
Cours
Working with DeepSeek in Python
3 h
1.2K
DeepSeek vient de publier la version 3.2-Exp, un modèle expérimental qui réduit de plus de moitié les coûts liés à l'API. Si vous avez déjà travaillé avec des modèles linguistiques de grande envergure, vous savez que le traitement de contextes longs peut rapidement devenir coûteux. Cette nouvelle version résout ce problème grâce à une technique appelée «DeepSeek Sparse Attention » ( ).
Dans ce tutoriel, je vais vous expliquer en quoi la version 3.2 diffère des versions précédentes de DeepSeek, comment fonctionne l'attention clairsemée en arrière-plan et comment utiliser le modèle dans vos projets. Nous aborderons les principes fondamentaux des appels API et créerons un projet de démonstration illustrant les domaines dans lesquels ce modèle est le plus efficace.
À la fin, vous aurez développé une application Streamlit qui compare les coûts de différents LLM, y compris DeepSeek v3.2 :
Commençons par présenter DeepSeek et les modifications apportées dans cette version.
DeepSeek est une entreprise d'intelligence artificielle open source basée en Chine qui développe de grands modèles linguistiques sous licence MIT. Leurs modèles rivalisent avec GPT-5 et Claude en matière de raisonnement, de codage et de tâches générales. La société a publié plusieurs versions au cours de l'année écoulée, notamment DeepSeek-V3 et DeepSeek-R1, qui ont attiré l'attention en raison de leurs performances élevées à des coûts inférieurs à ceux des alternatives à code source fermé.
Avant la version 3.2, la version la plus récente était v3.1-Terminus, un modèle comportant 685 milliards de paramètres. Bien qu'il ait affiché des performances solides, le traitement de contextes longs restait coûteux. C'est là qu'intervient la nouvelle version expérimentale.
DeepSeek a publié la version la version 3.2-Exp le 29 septembre 2025 (2025-09-29). Le préfixe « Exp » signifie « expérimental », ce qui indique que le modèle est encore en cours de test et de perfectionnement. Ne vous attendez pas encore à une stabilité de niveau production, mais vous pouvez l'utiliser pour vos recherches et vos projets lorsque vous souhaitez tester les dernières fonctionnalités.
Le modèle est basé sur la version 3.1-Terminus et conserve la même architecture de paramètres 685B. Ce qui le distingue, c'est la manière dont il traite les informations en interne. Il utilise un format API compatible avec OpenAI. Par conséquent, si vous avez déjà utilisé le SDK OpenAI, vous savez déjà comment utiliser DeepSeek (je vous expliquerai également dans cet article comment effectuer votre premier appel API).
Voici le changement majeur : DeepSeek a réduit les tarifs de son API de plus de 50 % par rapport àl' ion v3.1. Et les performances sont restées identiques. Vous bénéficiez de la même qualité de réponses à un coût réduit de moitié.
Cette baisse de prix résulte d'une amélioration technique appelée DeepSeek Sparse Attention (DSA). Au lieu de demander au modèle de prêter attention à chaque jeton de votre entrée (ce qui est coûteux en termes de calcul), DSA se concentre de manière sélective sur ce qui est important. Nous examinerons comment cela fonctionne dans la section suivante.
Si vous souhaitez obtenir tous les détails techniques, DeepSeek a publié un rapport technique sur GitHub qui explique les modifications apportées à l'architecture et les résultats des tests de performance.
Avant d'aborder le code, examinons ce qui rend la version 3.2 d' e plus économique et plus rapide. La réponse réside dans la manière dont le modèle traite vos données.
Lorsque vous envoyez du texte à un modèle linguistique, celui-ci divise votre saisie en tokens (grosso modo des mots ou des parties de mots). Le modèle doit ensuite déterminer quels jetons sont liés les uns aux autres. Ce processus est appelé attention.
Dans les transformateurs traditionnels, transformateurs, chaque jeton examine tous les autres jetons. Si vous disposez de 1 000 jetons, chacun d'entre eux vérifie les 999 autres. Cela représente un million de comparaisons. Avec 10 000 jetons, vous disposez de 100 millions de comparaisons. Le calcul est quadratique: doublez la longueur de votre entrée et vous quadruplez le coût de calcul.
C'est pourquoi le traitement dans un contexte étendu peut s'avérer coûteux. Votre facture API augmente rapidement à mesure que vos documents s'allongent.
Tous les jetons n'ont pas besoin de prendre en compte tous les autres jetons. Lorsque vous lisez cette phrase en ce moment, vous ne relisez pas constamment chaque mot qui précède. Vous vous concentrez sur ce qui est pertinent.
Une attention limitée produit le même effet. Au lieu de comparer chaque jeton à tous les autres jetons, le modèle sélectionne de manière sélective les comparaisons pertinentes. Certaines approches plus anciennes incluent :
Ces méthodes permettent d'économiser des ressources informatiques, mais elles sont rigides. Ils déterminent à l'avance quels jetons peuvent interagir, indépendamment du contenu réel de votre texte. Il est parfois nécessaire d'utiliser un mot au début d'un document pour faire le lien avec un élément à la fin. Les modèles fixes peuvent passer à côté de cela.
