
Curso
Gestión de datos en Databricks
3 h
5.5K
Las tablas delta son un componente fundamental de la arquitectura lakehouse de Databricks, que combina la fiabilidad de los almacenes de datos con la escalabilidad de los lagos de datos. En mi experiencia trabajando en diversos flujos de trabajo de datos, las tablas Delta han permitido canalizaciones más limpias, una depuración más fácil y consultas más rápidas. Su capacidad para admitir datos por lotes y en flujo en un único formato cambia las reglas del juego.
En esta guía, te explicaré cómo funcionan las Tablas Delta, por qué son importantes y cómo utilizarlas en tus proyectos, incluyendo las operaciones básicas y las mejores prácticas para el rendimiento y la gobernanza. Para empezar, recomiendo cursar nuestra Introducción a Databricks y Conceptos de Databricks para familiarizarte con la plataforma Databricks Lakehouse, incluyendo sus características y cómo gestionarla para distintos casos de uso. También deberías consultar cómo aprender Databricks para tener un enfoque estructurado del dominio de la plataforma.
Comprender la arquitectura que hay detrás de las Tablas Delta es clave para apreciar realmente su poder. En esta sección, desglosaré los componentes que hacen que Lago Delta sea resistente, eficaz y fiable para las cargas de trabajo de datos modernas.
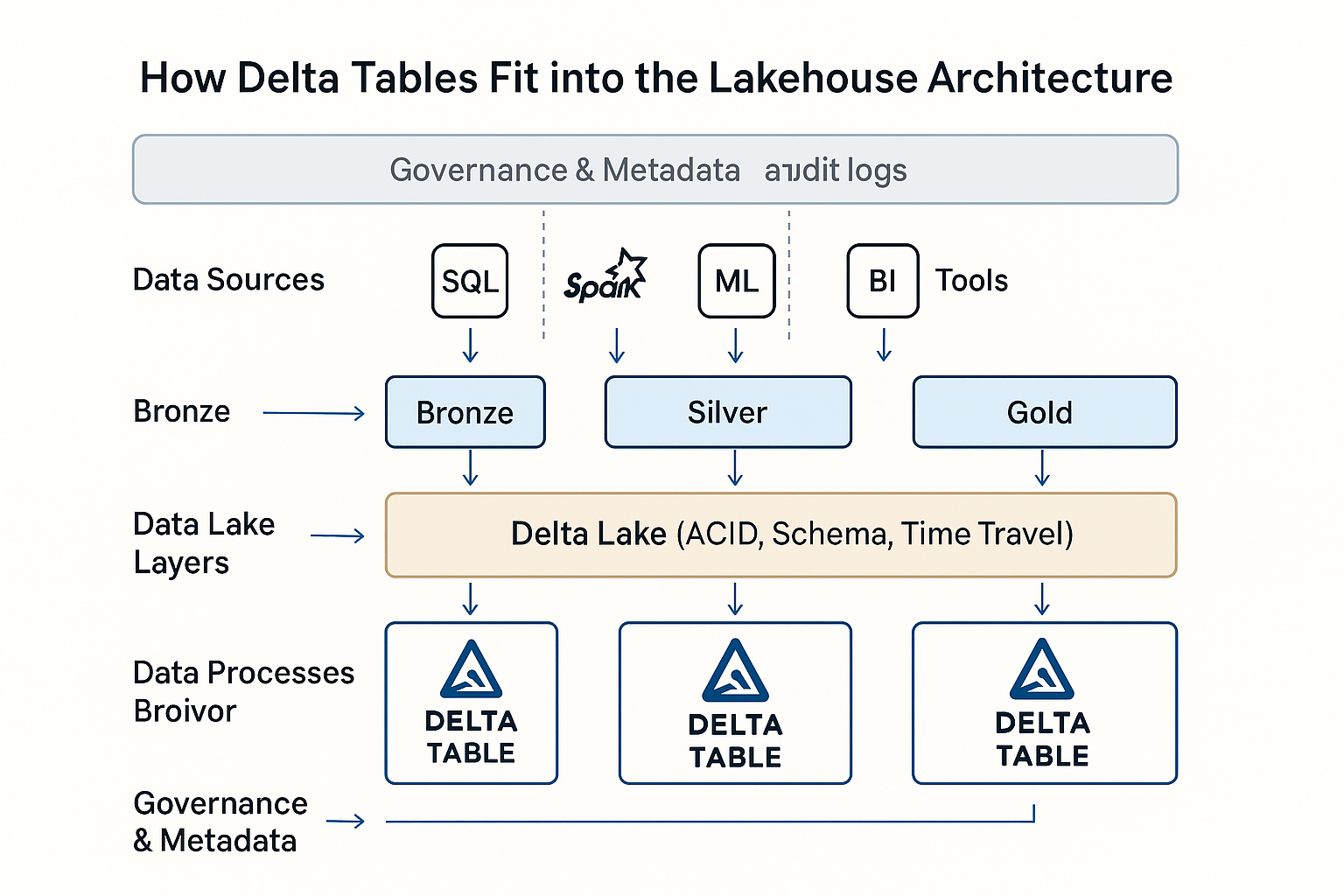
Delta Lake es una capa de almacenamiento de código abierto que aporta garantías de transacción ACID a Apache Spark y a las cargas de trabajo de big data. Las Tablas Delta son la manifestación física de esta capa, que son tablas de datos basadas en Parquet mejoradas con soporte transaccional y aplicación de esquemas.
En Databricks, las Tablas Delta son el formato de datos por defecto de la arquitectura Lakehouse. Unifican las cargas de trabajo por lotes y en flujo, admiten canalizaciones de datos escalables y simplifican la gobernanza con metadatos enriquecidos y control de versiones.
