
Cours
Gestion des données dans Databricks
3 h
5.6K
Les tableaux Delta font partie de l'architecture Lakehouse de Databricks. Leur objectif est de combiner la fiabilité des entrepôts de données et l'évolutivité des lacs de données. Dans mon expérience de travail sur les flux de données, j'ai vu comment les tableaux Delta ont permis des requêtes plus rapides (et un débogage plus facile).
Dans ce guide, je vais vous expliquer comment fonctionnent les tableaux Delta, pourquoi ils sont importants et comment les utiliser dans vos projets. Pour commencer, je vous recommande de suivre nos cours Introduction à Databricks et Concepts Databricks pour vous familiariser avec la plateforme Databricks Lakehouse, y compris ses fonctionnalités et la manière de la gérer pour différents cas d'utilisation.
Il est essentiel de comprendre l'architecture qui sous-tend les tableaux Delta pour en apprécier toute la puissance. Dans cette section, je vais décomposer les composants qui rendent Delta Lake résilient, performant et fiable pour les charges de travail de données modernes.
Delta Lake est une couche de stockage open-source qui apporte des garanties de transaction ACID à Apache Spark et aux charges de travail big data. Les tableaux Delta sont la manifestation physique de cette couche. Il s'agit de tableaux de données basés sur la technologie Parquet, dotés d'un support transactionnel et d'une mise en application du schéma.
Dans Databricks, les tableaux Delta constituent le format de données par défaut de l'architecture Lakehouse. Ils unifient les charges de travail en mode batch et en mode streaming, prennent en charge les pipelines de données évolutifs et simplifient la gouvernance grâce à des métadonnées riches et au contrôle des versions.
Dans la pratique, j'ai vu les tableaux Delta utilisés dans les analyses en temps réel, les pipelines ETL, les magasins de fonctionnalités d'apprentissage automatique et les pistes d'audit réglementaires.
DeltaLog est un journal des transactions qui enregistre chaque modification apportée autableau. Ce journal permet une conformité totale à la norme ACID, même à grande échelle. (La conformité ACID signifie que les opérations sur les données sont tout ou rien, cohérentes, isolées des autres transactions et durables malgré les défaillances).
Delta Lake utilise un contrôle de concurrence multi-version (MVCC) et un protocole de concurrence optimiste, qui permet à plusieurs lecteurs et écrivains de travailler avec les données sans conflit. Lorsqu'une transaction est validée, elle compare ses opérations avec le dernier état du tableau pour s'assurer qu'il n'y a pas eu de chevauchement des modifications.
Chaque livraison au DeltaLog enregistre des actions structurées telles que
Ces tableaux créent un historique clair et vérifiable du tableau. Cela permet des fonctionnalités telles que le voyage dans le temps, le retour en arrière et les pipelines reproductibles.
Les tableaux Delta appliquent un modèle de schéma en écriture, garantissant que toutes les données écrites dans un tableau correspondent à la structure déclarée. Cela permet d'éviter les erreurs en aval et de maintenir les pipelines propres et cohérents.
Parallèlement, Delta prend en charge ce que l'on appelle l'évolution des schémas. Cela signifie que vous pouvez ajouter de nouvelles colonnes ou promouvoir des types de données au fur et à mesure que votre modèle devient différent. Des fonctionnalités telles que le mappage de colonnes rendent les modifications de schéma plus faciles à gérer, et la promotion de type (comme de int à long, pour prendre un exemple), qui évite la perte de données. Comme les tableaux Delta prennent en charge DeltaLog, les modifications de schéma sont versionnées comme les modifications de données. Cela permet d'effectuer des lectures rétrocompatibles. Ainsi, les anciennes requêtes s'exécutent sans problème même si votre schéma évolue.
Delta prend également en charge les colonnes générées, les contraintes applicables et les balises de métadonnées personnalisées, ce qui rend le schéma plus expressif et les données plus faciles à décrire. J'ai trouvé ces capacités utiles.
Les tableaux Delta stockent les données au format Parquet en colonnes, optimisé avec Z-Ordering pour une lecture plus rapide en regroupant les données sur des colonnes à cardinalité élevée. Cela améliore considérablement les performances pour les requêtes sélectives. Le format universel Delta (UniForm) garantit l'interopérabilité en rendant les tableaux Delta lisibles par des outils autres que Databricks, élargissant ainsi l'accès au lac de données à travers les écosystèmes.