DSA adopte une approche différente. Au lieu d'utiliser des modèles fixes, il identifie quels tokens doivent réellement être pris en compte les uns par rapport aux autres en fonction du contenu lui-même. Le modèle sélectionne les connexions pertinentes en temps réel.
Voici comment cela fonctionne à un niveau élevé. Au cours de la formation, DeepSeek a intégré un mécanisme de sélection à chaque couche d'attention. Ce mécanisme examine vos jetons et détermine quelles connexions d'attention méritent d'être calculées. Il conserve les éléments importants et ignore le reste.
La sélection n'est pas aléatoire. Le modèle a appris pendant la formation quels types de connexions sont importants pour différentes tâches. Lorsque vous envoyez une invite concernant du code, celle-ci se concentre sur des modèles différents de ceux utilisés lorsque vous envoyez un document juridique.
Le résultat : Le DSA réduit le nombre d'opérations d'attention sans compromettre la qualité du résultat. Dans le rapport technique, DeepSeek démontre quela version 3.2 d' s affiche des performances quasi identiques à celles de la version 3.1-Terminus lors des tests de performance, tout en nécessitant moins de calculs par jeton. Vous bénéficiez de la même qualité de modèle pour environ la moitié du coût de l'API.
Voici ce que signifie concrètement le DSA :
Les avantages sont particulièrement évidents dans les cas d'utilisation suivants :
Si votre application traite des entrées volumineuses, DSA fait une réelle différence. Vous ne faites pas que réaliser des économies. Vous obtenez de meilleurs résultats dans les tâches où l'attention traditionnelle est difficile.
Maintenant que vous comprenez le fonctionnement de DSA, nous allons utiliser le modèle via son API.
Il est nécessaire que Python 3.8 ou une version plus récente soit installé sur votre ordinateur. Si vous débutez dans l'utilisation des LLM via des API, nous vous recommandons de consulter le guide DataCamp sur l'apprentissage de l'IA afin de vous familiariser avec les concepts fondamentaux. Nous proposons également un tutoriel sur l'API DeepSeek qui couvre les versions antérieures si vous souhaitez approfondir vos connaissances.
La bonne nouvelle : si vous avez déjà utilisé l'API d'OpenAI, vous savez déjà comment utiliser DeepSeek. Le format de l'API est identique.
Tout d'abord, veuillez obtenir votre clé API à partir de platform.deepseek.com. Il vous sera nécessaire de créer un compte si vous n'en possédez pas déjà un.
Veuillez installer les paquets requis :
uv add openai python-dotenvVeuillez créer un fichier .env dans le répertoire de votre projet et y ajouter votre clé API :
DEEPSEEK_API_KEY=your_api_key_hereVoici un exemple simple utilisant le SDK OpenAI. La seule différence par rapport à l'utilisation de l'API d'OpenAI réside dans le paramètre base_url et votre clé API :
from openai import OpenAI
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize OpenAI-compatible client with DeepSeek endpoint
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# Send a chat completion request to DeepSeek v3.2
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "Explain sparse attention in one sentence."}
]
)
# Print the model's response
print(response.choices[0].message.content)Lorsque vous exécutez cette commande, vous obtiendrez une réponse similaire à celle-ci :
Sparse attention reduces computational cost by having each token attend to only a subset of relevant tokens rather than all tokens in a sequence.Le modèle de l'« deepseek-chat » (l'esprit qui ne pense pas) est le mode de fonctionnement de l'v3.2-Exp. Il traite votre demande et renvoie une réponse sans exposer les étapes de son raisonnement.
Si vous souhaitez consulter le processus de raisonnement du modèle, veuillez utiliser deepseek-reasoner. Ce modèle présente son raisonnement avant de vous fournir la réponse finale :
# Use deepseek-reasoner to see the model's reasoning process
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "Which is larger: 9.11 or 9.8?"}
]
)
# Print both reasoning and final answer
print("Reasoning:", response.choices[0].message.reasoning_content)
print("Answer:", response.choices[0].message.content)Cela produira un résultat similaire à celui-ci :
Reasoning: To compare 9.11 and 9.8, I need to look at the digits after the decimal point. 9.11 has digits 1 and 1 after the decimal, making it 9 + 0.11. Meanwhile, 9.8 is 9 + 0.8. Since 0.8 is greater than 0.11, 9.8 is the larger number.
Answer: 9.8 is larger than 9.11.Le modèle de raisonnement peut générer jusqu'à 64 000 jetons de contenu de raisonnement (valeur par défaut : 32 000) avant de produire la réponse finale. Veuillez noter que certains paramètres tels que temperature ou top_p ne sont pas pris en charge. L'API officielle de DeepSeek ne prend pas encore en charge le paramètre reasoning_effort permettant de contrôler la profondeur du raisonnement (bien que certains fournisseurs tiers, tels que LangChain, l'aient ajouté à leurs intégrations).
L'objet de réponse respecte la structure d'OpenAI. Vous pouvez accéder au contenu via response.choices[0].message.content, vérifier l'utilisation des jetons avec response.usage et consulter le modèle utilisé avec response.model.
L'API n'est pas votre seule option. DeepSeek publie ses modèles en open source, vous pouvez donc les exécuter vous-même.
Hugging Face: Le modèle est disponible à l'adresse suivante : huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp. Vous pouvez utiliser les fournisseurs d'inférence de Hugging Face pour exécuter le modèle sans avoir à gérer vous-même l'infrastructure, ou télécharger les poids pour une inférence locale. La solution locale est efficace si vous disposez du matériel nécessaire (pensez aux budgets des centres de données ou à une petite ferme de GPU dans votre placard pour un modèle à 685 milliards de paramètres).
s sur le vLLM: Pour les déploiements auto-hébergés à grande échelle, vLLM offre une inférence optimisée avec la prise en charge de la version 3.2. Il est plus rapide que l'exécution du modèle via des transformateurs standard et gère efficacement le traitement par lots. Veuillez utiliser cette option si vous déployez le modèle en production et disposez d'une infrastructure solide pour le soutenir.
Pour la plupart des développeurs débutants, l'API constitue le choix approprié. Vous ne payez que ce que vous utilisez, et DeepSeek se charge de la mise à l'échelle et de la maintenance.
Vous avez observé le fonctionnement de l'API DeepSeek v3.2 et effectué vos premiers appels. Maintenant, examinons cela à l'aide d'une comparaison concrète.
L'attention limitée de DeepSeek permet-elle réellement de réduire les coûts lors du traitement de contextes longs ? Et comment se positionne-t-il par rapport à GPT-5 et Claude Sonnet 4.5 ?
Pour répondre à cette question, nous allons créer un outil de comparaison qui charge plusieurs articles de recherche dans un seul contexte et envoie la même requête aux quatre modèles. Vous pourrez voir précisément le coût de chaque modèle, sa rapidité de réponse et le type de réponses qu'il fournit.
La plupart des systèmes d'analyse de documents utilisent RAG: ils divisent vos documents en petits morceaux, les intègrent, puis ne récupèrent que les morceaux pertinents lorsque vous posez une question. Cette méthode est efficace pour les recherches simples, mais elle peut entraîner la perte de connexions entre différentes parties de vos documents. Que faire si la réponse nécessite de comprendre les relations entre plusieurs articles ?
Les modèles à contexte long résolvent ce problème en lisant tout en une seule fois. Pas de fragmentation, pas de récupération, pas de contexte manquant. Vous chargez tous vos documents dans une seule invite et permettez au modèle d'avoir une vue d'ensemble. Le problème réside dans le coût. Avec une approche traditionnelle, le traitement de plus de 50 000 jetons devient rapidement coûteux.
C'est ici que nous évaluons l'attention clairsemée de DeepSeek. Nous allons développer une application qui charge trois articles de recherche (environ 57 000 tokens au total) dans un seul contexte et compare la manière dont quatre modèles traitent la même requête : GPT-5, Claude Sonnet 4.5, DeepSeek v3.2-Exp (avec attention clairsemée) et DeepSeek v3.1-Terminus (la version précédente sans attention clairsemée). Vous pourrez comparer les différences de coûts, les délais de réponse et la qualité des résultats.
Voici à quoi ressemble l'application terminée :
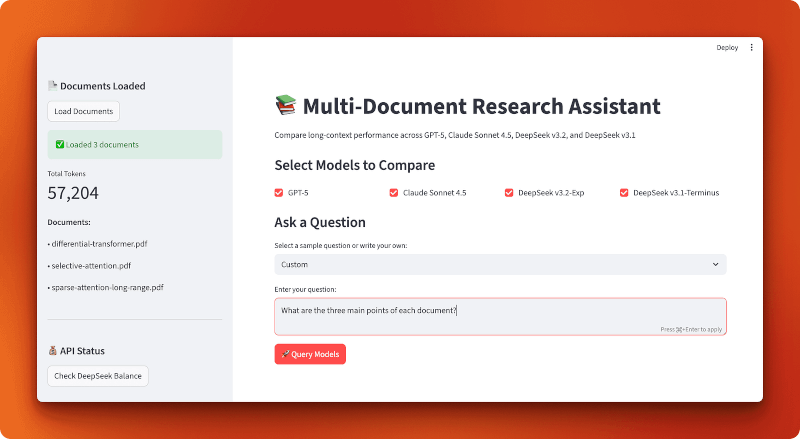
Remarque : Le reste de cette section présente une description détaillée de la manière de créer cette application à partir de zéro. Il n'est pas nécessaire de le créer pour comprendre les résultats de la comparaison, mais parcourir le code vous fournit des modèles pratiques pour créer vos propres applications à contexte long avec DeepSeek.
Nous allons développer cette application sous forme d'application Streamlit avec trois modules de support : un pour le chargement des documents, un pour la configuration du modèle et un pour le traitement des requêtes. Le processus d'utilisation est simple : chargez les fichiers PDF, sélectionnez les modèles, posez une question et comparez les résultats.