En la práctica, he visto tablas delta utilizadas en desde análisis en tiempo real y canalizaciones ETL hasta almacenes de funciones de machine learning y registros de auditoría reglamentarios. Su versatilidad los convierte en la opción preferida tanto de los ingenieros de datos como de los científicos.
Te recomiendo que hagas nuestra Introducción al dbt para iniciarte en la construcción de almacenes de datos y ETL pipelines.
DeltaLog es un registro de transacciones que registra todos los cambios realizados en la tabla. Este registro permite el pleno cumplimiento de ACID: atomicidad, consistencia, aislamiento y durabilidad, incluso a escala. El cumplimiento de ACID significa que las operaciones con datos son todo o nada, consistentes, aisladas de otras transacciones y duraderas a pesar de los fallos.
Delta Lake utiliza el control de concurrencia multiversión (MVCC) y un protocolo de concurrencia optimista, que permite que varios lectores y escritores trabajen con los datos sin conflictos. Cuando una transacción se confirma, valida sus operaciones con el último estado de la tabla para asegurarse de que no se han producido cambios superpuestos.
Cada envío al DeltaLog registra acciones estructuradas como
Estos registros crean un historial de tablas claro y auditable, que permite funciones como el viaje en el tiempo, la reversión y las canalizaciones reproducibles.
Las Tablas Delta aplican un modelo de esquema en escritura, que garantiza que todos los datos escritos en una tabla coinciden con la estructura declarada. Esto ayuda a evitar errores posteriores y mantiene las tuberías limpias y coherentes.
Al mismo tiempo, Delta admite la evolución del esquema, lo que te permite añadir nuevas columnas o promover tipos de datos a medida que crece tu modelo. Funciones como la asignación de columnas hacen que los cambios de esquema sean más manejables, y la promoción de tipos, como de int a long, para evitar pérdidas de datos innecesarias. Como las Tablas Delta admiten DeltaLog, los cambios de esquema se versionan como los cambios de datos. Esto permite lecturas compatibles con versiones anteriores, permitiendo que las consultas más antiguas se ejecuten sin problemas aunque tu esquema evolucione.
