
Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
O Docker permite que você crie ambientes consistentes, portáteis e isolados, o que o torna essencial para LLMOps (Large Language Models Operations). Ao encapsular vários aplicativos LLM e suas dependências em contêineres, o Docker simplifica a implantação, garante a compatibilidade entre sistemas e agiliza os testes.
Neste tutorial, você aprenderá a criar um aplicativo de chatbot de "perguntas e respostas sobre documentos" e a implantá-lo na nuvem usando o Docker. Usaremos o Gradio para a interface de usuário, o LlamaIndex para orquestração, o LlamaParse para analisar documentos, o Mixedbread AI para incorporação, o Groq para acessar grandes modelos de linguagem, o Docker para empacotar o aplicativo e suas dependências e o Hugging Face Spaces para implantar o aplicativo na nuvem.
Este tutorial foi projetado para ser direto, permitindo que qualquer pessoa com conhecimento limitado de como os aplicativos de IA funcionam possa criá-lo gratuitamente.
Há duas abordagens principais para o desenvolvimento e a implantação de aplicativos de IA:
Ambas as abordagens têm vantagens e desvantagens. Em nosso caso, escolhemos a segunda abordagem, integrando vários serviços de IA. Isso nos permite criar um aplicativo de IA rápido que leva apenas alguns segundos para ser criado e implantado. Nosso foco principal é reduzir o tamanho da imagem do Docker, o que pode ser alcançado de forma eficaz com a integração de vários serviços de IA.
Confira o tutorial Local AI with Docker, n8n, Qdrant e Ollama para criar um aplicativo LLM usando ferramentas e estruturas de código aberto para aumentar a privacidade!
Criaremos um chatbot de perguntas e respostas de uso geral que permite que os usuários carreguem documentos e conversem com eles em tempo real. Ele é bastante semelhante ao NotebookLM do Google.
