
Kurs
Data Management in Databricks
3 Std.
5.6K
Delta-Tabellen sind ein Teil der Databricks-Seehaus-Architektur. Ihr Ziel ist es, die Zuverlässigkeit von Data Warehouses und die Skalierbarkeit von Data Lakes zu vereinen. In meiner Arbeit mit Daten-Workflows habe ich gesehen, wie Delta-Tabellen schnellere Abfragen (und eine einfachere Fehlersuche) ermöglicht haben.
In diesem Leitfaden erkläre ich dir, wie Delta-Tabellen funktionieren, warum sie wichtig sind und wie du sie in deinen Projekten einsetzen kannst. Für den Anfang empfehle ich dir, unsere Kurse Einführung in Databricks und Databricks-Konzepte zu besuchen, um dich mit der Databricks Lakehouse-Plattform vertraut zu machen, einschließlich ihrer Funktionen und wie man sie für verschiedene Anwendungsfälle verwaltet.
Um die Leistungsfähigkeit von Delta Tabellen zu verstehen, ist es wichtig, die Architektur dahinter zu kennen. In diesem Abschnitt werde ich dieKomponenten aufschlüsseln, die Delta Lake für moderne Daten-Workloads belastbar, leistungsfähig und zuverlässig machen.
Delta Lake ist eine Open-Source-Speicherschicht, die ACID-Transaktionsgarantien für Apache Spark und Big Data Workloads bietet. Delta-Tabellen sind die physische Manifestation dieser Schicht. Es handelt sich dabei um Parquet-basierte Tabellen, die mit Transaktionsunterstützung und Schemaerzwingung erweitert wurden.
In Databricks dienen Delta-Tabellen als Standard-Datenformat für die Lakehouse-Architektur. Sie vereinheitlichen Batch- und Streaming-Workloads, unterstützen skalierbare Datenpipelines und vereinfachen die Verwaltung mit umfangreichen Metadaten und Versionskontrolle.
In der Praxis habe ich gesehen, dass Delta Tabellen in Echtzeit-Analysen und ETL-Pipelines bis hin zu Feature Stores für maschinelles Lernen und behördlichen Prüfpfaden eingesetzt werden.
DeltaLog ist ein Transaktionsprotokoll, das jede Änderung an derTabelle aufzeichnet. Dieses Protokoll ermöglicht eine vollständige ACID-Konformität, auch im großen Maßstab. (ACID-Konformität bedeutet, dass Datenoperationen alles oder nichts, konsistent, von anderen Transaktionen isoliert und trotz Ausfällen dauerhaft sind ).
Delta Lake verwendet Multi-Version Concurrency Control (MVCC) und ein optimistisches Gleichzeitigkeitsprotokoll, das es mehreren Lesern und Schreibern ermöglicht, konfliktfrei mit den Daten zu arbeiten. Wenn eine Transaktion festgeschrieben wird, prüft sie ihre Operationen anhand des letzten Zustands der Tabelle, um sicherzustellen, dass es keine überlappenden Änderungen gibt.
Jede Übertragung an das DeltaLog zeichnet strukturierte Aktionen auf, wie z.B.:
Diese Aufzeichnungen schaffen eine klare, nachprüfbare Historie der Tabellen. Dies ermöglicht Funktionen wie Zeitreise, Rollback und reproduzierbare Pipelines.
Delta-Tabellen setzen ein Schema-on-write-Modell durch, das sicherstellt, dass alle Daten, die in eine Tabelle geschrieben werden, mit der deklarierten Struktur übereinstimmen. Das hilft, nachgelagerte Fehler zu vermeiden und die Pipelines sauber und konsistent zu halten.
Gleichzeitig unterstützt Delta die so genannte Schema-Evolution. Das bedeutet, dass du neue Spalten hinzufügen oder Datentypen erweitern kannst, wenn sich dein Modell verändert. Funktionen wie die Spaltenzuordnung machen Schemaänderungen überschaubarer, und die Typumwandlung (z. B. von int zu long) verhindert Datenverluste. Da Delta-Tabellen DeltaLog unterstützen, werden Schemaänderungen wie Datenänderungen versioniert. Dies ermöglicht rückwärtskompatible Lesungen. So laufen ältere Abfragen reibungslos, auch wenn sich dein Schema weiterentwickelt.
Delta unterstützt auch generierte Spalten, erzwingbare Beschränkungen und benutzerdefinierte Metadaten-Tags, die das Schema aussagekräftiger und die Daten selbstbeschreibend machen. Ich fand diese Fähigkeiten hilfreich.
Delta-Tabellen speichern Daten im spaltenförmigen Parquet-Format, das mit Z-Ordering für schnellere Lesevorgänge optimiert ist, indem Daten auf Spalten mit hoher Kardinalität geclustert werden. Das verbessert die Leistung bei selektiven Abfragen erheblich. Das Delta Universal Format (UniForm) sorgt für Interoperabilität, indem es Delta-Tabellen für Nicht-Databricks-Tools lesbar macht und so den Zugriff auf den Data Lake über Ökosysteme hinweg erweitert.
Die Speicherung wird durch eine intelligente Dateigröße weiter optimiert. Delta Lake verwendet automatische Komprimierungs- und Bin-Packing-Strategien, um optimale Dateigrößen (100 bis 300 MB) zu erhalten.
Funktionen wie das Überspringen von Daten, Caching und automatische Indizierung steigern die Abfrageleistung weiter und machen Delta Tables ideal für umfangreiche Analysen und Echtzeit-Workloads.
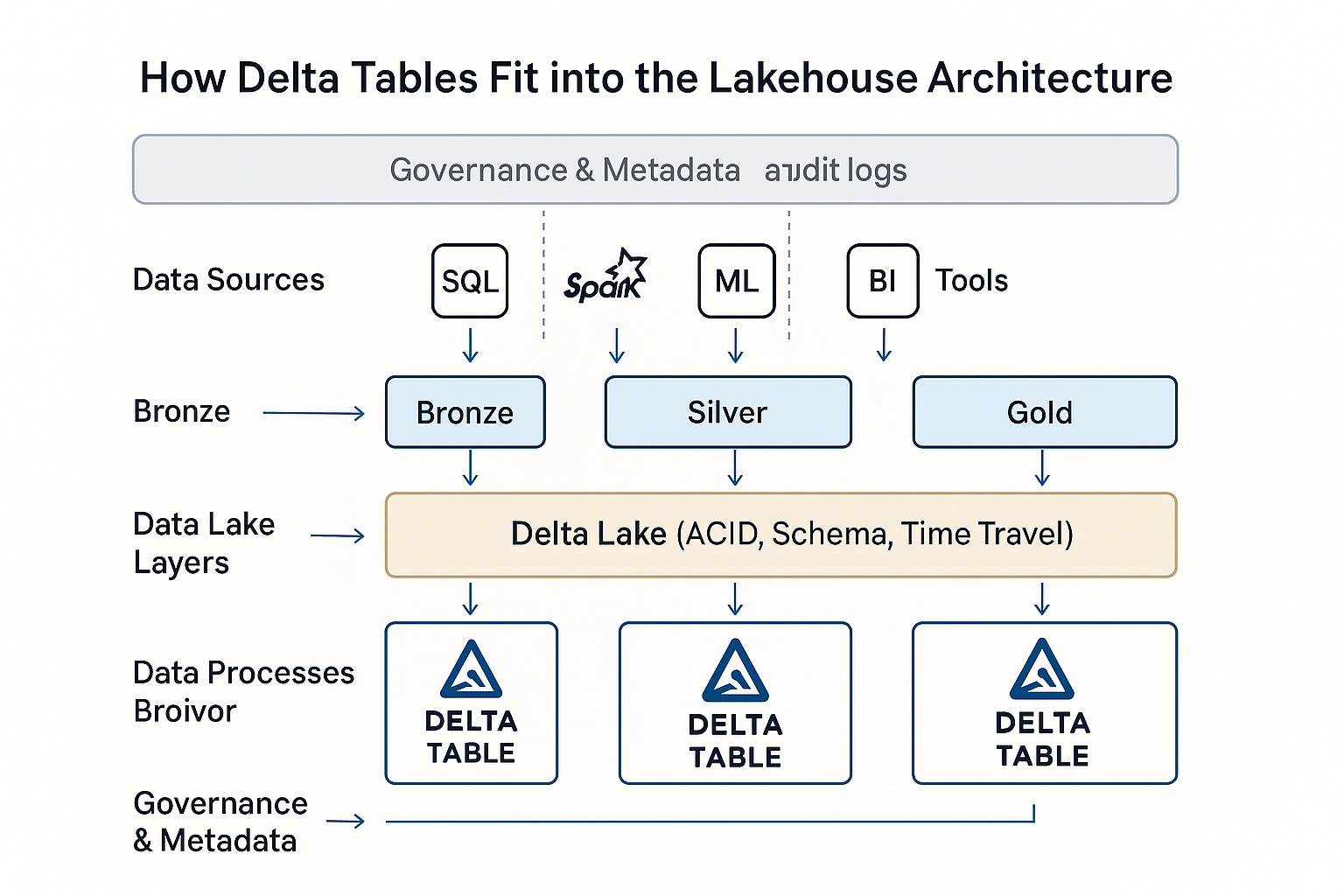
Delta-Tabellen in Databricks Lakehouse Architecture. Bild von OpenAI.
In diesem Abschnitt erkläre ich, wie Delta-Tabellen erstellt, mit Daten gefüllt und in den verschiedenen Phasen des Datenlebenszyklus geändert werden.
Je nach deinem Arbeitsablauf und deinen Präferenzen kannst du Delta-Tabellen mit verschiedenen Methoden erstellen. Du kannst Databricks SQLDDL-Anweisungen verwenden, wie CREATE TABLE ... USING DELTAverwenden oder sie programmatisch über DataFrames in PySpark, Scala oder Spark SQL erstellen. Diese Flexibilität hat es mir ermöglicht, Tabellendefinitionen in interaktiven Notebooks und automatisierten ETL-Jobs zu standardisieren.
Delta Lake unterstützt die einmalige und inkrementelle Konvertierung, wenn du bereits Daten im Parquet- oder Iceberg-Format hast. Du kannst eine einmalige Konvertierung für statische Datensätze mit CONVERT TO DELTA oder eine inkrementelle Konvertierung für aktiv geschriebene Daten mit Tabellenversionierung und Checkpointing-Strategien durchführen.
Ich empfehle, unserenKurs Einführung in Spark mit sparklyr in R zu besuchen, um zu lernen, wie man große Datensätze in Spark DataFrames bearbeitet.
Delta Lake unterstützt mehrere Ingestion-Methoden, darunter COPY INTO, die Daten strukturiert und mit automatischer Schema-Inferenz aus Cloud-Speichern lädt. Der Auto Loader ist jedoch bei der kontinuierlichen Aufnahme von Daten nützlich, vor allem bei Streaming oder häufig aktualisierten Datensätzen, und skaliert automatisch, wenn dein Eingabevolumen wächst.
Die Add Data UI in Databricks bietet eine einfache, interaktive Möglichkeit, lokale Dateien hochzuladen oder Cloud-Quellen zu durchsuchen, was für schnelle Experimente oder das Onboarding von technisch weniger versierten Nutzern praktisch ist.