Delta también admite columnas generadas, restricciones aplicables y etiquetas de metadatos personalizadas, que hacen que el esquema sea más expresivo y los datos más autodescriptivos. Estas capacidades me resultaron útiles a la hora de crear plataformas de datos gobernadas a gran escala.
Las tablas Delta almacenan los datos en formato Parquet columnar, optimizado con Z-Ordering para lecturas más rápidas agrupando los datos en columnas de alta cardinalidad. Esto mejora significativamente el rendimiento de las consultas selectivas. El Formato Universal Delta (UniForm) garantiza la interoperabilidad haciendo que las tablas Delta puedan ser leídas por herramientas que no sean Databricks, ampliando el acceso al lago de datos en todos los ecosistemas.
El almacenamiento se optimiza aún más mediante el dimensionamiento inteligente de los archivos. Delta Lake utiliza estrategias de autocompactación y bin-packing para mantener el tamaño óptimo de los archivos entre 100 y 300 MB, reduciendo la sobrecarga de los archivos pequeños y mejorando el rendimiento de E/S.
Funciones como la omisión de datos, el almacenamiento en caché y la indexación automática mejoran aún más el rendimiento de las consultas, lo que hace que las Tablas Delta sean ideales tanto para análisis a gran escala como para cargas de trabajo en tiempo real.
Tablas delta en la arquitectura Lakehouse de Databricks. Imagen de OpenAI.
En esta sección, explicaré cómo se crean las Tablas Delta, se ingestan con datos y se modifican en las distintas etapas del ciclo de vida de los datos.
Según tu flujo de trabajo y tus preferencias, puedes crear Tablas Delta utilizando varios métodos. Puedes utilizar Databricks SQL como CREATE TABLE ... USING DELTAo crearlas programáticamente mediante DataFrames en PySparkScala o Spark SQL. Esta flexibilidad me ha permitido estandarizar las definiciones de tablas entre cuadernos interactivos y trabajos ETL automatizados.
Delta Lake admite la conversión única e incremental si ya tienes datos en formatos Parquet o Iceberg. Puedes realizar una conversión única para conjuntos de datos estáticos utilizando CONVERT TO DELTA o una conversión incremental para datos escritos activamente utilizando estrategias de versionado de tablas y puntos de control.
Recomiendo tomar nuestro curso Introducción a Spark con sparklyr en R para aprender a manipular enormes conjuntos de datos en DataFrames de Spark.
Delta Lake admite varios métodos de ingestión, como COPY INTO, que carga datos desde el almacenamiento en la nube de forma estructurada con inferencia automática de esquemas. Sin embargo, el Cargador Automático es útil en la ingesta continua, especialmente para el streaming o los conjuntos de datos actualizados con frecuencia, y se escala automáticamente a medida que crece tu volumen de entrada.
La interfaz de usuario de Añadir Datos en Databricks proporciona una forma sencilla e interactiva de cargar archivos locales o explorar fuentes en la nube, lo que resulta práctico para experimentos rápidos o para la incorporación de usuarios menos técnicos.
También puedes ingerir datos en modo batch y streaming, creando pipelines unificados que manejen datos en tiempo real e históricos utilizando la misma tabla Delta. La integración con herramientas de terceros como Fivetran, Informatica y dbt amplía aún más el alcance de Delta Lake, permitiéndote conectar Delta a ecosistemas empresariales más amplios.
Delta Lake admite DML (Lenguaje de Manipulación de Datos) completo, lo que lo hace más avanzado que los lagos de datos tradicionales. Puedes UPDATE, DELETE, MERGE, y UPSERT datos directamente dentro de Tablas Delta utilizando SQL o PySpark sintaxis. Esto me ha permitido construir pipelines que reaccionan a eventos empresariales casi en tiempo real, como corregir registros de clientes o aplicar cambios en las políticas. Recomiendo tomar nuestro curso Limpieza de datos con PySpark para aprender los métodos y las mejores prácticas de uso de PySpark para la manipulación de datos.
Las Tablas Delta también admiten consultas de viaje en el tiempo, que te permiten consultar estados anteriores de las tablas utilizando números de versión o marcas de tiempo. Esto ha sido increíblemente útil para auditar, depurar y reproducir análisis históricos. La función de alimentación de datos de cambios (CDF) proporciona registros de cambios a nivel de fila, lo que permite a los consumidores posteriores procesar las actualizaciones de forma incremental sin releer tablas completas, lo que resulta útil para los cuadros de mando en tiempo real.
También debo señalar que la evolución del esquema afecta directamente a los flujos de trabajo de modificación. Por ejemplo, añadir una nueva columna no romperá una sentencia merge existente, pero los cambios de tipo pueden requerir un manejo cuidadoso, especialmente en entornos gobernados.
Permíteme compartir las mejores prácticas que utilizo para maximizar el rendimiento y conseguir unos análisis rápidos, rentables y fiables.
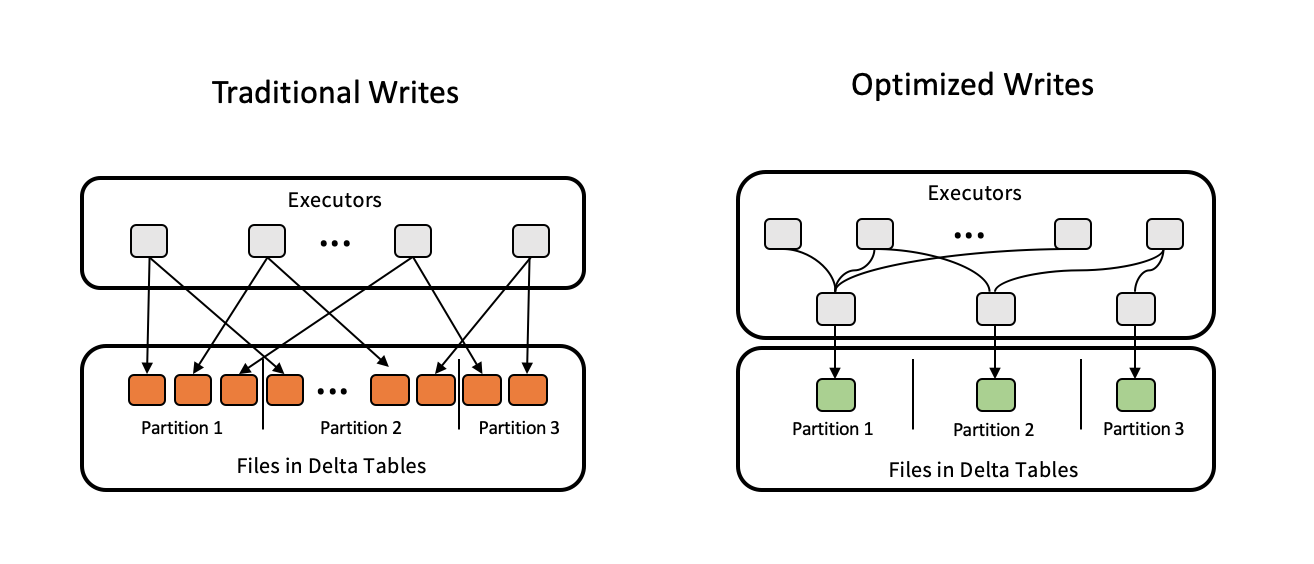
Uno de los problemas de rendimiento más comunes que veo es el tamaño inadecuado de los archivos, ya sean demasiados archivos pequeños o grandes archivos monolíticos. Delta Lake resuelve este problema mediante la auto-compactación y el bin-packing, garantizando que los archivos se mantengan dentro de los rangos de tamaño óptimos de 100-300 MB. Puedes activar estos procesos manualmente o configurarlos con las propiedades de las tablas.
