programa
Fundamentos de la IA
10 h
En este tutorial, aprenderemos a ajustar Llama 3 en un conjunto de datos médicos. También transformaremos el modelo en un formato listo para su uso local a través de la aplicación Jan.
Más concretamente
Si buscas un plan de estudios curado para aprender IA, echa un vistazo a esta pista de habilidades de seis cursos sobre Fundamentos de la IA.
Meta ha lanzado una nueva serie de grandes modelos lingüísticos (LLM) llamada Llama 3, una colección de modelos de texto a texto preentrenados y ajustados a las instrucciones.
Llama 3 es un modelo de lenguaje autorregresivo que utiliza una arquitectura de transformadores optimizada. Tanto los modelos preentrenados como los ajustados a las instrucciones vienen con parámetros de 8B y 70B con una longitud de contexto de 8K tokens.
Llama 3 8B es la LLM que más gusta en Cara de Abrazo. Su versión ajustada a las instrucciones es mejor que la Gemma 7B-It y la Mistral 7B Instruct de Google en varias métricas de rendimiento. La versión ajustada a las instrucciones 70B ha superado a Gemini Pro 1.5 y a Claude Sonnet en la mayoría de las métricas de rendimiento:
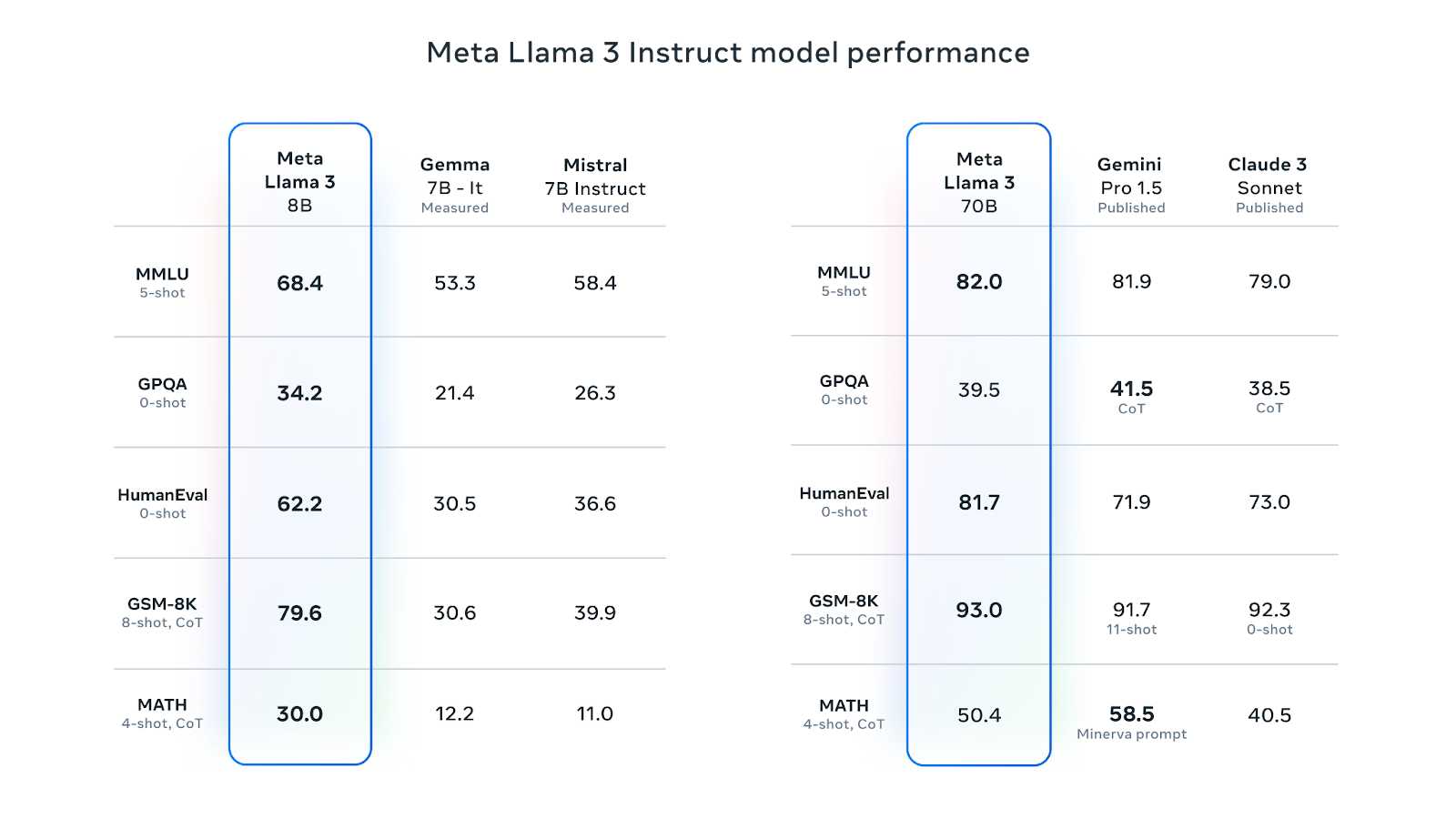
Fuente: Meta Llama 3
Meta entrenó a Llama 3 con una nueva mezcla de datos en línea disponibles públicamente, con un recuento de más de 15 billones de tokens. El modelo 8B tiene una fecha límite de conocimiento de marzo de 2023, mientras que el modelo 70B tiene una fecha límite de diciembre de 2023. Los modelos utilizan la Atención a las Consultas Agrupadas (GQA), que reduce el ancho de banda de la memoria y mejora la eficacia.
Los modelos Llama 3 se han publicado con una licencia comercial personalizada. Para acceder al modelo, tienes que rellenar el formulario con tu nombre, afiliación y correo electrónico y aceptar los términos y condiciones. Si utilizas diferentes direcciones de correo electrónico para distintas plataformas como Kaggle y Hugging Face, puede que tengas que rellenar el formulario varias veces.
Puedes obtener más información sobre Llama 3 en este artículo sobre ¿Qué es Llama 3?
En este tutorial, pondremos a punto el modelo Llama 3 8B-Chat utilizando el conjunto de datos ruslanmv/ai-medical-chatbot. El conjunto de datos contiene 250.000 diálogos entre un paciente y un médico. Utilizaremos el Cuaderno Kaggle para acceder a este modelo y liberar GPUs.
Antes de lanzar el Cuaderno Kaggle, rellena el formulario de descarga Meta con tu dirección de correo electrónico de Kaggle, luego ve a la página del modelo Llama 3 en Kaggle y acepta el acuerdo. El proceso de aprobación puede tardar de uno a dos días.
Sigamos ahora los siguientes pasos:
1. Inicia el nuevo Cuaderno en Kaggle, y añade el modelo Llama 3 haciendo clic en el botón + Añadir entrada, seleccionando la opción Modelos, y haciendo clic en el botón más + junto al modelo Llama 3. Después, selecciona el marco, la variación y la versión adecuados, y añade el modelo.
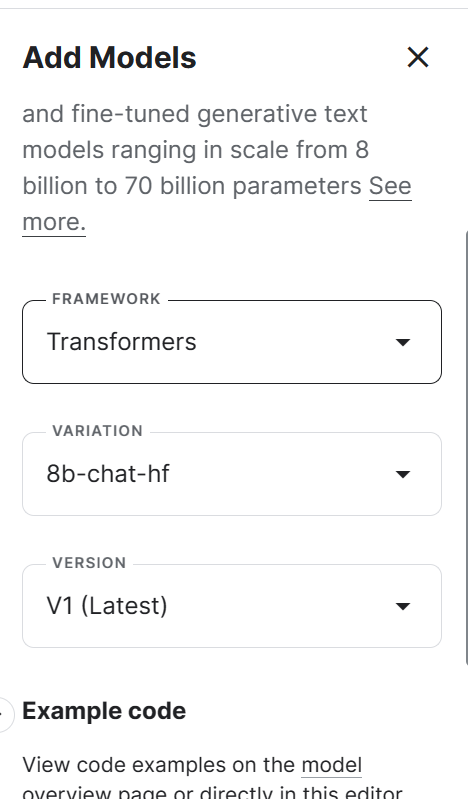
2. Ve a las opciones de la Sesión y selecciona la GPU P100 como acelerador.
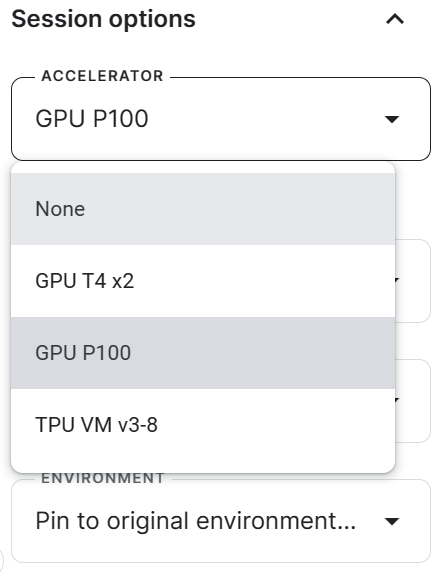
3. Genera el token Cara abrazada y Pesos y sesgos, y crea los Secretos Kaggle. Puedes crear y activar los Secretos de Kaggle yendo a Complementos > Secretos > Añadir un nuevo secreto.
4. Inicia la sesión Kaggle instalando todos los paquetes Python necesarios.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandb5. Importa las páginas de Python necesarias para cargar el conjunto de datos, el modelo y el tokenizador, y afínalos.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_format6. Seguiremos el proceso de entrenamiento utilizando Pesos y Sesgos y luego guardaremos el modelo afinado en Hugging Face, y para ello tenemos que iniciar sesión tanto en Hugging Face Hub como en Pesos y Sesgos utilizando la clave API.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama 3 8B on Medical Dataset',
job_type="training",
anonymous="allow"
)7. Establece el modelo base, el conjunto de datos y la nueva variable del modelo. Cargaremos el modelo base de Kaggle y el conjunto de datos del Hub HugginFace y luego guardaremos el nuevo modelo.
base_model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
dataset_name = "ruslanmv/ai-medical-chatbot"
new_model = "llama-3-8b-chat-doctor"8. Establece el tipo de datos y la implementación de la atención.
torch_dtype = torch.float16
attn_implementation = "eager"En esta parte, cargaremos el modelo desde Kaggle. Sin embargo, debido a limitaciones de memoria, no podemos cargar el modelo completo. Por tanto, cargaremos el modelo utilizando una precisión de 4 bits.
Nuestro objetivo en este proyecto es reducir el uso de memoria y acelerar el proceso de ajuste.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)Carga el tokenizador y, a continuación, configura un modelo y un tokenizador para tareas de IA conversacional. Por defecto, utiliza la plantilla chatml de OpenAI, que convertirá el texto introducido en un formato similar al del chat.
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
model, tokenizer = setup_chat_format(model, tokenizer)El ajuste fino del modelo completo llevará mucho tiempo, así que para mejorar el tiempo de entrenamiento, adjuntaremos la capa adaptadora con unos pocos parámetros, haciendo que todo el proceso sea más rápido y eficiente en memoria.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
model = get_peft_model(model, peft_config)Para cargar y preprocesar nuestro conjunto de datos, nosotros:
1. Carga el conjunto de datos ruslanmv/ai-medical-chatbot, revuélvelo y selecciona sólo las 1000 filas superiores. Esto reducirá significativamente el tiempo de formación.
2. Da formato a la plantilla del chat para que sea conversacional. Combina las preguntas del paciente y las respuestas del médico en una columna de "texto".
3. Muestra una muestra de la columna de texto (la columna "texto" tiene un formato similar al del chat, con tokens especiales).
#Importing the dataset
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
def format_chat_template(row):
row_json = [{"role": "user", "content": row["Patient"]},
{"role": "assistant", "content": row["Doctor"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc=4,
)
dataset['text'][3]
4. Divide el conjunto de datos en un conjunto de entrenamiento y otro de validación.
dataset = dataset.train_test_split(test_size=0.1)Estamos configurando los hiperparámetros del modelo para poder ejecutarlo en Kaggle. Puedes obtener más información sobre cada hiperparámetro leyendo el tutorial Ajuste fino de Llama 2.
Estamos afinando el modelo durante una época y registrando las métricas mediante los Pesos y Sesgos.
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)Ahora configuraremos un entrenador de ajuste fino supervisado (SFT) y proporcionaremos un conjunto de datos de entrenamiento y evaluación, la configuración de LoRA, el argumento de entrenamiento, el tokenizador y el modelo. Mantenemos max_seq_length en 512 para evitar exceder la memoria de la GPU durante el entrenamiento.
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length=512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Comenzaremos el proceso de ajuste ejecutando el código siguiente.
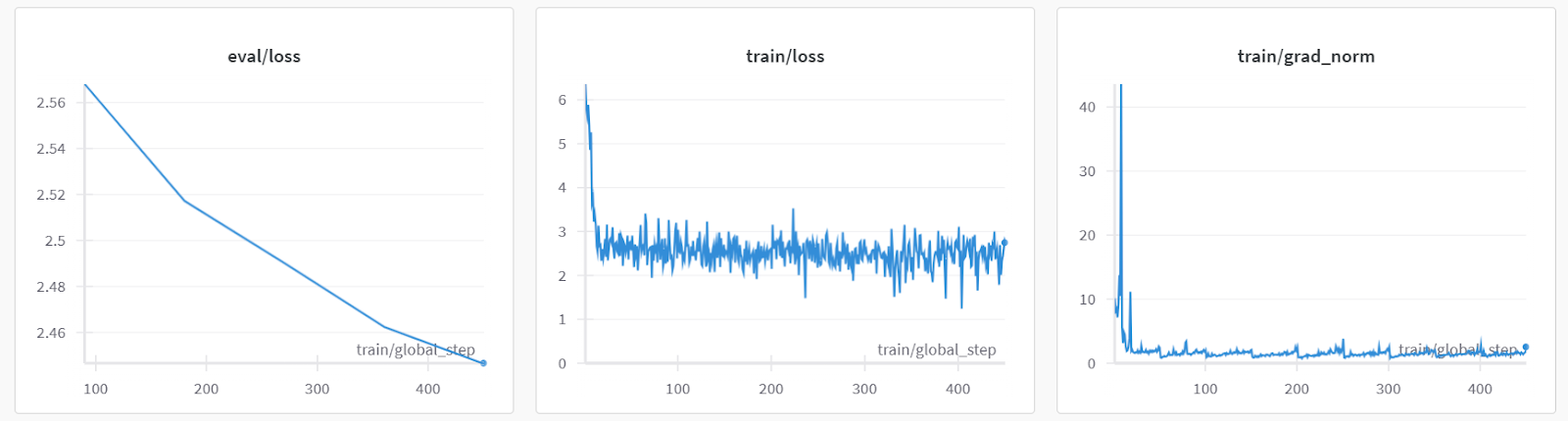
trainer.train()Tanto las pérdidas de entrenamiento como las de validación han disminuido. Considera la posibilidad de entrenar el modelo durante tres épocas en el conjunto de datos completo para obtener mejores resultados.
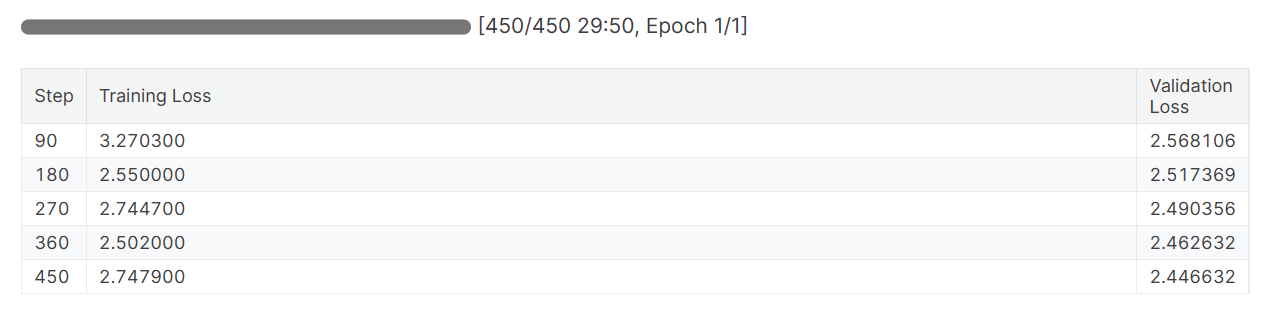
Cuando termines la sesión de Pesos y Sesgos, se generará el historial de ejecuciones y el resumen.
wandb.finish()
model.config.use_cache = True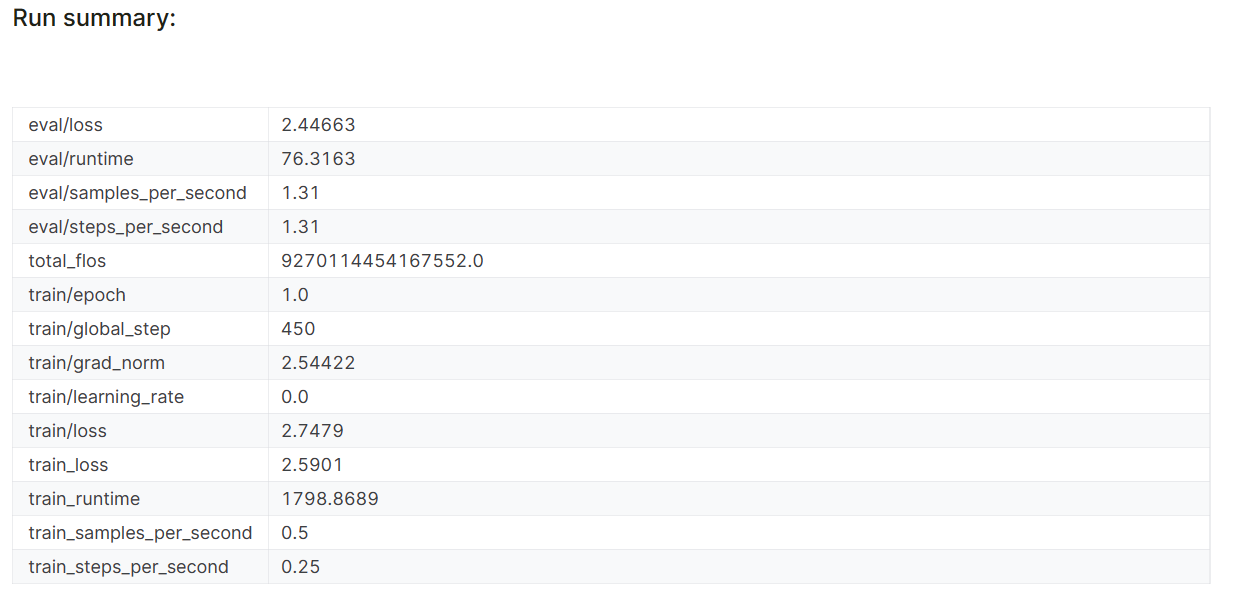
Las métricas de rendimiento del modelo también se almacenan bajo el nombre específico del proyecto en tu cuenta de Pesos y Parciales.