Le stockage est encore optimisé grâce à un dimensionnement intelligent des fichiers. Delta Lake utilise des stratégies d'auto-compactage et de bin-packing pour maintenir des tailles de fichiers optimales (100 à 300 Mo).
Des fonctionnalités telles que le saut de données, la mise en cache et l'indexation automatique améliorent encore les performances des requêtes, ce qui fait des tableaux Delta la solution idéale pour les analyses à grande échelle et les charges de travail en temps réel
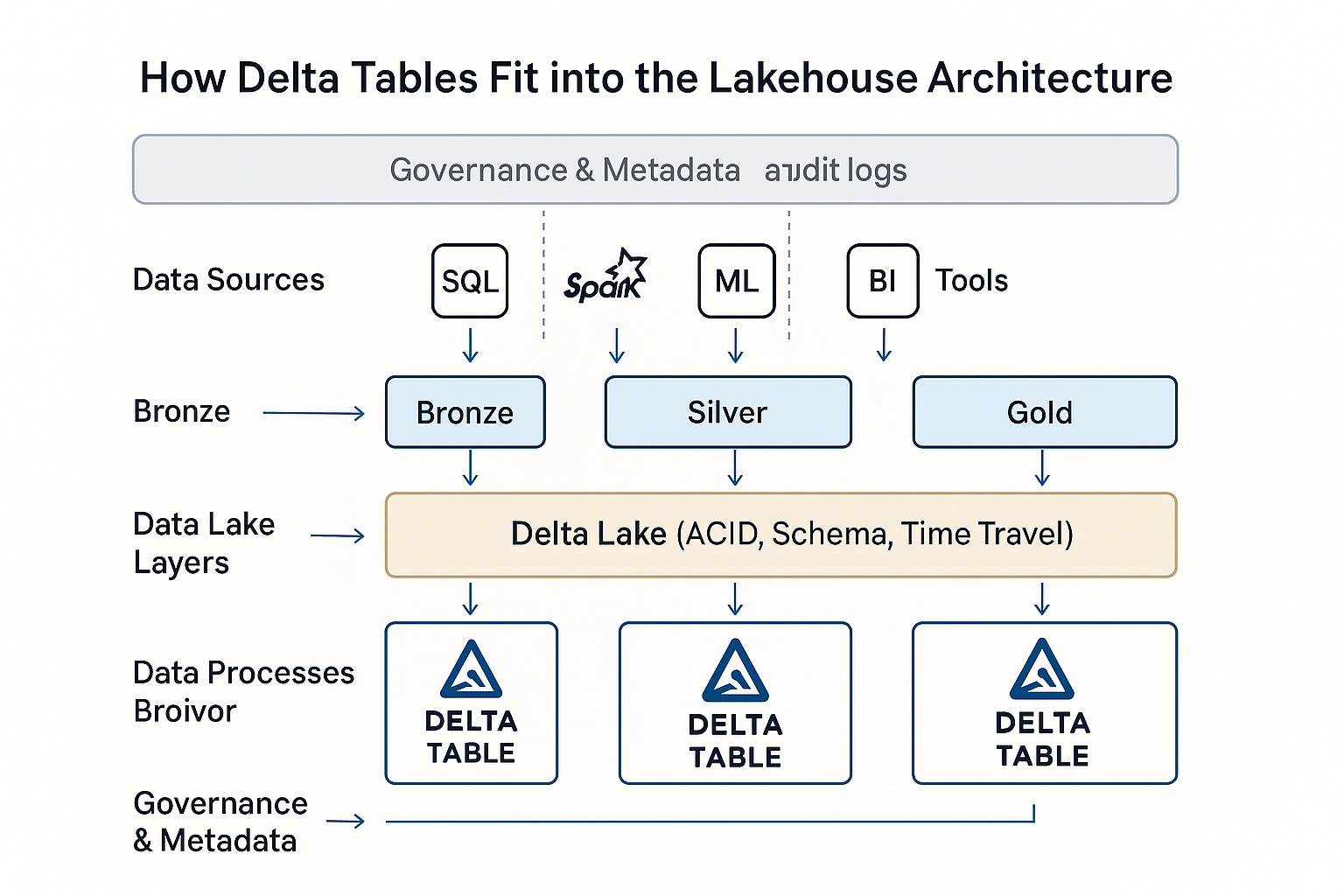
Tableaux Delta dans l'architecture Databricks Lakehouse. Image d'OpenAI.
