
Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
100.3K
Docker te permite crear entornos consistentes, portátiles y aislados, lo que lo hace esencial para las LLMOps (Large Language Models Operations). Al encapsular varias aplicaciones LLM y sus dependencias en contenedores, Docker simplifica el despliegue, garantiza la compatibilidad entre sistemas y agiliza las pruebas.
En este tutorial, aprenderás a crear una aplicación chatbot de "preguntas y respuestas sobre documentos" y a desplegarla en la nube utilizando Docker. Utilizaremos Gradio para la interfaz de usuario, LlamaIndex para la orquestación, LlamaParse para analizar documentos, Mixedbread AI para las incrustaciones, Groq para acceder a grandes modelos lingüísticos, Docker para empaquetar la aplicación y sus dependencias, y Hugging Face Spaces para desplegar la aplicación en la nube.
Este tutorial está diseñado para ser sencillo, permitiendo que cualquier persona con un conocimiento limitado de cómo funcionan las aplicaciones de IA pueda construirlo gratis.
Hay dos enfoques principales para desarrollar e implantar aplicaciones de IA:
Ambos enfoques tienen ventajas e inconvenientes. En nuestro caso, hemos optado por el segundo enfoque, integrando múltiples servicios de IA. Esto nos permite construir una aplicación de IA rápida que sólo tarda unos segundos en construirse y desplegarse. Nuestro principal objetivo es reducir el tamaño de la imagen Docker, lo que puede lograrse eficazmente integrando múltiples servicios de IA.
Consulta el tutorial Local AI with Docker, n8n, Qdrant, and Ollama para crear una aplicación LLM utilizando herramientas y marcos de trabajo de código abierto para mejorar la privacidad.
Construiremos un chatbot de preguntas y respuestas de uso general que permita a los usuarios subir documentos y chatear con ellos en tiempo real. Es bastante similar al NotebookLM de Google.
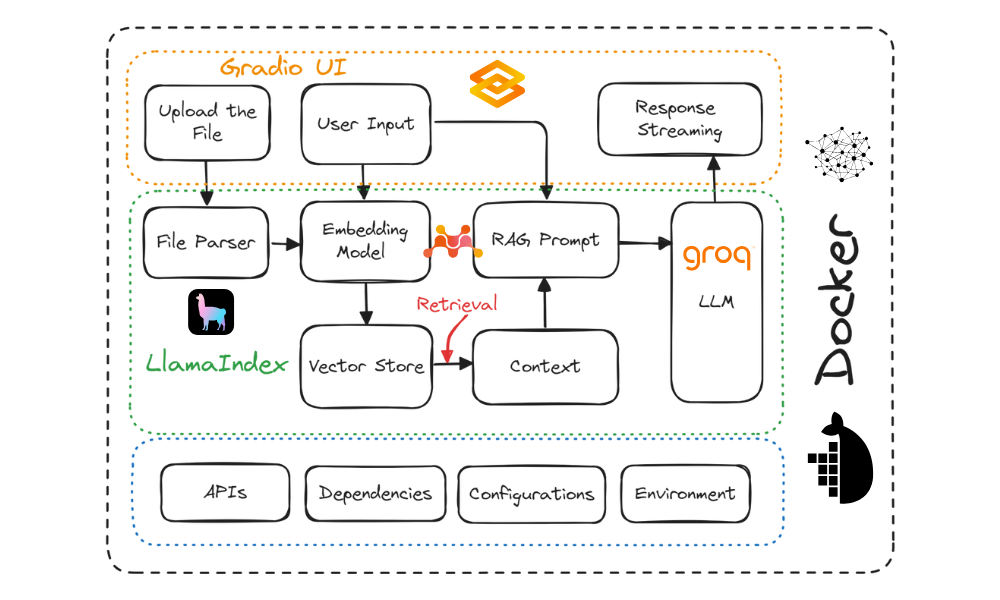
Diagrama del proyecto. Imagen del autor
Éstas son las herramientas que utilizaremos en este proyecto:
Si eres nuevo en el campo de los LLM, considera la posibilidad de realizar el curso Conceptos de los Modelos de Grandes Lenguajes (LLM) para aprender las terminologías básicas, las metodologías, las consideraciones éticas y las últimas investigaciones.