Para las cargas de trabajo analíticas, el Ordenamiento en Z es una de las herramientas de Delta Lake que se utilizan para reordenar los archivos de datos basándose en una o más columnas de alta cardinalidad, reduciendo el número de archivos escaneados en las consultas. El comando VACUUM ayuda a eliminar archivos de datos antiguos y sin referencias de versiones anteriores para mantener la salud del almacenamiento a largo plazo. Es una parte importante de la higiene de las tablas tener cuidado con el periodo de conservación para evitar borrar archivos utilizados para viajar en el tiempo.
Las Tablas Delta ofrecen varias funciones avanzadas para ajustar las consultas y el rendimiento del almacenamiento. La omisión de datos, la partición y la agrupación ayudan a minimizar la cantidad de datos escaneados durante las consultas, mientras que la poda dinámica de archivos (DFP) optimiza el rendimiento de las uniones eliminando las lecturas innecesarias de archivos.
El aprovisionamiento de hardware, que consiste en elegir el tamaño y la configuración correctos del clúster, combinado con la caché delta, puede acelerar las consultas repetidas. La optimización automatizada de la carga de trabajo en Databricks también garantiza el uso eficiente de los recursos. La poda de particiones y las estrategias de unión optimizadas son importantes para los grandes conjuntos de datos, ya que permiten que las consultas se ejecuten más rápido y de forma más predecible.
Escrituras optimizadas para optimizar las tablas Delta. Fuente de la imagen: Delta Lake.
Las Tablas Delta están diseñadas para unificar las cargas de trabajo por lotes y de flujo, permitiéndote procesar datos históricos y en tiempo real con la misma tabla y base de código. Funciones como el procesamiento "exactamente una vez" y la funcionalidad "desencadenar una vez" garantizan la coherencia y fiabilidad de los datos, incluso en escenarios de streaming complejos. La limitación de velocidad controla la velocidad de ingestión para evitar la contención de recursos.
Recomiendo las mejores prácticas, como supervisar los trabajos de streaming, ajustar los intervalos de puntos de control y gestionar las cargas de trabajo incrementales para garantizar operaciones fluidas y escalables.
En esta sección, destacaré algunas integraciones y optimizaciones avanzadas que elevan las Tablas Delta a una solución completa de nivel empresarial.
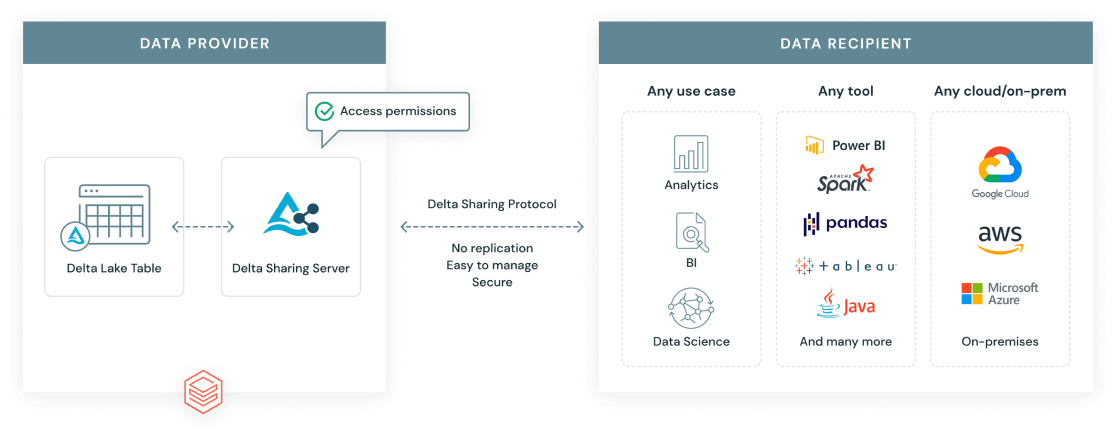
El Protocolo de Compartición Delta es un estándar abierto desarrollado por Databricks para permitir la compartición segura y escalable de datos más allá de los límites de organizaciones y plataformas. A diferencia de las exportaciones de datos tradicionales, Compartir Delta da a los destinatarios acceso en directo a los datos más actualizados, sin duplicaciones.
Hay dos escenarios principales para compartir:
Protocolo de compartición delta de Databricks. Fuente de la imagen: Databricks.
El motor Delta es un motor de consulta de alto rendimiento optimizado para tablas Delta. Se integra con Databricks SQL y Photon, un motor de ejecución vectorizado que acelera las cargas de trabajo SQL y DataFrame aprovechando las modernas arquitecturas de CPU. Esto se traduce en importantes mejoras de rendimiento, especialmente para análisis a gran escala y consultas complejas.
El motor Delta admite funciones avanzadas como vistas materializadasque proporcionan resultados de consulta precalculados para un análisis más rápido. Es importante tener en cuenta que las vistas materializadas difieren de las tablas de flujo. Mientras que las vistas materializadas están optimizadas para consultas repetidas y predecibles, las tablas de flujo están diseñadas para la ingestión y el procesamiento de datos continuos y en tiempo real.
La Poda Dinámica de Archivos (PDF) es una técnica de optimización durante las consultas de unión. Permite a Spark filtrar los archivos innecesarios del lado de la lectura basándose en claves de unión. En lugar de escanear todo el lado derecho de una unión, DFP limita el escaneo sólo a los bloques de archivo relevantes. Esta técnica mejora el rendimiento de los conjuntos de datos particionados o cuando se filtra por cliente, región o producto.
En la práctica, he visto que DFP marca una diferencia significativa a la hora de unir tablas particionadas de gran tamaño, como las canalizaciones ETL o los cuadros de mando analíticos. Esto conduce a un procesamiento más rápido y eficiente y a unos costes de computación más bajos.
A continuación encontrarás las mejores prácticas clave que he aprendido de la creación y ampliación de los flujos de trabajo Delta:
OPTIMIZE para reducir los problemas de archivos pequeños y mejorar el rendimiento del escaneado.dataRetentionDuration o VACUUM para establecer periodos de retención razonables que equilibren la flexibilidad de la reversión con la eficiencia del almacenamiento.Para comprender las ventajas de las Tablas Delta, es importante ver cómo se comparan y diferencian de las estructuras tradicionales de los lagos de datos y de otros tipos de tablas de Databricks. A continuación encontrarás una tabla resumen de esta comparación.
Veamos ahora los casos de uso habituales en los que se aplican tablas delta por su valor.
Delta Tablas ofrece una solución fiable y flexible para gestionar datos en Databricks, compatible con análisis en tiempo real y por lotes. El ecosistema de Delta Lake sigue evolucionando, con nuevas funciones que facilitan aún más el intercambio de datos, la gobernanza y el rendimiento. Recomiendo seguir las mejores prácticas para la disposición de datos y la automatización, y mantenerse al día de las nuevas capacidades.
Si estás buscando avanzar en tus habilidades en almacenamiento de datos, te recomiendo que tomes nuestro curso de Ingeniero de Datos Asociado en SQL para aprender a diseñar y trabajar con bases de datos. Mientras te preparas para tus entrevistas, echa un vistazo a nuestras Las 20 mejores preguntas para entrevistas de Databricks para destacar entre los demás profesionales de datos.
Aprende Databricks con DataCamp
Curso
Curso
Curso
blog
Gus Frazer
14 min
blog
Mike Shakhomirov
11 min
Tutorial
Joleen Bothma
Tutorial
Kafaru Simileoluwa
Tutorial
Joleen Bothma