
Course
Data Management in Databricks
3 hr
5.5K
Delta Tables are a part of Databricks’ lakehouse architecture. Their goal is to put together the reliability of data warehouses and the scalability of data lakes. In my experience working across data workflows, I have seen how Delta Tables have enabled faster queries (and easier debugging).
In this guide, I will explain how Delta Tables work, why they matter, and how to use them in your projects. As we get started, I recommend taking our Introduction to Databricks and Databricks Concepts courses to familiarize yourself with the Databricks Lakehouse platform, including its features and how to manage it for different use cases.
Understanding the architecture behind Delta Tables is key to truly appreciating their power. In this section, I will break down the components that make Delta Lake resilient, performant, and reliable for modern data workloads.
Delta Lake is an open-source storage layer that brings ACID transaction guarantees to Apache Spark and big data workloads. Delta Tables are the physical manifestation of this layer, which are Parquet-based data tables enhanced with transactional support and schema enforcement.
Within Databricks, Delta Tables serve as the default data format of the lakehouse architecture. They unify batch and streaming workloads, support scalable data pipelines, and simplify governance with rich metadata and version control.
In practice, I’ve seen Delta Tables used in from real-time analytics and ETL pipelines to machine learning feature stores and regulatory audit trails.
DeltaLog is a transaction log that records every change made to the table. This log enables full ACID compliance, even at scale. (ACID compliance means data operations are all-or-nothing, consistent, isolated from other transactions, and durable despite failures.)
Delta Lake uses multi-version concurrency control (MVCC) and an optimistic concurrency protocol, which allows multiple readers and writers to work with the data without conflict. When a transaction commits, it validates its operations against the latest table state to ensure no overlapping changes occurred.
Each commit to the DeltaLog records structured actions such as:
These records create a clear, auditable table history. This enables features like time travel, rollback, and reproducible pipelines.
Delta Tables enforce a schema-on-write model, ensuring all data written to a table matches the declared structure. This helps prevent downstream errors and keeps pipelines clean and consistent.
At the same time, Delta supports what is known as schema evolution. What this means is that you can add new columns or promote data types as your model becomes different. Features like column mapping make schema changes more manageable, and type promotion (such as from int to long, to take one example), which avoids data loss. Since Delta Tables support DeltaLog, schema changes are versioned like data changes. This allows for backward-compatible reads. So older queries run smoothly even though your schema evolves.
Delta also supports generated columns, enforceable constraints, and custom metadata tags, which make the schema more expressive and the data more self-describing. I found these capabilities helpful.
Delta Tables store data in columnar Parquet format, optimized with Z-Ordering for faster reads by clustering data on high-cardinality columns. This significantly improves performance for selective queries. The Delta Universal Format (UniForm) ensures interoperability by making Delta Tables readable by non-Databricks tools, expanding access to the data lake across ecosystems.