Du kannst Daten auch im Batch- und Streaming-Modus einlesen und so einheitliche Pipelines erstellen, die Echtzeit- und historische Daten mit derselben Delta-Tabelle verarbeiten. Die Integration mit Tools von Drittanbietern wie Fivetran, Informatica und dbt erweitert die Reichweite von Delta Lake und ermöglicht es dir, Delta in ein breiteres Unternehmens-Ökosystem zu integrieren.
Delta Lake unterstützt DML (Datenbearbeitung Language) in vollem Umfang und ist damit fortschrittlicher als herkömmliche Data Lakes. Du kannst UPDATE, DELETE, MERGE und UPSERT Daten direkt in Delta-Tabellen mit SQL- oder PySpark-Syntax eingeben. So konnte ich Pipelines erstellen, die nahezu in Echtzeit auf Geschäftsereignisse reagieren, z. B. auf die Korrektur von Kundendatensätzen oder die Anwendung von Richtlinienänderungen. Ich empfehle, unseren Kurs Cleaning Data with PySpark zu besuchen, um die Methoden und Best Practices der Datenmanipulation mit PySpark kennenzulernen .
Delta-Tabellen unterstützen auch Zeitreiseabfragen, bei denen du frühere Tabellenstände abfragen kannst, indem du dich auf Versionsnummern oder Zeitstempel konzentrierst. (Das ist vor allem bei der Rechnungsprüfung sehr wichtig.) Die Funktion Change Data Feed (CDF) liefert Änderungsprotokolle auf Zeilenebene, so dass nachgelagerte Verbraucher Aktualisierungen schrittweise verarbeiten können, ohne ganze Tabellen erneut einlesen zu müssen, was für Echtzeit-Dashboards hilfreich ist.
Ich sollte auch darauf hinweisen, dass die Schemaentwicklung direkte Auswirkungen auf die Änderungsabläufe hat. Wenn du zum Beispiel eine neue Spalte hinzufügst, wird eine bestehende Zusammenführungsanweisung nicht unterbrochen, aber Typänderungen müssen möglicherweise vorsichtig gehandhabt werden, vor allem in verwalteten Umgebungen.
Ich möchte dir die besten Methoden vorstellen, mit denen ich die Leistung für schnelle, kostengünstige und zuverlässige Analysen maximiere.
Eine der häufigsten Leistungsfallen, die ich sehe, ist die falsche Dateigröße, entweder zu viele kleine Dateien oder große monolithische Dateien. Delta Lake löst dieses Problem durch automatische Komprimierung und Bin-Packing und stellt sicher, dass die Dateien in einem optimalen Größenbereich von 100-300 MB bleiben. Du kannst diese Prozesse manuell auslösen oder sie über die Eigenschaften der Tabelle konfigurieren.
Für analytische Workloads ist Z-Ordering eines der Werkzeuge in Delta Lake, mit dem Datendateien auf der Grundlage einer oder mehrerer Spalten mit hoher Kardinalität neu geordnet werden können, um die Anzahl der in Abfragen gescannten Dateien zu reduzieren. Der Befehl VACUUM hilft dabei, alte, nicht referenzierte Datendateien aus früheren Versionen zu entfernen, um den Speicher langfristig zu erhalten. Es ist ein wichtiger Teil der Tabellenhygiene, auf die Aufbewahrungsfrist zu achten, um zu vermeiden, dass Dateien gelöscht werden, die für Zeitreisen verwendet werden.
Delta-Tabellen bieten verschiedene erweiterte Funktionen zur Optimierung von Abfragen und der Speicherleistung. Das Überspringen von Daten, die Partitionierung und das Clustering helfen dabei, die Menge der bei Abfragen gescannten Daten zu minimieren, während das Dynamic File Pruning (DFP) die Join-Leistung optimiert, indem es unnötige Dateilesevorgänge eliminiert.
Hardware-Provisioning, also die Wahl der richtigen Clustergröße und -konfiguration, kann in Kombination mit Delta-Caching wiederholte Abfragen beschleunigen. Die automatische Workload-Optimierung in Databricks stellt außerdem sicher, dass die Ressourcen effizient genutzt werden. Partition Pruning und optimierte Join-Strategien sind für große Datenmengen wichtig, damit Abfragen schneller und vorhersehbarer ablaufen können.
