
Curso
Working with DeepSeek in Python
3 h
1.2K
A DeepSeek acabou de lançar a versão 3.2-Exp, um modelo experimental que reduz os custos da API em mais da metade. Se você já trabalhou com grandes modelos de linguagem, sabe que o processamento de contextos longos fica caro rapidamente. Essa nova versão resolve esse problema com uma técnica chamadaAtenção Esparsa DeepSeek ( ).
Neste tutorial, vou explicar o que torna a versão 3.2 do DeepSeek diferente das versões anteriores, como funciona a atenção esparsa nos bastidores e como usar o modelo em seus projetos. Vamos falar sobre o básico de como fazer chamadas de API e criar um projeto de demonstração que mostra onde esse modelo funciona melhor.
No final, você vai criar um aplicativo Streamlit que compara os custos entre diferentes LLMs, incluindo o DeepSeek v3.2:
Vamos começar com algumas informações básicas sobre o DeepSeek e o que mudou nesta versão.
A DeepSeek é uma empresa de IA de código aberto com sede na China que cria grandes modelos de linguagem sob a licença do MIT. Os modelos deles competem com o GPT-5 e Claude em raciocínio, codificação e tarefas de uso geral. A empresa lançou várias versões ao longo do último ano, incluindo o DeepSeek-V3 e DeepSeek-R1, que chamaram a atenção pelo ótimo desempenho a custos mais baixos do que as alternativas de código fechado.
Antes da versão 3.2, a versão mais recente era v3.1-Terminus, um modelo com 685 bilhões de parâmetros. Embora tenha apresentado um desempenho sólido, o processamento de contextos longos continuou sendo caro. É aí que entra a nova versão experimental.
DeepSeek lançado v3.2-Exp em 29 de setembro de 2025 (2025-09-29). O “Exp” significa experimental, ou seja, o modelo ainda está sendo testado e aperfeiçoado. Não espere estabilidade de nível de produção ainda, mas você pode usá-lo para pesquisas e projetos nos quais deseja testar os recursos mais recentes.
O modelo foi construído com base na versão 3.1-Terminus e mantém a mesma arquitetura de parâmetros 685B. O que o diferencia é como ele processa as informações internamente. Ele usa um formato de API compatível com OpenAI, então se você já usou o SDK OpenAI antes, já sabe como trabalhar com o DeepSeek (também vou explicar neste artigo como fazer sua primeira chamada de API).
E aí vem a grande mudança: A DeepSeek baixou os preços da API em mais de 50% em comparação coma versão 3.1 do . E o desempenho continuou o mesmo. Você está recebendo respostas da mesma qualidade pela metade do preço.
Essa queda de preço veio de uma melhoria técnica chamada DeepSeek Sparse Attention (DSA). Em vez de fazer o modelo prestar atenção em cada token da sua entrada (o que é bem caro em termos de computação), o DSA foca seletivamente no que importa. Vamos ver como isso funciona na próxima seção.
Se você quiser saber todos os detalhes técnicos, a DeepSeek publicou um relatório técnico no GitHub que explica as mudanças na arquitetura e os resultados dos benchmarks.
Antes de entrarmos no código, vamos falar sobre o que torna o v3.2 mais barato e rápido. A resposta está em como o modelo processa suas entradas.
Quando você manda um texto para um modelo de linguagem, ele divide sua entrada em tokens (basicamente palavras ou partes de palavras). Depois, o modelo precisa descobrir quais tokens estão relacionados entre si. Esse processo é chamado de atenção.
Nos transformadores tradicionais transformadores, cada token olha para todos os outros tokens. Se você tem 1.000 fichas, cada uma verifica todas as outras 999. Isso dá 1 milhão de comparações. Com 10.000 tokens, você tem 100 milhões de comparações. A matemática é quadrática: se você dobrar o tamanho da entrada, vai quadruplicar o custo de computação.
É por isso que o processamento de contexto longo fica caro. Sua conta de API aumenta rapidamente à medida que seus documentos ficam mais longos.
Nem todos os tokens precisam olhar para todos os outros tokens. Quando você está lendo esta frase agora, você não está constantemente relendo cada palavra que veio antes. Você se concentra no que é importante.
A atenção dispersa faz a mesma coisa. Em vez de comparar cada token com todos os outros tokens, o modelo escolhe seletivamente quais comparações são importantes. Algumas abordagens mais antigas para isso incluem:
Esses métodos economizam computação, mas são meio rígidos. Eles decidem com antecedência quais tokens podem interagir, independentemente do que o seu texto realmente diz. Às vezes, você precisa de uma palavra no começo de um documento para conectar com algo no final. Padrões fixos podem deixar isso passar.
A DSA segue um caminho diferente. Em vez de usar padrões fixos, ele aprende quais tokens realmente precisam se relacionar com base no próprio conteúdo. O modelo escolhe conexões relevantes na hora.
Veja como funciona em um nível mais geral. Durante o treinamento, o DeepSeek adicionou um mecanismo de seleção a cada camada de atenção. Esse mecanismo analisa seus tokens e decide quais conexões de atenção valem a pena ser calculadas. Ele guarda as coisas importantes e ignora o resto.
A escolha não é aleatória. O modelo aprendeu durante o treinamento quais tipos de conexões são importantes para diferentes tarefas. Quando você manda uma mensagem sobre código, ela se concentra em padrões diferentes do que quando você manda um documento legal.
O resultado: O DSA reduz o número de operações de atenção sem prejudicar a qualidade da saída. No relatório técnico, a DeepSeek mostra queo v3.2 tem um desempenho quase igual ao do v3.1-Terminus nos benchmarks, mas com menos cálculos por token. Você obtém a mesma qualidade do modelo por aproximadamente metade do custo da API.
Aqui está o que DSA significa na prática:
Os benefícios aparecem mais nesses casos de uso:
Se o seu aplicativo lida com entradas longas, o DSA faz uma diferença real. Você não está só economizando dinheiro. Você está tendo um desempenho melhor em tarefas nas quais a atenção tradicional tem dificuldade.
Agora que você já entende como o DSA funciona, vamos usar o modelo por meio de sua API.
Você vai precisar do Python 3.8 ou mais recente instalado no seu computador. Se você é novo no trabalho com LLMs via APIs, talvez queira conferir o guia do DataCamp sobre como aprender IA para se familiarizar com o básico. Também temos um tutorial mais detalhado sobre a API DeepSeek. tutorial da API DeepSeek que fala sobre as versões anteriores, caso você queira saber mais.
A boa notícia: se você já usou a API da OpenAI antes, já sabe como usar o DeepSeek. O formato da API é igual.
Primeiro, pega sua chave API em platform.deepseek.com. Você vai precisar criar uma conta, caso ainda não tenha uma.
Instale os pacotes necessários:
uv add openai python-dotenvCrie um arquivo .env no diretório do seu projeto e adicione sua chave API:
DEEPSEEK_API_KEY=your_api_key_hereAqui está um exemplo básico usando o SDK da OpenAI. A única diferença em relação ao uso da API da OpenAI é o parâmetro base_url e sua chave API:
from openai import OpenAI
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize OpenAI-compatible client with DeepSeek endpoint
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# Send a chat completion request to DeepSeek v3.2
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "Explain sparse attention in one sentence."}
]
)
# Print the model's response
print(response.choices[0].message.content)Quando você executar isso, vai receber uma resposta tipo:
Sparse attention reduces computational cost by having each token attend to only a subset of relevant tokens rather than all tokens in a sequence.O modelo deepseek-chat é o modo sem pensar de v3.2-Exp. Ele processa sua solicitação e retorna uma resposta sem mostrar suas etapas de raciocínio.
Se você quiser ver como o modelo raciocina, use deepseek-reasoner. Esse modelo mostra a linha de raciocínio antes de te dar a resposta final:
# Use deepseek-reasoner to see the model's reasoning process
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "Which is larger: 9.11 or 9.8?"}
]
)
# Print both reasoning and final answer
print("Reasoning:", response.choices[0].message.reasoning_content)
print("Answer:", response.choices[0].message.content)Isso vai mostrar algo tipo:
Reasoning: To compare 9.11 and 9.8, I need to look at the digits after the decimal point. 9.11 has digits 1 and 1 after the decimal, making it 9 + 0.11. Meanwhile, 9.8 is 9 + 0.8. Since 0.8 is greater than 0.11, 9.8 is the larger number.
Answer: 9.8 is larger than 9.11.O modelo de raciocínio pode gerar até 64 mil tokens de conteúdo de raciocínio (padrão é 32 mil) antes de chegar na resposta final. Observe que ele não suporta alguns parâmetros como temperature ou top_p. A API oficial do DeepSeek ainda não suporta um parâmetro reasoning_effort para controlar a profundidade do raciocínio (embora alguns fornecedores terceirizados, como o LangChain, tenham adicionado esse recurso às suas integrações).
O objeto de resposta segue a estrutura da OpenAI. Você pode acessar o conteúdo através de response.choices[0].message.content, verificar o uso do token com response.usage e ver o modelo usado com response.model.
A API não é sua única opção. A DeepSeek disponibiliza seus modelos como código aberto, para que você mesmo possa executá-los.
Hugging Face: O modelo tá disponível em huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp. Você pode usar os provedores de inferência da Hugging Face para rodar o modelo sem precisar gerenciar a infraestrutura ou baixar os pesos para fazer a inferência localmente. A rota local funciona bem se você tiver o hardware (pense nos orçamentos de data center ou em uma pequena fazenda de GPUs no seu armário para um modelo de parâmetro 685B).
vLLM: Para implantações auto-hospedadas em escala, o vLLM oferece inferência otimizada com suporte para v3.2. É mais rápido do que rodar o modelo por transformadores padrão e lida bem com o processamento em lote. Use isso se você estiver usando o modelo em produção e tiver uma infraestrutura robusta para dar suporte.
Para a maioria dos desenvolvedores iniciantes, a API é a escolha certa. Você paga só pelo que usa, e o DeepSeek cuida do dimensionamento e da manutenção.
Você já viu como funciona a API do DeepSeek v3.2 e fez suas primeiras chamadas. Agora vamos testar isso com uma comparação do mundo real.
A atenção esparsa do DeepSeek realmente economiza dinheiro ao processar contextos longos? E como é o desempenho dele comparado com o GPT-5 e o Claude Sonnet 4.5?
Para responder a essa pergunta, vamos criar uma ferramenta de comparação que carrega vários artigos de pesquisa em um único contexto e envia a mesma consulta para todos os quatro modelos. Você vai ver exatamente quanto custa cada modelo, como ele responde e que tipo de respostas ele dá.
A maioria dos sistemas de análise de documentos usa RAG: eles dividem seus documentos em pequenos pedaços, incorporam-nos e recuperam apenas os pedaços relevantes quando você faz uma pergunta. Isso funciona bem para pesquisas simples, mas você perde as conexões entre as diferentes partes dos seus documentos. E se a resposta precisar entender as relações entre vários artigos?
Os modelos de contexto longo resolvem isso lendo tudo de uma vez. Sem fragmentação, sem recuperação, sem contexto perdido. Você coloca todos os seus documentos em um único prompt e deixa o modelo ver o quadro completo. O problema é o custo. Com a atenção tradicional, processar mais de 50.000 tokens fica caro rapidinho.
É aqui que a gente testa a atenção esparsa do DeepSeek. Vamos criar um aplicativo que carrega três artigos de pesquisa (aproximadamente 57.000 tokens no total) em um único contexto e compara como quatro modelos lidam com a mesma consulta: GPT-5, Claude Sonnet 4.5, DeepSeek v3.2-Exp (com atenção esparsa) e DeepSeek v3.1-Terminus (a versão anterior sem atenção esparsa). Você vai ver as diferenças de custo, tempos de resposta e qualidade de saída lado a lado.
Aqui tá como a aplicação final ficou:
Observação: O resto desta seção tem um passo a passo detalhado de como criar esse aplicativo do zero. Você não precisa construir isso para entender os resultados da comparação, mas examinar o código lhe dará padrões práticos para construir suas próprias aplicações de contexto longo com o DeepSeek.
Vamos criar isso como um aplicativo Streamlit com três módulos de suporte: um para carregar documentos, outro para configurar o modelo e outro para lidar com consultas. O fluxo do aplicativo é simples: carregue os PDFs, escolha os modelos, faça uma pergunta e compare os resultados.
Comece criando um diretório de projeto e instalando as dependências:
mkdir multi-document-qa
cd multi-document-qa
uv add streamlit langchain langchain-openai langchain-anthropic langchain-community pypdf tiktoken python-dotenv matplotlib pandasCrie um arquivo ` .env ` com suas chaves de API:
OPENAI_API_KEY=your_openai_key
ANTHROPIC_API_KEY=your_anthropic_key
DEEPSEEK_API_KEY=your_deepseek_keyBaixe três artigos de pesquisa sobre mecanismos de atenção:
mkdir documents
cd documents
curl -L -o selective-attention.pdf "https://arxiv.org/pdf/2410.02703"
curl -L -o differential-transformer.pdf "https://arxiv.org/pdf/2410.05258"
curl -L -o sparse-attention-long-range.pdf "https://arxiv.org/pdf/2406.16747"
cd ..Esses três documentos têm um total de 57.204 tokens quando carregados.
Criar um document_loader.py:
from langchain_community.document_loaders import PyPDFLoader
import tiktoken
from pathlib import Path
def load_documents(documents_dir="documents"):
docs_path = Path(documents_dir)
pdf_files = list(docs_path.glob("*.pdf"))
all_text = ""
document_names = []
# Load each PDF and concatenate with separators
for pdf_file in sorted(pdf_files):
loader = PyPDFLoader(str(pdf_file))
pages = loader.load()
doc_text = "\n\n".join([page.page_content for page in pages])
all_text += f"\n\n=== Document: {pdf_file.name} ===\n\n{doc_text}"
document_names.append(pdf_file.name)A função carrega todos os PDFs de um diretório, pega o texto de cada página e junta tudo com separadores de documento.
# Count tokens using GPT-4 encoding (accurate across providers)
encoding = tiktoken.encoding_for_model("gpt-4")
token_count = len(encoding.encode(all_text))
return all_text, token_count, document_namesA contagem de tokens usa o tiktoken com codificação GPT-4, que dá estimativas precisas em todos os provedores, já que eles usam tokenização parecida. Dá uma olhada no documento completo document_loader.py no GitHub.
Criar um model_config.py:
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
import os
# Pricing per million tokens (as of October 2025)
MODEL_PRICING = {
"gpt-5": {"input": 2.50, "output": 10.00, "name": "GPT-5"},
"claude-sonnet-4-5-20250929": {"input": 3.00, "output": 15.00, "name": "Claude Sonnet 4.5"},
"deepseek-chat": {"input": 0.28, "output": 0.42, "name": "DeepSeek v3.2-Exp"},
"deepseek-chat-v3.1": {"input": 0.55, "output": 2.19, "name": "DeepSeek v3.1-Terminus"},
}O dicionário de preços guarda os custos por milhão de tokens (em outubro de 2025). O DeepSeek v3.2 com atenção esparsa é cerca de 10 vezes mais barato que o GPT-5 e o Claude, enquanto o v3.1 fica no meio, custando o dobro do v3.2.
def get_model(model_name):
"""Initialize a chat model by name using LangChain's unified interface."""
if model_name == "gpt-5":
return ChatOpenAI(model="gpt-5", temperature=0, api_key=os.getenv("OPENAI_API_KEY"))
elif model_name == "claude-sonnet-4-5-20250929":
return ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0,
api_key=os.getenv("ANTHROPIC_API_KEY"))
elif model_name == "deepseek-chat":
return ChatOpenAI(model="deepseek-chat", temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com")
elif model_name == "deepseek-chat-v3.1":
# Note: v3.1-Terminus endpoint expires on October 15, 2025
return ChatOpenAI(model="deepseek-chat", temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v3.1_terminus_expires_on_20251015")
def calculate_cost(model_name, input_tokens, output_tokens):
"""Calculate total cost based on input and output token usage."""
pricing = MODEL_PRICING[model_name]
input_cost = (input_tokens / 1_000_000) * pricing["input"]
output_cost = (output_tokens / 1_000_000) * pricing["output"]
return input_cost + output_costA função ` get_model() ` inicializa cada modelo usando a interface unificada do LangChain. Os modelos DeepSeek usam pontos finais compatíveis com OpenAI com URLs base personalizadas. Observação: O endpoint v3.1-Terminus vai expirar em 15 de outubro de 2025. O arquivo completo model_config.py está no GitHub.
Criar um query_handler.py:
import time
from langchain_core.messages import SystemMessage, HumanMessage
from model_config import get_model, calculate_cost, MODEL_PRICING
def query_model(model_name, context, question):
"""Query a model with document context and track performance metrics."""
model = get_model(model_name)
# Embed full document context in system prompt
system_prompt = f"""Use the given context to answer the question.
If you don't know the answer, say you don't know. Keep the answer concise.
Context:
{context}"""
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=question)
]
# Track response time
start_time = time.time()O sistema incorpora todos os 57.000 tokens dos documentos. Os processos tradicionais de atenção analisam cada token em relação a todos os outros tokens. A atenção esparsa do DeepSeek v3.2 ignora conexões irrelevantes, reduzindo custos.
try:
response = model.invoke(messages)
elapsed_time = time.time() - start_time
# Extract token usage (different providers use different formats)
if hasattr(response, 'response_metadata') and 'token_usage' in response.response_metadata:
token_usage = response.response_metadata['token_usage']
input_tokens = token_usage.get('prompt_tokens', 0)
output_tokens = token_usage.get('completion_tokens', 0)
elif hasattr(response, 'usage_metadata'):
input_tokens = response.usage_metadata.get('input_tokens', 0)
output_tokens = response.usage_metadata.get('output_tokens', 0)
# Calculate total cost
cost = calculate_cost(model_name, input_tokens, output_tokens)
return {
"model": MODEL_PRICING[model_name]["name"],
"response": response.content,
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"cost": cost,
"time": elapsed_time,
"error": None
}Diferentes integrações LangChain retornam o uso de tokens em formatos diferentes (OpenAI usa response_metadata, Anthropic usa usage_metadata), então verificamos ambos. A função programa o tempo, pega a contagem de tokens, calcula os custos e devolve um dicionário com todas as métricas. Dá uma olhada no arquivo completo query_handler.py no GitHub.
Criar um app.py:
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
from document_loader import load_documents
from query_handler import query_model
from dotenv import load_dotenv
# Load API keys from .env file
load_dotenv()
# Configure Streamlit page with wide layout
st.set_page_config(
page_title="Multi-Document Research Assistant",
page_icon="📚",
layout="wide"
)
st.title("📚 Multi-Document Research Assistant")
st.markdown("Compare long-context performance across GPT-5, Claude Sonnet 4.5, DeepSeek v3.2, and DeepSeek v3.1")Configuração padrão do Streamlit com um layout amplo para comparações lado a lado.
# Sidebar for document loading
with st.sidebar:
st.header("📄 Documents Loaded")
if st.button("Load Documents"):
with st.spinner("Loading documents..."):
# Load all PDFs and count tokens
context, token_count, doc_names = load_documents("documents")
st.session_state.context = context
st.session_state.token_count = token_count
st.session_state.doc_names = doc_names
# Display loaded documents info
if "token_count" in st.session_state:
st.success(f"✅ Loaded {len(st.session_state.doc_names)} documents")
st.metric("Total Tokens", f"{st.session_state.token_count:,}")
st.write("**Documents:**")
for name in st.session_state.doc_names:
st.write(f"• {name}")A barra lateral carrega documentos e mostra a contagem de tokens. O estado da sessão do Streamlit mantém os documentos carregados entre as interações.
# Main content area
if "context" not in st.session_state:
st.info("👈 Click 'Load Documents' in the sidebar to begin")
else:
st.subheader("Select Models to Compare")
col1, col2, col3, col4 = st.columns(4)
# Model selection checkboxes
with col1:
use_gpt5 = st.checkbox("GPT-5", value=True)
with col2:
use_claude = st.checkbox("Claude Sonnet 4.5", value=True)
with col3:
use_deepseek_v32 = st.checkbox("DeepSeek v3.2-Exp", value=True)
with col4:
use_deepseek_v31 = st.checkbox("DeepSeek v3.1-Terminus", value=True)
# Sample questions for quick testing
sample_questions = [
"Compare the main approaches to attention mechanisms described in these documents",
"What are the key differences between sparse and dense attention?",
"Summarize the common themes across all documents"
]Quatro caixas de seleção para escolher o modelo e perguntas de exemplo pré-definidas.
# Question input with samples
question_choice = st.selectbox(
"Select a sample question or write your own:",
["Custom"] + sample_questions
)
if question_choice == "Custom":
question = st.text_area("Enter your question:", height=100)
else:
question = st.text_area("Enter your question:", value=question_choice, height=100)
# Query button and model execution
if st.button("🚀 Query Models", type="primary"):
if not question:
st.error("Please enter a question")
else:
# Build list of selected models
selected_models = []
if use_gpt5:
selected_models.append("gpt-5")
if use_claude:
selected_models.append("claude-sonnet-4-5-20250929")
if use_deepseek_v32:
selected_models.append("deepseek-chat")
if use_deepseek_v31:
selected_models.append("deepseek-chat-v3.1")Os usuários escolhem uma pergunta ou escrevem a sua própria e, em seguida, clicam em “Consultar modelos” para fazer a comparação nos modelos selecionados.
results = []
# Query each model sequentially with progress indicator
for model_name in selected_models:
with st.spinner(f"Querying {model_name}..."):
result = query_model(
model_name,
st.session_state.context,
question
)
results.append(result)
# Store results in session state for persistence
st.session_state.results = resultsCada modelo é consultado sequencialmente com um indicador giratório mostrando o progresso.
# Display results if available
if "results" in st.session_state:
st.divider()
st.subheader("📊 Results")
results = st.session_state.results
# Show model responses in expandable panels
st.markdown("### Responses")
for result in results:
with st.expander(f"**{result['model']}** - ${result['cost']:.4f} | {result['time']:.2f}s"):
if result['error']:
st.error(f"Error: {result['error']}")
else:
st.write(result['response'])
# Create metrics comparison table
metrics_df = pd.DataFrame([
{
"Model": r['model'],
"Input Tokens": r['input_tokens'],
"Output Tokens": r['output_tokens'],
"Total Tokens": r['total_tokens'],
"Cost ($)": f"${r['cost']:.4f}",
"Time (s)": f"{r['time']:.2f}"
}
for r in results
])
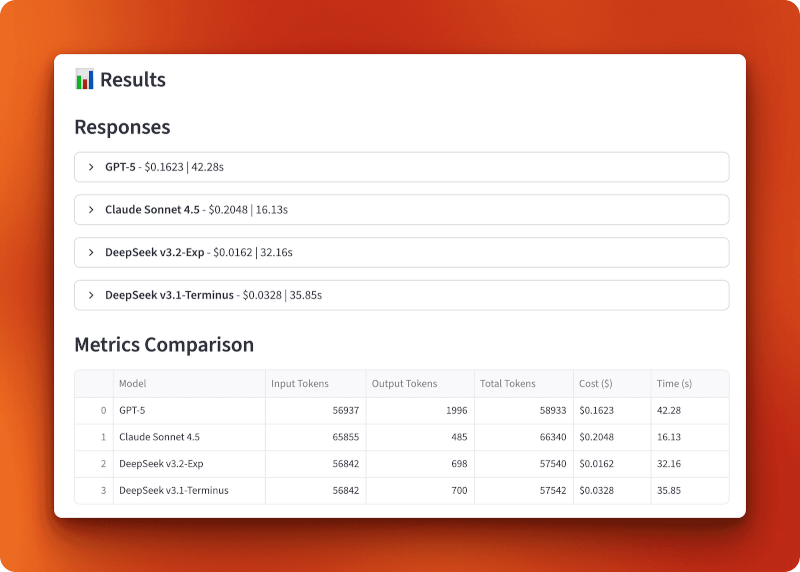
st.dataframe(metrics_df, use_container_width=True)Os resultados mostram a resposta de cada modelo em painéis expansíveis com custo e tempo no cabeçalho, seguidos por uma tabela de métricas classificável.
# Create visualization charts
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# Chart 1: Cost comparison bar chart
axes[0, 0].bar([r['model'] for r in results], [r['cost'] for r in results],
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
axes[0, 0].set_title('Cost Comparison')
axes[0, 0].set_ylabel('Cost ($)')
axes[0, 0].tick_params(axis='x', rotation=45)
# Chart 2: Response time bar chart
axes[0, 1].bar([r['model'] for r in results], [r['time'] for r in results],
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
axes[0, 1].set_title('Response Time Comparison')
axes[0, 1].set_ylabel('Time (seconds)')
# Chart 3: Token usage grouped bar chart
models = [r['model'] for r in results]
input_tokens = [r['input_tokens'] for r in results]
output_tokens = [r['output_tokens'] for r in results]
x = range(len(models))
width = 0.35
axes[1, 0].bar([i - width/2 for i in x], input_tokens, width, label='Input', color='#1f77b4')
axes[1, 0].bar([i + width/2 for i in x], output_tokens, width, label='Output', color='#ff7f0e')
axes[1, 0].set_title('Token Usage Comparison')
axes[1, 0].legend()Quatro gráficos matplotlib em uma grade 2x2: barras de custo, barras de tempo, barras de uso de tokens agrupadas e um gráfico de dispersão de custo versus tempo.
# Chart 4: Cost vs time tradeoff scatter plot
axes[1, 1].scatter([r['cost'] for r in results], [r['time'] for r in results],
s=100, alpha=0.6, color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
for i, r in enumerate(results):
axes[1, 1].annotate(r['model'], (r['cost'], r['time']), fontsize=8, ha='right')
axes[1, 1].set_title('Cost vs Time Trade-off')
axes[1, 1].set_xlabel('Cost ($)')
axes[1, 1].set_ylabel('Time (seconds)')
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
st.pyplot(fig)
# Display key findings
if len(results) > 1:
cheapest = min(results, key=lambda x: x['cost'])
fastest = min(results, key=lambda x: x['time'])
col1, col2 = st.columns(2)
with col1:
st.metric("Most Cost-Effective", cheapest['model'], f"${cheapest['cost']:.4f}")
with col2:
st.metric("Fastest Response", fastest['model'], f"{fastest['time']:.2f}s")As principais conclusões destacam automaticamente os modelos mais baratos e rápidos. Veja o aplicativo completo app.py no GitHub.
Inicie o aplicativo:
streamlit run app.pyClique em “Carregar documentos” para carregar os três PDFs (57.204 tokens no total). Escolha os modelos que você quer comparar (os quatro por padrão), escolha ou escreva uma pergunta e clique em “Consultar modelos”.
Tempos de resposta esperados para um contexto de 57.000 tokens:
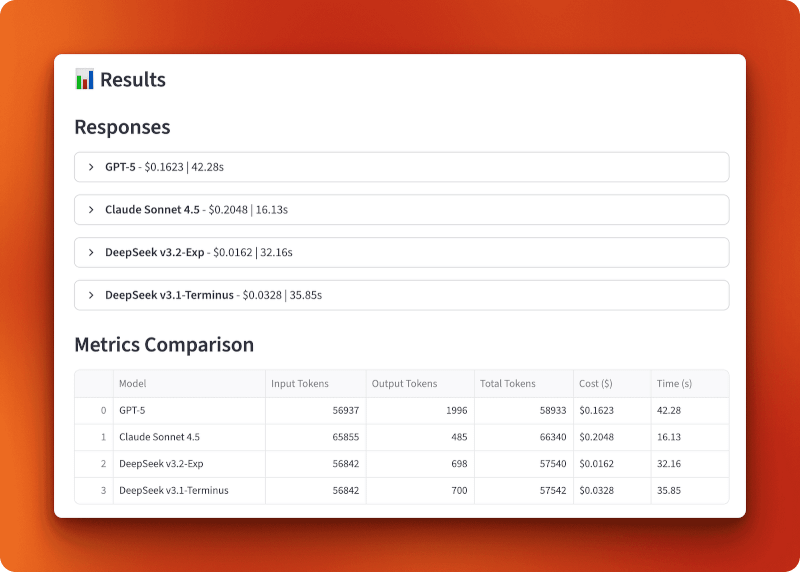
O GPT-5 processou 56.937 tokens de entrada e gerou 1.996 tokens de saída por US$ 0,1623 em 42,28 segundos. O Claude Sonnet 4.5 processou 65.855 tokens de entrada e gerou 485 tokens de saída por US$ 0,2048 em 16,13 segundos — o mais rápido, mas também o mais caro. O DeepSeek v3.2-Exp processou 56.842 tokens de entrada e gerou 698 tokens de saída por apenas US$ 0,0162 em 32,16 segundos. O DeepSeek v3.1-Terminus processou 56.842 tokens de entrada e gerou 700 tokens de saída por US$ 0,0328 em 35,85 segundos.
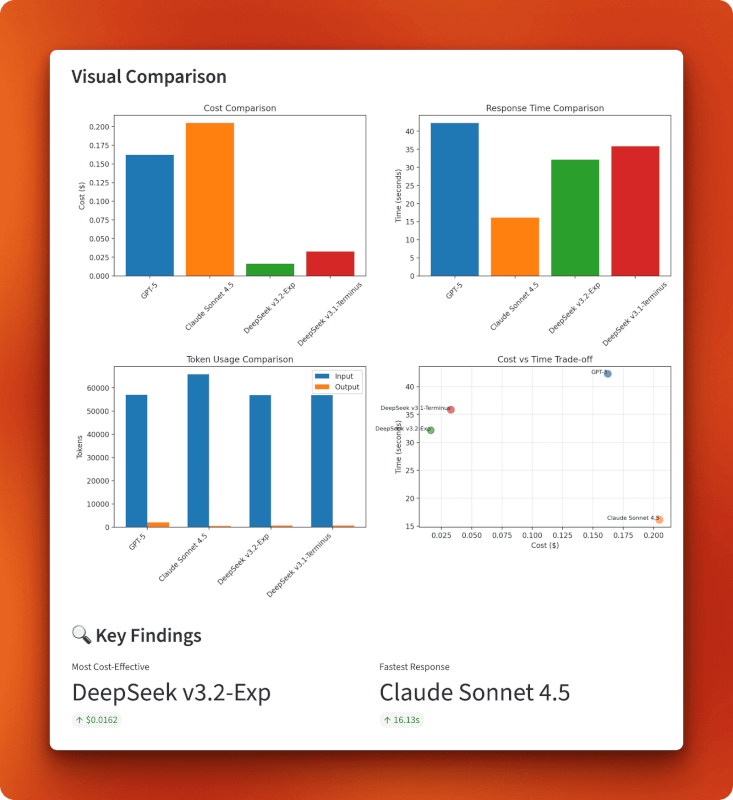
A comparação entre a versão 3.1 e a versão 3.2 mostra o impacto da atenção esparsa. Ambos processaram entradas idênticas e produziram resultados quase idênticos (698 contra 700 tokens), mas a versão 3.2 custou metade do preço (US$ 0,0162 contra US$ 0,0328) e foi um pouco mais rápida (32,16 s contra 35,85 s). Isso representa uma redução de custo duas vezes maior do que apenas a atenção esparsa.
Comparado com o GPT-5 e o Claude, o v3.2 é 10 vezes mais barato que o GPT-5 (R$ 0,0162 contra R$ 0,1623) e 13 vezes mais barato que o Claude (R$ 0,0162 contra R$ 0,2048). Com mais de 100 consultas desse tamanho, você gastaria US$ 16,20 com o DeepSeek v3.2, contra US$ 162,30 com o GPT-5 ou US$ 204,80 com o Claude.
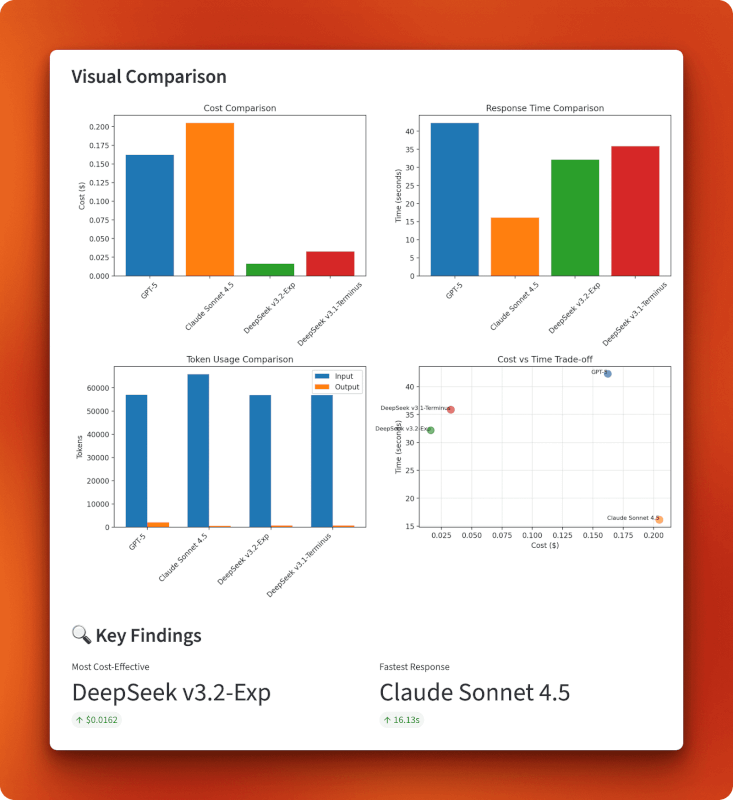
Os gráficos mostram que o DeepSeek v3.2 tá no canto inferior esquerdo do gráfico de custo versus tempo: é o mais barato no geral, com US$ 0,0162, e ainda mantém uma velocidade razoável de 32 segundos. Claude troca custo por velocidade (caro, mas mais rápido), o GPT-5 fica para trás em ambos os quesitos (caro e mais lento) e a v3.1 fica no meio termo. O gráfico de uso de tokens mostra que todos os modelos processam tamanhos de entrada parecidos, mas os comprimentos de saída variam — o GPT-5 gerou a resposta mais longa, com 1.996 tokens, o Claude foi mais direto, com 485 tokens, e as duas versões do DeepSeek produziram saídas parecidas, com cerca de 700 tokens.
Carregar documentos completos no contexto funciona melhor quando você precisa entender vários documentos. Se a sua pergunta precisa juntar ideias de três artigos diferentes, dividir em partes e recuperar pode deixar passar essas conexões. O modelo precisa ver tudo de uma vez.
Esse padrão serve pra vários casos de uso:
Essa abordagem não funciona bem quando:
A atenção esparsa do DeepSeek muda a economia do processamento de contexto longo. O que costumava custar US$ 0,15–0,20 por consulta agora custa US$ 0,01–0,02. Isso torna as abordagens de contexto completo práticas para aplicativos que executam centenas ou milhares de consultas por dia.
A atenção esparsa do DeepSeek v3.2 oferece a mesma qualidade de modelo pela metade do custo do v3.1. A comparação de vários documentos que fizemos mostrou isso na prática. Processar 57.000 tokens custou US$ 0,0162 com a versão 3.2, contra US$ 0,0328 com a versão 3.1, e ambas produziram resultados quase idênticos. Comparado com o GPT-5 e o Claude, o v3.2 é 10 a 13 vezes mais barato, mantendo tempos de resposta razoáveis. Para aplicativos que processam contextos longos regularmente, essas economias aumentam rapidamente.
Se você está trabalhando com análise de documentos, ferramentas de pesquisa ou qualquer aplicativo que lida com contextos longos, vale a pena testar a versão 3.2. Lembre-se de que ainda é experimental, então teste antes de colocar em produção.
Pra saber mais sobre as últimas novidades em IA, dá uma olhada nesses blogs:
Aprenda IA com esses cursos!
Curso
Curso
Curso
blog
Richie Cotton
7 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan


