
Curso
Sistemas multiagente con LangGraph
2 h 45 min
6.5K
La extracción de datos estructurados de documentos de texto plantea importantes problemas a los equipos de datos. Las expresiones regulares fallan cuando cambian los formatos, el código de análisis personalizado pasa por alto el contexto que los humanos captan fácilmente y estas soluciones requieren correcciones constantes a medida que cambian tus fuentes de datos.
LangExtract resuelve este problema utilizando modelos de inteligencia artificial que pueden leer textos como lo hacen los humanos y programar exactamente de dónde proviene la información. Tú le indicas qué datos deseas en términos sencillos con algunos ejemplos, y él se encarga del arduo trabajo de comprender y extraer esa información.
En este tutorial, explicaré paso a paso cómo configurar LangExtract para el reconocimiento de entidades nombradas, extraer relaciones entre entidades, trabajar con diferentes proveedores de modelos de IA y comparar el enfoque de LangExtract con las bibliotecas tradicionales de PLN. También aprenderás a definir tareas de extracción, proporcionar ejemplos de entrenamiento y procesar los resultados estructurados para tus flujos de trabajo de análisis.
LangExtract es una biblioteca de Python que convierte texto desordenado en datos organizados utilizando modelos de inteligencia artificial. Las herramientas antiguas de procesamiento de texto se confunden con el contexto: pueden ver «Apple» y pensar que se trata de una fruta cuando estás leyendo sobre la empresa tecnológica, o encontrar «500 $» y considerarlo un precio cuando en realidad es un número de identificación de empleado. La coincidencia de patrones básicos puede detectar direcciones de correo electrónico, pero no puede determinar si «john.doe@company.com» es un empleado actual o simplemente alguien mencionado en un correo electrónico antiguo.
Para solucionar estos problemas de contexto y precisión, LangExtract te ofrece:
Fuente: GitHub
Estas herramientas funcionan conjuntamente para cambiar la forma en que extraes información del texto. En lugar de escribir reglas complejas que se rompen fácilmente, le dices a la IA lo que quieres utilizando ejemplos sencillos. La IA lee el texto como lo haría un humano y realiza un seguimiento del origen de cada elemento. Esto te permite extraer información y relaciones complejas que, con el método antiguo, requerirían cientos de líneas de código para encontrarlas.
LangExtract funciona mejor cuando necesitas extraer información personalizada que las herramientas tradicionales de PLN no pueden manejar bien. Si trabajas con textos específicos de un dominio en los que el reconocimiento estándar de entidades nombradas no es suficiente, LangExtract te permite definir exactamente lo que es importante para tu negocio sin necesidad de escribir reglas complejas ni volver a entrenar modelos. Es especialmente útil cuando necesitas comprender el contexto y las relaciones entre diferentes datos, y no solo encontrar entidades individuales.
LangExtract es una buena opción cuando tienes:
Debes considerar otras herramientas si trabajas con tareas de PLN bien establecidas, como el reconocimiento básico de entidades nombradas para categorías comunes, necesitas un procesamiento extremadamente rápido de patrones simples o tienes requisitos estrictos para evitar llamadas a API externas. Bibliotecas tradicionales como spaCy destacan en tareas estándar de PLN con procesamiento de gran volumen, mientras que LangExtract destaca cuando necesitas una extracción inteligente y personalizada con una complejidad de configuración mínima.
Antes de poder empezar a extraer datos, debes instalar LangExtract y configurar el acceso a los modelos de IA. La biblioteca admite múltiples métodos de instalación y funciona con diferentes proveedores de IA.
Instala LangExtract utilizando pip o uv. Para OpenAI, utiliza el paquete extras:
# Using pip
pip install langextract[openai]
# Using uv
uv add langextract[openai]El complemento [openai] incluye el cliente OpenAI Python. Para otros proveedores, puedes instalar el paquete base y añadir las bibliotecas específicas del proveedor según sea necesario.
LangExtract trabaja con varios proveedores de IA. Configura las claves API como variables de entorno:
# OpenAI (get your key from https://platform.openai.com/api-keys)
export OPENAI_API_KEY="your-openai-key-here"
# Anthropic (get your key from https://console.anthropic.com/settings/keys)
export ANTHROPIC_API_KEY="your-anthropic-key-here"
# Google AI (get your key from https://aistudio.google.com/app/apikey)
export GOOGLE_API_KEY="your-google-key-here"Solo necesitas las claves de los proveedores que pienses utilizar. Para los modelos locales a través de Ollama, no se requieren claves API, solo hay que instalar y ejecutar Ollama en tu equipo.
Verifica tu configuración con una prueba sencilla:
import langextract as lx
import textwrap
# 1. Define the prompt and extraction rules
prompt = textwrap.dedent(
"""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context."""
)
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
],
)
]
# The input text to be processed
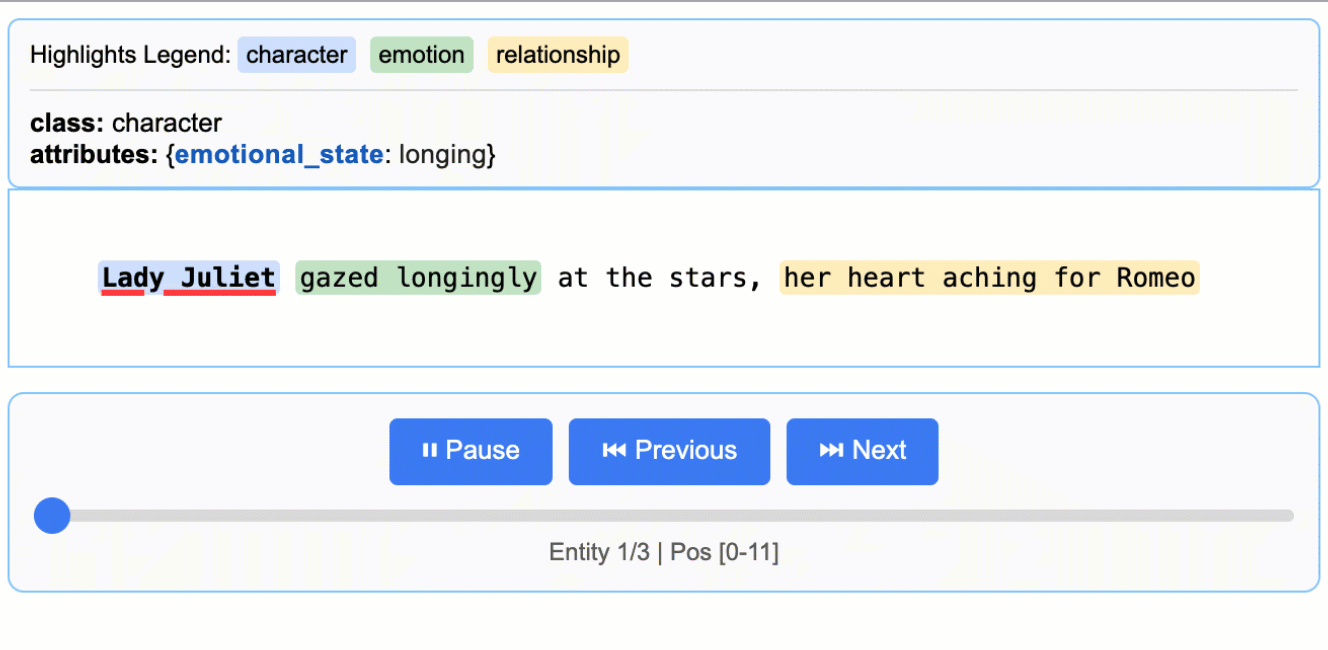
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# Run the extraction
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini",
)
print("Extraction successful!")El reconocimiento de entidades nombradas (NER) encuentra y clasifica información específica en un texto, como todos los nombres de empresas, personas y ubicaciones mencionados en un informe comercial.
Las herramientas tradicionales de NER funcionan con categorías predefinidas como «PERSONA» u «ORGANIZACIÓN», pero a menudo pasan por alto entidades específicas del contexto que son importantes para tu negocio. LangExtract te permite definir tipos de entidades personalizados y enseñar a la IA a reconocer patrones específicos de tu dominio.
Veamos cómo extraer entidades de los correos electrónicos de atención al cliente. En lugar de categorías genéricas, identificaremos entidades específicas de soporte, como tipos de quejas, nombres de productos y plazos de resolución, que ayudan a priorizar los tickets.
El primer paso es describir lo que deseas extraer utilizando una indicación clara. Esta indicación funciona como las instrucciones para un analista humano: cuanto más específico seas, mejores resultados obtendrás:
import langextract as lx
import textwrap
# Define what we want to extract from support emails
prompt = textwrap.dedent("""
Extract customer support entities from email text.
Focus on actionable information that helps prioritize and route tickets.
Use exact text from the email - don't paraphrase or summarize.
Include helpful attributes that add context for support agents.
""")La función « textwrap.dedent() » elimina la sangría adicional de las cadenas de varias líneas, lo que facilita la lectura de las indicaciones en el código y las mantiene limpias cuando se envían a la IA. Sin él, la IA vería todos los espacios adicionales de la sangría de tu código.
Esta indicación le dice a la IA que busque información específica sobre asistencia, utilice citas exactas del texto y añada contexto mediante atributos. La clave está en ser específico sobre tu ámbito (atención al cliente) y lo que hace que la información sea útil (ayuda a priorizar y dirigir los tickets).
Los ejemplos enseñan a la IA exactamente lo que quieres y cómo dar formato a los resultados. Cada ejemplo muestra a la IA un fragmento de texto y las entidades exactas que deseas extraer de él:
# Create examples that show the AI what to extract
examples = [
lx.data.ExampleData(
text="My laptop screen keeps flickering. I bought it 3 months ago and need this fixed urgently for my presentation tomorrow.",
extractions=[
lx.data.Extraction(
extraction_class="product",
extraction_text="laptop",
attributes={"issue": "screen flickering", "urgency": "high"}
),
lx.data.Extraction(
extraction_class="timeline",
extraction_text="3 months ago",
attributes={"context": "purchase_date"}
),
lx.data.Extraction(
extraction_class="urgency_indicator",
extraction_text="urgently for my presentation tomorrow",
attributes={"priority": "high", "deadline": "tomorrow"}
)
]
)
]Cada objeto ExampleData contiene una muestra de texto y una lista de objetos Extraction. Los objetos ` Extraction ` especifican tres cosas:
extraction_class: El tipo de entidad (como «producto» o «línea temporal»).extraction_text: Las palabras exactas del texto originalattributes: Contexto adicional que ayuda a comprender mejor la entidad.Los atributos son lo que diferencia a LangExtract del NER tradicional. En lugar de limitarte a buscar «ordenador portátil», puedes detectar que tiene un problema de «parpadeo de la pantalla» y marcarlo como de alta urgencia.
Ahora puedes ejecutar la extracción en un nuevo texto utilizando tu indicador y tus ejemplos. LangExtract aplicará lo que ha aprendido para encontrar entidades similares:
# Sample support email to analyze
support_email = """
Subject: WiFi adapter not working after Windows update
Hi support team,
My USB WiFi adapter stopped working completely after yesterday's Windows update.
I've tried restarting my computer multiple times but no luck. This is blocking me
from working from home today. I have an important client call at 2 PM and really
need internet access. The adapter worked perfectly before the update.
Thanks,
Mike Chen
"""
# Run the extraction
result = lx.extract(
text_or_documents=support_email,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini"
)
print("Extraction completed successfully!")Salida:
INFO:absl:Finalizing annotation for document ID doc_435b1cd5.
INFO:absl:Document annotation completed.
✓ Extracted 4 entities (3 unique types)
• Time: 3.34s
• Speed: 123 chars/sec
• Chunks: 1
Extraction completed successfully!La función « lx.extract() » toma tu texto, aplica las instrucciones del mensaje y utiliza los ejemplos para guiar la extracción. Devuelve un objeto de resultado que contiene todas las entidades encontradas, junto con sus ubicaciones exactas en el texto original.
Puedes probar diferentes modelos cambiando el parámetro model_id. Modelos como "claude-3-haiku" o "gpt-4o" pueden dar resultados diferentes dependiendo de la complejidad del texto y tus requisitos.
Una vez completada la extracción, LangExtract devuelve un objeto de resultado que contiene todas las entidades encontradas con sus ubicaciones y atributos exactos. El verdadero poder reside en cómo puedes acceder, analizar y compartir estos datos estructurados.
El objeto resultado almacena todas las entidades encontradas en la propiedad « extractions ». Cada extracción contiene el texto de la entidad, su tipo, su ubicación en el documento original y cualquier atributo:
# Look at all extracted entities
for extraction in result.extractions:
print(f"Type: {extraction.extraction_class}")
print(f"Text: '{extraction.extraction_text}'")
print(f"Location: chars {extraction.char_interval.start_pos}-{extraction.char_interval.end_pos}")
print(f"Attributes: {extraction.attributes}")
print("---")Salida:
Type: product
Text: 'USB WiFi adapter'
Location: chars 78-94
Attributes: {'issue': 'not working after Windows update', 'previous_status': 'worked perfectly before the update'}
---
Type: timeline
Text: 'yesterday'
Location: chars 128-137
Attributes: {'context': 'Windows update'}
---
Type: urgency_indicator
Text: 'blocking me from working from home today'
Location: chars 227-268
Attributes: {'priority': 'high', 'context': 'work from home'}
---
Type: urgency_indicator
Text: 'important client call at 2 PM'
Location: chars 280-309
Attributes: {'priority': 'high', 'deadline': '2 PM today'}
---Cada objeto de extracción rastrea exactamente de dónde proviene la información utilizando char_interval, que muestra las posiciones inicial y final en el texto original. Este seguimiento de fuentes te permite verificar los resultados y comprender el contexto.
Puedes agrupar y contar entidades para comprender los patrones de tus datos:
from collections import Counter
# Count different entity types
entity_types = Counter(e.extraction_class for e in result.extractions)
print("Entity breakdown:")
for entity_type, count in entity_types.items():
percentage = (count / len(result.extractions)) * 100
print(f" {entity_type}: {count} entities ({percentage:.1f}%)")
# Find high-priority support tickets
urgent_entities = [
e for e in result.extractions
if e.extraction_class == "urgency_indicator"
and e.attributes.get("priority") == "high"
]
print(f"\nFound {len(urgent_entities)} high-priority indicators")Salida:
Entity breakdown:
product: 1 entities (25.0%)
timeline: 1 entities (25.0%)
urgency_indicator: 2 entities (50.0%)
Found 2 high-priority indicatorsEste análisis te ayuda a detectar rápidamente patrones como qué tipos de productos generan más tickets de soporte técnico o cuántas solicitudes urgentes recibes.
LangExtract guarda los resultados en formato JSONL (JSON Lines), donde cada línea contiene los datos extraídos de un documento. Este formato funciona bien con herramientas de procesamiento de datos y facilita la combinación de resultados de múltiples extracciones:
# Save results to a JSONL file
lx.io.save_annotated_documents(
[result],
output_name="support_ticket_extractions.jsonl",
output_dir="."
)JSONL almacena cada documento en una línea separada como un objeto JSON completo. A diferencia de los archivos JSON normales, que contienen un gran arreglo, los archivos JSONL se pueden procesar línea por línea, lo que los hace perfectos para conjuntos de datos de gran tamaño. Puedes abrir estos archivos en cualquier editor de texto o cargarlos en herramientas de análisis de datos como pandas.
La visualización HTML es donde LangExtract realmente destaca. Crea un informe interactivo que resalta las entidades extraídas del texto original y te permite hacer clic en los resultados:
# Generate interactive HTML visualization
html_content = lx.visualize("support_ticket_extractions.jsonl")
# Save the HTML file
with open("support_analysis.html", "w") as f:
if hasattr(html_content, "data"):
f.write(html_content.data) # For Jupyter notebooks
else:
f.write(html_content) # For regular Python scripts
print("HTML visualization saved as 'support_analysis.html'")Salida:
HTML visualization saved as 'support_analysis.html'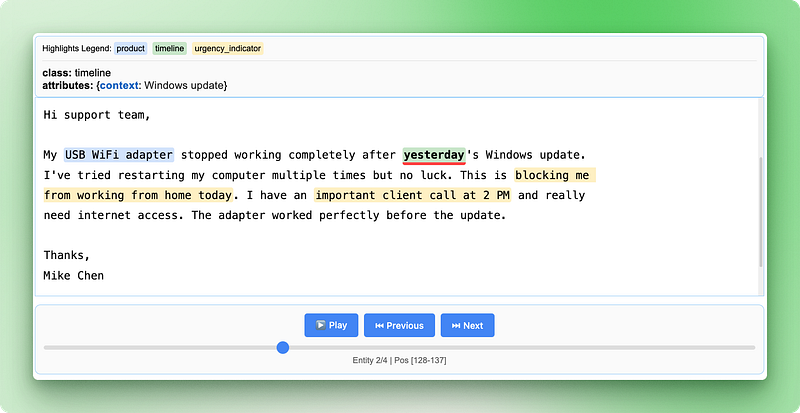
La visualización HTML muestra tu texto original con resaltados codificados por colores para cada tipo de entidad. Puedes hacer clic en el texto resaltado para ver los atributos extraídos, navegar entre las diferentes entidades utilizando los controles y verificar que la IA ha identificado correctamente la información importante. Esto facilita la comprobación aleatoria de los resultados y aumenta la confianza en tu canalización de extracción.
La visualización incluye una leyenda que muestra cada tipo de entidad, controles de navegación para desplazarse entre entidades e información detallada sobre los atributos de cada extracción. Este enfoque interactivo facilita mucho la comprensión y la validación de los resultados en comparación con la consulta de datos JSON sin procesar.
Las entidades de atención al cliente que hemos extraído funcionan bien individualmente, pero no cuentan toda la historia. Cuando un cliente menciona «mi MacBook Pro de 2021 tiene problemas con la batería», debes entender que el producto, el año del modelo y el problema forman parte de un mismo caso de asistencia técnica. Encontrar estas piezas por separado no sirve de nada: necesitas las relaciones entre ellas.
El PLN tradicional no maneja bien esta situación porque trata cada entidad como información aislada. Podrías extraer «MacBook Pro», «2021» y «problemas con la batería» como entidades separadas, pero entonces necesitarías reglas complejas para determinar qué detalles corresponden a cada producto. Este enfoque se desmorona rápidamente cuando se trata de múltiples productos o clientes en el mismo texto.
LangExtract resuelve este problema extrayendo las relaciones durante la pasada inicial, en lugar de intentar conectar las entidades posteriormente. Puedes agrupar información relacionada utilizando atributos compartidos sin dejar de rastrear exactamente de dónde proviene cada fragmento en el texto original. Trabajemos en la extracción de información de los empleados a partir de documentos de RR. HH., donde necesitamos relacionar a las personas con sus funciones, departamentos y datos de contacto.
Para este ejemplo, extraeremos información de los empleados de los anuncios de la empresa, en los que es necesario conectar múltiples detalles sobre cada persona:
import langextract as lx
import textwrap
# Define relationship extraction prompt
prompt = textwrap.dedent("""
Extract employee information from company announcements.
Group related details about each person using employee_group attributes.
Connect names, titles, departments, and contact info for each employee.
Use exact text from the announcement - don't paraphrase.
""")
# Create examples showing how to group related information
examples = [
lx.data.ExampleData(
text="Sarah Johnson, our new Marketing Director, will lead the digital campaigns team. You can reach Sarah at sarah.j@company.com for any marketing questions.",
extractions=[
lx.data.Extraction(
extraction_class="person",
extraction_text="Sarah Johnson",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="job_title",
extraction_text="Marketing Director",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="department",
extraction_text="digital campaigns team",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="contact",
extraction_text="sarah.j@company.com",
attributes={"employee_group": "Sarah Johnson", "type": "email"}
)
]
)
]El atributo employee_group actúa como un sistema de vinculación: todas las entidades con el mismo valor employee_group pertenecen a la misma persona. Esto te permite extraer información compleja y compuesta por varias partes, al tiempo que realizas un seguimiento de los detalles que van juntos.
Ahora extraigamos información de un anuncio de una empresa con varios empleados:
# Sample HR announcement with multiple employees
hr_announcement = """
We're excited to announce two new hires joining our team this month.
Mike Chen joins us as Senior Software Engineer in our Backend Development group. Mike brings 8 years of Python experience and will focus on API architecture. Please welcome Mike - he'll be working from our Seattle office and you can reach him at m.chen@company.com.
Additionally, Lisa Rodriguez starts as Product Manager for our Mobile Apps division. Lisa previously worked at TechStart Inc and has extensive experience with user research. Her office phone is 555-0199 and email is lisa.r@company.com.
"""
# Extract relationships
result = lx.extract(
text_or_documents=hr_announcement,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini"
)
print(f"Extracted {len(result.extractions)} entities")Salida:
✓ Extraction processing complete
INFO:absl:Finalizing annotation for document ID doc_a349ae1d.
INFO:absl:Document annotation completed.
✓ Extracted 10 entities (4 unique types)
• Time: 8.57s
• Speed: 67 chars/sec
• Chunks: 1
Extracted 10 entitiesDespués de la extracción, puedes agrupar las entidades relacionadas para ver la información completa de cada empleado. Para ello, es necesario utilizar código Python para organizar las entidades dispersas en grupos lógicos:
from collections import defaultdict
# Group entities by employee_group
employee_groups = defaultdict(list)
for extraction in result.extractions:
group_id = extraction.attributes.get("employee_group")
if group_id:
employee_groups[group_id].append(extraction)
# Print organized employee information
for employee, details in employee_groups.items():
print(f"\n=== {employee} ===")
for detail in details:
print(f"{detail.extraction_class}: {detail.extraction_text}")
if detail.attributes.get("type"):
print(f" Type: {detail.attributes['type']}")Salida:
=== Mike Chen ===
person: Mike Chen
job_title: Senior Software Engineer
department: Backend Development group
contact: m.chen@company.com
Type: email
contact: Seattle office
Type: location
=== Lisa Rodriguez ===
person: Lisa Rodriguez
job_title: Product Manager
department: Mobile Apps division
contact: lisa.r@company.com
Type: email
contact: 555-0199
Type: phoneEsto es lo que hace este código paso a paso:
defaultdict(list) crea un diccionario en el que cada nueva entrada comienza automáticamente como una lista vacíaextraction.attributes.get("employee_group") Obtiene de forma segura el ID de grupo a partir de los atributos de cada entidad y devuelve None si no existe.employee_groups[group_id].append(extraction) añade cada entidad a la lista de su grupodefaultdict es una colección de Python que crea automáticamente las entradas que faltan. Cuando accedes a employee_groups["Mike Chen"] por primera vez, se crea automáticamente una lista vacía para ese empleado. Esto te ahorra tener que comprobar si cada empleado ya existe en el diccionario.
Este enfoque de agrupación te permite reconstruir perfiles completos de empleados a partir de la información dispersa en el texto original, al tiempo que se mantienen las ubicaciones exactas de origen de cada dato.
La visualización HTML cobra aún más valor con los datos relacionales, ya que muestra tanto las entidades individuales como sus conexiones:
# Save the relationship extraction results
lx.io.save_annotated_documents(
[result],
output_name="employee_relationships.jsonl",
output_dir="."
)
# Generate HTML visualization showing relationships
html_content = lx.visualize("employee_relationships.jsonl")
with open("employee_relationships.html", "w") as f:
if hasattr(html_content, "data"):
f.write(html_content.data)
else:
f.write(html_content)
print("Relationship visualization saved as 'employee_relationships.html'")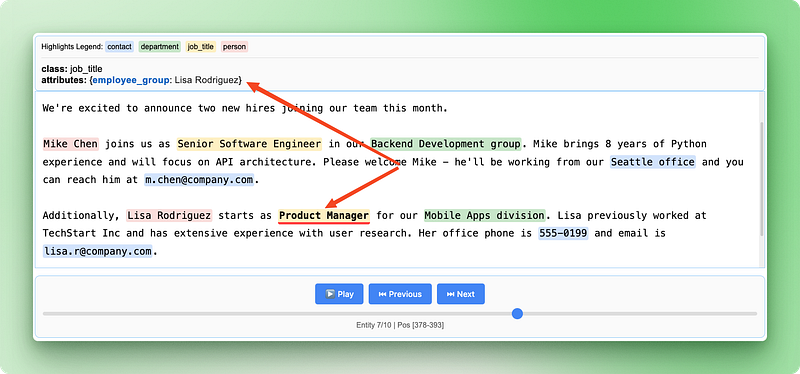
La visualización de las relaciones destaca cómo los diferentes datos se conectan para formar registros completos de los empleados, lo que facilita verificar que la IA haya identificado y agrupado correctamente los detalles relacionados del anuncio original.
LangExtract trabaja con varios proveedores de modelos de IA, cada uno de los cuales ofrece diferentes combinaciones entre coste, velocidad y precisión. Los modelos Gemini de Google funcionan desde el primer momento con soporte de esquema integrado, lo que los convierte en la opción más sencilla para la mayoría de las tareas de extracción. Los modelos GPT ( ) de OpenAI suelen ofrecer una mayor precisión, pero requieren una configuración adicional y tienen un coste mayor por extracción.
# Using Google Gemini (default and recommended)
result_gemini = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash" # Fast and cost-effective
)
# Using OpenAI GPT models
result_openai = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini",
fence_output=True, # Required for OpenAI
use_schema_constraints=False # OpenAI doesn't support constraints
)Para el procesamiento local o cuando quieras evitar los costes de la API, puedes ejecutar modelos localmente utilizando Ollama. Los modelos locales funcionan bien para tareas de extracción más sencillas y te ofrecen un control total sobre tus datos, aunque suelen ser más lentos y pueden ser menos precisos que las opciones basadas en la nube.
# Using local models with Ollama (requires Ollama installed)
result_local = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gemma2:2b", # Local Gemma model
model_url="http://localhost:11434", # Ollama server
fence_output=False, # Local models don't need fencing
use_schema_constraints=False # Disable constraints
)El texto del mundo real no se parece en nada a nuestros ejemplos limpios. Recibes informes de 50 páginas con un formato desordenado, correos electrónicos de clientes llenos de errores ortográficos y archivos PDF con espacios extraños. Algunos documentos contienen miles de palabras repartidas en diferentes secciones, y la información importante puede estar oculta en cualquier parte.
LangExtract maneja estas situaciones complicadas con tres herramientas principales: ejecutar varios documentos a la vez, intentar la extracción varias veces y dividir los documentos grandes en partes más pequeñas. En lugar de procesar un documento cada vez, puedes trabajar con varios documentos a la vez, lo que agiliza considerablemente el proceso.
# Settings for processing lots of real documents
result = lx.extract(
text_or_documents=document_batch,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
max_workers=20, # Work on many documents at once
extraction_passes=3, # Try extraction 3 times
max_char_buffer=1000 # Break big text into small pieces
)La configuración « max_workers » (Procesamiento de documentos) controla cuántos documentos se procesan al mismo tiempo. Más trabajadores significa resultados más rápidos, pero también cuesta más dinero y podría alcanzar los límites de la API. Empieza con 10-20 trabajadores y ve cómo va.
Las múltiples pasadas de extracción ayudan a encontrar información que podría pasarse por alto la primera vez. LangExtract ejecuta la extracción varias veces y combina los resultados. Esto capta más detalles, pero lleva más tiempo y es más caro.
Dividir los documentos en fragmentos ayuda con los textos largos. La configuración « max_char_buffer » (Ajustar al tamaño de la página) divide los documentos grandes en partes más pequeñas que funcionan mejor con los modelos de IA. Los fragmentos pequeños (1000-2000 caracteres) captan más detalles, mientras que los fragmentos grandes (3000-5000 caracteres) conservan más contexto, pero pueden pasar por alto algunos aspectos.
# Different settings for different types of documents
# For important documents that need careful review
detailed_result = lx.extract(
text_or_documents=legal_documents,
extraction_passes=5, # Try 5 times for accuracy
max_char_buffer=800, # Small chunks for detail
max_workers=10 # Fewer workers to avoid limits
)
# For quick processing of simple documents
quick_result = lx.extract(
text_or_documents=email_batch,
extraction_passes=1, # Single pass for speed
max_char_buffer=3000, # Bigger chunks for speed
max_workers=30 # More workers for faster results
)El trabajo de producción implica lidiar con problemas. Los documentos pueden tener errores de codificación, las conexiones de red pueden fallar y las API pueden limitar la velocidad de procesamiento. Supervisa tus trabajos de extracción, añade lógica de reintento para los documentos fallidos y programa cuánto estás gastando en diferentes proveedores de IA.
Cuando trabajes con diferentes tipos de documentos, configura reglas de extracción diferentes para cada tipo. Los contratos legales requieren indicaciones diferentes a las de los correos electrónicos de los clientes. Los informes financieros requieren tamaños de fragmentos diferentes a los de las publicaciones en redes sociales. Crea procesos separados para cada tipo de documento en lugar de intentar que un solo sistema se encargue de todo.
LangExtract adopta un enfoque diferente al de las bibliotecas tradicionales de PLN. Mientras que la mayoría de las bibliotecas se basan en modelos preentrenados o sistemas basados en reglas, LangExtract utiliza modelos de lenguaje grandes que pueden comprender el contexto y el significado como lo hacen los humanos. Comparémoslo con tres bibliotecas populares de NLP de Python para comprender cuándo elegirías LangExtract en lugar de otras opciones.
spaCy se centra en la velocidad y en tareas de PLN listas para la producción, como la tokenización, el etiquetado de partes del discurso y el reconocimiento de entidades nombradas. Incluye modelos preentrenados que reconocen entidades comunes como personas, organizaciones y ubicaciones, pero tiene dificultades con entidades específicas de un dominio o categorías personalizadas. spaCy destaca por su capacidad para procesar grandes cantidades de texto rápidamente, pero es necesario volver a entrenar los modelos o escribir reglas complejas para extraer información personalizada.
LangExtract elimina esta complejidad al permitirte definir entidades personalizadas mediante ejemplos y sugerencias sencillos, al tiempo que proporciona ubicaciones de origen exactas que spaCy no programa.
NLTK (Natural Language Toolkit) está diseñado para la educación y la investigación, y ofrece una amplia gama de algoritmos y conjuntos de datos de PLN. Proporciona los componentes básicos para el procesamiento de texto, pero requiere conocimientos significativos de programación para crear soluciones completas. NLTK funciona bien para aprender conceptos de PLN y crear prototipos, pero para construir sistemas de extracción listos para la producción es necesario combinar múltiples componentes de NLTK y escribir una cantidad considerable de código.
LangExtract ofrece una solución completa lista para usar: tú defines lo que deseas mediante ejemplos en lugar de algoritmos de codificación y obtienes visualizaciones interactivas sin necesidad de realizar trabajos de desarrollo adicionales.
Transformers (Hugging Face) ofrece acceso a modelos transformadores de última generación para diversas tareas de PLN, entre las que se incluyen el reconocimiento de entidades nombradas y la respuesta a preguntas. Aunque es potente, requiere conocimientos especializados en machine learning para ajustar los modelos a dominios específicos y no ofrece funciones integradas de seguimiento de fuentes ni extracción de relaciones. Debes gestionar la implementación de modelos, administrar diferentes formatos de modelos y crear tus propias herramientas de visualización.
LangExtract elimina la complejidad que supone trabajar con diferentes modelos de IA, gestiona automáticamente el seguimiento de fuentes y extrae relaciones mediante una sencilla agrupación de atributos, en lugar de complejas arquitecturas de modelos.
|
Característica |
LangExtract |
spaCy |
NLTK |
Transformers |
|
Complejidad de la configuración |
Indicaciones sencillas + ejemplos |
Entrenamiento/reglas del modelo |
Codificación de algoritmos |
Ajuste del modelo |
|
Entidades personalizadas |
Definición en lenguaje natural |
Se requiere reciclaje profesional |
Redacción manual de reglas |
Ajuste del modelo |
|
Seguimiento de fuentes |
Automático con posiciones exactas |
No disponible |
Implementación manual |
Implementación manual |
|
Extracción de relaciones |
Agrupación integrada |
Redacción de reglas complejas |
Codificación manual |
Desarrollo de modelos personalizados |
|
Comprensión del contexto |
Con tecnología LLM |
Basado en patrones |
Basado en reglas |
Dependiente del modelo |
|
Visualización |
HTML interactivo |
Herramientas externas necesarias |
Herramientas externas necesarias |
Herramientas externas necesarias |
|
Curva de aprendizaje |
Bajo (basado en ejemplos) |
Medio (conocimientos de PNL) |
Alto (algoritmos) |
Alto (experiencia en ML) |
|
Ideal para |
Extracción específica del dominio |
Pipelines generales de PNL |
Investigación/aprendizaje |
Aplicaciones de IA personalizadas |
LangExtract cambia la extracción de texto, pasando de escribir reglas complejas a mantener conversaciones con la IA sobre tus datos. Has aprendido a configurar la extracción de entidades personalizadas mediante sencillas indicaciones y ejemplos, a agrupar información relacionada mediante la extracción de relaciones y a crear visualizaciones interactivas que muestran exactamente de dónde proviene cada dato. La biblioteca gestiona retos de producción como el procesamiento paralelo y la fragmentación de documentos, lo que la hace práctica para aplicaciones del mundo real con texto desordenado e inconsistente.
Ya sea que estés procesando tickets de atención al cliente, analizando documentos legales o extrayendo información de artículos de investigación, LangExtract ofrece un enfoque más intuitivo que las bibliotecas tradicionales de PLN. En lugar de dedicar tiempo a entrenar modelos o redactar reglas, puedes centrarte en definir qué información es importante para tu caso de uso específico. Comienza con extracciones sencillas en tus propios datos de texto y, a continuación, amplía la escala utilizando las técnicas de producción que se describen en este tutorial.
¡Aprende IA con estos cursos!
Curso
Curso
Curso
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Dimitri Didmanidze

