. Run the test:
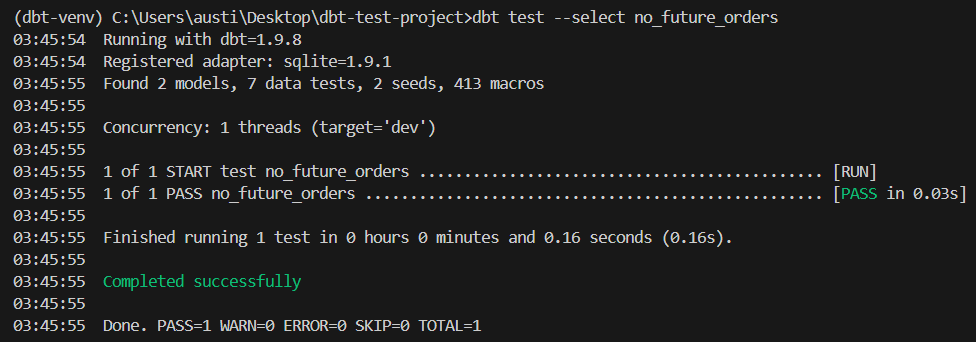
dbt test --select no_future_ordersThis test will fail if any orders have future-dated order_date values.
Here is an expected result:
To ensure consistent test execution, integrate dbt tests into your development pipeline.
1. Use tags to prioritize or isolate tests:
You can modify any model schema to include the following tags in this format:
columns:
- name: customer_id
tests:
- not_null:
tags: [critical]2. Run selective tests locally:
dbt test --select tag:criticalIf the tests run correctly, you should expect this output:

3. Configure your CI workflow to run dbt tests automatically. You can connect this to a CI platform like GitHub Actions.
Implementing dbt tests effectively is not just about writing them; it's about integrating testing into your team's development lifecycle and culture. Here are some best practices to guide you:
Always apply not_null and unique tests to primary key columns in dimension and fact tables. These two constraints are the foundation of reliable joins and deduplication logic in downstream queries.
Foreign keys are critical for maintaining referential integrity. Use the relationships test to mimic foreign key constraints, especially in data warehouses that do not enforce them natively.
Control dimensional consistency by enforcing specific values in columns like status, region, or product_type. This reduces the risk of typos or unhandled enum expansions.
Business logic doesn’t always map cleanly to generic rules. Examples of logic you should write custom tests for include:
If you have many tests set in place, it can get messy very quickly. You should consider these best practices to keep them organized:
tests/ folder and name them descriptively.Run dbt test as part of your CI pipeline. This ensures that code cannot be merged unless data quality constraints pass. Integrating tests into CI/CD reinforces accountability and trust in the data pipeline.
Excessive or unnecessary testing (especially on large volumes of data) can slow down deployments. Focus on tests that are:
Avoid testing calculated fields unless they are part of a contractual SLA.
For an advanced test example, we can perform an outlier detection test.
Create a SQL file in your tests folder with the following code:
SELECT *
FROM {{ ref('orders') }}
WHERE order_total > 100000This is a basic outlier detection test. If your business typically sees orders below $10,000, you can flag orders over $100,000 for manual review. While not a strict data quality violation, this can be valuable for fraud detection or operational monitoring.
As your dbt project scales and test coverage grows, performance becomes increasingly important. This section outlines techniques and strategies to maintain test efficiency and control computational costs.
For testing, try these techniques to optimize performance:
dbt test --select customers
dbt test --exclude tag:slowImplementing cost management strategies ensures dbt tests remain performant and cost-efficient, especially in environments where compute billing is tied to query complexity and frequency.
Some strategies are:
dbt tests are a powerful way to ensure high data quality, automate validation checks, and catch issues early in your transformation pipeline. Generic and custom tests can be used to create robust and maintainable data workflows.
Learn more about dbt in our Introduction to dbt course or our dbt tutorial.
Top DataCamp Courses
Track
Course
Course
blog
Laiba Siddiqui
15 min
blog
Don Kaluarachchi
15 min
cheat-sheet
Joe Franklin
Tutorial
Mike Shakhomirov
Tutorial
Bex Tuychiev
Tutorial
Moez Ali

