
Cursus
Développer des LLM
16 h
Avant de commencer, une remarque : lorsque l'on aborde les cas d'utilisation de l'IA dans le domaine de la santé, il est extrêmement important d'être attentif aux conséquences potentiellement néfastes pour les patients. L'exemple ci-dessous, bien que complet, vise uniquement à illustrer la mise au point sur un ensemble de données réelles. Si vous souhaitez utiliser l'IA dans le domaine de la santé ou dans d'autres domaines sensibles, nous vous recommandons vivement de lire notre guide sur l'éthique de l'IA.
Dans ce tutoriel, nous allons découvrir les modèles Llama 3.1 et affiner le modèle Llama-3.1-8b-It sur l'analyse des sentiments pour l'ensemble de données sur la santé mentale. Notre objectif est de personnaliser le modèle afin qu'il puisse prédire l'état de santé mentale du patient sur la base du texte. Nous fusionnerons également l'adaptateur avec le modèle basé et enregistrerons le modèle complet sur le hub de Hugging Face.
Nous apprendrons à connaître les modèles Llama 3.1, à y accéder sur Kaggle et à utiliser la bibliothèque Transformer pour exécuter l'inférence du modèle. Nous allons également affiner le modèle Llama-3.1-8b-It sur l'ensemble de données de classification de la santé mentale. Enfin, nous fusionnerons l'adaptateur sauvegardé avec le modèle de base et pousserons le modèle complet vers le Hugging Face Hub.
Si vous êtes novice en la matière, vous pouvez vous familiariser avec la théorie du réglage fin en lisant notre article, Guide d'introduction aux LLM de précision.

Image par l'auteur
Llama 3.1 est la dernière série de grands modèles linguistiques multilingues (LLM) développés par Meta AI, qui repoussent les limites de la compréhension et de la génération de langues. Il existe en trois tailles : Les paramètres 8B, 70B et 405B.
Les modèles Llama 3.1 sont construits sur une architecture de modèle de langage auto-régressif avec des transformateurs optimisés et peuvent être affinés pour diverses tâches de traitement du langage naturel et ensembles de données. Ils sont formés sur un ensemble diversifié de données en ligne accessibles au public, prennent en charge huit langues (anglais, allemand, français, italien, portugais, hindi, espagnol et thaï) et disposent d'une longueur de contexte de 128k.
Les modèles de lama 3.1 sont disponibles pour tous sous des licences commerciales personnalisées et nécessitent un minimum d'informations sur l'individu pour télécharger les poids du modèle.
Llama 3.1 est optimisé pour le dialogue multilingue et a surpassé Gemma 2, GPT 3.5 turbo, et GPT-4o sur divers critères, y compris le chat général, le codage, les mathématiques, le raisonnement, et plus encore. C'est de loin le modèle open-source le plus rapide et le plus précis disponible.
Source : Llama 3.1 (meta.com)
Pour en savoir plus sur le modèle Llama 3.1, consultez le siteQu'est-ce que le Llama 3.1 405B de Meta ? Comment ça marche, les cas d'utilisation et plus encore.
Pour ce tutoriel, nous utiliserons Kaggle Notebook comme environnement de développement car il offre gratuitement des GPU et des TPU. Pour utiliser le modèle Llama 3.1 sur le carnet Kaggle, suivez ces étapes :