Aprende a trabajar con LLMs en Python directamente en tu navegador

Antes de construir la aplicación LLM, tenemos que descargar e instalar Docker desde el sitio web oficial.
.env. Utilizaremos este archivo para almacenar las claves API de LlamaCloud, MixedBread AI y Groq Cloud.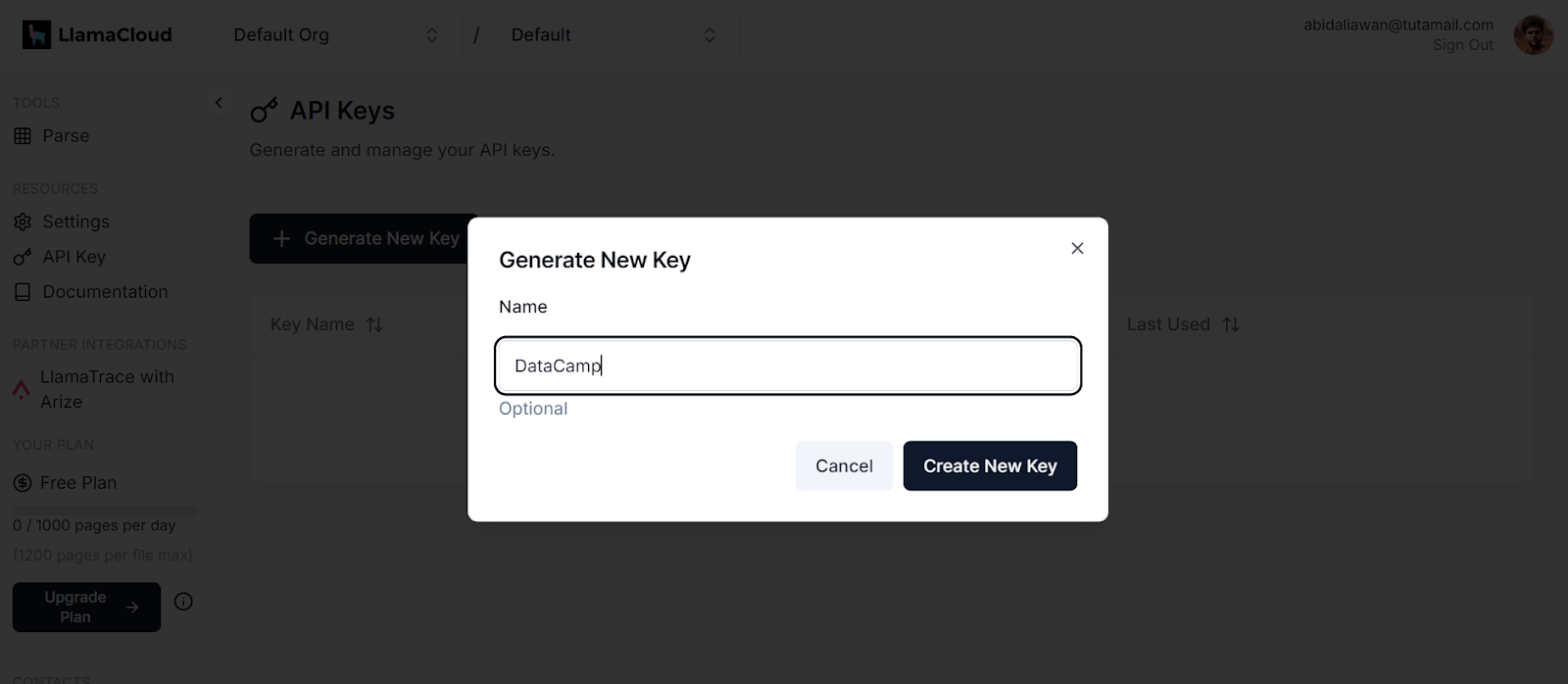
Generar una nueva clave en LlamaCloud. Fuente de la imagen: LlamaCloud
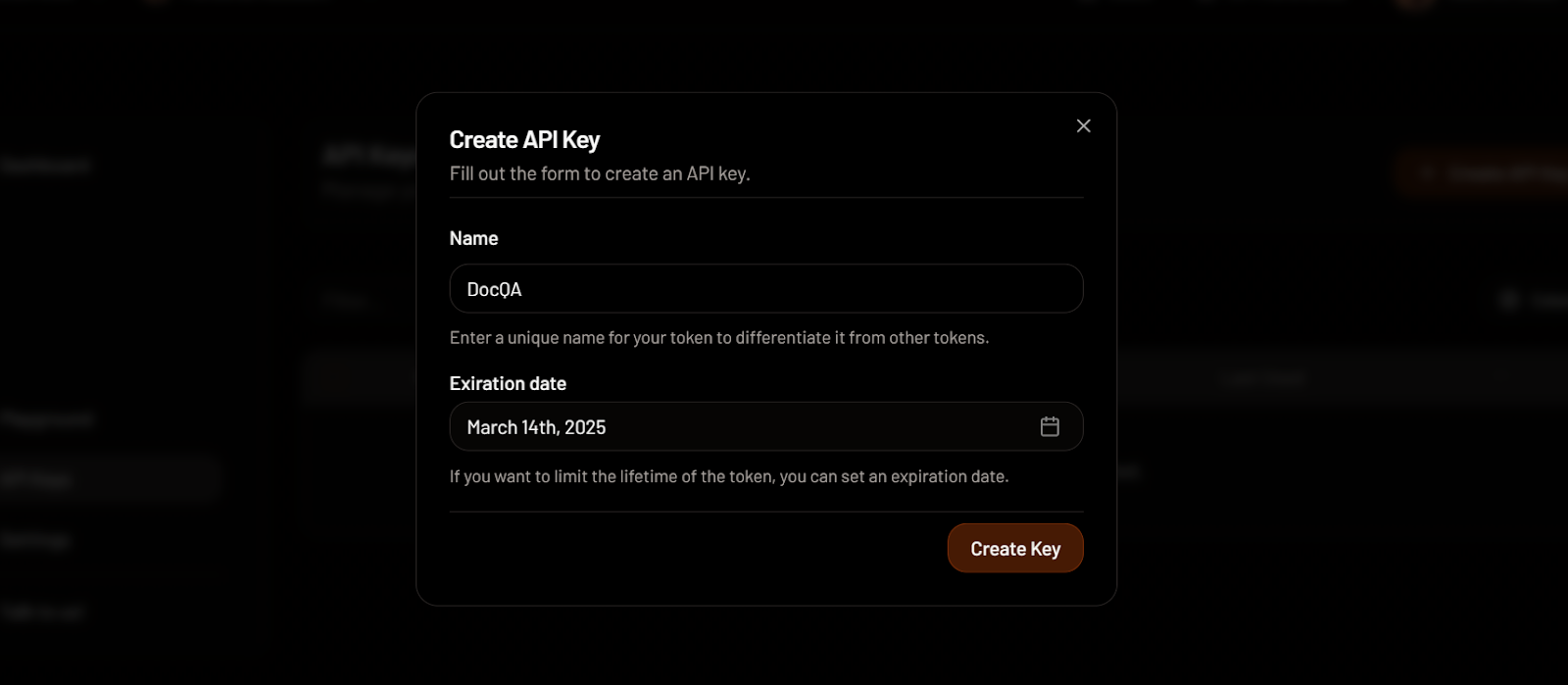
Crear una clave API en MixedBread. Fuente de la imagen: MixedBread
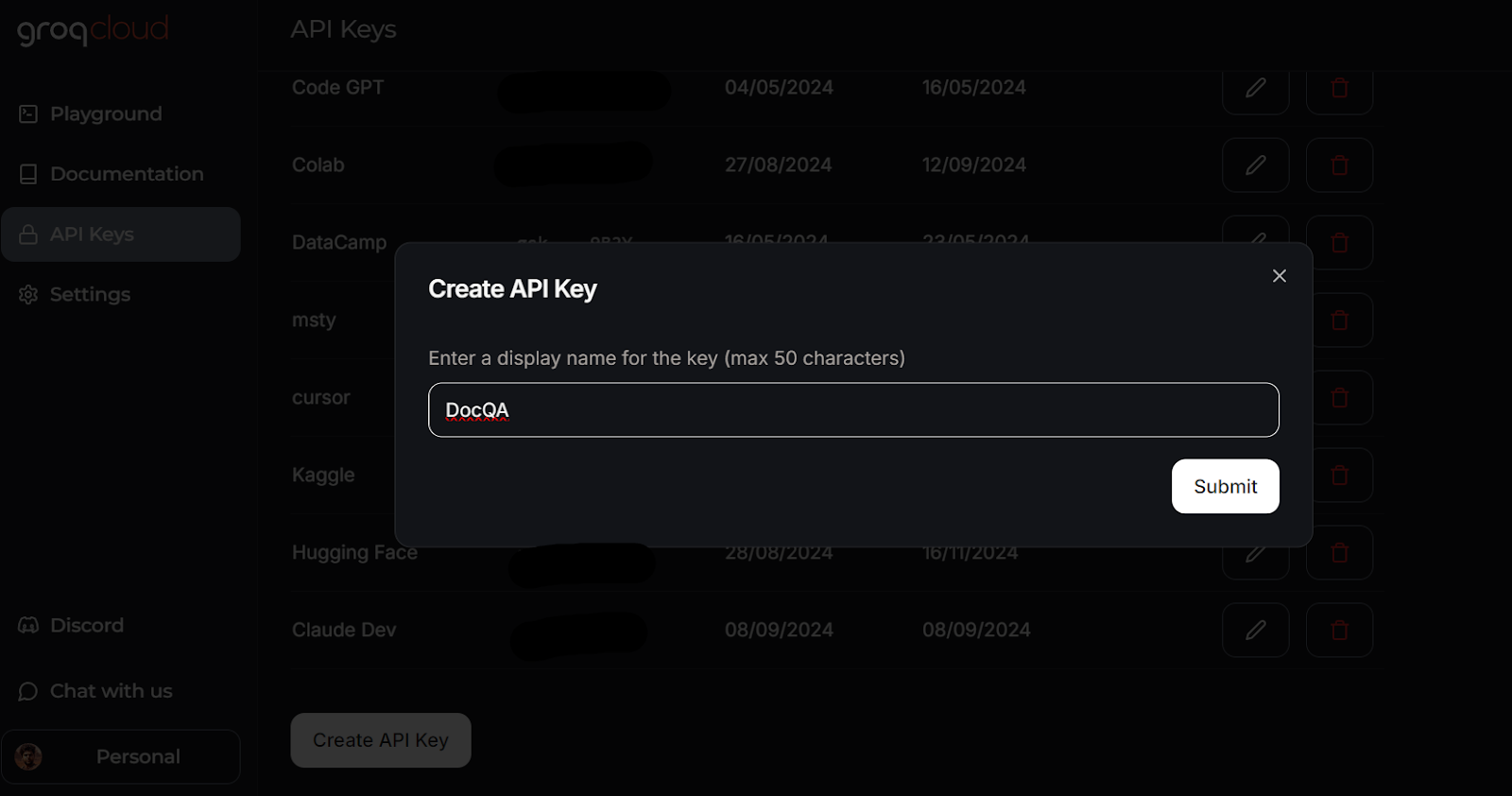
Crear una clave API en GroqCloud. Fuente de la imagen: GroqCloud
Aprende todo sobre GroqCloud leyendo el artículo sobre el motor de inferencia Groq LPU. Conocerás la API de Groq y sus funciones con ejemplos de código. Además, aprende a crear aplicaciones de IA conscientes del contexto utilizando la API Groq y LlamaIndex.
Este es el aspecto que debe tener tu archivo .env:
LLAMA_CLOUD_API_KEY=llx-XXXXXX
GROQ_API_KEY=gsk_XXXXXXX
MXBAI_API_KEY=emb_XXXXXXRecuerda añadir el archivo .env a tu archivo .gitignore para evitar exponer accidentalmente tus claves API al público.
Ahora crearemos un script en Python llamado app.py y añadiremos los componentes de la interfaz de usuario, a la vez que integramos todos los servicios de IA utilizando LlamaParser para desarrollar la tubería de Recuperación-Generación Aumentada (RAG) con LlamaIndex.
El script app.py hará lo siguiente:
.env.mixedbread-ai/mxbai-embed-large-v1.llama-3.1-70b-versatile.A continuación, implementa las siguientes funciones de Python:
load_files(): Esta función cargará los archivos, los analizará utilizando LlamaParser, los convertirá en incrustaciones y los almacenará en el almacén de vectores. Se incluirá un tratamiento de excepciones para gestionar los casos en los que se suban archivos que no sean archivos o formatos de archivo no compatibles.respond(): Esta función tomará la entrada del usuario, recuperará el contenido del almacén vectorial y lo utilizará para generar una respuesta utilizando el modelo Groq. La generación de la respuesta será en formato streaming, y se incluirá el manejo de excepciones si no se han subido archivos.Por último, construirá los componentes de la interfaz de usuario, incluyendo un cargador de archivos, botones, un cuadro de chat y la interfaz general del chat.
