
programa
Desarrollar grandes modelos lingüísticos
16 h
Antes de empezar, una nota: al abordar los casos de uso de la IA en la asistencia sanitaria, es muy importante tener en cuenta los resultados potencialmente perjudiciales para los pacientes. El ejemplo siguiente, aunque exhaustivo, sólo pretende ilustrar el ajuste fino en un conjunto de datos del mundo real. Si persigues casos de uso de la IA en la sanidad u otros ámbitos sensibles, te recomendamos encarecidamente que leas nuestra guía sobre Ética de la IA.
En este tutorial, aprenderemos sobre los modelos Llama 3.1 y pondremos a punto el modelo Llama-3.1-8b-It sobre el análisis de sentimientos para el conjunto de datos de salud mental. Nuestro objetivo es personalizar el modelo para que pueda predecir el estado de salud mental del paciente basándose en el texto. También fusionaremos el adaptador con el modelo basado y guardaremos el modelo completo en el hub Cara Abrazada.
Aprenderemos sobre los modelos Llama 3.1, cómo acceder a ellos en Kaggle y cómo utilizar la biblioteca Transformer para ejecutar la inferencia del modelo. También pondremos a punto el modelo Llama-3.1-8b-It en el conjunto de datos de clasificación de salud mental. Por último, fusionaremos el adaptador guardado con el modelo base y enviaremos el modelo completo al Hub Cara Abrazada.
Si eres nuevo en el tema, puedes aprender sobre la teoría que hay detrás del ajuste fino leyendo nuestro artículo, Guía introductoria a los LLM de ajuste fino.

Imagen del autor
Llama 3.1 es la última serie de grandes modelos lingüísticos multilingües (LLM) desarrollados por Meta AI, que están ampliando los límites de la comprensión y la generación lingüísticas. Está disponible en tres tamaños: Parámetros 8B, 70B y 405B.
Los modelos de Llama 3.1 se basan en una arquitectura de modelos lingüísticos autorregresivos con transformadores optimizados y se pueden ajustar con precisión para diversas tareas y conjuntos de datos de procesamiento del lenguaje natural. Se han entrenado con un conjunto diverso de datos disponibles públicamente en Internet, admiten ocho idiomas (inglés, alemán, francés, italiano, portugués, hindi, español y tailandés) y tienen una longitud de contexto de 128 k.
Los modelos Llama 3.1 están disponibles para todo el mundo bajo licencias comerciales personalizadas y requieren una información mínima sobre el individuo para descargar los pesos del modelo.
Llama 3.1 está optimizado para el diálogo multilingüe y ha superado a Gemma 2, GPT 3.5 turbo y GPT-4o en varias pruebas de referencia, como chat general, codificación, matemáticas, razonamiento y más. Es, con diferencia, el modelo de código abierto más rápido y preciso que existe.
Fuente: Llama 3.1 (meta.com)
Puedes obtener más información sobre el modelo Llama 3.1 leyendo ¿Qué es la Llama 3.1 405B de Meta? Cómo funciona, casos prácticos y más.
Para este tutorial, utilizaremos Kaggle Notebook como entorno de desarrollo, ya que ofrece GPUs y TPUs gratuitas. Para utilizar el modelo Llama 3.1 en el cuaderno Kaggle, sigue estos pasos:
1. Rellena el formulario en meta.com con la misma dirección de correo electrónico que tu cuenta de Kaggle.
2. Accede a Meta | Llama 3.1 en Kaggle y haz clic en el botón "Acceder al modelo". Acepta todas las condiciones y, tras unos segundos, accederás al modelo.