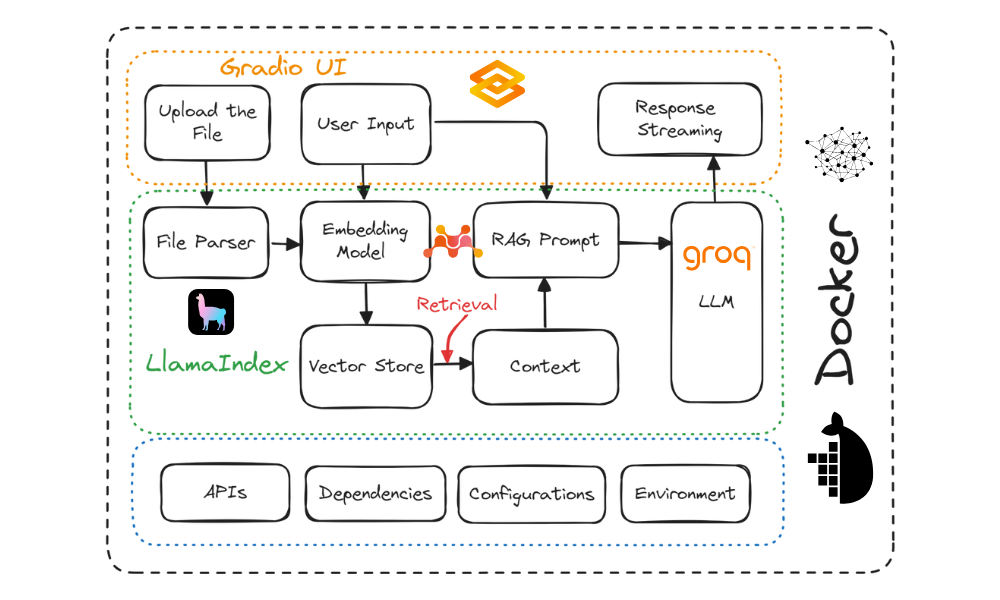
Diagrama do projeto. Imagem do autor
Aqui estão as ferramentas que usaremos neste projeto:
Se você não conhece os LLMs, considere fazer o curso Master Large Language Models (LLMs) Concepts para conhecer as terminologias básicas, as metodologias, as considerações éticas e as pesquisas mais recentes.
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

Antes de criar o aplicativo LLM, precisamos fazer download e instalar o Docker no site oficial.
.env. Usaremos esse arquivo para armazenar as chaves de API do LlamaCloud, MixedBread AI e Groq Cloud.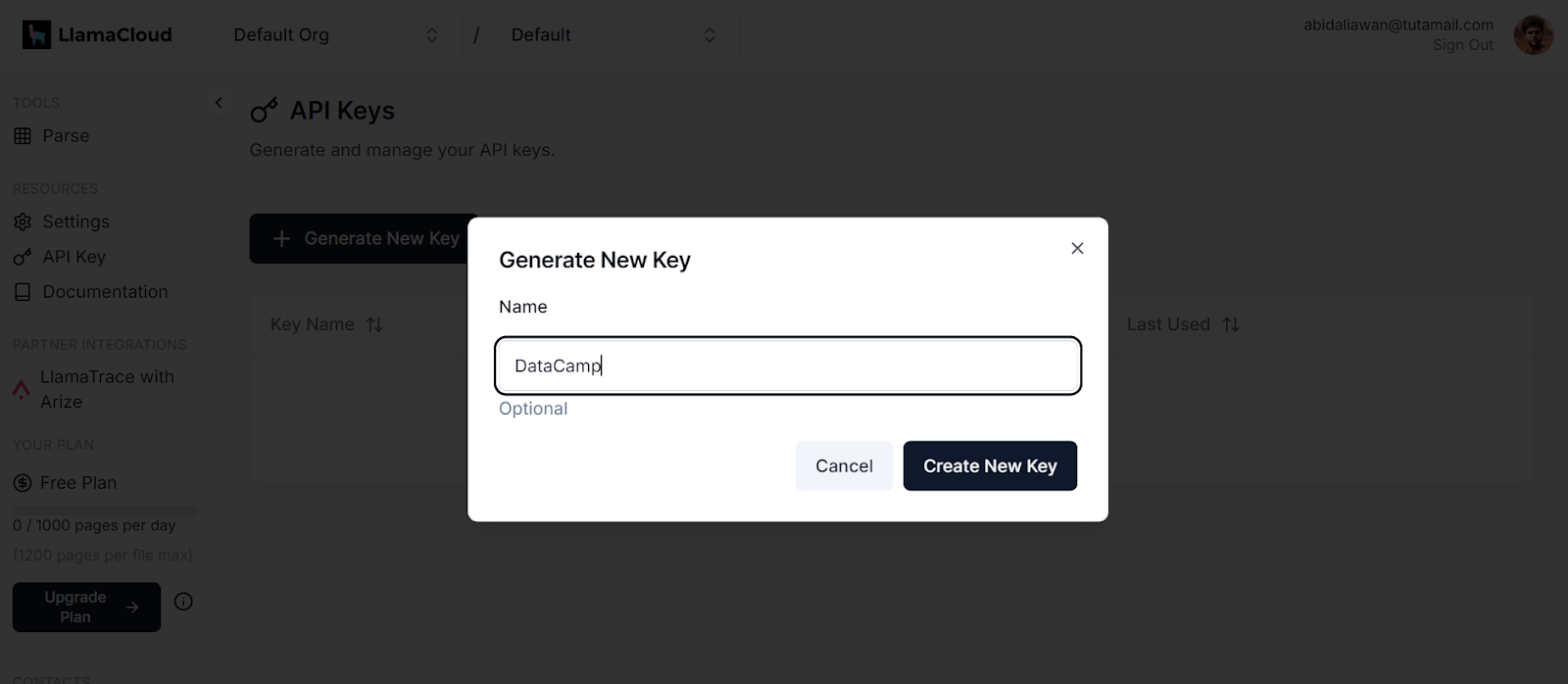
Geração de uma nova chave no LlamaCloud. Fonte da imagem: LlamaCloud
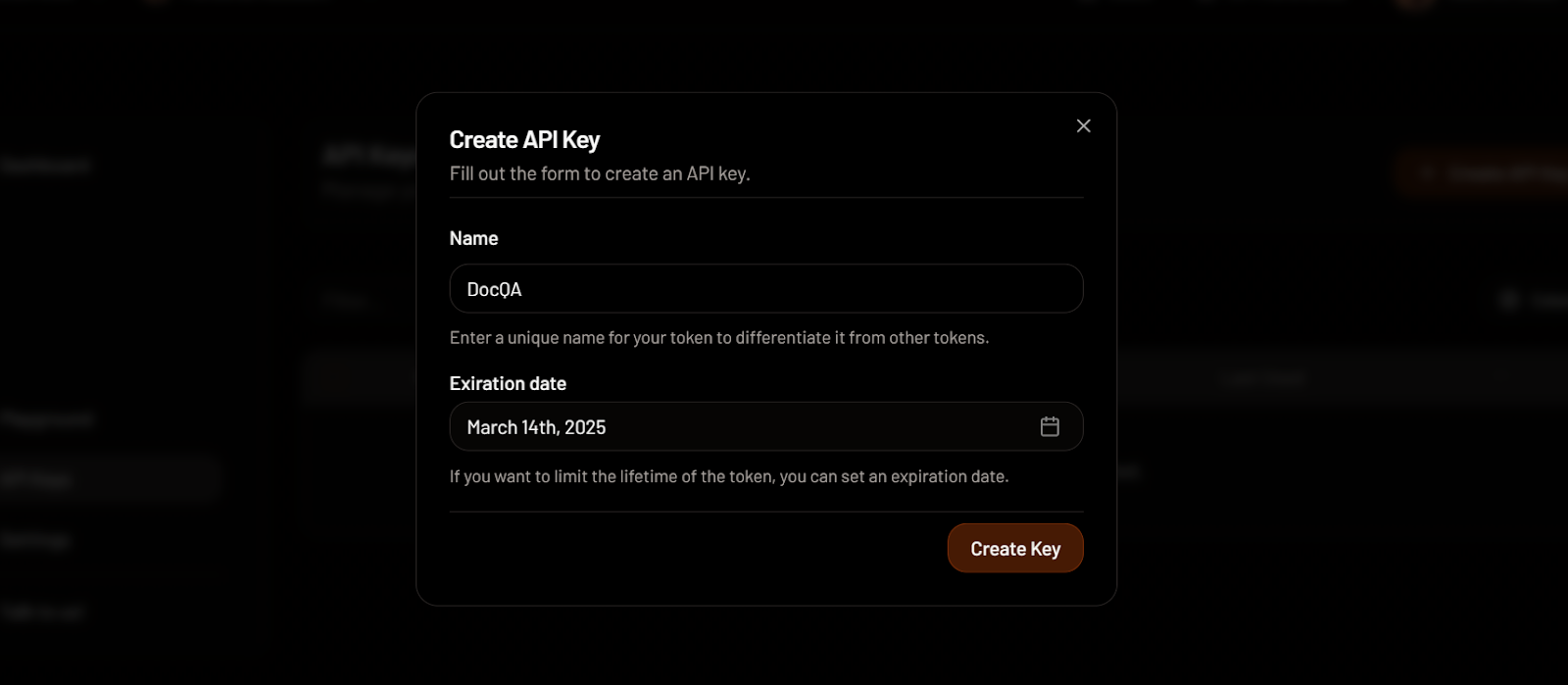
Criando uma chave de API na MixedBread. Fonte da imagem: MixedBread
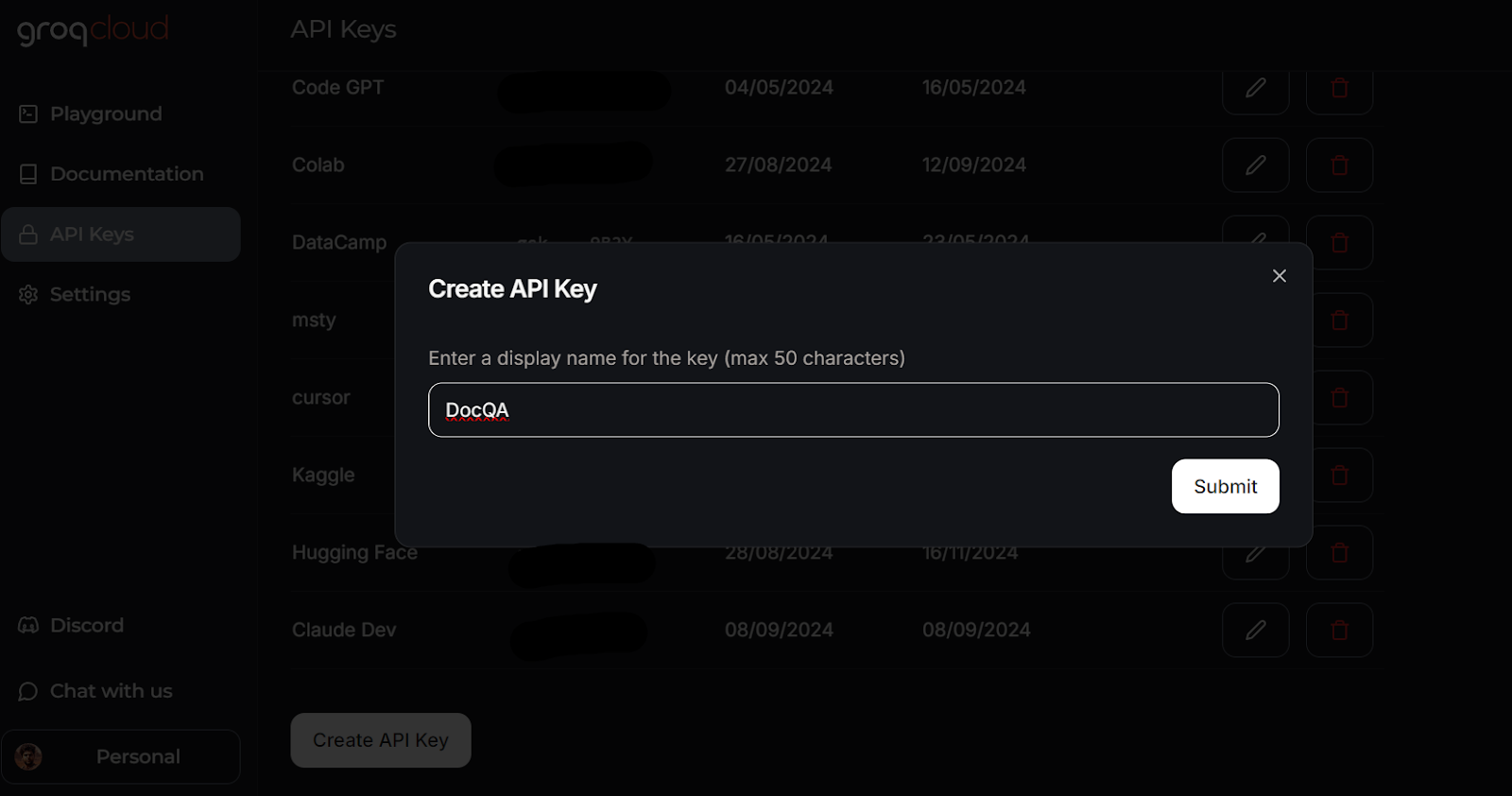
Criando uma chave de API no GroqCloud. Fonte da imagem: GroqCloud
Saiba tudo sobre o GroqCloud lendo o artigo sobre o Groq LPU Inference Engine. Você aprenderá sobre a API do Groq e seus recursos com exemplos de código. Além disso, saiba como criar aplicativos de IA com reconhecimento de contexto usando a API Groq e o LlamaIndex.
É assim que o seu arquivo .env deve se parecer:
LLAMA_CLOUD_API_KEY=llx-XXXXXX
GROQ_API_KEY=gsk_XXXXXXX
MXBAI_API_KEY=emb_XXXXXXLembre-se de adicionar o arquivo .env ao seu arquivo .gitignore para evitar que você exponha acidentalmente suas chaves de API ao público.
Agora, criaremos um script Python chamado app.py e adicionaremos os componentes da interface do usuário enquanto integramos todos os serviços de IA usando o LlamaParser para desenvolver o pipeline Retrieval-Augmented Generation (RAG) com o LlamaIndex.