Dans cette section, j'expliquerai comment les tableaux Delta sont créés, alimentés en données et modifiés au cours des différentes étapes du cycle de vie des données.
En fonction de votre flux de travail et de vos préférences, vous pouvez créer des tableaux Delta à l'aide de plusieurs méthodes. Vous pouvez utiliser lesinstructions DDL SQL de Databrickstelles que CREATE TABLE ... USING DELTAou les créer par programmation via DataFrame dans PySpark, Scala ou Spark SQL. Cette flexibilité m'a permis de normaliser les définitions des tableaux dans les carnets interactifs et les travaux ETL automatisés.
Delta Lake prend en charge la conversion unique et incrémentale si vous disposez déjà de données aux formats Parquet ou Iceberg. Vous pouvez effectuer une conversion unique pour les ensembles de données statiques à l'aide de CONVERT TO DELTA ou une conversion incrémentielle pour les données écrites activement à l'aide de stratégies de versionnement des tableaux et de points de contrôle.
Je vous recommande de suivre notrecours Introduction à Spark avec sparklyr en R pour apprendre à manipuler d'énormes ensembles de données dans Spark DataFrame.
Delta Lake prend en charge plusieurs méthodes d'ingestion, notamment COPY INTO, qui charge les données à partir d'un stockage dans le cloud de manière structurée avec inférence automatique des schémas. Cependant, Auto Loader est utile pour l'ingestion continue, en particulier pour les ensembles de données en continu ou fréquemment mis à jour, et s'adapte automatiquement à l'augmentation de votre volume d'entrée.
L'interface utilisateur Ajouter des données dans Databricks offre un moyen simple et interactif de télécharger des fichiers locaux ou de parcourir des sources cloud, ce qui est pratique pour des expériences rapides ou l'onboarding d'utilisateurs moins techniques.
Vous pouvez également ingérer des données en mode batch et en mode streaming, en créant des pipelines unifiés qui traitent des données en temps réel et des données historiques à l'aide du même tableau Delta. L'intégration avec des outils tiers tels que Fivetran, Informatica et dbt élargit encore la portée de Delta Lake, vous permettant de l'intégrer dans des écosystèmes d'entreprise plus vastes.
Delta Lake prend en charge l'intégralité du DML (Data Manipulation Language), ce qui le rend plus avancé que les lacs de données traditionnels. Vous pouvez UPDATE, DELETE, MERGE, et UPSERT données directement dans les tableaux Delta en utilisant SQL ou la syntaxe PySpark . Cela m'a permis de créer des pipelines qui réagissent aux événements commerciaux en temps quasi réel, comme la correction des dossiers des clients ou l'application de changements de politique. Je vous recommande de suivre notre cours Nettoyage de données avec PySpark pour apprendre les méthodes et les meilleures pratiques d'utilisation de PySpark pour la manipulation de données.
Les tableaux Delta prennent également en charge les requêtes de type "voyage dans le temps", qui vous permettent d'interroger les états précédents du tableau en vous concentrant sur les numéros de version ou les horodatages. (Ceci est très important pour l'audit en particulier). La fonction Change Data Feed (CDF) fournit des journaux de modifications au niveau des lignes, ce qui permet aux consommateurs en aval de traiter les mises à jour de manière incrémentielle sans relire des tableaux complets, ce qui est utile pour les tableaux de bord en temps réel.
Je dois également souligner que l'évolution des schémas a un impact direct sur les flux de modification. Par exemple, l'ajout d'une nouvelle colonne n'interrompra pas une instruction de fusion existante, mais les changements de type peuvent nécessiter une manipulation prudente, en particulier dans les environnements gouvernés.
Permettez-moi de vous faire part des meilleures pratiques que j'utilise pour maximiser les performances afin d'obtenir des analyses rapides, rentables et fiables.
L'un des problèmes de performance les plus courants que je constate est le mauvais dimensionnement des fichiers, qu'il s'agisse d'un trop grand nombre de petits fichiers ou de gros fichiers monolithiques. Delta Lake résout ce problème grâce à l'auto-compactage et au bin-packing, en veillant à ce que les fichiers ne dépassent pas la taille optimale de 100 à 300 Mo. Vous pouvez déclencher ces processus manuellement ou les configurer avec les propriétés du tableau.
Pour les charges de travail analytiques, le Z-Ordering est l'un des outils de Delta Lake utilisés pour réorganiser les fichiers de données sur la base d'une ou plusieurs colonnes à forte cardinalité, réduisant ainsi le nombre de fichiers analysés dans les requêtes. La commande VACUUM permet de supprimer les anciens fichiers de données non référencés des versions précédentes afin de préserver la santé du stockage à long terme. C'est un élément important de l'hygiène des tableaux que de faire attention à la durée de conservation pour éviter de supprimer des fichiers utilisés pour voyager dans le temps.
Les tableaux Delta offrent plusieurs fonctionnalités avancées permettant d'optimiser les performances des requêtes et du stockage. Le saut de données, le partitionnement et le regroupement permettent de minimiser la quantité de données analysées lors des requêtes, tandis que l'élagage dynamique des fichiers (DFP) optimise les performances des jointures en éliminant les lectures de fichiers inutiles.
Le provisionnement du matériel, c'est-à-dire le choix de la taille et de la configuration correctes de la grappe, combiné à la mise en cache delta, peut accélérer les requêtes répétées. L'optimisation automatisée de la charge de travail dans Databricks garantit également une utilisation efficace des ressources. L'élagage des partitions et l'optimisation des stratégies de jointure sont importants pour les grands ensembles de données, car ils permettent aux requêtes de s'exécuter plus rapidement et de manière plus prévisible.
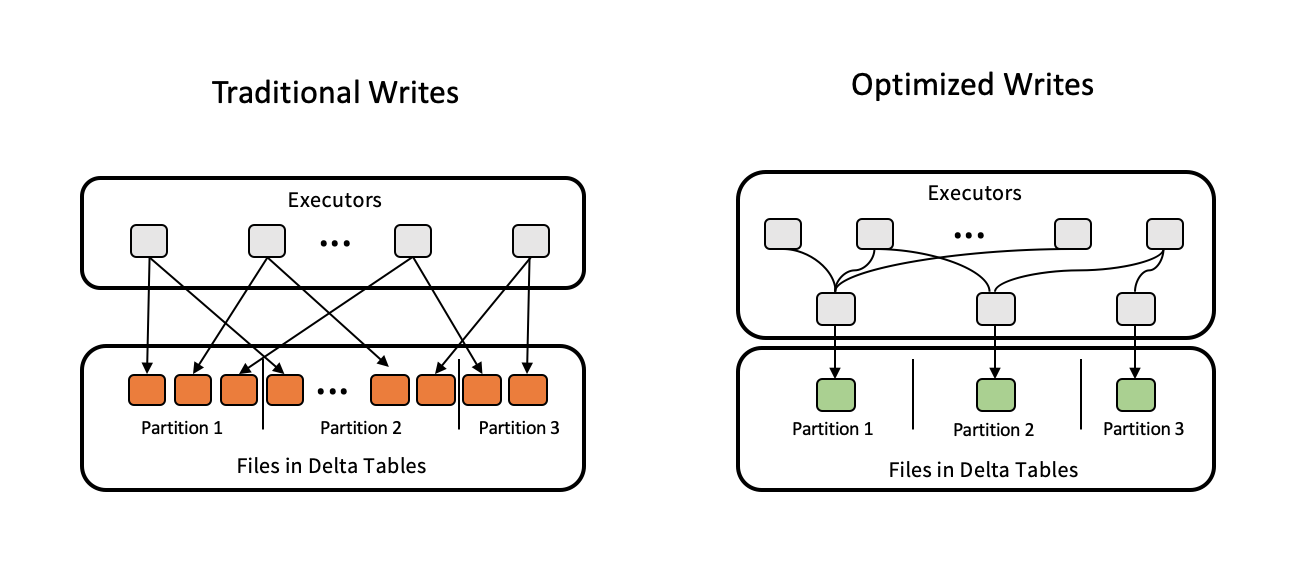
Écritures optimisées pour l'optimisation des tableaux Delta. Source de l'image : Delta Lake.
Les tableaux Delta sont conçus pour unifier les charges de travail en mode batch et en mode streaming. Les caractéristiquesures telles que le traitement "exactly-once" et la fonctionnalité "trigger-once" assurent la cohérence des données dans des scénarios de diffusion en continu plus complexes. La limitation du débit permet de contrôler la vitesse d'ingestion.
Dans cette section, je mettrai en évidence certaines intégrations et optimisations avancées qui élèvent Delta Tableaux au rang de solution d'entreprise complète.
Le protocole de partage Delta est une norme ouverte développée par Databricks pour permettre un partage de données sécurisé et évolutif au-delà des frontières organisationnelles et des plates-formes. Contrairement aux exportations de données traditionnelles, Delta Sharing permet aux destinataires d'accéder en direct aux données les plus récentes, sans duplication.
Il existe deux principaux scénarios de partage :
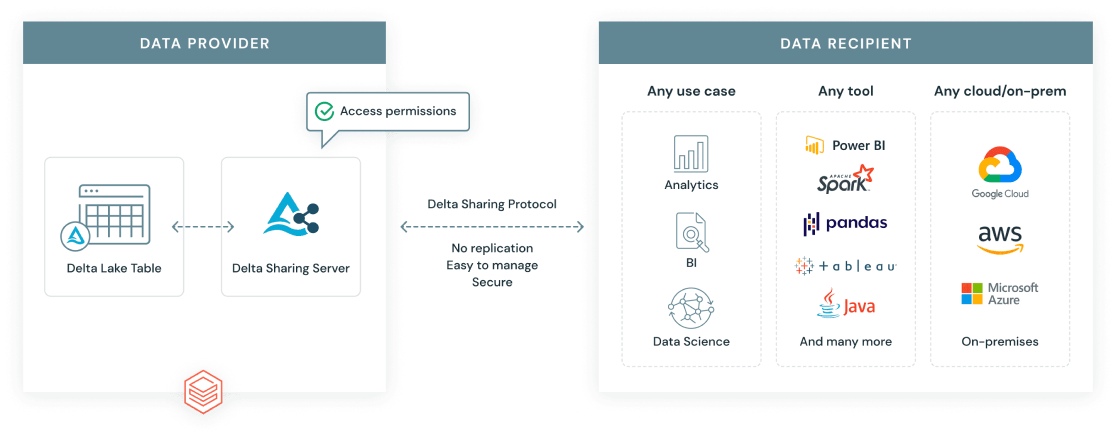
Protocole de partage delta Databricks. Source de l'image : Databricks.
Le moteur Delta est un moteur de requête très performant, optimisé pour les tableaux Delta. Il s'intègre à Databricks SQL et Photon, un moteur d'exécution vectorisé qui accélère les charges de travail SQL et DataFrame en tirant parti des architectures de CPU modernes. Il en résulte des gains de performance significatifs, en particulier pour les analyses à grande échelle et les requêtes complexes.
Le moteur Delta prend en charge des fonctions avancées telles que les vues matérialisées. Il est important de noter que les vues matérialisées diffèrent des tableaux en continu. Alors que les vues matérialisées sont optimisées pour les requêtes répétées et prévisibles, les tableaux en continu sont conçus pour l'ingestion et le traitement de données en continu et en temps réel.
L'élagage dynamique des fichiers (DFP) est une technique d'optimisation des requêtes de jointure. Il permet à Spark de filtrer les fichiers inutiles du côté lecture en se basant sur les clés de jointure. Au lieu d'analyser tout le côté droit d'une jointure, DFP limite l'analyse aux seuls blocs de fichiers pertinents. Cette technique améliore les performances pour les ensembles de données partitionnés ou lors du filtrage par client, région ou produit.
En pratique, j'ai vu DFP faire une différence significative à l'endroit où de grands tableaux partitionnés sont joints, tels que les pipelines ETL ou les tableaux de bord analytiques. Cela permet un traitement plus rapide et plus efficace et une réduction des coûts de calcul.
Vous trouverez ci-dessous les meilleures pratiques que j'ai apprises en construisant et en développant les flux de travail Delta :
Gestion de la taille des fichiers : Conservez les fichiers de données entre 100 et 300 Mo à l'aide de l'auto-compactage ou de OPTIMIZE pour réduire les problèmes liés aux petits fichiers et améliorer les performances de l'analyse.
Configuration du voyage dans le temps: Utilisez dataRetentionDuration ou VACUUM pour définir des périodes de conservation raisonnables qui concilient la flexibilité du retour en arrière et l'efficacité du stockage.
Contrôles de simultanéité: Utilisez les niveaux d'isolation et le contrôle optimiste de la concurrence pour gérer les écritures multi-utilisateurs et réduire les conflits de validation.
Optimisation des coûts: Utilisez Photon, Delta Caching et Z-Ordering pour minimiser les coûts de calcul, en particulier pour les requêtes répétées.
Contrôler les performances: Utilisez les rapports Query Profile, Lakehouse Monitoring et Workload Utilization pour identifier les requêtes lentes et optimiser l'utilisation des ressources.
Partitionnement et disposition des données: Pour minimiser les balayages de données, partitionnez les tableaux uniquement sur les colonnes à faible cardinalité, comme les dates ou les lieux. Utilisez l'ordre Z dans les partitions pour les champs à cardinalité élevée afin d'accélérer davantage les requêtes. Évitez le surpartitionnement, qui peut conduire à des fichiers de petite taille et à une dégradation des performances.
J'ai beaucoup parlé de la raison d'être des tableaux Delta, mais il est utile de les comparer à des structures de lac de données plus traditionnelles, ainsi qu'à d'autres types de tableaux au sein même de Databricks :
|
Fonctionnalité |
Tableaux Delta |
Tableaux de la ruche |
Tableaux Delta Live (DLT) |
Tableaux en continu |
Vues matérialisées |
|
Transactions ACID |
Soutien complet |
Limité/Aucun |
Construit sur Delta |
via Delta |
au sommet du Delta |
|
Application du schéma |
Appliqué à l'écriture |
Application manuelle |
Déclaratif + géré |
Compatibilité avec la diffusion en continu |
Suit la base du tableau Delta |
|
Voyage dans le temps |
Intégré |
Non pris en charge |
Héritée de Delta |
(lecture en fonction de la version) |
En fonction de l'actualisation |
|
Prise en charge de la diffusion en continu |
Traitement unifié par lots et en flux (batch/streaming) |
Traitement séparé |
Autogestion |
Soutien aux autochtones |
Mise à jour périodique uniquement |
|
Évolution des métadonnées |
Balances avec grands tableaux |
Plus lent avec les partitions |
Optimisé par DLT |
Avec le cursus |
Hérite de Delta |
|
Gestion opérationnelle |
Avec OPTIMIZE, VACUUM, etc. |
Manuel et cassant |
Géré par les pipelines DLT |
Déclencheurs configurables |
Options de rafraîchissement et de cache |
Examinons à présent les cas d'utilisation courants dans lesquels les tableaux Delta sont utilisés pour leur valeur.
Delta Tableaux offre une solution fiable et flexible pour la gestion des données dans Databricks, prenant en charge les analyses en temps réel et par lots. L'écosystème Delta Lake continue d'évoluer, avec de nouvelles fonctionnalités qui facilitent le partage, la gouvernance et la performance des données. Je vous recommande de suivre les meilleures pratiques en matière de présentation des données et d'automatisation et de vous tenir au courant des nouvelles possibilités.
Si vous souhaitez améliorer vos compétences en matière d'entreposage de données, je vous recommande de suivre notre cours Associate Data Engineer in SQL pour apprendre à concevoir et à travailler avec des bases de données. Alors que vous vous préparez pour vos entretiens, consultez nos 20 meilleures questions d'entretien Databricks pour vous démarquerdes autres professionnels des données.
Apprenez Databricks avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min