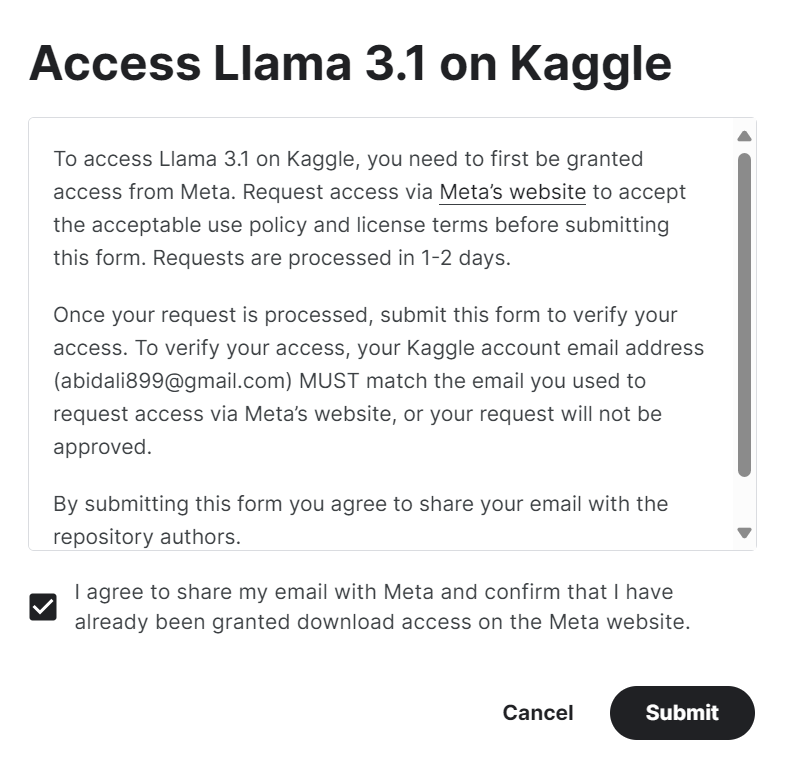
3. Inicia el cuaderno Kaggle con los modelos Llama 3.1 haciendo clic en el botón "Código" disponible en la parte superior derecha de la página del modelo.
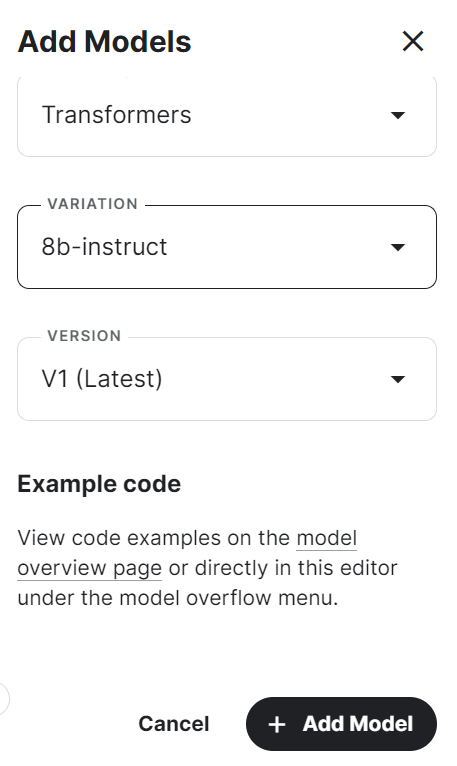
4. Selecciona el marco, la variación y la versión, y pulsa el botón "Añadir modelo".
5. Instala los paquetes Python necesarios en el cuaderno Kaggle utilizando el siguiente comando:
%pip install -U transformers accelerate6. Carga el modelo y el tokenizador utilizando la biblioteca Transformers del directorio local.
7. Crea el canal de generación de texto con el modelo, el tokenizador, el tipo de antorcha y el mapa de dispositivos.
from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)8. Escribe el mensaje y conviértelo en el aviso adecuado utilizando la plantilla de chat.
9. Ejecuta la tubería utilizando el prompt e imprime la salida generada.
messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])La respuesta es precisa y detallada.

Si tienes dificultades para ejecutar la inferencia del modelo, consulta el Cuaderno Kaggle en Llama 3.1 Inferencia simple del modelo.
Ahora debemos cargar el conjunto de datos, procesarlo y ajustar el modelo Llama 3.1. También compararemos el rendimiento del modelo antes y después del ajuste.
Si eres nuevo en los LLM, te recomiendo que realices el curso Dominar los Conceptos de los Grandes Modelos Lingüísticos (LLM) antes de sumergirte en la parte de ajuste del tutorial.
En primer lugar, iniciaremos el nuevo cuaderno Kaggle y el modelo Llama 3.1 tal y como hicimos en la sección anterior.
A continuación, instalaremos los paquetes de Python necesarios, como se indica a continuación:
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlA continuación, añadimos el Análisis de Sentimiento para la Salud Mental en el cuaderno Kaggle. Para ello, haz clic en el botón "Añadir entrada" situado en la parte superior derecha y pega el enlace del modelo en la barra de búsqueda. Después, para añadir el modelo, simplemente haz clic en el botón más (+).
Seguiremos el rendimiento del modelo utilizando la API de Pesos y Sesgos. Para acceder a la API, necesitamos la clave API. Configura la clave API en Kaggle utilizando Secretos y actívala, como se muestra a continuación.
A continuación, podemos iniciar el proyecto Pesos y sesgos utilizando la clave API.
import wandb
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune llama-3.1-8b-it on Sentiment Analysis Dataset',
job_type="training",
anonymous="allow"
)A continuación, tenemos que importar todos los paquetes y funciones de Python necesarios.
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
from sklearn.model_selection import train_test_splitAhora es el momento de cargar el conjunto de datos, realizar la limpieza de datos y eliminar tres categorías ambiguas.
Para simplificar las cosas, suprimiremos la categoría "Suicida" porque Llama 3.1 tiene mecanismos de seguridad para impedir ciertas palabras desencadenantes. El "Estrés" no se considera un trastorno mental, y el "Trastorno de la Personalidad" se solapa mucho con el "Trastorno Bipolar".
Como resultado, nos quedaremos sólo con cuatro categorías: "Normal", "Depresión", "Ansiedad" y "Bipolar".
df = pd.read_csv("/kaggle/input/sentiment-analysis-for-mental-health/Combined Data.csv",index_col = "Unnamed: 0")
df.loc[:,'status'] = df.loc[:,'status'].str.replace('Bi-Polar','Bipolar')
df = df[(df.status != "Personality disorder") & (df.status != "Stress") & (df.status != "Suicidal")]
df.head()
Para ahorrar tiempo de entrenamiento, afinaremos el modelo sólo con 3000 muestras. Para ello, barajaremos el conjunto de datos y seleccionaremos 3000 filas.
A continuación, dividiremos el conjunto de datos en los conjuntos de entrenamiento, evaluación y prueba para el entrenamiento y la prueba del modelo.
También queremos crear la columna "texto" en los conjuntos de entrenamiento y evaluación utilizando la función generate_prompt, que combina los datos de las columnas "declaración" y "estado".
Por último, crearemos la columna "texto" en el conjunto de prueba utilizando la función generate_test_prompt y la y_true utilizando la columna "estado". Lo utilizaremos para generar el informe de evaluación del modelo, como se muestra a continuación.
# Shuffle the DataFrame and select only 3000 rows
df = df.sample(frac=1, random_state=85).reset_index(drop=True).head(3000)
# Split the DataFrame
train_size = 0.8
eval_size = 0.1
# Calculate sizes
train_end = int(train_size * len(df))
eval_end = train_end + int(eval_size * len(df))
# Split the data
X_train = df[:train_end]
X_eval = df[train_end:eval_end]
X_test = df[eval_end:]
# Define the prompt generation functions
def generate_prompt(data_point):
return f"""
Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {data_point["statement"]}
label: {data_point["status"]}""".strip()
def generate_test_prompt(data_point):
return f"""
Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {data_point["statement"]}
label: """.strip()
# Generate prompts for training and evaluation data
X_train.loc[:,'text'] = X_train.apply(generate_prompt, axis=1)
X_eval.loc[:,'text'] = X_eval.apply(generate_prompt, axis=1)
# Generate test prompts and extract true labels
y_true = X_test.loc[:,'status']
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])Llegados a este punto, queremos comprobar la distribución de las categorías en el conjunto de trenes.