Aprende más sobre el marco LlamaIndex siguiendo el tutorial LlamaIndex más directo.
Aquí tienes el guión app.py:
import os
import gradio as gr
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.embeddings.mixedbreadai import MixedbreadAIEmbedding
from llama_index.llms.groq import Groq
from llama_parse import LlamaParse
# API keys
llama_cloud_key = os.environ.get("LLAMA_CLOUD_API_KEY")
groq_key = os.environ.get("GROQ_API_KEY")
mxbai_key = os.environ.get("MXBAI_API_KEY")
if not (llama_cloud_key and groq_key and mxbai_key):
raise ValueError(
"API Keys not found! Ensure they are passed to the Docker container."
)
# models name
llm_model_name = "llama-3.1-70b-versatile"
embed_model_name = "mixedbread-ai/mxbai-embed-large-v1"
# Initialize the parser
parser = LlamaParse(api_key=llama_cloud_key, result_type="markdown")
# Define file extractor with various common extensions
file_extractor = {
".pdf": parser,
".docx": parser,
".doc": parser,
".txt": parser,
".csv": parser,
".xlsx": parser,
".pptx": parser,
".html": parser,
".jpg": parser,
".jpeg": parser,
".png": parser,
".webp": parser,
".svg": parser,
}
# Initialize the embedding model
embed_model = MixedbreadAIEmbedding(api_key=mxbai_key, model_name=embed_model_name)
# Initialize the LLM
llm = Groq(model="llama-3.1-70b-versatile", api_key=groq_key)
# File processing function
def load_files(file_path: str):
global vector_index
if not file_path:
return "No file path provided. Please upload a file."
valid_extensions = ', '.join(file_extractor.keys())
if not any(file_path.endswith(ext) for ext in file_extractor):
return f"The parser can only parse the following file types: {valid_extensions}"
document = SimpleDirectoryReader(input_files=[file_path], file_extractor=file_extractor).load_data()
vector_index = VectorStoreIndex.from_documents(document, embed_model=embed_model)
print(f"Parsing completed for: {file_path}")
filename = os.path.basename(file_path)
return f"Ready to provide responses based on: {filename}"
# Respond function
def respond(message, history):
try:
# Use the preloaded LLM
query_engine = vector_index.as_query_engine(streaming=True, llm=llm)
streaming_response = query_engine.query(message)
partial_text = ""
for new_text in streaming_response.response_gen:
partial_text += new_text
# Yield an empty string to cleanup the message textbox and the updated conversation history
yield partial_text
except (AttributeError, NameError):
print("An error occurred while processing your request.")
yield "Please upload the file to begin chat."
# Clear function
def clear_state():
global vector_index
vector_index = None
return [None, None, None]
# UI Setup
with gr.Blocks(
theme=gr.themes.Default(
primary_hue="green",
secondary_hue="blue",
font=[gr.themes.GoogleFont("Poppins")],
),
css="footer {visibility: hidden}",
) as demo:
gr.Markdown("# DataCamp Doc Q&A 🤖📃")
with gr.Row():
with gr.Column(scale=1):
file_input = gr.File(
file_count="single", type="filepath", label="Upload Document"
)
with gr.Row():
btn = gr.Button("Submit", variant="primary")
clear = gr.Button("Clear")
output = gr.Textbox(label="Status")
with gr.Column(scale=3):
chatbot = gr.ChatInterface(
fn=respond,
chatbot=gr.Chatbot(height=300),
theme="soft",
show_progress="full",
textbox=gr.Textbox(
placeholder="Ask questions about the uploaded document!",
container=False,
),
)
# Set up Gradio interactions
btn.click(fn=load_files, inputs=file_input, outputs=output)
clear.click(
fn=clear_state, # Use the clear_state function
outputs=[file_input, output],
)
# Launch the demo
if __name__ == "__main__":
demo.launch()$ python app.py Salida:

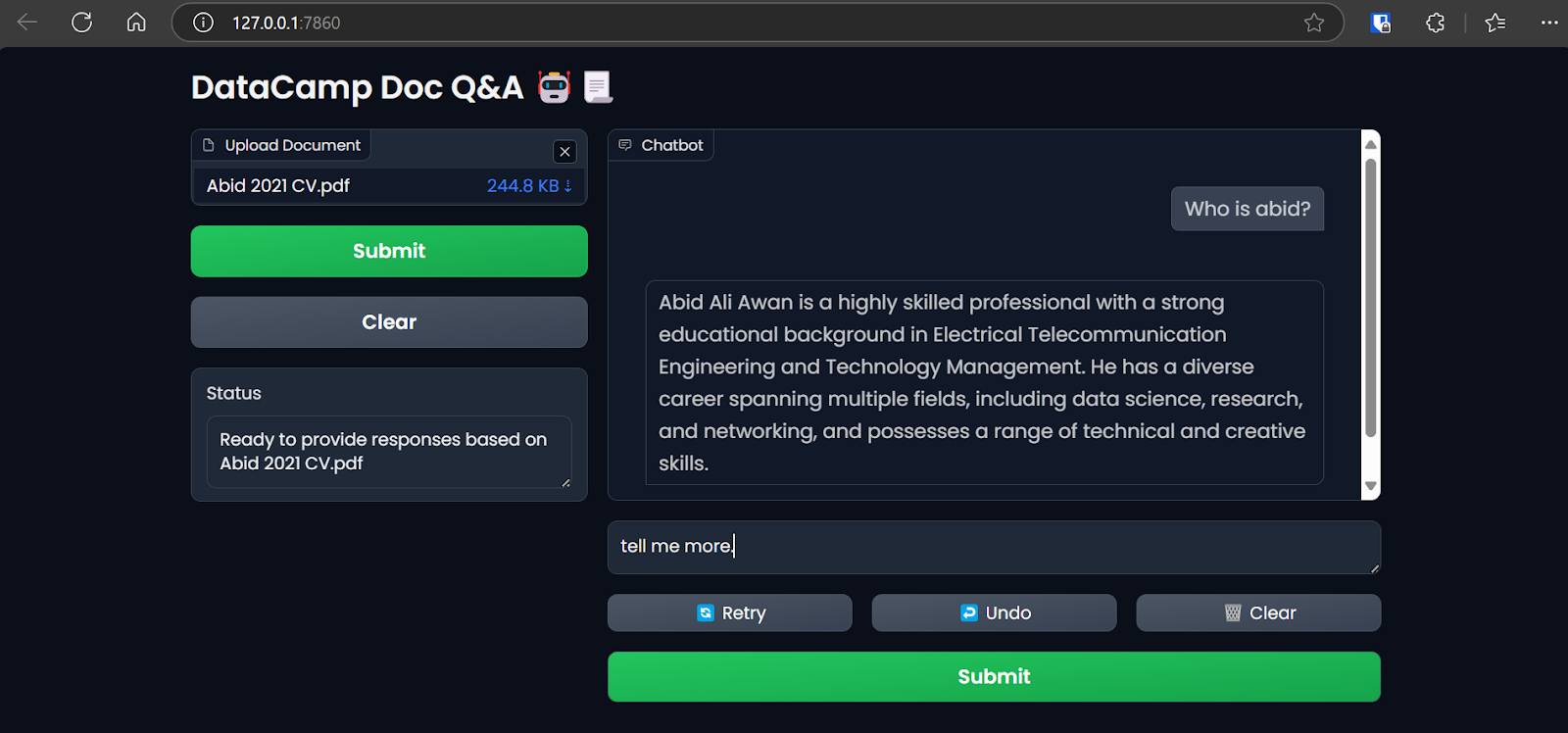
Acceder a la app Gradio en el navegador. Imagen del autor
Utilizamos LlamaIndex para desplegar y construir nuestra aplicación LLM para este tutorial. Puedes crear una aplicación similar con LangChain siguiendo el curso breve Desarrollo de aplicaciones LLM con LangChain.
Dockerfile para empaquetar el script de la aplicación, las dependencias de Python y las configuraciones del servidor mientras se inicializa el servidor Gradio. El Dockerfile realizará las siguientes tareas:
requirements.txt en el directorio /app. Este archivo contiene los nombres de todos los paquetes de Python necesarios.requirements.txt.app.py en el directorio /app.Este es el aspecto que debe tener Dockerfile:
# Dockerfile
# Use the official Python image with the desired version
FROM python:3.9-slim
# Set the working directory inside the container
WORKDIR /app
# Copy the requirements file to the working directory
COPY requirements.txt /app
# Install the dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code to the working directory
COPY app.py /app
# Expose the port that Gradio will run on (default is 7860)
EXPOSE 7860
ENV GRADIO_SERVER_NAME="0.0.0.0"
# Command to run your application
CMD ["python", "app.py"]requirements.txt. Añádelo también a tu proyecto:gradio
llama-index-embeddings-mixedbreadai
llama-index-llms-groq
llama-indexdocqa. Utilizará la dirección Dockerfile para crear la imagen Docker.$ docker build -t docqa . Podemos ver los registros de los procesos que tienen lugar mientras se construye la imagen Docker:
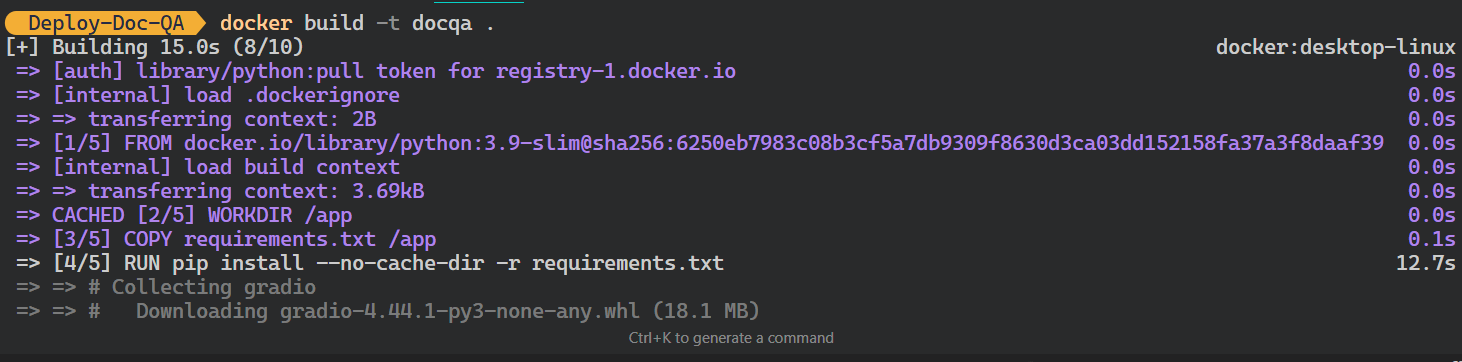
Construir la imagen Docker de LLM. Imagen del autor
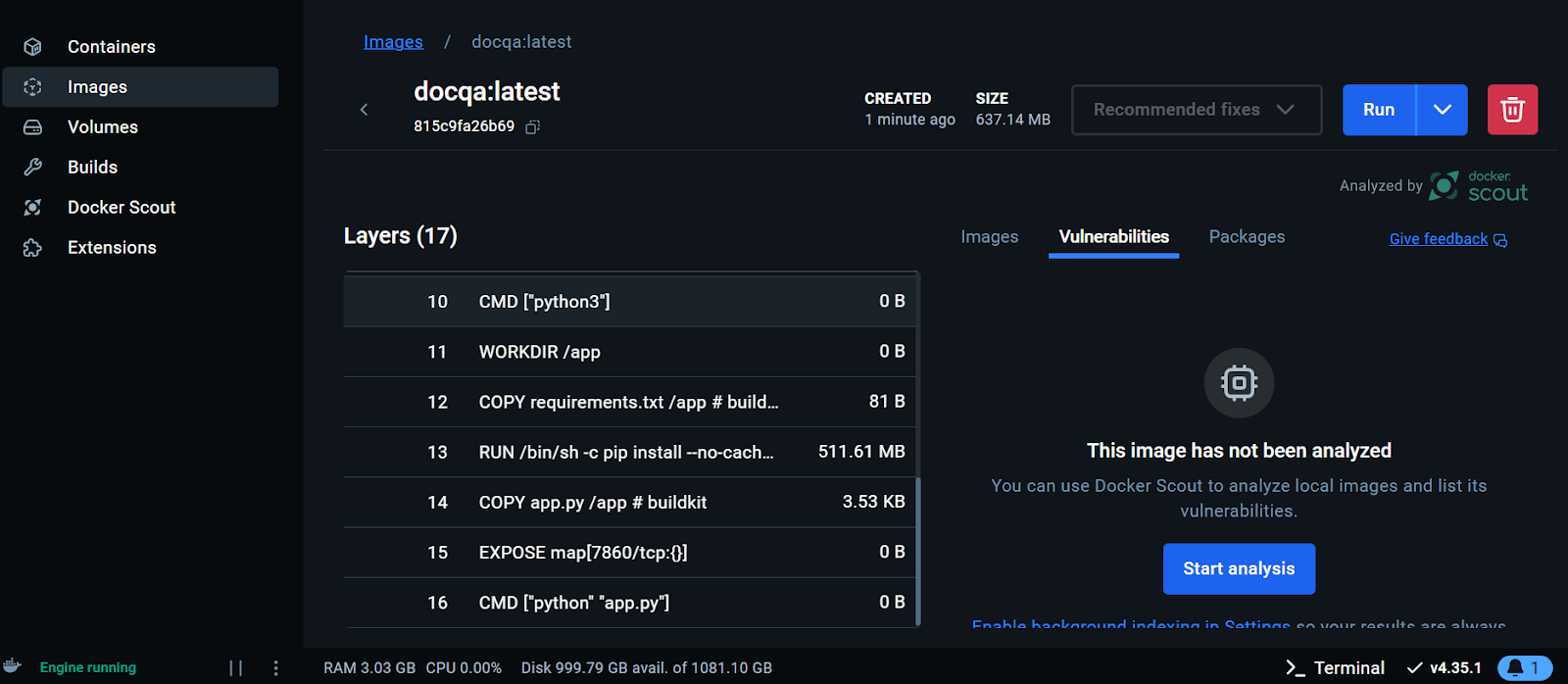
Visualización de la imagen Docker en el Escritorio Docker. Imagen del autor
Ahora ejecutaremos el contenedor Docker localmente utilizando la imagen. Le proporcionaremos el número de puerto, un archivo .env para configurar las variables de entorno, el nombre del contenedor Docker y la etiqueta de la imagen Docker.
$ docker run -p 7860:7860 --env-file .env --name docqa-container docqaUna vez que el contenedor empiece a funcionar, puedes acceder a la app Gradio pegando la URL, en este caso, http://0.0.0.1:7860/ en el navegador.
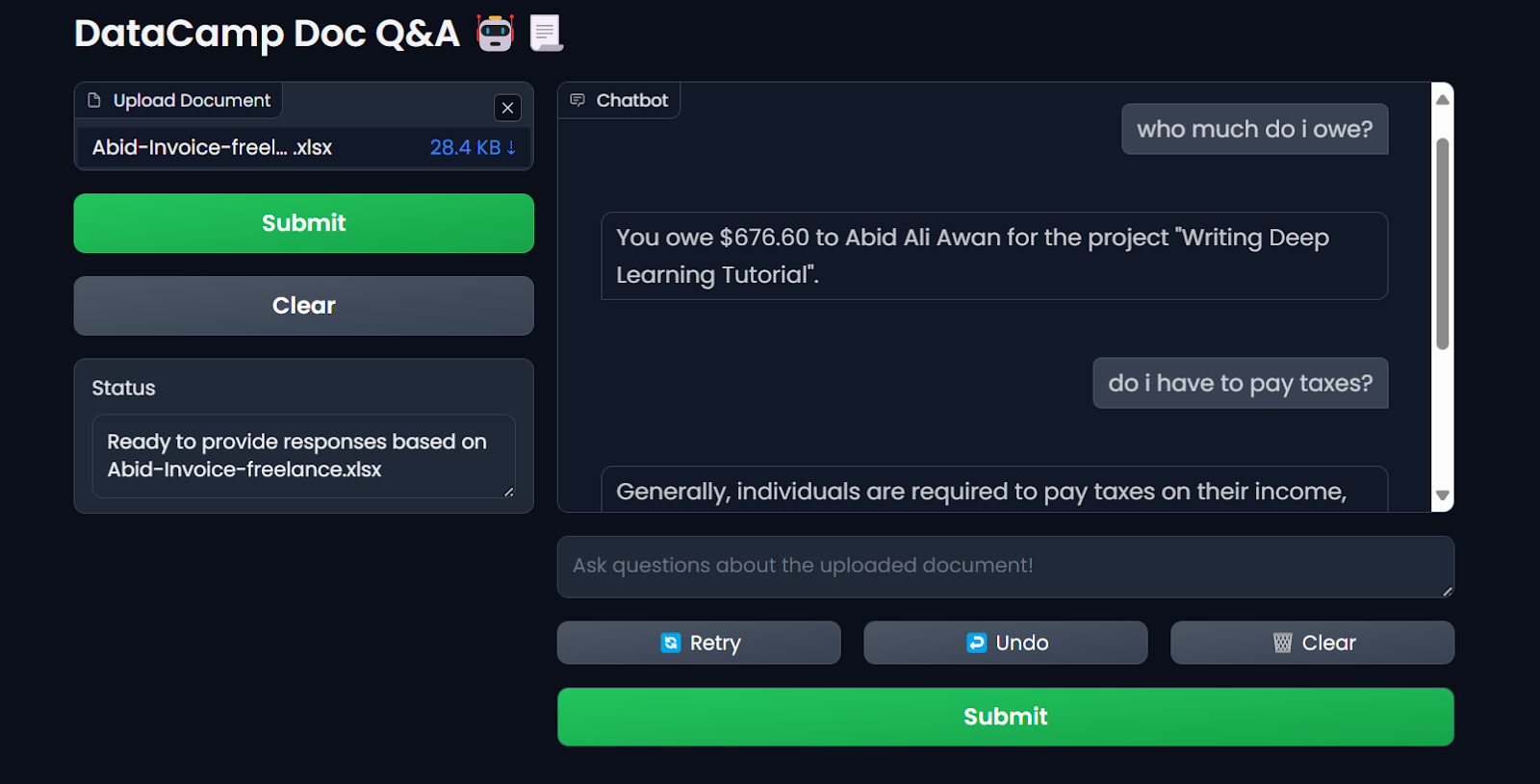
Probar la aplicación LLM del contenedor Docker. Imagen del autor
$ docker psSalida:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ff2a11da13d7 docqa "python app.py" 17 seconds ago Up 16 seconds 0.0.0.0:7860->7860/tcp docqa-containerstop:$ docker stop docqa-container rm:$ docker rm docqa-container Una vez que tenemos una imagen Docker, podemos desplegar nuestra aplicación LLM en cualquier lugar: GCP, AWS, Azure o cualquier servidor en la nube que admita el despliegue de Docker.
Para simplificar las cosas a los principiantes, desplegaremos la aplicación utilizando Docker en la Nube de Caras Abrazadas (Spaces).
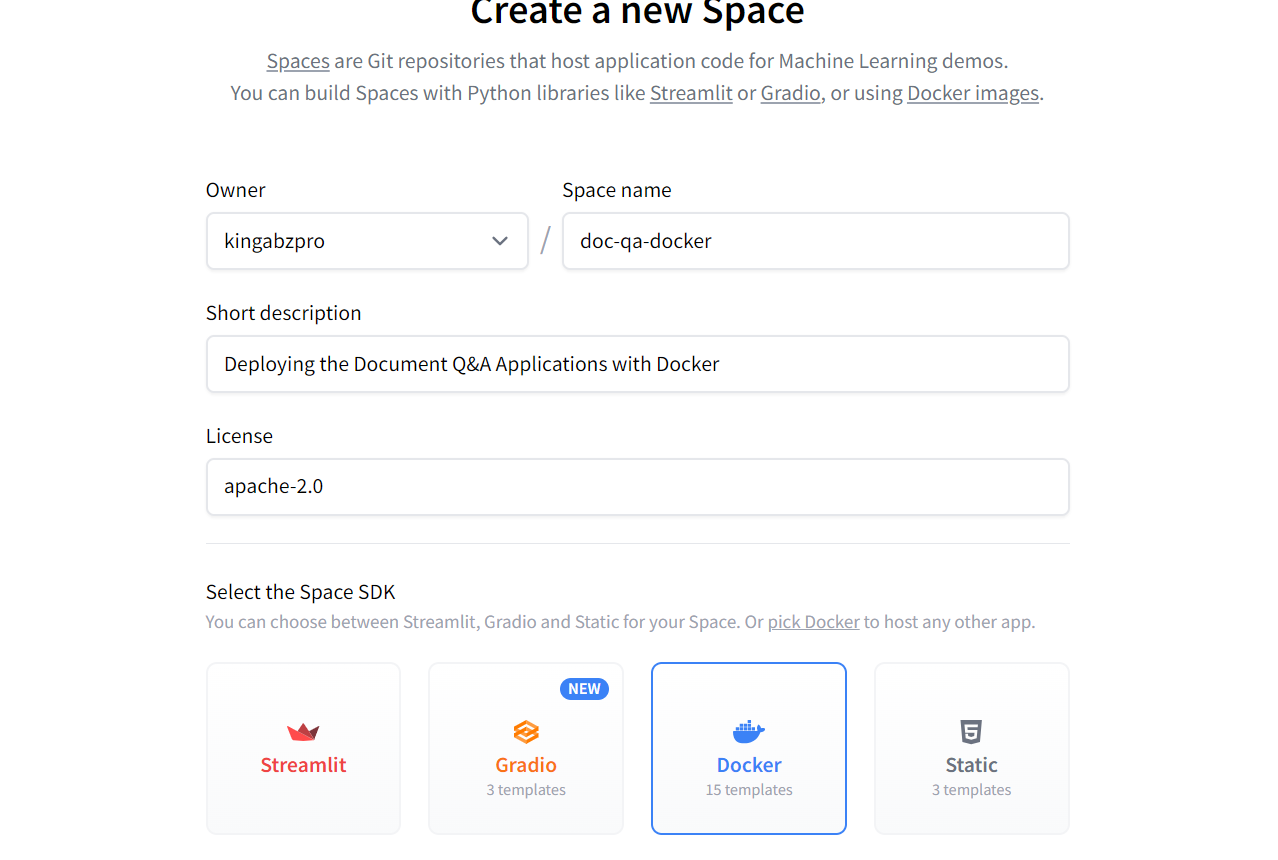
Creación del nuevo Espacio Cara Abrazada utilizando Docker. Fuente de la imagen: Cara de abrazo
Una vez creado el repositorio de Space, recibirás instrucciones sobre cómo clonarlo y añadir los archivos necesarios.
$ git clone https://huggingface.co/spaces/kingabzpro/doc-qa-dockerEste es el aspecto que debe tener el directorio de tu proyecto con todos los archivos. Asegúrate siempre de no empujar el archivo .env, así que añádelo a .gitignore.
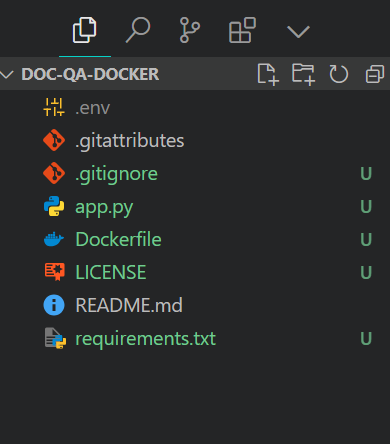
Estructura de los archivos del proyecto. Imagen del autor
$ git add .
$ git commit -m "Deploying the App"
$ git pushSalida:
Enumerating objects: 8, done.
Counting objects: 100% (8/8), done.
Delta compression using up to 16 threads
Compressing objects: 100% (7/7), done.
Writing objects: 100% (7/7), 7.60 KiB | 7.60 MiB/s, done.
Total 7 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
To https://huggingface.co/spaces/kingabzpro/doc-qa-docker
afb20ad..5ca6388 main -> main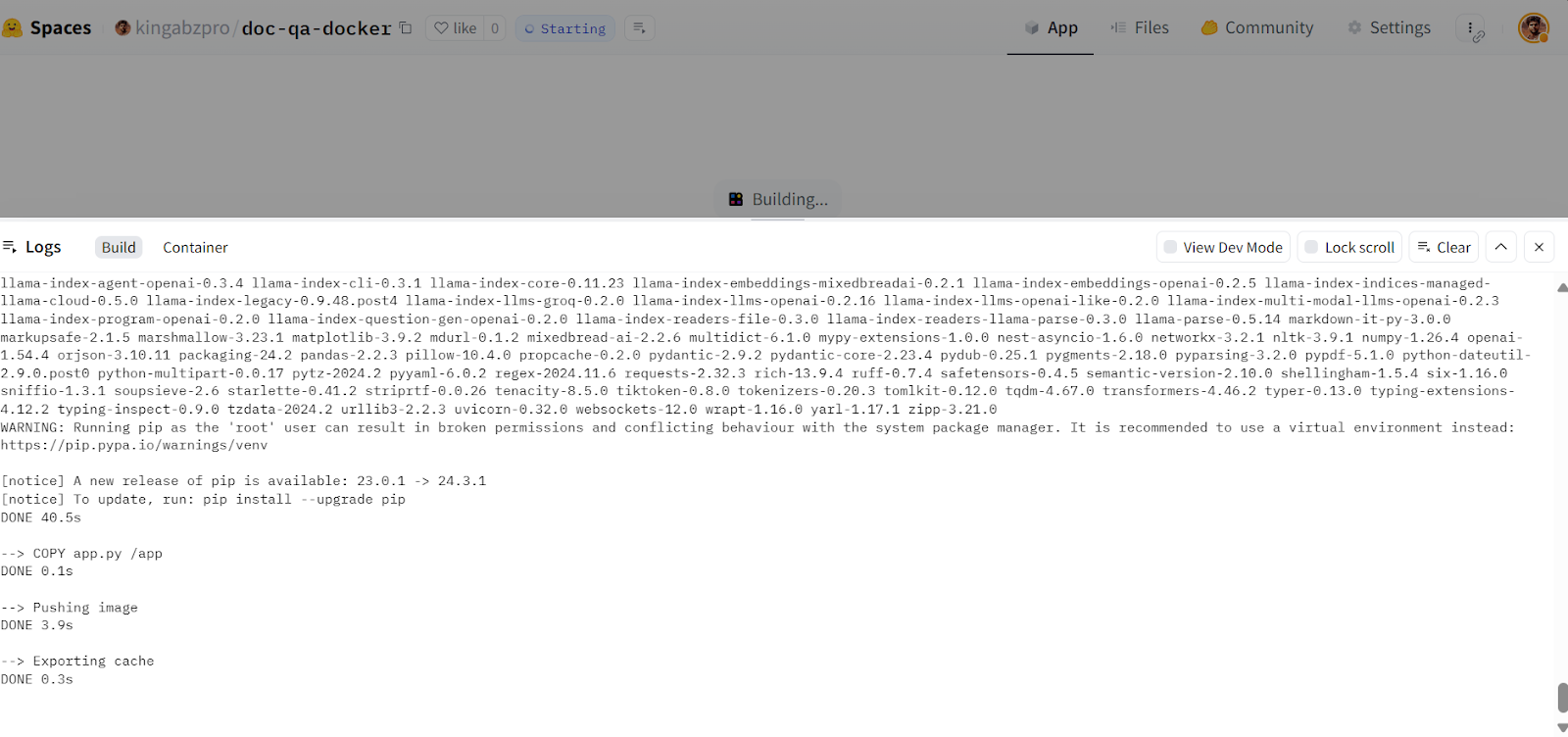
Construir la imagen Docker en la Nube de Cara Abrazada. Fuente de la imagen: Doc Qa Docker
Si aparece un error como el siguiente, no te preocupes. Se debe a que faltan variables de entorno. Todo lo que tenemos que hacer es establecer esas variables en el Espacio Cara Abrazada.

Error de ejecución en la aplicación desplegada. Fuente de la imagen: Doc Qa Docker
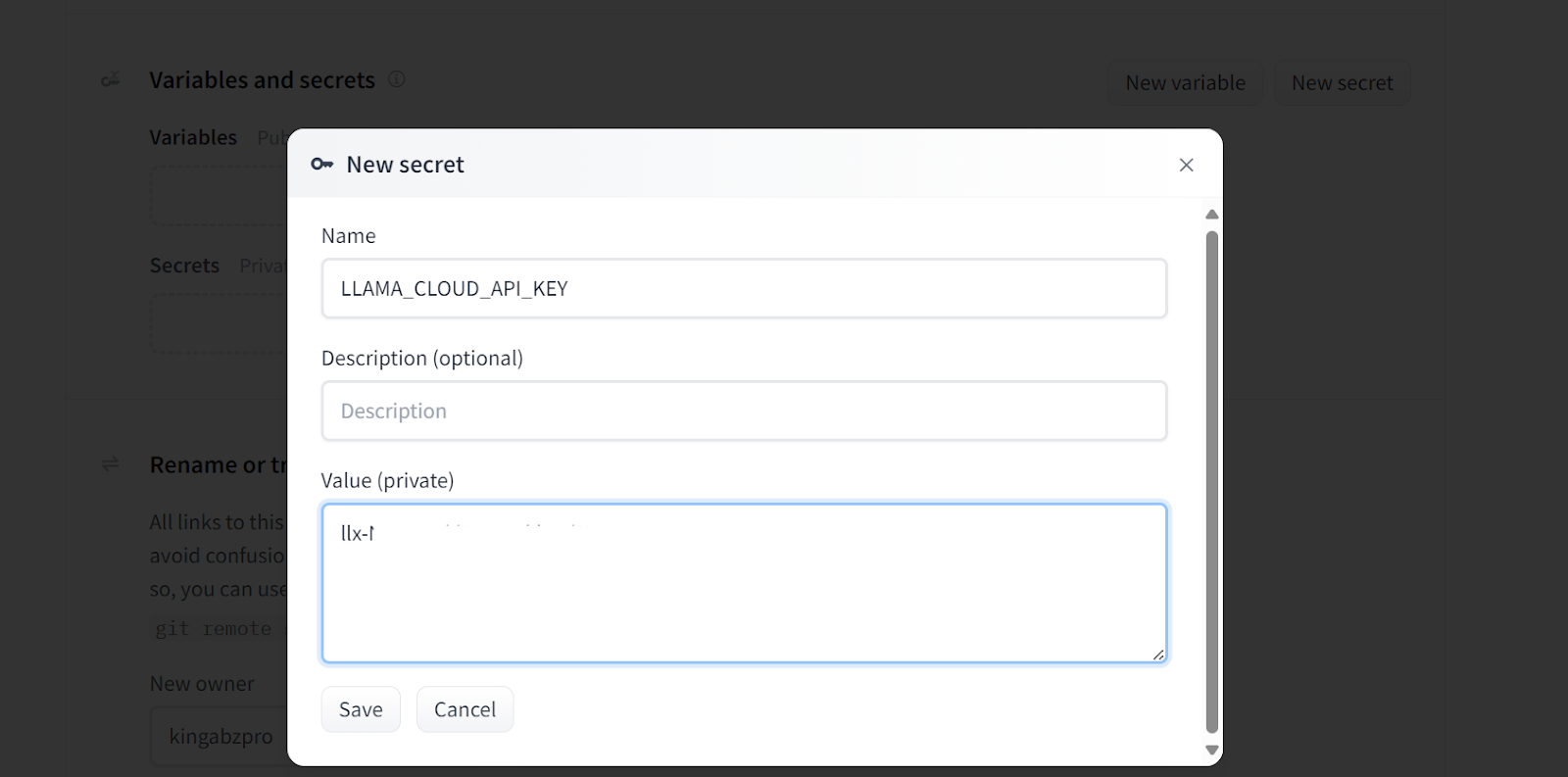
Añadir secretos a la aplicación desplegada. Fuente de la imagen: Doc Qa Configuración de Docker.
Este es el aspecto que deben tener tus secretos después de añadir todas las claves API necesarias como variables de entorno:
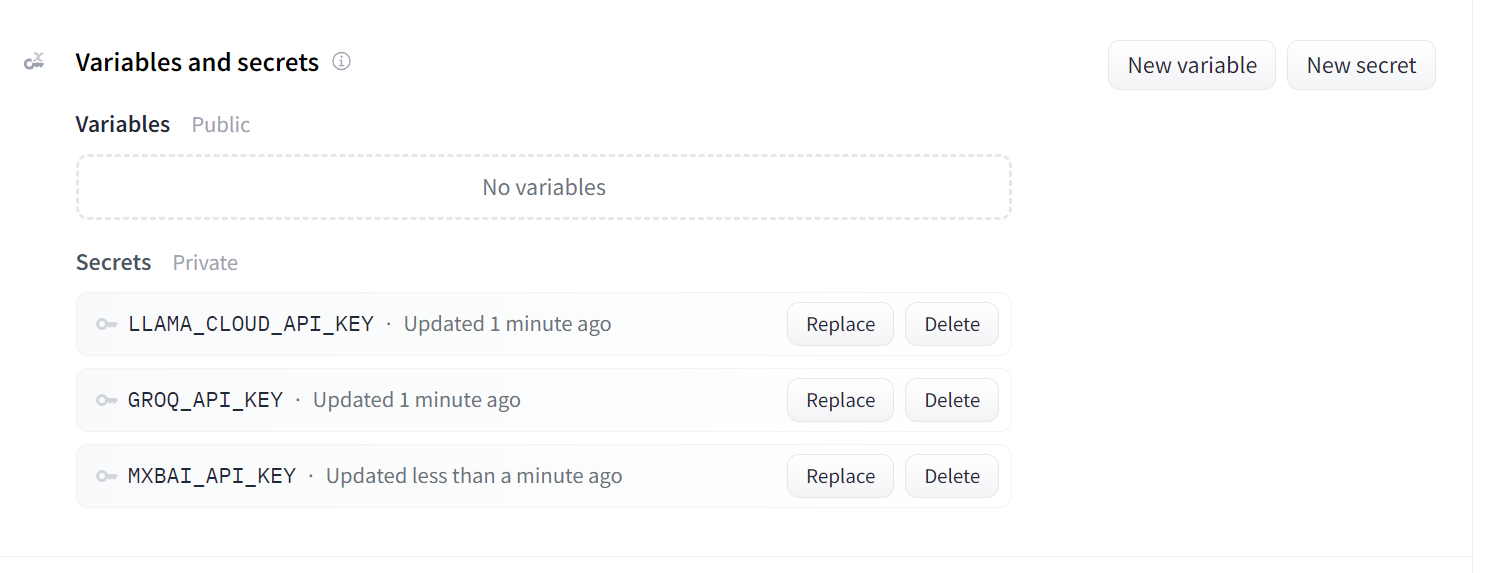
Secretos para la aplicación desplegada. Fuente de la imagen: Doc Qa Configuración de Docker.
Una vez que hayas configurado los secretos, la aplicación se reiniciará automáticamente, y deberías ver la aplicación en funcionamiento. ¡Úsalo y disfruta de tu aplicación de preguntas y respuestas sobre documentos en la nube!
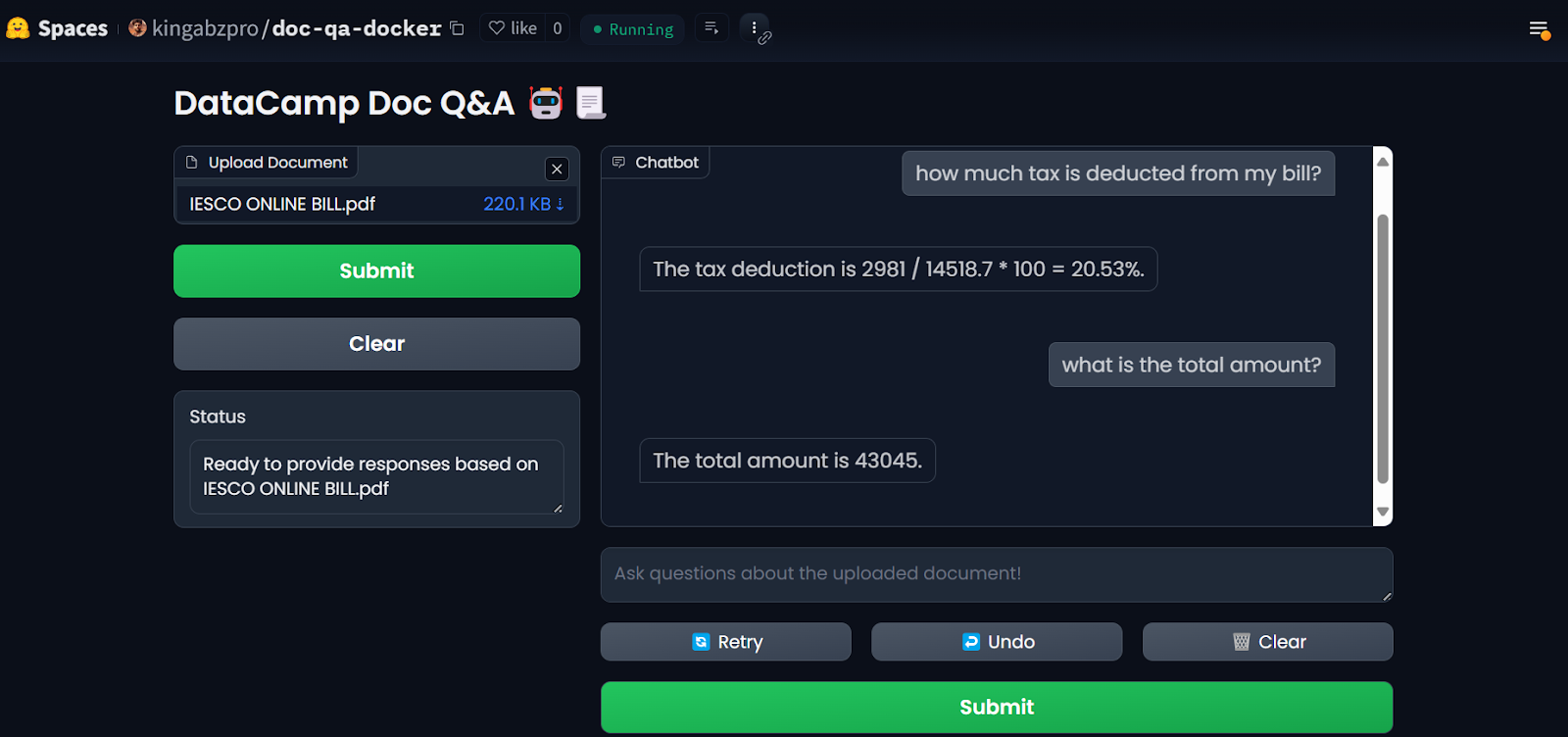
Aplicación LLM en los Espacios Cara Abrazada. Fuente de la imagene: Doc Qa Docker
Para reproducir los resultados, puedes encontrar todos los archivos y configuraciones en el repositorio de GitHubsitory: kingabzpro/Deploy-Doc-QA.
Utilizar servicios de IA tiene ventajas: No tienes que desplegar ni gestionar ningún servicio, obtienes un alto rendimiento y un panel de control con los registros.
Tu panel de control de LlamaCloud registra todos los documentos que se han analizado. Puedes consultar el historial o solicitar y comparar el uso.
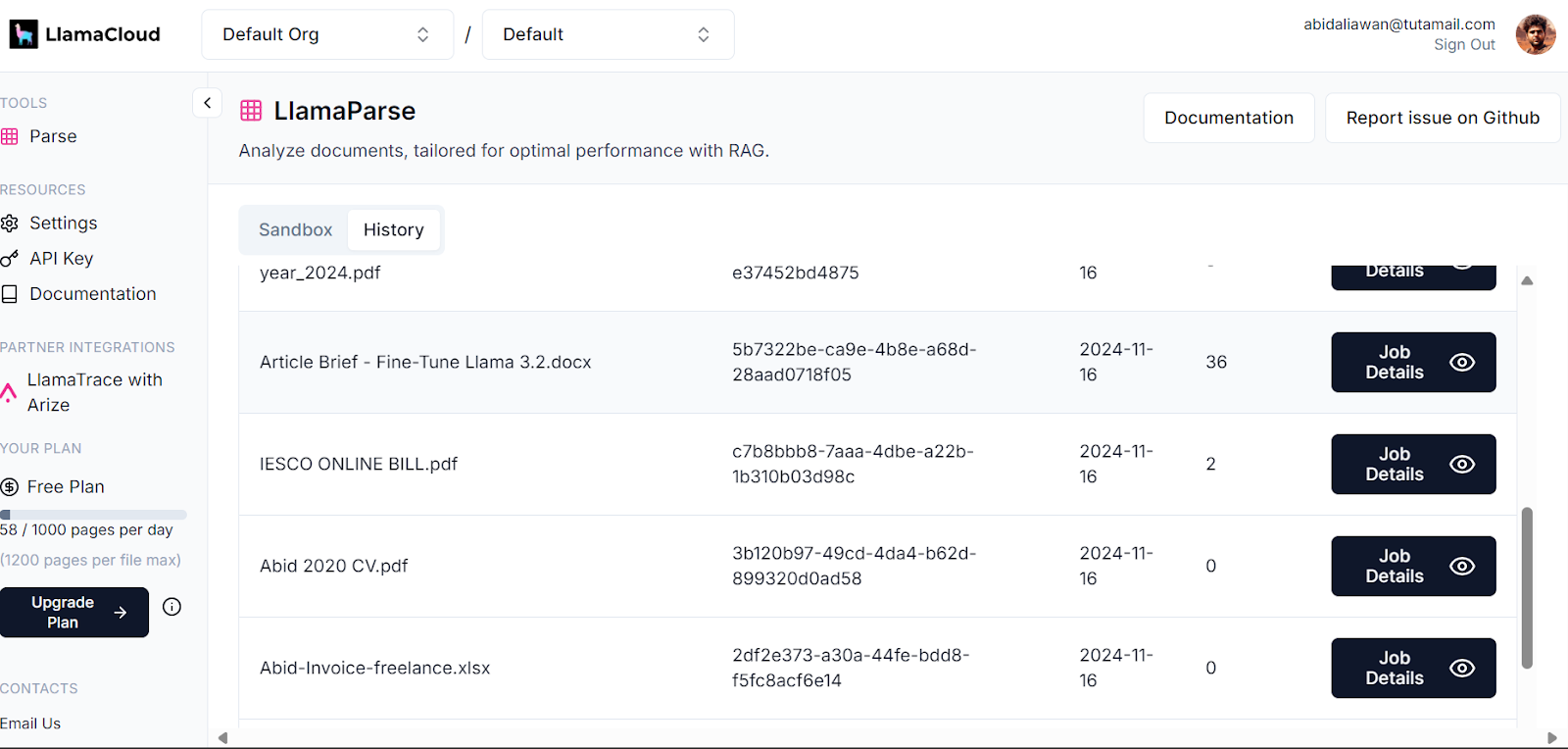
Salpicadero de la Nube Llama. Imagen source: LlamaCloud
Del mismo modo, también puedes comprobar el número de tokens que hemos utilizado para el modelo de incrustación y el número de solicitudes generadas.
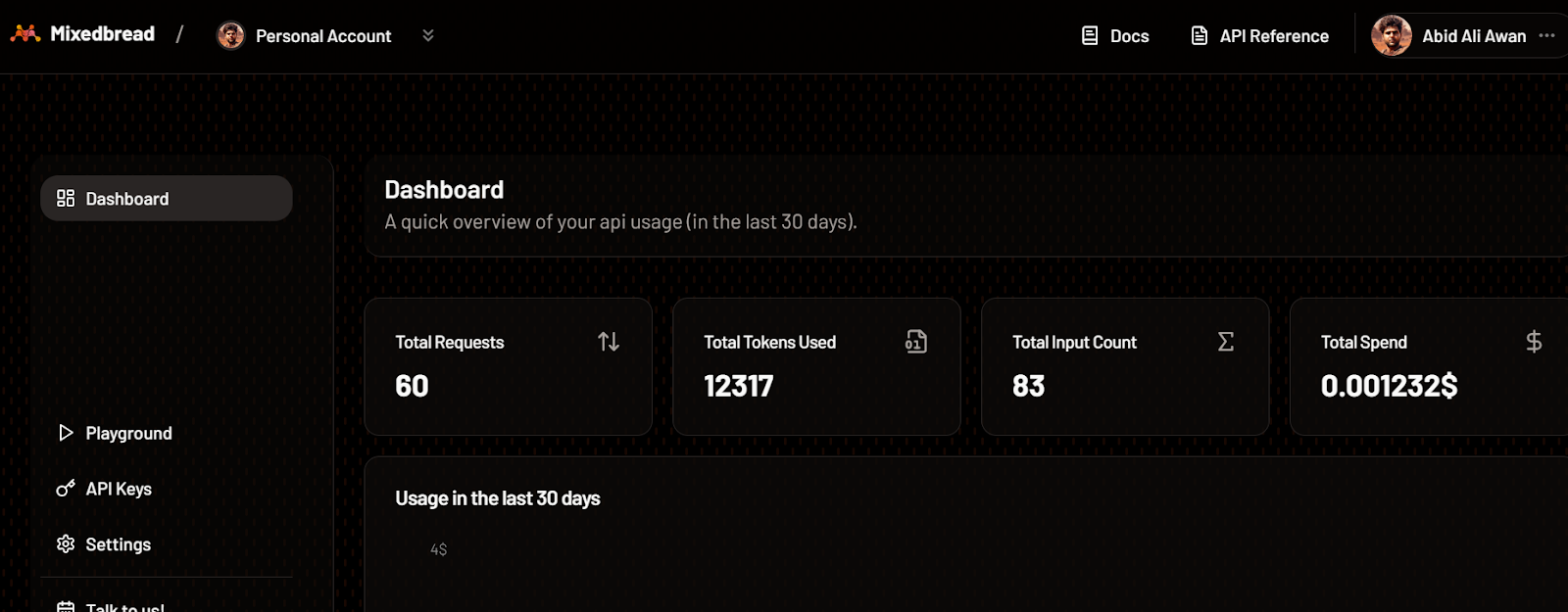
Tablero de pan mixto. Fuente de la imagene: Mixedbread
Los registros más detallados de cada API se pueden encontrar en GroqCloud, con información sobre la latencia, el número de tokens, la clave AI y el ID de solicitud para que puedas depurar el sistema.
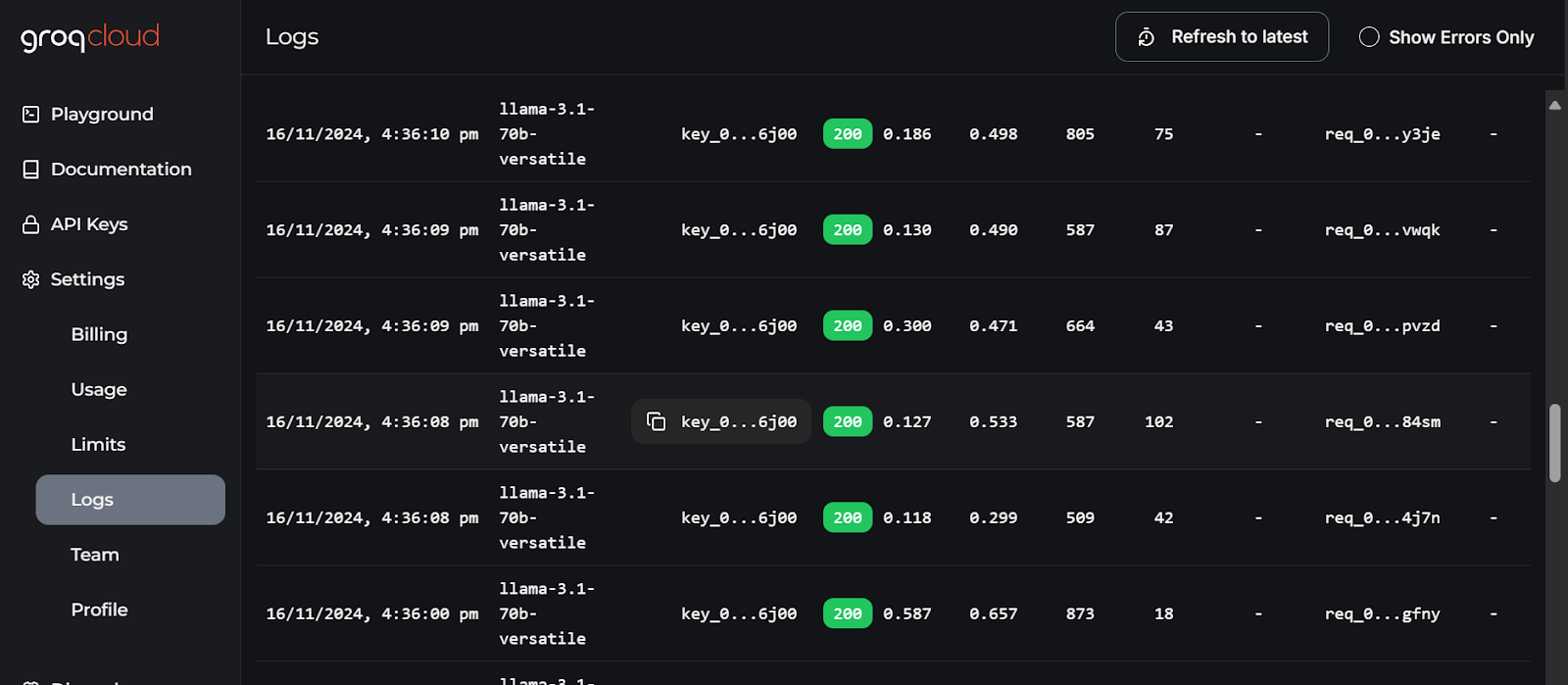
Registros de GroqCloud. Imagen tanurce: GroqCloud
Esta guía nos enseñó a combinar varios servicios para crear una aplicación eficiente de preguntas y respuestas sobre documentos con un uso mínimo de recursos y una sobrecarga computacional. Todos los servicios y herramientas que hemos utilizado están disponibles gratuitamente para que pruebes y construyas tu propia aplicación.
Hemos reducido el tamaño de nuestra imagen Docker en 600 MB utilizando múltiples servicios de IA listos para usar. Si hubiéramos desplegado todo por nuestra cuenta, el tamaño de la imagen habría sido de unos 20 GB o más.
Te recomiendo que tomes el curso LLMOps Concepts: From Ideation to Deployment curso como siguiente paso en tu viaje de aprendizaje. Este curso te ayudará a comprender mejor el ciclo de vida del desarrollo LLM y los retos que plantea el despliegue de aplicaciones. También te enseñará a aplicar estos conceptos con eficacia.
¡Aprende más sobre los LLM con estos cursos!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan