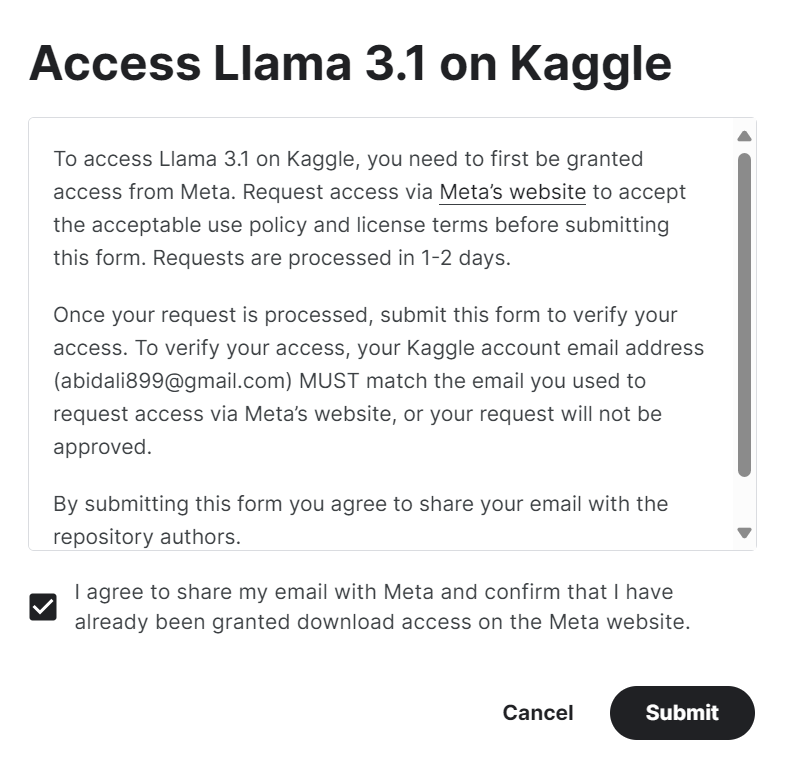
1. Remplissez le formulaire sur meta.com avec la même adresse email que votre compte Kaggle.
2. Accédez à la Meta | Llama 3.1 sur Kaggle et cliquez sur le bouton "accéder au modèle". Acceptez toutes les conditions, et après quelques secondes, vous aurez accès au modèle.
3. Lancez le carnet Kaggle avec les modèles Llama 3.1 en cliquant sur le bouton "Code" disponible en haut à droite de la page du modèle.
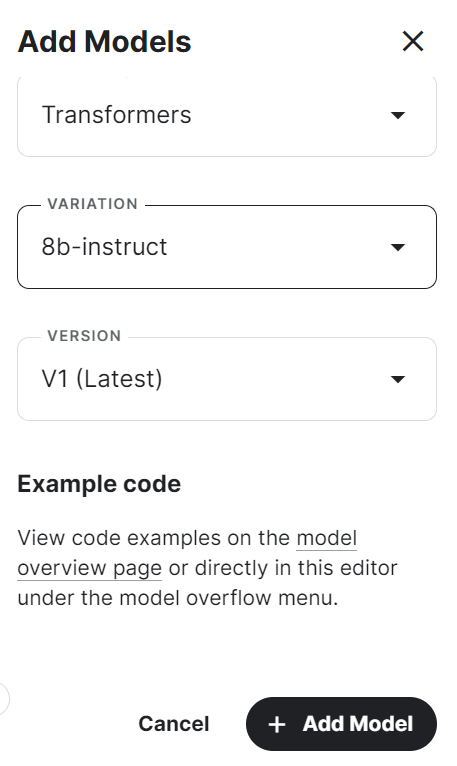
4. Sélectionnez le cadre, la variation et la version, puis cliquez sur le bouton "Ajouter un modèle".
5. Installez les paquets Python nécessaires dans le notebook Kaggle à l'aide de la commande suivante :
%pip install -U transformers accelerate6. Chargez le modèle et le tokenizer à l'aide de la bibliothèque Transformers du répertoire local.
7. Créez le pipeline de génération de texte avec le modèle, le tokenizer, le type de torche et la carte des appareils.
from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)8. Rédigez le message et convertissez-le en une invite appropriée à l'aide du modèle de chat.
9. Exécutez le pipeline à l'aide de l'invite et imprimez la sortie générée.
messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])La réponse est précise et détaillée.

Si vous rencontrez des difficultés dans l'exécution de l'inférence du modèle, veuillez vous référer au Carnet de notes Kaggle à l'adresse suivante Llama 3.1 Inférence de modèle simple.
Nous devons maintenant charger le jeu de données, le traiter et affiner le modèle du lama 3.1. Nous comparerons également les performances du modèle avant et après la mise au point.
Si vous êtes novice en matière de LLM, je vous recommande de suivre la formation suivante Maîtriser les concepts des grands modèles de langage (LLM) avant de vous plonger dans la partie du tutoriel consacrée à la mise au point.
Tout d'abord, nous allons démarrer le nouveau notebook Kaggle et le modèle Llama 3.1 comme nous l'avons fait dans la section précédente.
Nous installerons ensuite les paquets Python nécessaires, comme indiqué ci-dessous :
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlEnsuite, nous ajoutons le Analyse de sentiments pour la santé mentale dans le carnet Kaggle. Pour ce faire, cliquez sur le bouton "Ajouter une entrée" situé en haut à droite et collez le lien du modèle dans la barre de recherche. Ensuite, pour ajouter le modèle, il suffit de cliquer sur le bouton plus (+).
Nous assurerons le cursus des performances du modèle à l'aide de l'API "Pondérations et biais". Pour accéder à l'API, nous avons besoin de la clé API. Configurez la clé API dans Kaggle en utilisant Secrets et activez-la, comme indiqué ci-dessous.
Nous pouvons ensuite lancer le projet Weights and Biases en utilisant la clé API.
import wandb
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune llama-3.1-8b-it on Sentiment Analysis Dataset',
job_type="training",
anonymous="allow"
)Ensuite, nous devons importer tous les paquets et fonctions Python nécessaires.
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
from sklearn.model_selection import train_test_splitIl est maintenant temps de charger l'ensemble de données, d'effectuer un nettoyage des données et de supprimer trois catégories ambiguës.
Pour simplifier les choses, nous allons supprimer la catégorie "Suicidaire" car Llama 3.1 dispose de mécanismes de sécurité qui empêchent l'utilisation de certains mots déclencheurs. Le "stress" n'est pas considéré comme un trouble mental, et les "troubles de la personnalité" se recoupent largement avec les "troubles bipolaires".
Il ne reste donc plus que quatre catégories : "Normal", "Dépression", "Anxiété" et "Bipolaire".
df = pd.read_csv("/kaggle/input/sentiment-analysis-for-mental-health/Combined Data.csv",index_col = "Unnamed: 0")
df.loc[:,'status'] = df.loc[:,'status'].str.replace('Bi-Polar','Bipolar')
df = df[(df.status != "Personality disorder") & (df.status != "Stress") & (df.status != "Suicidal")]
df.head()
Pour économiser du temps de formation, nous allons affiner le modèle sur seulement 3000 échantillons. Pour cela, nous allons mélanger l'ensemble des données et sélectionner 3000 lignes.
Nous diviserons ensuite l'ensemble de données en ensembles de formation, d'évaluation et de test pour la formation et le test du modèle.
Nous voulons également créer la colonne "text" dans les ensembles train et eval à l'aide de la fonction generate_prompt, qui combine les données des colonnes "statement" et "status".
Enfin, nous créerons la colonne "text" dans le jeu de test à l'aide de la fonction generate_test_prompt et la colonne "status" à l'aide de la fonction y_true. Nous l'utiliserons pour générer le rapport d'évaluation du modèle, comme indiqué ci-dessous.
# Shuffle the DataFrame and select only 3000 rows
df = df.sample(frac=1, random_state=85).reset_index(drop=True).head(3000)
# Split the DataFrame
train_size = 0.8
eval_size = 0.1
# Calculate sizes
train_end = int(train_size * len(df))
eval_end = train_end + int(eval_size * len(df))
# Split the data
X_train = df[:train_end]
X_eval = df[train_end:eval_end]
X_test = df[eval_end:]
# Define the prompt generation functions
def generate_prompt(data_point):
return f"""
Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {data_point["statement"]}
label: {data_point["status"]}""".strip()
def generate_test_prompt(data_point):
return f"""
Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {data_point["statement"]}
label: """.strip()
# Generate prompts for training and evaluation data
X_train.loc[:,'text'] = X_train.apply(generate_prompt, axis=1)
X_eval.loc[:,'text'] = X_eval.apply(generate_prompt, axis=1)
# Generate test prompts and extract true labels
y_true = X_test.loc[:,'status']
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])À ce stade, nous souhaitons vérifier la répartition des catégories dans l'ensemble de données.
X_train.status.value_counts()Vous pouvez voir ci-dessous que la répartition des catégories "Normal" et "Dépression" est presque égale. Les autres labels sont minoritaires. Cela signifie que notre ensemble de données est déséquilibré et que le modèle prédit mieux les étiquettes de la majorité que celles de la minorité.
Nous pouvons équilibrer l'ensemble des données, mais ce n'est pas l'objectif de ce tutoriel.
status
Normal 1028
Depression 938
Anxiety 258
Bipolar 176
Name: count, dtype: int64Ensuite, nous voulons convertir les ensembles de formation et d'évaluation en ensembles de données Hugging Face.
# Convert to datasets
train_data = Dataset.from_pandas(X_train[["text"]])
eval_data = Dataset.from_pandas(X_eval[["text"]])Ensuite, nous affichons le quatrième échantillon de la colonne "texte".
train_data['text'][3]Nous constatons que la colonne "texte" comporte une invite système, la déclaration et les statuts en tant qu'étiquettes.

Ensuite, nous voulons charger le modèle Llama-3.1-8b-instruct en quantification 4 bits. quantification de 4 bits pour économiser la mémoire du GPU.
Nous allons ensuite charger le tokenizer et définir l'identifiant du token pad.
base_model_name = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype="float16",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token_id = tokenizer.eos_token_idNous créons ici la fonction predict, qui utilisera le pipeline de génération de texte pour prédire les étiquettes de la colonne "texte". L'exécution de la fonction renvoie une liste de catégories de troubles mentaux basée sur divers échantillons de l'ensemble de tests.
def predict(test, model, tokenizer):
y_pred = []
categories = ["Normal", "Depression", "Anxiety", "Bipolar"]
for i in tqdm(range(len(test))):
prompt = test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=2,
temperature=0.1)
result = pipe(prompt)
answer = result[0]['generated_text'].split("label:")[-1].strip()
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_pred
y_pred = predict(X_test, model, tokenizer)100%|██████████| 300/300 [02:54<00:00, 1.72it/s]Ensuite, nous créons la fonction evaluate qui utilisera les étiquettes prédites et les vraies étiquettes pour calculer la précision globale du modèle et la précision par catégorie, générer un rapport de classification et imprimer une matrice de confusion. L'exécution de la fonction nous donnera un résumé détaillé de l'évaluation du modèle.
def evaluate(y_true, y_pred):
labels = ["Normal", "Depression", "Anxiety", "Bipolar"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(x, -1) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f'Accuracy: {accuracy:.3f}')
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {labels[label]}: {label_accuracy:.3f}')
# Generate classification report
class_report = classification_report(y_true=y_true_mapped, y_pred=y_pred_mapped, target_names=labels, labels=list(range(len(labels))))
print('\nClassification Report:')
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels))))
print('\nConfusion Matrix:')
print(conf_matrix)
evaluate(y_true, y_pred)Llama 3.1 a obtenu des résultats exceptionnels, même sans ajustement. Une précision de 79 % est suffisante. Voyons comment notre modèle s'améliore lorsque nous l'affinons sur l'ensemble des données.
Accuracy: 0.790
Accuracy for label Normal: 0.741
Accuracy for label Depression: 0.939
Accuracy for label Anxiety: 0.556
Accuracy for label Bipolar: 0.533
Classification Report:
precision recall f1-score support
Normal 0.92 0.74 0.82 143
Depression 0.70 0.94 0.80 115
Anxiety 0.68 0.56 0.61 27
Bipolar 0.89 0.53 0.67 15
accuracy 0.79 300
macro avg 0.80 0.69 0.73 300
weighted avg 0.81 0.79 0.79 300
Confusion Matrix:
[[106 33 4 0]
[ 3 108 3 1]
[ 4 8 15 0]
[ 2 5 0 8]]Lors de la construction du modèle, nous commençons par extraire les noms des modules linéaires du modèle à l'aide de la bibliothèque bits and bytes.
Nous configurons ensuite LoRA à l'aide des modules cibles, du type de tâche et d'autres arguments avant de définir les arguments de formation. Ces arguments d'entraînement sont optimisés pour le carnet Kaggle. Vous devrez peut-être les modifier si vous les utilisez localement.
Nous créerons ensuite l'entraîneur de modèle en utilisant des arguments d'entraînement, un modèle, un tokenizer, une configuration LoRA et un ensemble de données.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)
modules['down_proj', 'gate_proj', 'o_proj', 'v_proj', 'up_proj', 'q_proj', 'k_proj']output_dir="llama-3.1-fine-tuned-model"
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules,
)
training_arguments = TrainingArguments(
output_dir=output_dir, # directory to save and repository id
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_accumulation_steps=8, # number of steps before performing a backward/update pass
gradient_checkpointing=True, # use gradient checkpointing to save memory
optim="paged_adamw_32bit",
logging_steps=1,
learning_rate=2e-4, # learning rate, based on QLoRA paper
weight_decay=0.001,
fp16=True,
bf16=False,
max_grad_norm=0.3, # max gradient norm based on QLoRA paper
max_steps=-1,
warmup_ratio=0.03, # warmup ratio based on QLoRA paper
group_by_length=False,
lr_scheduler_type="cosine", # use cosine learning rate scheduler
report_to="wandb", # report metrics to w&b
eval_strategy="steps", # save checkpoint every epoch
eval_steps = 0.2
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=512,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)Il est maintenant temps d'initier la formation au modèle :
trainer.train()Il a fallu 1,5 heure pour affiner le modèle, et notre perte de validation a progressivement diminué. Pour obtenir des performances encore meilleures, essayez d'entraîner le modèle sur l'ensemble des données pendant au moins cinq époques.
Ensuite, nous terminons l'exécution des poids et des biais.
wandb.finish()
model.config.use_cache = TrueNous serons en mesure d'afficher le résumé de l'exécution, y compris toutes les mesures nécessaires pour la performance du modèle.
Pour obtenir un résumé détaillé, accédez à votre compte Pondérations et Biais et visualisez la série dans votre navigateur. Il est accompagné de visualisations interactives.
Nous pouvons alors enregistrer localement l'adaptateur de modèle et le tokenizer. Dans la section suivante, nous l'utiliserons pour fusionner le modèle adoptif avec le modèle de base.
# Save trained model and tokenizer
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)Vient maintenant la partie la plus cruciale. Notre modèle sera-t-il plus performant après l'avoir affiné ou se dégradera-t-il ? Pour le savoir, nous devons exécuter la fonction "predict" sur l'ensemble de test, puis la fonction "evaluate" pour générer un rapport d'évaluation du modèle.
y_pred = predict(X_test, model, tokenizer)
evaluate(y_true, y_pred)Comme vous pouvez le constater dans les résultats ci-dessous, il s'agit d'une amélioration considérable des performances du modèle, dont la précision passe de 79 % à 91,3 %. Même les résultats de la F1 sont bons.
100%|██████████| 300/300 [03:24<00:00, 1.47it/s]
Accuracy: 0.913
Accuracy for label Normal: 0.972
Accuracy for label Depression: 0.913
Accuracy for label Anxiety: 0.667
Accuracy for label Bipolar: 0.800
Classification Report:
precision recall f1-score support
Normal 0.92 0.97 0.95 143
Depression 0.93 0.91 0.92 115
Anxiety 0.75 0.67 0.71 27
Bipolar 1.00 0.80 0.89 15
accuracy 0.91 300
macro avg 0.90 0.84 0.87 300
weighted avg 0.91 0.91 0.91 300
Confusion Matrix:
[[139 3 1 0]
[ 5 105 5 0]
[ 6 3 18 0]
[ 1 2 0 12]]Nous pouvons maintenant enregistrer le carnet Kaggle pour sauvegarder les résultats et les fichiers de modèle. Pour ce faire, nous cliquons sur le bouton "Enregistrer la version" en haut à droite, nous sélectionnons le type de version "Enregistrement rapide" et nous sélectionnons le type de sortie d'enregistrement "Toujours enregistrer la sortie lors de la création d'un enregistrement rapide".
Si vous avez des difficultés à affiner le modèle, veuillez vous référer au Kaggle Kaggle pour obtenir de l'aide.
Vous pouvez également apprendre à peaufiner les modèles de Llama 3.0 en suivant notre guide, Ajuster Llama 3 et l'utiliser localement.
Dans cette section, nous allons fusionner l'adaptateur avec le modèle de base et enregistrer la version complète sur le concentrateur Hugging Face.
Tout d'abord, nous lançons un nouveau bloc-notes Kaggle avec accélération GPU et ajoutons le bloc-notes sauvegardé pour accéder aux fichiers de modèle. Nous pouvons également inclure d'autres carnets Kaggle en entrée, de la même manière que nous ajoutons un ensemble de données.