Commencez par créer un répertoire de projet et installer les dépendances :
mkdir multi-document-qa
cd multi-document-qa
uv add streamlit langchain langchain-openai langchain-anthropic langchain-community pypdf tiktoken python-dotenv matplotlib pandasVeuillez créer un fichier .env contenant vos clés API :
OPENAI_API_KEY=your_openai_key
ANTHROPIC_API_KEY=your_anthropic_key
DEEPSEEK_API_KEY=your_deepseek_keyVeuillez télécharger trois articles de recherche sur les mécanismes de l'attention :
mkdir documents
cd documents
curl -L -o selective-attention.pdf "https://arxiv.org/pdf/2410.02703"
curl -L -o differential-transformer.pdf "https://arxiv.org/pdf/2410.05258"
curl -L -o sparse-attention-long-range.pdf "https://arxiv.org/pdf/2406.16747"
cd ..Ces trois documents totalisent 57 204 tokens lorsqu'ils sont chargés.
Créer un document_loader.py:
from langchain_community.document_loaders import PyPDFLoader
import tiktoken
from pathlib import Path
def load_documents(documents_dir="documents"):
docs_path = Path(documents_dir)
pdf_files = list(docs_path.glob("*.pdf"))
all_text = ""
document_names = []
# Load each PDF and concatenate with separators
for pdf_file in sorted(pdf_files):
loader = PyPDFLoader(str(pdf_file))
pages = loader.load()
doc_text = "\n\n".join([page.page_content for page in pages])
all_text += f"\n\n=== Document: {pdf_file.name} ===\n\n{doc_text}"
document_names.append(pdf_file.name)Cette fonction charge tous les fichiers PDF d'un répertoire, extrait le texte de chaque page et concatène le tout à l'aide de séparateurs de documents.
# Count tokens using GPT-4 encoding (accurate across providers)
encoding = tiktoken.encoding_for_model("gpt-4")
token_count = len(encoding.encode(all_text))
return all_text, token_count, document_namesLe comptage des jetons utilise tiktoken avec le codage GPT-4, qui fournit des estimations précises pour tous les fournisseurs, car ils utilisent une tokenisation similaire. Veuillez consulter le document_loader.py complet sur GitHub.
Créer un model_config.py:
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
import os
# Pricing per million tokens (as of October 2025)
MODEL_PRICING = {
"gpt-5": {"input": 2.50, "output": 10.00, "name": "GPT-5"},
"claude-sonnet-4-5-20250929": {"input": 3.00, "output": 15.00, "name": "Claude Sonnet 4.5"},
"deepseek-chat": {"input": 0.28, "output": 0.42, "name": "DeepSeek v3.2-Exp"},
"deepseek-chat-v3.1": {"input": 0.55, "output": 2.19, "name": "DeepSeek v3.1-Terminus"},
}Le dictionnaire des prix contient les coûts par million de jetons (à compter d'octobre 2025). DeepSeek v3.2 avec attention clairsemée est environ 10 fois moins coûteux que GPT-5 et Claude, tandis que la version v3.1 se situe entre les deux, avec un coût deux fois supérieur à celui de la version v3.2.
def get_model(model_name):
"""Initialize a chat model by name using LangChain's unified interface."""
if model_name == "gpt-5":
return ChatOpenAI(model="gpt-5", temperature=0, api_key=os.getenv("OPENAI_API_KEY"))
elif model_name == "claude-sonnet-4-5-20250929":
return ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0,
api_key=os.getenv("ANTHROPIC_API_KEY"))
elif model_name == "deepseek-chat":
return ChatOpenAI(model="deepseek-chat", temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com")
elif model_name == "deepseek-chat-v3.1":
# Note: v3.1-Terminus endpoint expires on October 15, 2025
return ChatOpenAI(model="deepseek-chat", temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v3.1_terminus_expires_on_20251015")
def calculate_cost(model_name, input_tokens, output_tokens):
"""Calculate total cost based on input and output token usage."""
pricing = MODEL_PRICING[model_name]
input_cost = (input_tokens / 1_000_000) * pricing["input"]
output_cost = (output_tokens / 1_000_000) * pricing["output"]
return input_cost + output_costLa fonction « get_model() » initialise chaque modèle à l'aide de l'interface unifiée de LangChain. Les modèles DeepSeek utilisent des points de terminaison compatibles avec OpenAI avec des URL de base personnalisées. Remarque : Le point de terminaison v3.1-Terminus expirera le 15 octobre 2025. Le fichier complet script model_config.py est disponible sur GitHub.
Créer un query_handler.py:
import time
from langchain_core.messages import SystemMessage, HumanMessage
from model_config import get_model, calculate_cost, MODEL_PRICING
def query_model(model_name, context, question):
"""Query a model with document context and track performance metrics."""
model = get_model(model_name)
# Embed full document context in system prompt
system_prompt = f"""Use the given context to answer the question.
If you don't know the answer, say you don't know. Keep the answer concise.
Context:
{context}"""
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=question)
]
# Track response time
start_time = time.time()Le système intègre l'ensemble des 57 000 jetons des documents. Les processus d'attention traditionnels traitent chaque élément par rapport à tous les autres éléments. DeepSeek v3.2 ignore les connexions non pertinentes, ce qui réduit les coûts.
try:
response = model.invoke(messages)
elapsed_time = time.time() - start_time
# Extract token usage (different providers use different formats)
if hasattr(response, 'response_metadata') and 'token_usage' in response.response_metadata:
token_usage = response.response_metadata['token_usage']
input_tokens = token_usage.get('prompt_tokens', 0)
output_tokens = token_usage.get('completion_tokens', 0)
elif hasattr(response, 'usage_metadata'):
input_tokens = response.usage_metadata.get('input_tokens', 0)
output_tokens = response.usage_metadata.get('output_tokens', 0)
# Calculate total cost
cost = calculate_cost(model_name, input_tokens, output_tokens)
return {
"model": MODEL_PRICING[model_name]["name"],
"response": response.content,
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"cost": cost,
"time": elapsed_time,
"error": None
}Différentes intégrations LangChain renvoient l'utilisation des jetons dans différents formats (OpenAI utilise response_metadata, Anthropic utilise usage_metadata), nous vérifions donc les deux. Cette fonction permet de suivre le temps, d'extraire le nombre de jetons, de calculer les coûts et de renvoyer un dictionnaire contenant toutes les métriques. Veuillez consulter le fichier complet query_handler.py sur GitHub.
Créer un app.py:
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
from document_loader import load_documents
from query_handler import query_model
from dotenv import load_dotenv
# Load API keys from .env file
load_dotenv()
# Configure Streamlit page with wide layout
st.set_page_config(
page_title="Multi-Document Research Assistant",
page_icon="📚",
layout="wide"
)
st.title("📚 Multi-Document Research Assistant")
st.markdown("Compare long-context performance across GPT-5, Claude Sonnet 4.5, DeepSeek v3.2, and DeepSeek v3.1")Configuration Streamlit standard avec une mise en page large pour les comparaisons côte à côte.
# Sidebar for document loading
with st.sidebar:
st.header("📄 Documents Loaded")
if st.button("Load Documents"):
with st.spinner("Loading documents..."):
# Load all PDFs and count tokens
context, token_count, doc_names = load_documents("documents")
st.session_state.context = context
st.session_state.token_count = token_count
st.session_state.doc_names = doc_names
# Display loaded documents info
if "token_count" in st.session_state:
st.success(f"✅ Loaded {len(st.session_state.doc_names)} documents")
st.metric("Total Tokens", f"{st.session_state.token_count:,}")
st.write("**Documents:**")
for name in st.session_state.doc_names:
st.write(f"• {name}")La barre latérale charge les documents et affiche le nombre de jetons. L'état de session de Streamlit conserve les documents chargés entre les interactions.
# Main content area
if "context" not in st.session_state:
st.info("👈 Click 'Load Documents' in the sidebar to begin")
else:
st.subheader("Select Models to Compare")
col1, col2, col3, col4 = st.columns(4)
# Model selection checkboxes
with col1:
use_gpt5 = st.checkbox("GPT-5", value=True)
with col2:
use_claude = st.checkbox("Claude Sonnet 4.5", value=True)
with col3:
use_deepseek_v32 = st.checkbox("DeepSeek v3.2-Exp", value=True)
with col4:
use_deepseek_v31 = st.checkbox("DeepSeek v3.1-Terminus", value=True)
# Sample questions for quick testing
sample_questions = [
"Compare the main approaches to attention mechanisms described in these documents",
"What are the key differences between sparse and dense attention?",
"Summarize the common themes across all documents"
]Quatre cases à cocher pour la sélection du modèle et des exemples de questions prédéfinies.
# Question input with samples
question_choice = st.selectbox(
"Select a sample question or write your own:",
["Custom"] + sample_questions
)
if question_choice == "Custom":
question = st.text_area("Enter your question:", height=100)
else:
question = st.text_area("Enter your question:", value=question_choice, height=100)
# Query button and model execution
if st.button("🚀 Query Models", type="primary"):
if not question:
st.error("Please enter a question")
else:
# Build list of selected models
selected_models = []
if use_gpt5:
selected_models.append("gpt-5")
if use_claude:
selected_models.append("claude-sonnet-4-5-20250929")
if use_deepseek_v32:
selected_models.append("deepseek-chat")
if use_deepseek_v31:
selected_models.append("deepseek-chat-v3.1")Les utilisateurs sélectionnent une question ou rédigent la leur, puis cliquent sur « Query Models » (Modèles de requête) pour lancer la comparaison sur les modèles sélectionnés.
results = []
# Query each model sequentially with progress indicator
for model_name in selected_models:
with st.spinner(f"Querying {model_name}..."):
result = query_model(
model_name,
st.session_state.context,
question
)
results.append(result)
# Store results in session state for persistence
st.session_state.results = resultsChaque modèle est interrogé de manière séquentielle à l'aide d'un indicateur de progression.
# Display results if available
if "results" in st.session_state:
st.divider()
st.subheader("📊 Results")
results = st.session_state.results
# Show model responses in expandable panels
st.markdown("### Responses")
for result in results:
with st.expander(f"**{result['model']}** - ${result['cost']:.4f} | {result['time']:.2f}s"):
if result['error']:
st.error(f"Error: {result['error']}")
else:
st.write(result['response'])
# Create metrics comparison table
metrics_df = pd.DataFrame([
{
"Model": r['model'],
"Input Tokens": r['input_tokens'],
"Output Tokens": r['output_tokens'],
"Total Tokens": r['total_tokens'],
"Cost ($)": f"${r['cost']:.4f}",
"Time (s)": f"{r['time']:.2f}"
}
for r in results
])
st.dataframe(metrics_df, use_container_width=True)Les résultats affichent la réponse de chaque modèle dans des panneaux extensibles avec le coût et le temps dans l'en-tête, suivis d'un tableau de mesures triables.
# Create visualization charts
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# Chart 1: Cost comparison bar chart
axes[0, 0].bar([r['model'] for r in results], [r['cost'] for r in results],
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
axes[0, 0].set_title('Cost Comparison')
axes[0, 0].set_ylabel('Cost ($)')
axes[0, 0].tick_params(axis='x', rotation=45)
# Chart 2: Response time bar chart
axes[0, 1].bar([r['model'] for r in results], [r['time'] for r in results],
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
axes[0, 1].set_title('Response Time Comparison')
axes[0, 1].set_ylabel('Time (seconds)')
# Chart 3: Token usage grouped bar chart
models = [r['model'] for r in results]
input_tokens = [r['input_tokens'] for r in results]
output_tokens = [r['output_tokens'] for r in results]
x = range(len(models))
width = 0.35
axes[1, 0].bar([i - width/2 for i in x], input_tokens, width, label='Input', color='#1f77b4')
axes[1, 0].bar([i + width/2 for i in x], output_tokens, width, label='Output', color='#ff7f0e')
axes[1, 0].set_title('Token Usage Comparison')
axes[1, 0].legend()Quatre graphiques matplotlib dans une grille 2x2 : barres de coût, barres de temps, barres d'utilisation groupée des jetons et nuage de points coût-temps.
# Chart 4: Cost vs time tradeoff scatter plot
axes[1, 1].scatter([r['cost'] for r in results], [r['time'] for r in results],
s=100, alpha=0.6, color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728'][:len(results)])
for i, r in enumerate(results):
axes[1, 1].annotate(r['model'], (r['cost'], r['time']), fontsize=8, ha='right')
axes[1, 1].set_title('Cost vs Time Trade-off')
axes[1, 1].set_xlabel('Cost ($)')
axes[1, 1].set_ylabel('Time (seconds)')
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
st.pyplot(fig)
# Display key findings
if len(results) > 1:
cheapest = min(results, key=lambda x: x['cost'])
fastest = min(results, key=lambda x: x['time'])
col1, col2 = st.columns(2)
with col1:
st.metric("Most Cost-Effective", cheapest['model'], f"${cheapest['cost']:.4f}")
with col2:
st.metric("Fastest Response", fastest['model'], f"{fastest['time']:.2f}s")Les principales conclusions mettent automatiquement en évidence les modèles les plus économiques et les plus rapides. Veuillez consulter le fichier complet app.py sur GitHub.
Veuillez démarrer l'application :
streamlit run app.pyVeuillez cliquer sur « Charger les documents » pour télécharger les trois fichiers PDF (57 204 jetons au total). Veuillez sélectionner les modèles à comparer (les quatre par défaut), choisir ou rédiger une question, puis cliquer sur « Query Models » (Interroger les modèles).
Temps de réponse attendus pour un contexte de 57 000 jetons :
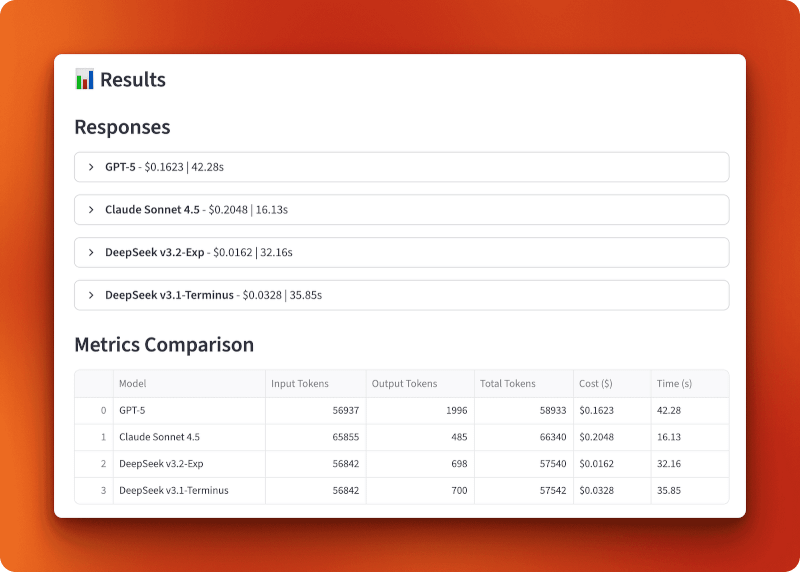
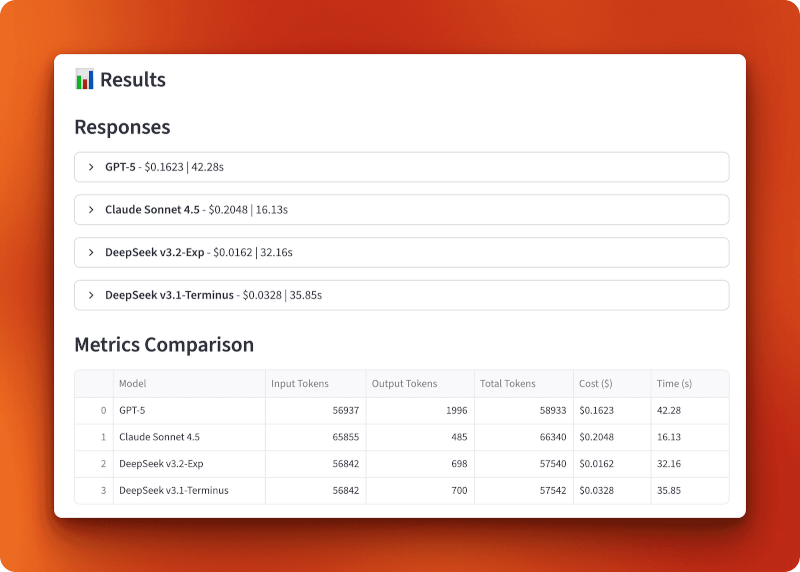
GPT-5 a traité 56 937 jetons d'entrée et généré 1 996 jetons de sortie pour un coût de 0,1623 $ en 42,28 secondes. Claude Sonnet 4.5 a traité 65 855 jetons d'entrée et généré 485 jetons de sortie pour un coût de 0,2048 $ en 16,13 secondes — le plus rapide, mais également le plus onéreux. DeepSeek v3.2-Exp a traité 56 842 jetons d'entrée et généré 698 jetons de sortie pour seulement 0,0162 $ en 32,16 secondes. DeepSeek v3.1-Terminus a traité 56 842 jetons d'entrée et généré 700 jetons de sortie pour un coût de 0,0328 $ en 35,85 secondes.
La comparaison entre les versions 3.1 et 3.2 démontre l'impact de l'attention clairsemée. Les deux versions ont traité des entrées identiques et produit des résultats presque identiques (698 contre 700 jetons), mais la version 3.2 a coûté deux fois moins cher (0,0162 $ contre 0,0328 $) et a fonctionné légèrement plus rapidement (32,16 s contre 35,85 s). Cela représente une réduction des coûts de 50 % par rapport à l'attention clairsemée seule.
Par rapport à GPT-5 et Claude, la version 3.2 est 10 fois moins chère que GPT-5 (0,0162 $ contre 0,1623 $) et 13 fois moins chère que Claude (0,0162 $ contre 0,2048 $). Pour plus de 100 requêtes de cette longueur, vous dépenseriez 16,20 $ avec DeepSeek v3.2, contre 162,30 $ avec GPT-5 ou 204,80 $ avec Claude.
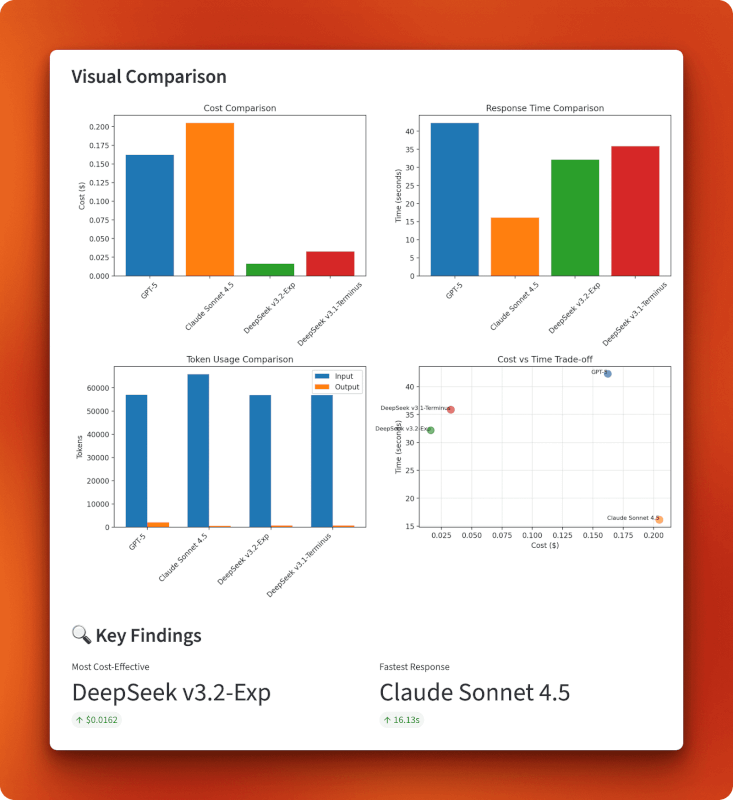
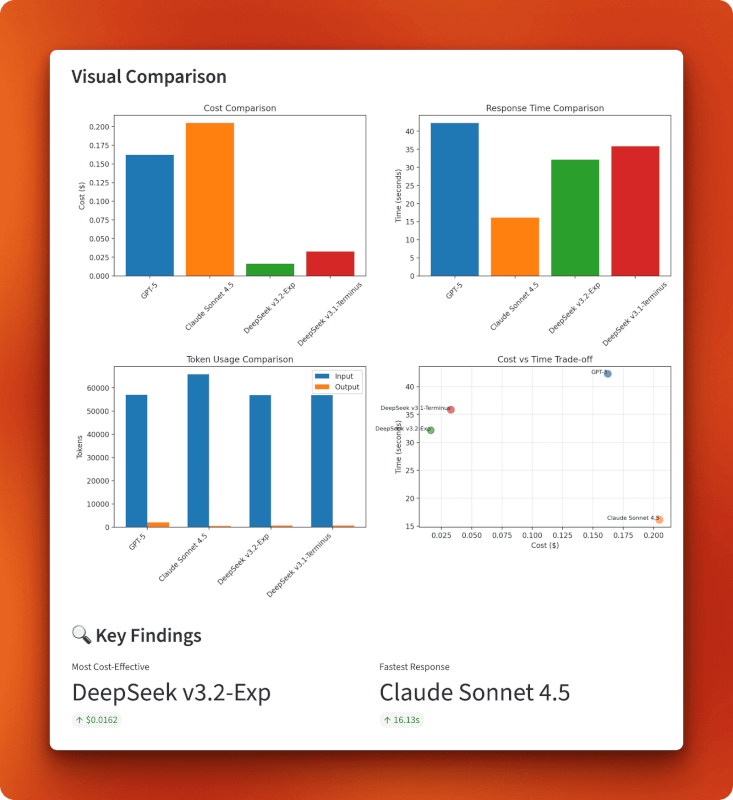
Les graphiques confirment la position de DeepSeek v3.2 dans le quadrant inférieur gauche du compromis coût-temps : le moins cher globalement à 0,0162 $ tout en conservant une vitesse raisonnable de 32 secondes. Claude privilégie la rapidité au détriment du coût (il est onéreux mais le plus rapide), GPT-5 se classe en dernière position sur ces deux critères (il est onéreux et le plus lent), et la version 3.1 se situe entre les deux. Le graphique d'utilisation des tokens montre que tous les modèles traitent des tailles d'entrée similaires, mais que la longueur des sorties varie : GPT-5 a généré la réponse la plus longue avec 1 996 tokens, Claude est resté concis avec 485 tokens, et les deux versions de DeepSeek ont produit des sorties similaires d'environ 700 tokens.
Le chargement de documents complets dans le contexte est particulièrement efficace lorsque vous avez besoin d'une compréhension globale des documents. Si votre question nécessite de relier des idées issues de trois articles différents, le découpage et la récupération pourraient omettre ces liens. Le modèle doit pouvoir visualiser l'ensemble des éléments simultanément.
Ce modèle convient à plusieurs cas d'utilisation :
Cette approche n'est pas efficace lorsque :
L'attention limitée de DeepSeek modifie l'économie du traitement de contextes longs. Ce qui coûtait auparavant entre 0,15 et 0,20 dollar par requête coûte désormais entre 0,01 et 0,02 dollar. Cela rend les approches contextuelles complètes pratiques pour les applications qui exécutent des centaines ou des milliers de requêtes par jour.
La fonctionnalité « sparse attention » de DeepSeek v3.2 offre la même qualité de modèle que la version v3.1, mais à un coût deux fois moins élevé. La comparaison de plusieurs documents que nous avons réalisée a démontré cela dans la pratique. Le traitement de 57 000 jetons coûte 0,0162 $ avec la version 3.2 contre 0,0328 $ avec la version 3.1, et les deux versions produisent des résultats pratiquement identiques. Par rapport à GPT-5 et Claude, la version 3.2 est 10 à 13 fois plus économique tout en conservant des temps de réponse raisonnables. Pour les applications qui traitent régulièrement des contextes longs, ces économies s'accumulent rapidement.
Si vous travaillez sur l'analyse de documents, des outils de recherche ou toute autre application traitant de contextes longs, la version 3.2 mérite d'être testée. Veuillez noter qu'il s'agit encore d'une fonctionnalité expérimentale, il est donc recommandé de la tester avant de l'utiliser en production.
Pour en savoir plus sur les dernières avancées en matière d'IA, veuillez consulter ces blogs :
Apprenez l'IA grâce à ces cours.
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Nathaniel Taylor-Leach
Tutoriel
Moez Ali
Tutoriel
Matt Crabtree