O script app.py fará o seguinte:
.env.mixedbread-ai/mxbai-embed-large-v1.llama-3.1-70b-versatile.Em seguida, ele implementará as seguintes funções Python:
load_files(): Essa função carregará os arquivos, os analisará usando o LlamaParser, os converterá em embeddings e os armazenará no armazenamento de vetores. O tratamento de exceções será incluído para gerenciar os casos em que não forem carregados arquivos ou formatos de arquivo não compatíveis.respond(): Essa função receberá a entrada do usuário, recuperará o conteúdo do armazenamento de vetores e o usará para gerar uma resposta utilizando o modelo Groq. A geração de resposta será em formato de fluxo contínuo e o tratamento de exceções será incluído se nenhum arquivo tiver sido carregado.Por fim, ele criará os componentes da interface do usuário, incluindo um carregador de arquivos, botões, uma caixa de bate-papo e a interface geral do bate-papo.
Saiba mais sobre a estrutura do LlamaIndex seguindo o tutorial mais direto do LlamaIndex.
Aqui está o script app.py:
import os
import gradio as gr
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.embeddings.mixedbreadai import MixedbreadAIEmbedding
from llama_index.llms.groq import Groq
from llama_parse import LlamaParse
# API keys
llama_cloud_key = os.environ.get("LLAMA_CLOUD_API_KEY")
groq_key = os.environ.get("GROQ_API_KEY")
mxbai_key = os.environ.get("MXBAI_API_KEY")
if not (llama_cloud_key and groq_key and mxbai_key):
raise ValueError(
"API Keys not found! Ensure they are passed to the Docker container."
)
# models name
llm_model_name = "llama-3.1-70b-versatile"
embed_model_name = "mixedbread-ai/mxbai-embed-large-v1"
# Initialize the parser
parser = LlamaParse(api_key=llama_cloud_key, result_type="markdown")
# Define file extractor with various common extensions
file_extractor = {
".pdf": parser,
".docx": parser,
".doc": parser,
".txt": parser,
".csv": parser,
".xlsx": parser,
".pptx": parser,
".html": parser,
".jpg": parser,
".jpeg": parser,
".png": parser,
".webp": parser,
".svg": parser,
}
# Initialize the embedding model
embed_model = MixedbreadAIEmbedding(api_key=mxbai_key, model_name=embed_model_name)
# Initialize the LLM
llm = Groq(model="llama-3.1-70b-versatile", api_key=groq_key)
# File processing function
def load_files(file_path: str):
global vector_index
if not file_path:
return "No file path provided. Please upload a file."
valid_extensions = ', '.join(file_extractor.keys())
if not any(file_path.endswith(ext) for ext in file_extractor):
return f"The parser can only parse the following file types: {valid_extensions}"
document = SimpleDirectoryReader(input_files=[file_path], file_extractor=file_extractor).load_data()
vector_index = VectorStoreIndex.from_documents(document, embed_model=embed_model)
print(f"Parsing completed for: {file_path}")
filename = os.path.basename(file_path)
return f"Ready to provide responses based on: {filename}"
# Respond function
def respond(message, history):
try:
# Use the preloaded LLM
query_engine = vector_index.as_query_engine(streaming=True, llm=llm)
streaming_response = query_engine.query(message)
partial_text = ""
for new_text in streaming_response.response_gen:
partial_text += new_text
# Yield an empty string to cleanup the message textbox and the updated conversation history
yield partial_text
except (AttributeError, NameError):
print("An error occurred while processing your request.")
yield "Please upload the file to begin chat."
# Clear function
def clear_state():
global vector_index
vector_index = None
return [None, None, None]
# UI Setup
with gr.Blocks(
theme=gr.themes.Default(
primary_hue="green",
secondary_hue="blue",
font=[gr.themes.GoogleFont("Poppins")],
),
css="footer {visibility: hidden}",
) as demo:
gr.Markdown("# DataCamp Doc Q&A 🤖📃")
with gr.Row():
with gr.Column(scale=1):
file_input = gr.File(
file_count="single", type="filepath", label="Upload Document"
)
with gr.Row():
btn = gr.Button("Submit", variant="primary")
clear = gr.Button("Clear")
output = gr.Textbox(label="Status")
with gr.Column(scale=3):
chatbot = gr.ChatInterface(
fn=respond,
chatbot=gr.Chatbot(height=300),
theme="soft",
show_progress="full",
textbox=gr.Textbox(
placeholder="Ask questions about the uploaded document!",
container=False,
),
)
# Set up Gradio interactions
btn.click(fn=load_files, inputs=file_input, outputs=output)
clear.click(
fn=clear_state, # Use the clear_state function
outputs=[file_input, output],
)
# Launch the demo
if __name__ == "__main__":
demo.launch()$ python app.py Saída:

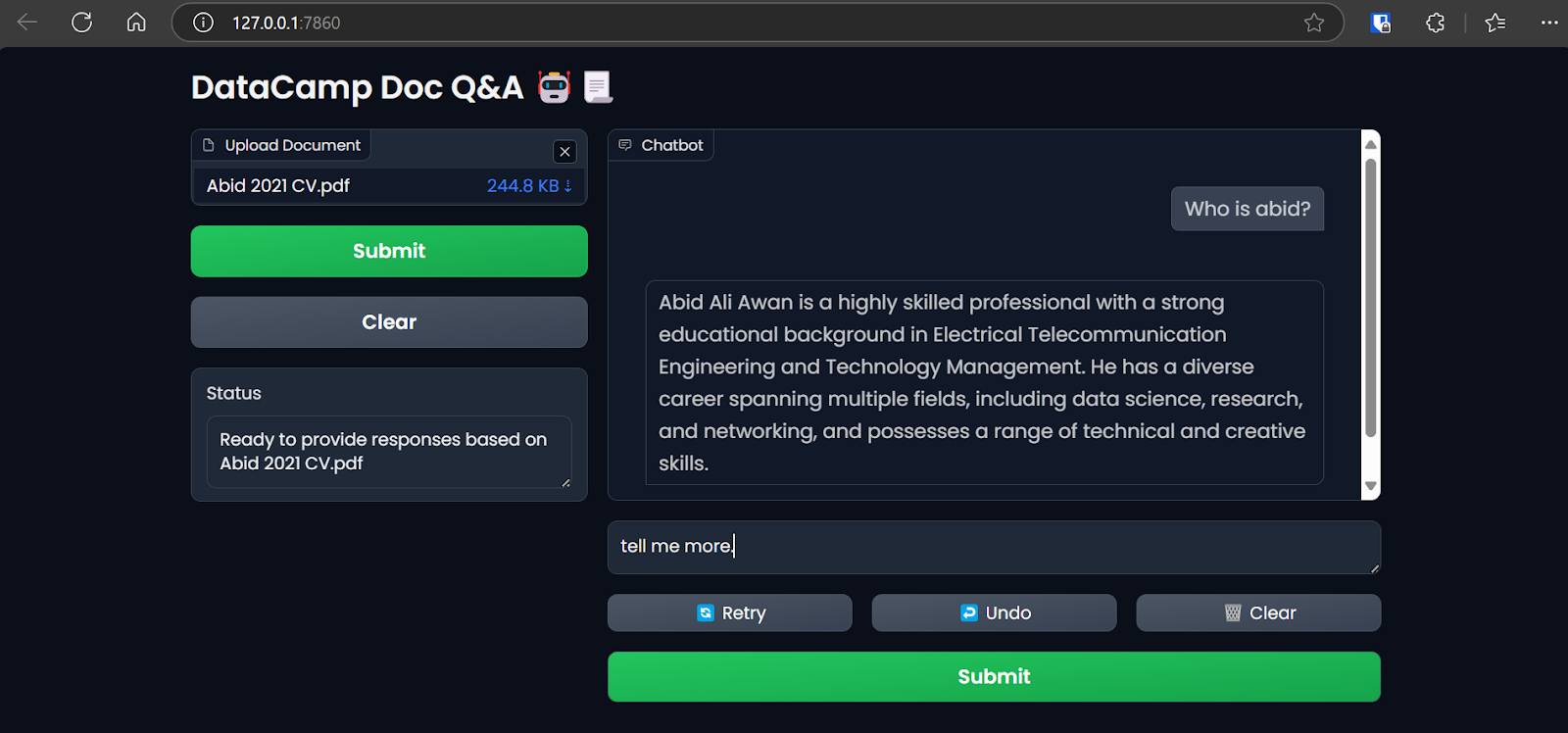
Acessando o aplicativo Gradio no navegador. Imagem do autor
Usamos o LlamaIndex para implementar e criar nosso aplicativo LLM para este tutorial. Você pode criar um aplicativo semelhante com o LangChain fazendo o curso de curta duração Developing LLM Applications with LangChain.
Dockerfile para empacotar o script do aplicativo, as dependências do Python e as configurações do servidor ao inicializar o servidor Gradio. O Dockerfile realizará as seguintes tarefas:
requirements.txt para o diretório /app. Esse arquivo contém os nomes de todos os pacotes Python necessários.requirements.txt.app.py para o diretório /app.Veja como deve ser o site Dockerfile:
# Dockerfile
# Use the official Python image with the desired version
FROM python:3.9-slim
# Set the working directory inside the container
WORKDIR /app
# Copy the requirements file to the working directory
COPY requirements.txt /app
# Install the dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code to the working directory
COPY app.py /app
# Expose the port that Gradio will run on (default is 7860)
EXPOSE 7860
ENV GRADIO_SERVER_NAME="0.0.0.0"
# Command to run your application
CMD ["python", "app.py"]requirements.txt. Adicione-o também ao seu projeto:gradio
llama-index-embeddings-mixedbreadai
llama-index-llms-groq
llama-indexdocqa. Você usará o endereço Dockerfile para criar a imagem do Docker.$ docker build -t docqa . Podemos ver os registros dos processos que ocorrem durante a criação da imagem do Docker:
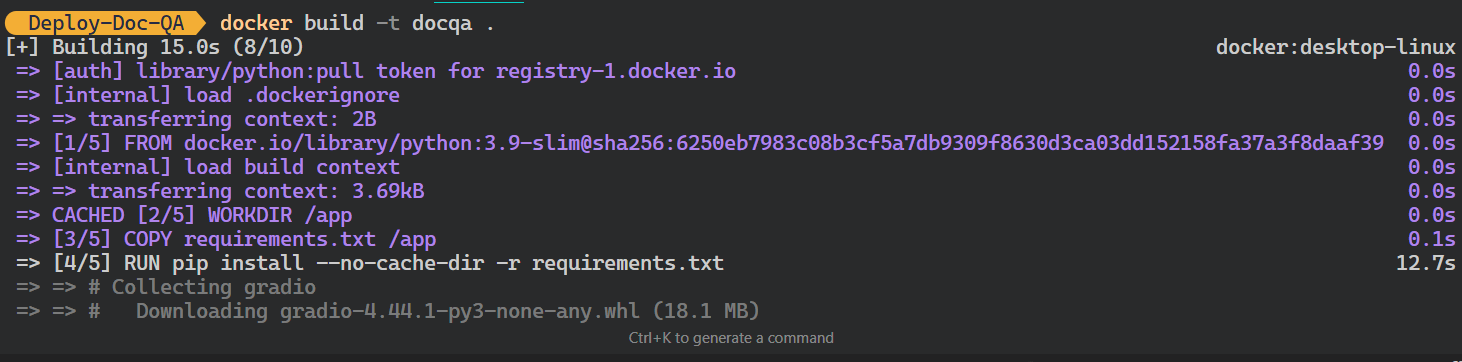
Criando a imagem do LLM Docker. Imagem do autor
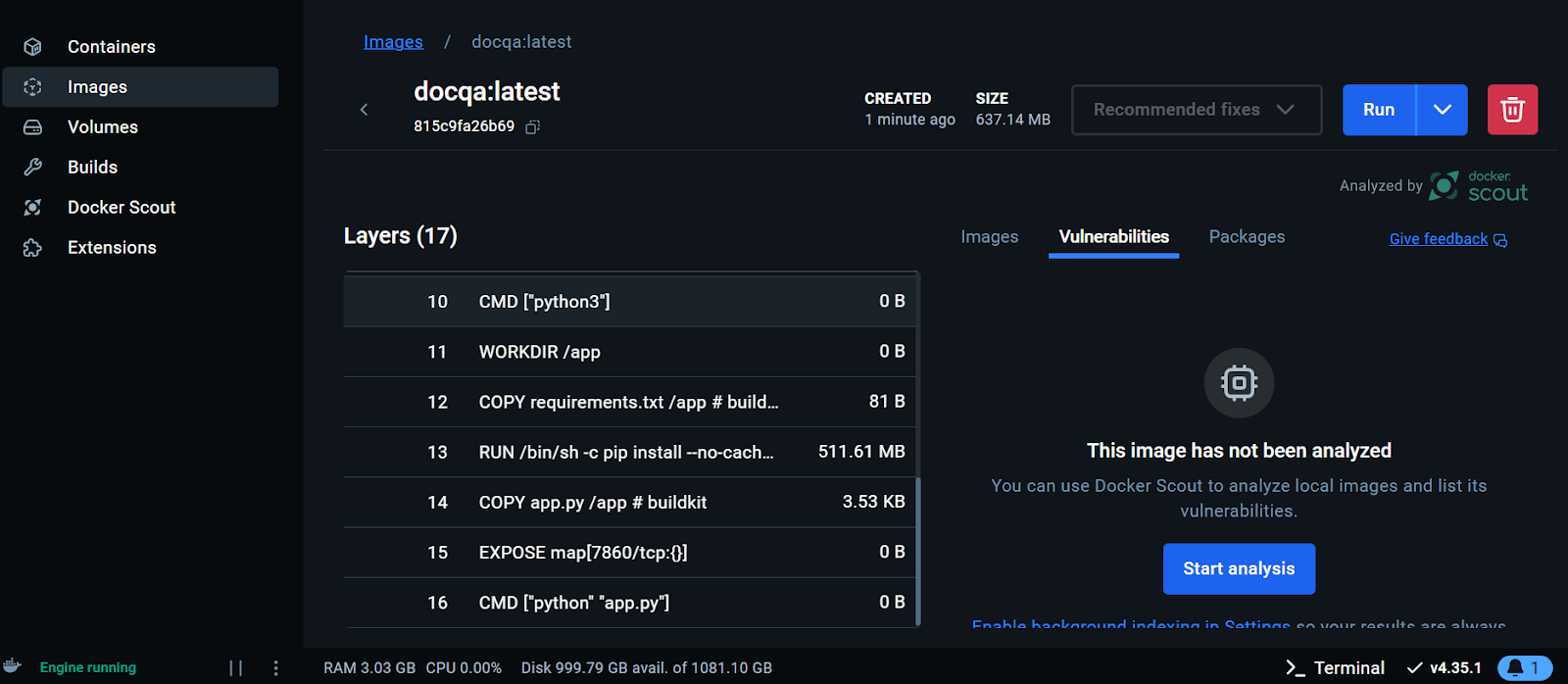
Visualizando a imagem do Docker no Docker Desktop. Imagem do autor
Agora, executaremos o contêiner do Docker localmente usando a imagem. Forneceremos a ele o número da porta, um arquivo .env para configurar as variáveis de ambiente, o nome do contêiner do Docker e a tag da imagem do Docker.
$ docker run -p 7860:7860 --env-file .env --name docqa-container docqaQuando o contêiner começar a ser executado, você poderá acessar o aplicativo Gradio colando o URL, neste caso, http://0.0.0.1:7860/ no navegador.