X_train.status.value_counts()Puedes ver a continuación que tenemos una distribución casi igual de las categorías "Normal" y "Depresión". El resto de las etiquetas son minoritarias. Esto significa que nuestro conjunto de datos está desequilibrado, y que el modelo predecirá mejor las etiquetas mayoritarias que las minoritarias.
Podemos equilibrar el conjunto de datos, pero ése no es el objetivo de este tutorial.
status
Normal 1028
Depression 938
Anxiety 258
Bipolar 176
Name: count, dtype: int64Así que, a continuación, queremos convertir el conjunto de entrenamiento y evaluación en los conjuntos de datos Cara Abrazada.
# Convert to datasets
train_data = Dataset.from_pandas(X_train[["text"]])
eval_data = Dataset.from_pandas(X_eval[["text"]])A continuación, mostramos la 4ª muestra de la columna "texto".
train_data['text'][3]Vemos que la columna "texto" tiene como etiquetas un aviso del sistema, la declaración y los estados.

A continuación, queremos cargar el modelo Llama-3.1-8b-instruct en 4 bits cuantización para ahorrar memoria de la GPU.
A continuación, cargaremos el tokenizador y estableceremos el identificador del token de almohadilla.
base_model_name = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype="float16",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token_id = tokenizer.eos_token_idAquí creamos la función predict, que utilizará la canalización de generación de texto para predecir etiquetas a partir de la columna "texto". La ejecución de la función devolverá una lista de categorías de trastornos mentales basada en varias muestras del conjunto de pruebas.
def predict(test, model, tokenizer):
y_pred = []
categories = ["Normal", "Depression", "Anxiety", "Bipolar"]
for i in tqdm(range(len(test))):
prompt = test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=2,
temperature=0.1)
result = pipe(prompt)
answer = result[0]['generated_text'].split("label:")[-1].strip()
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_pred
y_pred = predict(X_test, model, tokenizer)100%|██████████| 300/300 [02:54<00:00, 1.72it/s]Después, creamos la función evaluate que utilizará las etiquetas predichas y las etiquetas verdaderas para calcular la precisión global del modelo y la precisión por categoría, generar un informe de clasificación e imprimir una matriz de confusión. Ejecutando la función obtendremos un resumen detallado de la evaluación del modelo.
def evaluate(y_true, y_pred):
labels = ["Normal", "Depression", "Anxiety", "Bipolar"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(x, -1) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f'Accuracy: {accuracy:.3f}')
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {labels[label]}: {label_accuracy:.3f}')
# Generate classification report
class_report = classification_report(y_true=y_true_mapped, y_pred=y_pred_mapped, target_names=labels, labels=list(range(len(labels))))
print('\nClassification Report:')
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels))))
print('\nConfusion Matrix:')
print(conf_matrix)
evaluate(y_true, y_pred)Llama 3.1 ha tenido un rendimiento excepcional, incluso sin ajuste fino. Un 79% de precisión es suficiente. Veamos cómo mejora nuestro modelo cuando lo afinamos en el conjunto de datos.
Accuracy: 0.790
Accuracy for label Normal: 0.741
Accuracy for label Depression: 0.939
Accuracy for label Anxiety: 0.556
Accuracy for label Bipolar: 0.533
Classification Report:
precision recall f1-score support
Normal 0.92 0.74 0.82 143
Depression 0.70 0.94 0.80 115
Anxiety 0.68 0.56 0.61 27
Bipolar 0.89 0.53 0.67 15
accuracy 0.79 300
macro avg 0.80 0.69 0.73 300
weighted avg 0.81 0.79 0.79 300
Confusion Matrix:
[[106 33 4 0]
[ 3 108 3 1]
[ 4 8 15 0]
[ 2 5 0 8]]Al construir el modelo, empezamos por extraer los nombres de los módulos lineales del modelo utilizando la biblioteca bits and bytes.
A continuación, configuramos LoRA utilizando los módulos objetivo, el tipo de tarea y otros argumentos antes de configurar los argumentos de entrenamiento. Estos argumentos de entrenamiento están optimizados para el cuaderno Kaggle. Puede que tengas que cambiarlos si los utilizas localmente.
A continuación, crearemos el modelo entrenador utilizando argumentos de entrenamiento, un modelo, un tokenizador, una configuración LoRA y un conjunto de datos.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)
modules['down_proj', 'gate_proj', 'o_proj', 'v_proj', 'up_proj', 'q_proj', 'k_proj']output_dir="llama-3.1-fine-tuned-model"
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules,
)
training_arguments = TrainingArguments(
output_dir=output_dir, # directory to save and repository id
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_accumulation_steps=8, # number of steps before performing a backward/update pass
gradient_checkpointing=True, # use gradient checkpointing to save memory
optim="paged_adamw_32bit",
logging_steps=1,
learning_rate=2e-4, # learning rate, based on QLoRA paper
weight_decay=0.001,
fp16=True,
bf16=False,
max_grad_norm=0.3, # max gradient norm based on QLoRA paper
max_steps=-1,
warmup_ratio=0.03, # warmup ratio based on QLoRA paper
group_by_length=False,
lr_scheduler_type="cosine", # use cosine learning rate scheduler
report_to="wandb", # report metrics to w&b
eval_strategy="steps", # save checkpoint every epoch
eval_steps = 0.2
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=512,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)Ha llegado el momento de iniciar el entrenamiento del modelo:
trainer.train()Tardamos 1,5 horas en afinar el modelo, y nuestra pérdida de validación ha disminuido gradualmente. Para obtener un rendimiento aún mejor, intenta entrenar el modelo con el conjunto de datos completo durante al menos cinco épocas.
A continuación, terminamos la ejecución de los pesos y sesgos.
wandb.finish()
model.config.use_cache = TruePodremos ver el resumen de la ejecución, incluyendo todas las métricas necesarias para el rendimiento del modelo.
Para ver un resumen detallado, ve a tu cuenta de Pesos y Parciales y visualiza la ejecución en tu navegador. Viene con visualizaciones interactivas.
A continuación, podemos guardar localmente tanto el adaptador del modelo como el tokenizador. En la siguiente sección, lo utilizaremos para fusionar el adoptante con el modelo base.
# Save trained model and tokenizer
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)Ahora viene la parte más crucial. ¿Nuestro modelo funcionará mejor después de afinarlo, o empeorará? Para averiguarlo, debemos ejecutar la función "predecir" en el conjunto de pruebas y luego la función "evaluar" para generar un informe de evaluación del modelo.
y_pred = predict(X_test, model, tokenizer)
evaluate(y_true, y_pred)Como puedes ver en los resultados que aparecen a continuación, se trata de una enorme mejora en el rendimiento del modelo, del 79% al 91,3% de precisión. Incluso las puntuaciones de F1 tienen buena pinta.
100%|██████████| 300/300 [03:24<00:00, 1.47it/s]
Accuracy: 0.913
Accuracy for label Normal: 0.972
Accuracy for label Depression: 0.913
Accuracy for label Anxiety: 0.667
Accuracy for label Bipolar: 0.800
Classification Report:
precision recall f1-score support
Normal 0.92 0.97 0.95 143
Depression 0.93 0.91 0.92 115
Anxiety 0.75 0.67 0.71 27
Bipolar 1.00 0.80 0.89 15
accuracy 0.91 300
macro avg 0.90 0.84 0.87 300
weighted avg 0.91 0.91 0.91 300
Confusion Matrix:
[[139 3 1 0]
[ 5 105 5 0]
[ 6 3 18 0]
[ 1 2 0 12]]Ahora podemos guardar el cuaderno Kaggle para guardar los resultados y los archivos del modelo. Para ello, hacemos clic en el botón "Guardar versión" de la parte superior derecha, seleccionamos el tipo de versión "Guardado rápido" y seleccionamos el tipo de salida de guardado "Guardar siempre la salida al crear un Guardado rápido".
Si tienes problemas para ajustar el modelo, consulta el cuaderno Kaggle cuaderno para obtener más ayuda.