Evaluemos el modelo en una consulta de muestra de un paciente para comprobar si está bien afinado.
Para generar una respuesta, tenemos que convertir los mensajes en formato chat, pasarlos por el tokenizador, introducir el resultado en el modelo y, a continuación, descodificar el token generado para mostrar el texto.
messages = [
{
"role": "user",
"content": "Hello doctor, I have bad acne. How do I get rid of it?"
}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False,
add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True,
truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=150,
num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])
Resulta que podemos obtener resultados medios incluso con una sola época.
Ahora guardaremos el adaptador ajustado y lo empujaremos al Hub Cara Abrazada. La API Hub creará automáticamente el repositorio y almacenará el archivo adaptador.
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)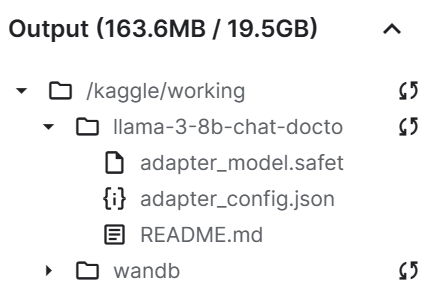
Como podemos ver, nuestro archivo adaptador de guardado es significativamente más pequeño que el modelo base.
Por último, guardaremos el cuaderno con el archivo adaptador para fusionarlo con el modelo base en el nuevo cuaderno.
Para guardar el Cuaderno Kaggle, pulsa el botón Guardar versión en la parte superior derecha, selecciona el tipo de versión como Guardado rápido , abre la configuración avanzada, selecciona Guardar siempre la salida al crear un Guardado rápido y, a continuación, pulsa el botón Guardar.
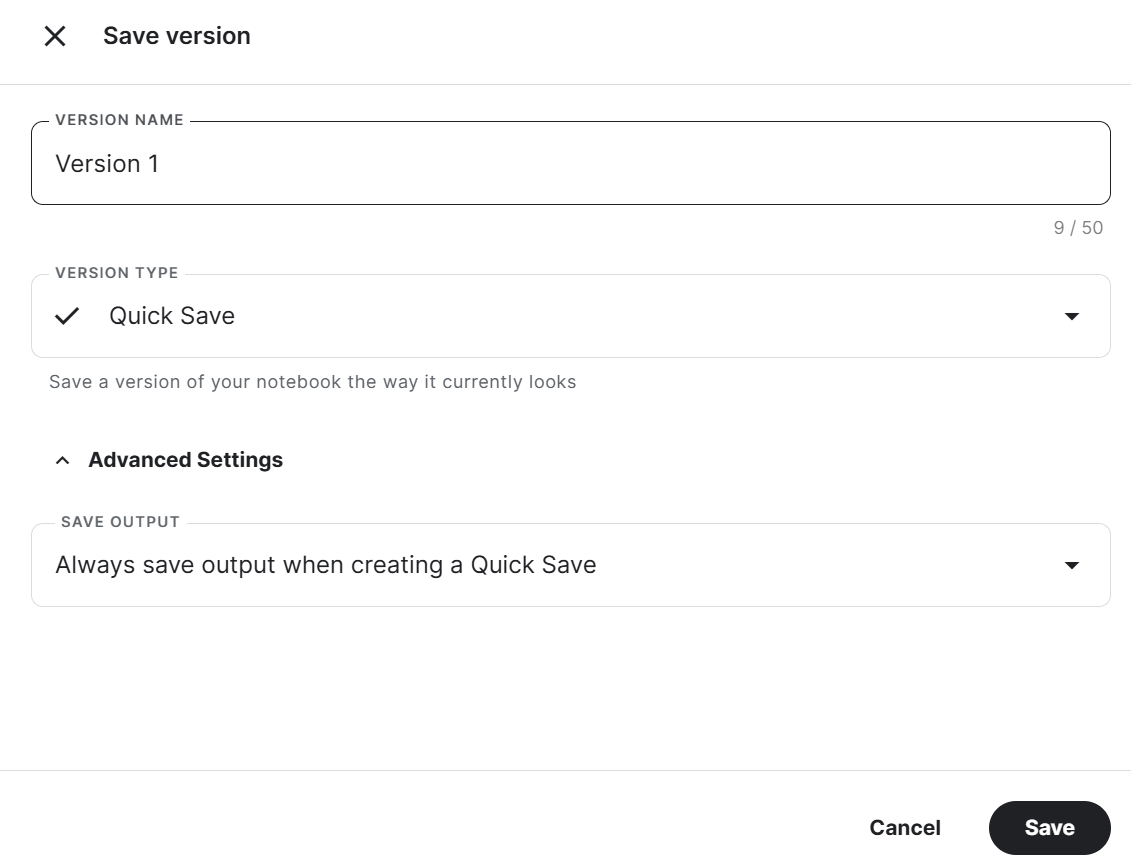
Si tienes algún problema al ejecutar el código, consulta este Cuaderno Kaggle: Afinar Llama 3 8B en el Conjunto de Datos Médicos.
Hemos afinado nuestro modelo utilizando la GPU. También puedes aprender a afinar LLMs utilizando las TPUs siguiendo el tutorial Afinar y ejecutar inferencias en el modelo Gemma de Google utilizando TPUs.
Si quieres aprender a afinar otros modelos, consulta este tutorial de Mistral 7B: Guía paso a paso para utilizar y afinar el Mistral 7B.
Para utilizar localmente el modelo ajustado, primero tenemos que fusionar el adaptador con el modelo base y luego guardar el modelo completo.
Sigamos los siguientes pasos:
1. Crea un nuevo Cuaderno Kaggle e instala todos los paquetes Python necesarios. Asegúrate de que utilizas la GPU como acelerador.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trl2. Inicia sesión en el Hub de Cara Abrazada utilizando los Secretos de Kaggle. Nos ayudará a subir fácilmente el modelo completo afinado.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)3. Añade el modelo de Chat Llama 3 8B y un Cuaderno Kaggle afinado que hemos guardado recientemente. Podemos añadir los Cuadernos en la sesión actual igual que se añade un conjunto de datos y modelos.
Añadir Notebook a la sesión de Kaggle nos permitirá acceder a los archivos de salida. En nuestro caso, es un archivo adaptador del modelo.
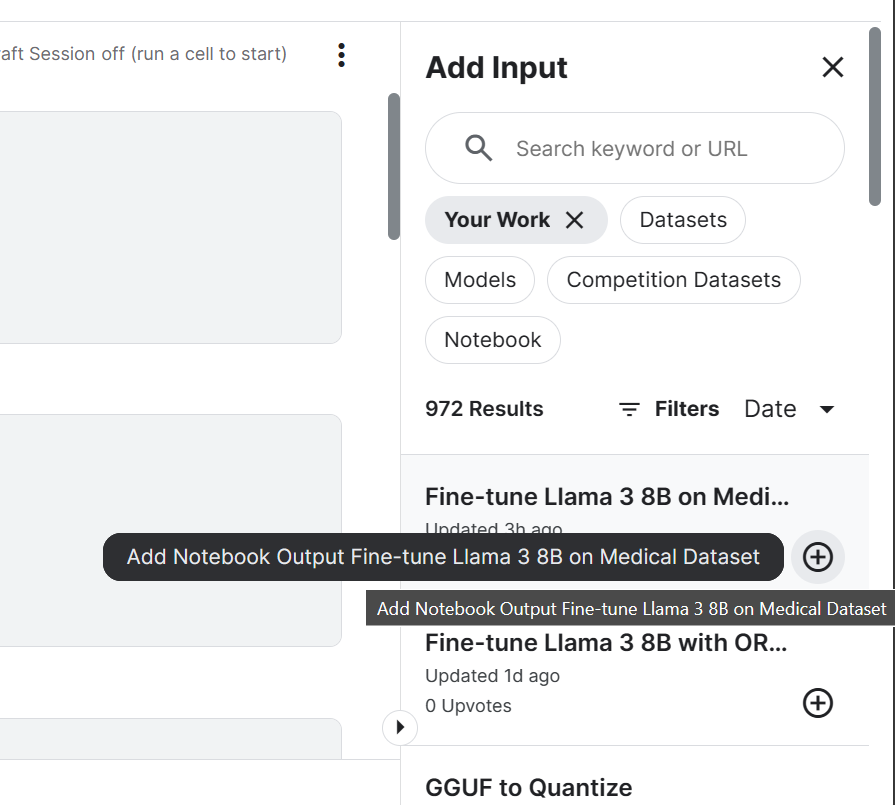
4. Configurar la variable con la ubicación del modelo base y el adaptador.
base_model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
new_model = "/kaggle/input/fine-tune-llama-3-8b-on-medical-dataset/llama-3-8b-chat-doctor/"Primero cargaremos el tokenizador y el modelo base utilizando la biblioteca transformers. A continuación, configuraremos el formato del chat utilizando la biblioteca trl. Por último, cargaremos y fusionaremos el adaptador con el modelo base utilizando la biblioteca PEFT.
La función merge_and_unload() nos ayudará a fusionar los pesos del adaptador con el modelo base y a utilizarlo como modelo independiente.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, new_model)
model = model.merge_and_unload()Para comprobar si nuestro modelo se ha fusionado correctamente, realizaremos una inferencia sencilla utilizando pipeline de la biblioteca transformers. Convertiremos el mensaje utilizando la plantilla de chat y, a continuación, proporcionaremos un aviso a la canalización. La canalización se inicializó utilizando el modelo, el tokenizador y el tipo de tarea.
Como nota al margen, puedes configurar device_map en "auto" si quieres utilizar varias GPU.
messages = [{"role": "user", "content": "Hello doctor, I have bad acne. How do I get rid of it?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
Nuestro modelo ajustado funciona como se esperaba después de ser fusionado.
Ahora guardaremos un tokenizador y un modelo utilizando la función save_pretrained().
model.save_pretrained("llama-3-8b-chat-doctor")
tokenizer.save_pretrained("llama-3-8b-chat-doctor")Los archivos del modelo se almacenan en el formato safetensors, y el tamaño total del modelo es de unos 16 GB.
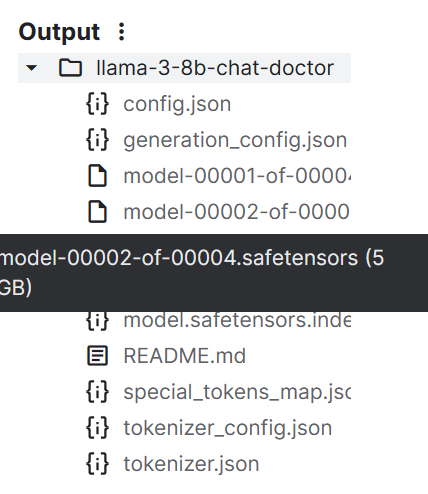
Podemos enviar todos los archivos al Hub Cara Abrazada utilizando la función push_to_hub().
model.push_to_hub("llama-3-8b-chat-doctor", use_temp_dir=False)
tokenizer.push_to_hub("llama-3-8b-chat-doctor", use_temp_dir=False)Al final, podemos guardar el Cuaderno Kaggle igual que hicimos anteriormente.
Utilizar el Adaptador de Ajuste Fino para modelar completamente el Cuaderno Kaggle te ayudará a resolver cualquier problema relacionado con la ejecución del código por tu cuenta.
No podemos utilizar los archivos safetensores localmente, ya que la mayoría de los chatbots de IA locales no los admiten. En lugar de eso, vamos a convertirlo al formato de archivo llama.cpp GGUF.
Inicia la nueva sesión de Kaggle Notebook y añade el Adaptador afinado al modelo completo de Notebook.
Clona el repositorio llama.cpp e instala el framework llama.cpp utilizando el comando make como se muestra a continuación.
Como nota al margen, el comando siguiente sólo funciona para el Cuaderno Kaggle. Puede que tengas que cambiar algunas cosas para ejecutarlo en otras plataformas o localmente.
%cd /kaggle/working
!git clone --depth=1 https://github.com/ggerganov/llama.cpp.git
%cd /kaggle/working/llama.cpp
!sed -i 's|MK_LDFLAGS += -lcuda|MK_LDFLAGS += -L/usr/local/nvidia/lib64 -lcuda|' Makefile
!LLAMA_CUDA=1 conda run -n base make -j > /dev/nullEjecuta el siguiente comando en la celda de Kaggle Notebook para convertir el modelo al formato GGUF.
La página convert-hf-to-gguf.py requiere un directorio de modelo de entrada, un directorio de archivo de salida y un tipo de salida.
!python convert-hf-to-gguf.py /kaggle/input/fine-tuned-adapter-to-full-model/llama-3-8b-chat-doctor/ \
--outfile /kaggle/working/llama-3-8b-chat-doctor.gguf \
--outtype f16En unos minutos, el modelo se convierte y se guarda localmente. A continuación, podemos guardar el bloc de notas para guardar el archivo.
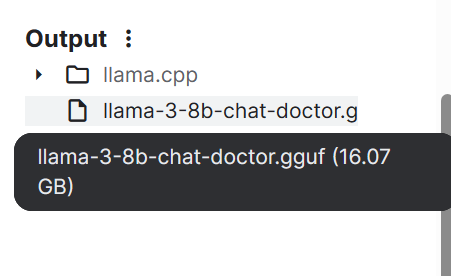
Si tienes problemas para ejecutar el código anterior, consulta el Cuaderno Kaggle de HF LLM a GGUF .
Los portátiles normales no tienen suficiente memoria RAM y GPU para cargar todo el modelo, así que tenemos que cuantificar el modelo GGUF, reduciendo el modelo de 16 GB a unos 4-5 GB.
Inicia la nueva sesión del Cuaderno Kaggle y añade el LLM HF al Cuaderno GGUF.
A continuación, instala el llama.cpp ejecutando el siguiente comando en la celda de Kaggle Notebook.
%cd /kaggle/working
!git clone --depth=1 https://github.com/ggerganov/llama.cpp.git
%cd /kaggle/working/llama.cpp
!sed -i 's|MK_LDFLAGS += -lcuda|MK_LDFLAGS += -L/usr/local/nvidia/lib64 -lcuda|' Makefile
!LLAMA_CUDA=1 conda run -n base make -j > /dev/nullEl script de cuantización requiere un directorio del modelo GGUF, un directorio del archivo de salida y un método de cuantización. Estamos convirtiendo el modelo mediante el método Q4_K_M.
%cd /kaggle/working/
!./llama.cpp/llama-quantize /kaggle/input/hf-llm-to-gguf/llama-3-8b-chat-doctor.gguf llama-3-8b-chat-doctor-Q4_K_M.gguf Q4_K_M
El tamaño de nuestro modelo ha disminuido significativamente de 15317,05 MB a 4685,32 MB.
Para empujar la fila india hacia el Centro de Cara Abrazada, haremos lo siguiente
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
from huggingface_hub import HfApi
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
api = HfApi()
api.upload_file(
path_or_fileobj="/kaggle/working/llama-3-8b-chat-doctor-Q4_K_M.gguf",
path_in_repo="llama-3-8b-chat-doctor-Q4_K_M.gguf",
repo_id="kingabzpro/llama-3-8b-chat-doctor",
repo_type="model",
)
Nuestro modelo se envía correctamente al servidor remoto, como se muestra a continuación.
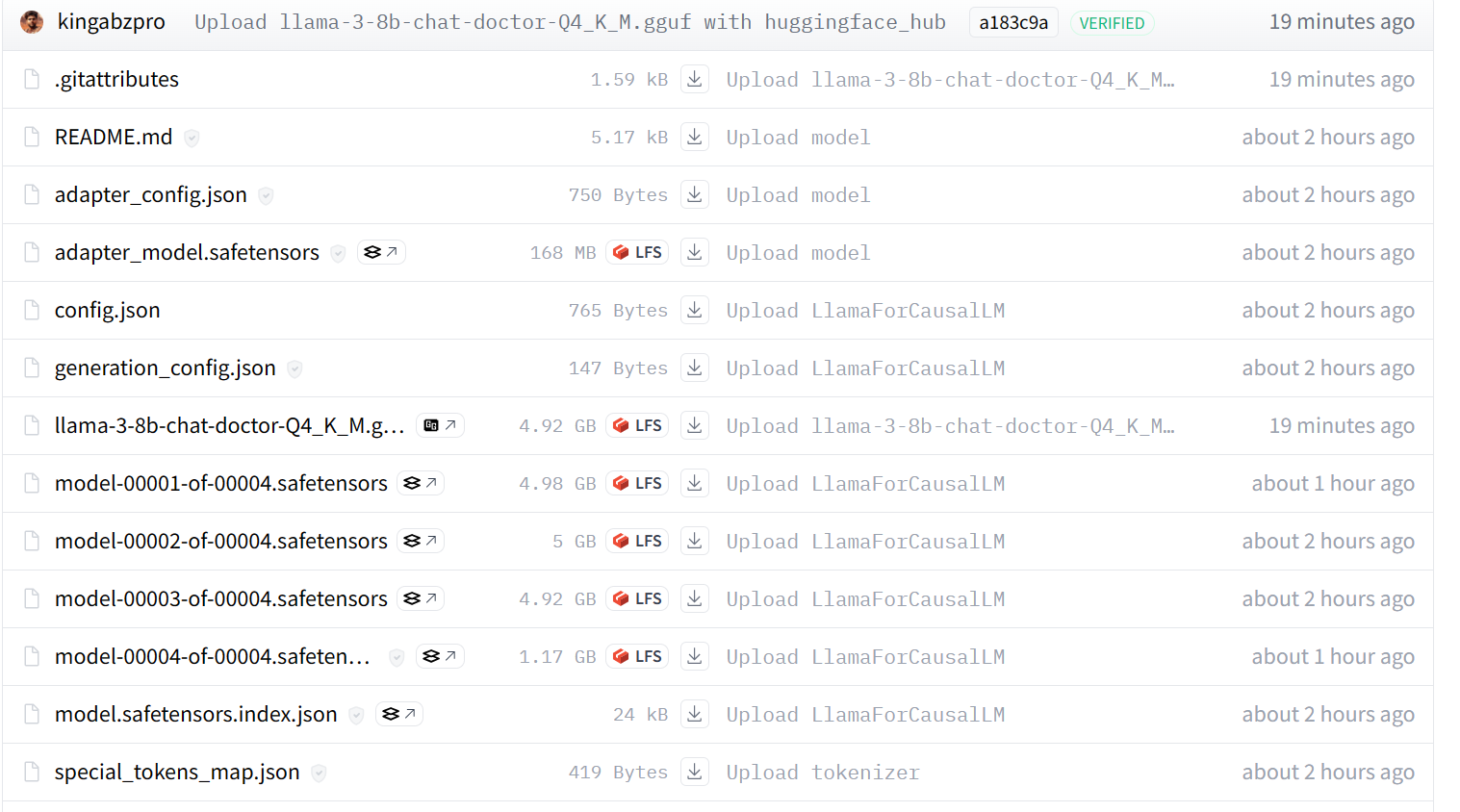
Si sigues teniendo problemas, consulta el Cuaderno Kaggle de GGUF to Quantize, que contiene todo el código y los resultados.
Si buscas una forma más sencilla de convertir y cuantizar tu modelo, visita este Espacio de Caras Abrazadas y proporciónale el Id. de modelo del Hub.
Para utilizar el modelo GGUF localmente, debes descargarlo e importarlo a la aplicación Jan.
Para descargar el modelo, necesitamos
1. Ve a nuestro repositorio de Caras Abrazadas.
2. Haz clic en la pestaña Archivos.
3. Haz clic en el archivo del modelo cuantizado con la extensión GGUF.

4. Haz clic en el botón de descarga.
Tardarás varios minutos en descargar el archivo localmente.
Descarga e instala la aplicación Jan de Jan AI.
Así es como se ve cuando inicias la aplicación de la ventana Jan:
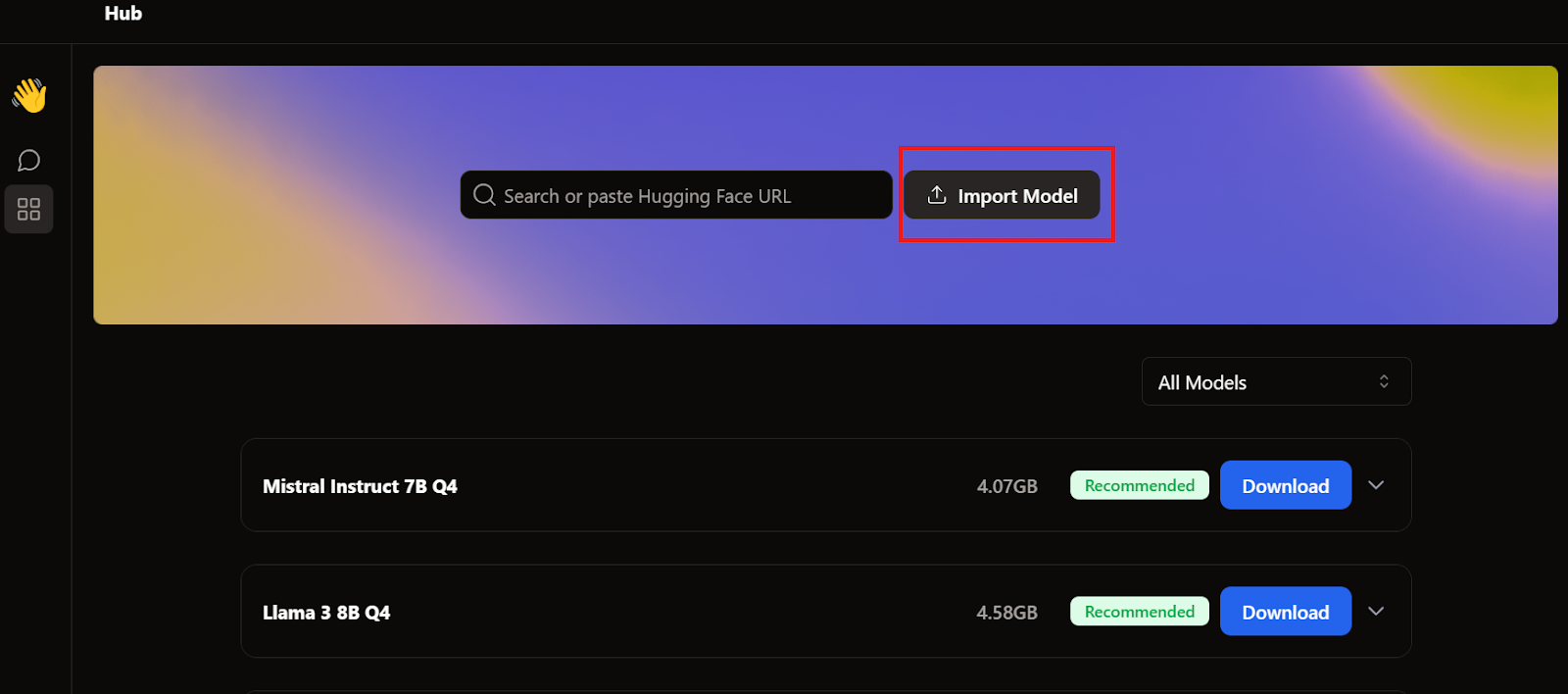
Para añadir el modelo a la aplicación Jan, tenemos que importar el archivo GGUF cuantizado.
Tenemos que ir al menú Hub y hacer clic en Importar modelo, como se muestra a continuación. Proporcionamos la ubicación del archivo descargado recientemente, y ya está.
Vamos al menú Hilo y seleccionamos el modelo afinado.
Antes de utilizar el modelo, tenemos que personalizarlo para que muestre la respuesta correctamente. En primer lugar, modificamos la plantilla Prompt en la sección Parámetros del modelo.
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistantAñadimos el testigo Stop y cambiamos el testigo max a 512 en los parámetros de inferencia.
<endofstring>, Best, Regards, Thanks,-->Empezamos a escribir las consultas, y el médico responderá en consecuencia.
Nuestro modelo afinado funciona perfectamente a nivel local.
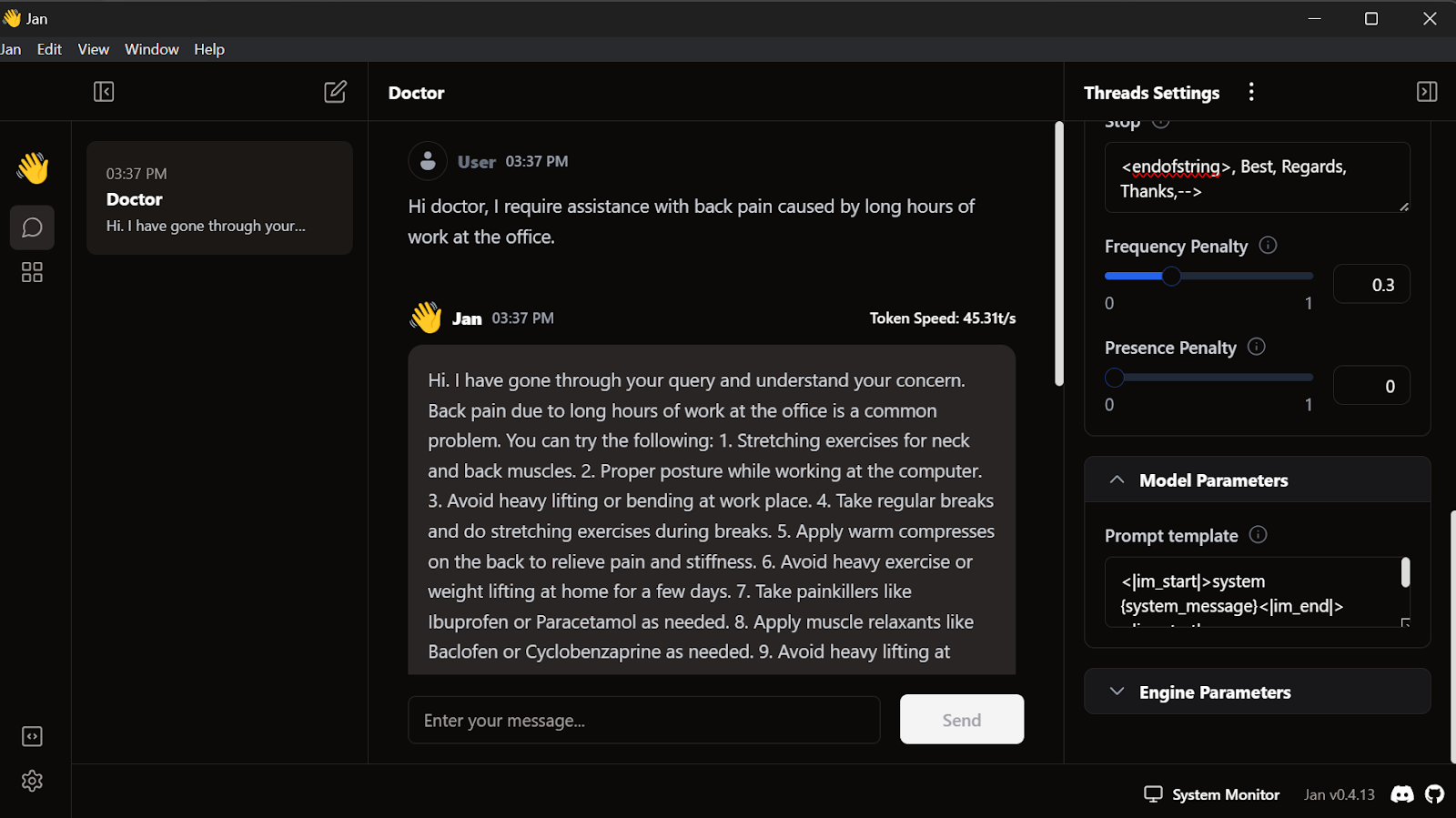
Este modelo funciona con GPT4ALL, Llama.cpp, Ollama y muchas otras aplicaciones locales de IA. Para aprender a utilizar cada uno de ellos, consulta este tutorial sobre cómo ejecutar LLMs localmente.
Afinar el modelo Llama 3 en un conjunto de datos personalizado y utilizarlo localmente ha abierto muchas posibilidades para crear aplicaciones innovadoras. Los posibles casos de uso van desde soluciones privadas y personalizadas de IA conversacional hasta chatbots de dominios específicos, clasificación de textos, traducción de idiomas, sistemas de recomendación personalizados para responder preguntas, e incluso aplicaciones de automatización de la atención sanitaria y el marketing.
Con los frameworks Ollama y Langchain, crear tu propia aplicación de IA es ahora más accesible que nunca, ya que sólo requiere unas pocas líneas de código. Para ello, sigue el enlace LlamaIndex: Un marco de datos para aplicaciones basadas en grandes modelos lingüísticos (LLM) tutorial.
En este tutorial, aprendimos a afinar el Chat Llama 3 8B en un conjunto de datos médicos. Pasamos por el proceso de fusionar el adaptador con el modelo base, convertirlo al formato GGUF y cuantizarlo para su uso local en una aplicación chatbot de Jan.
Si quieres saber más, echa un vistazo a este itinerario de cuatro cursos sobre Desarrollo de grandes modelos lingüísticos.
Aprende IA con estos cursos
programa
programa
programa
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer