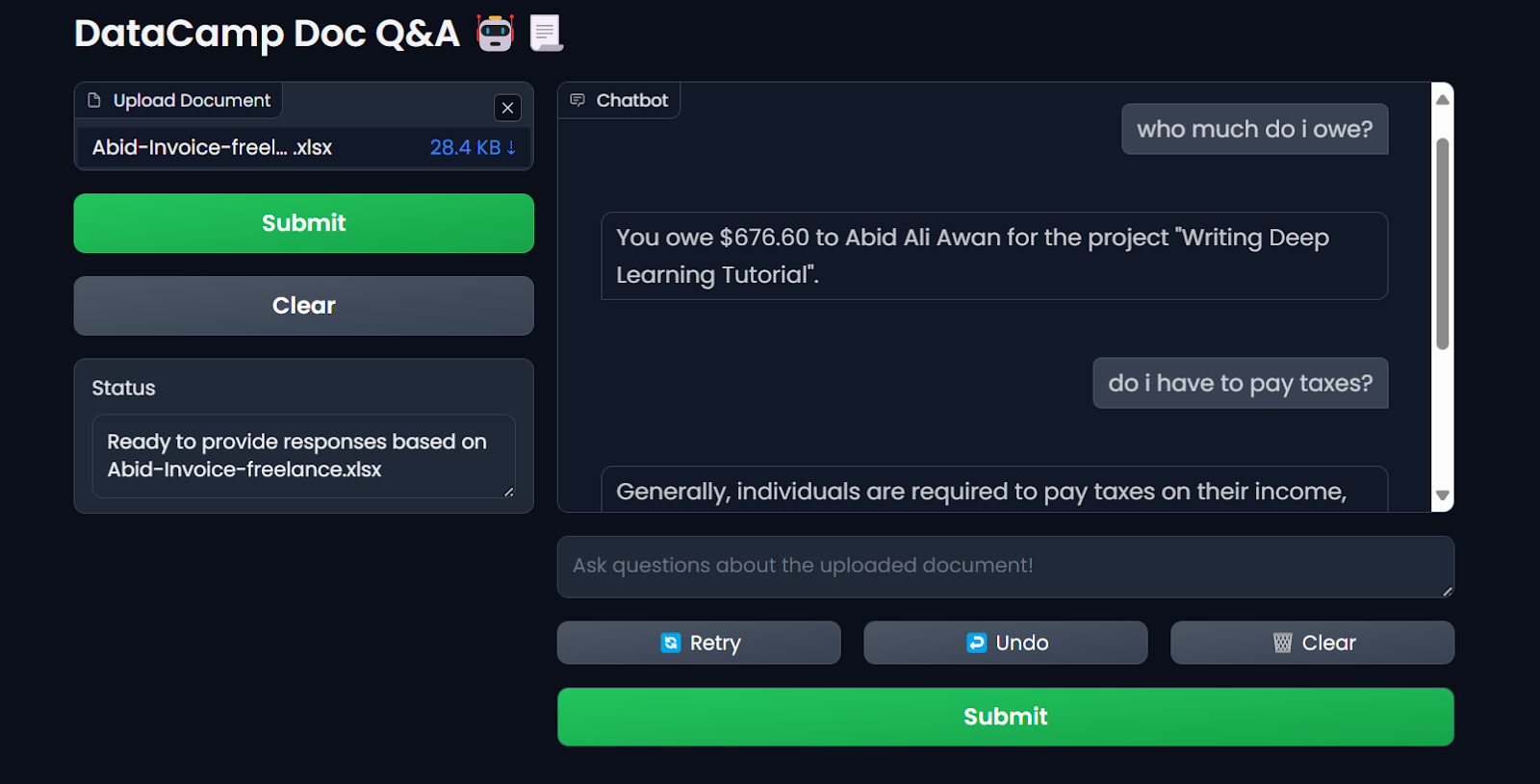
Testar o aplicativo LLM do contêiner do Docker. Imagem do autor
$ docker psSaída:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ff2a11da13d7 docqa "python app.py" 17 seconds ago Up 16 seconds 0.0.0.0:7860->7860/tcp docqa-containerstop:$ docker stop docqa-container rm:$ docker rm docqa-container Quando tivermos uma imagem do Docker, poderemos implementar nosso aplicativo LLM em qualquer lugar: GCP, AWS, Azure ou qualquer servidor em nuvem que ofereça suporte à implementação do Docker.
Para simplificar as coisas para os iniciantes, implantaremos o aplicativo usando o Docker no Hugging Face Cloud (Spaces).
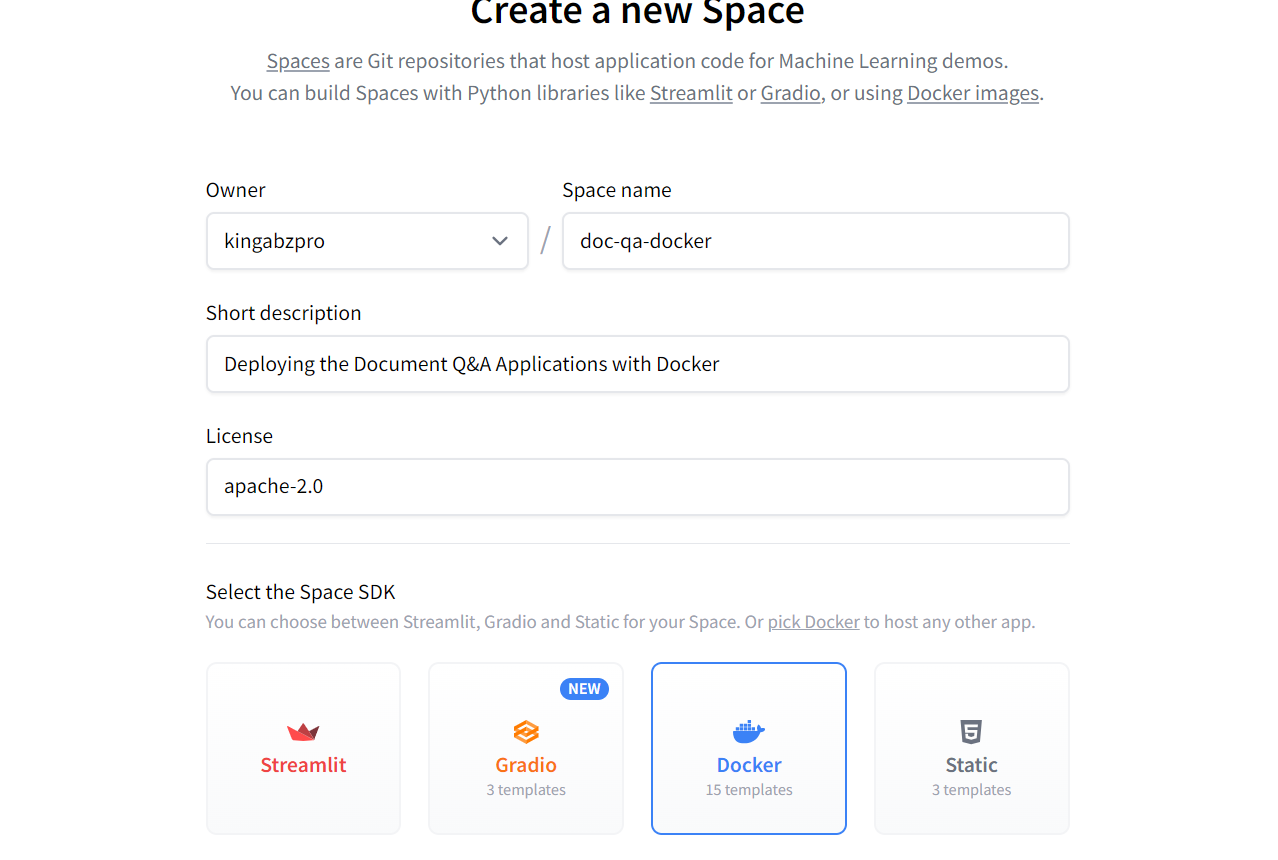
Criando o novo Hugging Face Space usando o Docker. Imagem fonte: Cara de abraço
Depois que o repositório do Space for criado, você receberá instruções sobre como cloná-lo e adicionar os arquivos necessários.
$ git clone https://huggingface.co/spaces/kingabzpro/doc-qa-dockerÉ assim que o diretório do seu projeto deve ficar com todos os arquivos. Certifique-se sempre de que você não envie o arquivo .env, portanto, adicione-o ao arquivo .gitignore.
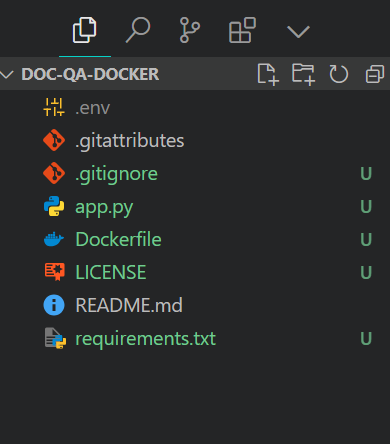
Estrutura do arquivo do projeto. Imagem do autor
$ git add .
$ git commit -m "Deploying the App"
$ git pushSaída:
Enumerating objects: 8, done.
Counting objects: 100% (8/8), done.
Delta compression using up to 16 threads
Compressing objects: 100% (7/7), done.
Writing objects: 100% (7/7), 7.60 KiB | 7.60 MiB/s, done.
Total 7 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
To https://huggingface.co/spaces/kingabzpro/doc-qa-docker
afb20ad..5ca6388 main -> main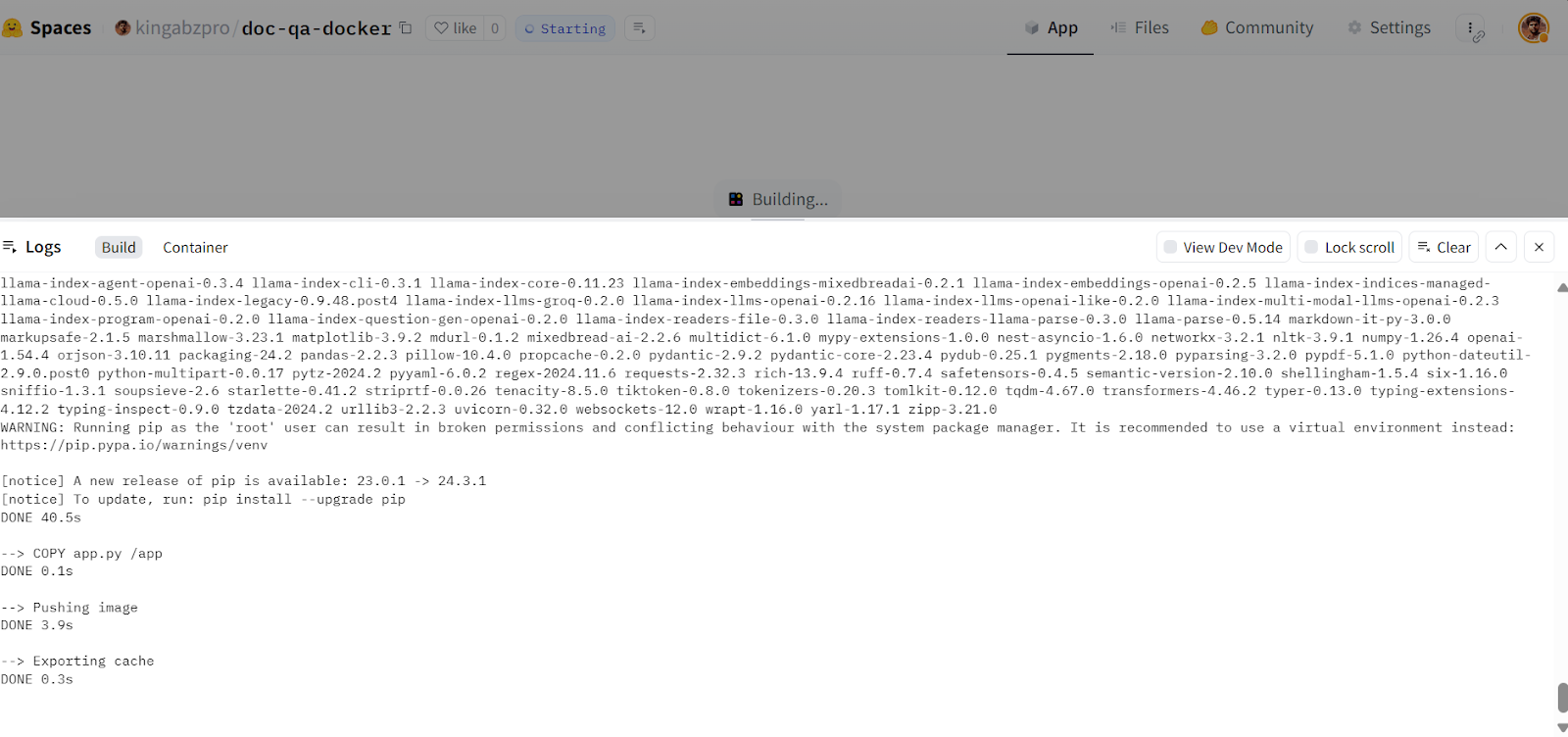
Criando a imagem do Docker na nuvem Hugging Face. Fonte da imagem: Doc Qa Docker
Se você vir um erro como o abaixo, não se preocupe. Isso se deve à falta de variáveis de ambiente. Tudo o que precisamos fazer é configurar essas variáveis no Hugging Face Space.

Erro de tempo de execução no aplicativo implantado. Fonte da imagem: Doc Qa Docker
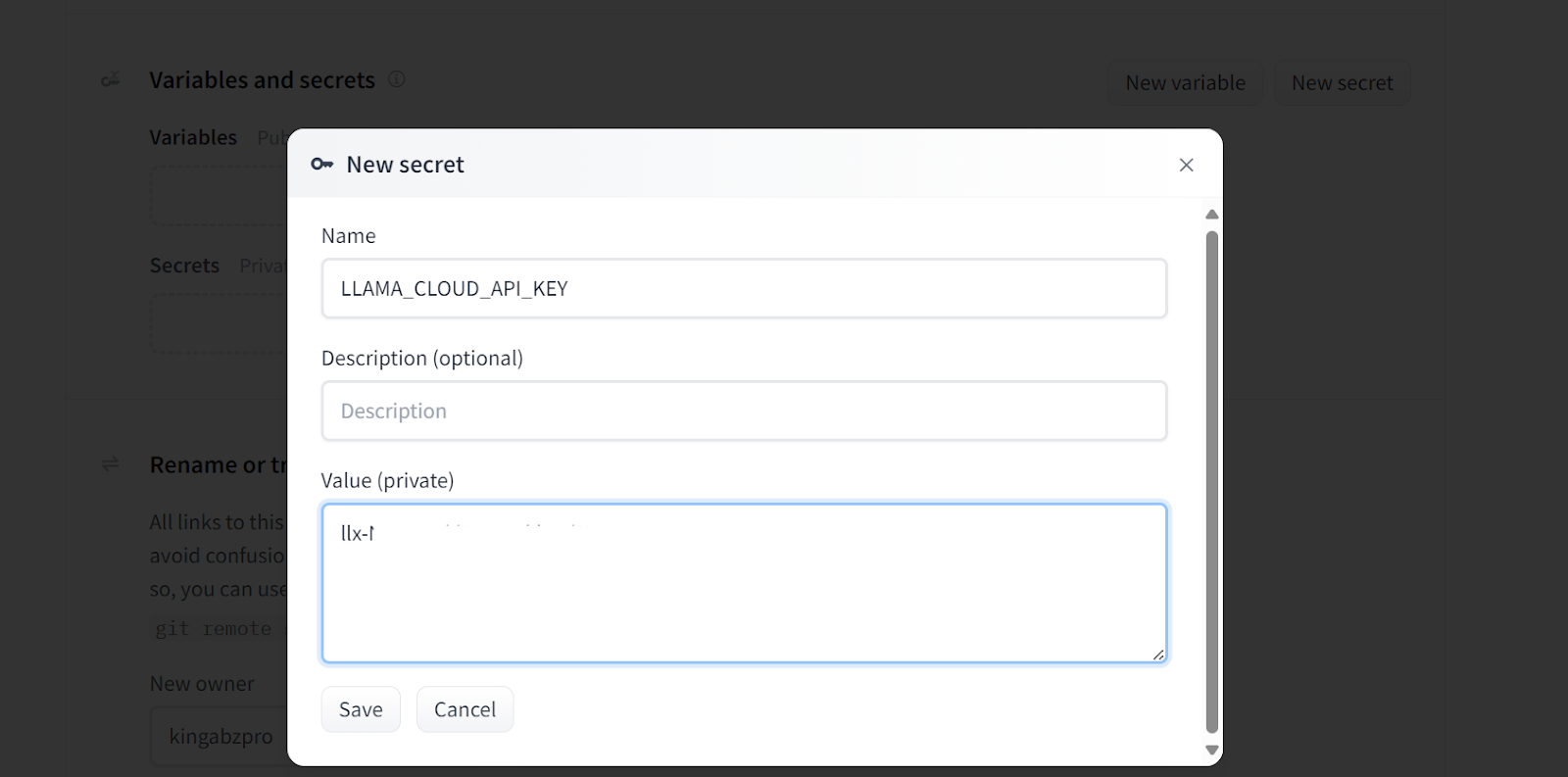
Adicionando segredos ao aplicativo implantado. Fonte da imagem: Doc Qa Configurações do Docker.
É assim que seus segredos devem ficar depois que você adicionar todas as chaves de API necessárias como variáveis de ambiente:
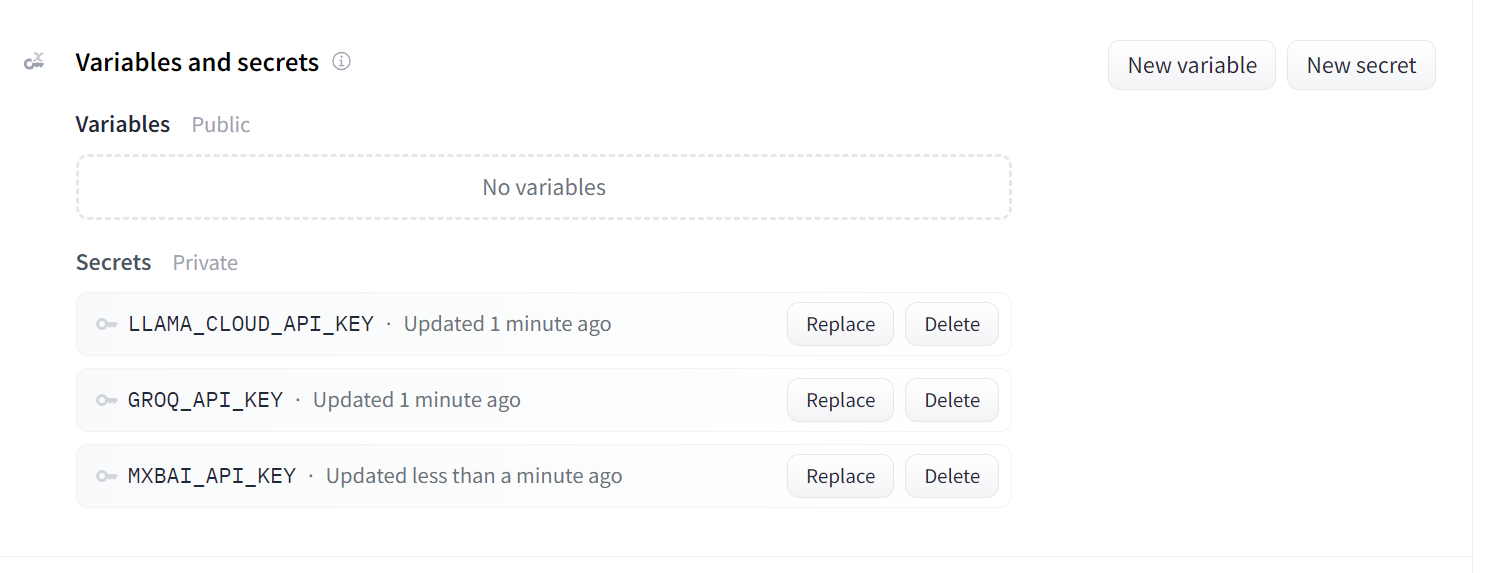
Segredos para o aplicativo implantado. Fonte da imagem: Doc Qa Configurações do Docker.
Depois de configurar os segredos, o aplicativo será reiniciado automaticamente e você deverá ver o aplicativo em execução. Use-o e aproveite seu aplicativo de Q&A de documentos na nuvem!
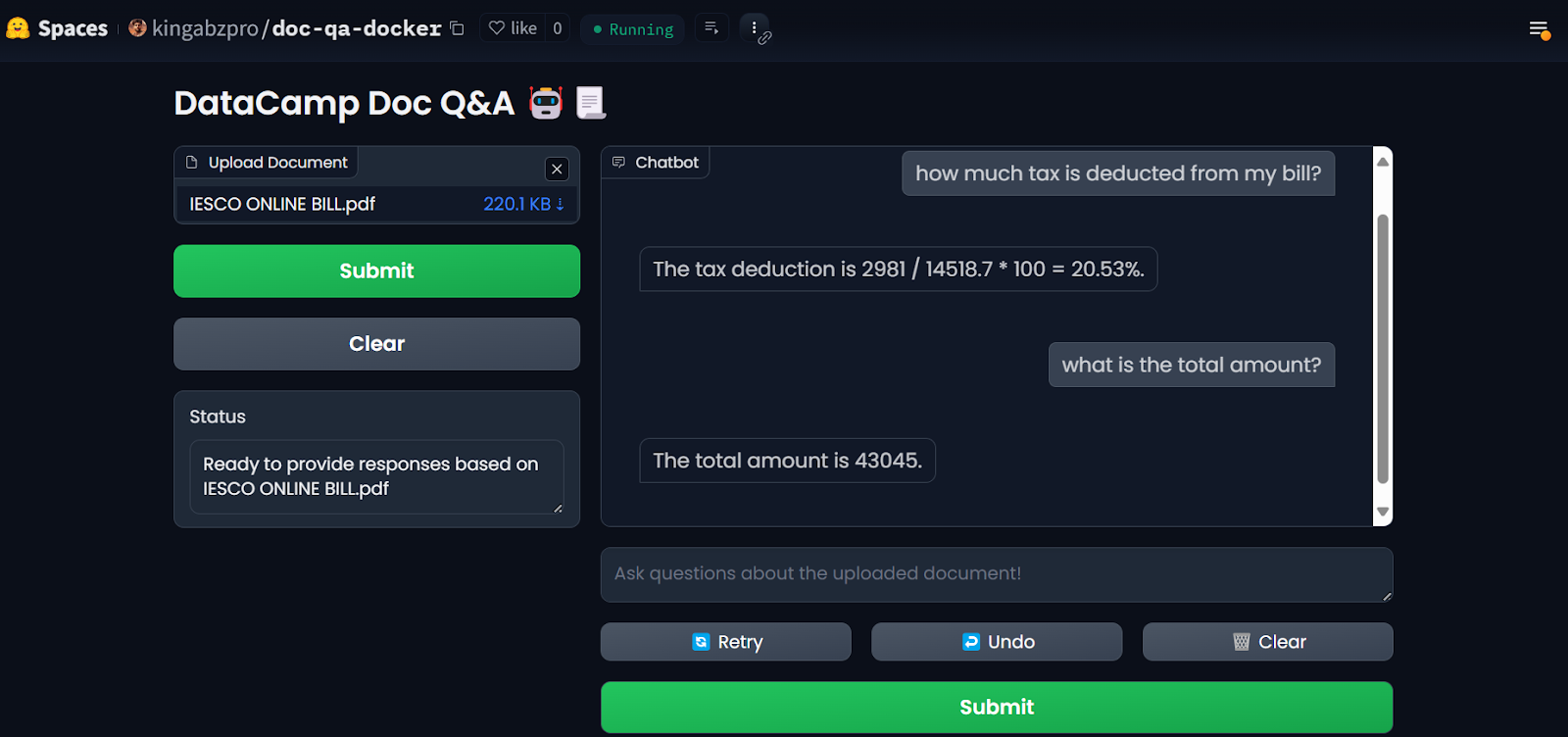
Aplicativo LLM nos espaços do Hugging Face. Fonte da imageme: Doc Qa Docker
Para reproduzir os resultados, todos os arquivos e configurações podem ser encontrados no repositório do GitHubsite: kingabzpro/Deploy-Doc-QA.
O uso de serviços de IA tem vantagens: Você não precisa implantar nem gerenciar nenhum serviço, obtém alta taxa de transferência e um painel de controle com os registros.
O painel de controle do LlamaCloud registra todos os documentos que foram analisados. Você pode verificar o histórico ou solicitar e comparar o uso.
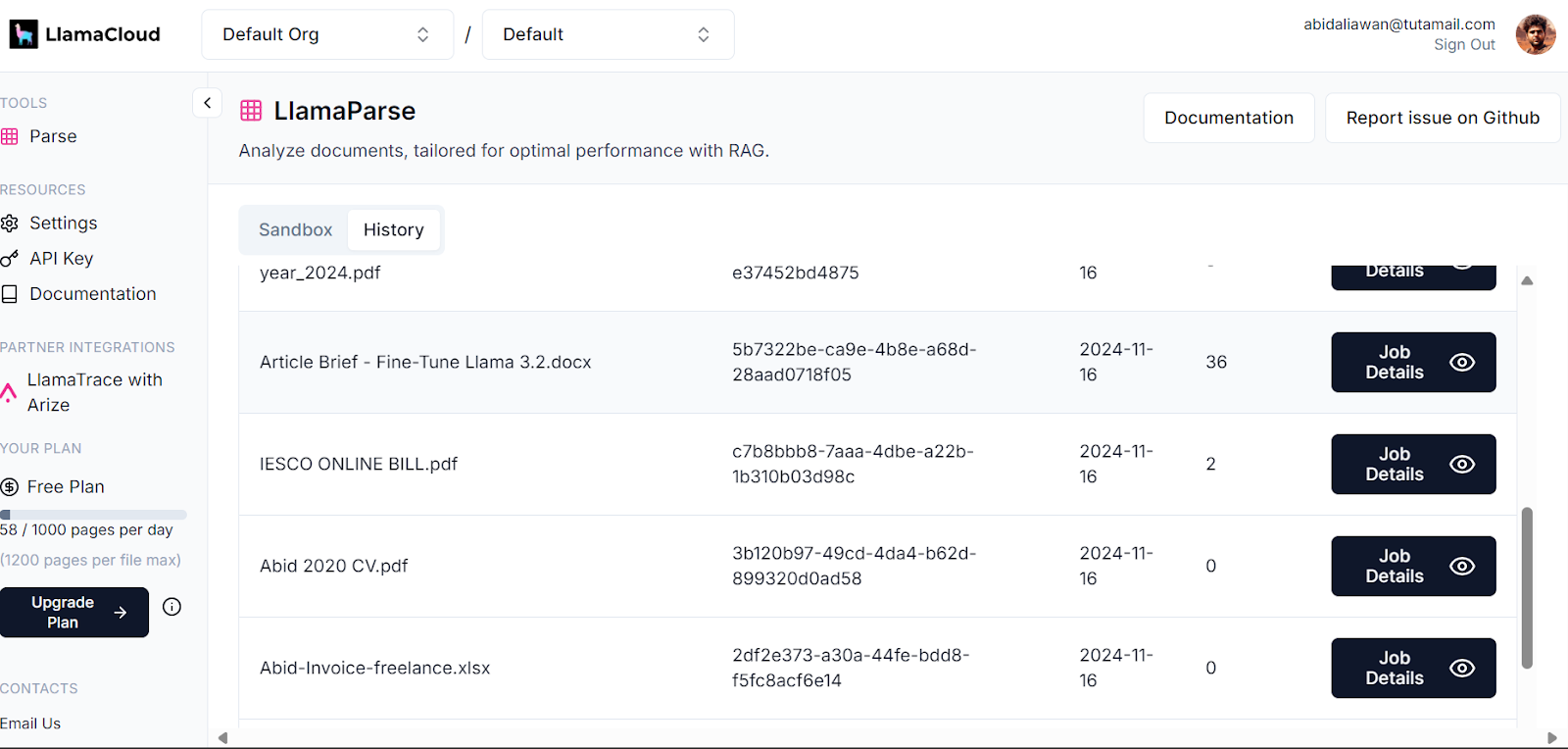
Painel de controle do Llama Cloud. Imagem source: LlamaCloud
Da mesma forma, você também pode verificar o número de tokens que usamos para o modelo de incorporação e o número de solicitações geradas.
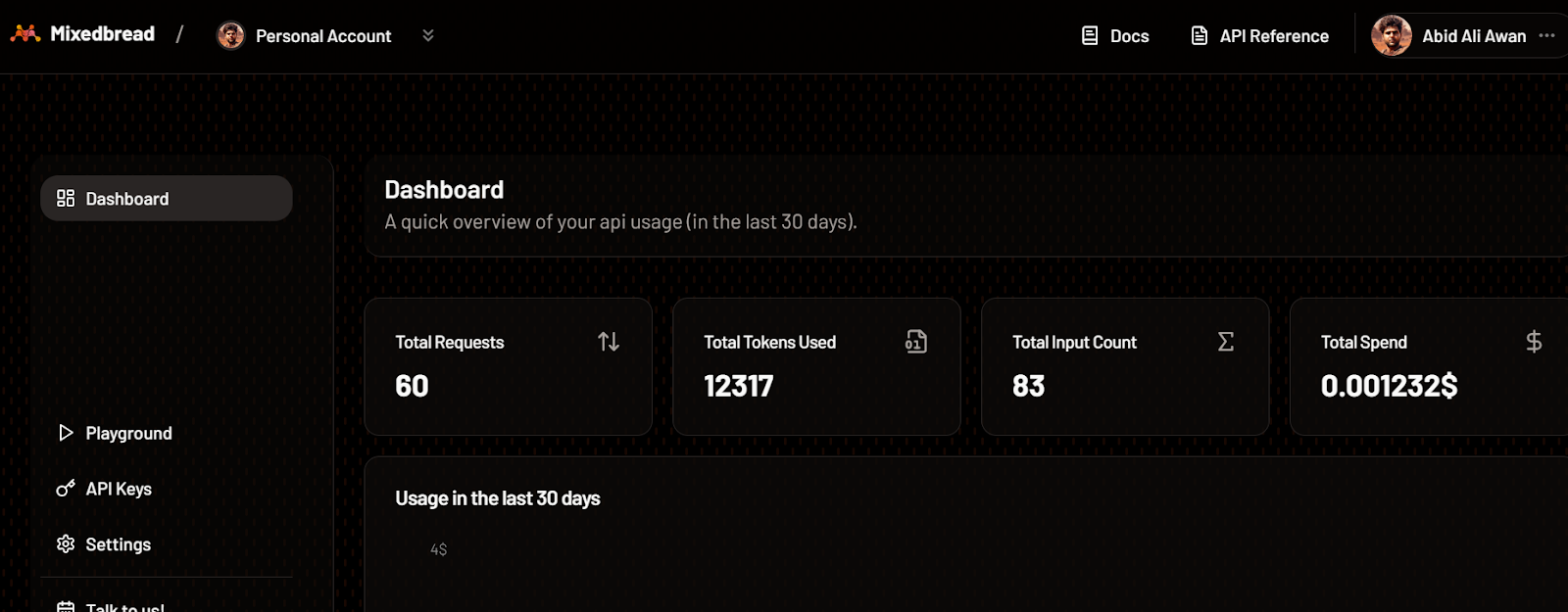
Painel de controle de pão misto. Fonte da imageme: Pão misto
Os logs mais detalhados de cada API podem ser encontrados no GroqCloud, com informações sobre a latência, o número de tokens, a chave de IA e o ID da solicitação para que você possa depurar o sistema.
Registros do GroqCloud. Imagem emurce: GroqCloud
Este guia nos ensinou como combinar vários serviços para criar um aplicativo eficiente de Q&A de documentos com uso mínimo de recursos e sobrecarga computacional. Todos os serviços e ferramentas que usamos estão disponíveis gratuitamente para você testar e criar seu próprio aplicativo.
Reduzimos o tamanho da nossa imagem do Docker em 600 MB usando vários serviços de IA prontos para uso. Se tivéssemos implementado tudo por conta própria, o tamanho da imagem teria sido de cerca de 20 GB ou mais.
Recomendo que você faça o curso LLMOps Concepts: From Ideation to Deployment como a próxima etapa de sua jornada de aprendizado. Este curso ajudará você a obter insights sobre o ciclo de vida de desenvolvimento do LLM e os desafios da implantação de aplicativos. Ele também ensinará a você como aplicar esses conceitos de forma eficaz.
Saiba mais sobre LLMs com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
8 min
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Zoumana Keita