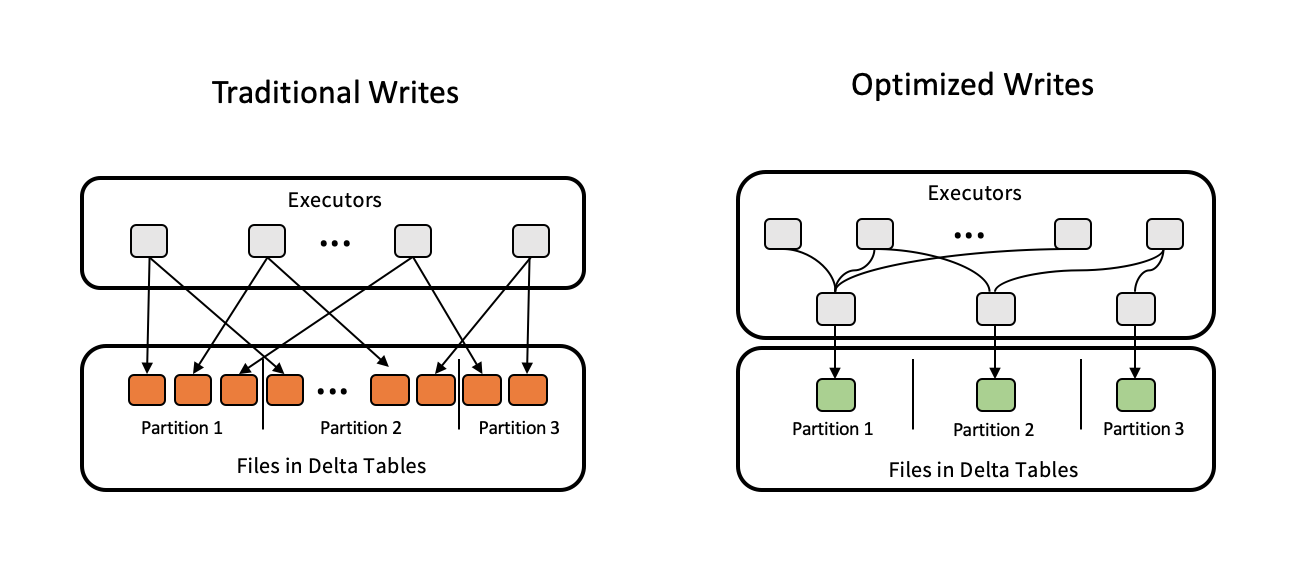
Optimierte Schreibvorgänge zur Optimierung von Delta-Tabellen. Bildquelle: Delta Lake.
Delta-Tabellen wurden entwickelt, um Batch- und Streaming-Workloads zu vereinen. Funktionen wie die Exact-Once-Verarbeitung und die Trigger-Once-Funktionalitäthalten die Daten in komplexeren Streaming-Szenarien konsistent. Und die Ratenbegrenzung kontrolliert die Aufnahmegeschwindigkeit.
In diesem Abschnitt werde ich einige fortgeschrittene Integrationen und Optimierungen vorstellen, die Delta Tabellen zu einer vollständigen Unternehmenslösung machen.
Das Delta Sharing Protocol ist ein offener Standard, der von Databricks entwickelt wurde, um einen sicheren, skalierbaren Datenaustausch über Unternehmens- und Plattformgrenzen hinweg zu ermöglichen. Im Gegensatz zu herkömmlichen Datenexporten bietet Delta Sharing den Empfängern einen Live-Zugang zu den aktuellsten Daten ohne Duplikate.
Es gibt zwei Hauptszenarien für die gemeinsame Nutzung:
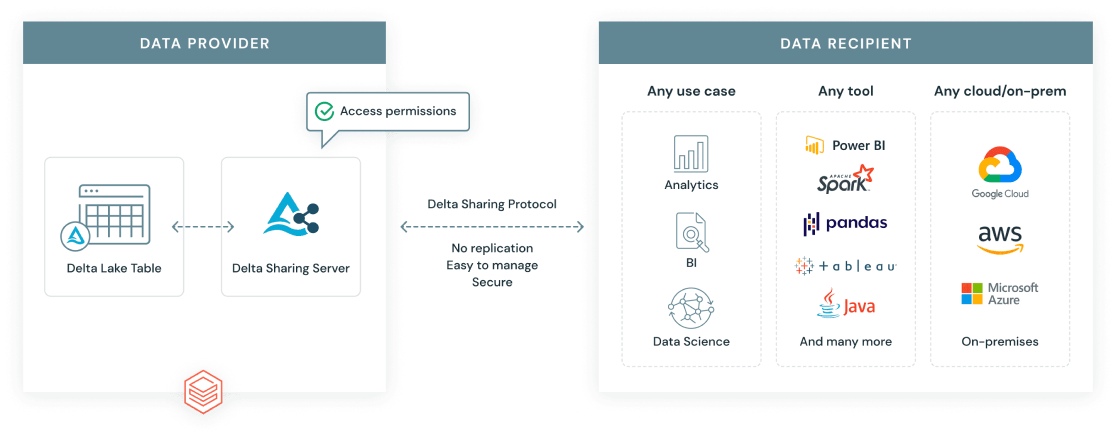
Databricks Delta-Sharing-Protokoll. Bildquelle: Databricks.
Die Delta-Engine ist eine leistungsstarke Abfrage-Engine, die für Delta-Tabellen optimiert ist. Sie ist mit Databricks SQL und Photon integriert, einer vektorisierten Ausführungsengine, die SQL- und DataFrame-Workloads durch die Nutzung moderner CPU-Architekturen beschleunigt. Dies führt zu erheblichen Leistungssteigerungen, insbesondere bei umfangreichen Analysen und komplexen Abfragen.
Die Delta Engine unterstützt erweiterte Funktionen wie materialisierte Ansichten. Es ist wichtig zu wissen, dass sich materialisierte Ansichten von Streaming-Tabellen unterscheiden. Während Materialized Views für wiederholte, vorhersehbare Abfragen optimiert sind , sind Streaming Tabellen für die kontinuierliche Datenaufnahme und -verarbeitung in Echtzeit konzipiert.
Dynamic File Pruning (DFP) ist eine Optimierungstechnik bei Join-Abfragen. Sie ermöglicht es Spark, unnötige Dateien auf der Leseseite anhand von Verknüpfungsschlüsseln herauszufiltern. Anstatt die gesamte rechte Seite einer Verknüpfung zu scannen, beschränkt DFP die Suche auf die relevanten Dateiblöcke. Diese Technik verbessert die Leistung bei partitionierten Datensätzen oder bei der Filterung nach Kunden, Regionen oder Produkten.
In der Praxis habe ich gesehen, dass DFP einen großen Unterschied macht, wenn große, partitionierte Tabellen verbunden werden, z. B. in ETL-Pipelines oder Analyse-Dashboards. Das führt zu einer schnelleren, effizienteren Verarbeitung und niedrigeren Rechenkosten.
Im Folgenden findest du die wichtigsten Best Practices, die ich beim Aufbau und der Skalierung von Delta-Workflows gelernt habe:
Verwaltung der Dateigröße: Halte die Datendateien zwischen 100 und 300 MB, indem du die automatische Komprimierung oder OPTIMIZE verwendest, um Probleme mit kleinen Dateien zu reduzieren und die Scanleistung zu verbessern.
Zeitreisekonfiguration: Verwende dataRetentionDuration oder VACUUM, um angemessene Aufbewahrungsfristen festzulegen, die ein Gleichgewicht zwischen Rollback-Flexibilität und Speichereffizienz herstellen.
Gleichzeitigkeitskontrollen: Verwende Isolationsebenen und optimistische Gleichzeitigkeitskontrolle, um Schreibvorgänge mehrerer Benutzer zu verwalten und Commit-Konflikte zu reduzieren.
Kostenoptimierung: Nutze Photon, Delta Caching und Z-Ordering, um die Rechenkosten zu minimieren, insbesondere bei wiederholten Abfragen.
Überwache die Leistung: Nutze Abfrageprofile, Lakehouse Monitoring und Workload Utilization Reports, um langsame Abfragen zu identifizieren und die Ressourcennutzung zu optimieren.
Partitionierung und Datenlayout: Um Datenscans zu minimieren, partitioniere Tabellen nur nach Spalten mit geringer Kardinalität, wie z.B. Datum oder Ort. Verwende Z-Ordering innerhalb von Partitionen für Felder mit hoher Kardinalität, um Abfragen weiter zu beschleunigen. Vermeide eine übermäßige Partitionierung, die zu kleinen Dateien und Leistungseinbußen führen kann.
Ich habe viel über die Gründe für Delta-Tabellen gesprochen, aber es ist auch hilfreich, sie mit traditionellen Data-Lake-Strukturen und mit anderen Tabellenarten in Databricks selbst zu vergleichen:
|
Feature |
Delta-Tabellen |
Hive Tabellen |
Delta Live Tabellen (DLT) |
Streaming-Tabellen |
Materialisierte Ansichten |
|
ACID-Transaktionen |
Volle Unterstützung |
Begrenzt/Keine |
Auf Delta gebaut |
via Delta |
oben auf dem Delta |
|
Schema-Durchsetzung |
Erzwungen beim Schreiben |
Manuelle Durchsetzung |
Deklarativ + verwaltet |
Mit Streaming-Kompatibilität |
Folgt Basis Delta Tabelle |
|
Zeitreise |
Eingebaut |
Nicht unterstützt |
Geerbt von Delta |
(Version-bewusstes Lesen) |
Refresh-abhängig |
|
Streaming-Unterstützung |
Einheitliches Batch/Streaming |
Getrennte Handhabung |
Auto-verwaltet |
Native Unterstützung |
Nur periodische Aktualisierung |
|
Skalierbarkeit der Metadaten |
Waagen mit großen Tabellen |
Langsamer mit Trennwänden |
Optimiert über DLT |
Mit Lernpfad |
Erbt von Delta |
|
Operatives Management |
Mit OPTIMIZE, VACUUM, etc. |
Manuell und spröde |
Verwaltet durch DLT-Pipelines |
Konfigurierbare Auslöser |
Aktualisierungs- und Cache-Optionen |
Schauen wir uns nun die häufigsten Anwendungsfälle an, in denen Delta-Tabellen zum Einsatz kommen.
Delta Tables bietet eine zuverlässige und flexible Lösung für die Verwaltung von Daten in Databricks, die Echtzeit- und Batch-Analysen unterstützt. Das Delta Lake-Ökosystem wird ständig weiterentwickelt, mit neuen Funktionen, die die gemeinsame Nutzung von Daten, Governance und Leistung noch einfacher machen. Ich empfehle dir, die Best Practices für Datenlayout und Automatisierung zu befolgen und dich über neue Möglichkeiten auf dem Laufenden zu halten.
Wenn du deine Kenntnisse im Bereich Data Warehousing erweitern möchtest, empfehle ich dir unseren Kurs Associate Data Engineer in SQL, in dem du lernst, wie man Datenbanken entwirft und mit ihnen arbeitet. Wenn du dich auf deine Vorstellungsgespräche vorbereitest, sieh dir unsere Top 20 Databricks Interviewfragen an, um dichvon anderen Datenexperten abzuheben.
Databricks lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