Storage is further optimized through intelligent file sizing. Delta Lake uses auto-compaction and bin-packing strategies to maintain optimal file sizes (100 to 300 MB).
Features like data skipping, caching, and automatic indexing further boost query performance, making Delta Tables ideal for both large-scale analytics and real-time workloads
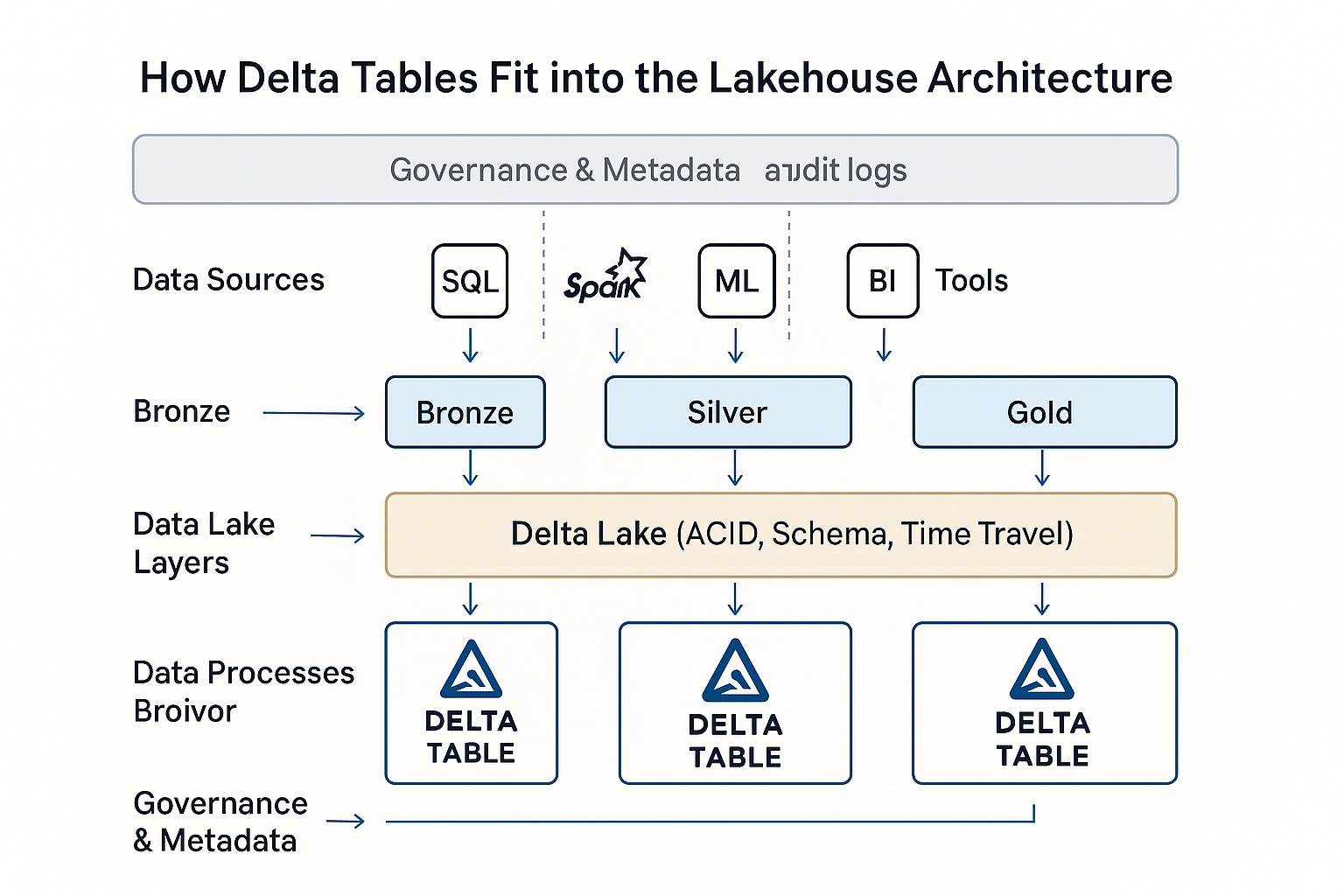
Delta Tables in Databricks Lakehouse Architecture. Image from OpenAI.
In this section, I will explain how Delta Tables are created, ingested with data, and modified across different data lifecycle stages.
Depending on your workflow and preferences, you can create Delta Tables using several methods. You can use Databricks SQL DDL statements such as CREATE TABLE ... USING DELTA, or create them programmatically via DataFrames in PySpark, Scala, or Spark SQL. This flexibility has allowed me to standardize table definitions across interactive notebooks and automated ETL jobs.
Delta Lake supports one-time and incremental conversion if you already have data in Parquet or Iceberg formats. You can perform a one-time conversion for static datasets using CONVERT TO DELTA or an incremental conversion for actively written data using table versioning and checkpointing strategies.
I recommend taking our Introduction to Spark with sparklyr in R course to learn how to manipulate huge datasets in Spark DataFrames.
Delta Lake supports several ingestion methods, including COPY INTO, which loads data from cloud storage in a structured manner with automatic schema inference. However, Auto Loader is useful in continuous ingestion, especially for streaming or frequently updated datasets, and scales automatically as your input volume grows.
The Add Data UI in Databricks provides a simple, interactive way to upload local files or browse cloud sources, which is handy for quick experiments or onboarding less technical users.
You can also ingest data in batch and streaming modes, creating unified pipelines that handle real-time and historical data using the same Delta Table. Integration with third-party tools like Fivetran, Informatica, and dbt further expands Delta Lake’s reach, letting you plug Delta into broader enterprise ecosystems.
Delta Lake supports full DML (Data Manipulation Language), making it more advanced than traditional data lakes. You can UPDATE, DELETE, MERGE, and UPSERT data directly within Delta Tables using SQL or PySpark syntax. This has allowed me to build pipelines that react to business events in near real-time, such as correcting customer records or applying policy changes. I recommend taking our Cleaning Data with PySpark course to learn the methods and best practices of using PySpark for data manipulation.
Delta Tables also support time travel queries, where you can query previous table states by focusing on version numbers or timestamps. (This is very important with auditing especially.) The Change Data Feed (CDF) feature provides row-level change logs, enabling downstream consumers to incrementally process updates without re-reading full tables, which is helpful for real-time dashboards.
I should also point out that schema evolution directly impacts modification workflows. For example, adding a new column won’t break an existing merge statement, but type changes might require careful handling, especially in governed environments.
Let me share the best practices I use to maximize performance for fast, cost-effective, and reliable analytics.
One of the most common performance pitfalls I see is improper file sizing, either too many small files or large monolithic ones. Delta Lake solves this problem through auto-compaction and bin-packing, ensuring files stay within optimal size ranges of 100–300 MB. You can trigger these processes manually or configure them with table properties.
For analytical workloads, Z-Ordering is one of the tools in Delta Lake used to reorder data files based on one or more high-cardinality columns, reducing the number of files scanned in queries. The VACUUM command helps remove old, unreferenced data files from previous versions to maintain long-term storage health. It is an important part of table hygiene to be careful with the retention period to avoid deleting files used for time travel.
Delta Tables offer several advanced features for tuning queries and storage performance. Data skipping, partitioning, and clustering help minimize the amount of data scanned during queries, while dynamic file pruning (DFP) optimizes join performance by eliminating unnecessary file reads.
Hardware provisioning, which is choosing the correct cluster size and configuration, combined with delta caching, can speed up repeated queries. Automated workload optimization in Databricks also ensures resources are used efficiently. Partition pruning and optimized join strategies are important for large datasets, enabling queries to run faster and more predictably.
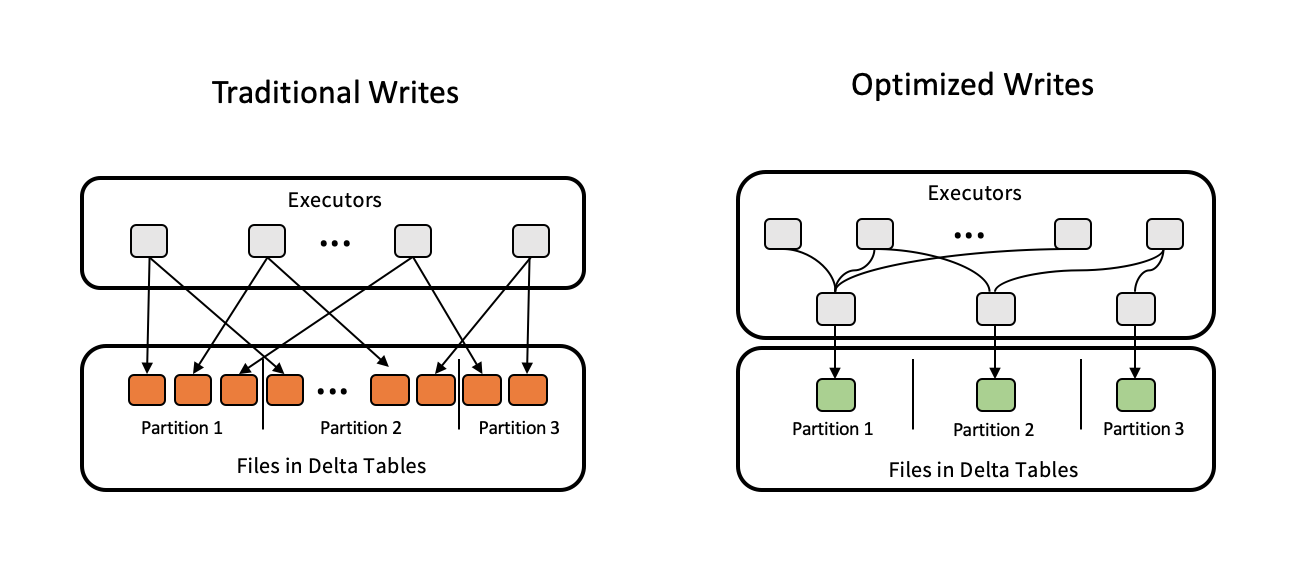
Optimized writes for optimizing Delta tables. Image source: Delta Lake.
Delta Tables are designed to unify batch and streaming workloads. Features like exactly-once processing and trigger-once functionality keep data consistent in more complex streaming scenarios. And rate limiting controls ingestion speed.
In this section, I will highlight some advanced integrations and optimizations that elevate Delta Tables to a complete enterprise-grade solution.
The Delta Sharing Protocol is an open standard developed by Databricks to enable secure, scalable data sharing across organizational and platform boundaries. Unlike traditional data exports, Delta Sharing gives recipients live access to the most up-to-date data without duplication.
There are two main sharing scenarios:
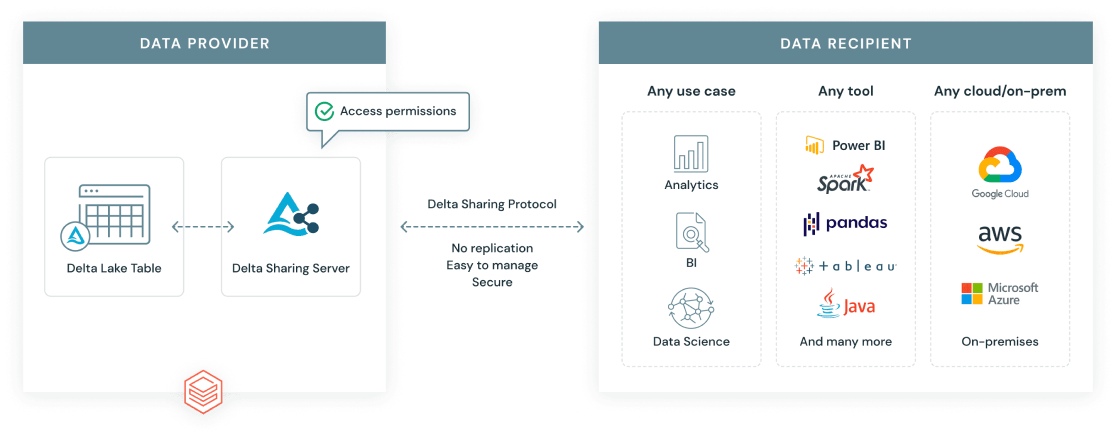
Databricks delta sharing protocol. Image source: Databricks.
The Delta Engine is a high-performance query engine optimized for Delta Tables. It integrates with Databricks SQL and Photon, a vectorized execution engine that accelerates SQL and DataFrame workloads by leveraging modern CPU architectures. This results in significant performance gains, especially for large-scale analytics and complex queries.
Delta Engine supports advanced features such as materialized views. It’s important to note that materialized views differ from streaming tables. While materialized views optimize for repeated, predictable queries, streaming tables are designed for continuous, real-time data ingestion and processing.
Dynamic File Pruning (DFP) is an optimization technique during join queries. It allows Spark to filter out unnecessary files from the read side based on join keys. Instead of scanning the full right-hand side of a join, DFP limits the scan to only relevant file blocks. This technique improves performance for partitioned datasets or when filtering by customer, region, or product.
In practice, I have seen DFP make a significant difference in where large, partitioned tables are joined, such as ETL pipelines or analytics dashboards. This leads to faster, more efficient processing and lower compute costs.
Below are key best practices I’ve learned from building and scaling Delta workflows:
File size management: Keep data files between 100 and 300 MB using auto-compaction or OPTIMIZE to reduce small file issues and improve scan performance.
Time travel configuration: Use dataRetentionDuration or VACUUM to set reasonable retention periods that balance rollback flexibility with storage efficiency.
Concurrency controls: Use isolation levels and optimistic concurrency control to manage multi-user writes and reduce commit conflicts.
Cost optimization: Use Photon, Delta Caching, and Z-Ordering to minimize computing costs, especially for repeated queries.
Monitor performance: Use Query Profile, Lakehouse Monitoring, and Workload Utilization Reports to identify slow queries and optimize resource usage.
Partitioning and data layout: To minimize data scans, partition tables only on low-cardinality columns like dates or locations. Use Z-Ordering within partitions for high-cardinality fields to further accelerate queries. Avoid over-partitioning, which can lead to small files and degraded performance.
I’ve talked a lot about the reason for Delta Tables, but it’s helpful also to compare to more traditional data lake structures also to compare with other table types within Databricks itself:
|
Feature |
Delta Tables |
Hive Tables |
Delta Live Tables (DLT) |
Streaming Tables |
Materialized Views |
|
ACID Transactions |
Full support |
Limited/None |
Built on Delta |
via Delta |
on top of Delta |
|
Schema Enforcement |
Enforced on write |
Manual enforcement |
Declarative + managed |
With streaming compatibility |
Follows base Delta Table |
|
Time Travel |
Built-in |
Not supported |
Inherited from Delta |
(version-aware reads) |
Refresh-dependent |
|
Streaming Support |
Unified batch/streaming |
Separate handling |
Auto-managed |
Native support |
Periodic update only |
|
Metadata Scalability |
Scales with large tables |
Slower with partitions |
Optimized via DLT |
With log tracking |
Inherits from Delta |
|
Operational Management |
With OPTIMIZE, VACUUM, etc. |
Manual and brittle |
Managed by DLT pipelines |
Configurable triggers |
Refresh and cache options |
Now, let us look at the common use cases where Delta Tables are applied for their value.
Delta Tables offers a reliable and flexible solution for managing data in Databricks, supporting real-time and batch analytics. The Delta Lake ecosystem continues to evolve, with new features making data sharing, governance, and performance even easier.
If you are looking to advance your skills in data warehousing, I recommend taking our Associate Data Engineer in SQL course to learn how to design and work with databases. As you prepare for your interviews, check out our Top 20 Databricks Interview Questions to stand out among other people interviewing.
Learn Databricks with DataCamp
Course
Course
Course
blog
Josep Ferrer
Tutorial
Khalid Abdelaty
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Arunn Thevapalan
Tutorial
Bex Tuychiev


