Course
Introduction to R
4 hr
3M
One could argue that proper ETL pipelines are a vital organ of data science. Without clean and organized data, it becomes tough to produce quality insights that enhance business decisions.
Therefore, in this tutorial, we will explore what it entails to build a simple ETL pipeline to stream real-time Tweets directly into a SQLite database using R. This is a fairly common task involved in social network analysis for example.
The focus will be on covering the thought process of data collection and storage as well as how to operate the Twitter API using the rtweet package in R.
To begin, let's start with having all the right tools. The first thing that you will need is set up your access to the Twitter API. Overall, you would need to follow these steps:
Once you are all set with the Twitter API, you need to get SQLite if you don't have it. For the full process on how to get SQLite on your computer, follow the Beginners Guide to SQLite tutorial here at DataCamp. The choice of using SQLite for this tutorial was made due to its simplicity of operation.
With both the Twitter API access and SQLite installed, we can finally begin building a pipeline to store Tweets as we stream them over time. To start, we are going to create our new SQLite database using R as outlined below:
# Import necessary libraries and functions
library(RSQLite)
library(rtweet)
library(tm)
library(dplyr)
library(knitr)
library(wordcloud)
library(lubridate)
library(ggplot2)
source("transform_and_clean_tweets.R")
# Create our SQLite database
conn <- dbConnect(RSQLite::SQLite(), "Tweet_DB.db")
Afterward, we can create a table inside the database to hold the tweets. In our particular case, we are going to store the following variables:
You may wonder, why do I set the dates as integers? This is due to the fact that SQLite doesn't have a reserved data type for dates and times. Therefore, the dates will be stored as the number of seconds since 1970-01-01.
Let us now proceed to write the table:
dbExecute(conn, "CREATE TABLE Tweet_Data(
Tweet_ID INTEGER PRIMARY KEY,
User TEXT,
Tweet_Content TEXT,
Date_Created INTEGER)")
Once you have created the table, you can go to sqlite3.exe and check that is has indeed been created. You can see a screenshot of this below:
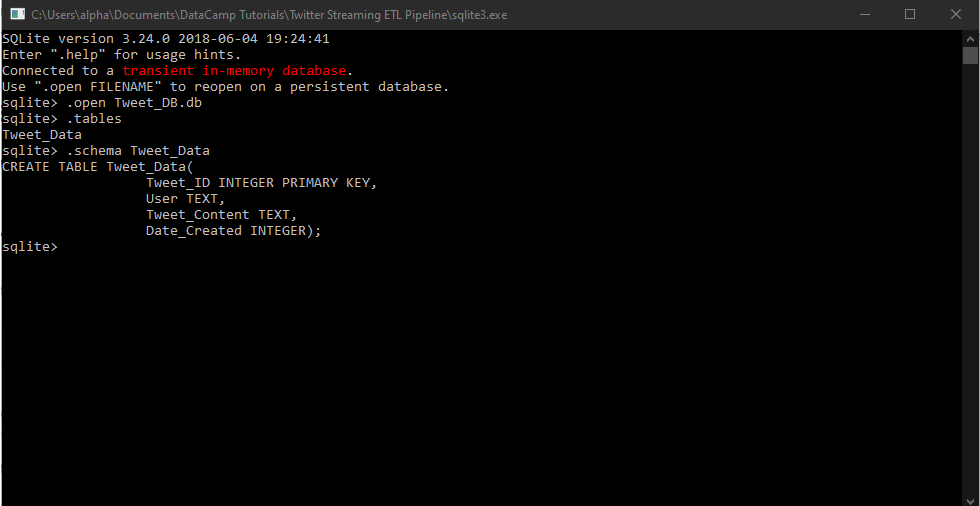
Believe it or not, you are done in terms of requirements and infrastructure needed to have a simple, functional Twitter streaming pipeline. What we need to do now is to stream Tweets using the API. It is worth noting that for the purposes of this tutorial, I will be using the standard free API. There are premium paid versions that may suit your Tweet streaming needs better if you conduct research, for instance.
Without further delay, let us start the process of setting up our Twitter listener. The first thing that you will need is to import the rtweet package and input your application's access tokens and secrets as described in the beginning:
token <- create_token(app = 'Your_App_Name',
consumer_key = 'Your_Consumer_Key',
consumer_secret = 'Your_Consumer_Secret',
access_token = 'Your_Access_Token',
access_secret = 'Your_Access_Secret')
With your token in place, the next thing is to decide what tweets do you want to stream (i.e., to listen to). The function stream_tweets in the rtweet package provides us with a variety of options to query the Twitter API. For example, you can stream tweets that contain one or more of a set of given hashtags or keywords (up to 400), a small random subset of all publicly available tweets, track the tweets of a group of user IDs or screen (user) names (up to 5000), or gather tweets by geographic location.
For this tutorial, I decided to go ahead and stream tweets containing hashtags related to data science (see list below). You may notice that the format in which I defined the hashtags to stream is a bit odd. However, that is the format required by the stream_tweets function when you want to listen to hashtags or keywords. This format varies if you intend to listen to a given set of users or based on coordinates. For more details, refer to the documentation.
keys <- "#nlp,#machinelearning,#datascience,#chatbots,#naturallanguageprocessing,#deeplearning"
With the keywords defined, it is time to define the tweet streaming loop. There are several ways to do this, but this format has worked well for me in the past:
# Initialize the streaming hour tally
hour_counter <- 0
# Initialize a while loop that stops when the number of hours you want to stream tweets for is exceeded
while(hour_counter <= 12){
# Set the stream time to 2 hours each iteration (7200 seconds)
streamtime <- 7200
# Create the file name where the 2 hour stream will be stored. Note that the Twitter API outputs a .json file.
filename <- paste0("nlp_stream_",format(Sys.time(),'%d_%m_%Y__%H_%M_%S'),".json")
# Stream Tweets containing the desired keys for the specified amount of time
stream_tweets(q = keys, timeout = streamtime, file_name = filename)
# Clean the streamed tweets and select the desired fields
clean_stream <- transform_and_clean_tweets(filename, remove_rts = TRUE)
# Append the streamed tweets to the Tweet_Data table in the SQLite database
dbWriteTable(conn, "Tweet_Data", clean_stream, append = T)
# Delete the .json file from this 2-hour stream
file.remove(filename)
# Add the hours to the tally
hour_counter <- hour_counter + 2
}
In essence, that loop streams as many tweets as possible mentioning any of the hashtags in the key strings in intervals of 2 hours for a total time of 12 hours. Every 2 hours, the Twitter listener creates a .json file in your current working directory with the name specified in the variable filename.
Then, it passes this filename to the transform_and_clean_tweets function that removes retweets if desired, selects the columns we want to keep from all those given by the Twitter API, and normalizes the text contained in the Tweets.
Then, it appends the resulting dataframe to the Tweet_Data table that we created earlier inside our SQLite database. Finally, it adds 2 to the hour counter tally (since the streams last for 2 hours), and it removes the .json file created. This is done since all the data of interest is now in our database, and keeping the .json files can become a storage burden.
Let us know look closer to the transform_and_clean_tweets function in detail:
transform_and_clean_tweets <- function(filename, remove_rts = TRUE){
# Import the normalize_text function
source("normalize_text.R")
# Parse the .json file given by the Twitter API into an R data frame
df <- parse_stream(filename)
# If remove_rst = TRUE, filter out all the retweets from the stream
if(remove_rts == TRUE){
df <- filter(df,df$is_retweet == FALSE)
}
# Keep only the tweets that are in English
df <- filter(df, df$lang == "en")
# Select the features that you want to keep from the Twitter stream and rename them
# so the names match those of the columns in the Tweet_Data table in our database
small_df <- df[,c("screen_name","text","created_at")]
names(small_df) <- c("User","Tweet_Content","Date_Created")
# Finally normalize the tweet text
small_df$Tweet_Content <- sapply(small_df$Tweet_Content, normalize_text)
# Return the processed data frame
return(small_df)
}
As noted, this function is meant to filter retweets if desired, retain the desired features, and normalize the tweet text. In essence, this can be considered the "T" part of the ETL acronym (the transformation). One key component of this function is the process of cleaning the tweet text.
Usually, text data requires a few preprocessing steps before it can be ready for any sort of analysis. In the case of tweets, these steps can include removal of URLs, stop words and mentions, turning the text to lower case, stemming words, etc. However, not all of these steps are necessary all of the time. Nevertheless, for the time being, I will display the normalize_text function that I used to preprocess these tweets below:
normalize_text <- function(text){
# Keep only ASCII characters
text = iconv(text, "latin1", "ASCII", sub="")
# Convert to lower case characters
text = tolower(text)
# Remove any HTML tags
text = gsub("<.*?>", " ", text)
# Remove URLs
text = gsub("\\s?(f|ht)(tp)(s?)(://)([^\\.]*)[\\.|/](\\S*)", "", text)
# Keep letters and numbers only
text = gsub("[^[:alnum:]]", " ", text)
# Remove stop words
text = removeWords(text,c("rt","gt",stopwords("en")))
# Remove any extra white space
text = stripWhitespace(text)
text = gsub("^\\s+|\\s+$", "", text)
return(text)
}
Depending on your use case, these steps may be sufficient. As mentioned earlier, you may choose to add more or different steps such as stemming or lemmatization or to keep only letters instead of letters and numbers. I encourage you to experiment and try out different combinations. This can be a great place to practice regex skills.
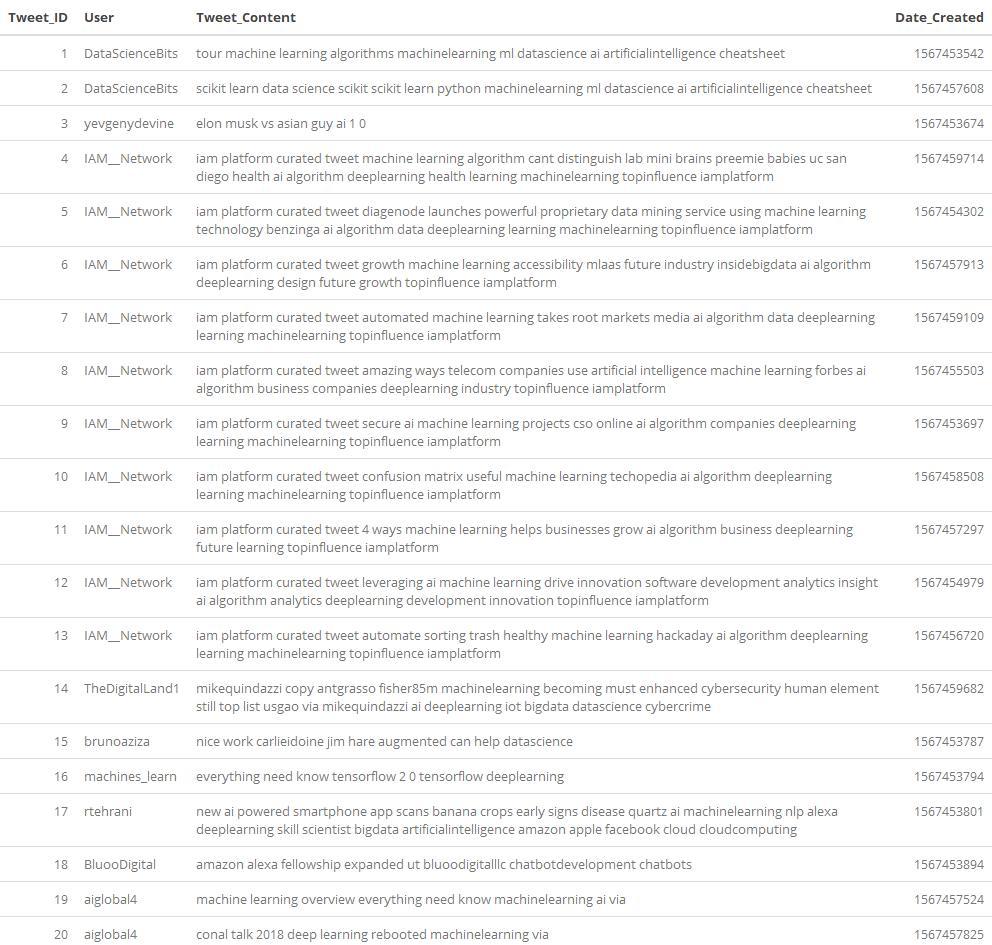
After all of these steps, the resulting state is a SQLite database populated with all the streamed tweets. You can validate that everything worked correctly by running a couple of simple queries, for instance:
data_test <- dbGetQuery(conn, "SELECT * FROM Tweet_Data LIMIT 20")
unique_rows <- dbGetQuery(conn, "SELECT COUNT() AS Total FROM Tweet_Data")
kable(data_test)
print(as.numeric(unique_rows))
## [1] 1863
When there is a certainty that the ETL process is working as intended, the final step is to gather some insights and analyze the data that you have collected. For example, for the tweets that we have collected, we can try a couple of different things; a wordcloud of terms mentioned in the tweet's content, and a timeline to visualize when in our 12-hour streaming period did we obtain the most amount of tweets. This list is obviously not a comprehensive overview of the whole array of research that can be conducted using tweets, which can range from sentiment analysis to psychographic studies and beyond.
With that said, lets jump straight to building a nice wordcloud:
# Gather all tweets from the database
all_tweets <- dbGetQuery(conn, "SELECT Tweet_ID, Tweet_Content FROM Tweet_Data")
# Create a term-document matrix and sort the words by frequency
dtm <- TermDocumentMatrix(VCorpus(VectorSource(all_tweets$Tweet_Content)))
dtm_mat <- as.matrix(dtm)
sorted <- sort(rowSums(dtm_mat), decreasing = TRUE)
freq_df <- data.frame(words = names(sorted), freq = sorted)
# Plot the wordcloud
set.seed(42)
wordcloud(words = freq_df$words, freq = freq_df$freq, min.freq = 10,
max.words=50, random.order=FALSE, rot.per=0.15,
colors=brewer.pal(8, "RdYlGn"))

Well, what a tremendous surprise! machinelearning and datascience are the most mentioned words in all our tweets—they just happen to be two of the hashtags that we were streaming for. Thus, this result was expected. The other words though are a bit more fun to look at. For example, bigdata and artificialintelligence were not hashtags in our keys, yet they appeared with high frequency, so one could argue that they are talked about often along with the other two. There are other words of interest that we picked up such as python or tensorflow that gives us a little bit more context into the content of the tweets we collected beyond just the hashtags.
Let us now turn to another simple analysis. In our 12-hour stream, at what time did we collect the most tweets? For that, we will gather our integer dates, turn them into a proper format, and then plot the quantity of tweets over time:
# Select the dates in which the tweets were created and convert them into UTC date-time format
all_tweets <- dbGetQuery(conn, "SELECT Tweet_ID, Date_Created FROM Tweet_Data")
all_tweets$Date_Created <- as.POSIXct(all_tweets$Date_Created, origin = "1970-01-01", tz = "UTC")
# Group by the day and hour and count the number of tweets that occurred in each bucket
all_tweets_2 <- all_tweets %>%
mutate(day = day(Date_Created),
month = month(Date_Created, label = TRUE),
hour = hour(Date_Created)) %>%
mutate(day_hour = paste(month,"-",day,"-",hour, sep = "")) %>%
group_by(day_hour) %>%
tally()
# Simple line ggplot
ggplot(all_tweets_2, aes(x = day_hour, y = n)) +
geom_line(aes(group = 1)) +
theme_minimal() +
ggtitle("Tweet Freqeuncy During the 12-h Streming Period")+
ylab("Tweet Count")+
xlab("Month-Day-Hour")
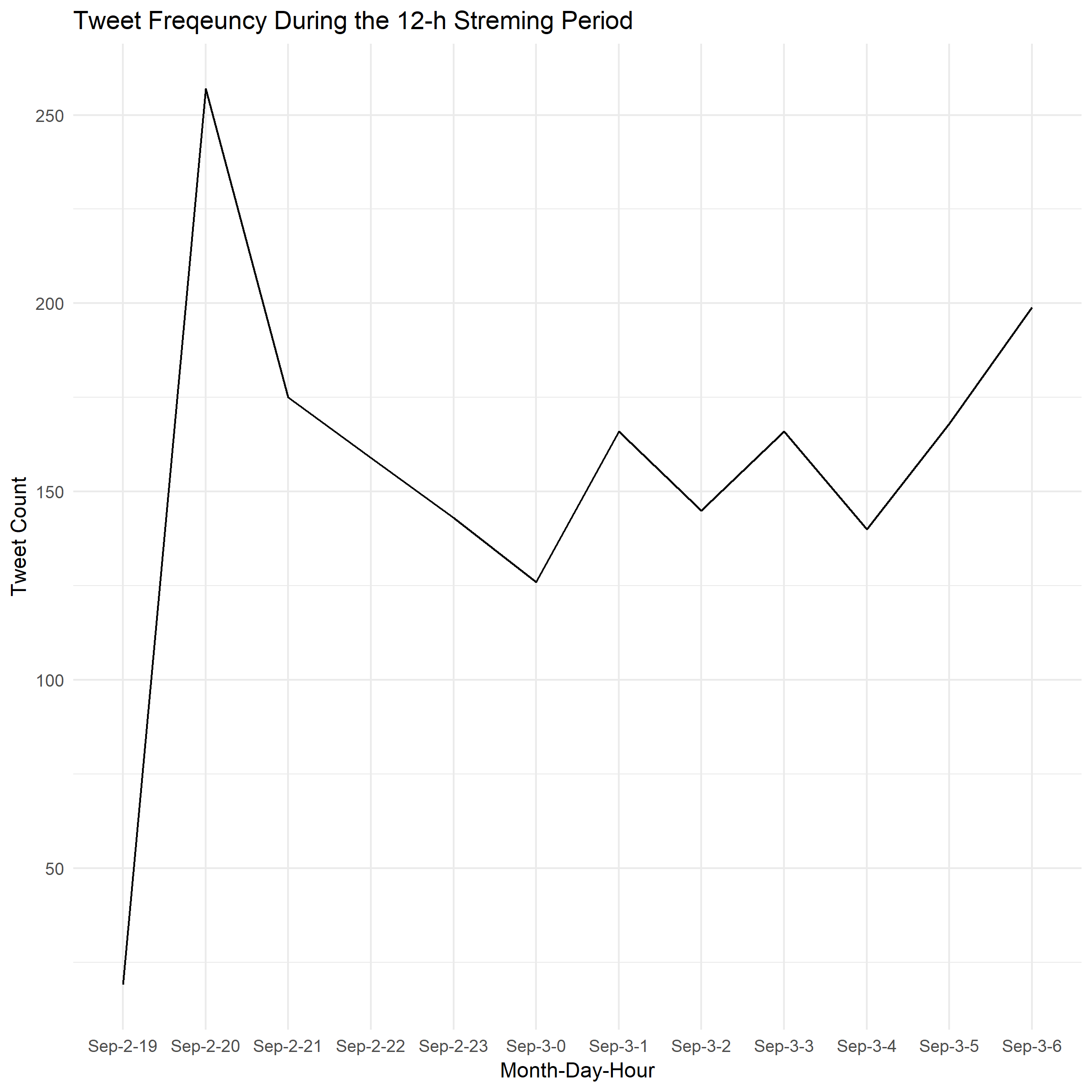
Sweet! Now we can see that the largest amount of unique tweets that we obtain came from the 2nd of September between 8:00 PM UTC and 8:59PM UTC (This appears in military time as 20).
Congratulations! Now you know how to build a simple ETL pipeline in R. The two analyses we conducted represent very basic analyses conducted using Twitter data. However, as mentioned previously, there are lots of things to do as long as you build a robust pipeline to bring in the data. This aspect was the main focus of this tutorial.
With that said, this tutorial only showed a very small scale case study to walk over the process of building ETL pipelines for Twitter data. Building robust and scalable ETL pipelines for a whole enterprise is a complicated endeavor that requires extensive computing resources and knowledge, especially when big data is involved.
I encourage you to do further research and try to build your own small scale pipelines, which could involve building one in Python. Maybe, even go ahead and try some big data projects. For example, DataCamp already has some courses like this Big Data Fundamentals via PySpark course where they go over big data using tools such as PySpark that can further your knowledge of this field.
If you would like to learn about data engineering, take DataCamp's Introduction to Data Engineering course. And if you're ready to prove your new skills to employers, check out our Data Engineer Certification.
References
Learn more about R
Course
Course
Course
Tutorial
Karlijn Willems
Tutorial
Jake Roach
Tutorial
Francisco Javier Carrera Arias
Tutorial
Hugo Bowne-Anderson
Tutorial
Kyle Weller
code-along
Jake Roach