También puedes aprender a afinar los modelos Llama 3.0 siguiendo nuestra guía, Ajuste fino de Llama 3 y uso local.
En esta sección, fusionaremos el adaptador con el modelo base y guardaremos la versión completa en el hub Cara Abrazada.
Primero, lanzamos un nuevo cuaderno Kaggle con aceleración por GPU y añadimos el cuaderno guardado para acceder a los archivos del modelo. También podemos incluir otros cuadernos Kaggle como entrada, de forma similar a añadir un conjunto de datos.
A continuación, podemos instalar los paquetes de Python necesarios.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peftA continuación, iniciamos sesión en el hub API de Hugging Face utilizando la clave API para introducir nuestros archivos de modelo en el repositorio de modelos de Hugging Face.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)A continuación, podemos establecer el directorio del modelo base y del modelo afinado.
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
fine_tuned_model = "/kaggle/input/fine-tune-llama-3-1-for-text-classification/llama-3.1-fine-tuned-model/"A continuación, carga el tokenizador y el modelo base.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)Fusionamos el modelo base con el adaptador afinado, como se ve a continuación.
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, fine_tuned_model)
model = model.merge_and_unload()Antes de guardar nuestro modelo, comprobemos si funciona correctamente. Crea una canalización de generación de texto con el modelo y el tokenizador, y proporciónale el aviso de muestra.
text = "I'm trapped in a storm of emotions that I can't control, and it feels like no one understands the chaos inside me"
prompt = f"""Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {text}
label: """.strip()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=2, do_sample=True, temperature=0.1)
print(outputs[0]["generated_text"].split("label: ")[-1].strip())Nuestro modelo funciona perfectamente.
DepressionAhora podemos guardar el modelo y el tokenizador localmente.
model_dir = "Llama-3.1-8B-Instruct-Mental-Health-Classification"
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)Y luego empuja el modelo y el tokenizador al Hub Cara Abrazada.
model.push_to_hub(model_dir, use_temp_dir=False)
tokenizer.push_to_hub(model_dir, use_temp_dir=False)Esto creará el repositorio en Cara Abrazada y empujará todos los archivos del modelo y del tokenizador.
CommitInfo(commit_url='https://huggingface.co/kingabzpro/Llama-3.1-8B-Instruct-Mental-Health-Classification/commit/e1244abeaac159e0a48439095200a4190c2b493c', commit_message='Upload tokenizer', commit_description='', oid='e1244abeaac159e0a48439095200a4190c2b493c', pr_url=None, pr_revision=None, pr_num=None)Podemos ver todos los archivos de los modelos visitando el sitio web de Hugging Face.
Fuente: kingabzpro/Llama-3.1-8B-Instrucción-Clasificación-Salud-Mental - Cara de abrazo
Si tienes problemas para fusionar el adaptador con el modelo base, consulta el cuaderno Kaggle.
Si te resulta difícil afinar los LLM, puedes seguir la páginaAfinar el GPT-4 de OpenAI: Una guía paso a paso tutorial para aprender una forma más sencilla de utilizar la API de OpenAI para afinar el modelo en cualquier conjunto de datos con sólo unas pocas líneas de código.
El ajuste del modelo no se limita a la personalización basada en el conjunto de datos. Podemos afinar grandes modelos lingüísticos en diversas tareas de lenguaje natural, como traducción automática, agrupación, clasificación, preguntas y respuestas, incrustación, etc.
En este tutorial, hemos aprendido a afinar el modelo Llama 3.1 en un conjunto de datos de clasificación de salud mental. Este modelo puede utilizarse para identificar a los pacientes e incluso a los empleados que se enfrentan a retos en su vida cotidiana.
Si te preguntas cómo puedes iniciarte en los LLM y empezar a afinar modelos por tu cuenta, entonces deberías considerar la posibilidad de cursar el curso Desarrollo de grandes modelos lingüísticos para desarrollar grandes modelos lingüísticos. Con esta serie de cursos, construirás una base sólida en LLM, que te impulsará hacia el nuevo panorama impulsado por la IA.
Top Cursos DataCamp LLM
programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita

