
Curso
Gerenciamento de Dados no Databricks
3 h
5.6K
As tabelas Delta fazem parte da arquitetura lakehouse da Databricks. Seu objetivo é reunir a confiabilidade dos data warehouses e a escalabilidade dos data lakes. Em minha experiência de trabalho em fluxos de trabalho de dados, vi como as tabelas Delta permitiram consultas mais rápidas (e depuração mais fácil).
Neste guia, explicarei como as tabelas Delta funcionam, por que elas são importantes e como você pode usá-las em seus projetos. Para começar, recomendo que você faça nossos cursos Introduction to Databricks e Databricks Concepts para se familiarizar com a plataforma Databricks Lakehouse, incluindo seus recursos e como gerenciá-la para diferentes casos de uso.
Entender a arquitetura por trás das tabelas Delta é fundamental para que você possa realmente apreciar seu poder. Nesta seção, detalharei os componentes que tornam o Delta Lake resiliente, eficiente e confiável para cargas de trabalho de dados modernas.
O Delta Lake é uma camada de armazenamento de código aberto que traz garantias de transações ACID para o Apache Spark e cargas de trabalho de Big Data. As tabelas Delta são a manifestação física dessa camada, que são tabelas de dados baseadas em Parquet, aprimoradas com suporte transacional e aplicação de esquema.
Na Databricks, as tabelas Delta servem como o formato de dados padrão da arquitetura lakehouse. Eles unificam as cargas de trabalho em lote e de streaming, oferecem suporte a pipelines de dados dimensionáveis e simplificam a governança com metadados avançados e controle de versão.
Na prática, já vi o uso de tabelas Delta em análises em tempo real e pipelines de ETL, em armazenamentos de recursos de machine learning e em trilhas de auditoria regulatórias.
O DeltaLog é um log de transações que registra todas as alterações feitas natabela. Esse registro permite a conformidade total com ACID, mesmo em escala. (Conformidade com ACID significa que as operações de dados são do tipo tudo ou nada, consistentes, isoladas de outras transações e duráveis apesar de falhas).
O Delta Lake usa o controle de simultaneidade de várias versões (MVCC) e um protocolo de simultaneidade otimista, que permite que vários leitores e gravadores trabalhem com os dados sem conflito. Quando uma transação é confirmada, ela valida suas operações em relação ao estado mais recente da tabela para garantir que não ocorreram alterações sobrepostas.
Cada confirmação do DeltaLog registra ações estruturadas, como:
Esses registros criam um histórico claro e auditável da tabela. Isso permite recursos como viagem no tempo, reversão e pipelines reproduzíveis.
As tabelas Delta aplicam um modelo de esquema na gravação, garantindo que todos os dados gravados em uma tabela correspondam à estrutura declarada. Isso ajuda a evitar erros de downstream e mantém os pipelines limpos e consistentes.
Ao mesmo tempo, a Delta oferece suporte ao que é conhecido como evolução do esquema. Isso significa que você pode adicionar novas colunas ou promover tipos de dados à medida que seu modelo se torna diferente. Recursos como o mapeamento de colunas tornam as alterações de esquema mais gerenciáveis e a promoção de tipos (como de int para long, para citar um exemplo), que evita a perda de dados. Como as tabelas Delta suportam DeltaLog, as alterações de esquema são versionadas como as alterações de dados. Isso permite leituras compatíveis com versões anteriores. Assim, as consultas mais antigas são executadas sem problemas, mesmo que seu esquema tenha evoluído.
O Delta também oferece suporte a colunas geradas, restrições aplicáveis e tags de metadados personalizados, o que torna o esquema mais expressivo e os dados mais autodescritivos. Achei esses recursos úteis.
As tabelas Delta armazenam dados no formato Parquet colunar, otimizado com Z-Ordering para leituras mais rápidas, agrupando dados em colunas de alta cardinalidade. Isso melhora significativamente o desempenho das consultas seletivas. O Delta Universal Format (UniForm) garante a interoperabilidade ao tornar as tabelas Delta legíveis por ferramentas que não são da Databricks, expandindo o acesso ao data lake em todos os ecossistemas.
O armazenamento é otimizado ainda mais por meio do dimensionamento inteligente de arquivos. O Delta Lake usa estratégias de compactação automática e empacotamento de compartimentos para manter o tamanho ideal dos arquivos (100 a 300 MB).
Recursos como ignorar dados, armazenamento em cache e indexação automática aumentam ainda mais o desempenho das consultas, tornando as tabelas Delta ideais para análises em grande escala e cargas de trabalho em tempo real.
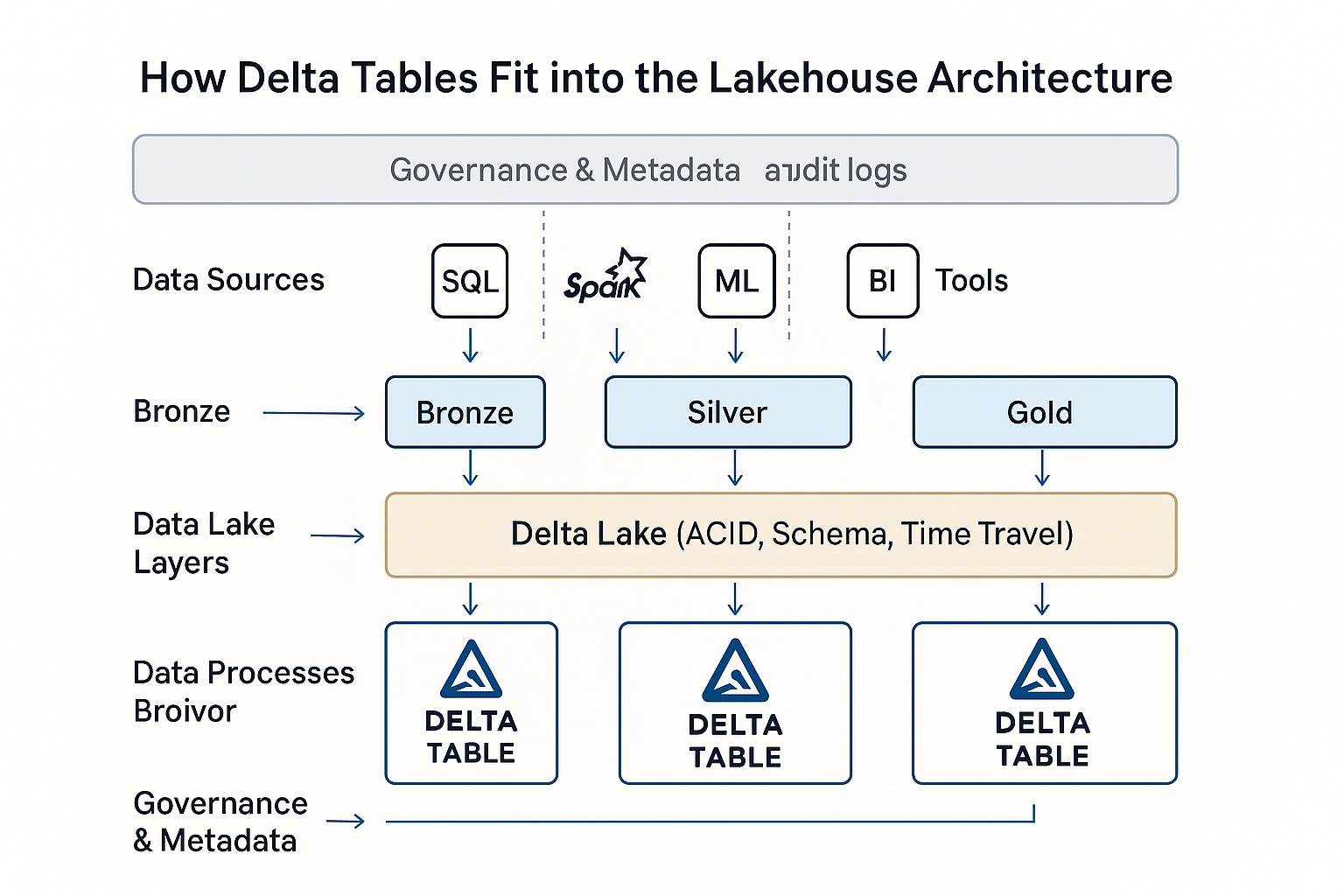
Tabelas delta na arquitetura Lakehouse da Databricks. Imagem da OpenAI.
Nesta seção, explicarei como as tabelas Delta são criadas, ingeridas com dados e modificadas em diferentes estágios do ciclo de vida dos dados.
Dependendo do seu fluxo de trabalho e preferências, você pode criar tabelas Delta usando vários métodos. Você pode usarinstruções SQL DDL do Databricks, como CREATE TABLE ... USING DELTAou criá-las programaticamente por meio de DataFrames em PySpark, Scala ou Spark SQL. Essa flexibilidade me permitiu padronizar as definições de tabelas em notebooks interativos e trabalhos de ETL automatizados.
O Delta Lake oferece suporte à conversão única e incremental se você já tiver dados nos formatos Parquet ou Iceberg. Você pode realizar uma conversão única para conjuntos de dados estáticos usando CONVERT TO DELTA ou uma conversão incremental para dados gravados ativamente usando versionamento de tabelas e estratégias de checkpointing.
Recomendo quevocê faça ocurso Introdução ao Spark com sparklyr em R para aprender a manipular conjuntos de dados enormes no DataFrames do Spark.
O Delta Lake oferece suporte a vários métodos de ingestão, incluindo COPY INTO, que carrega dados do armazenamento em nuvem de forma estruturada com inferência automática de esquema. No entanto, o Auto Loader é útil na ingestão contínua, especialmente para conjuntos de dados de streaming ou atualizados com frequência, e é dimensionado automaticamente à medida que o volume de entrada aumenta.
A interface de usuário Add Data no Databricks fornece uma maneira simples e interativa de fazer upload de arquivos locais ou procurar fontes na nuvem, o que é útil para experimentos rápidos ou para a integração de usuários menos técnicos.
Você também pode ingerir dados nos modos batch e streaming, criando pipelines unificados que lidam com dados históricos e em tempo real usando a mesma tabela Delta. A integração com ferramentas de terceiros, como Fivetran, Informatica e dbt, expande ainda mais o alcance do Delta Lake, permitindo que você conecte o Delta a ecossistemas empresariais mais amplos.
O Delta Lake é totalmente compatível com DML (Data Manipulation Language, linguagem de manipulação de dados), o que o torna mais avançado do que os data lakes tradicionais. Você pode acessar os dados UPDATE, DELETE, MERGE e UPSERT diretamente nas tabelas Delta usando a sintaxe SQL ou PySpark . Isso me permitiu criar pipelines que reagem a eventos comerciais quase em tempo real, como a correção de registros de clientes ou a aplicação de alterações de políticas. Recomendo que você faça nosso curso Cleaning Data with PySpark para conhecer os métodos e as práticas recomendadas de uso do PySpark para manipulação de dados.
As tabelas Delta também suportam consultas de viagem no tempo, nas quais você pode consultar estados anteriores da tabela concentrando-se em números de versão ou carimbos de data/hora. (Isso é muito importante principalmente para a auditoria). O recurso Change Data Feed (CDF) fornece registros de alterações no nível da linha, permitindo que os consumidores downstream processem atualizações de forma incremental sem reler tabelas completas, o que é útil para painéis em tempo real.
Também devo salientar que a evolução do esquema afeta diretamente os fluxos de trabalho de modificação. Por exemplo, a adição de uma nova coluna não quebrará uma instrução de mesclagem existente, mas as alterações de tipo podem exigir um tratamento cuidadoso, especialmente em ambientes governados.
Deixe-me compartilhar as práticas recomendadas que uso para maximizar o desempenho para obter análises rápidas, econômicas e confiáveis.
Uma das armadilhas de desempenho mais comuns que vejo é o dimensionamento inadequado de arquivos, seja um número excessivo de arquivos pequenos ou arquivos monolíticos grandes. O Delta Lake resolve esse problema por meio da compactação automática e do empacotamento em compartimentos, garantindo que os arquivos permaneçam dentro de faixas de tamanho ideais de 100 a 300 MB. Você pode acionar esses processos manualmente ou configurá-los com as propriedades da tabela.
Para cargas de trabalho analíticas, o Z-Ordering é uma das ferramentas do Delta Lake usadas para reordenar os arquivos de dados com base em uma ou mais colunas de alta cardinalidade, reduzindo o número de arquivos digitalizados nas consultas. O comando VACUUM ajuda a remover arquivos de dados antigos e não referenciados de versões anteriores para manter a integridade do armazenamento a longo prazo. É uma parte importante da higiene da tabela que você tenha cuidado com o período de retenção para evitar a exclusão de arquivos usados para viajar no tempo.
As tabelas Delta oferecem vários recursos avançados para que você possa ajustar as consultas e o desempenho do armazenamento. A omissão de dados, o particionamento e o agrupamento ajudam a minimizar a quantidade de dados digitalizados durante as consultas, enquanto a poda dinâmica de arquivos (DFP) otimiza o desempenho da união, eliminando leituras desnecessárias de arquivos.
O provisionamento de hardware, que consiste em escolher o tamanho e a configuração corretos do cluster, combinado com o cache delta, pode acelerar as consultas repetidas. A otimização automatizada da carga de trabalho no Databricks também garante que os recursos sejam usados com eficiência. A poda de partição e as estratégias de união otimizadas são importantes para grandes conjuntos de dados, permitindo que as consultas sejam executadas de forma mais rápida e previsível.
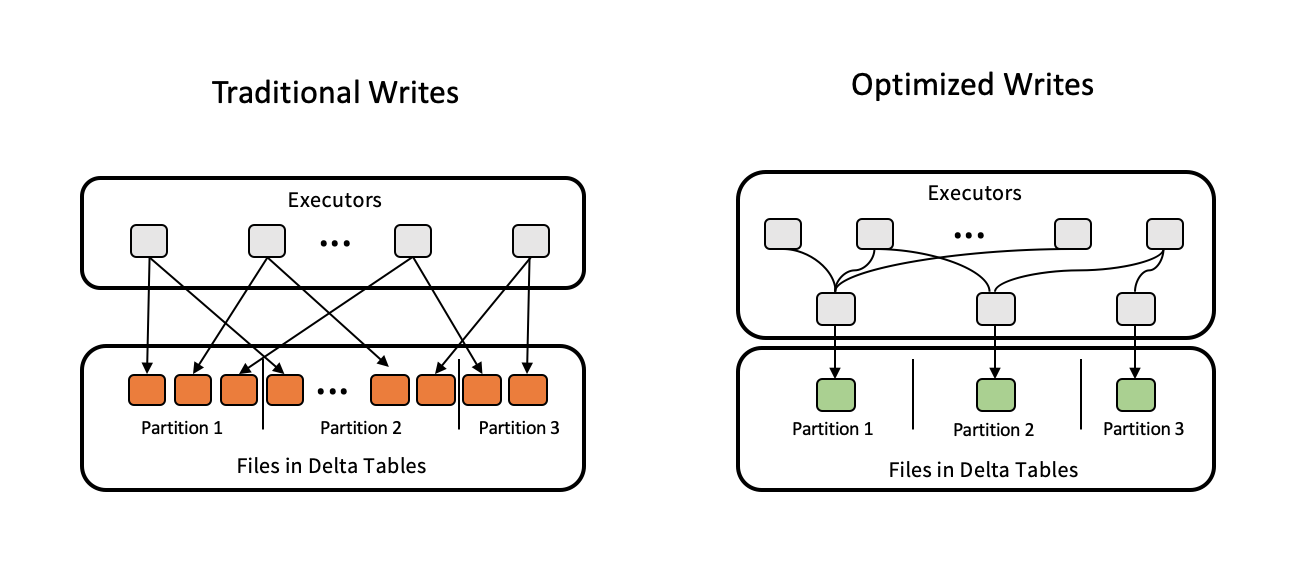
Gravações otimizadas para você otimizar as tabelas Delta. Fonte da imagem: Delta Lake.
As tabelas Delta são projetadas para unificar cargas de trabalho em lote e de streaming. Recursos como o processamento exatamente único e a funcionalidade trigger-once mantêm os dados consistentes em cenários de streaming mais complexos. E a limitação de taxa controla a velocidade de ingestão.
Nesta seção, destacarei algumas integrações e otimizações avançadas que elevam o Delta Tables a uma solução completa de nível empresarial.
O Delta Sharing Protocol é um padrão aberto desenvolvido pela Databricks para permitir o compartilhamento seguro e dimensionável de dados entre fronteiras organizacionais e de plataforma. Diferentemente das exportações de dados tradicionais, o Delta Sharing oferece aos destinatários acesso em tempo real aos dados mais atualizados, sem duplicação.
Há dois cenários principais de compartilhamento:
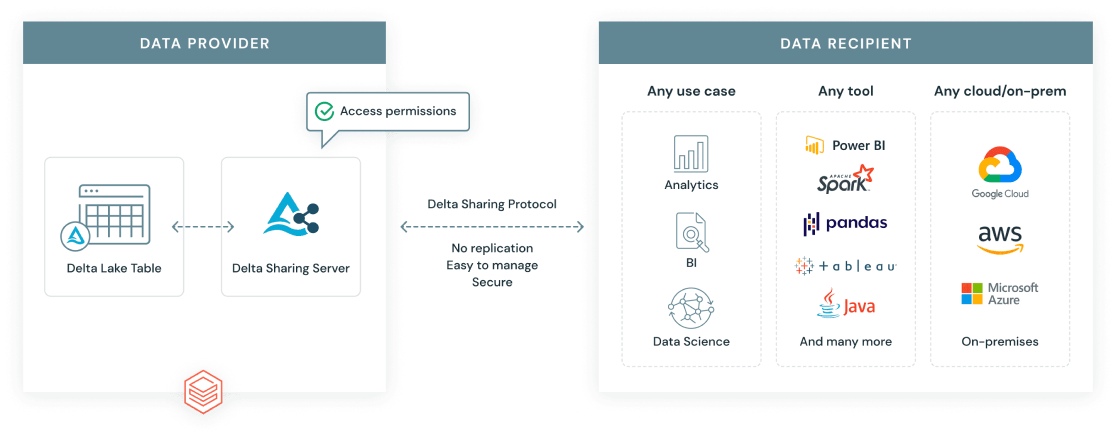
Protocolo de compartilhamento delta da Databricks. Fonte da imagem: Databricks.
O Delta Engine é um mecanismo de consulta de alto desempenho otimizado para tabelas Delta. Ele se integra ao Databricks SQL e ao Photon, um mecanismo de execução vetorizada que acelera as cargas de trabalho do SQL e do DataFrame, aproveitando as arquiteturas modernas da CPU. Isso resulta em ganhos significativos de desempenho, especialmente para análises em grande escala e consultas complexas.
O Delta Engine oferece suporte a recursos avançados, como visualizações materializadas. É importante observar que as visualizações materializadas são diferentes das tabelas de streaming. Enquanto as visualizações materializadas são otimizadas para consultas repetidas e previsíveis, as tabelas de streaming são projetadas para ingestão e processamento de dados contínuos e em tempo real.
O Dynamic File Pruning (DFP) é uma técnica de otimização durante as consultas de junção. Ele permite que o Spark filtre os arquivos desnecessários do lado da leitura com base nas chaves de junção. Em vez de fazer a varredura de todo o lado direito de uma união, o DFP limita a varredura apenas aos blocos de arquivos relevantes. Essa técnica melhora o desempenho de conjuntos de dados particionados ou ao filtrar por cliente, região ou produto.
Na prática, vi o DFP fazer uma diferença significativa no local em que tabelas grandes e particionadas são unidas, como pipelines de ETL ou painéis de análise. Isso resulta em um processamento mais rápido e eficiente e em custos de computação mais baixos.
Abaixo estão as principais práticas recomendadas que aprendi ao criar e dimensionar fluxos de trabalho Delta:
Gerenciamento do tamanho do arquivo: Mantenha os arquivos de dados entre 100 e 300 MB usando a compactação automática ou OPTIMIZE para reduzir os problemas de arquivos pequenos e melhorar o desempenho da varredura.
Configuração de viagem no tempo: Use dataRetentionDuration ou VACUUM para definir períodos de retenção razoáveis que equilibrem a flexibilidade de reversão com a eficiência do armazenamento.
Controles de simultaneidade: Use níveis de isolamento e controle de simultaneidade otimista para gerenciar gravações de vários usuários e reduzir conflitos de confirmação.
Otimização de custos: Use Photon, Delta Caching e Z-Ordering para minimizar os custos de computação, especialmente para consultas repetidas.
Monitore o desempenho: Use os relatórios Query Profile, Lakehouse Monitoring e Workload Utilization para identificar consultas lentas e otimizar o uso de recursos.
Particionamento e layout de dados: Para minimizar as varreduras de dados, particione as tabelas somente em colunas de baixa cardinalidade, como datas ou locais. Use a ordem Z nas partições para campos de alta cardinalidade para acelerar ainda mais as consultas. Evite o excesso de particionamento, que pode resultar em arquivos pequenos e desempenho prejudicado.
Falei muito sobre o motivo das tabelas Delta, mas também é útil que você compare com as estruturas de data lake mais tradicionais e com outros tipos de tabelas do próprio Databricks:
|
Recurso |
Tabelas Delta |
Tabelas Hive |
Tabelas Delta Live (DLT) |
Tabelas de streaming |
Visualizações materializadas |
|
Transações ACID |
Suporte total |
Limitado/Nenhum |
Construído em Delta |
via Delta |
no topo da Delta |
|
Aplicação do esquema |
Aplicado na gravação |
Aplicação manual |
Declarativo + gerenciado |
Com compatibilidade de streaming |
Você segue a base da tabela Delta |
|
Viagem no tempo |
Incorporado |
Não suportado |
Herdado de Delta |
(leituras com reconhecimento de versão) |
Dependente de atualização |
|
Suporte a streaming |
Lote unificado/streaming |
Manuseio separado |
Gerenciado automaticamente |
Suporte nativo |
Somente atualização periódica |
|
Escalabilidade de metadados |
Balanças com tabelas grandes |
Mais lento com partições |
Otimizado via DLT |
Com programa de registro |
Herança de Delta |
|
Gerenciamento operacional |
Com OPTIMIZE, VACUUM, etc. |
Manual e frágil |
Gerenciado por pipelines de DLT |
Acionadores configuráveis |
Opções de atualização e cache |
Agora, vamos examinar os casos de uso comuns em que as tabelas delta são aplicadas para obter valor.
O Delta Tables oferece uma solução confiável e flexível para o gerenciamento de dados no Databricks, com suporte para análises em tempo real e em lote. O ecossistema Delta Lake continua a evoluir, com novos recursos que facilitam ainda mais o compartilhamento de dados, a governança e o desempenho. Recomendo que você siga as práticas recomendadas de layout e automação de dados e mantenha-se atualizado sobre os novos recursos.
Se você deseja aprimorar suas habilidades em data warehouse, recomendo que faça nosso curso Associate Data Engineer in SQL para aprender a projetar e trabalhar com bancos de dados. Enquanto você se prepara para as entrevistas, confira nossas 20 principais perguntas para entrevistas da Databricks para se destacarentre outros profissionais de dados.
Aprenda a usar o Databricks com a DataCamp
Curso
Curso
Curso
blog
Wendy Gittleson
15 min
blog
Mike Shakhomirov
11 min
Tutorial
Zoumana Keita
Tutorial
Joleen Bothma
Tutorial
Natassha Selvaraj