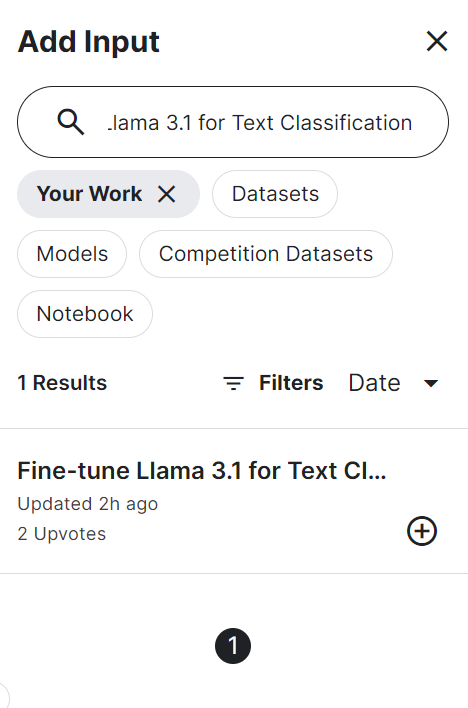
Nous pouvons ensuite installer les paquets Python nécessaires.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peftEnsuite, nous nous connectons à l'API hub de Hugging Face en utilisant la clé API pour pousser nos fichiers de modèle dans le référentiel de modèles de Hugging Face.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Nous pouvons ensuite définir le répertoire du modèle de base et du modèle affiné.
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
fine_tuned_model = "/kaggle/input/fine-tune-llama-3-1-for-text-classification/llama-3.1-fine-tuned-model/"Chargez ensuite le tokenizer et le modèle de base.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)Nous fusionnons le modèle de base avec l'adaptateur perfectionné, comme indiqué ci-dessous.
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, fine_tuned_model)
model = model.merge_and_unload()Avant d'enregistrer notre modèle, vérifions qu'il fonctionne correctement. Créez un pipeline de génération de texte avec le modèle et le tokenizer et fournissez-lui l'exemple d'invite.
text = "I'm trapped in a storm of emotions that I can't control, and it feels like no one understands the chaos inside me"
prompt = f"""Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {text}
label: """.strip()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=2, do_sample=True, temperature=0.1)
print(outputs[0]["generated_text"].split("label: ")[-1].strip())Notre modèle fonctionne parfaitement.
DepressionNous pouvons maintenant sauvegarder le modèle et le tokenizer localement.
model_dir = "Llama-3.1-8B-Instruct-Mental-Health-Classification"
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)Puis envoyez le modèle et le tokenizer au Hub Hugging Face.
model.push_to_hub(model_dir, use_temp_dir=False)
tokenizer.push_to_hub(model_dir, use_temp_dir=False)Cela créera le dépôt sur Hugging Face et poussera tous les fichiers de modèle et de tokenizer.
CommitInfo(commit_url='https://huggingface.co/kingabzpro/Llama-3.1-8B-Instruct-Mental-Health-Classification/commit/e1244abeaac159e0a48439095200a4190c2b493c', commit_message='Upload tokenizer', commit_description='', oid='e1244abeaac159e0a48439095200a4190c2b493c', pr_url=None, pr_revision=None, pr_num=None)On peut consulter tous les fichiers modèles en visitant le site web de Hugging Face.
Source : kingabzpro/Llama-3.1-8B-Instruct-Mental-Health-Classification - Hugging Face
Si vous rencontrez des problèmes pour fusionner l'adaptateur avec le modèle de base, veuillez vous référer au carnet Kaggle.
Si vous avez du mal à affiner les LLM, vous pouvez suivre le siteFine-Tuning OpenAI's GPT-4 : A Step-by-Step Guide tutoriel pour apprendre une façon plus facile d'utiliser l'API OpenAI pour affiner le modèle sur n'importe quel ensemble de données avec seulement quelques lignes de code.
La mise au point du modèle ne se limite pas à la personnalisation en fonction de l'ensemble des données. Nous pouvons affiner de grands modèles de langage sur diverses tâches de langage naturel telles que la traduction automatique, le regroupement, la classification, les questions et réponses, l'intégration, etc.
Dans ce tutoriel, nous avons appris à affiner le modèle Llama 3.1 sur un ensemble de données de classification de la santé mentale. Ce modèle peut être utilisé pour identifier les patients et même les employés qui sont confrontés à des difficultés dans leur vie quotidienne.
Si vous vous demandez comment vous pouvez commencer à utiliser les LLM et à affiner les modèles par vous-même, vous devriez envisager de suivre la formation sur les LLM. Développement de grands modèles de langage le cursus de compétences. Cette série de cours vous permettra d'acquérir des bases solides en matière de LLM et vous propulsera dans le nouveau paysage alimenté par l'IA.
Les meilleurs cours de DataCamp LLM
Cursus
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach