
Curso
Trabajar con DeepSeek en Python
3 h
1.2K
DeepSeek acaba de lanzar la versión 3.2-Exp, un modelo experimental que reduce los costes de API a más de la mitad. Si has trabajado con modelos lingüísticos de gran tamaño, sabrás que el procesamiento de contextos largos se vuelve muy costoso rápidamente. Esta nueva versión aborda ese problema con una técnica denominada« DeepSeek Sparse Attention» (Atención dispersa deDeepSeek con atención dispersa).
En este tutorial, explicaré en qué se diferencia la versión 3.2 de de las versiones anteriores de DeepSeek, cómo funciona la atención dispersa en segundo plano y cómo utilizar el modelo en tus proyectos. Cubriremos los aspectos básicos de las llamadas a la API y crearemos un proyecto de demostración que muestre dónde funciona mejor este modelo.
Al final, crearás una aplicación Streamlit que compara los costes de diferentes LLM, incluido DeepSeek v3.2:
Comencemos con algunos antecedentes sobre DeepSeek y qué ha cambiado en esta versión.
DeepSeek es una empresa de inteligencia artificial de código abierto con sede en China que crea grandes modelos lingüísticos bajo la licencia del MIT. Sus modelos compiten con GPT-5 y Claude en razonamiento, codificación y tareas de propósito general. La compañía ha lanzado varias versiones durante el último año, entre las que se incluyen DeepSeek-V3 y DeepSeek-R1, que llamaron la atención por su gran rendimiento a un coste inferior al de las alternativas de código cerrado.
Antes de la versión 3.2, la versión más reciente era v3.1-Terminus, un modelo de 685 000 millones de parámetros. Aunque ofrecía un rendimiento sólido, el procesamiento de contextos largos seguía siendo costoso. Aquí es donde entra en juego la nueva versión experimental.
DeepSeek ha lanzado la versión 3.2-Exp el 29 de septiembre de 2025 (2025-09-29). La «Exp» significa «experimental», lo que significa que el modelo aún se está probando y perfeccionando. No esperes todavía una estabilidad a nivel de producción, pero puedes utilizarlo para investigación y proyectos en los que quieras probar las últimas funciones.
El modelo se basa en la versión 3.1-Terminus y mantiene la misma arquitectura de parámetros 685B. Lo que lo distingue es cómo procesa la información internamente. Utiliza un formato API compatible con OpenAI, por lo que si ya has utilizado el SDK de OpenAI anteriormente, ya sabes cómo trabajar con DeepSeek (en este artículo también explicaré cómo realizar tu primera llamada API).
Aquí está el gran cambio: DeepSeek redujo los precios de la API en más de un 50 % en comparación con v3.1. Y el rendimiento se mantuvo igual. Obtienes la misma calidad de respuestas a mitad de precio.
Esta bajada de precios se debió a una mejora técnica denominada DeepSeek Sparse Attention (DSA). En lugar de hacer que el modelo preste atención a cada uno de los tokens de tu entrada (lo cual requiere un gran esfuerzo computacional), DSA se centra selectivamente en lo que realmente importa. Veremos cómo funciona esto en la siguiente sección.
Si deseas conocer todos los detalles técnicos, DeepSeek ha publicado un informe técnico en GitHub que explica los cambios en la arquitectura y los resultados de las pruebas de rendimiento.
Antes de entrar en el código, hablemos de lo que hace que la versión 3.2 de sea más barata y rápida. La respuesta está en cómo el modelo procesa tu entrada.
Cuando envías texto a un modelo de lenguaje, este divide tu entrada en tokens (aproximadamente palabras o partes de palabras). A continuación, el modelo debe determinar qué tokens están relacionados entre sí. Este proceso se denomina atención.
En los transformadores tradicionales transformadores, cada ficha mira a todas las demás fichas. Si tienes 1000 fichas, cada una comprueba las otras 999. Eso es un millón de comparaciones. Con 10 000 tokens, tienes 100 millones de comparaciones. Las matemáticas son cuadrático: si duplicas la longitud de la entrada, cuadruplicas el coste de cálculo.
Por eso el procesamiento de contextos largos resulta caro. Tu factura de API aumenta rápidamente a medida que tus documentos se hacen más largos.
No todos los tokens tienen que mirar a todos los demás tokens. Cuando estás leyendo esta frase ahora mismo, no estás releyendo constantemente cada palabra que la precede. Te centras en lo que es relevante.
La atención dispersa tiene el mismo efecto. En lugar de comparar cada token con todos los demás, el modelo selecciona de forma selectiva las comparaciones que son importantes. Algunos enfoques más antiguos al respecto incluyen:
Estos métodos ahorran recursos informáticos, pero son rígidos. Deciden de antemano qué tokens pueden interactuar, independientemente de lo que diga tu texto real. A veces necesitas una palabra al principio de un documento para conectar con algo al final. Los patrones fijos pueden pasar eso por alto.
DSA toma un camino diferente. En lugar de utilizar patrones fijos, aprende qué tokens deben relacionarse entre sí basándose en el propio contenido. El modelo selecciona conexiones relevantes sobre la marcha.
Así es como funciona a alto nivel. Durante el entrenamiento, DeepSeek añadió un mecanismo de selección a cada capa de atención. Este mecanismo analiza tus tokens y decide qué conexiones de atención vale la pena calcular. Conserva los importantes y omite el resto.
La selección no es aleatoria. El modelo aprendió durante el entrenamiento qué tipos de conexiones son importantes para diferentes tareas. Cuando envías una solicitud sobre código, se centra en patrones diferentes a los que se utilizan cuando envías un documento legal.
El resultado: DSA reduce el número de operaciones de atención sin perjudicar la calidad del resultado. En el informe técnico, DeepSeek muestra que v3.2 tiene un rendimiento casi idéntico al de v3.1-Terminus en las pruebas de rendimiento, al tiempo que realiza menos cálculos por token. Obtienes la misma calidad de modelo a aproximadamente la mitad del coste de la API.
Esto es lo que significa DSA en la práctica:
Las ventajas se aprecian sobre todo en estos casos de uso:
Si tu aplicación maneja entradas largas, DSA marca una verdadera diferencia. No solo estás ahorrando dinero. Estás obteniendo un mejor rendimiento en tareas en las que la atención tradicional tiene dificultades.
Ahora que ya entiendes cómo funciona DSA, vamos a utilizar el modelo a través de su API.
Necesitarás tener instalado Python 3.8 o una versión más reciente en tu equipo. Si eres nuevo en el trabajo con LLM a través de API, quizá te interese consultar la guía de DataCamp sobre cómo aprender IA para familiarizarte con los conceptos básicos. También disponemos de un tutorial más detallado sobre la API de DeepSeek. tutorial de la API de DeepSeek que cubre versiones anteriores si deseas profundizar más.
La buena noticia: si ya has utilizado la API de OpenAI anteriormente, ya sabes cómo utilizar DeepSeek. El formato de la API es idéntico.
En primer lugar, obtén tu clave API en platform.deepseek.com. Tendrás que crear una cuenta si aún no tienes una.
Instala los paquetes necesarios:
uv add openai python-dotenvCrea un archivo .env en el directorio de tu proyecto y añade tu clave API:
DEEPSEEK_API_KEY=your_api_key_hereAquí tienes un ejemplo básico utilizando el SDK de OpenAI. La única diferencia con respecto al uso de la API de OpenAI es el parámetro base_url y tu clave API:
from openai import OpenAI
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize OpenAI-compatible client with DeepSeek endpoint
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# Send a chat completion request to DeepSeek v3.2
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "Explain sparse attention in one sentence."}
]
)
# Print the model's response
print(response.choices[0].message.content)Cuando ejecutes esto, obtendrás una respuesta como:
Sparse attention reduces computational cost by having each token attend to only a subset of relevant tokens rather than all tokens in a sequence.El modelo « deepseek-chat » (no pensar) es el modo de no pensar de v3.2-Exp. Procesa tu solicitud y devuelve una respuesta sin mostrar los pasos del razonamiento.
Si deseas ver el proceso de razonamiento del modelo, utiliza deepseek-reasoner. Este modelo muestra su cadena de pensamiento antes de darte la respuesta final:
# Use deepseek-reasoner to see the model's reasoning process
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "Which is larger: 9.11 or 9.8?"}
]
)
# Print both reasoning and final answer
print("Reasoning:", response.choices[0].message.reasoning_content)
print("Answer:", response.choices[0].message.content)Esto generará un resultado similar al siguiente:
Reasoning: To compare 9.11 and 9.8, I need to look at the digits after the decimal point. 9.11 has digits 1 and 1 after the decimal, making it 9 + 0.11. Meanwhile, 9.8 is 9 + 0.8. Since 0.8 is greater than 0.11, 9.8 is the larger number.
Answer: 9.8 is larger than 9.11.El modelo de razonamiento puede generar hasta 64 000 tokens de contenido de razonamiento (el valor predeterminado es 32 000) antes de producir la respuesta final. Ten en cuenta que no admite algunos parámetros como temperature o top_p. La API oficial de DeepSeek aún no admite un parámetro « reasoning_effort » para controlar la profundidad del razonamiento (aunque algunos proveedores externos, como LangChain, lo han añadido a sus integraciones).
El objeto de respuesta sigue la estructura de OpenAI. Puedes acceder al contenido a través de response.choices[0].message.content, comprobar el uso de tokens con response.usage y ver el modelo utilizado con response.model.
La API no es tu única opción. DeepSeek publica sus modelos como código abierto, por lo que puedes ejecutarlos tú mismo.
Hugging Face: El modelo está disponible en huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp. Puedes utilizar los proveedores de inferencia de Hugging Face para ejecutar el modelo sin tener que gestionar tú mismo la infraestructura, o descargar los pesos para la inferencia local. La ruta local funciona bien si se dispone del hardware necesario (piensa en los presupuestos de los centros de datos o en una pequeña granja de GPU en tu armario para un modelo de 685B parámetros).
vLLM: Para implementaciones autohospedadas a gran escala, vLLM ofrece inferencia optimizada con compatibilidad con v3.2. Es más rápido que ejecutar el modelo a través de transformadores estándar y gestiona bien el procesamiento por lotes. Utiliza esta opción si vas a utilizar el modelo en producción y dispones de una infraestructura sólida que lo respalde.
Para la mayoría de los programadores que están empezando, la API es la opción adecuada. Solo pagas por lo que utilizas, y DeepSeek se encarga del escalado y el mantenimiento.
Ya has visto cómo funciona la API de DeepSeek v3.2 y has realizado tus primeras llamadas. Ahora pongámoslo a prueba con una comparación del mundo real.
¿La escasa atención que presta DeepSeek realmente ahorra dinero al procesar contextos largos? ¿Y cómo se comporta en comparación con GPT-5 y Claude Sonnet 4.5?
Para responder a esta pregunta, crearemos una herramienta de comparación que cargue varios artículos de investigación en un único contexto y envíe la misma consulta a los cuatro modelos. Verás exactamente cuánto cuesta cada modelo, qué tan rápido responde y qué tipo de respuestas da.
La mayoría de los sistemas de análisis de documentos utilizan RAG: dividen los documentos en pequeños fragmentos, los incorporan y recuperan solo los fragmentos relevantes cuando se formula una pregunta. Esto funciona bien para búsquedas sencillas, pero se pierden las conexiones entre las diferentes partes de los documentos. ¿Qué pasa si la respuesta requiere comprender las relaciones entre varios artículos?
Los modelos de contexto largo resuelven este problema leyendo todo de una vez. Sin fragmentación, sin recuperación, sin pérdida de contexto. Cargas todos tus documentos en una sola ventana y dejas que el modelo vea el panorama completo. El problema es el costo. Con la atención tradicional, procesar más de 50 000 tokens se vuelve muy caro rápidamente.
Aquí es donde probamos la atención dispersa de DeepSeek. Crearemos una aplicación que cargue tres artículos de investigación (aproximadamente 57 000 tokens en total) en un único contexto y compare cómo cuatro modelos gestionan la misma consulta: GPT-5, Claude Sonnet 4.5, DeepSeek v3.2-Exp (con atención dispersa) y DeepSeek v3.1-Terminus (la versión anterior sin atención dispersa). Verás las diferencias de coste, los tiempos de respuesta y la calidad del resultado comparados entre sí.
Así es como se ve la aplicación terminada:
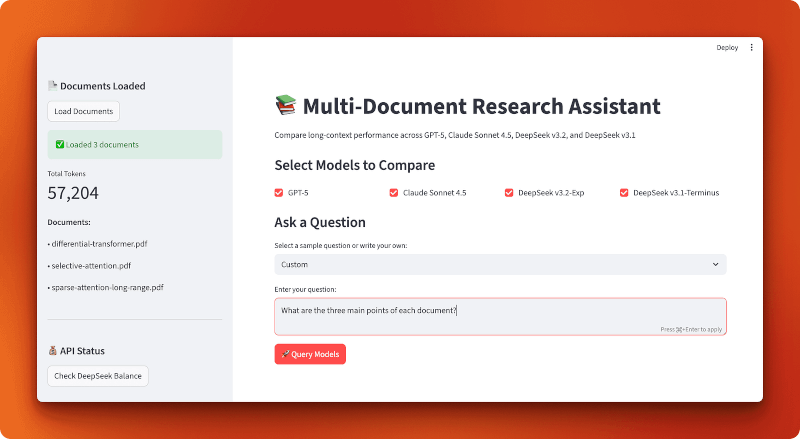
Nota: El resto de esta sección contiene una descripción detallada de cómo crear esta aplicación desde cero. No es necesario crearlo para comprender los resultados de la comparación, pero revisar el código te proporciona patrones prácticos para crear tus propias aplicaciones de contexto largo con DeepSeek.
Crearemos esto como una aplicación Streamlit con tres módulos de apoyo: uno para cargar documentos, otro para configurar el modelo y otro para gestionar las consultas. El flujo de la aplicación es sencillo: carga los archivos PDF, selecciona los modelos, haz una pregunta y compara los resultados.
Comienza creando un directorio para el proyecto e instalando las dependencias:
mkdir multi-document-qa
cd multi-document-qa
uv add streamlit langchain langchain-openai langchain-anthropic langchain-community pypdf tiktoken python-dotenv matplotlib pandasCrea un archivo .env con tus claves API:
OPENAI_API_KEY=your_openai_key
ANTHROPIC_API_KEY=your_anthropic_key
DEEPSEEK_API_KEY=your_deepseek_keyDescarga tres artículos de investigación sobre los mecanismos de atención:
mkdir documents
cd documents
curl -L -o selective-attention.pdf "https://arxiv.org/pdf/2410.02703"
curl -L -o differential-transformer.pdf "https://arxiv.org/pdf/2410.05258"
curl -L -o sparse-attention-long-range.pdf "https://arxiv.org/pdf/2406.16747"
cd ..Estos tres documentos suman un total de 57 204 tokens cuando se cargan.
Crear un document_loader.py:
from langchain_community.document_loaders import PyPDFLoader
import tiktoken
from pathlib import Path
def load_documents(documents_dir="documents"):
docs_path = Path(documents_dir)
pdf_files = list(docs_path.glob("*.pdf"))
all_text = ""
document_names = []
# Load each PDF and concatenate with separators
for pdf_file in sorted(pdf_files):
loader = PyPDFLoader(str(pdf_file))
pages = loader.load()
doc_text = "\n\n".join([page.page_content for page in pages])
all_text += f"\n\n=== Document: {pdf_file.name} ===\n\n{doc_text}"
document_names.append(pdf_file.name)La función carga todos los archivos PDF de un directorio, extrae el texto de cada página y concatena todo con separadores de documentos.
# Count tokens using GPT-4 encoding (accurate across providers)
encoding = tiktoken.encoding_for_model("gpt-4")
token_count = len(encoding.encode(all_text))
return all_text, token_count, document_namesEl recuento de tokens utiliza tiktoken con codificación GPT-4, que proporciona estimaciones precisas en todos los proveedores, ya que utilizan una tokenización similar. Consulta el documento completo document_loader.py en GitHub.
Crear un model_config.py:
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
import os
# Pricing per million tokens (as of October 2025)
MODEL_PRICING = {
"gpt-5": {"input": 2.50, "output": 10.00, "name": "GPT-5"},
"claude-sonnet-4-5-20250929": {"input": 3.00, "output": 15.00, "name": "Claude Sonnet 4.5"},
"deepseek-chat": {"input": 0.28, "output": 0.42, "name": "DeepSeek v3.2-Exp"},
"deepseek-chat-v3.1": {"input": 0.55, "output": 2.19, "name": "DeepSeek v3.1-Terminus"},
}El diccionario de precios almacena los costes por millón de tokens (a fecha de octubre de 2025). DeepSeek v3.2 con atención dispersa es aproximadamente 10 veces más barato que GPT-5 y Claude, mientras que v3.1 se sitúa en un término medio, con un coste dos veces superior al de v3.2.
def get_model(model_name):
"""Initialize a chat model by name using LangChain's unified interface."""
if model_name == "gpt-5":
return ChatOpenAI(model="gpt-5", temperature=0, api_key=os.getenv("OPENAI_API_KEY"))
elif model_name == "claude-sonnet-4-5-20250929":
return ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0,
api_key=os.getenv("ANTHROPIC_API_KEY"))
elif model_name == "deepseek-chat":
return ChatOpenAI(model="deepseek-chat", temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com")
elif model_name == "deepseek-chat-v3.1":
# Note: v3.1-Terminus endpoint expires on October 15, 2025
return ChatOpenAI(model="deepseek-chat", temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v3.1_terminus_expires_on_20251015")
def calculate_cost(model_name, input_tokens, output_tokens):
"""Calculate total cost based on input and output token usage."""
pricing = MODEL_PRICING[model_name]
input_cost = (input_tokens / 1_000_000) * pricing["input"]
output_cost = (output_tokens / 1_000_000) * pricing["output"]
return input_cost + output_costLa función « get_model() » inicializa cada modelo utilizando la interfaz unificada de LangChain. Los modelos DeepSeek utilizan puntos finales compatibles con OpenAI con URL base personalizadas. Nota: El punto final v3.1-Terminus caduca el 15 de octubre de 2025. El archivo completo script se encuentra en GitHub.
Crear un query_handler.py:
import time
from langchain_core.messages import SystemMessage, HumanMessage
from model_config import get_model, calculate_cost, MODEL_PRICING
def query_model(model_name, context, question):
"""Query a model with document context and track performance metrics."""
model = get_model(model_name)
# Embed full document context in system prompt
system_prompt = f"""Use the given context to answer the question.
If you don't know the answer, say you don't know. Keep the answer concise.
Context:
{context}"""
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=question)
]
# Track response time
start_time = time.time()El sistema incrusta los 57 000 tokens de los documentos. La atención tradicional procesa cada token en relación con todos los demás tokens. La atención dispersa de DeepSeek v3.2 omite las conexiones irrelevantes, lo que reduce los costes.
try:
response = model.invoke(messages)
elapsed_time = time.time() - start_time
# Extract token usage (different providers use different formats)
if hasattr(response, 'response_metadata') and 'token_usage' in response.response_metadata:
token_usage = response.response_metadata['token_usage']
input_tokens = token_usage.get('prompt_tokens', 0)
output_tokens = token_usage.get('completion_tokens', 0)
elif hasattr(response, 'usage_metadata'):
input_tokens = response.usage_metadata.get('input_tokens', 0)
output_tokens = response.usage_metadata.get('output_tokens', 0)
# Calculate total cost
cost = calculate_cost(model_name, input_tokens, output_tokens)
return {
"model": MODEL_PRICING[model_name]["name"],
"response": response.content,
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"cost": cost,
"time": elapsed_time,
"error": None
}Las diferentes integraciones de LangChain devuelven el uso de tokens en diferentes formatos (OpenAI utiliza response_metadata y Anthropic utiliza usage_metadata), por lo que comprobamos ambos. La función programa el tiempo, extrae recuentos de tokens, calcula los costes y devuelve un diccionario con todas las métricas. Echa un vistazo al archivo completo query_handler.py en GitHub.
Crear un app.py:
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
from document_loader import load_documents
from query_handler import query_model
from dotenv import load_dotenv
# Load API keys from .env file
load_dotenv()
# Configure Streamlit page with wide layout
st.set_page_config(
page_title="Multi-Document Research Assistant",
page_icon="📚",
layout="wide"
)
st.title("📚 Multi-Document Research Assistant")
st.markdown("Compare long-context performance across GPT-5, Claude Sonnet 4.5, DeepSeek v3.2, and DeepSeek v3.1")Configuración estándar de Streamlit con un diseño amplio para comparaciones en paralelo.
# Sidebar for document loading
with st.sidebar:
st.header("📄 Documents Loaded")
if st.button("Load Documents"):
with st.spinner("Loading documents..."):
# Load all PDFs and count tokens
context, token_count, doc_names = load_documents("documents")
st.session_state.context = context
st.session_state.token_count = token_count
st.session_state.doc_names = doc_names
# Display loaded documents info
if "token_count" in st.session_state:
st.success(f"✅ Loaded {len(st.session_state.doc_names)} documents")
st.metric("Total Tokens", f"{st.session_state.token_count:,}")
st.write("**Documents:**")
for name in st.session_state.doc_names:
st.write(f"• {name}")La barra lateral carga documentos y muestra el recuento de tokens. El estado de sesión de Streamlit mantiene los documentos cargados entre interacciones.
# Main content area
if "context" not in st.session_state:
st.info("👈 Click 'Load Documents' in the sidebar to begin")
else:
st.subheader("Select Models to Compare")
col1, col2, col3, col4 = st.columns(4)
# Model selection checkboxes
with col1:
use_gpt5 = st.checkbox("GPT-5", value=True)
with col2:
use_claude = st.checkbox("Claude Sonnet 4.5", value=True)
with col3:
use_deepseek_v32 = st.checkbox("DeepSeek v3.2-Exp", value=True)
with col4:
use_deepseek_v31 = st.checkbox("DeepSeek v3.1-Terminus", value=True)
# Sample questions for quick testing
sample_questions = [
"Compare the main approaches to attention mechanisms described in these documents",
"What are the key differences between sparse and dense attention?",
"Summarize the common themes across all documents"
]Cuatro casillas de verificación para la selección del modelo y preguntas de muestra predefinidas.
# Question input with samples
question_choice = st.selectbox(
"Select a sample question or write your own:",
["Custom"] + sample_questions
)
if question_choice == "Custom":
question = st.text_area("Enter your question:", height=100)
else:
question = st.text_area("Enter your question:", value=question_choice, height=100)
# Query button and model execution
if st.button("🚀 Query Models", type="primary"):
if not question:
st.error("Please enter a question")
else:
# Build list of selected models
selected_models = []
if use_gpt5:
selected_models.append("gpt-5")
if use_claude:
selected_models.append("claude-sonnet-4-5-20250929")
if use_deepseek_v32:
selected_models.append("deepseek-chat")
if use_deepseek_v31:
selected_models.append("deepseek-chat-v3.1")Los usuarios eligen una pregunta o escriben la suya propia y, a continuación, hacen clic en «Consultar modelos» para ejecutar la comparación en los modelos seleccionados.
results = []
# Query each model sequentially with progress indicator
for model_name in selected_models:
with st.spinner(f"Querying {model_name}..."):
result = query_model(
model_name,
st.session_state.context,
question
)
results.append(result)
# Store results in session state for persistence
st.session_state.results = resultsCada modelo se consulta secuencialmente con un indicador que muestra el progreso.
# Display results if available
if "results" in st.session_state:
st.divider()
st.subheader("📊 Results")
results = st.session_state.results
# Show model responses in expandable panels
st.markdown("### Responses")
for result in results:
with st.expander(f"**{result['model']}** - ${result['cost']:.4f} | {result['time']:.2f}s"):
if result['error']:
st.error(f"Error: {result['error']}")
else:
st.write(result['response'])
# Create metrics comparison table
metrics_df = pd.DataFrame([
{
"Model": r['model'],
"Input Tokens": r['input_tokens'],
"Output Tokens": r['output_tokens'],
"Total Tokens": r['total_tokens'],
"Cost ($)": f"${r['cost']:.4f}",
"Time (s)": f"{r['time']:.2f}"
}
for r in results
])
st.dataframe(metrics_df, use_container_width=True)Los resultados muestran la respuesta de cada modelo en paneles ampliables con el coste y el tiempo en el encabezado, seguidos de una tabla de métricas que se puede ordenar.
# Create visualization charts
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# Chart 1: Cost comparison bar chart
axes[0, 0].bar([r['model'] for r in results], [r['cost'] for r in results],
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
axes[0, 0].set_title('Cost Comparison')
axes[0, 0].set_ylabel('Cost ($)')
axes[0, 0].tick_params(axis='x', rotation=45)
# Chart 2: Response time bar chart
axes[0, 1].bar([r['model'] for r in results], [r['time'] for r in results],
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
axes[0, 1].set_title('Response Time Comparison')
axes[0, 1].set_ylabel('Time (seconds)')
# Chart 3: Token usage grouped bar chart
models = [r['model'] for r in results]
input_tokens = [r['input_tokens'] for r in results]
output_tokens = [r['output_tokens'] for r in results]
x = range(len(models))
width = 0.35
axes[1, 0].bar([i - width/2 for i in x], input_tokens, width, label='Input', color='#1f77b4')
axes[1, 0].bar([i + width/2 for i in x], output_tokens, width, label='Output', color='#ff7f0e')
axes[1, 0].set_title('Token Usage Comparison')
axes[1, 0].legend()Cuatro gráficos matplotlib en una parilla 2x2: barras de coste, barras de tiempo, barras de uso de tokens agrupadas y un gráfico de dispersión de coste frente a tiempo.
# Chart 4: Cost vs time tradeoff scatter plot
axes[1, 1].scatter([r['cost'] for r in results], [r['time'] for r in results],
s=100, alpha=0.6, color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
for i, r in enumerate(results):
axes[1, 1].annotate(r['model'], (r['cost'], r['time']), fontsize=8, ha='right')
axes[1, 1].set_title('Cost vs Time Trade-off')
axes[1, 1].set_xlabel('Cost ($)')
axes[1, 1].set_ylabel('Time (seconds)')
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
st.pyplot(fig)
# Display key findings
if len(results) > 1:
cheapest = min(results, key=lambda x: x['cost'])
fastest = min(results, key=lambda x: x['time'])
col1, col2 = st.columns(2)
with col1:
st.metric("Most Cost-Effective", cheapest['model'], f"${cheapest['cost']:.4f}")
with col2:
st.metric("Fastest Response", fastest['model'], f"{fastest['time']:.2f}s")Los resultados principales resaltan automáticamente los modelos más baratos y rápidos. Ver el archivo completo app.py en GitHub.
Inicia la aplicación:
streamlit run app.pyHaz clic en «Cargar documentos» para cargar los tres archivos PDF (57 204 tokens en total). Selecciona los modelos que deseas comparar (los cuatro por defecto), elige o escribe una pregunta y, a continuación, haz clic en «Consultar modelos».
Tiempos de respuesta esperados para un contexto de 57 000 tokens:
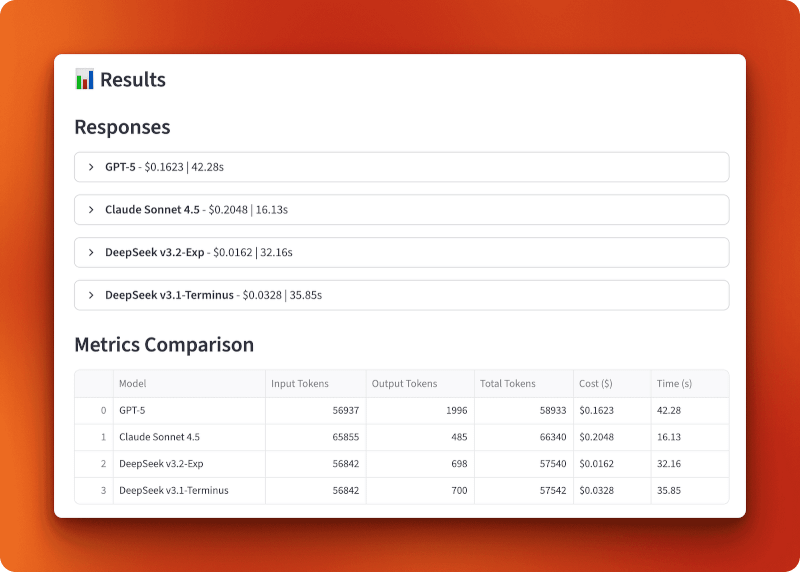
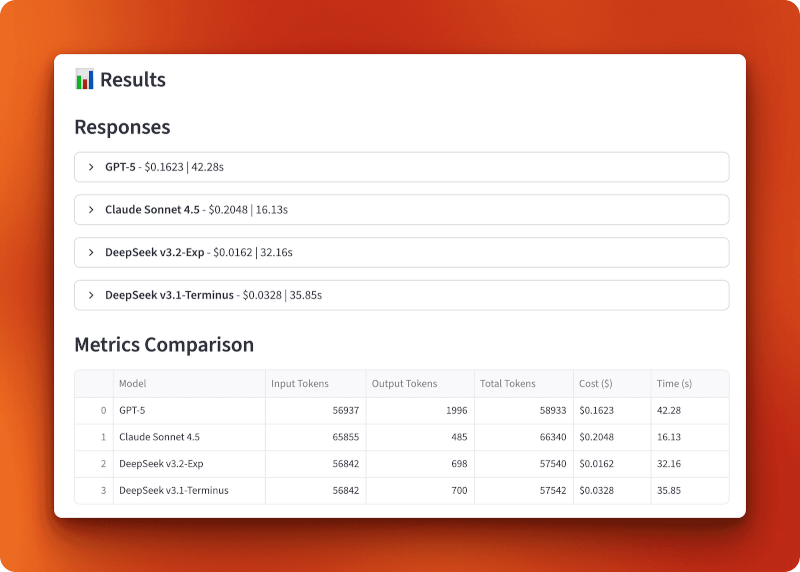
GPT-5 procesó 56 937 tokens de entrada y generó 1996 tokens de salida por 0,1623 dólares en 42,28 segundos. Claude Sonnet 4.5 procesó 65 855 tokens de entrada y generó 485 tokens de salida por 0,2048 dólares en 16,13 segundos: el más rápido, pero también el más caro. DeepSeek v3.2-Exp procesó 56 842 tokens de entrada y generó 698 tokens de salida por solo 0,0162 dólares en 32,16 segundos. DeepSeek v3.1-Terminus procesó 56 842 tokens de entrada y generó 700 tokens de salida por 0,0328 $ en 35,85 segundos.
La comparación entre la versión 3.1 y la versión 3.2 muestra el impacto de la atención dispersa. Ambos procesaron entradas idénticas y produjeron resultados casi idénticos (698 frente a 700 tokens), pero la versión 3.2 costó la mitad (0,0162 $ frente a 0,0328 $) y funcionó ligeramente más rápido (32,16 s frente a 35,85 s). Eso supone una reducción del coste dos veces mayor que la que se consigue solo con la atención dispersa.
En comparación con GPT-5 y Claude, la versión 3.2 es 10 veces más barata que GPT-5 (0,0162 $ frente a 0,1623 $) y 13 veces más barata que Claude (0,0162 $ frente a 0,2048 $). Con más de 100 consultas de esta longitud, gastarías 16,20 $ con DeepSeek v3.2, frente a los 162,30 $ con GPT-5 o los 204,80 $ con Claude.
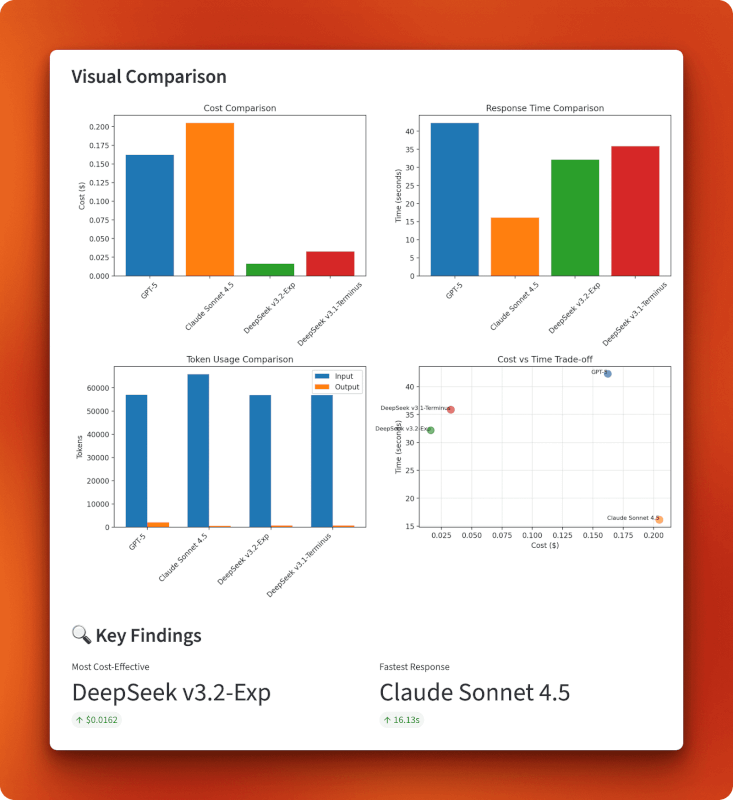
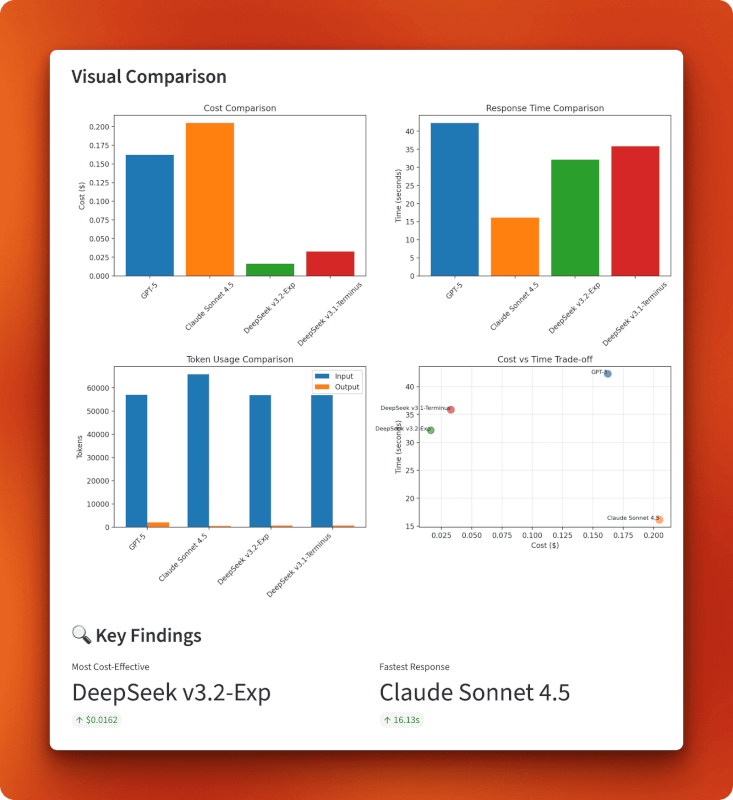
Los gráficos confirman la posición de DeepSeek v3.2 en el cuadrante inferior izquierdo de la relación coste-tiempo: el más barato en general, con 0,0162 dólares, al tiempo que mantiene una velocidad razonable de 32 segundos. Claude sacrifica el coste por la velocidad (es caro, pero el más rápido), GPT-5 queda rezagado en ambos parámetros (es caro y el más lento) y la versión 3.1 se sitúa en un término medio. El gráfico de uso de tokens muestra que todos los modelos procesan tamaños de entrada similares, pero la longitud de la salida varía: GPT-5 generó la respuesta más larga, con 1996 tokens, Claude fue más breve, con 485 tokens, y las dos versiones de DeepSeek produjeron salidas similares, en torno a los 700 tokens.
Cargar documentos completos en el contexto funciona mejor cuando necesitas comprender varios documentos. Si tu pregunta requiere conectar ideas de tres artículos diferentes, la fragmentación y la recuperación podrían pasar por alto esas conexiones. El modelo necesita verlo todo de una vez.
Este patrón se adapta a varios casos de uso:
El enfoque no funciona bien cuando:
La escasa atención de DeepSeek cambia la economía del procesamiento de contextos largos. Lo que antes costaba entre 0,15 y 0,20 dólares por consulta, ahora cuesta entre 0,01 y 0,02 dólares. Esto hace que los enfoques de contexto completo sean prácticos para aplicaciones que ejecutan cientos o miles de consultas al día.
La atención dispersa de DeepSeek v3.2 ofrece la misma calidad de modelo a la mitad del coste de la v3.1. La comparación de múltiples documentos que creamos lo demostró en la práctica. El procesamiento de 57 000 tokens costó 0,0162 dólares con la versión 3.2 frente a los 0,0328 dólares con la versión 3.1, y ambas produjeron resultados casi idénticos. En comparación con GPT-5 y Claude, la versión 3.2 es entre 10 y 13 veces más barata, al tiempo que mantiene unos tiempos de respuesta razonables. En las aplicaciones que procesan contextos largos con regularidad, ese ahorro se acumula rápidamente.
Si estás trabajando en el análisis de documentos, herramientas de investigación o cualquier aplicación que maneje contextos largos, vale la pena probar la versión 3.2. Solo recuerda que aún es experimental, así que pruébalo antes de ponerlo en producción.
Para obtener más información sobre las últimas novedades en IA, consulta estos blogs:
¡Aprende IA con estos cursos!
Curso
Curso
Curso
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita
Tutorial
Tutorial
Kurtis Pykes


