
Kurs
Multi-Agent Systems mit LangGraph
2 Std. 45 Min.
6.5K
Das Herausziehen von strukturierten Daten aus Textdokumenten macht den Datenteams echt Probleme. Reguläre Ausdrücke funktionieren nicht mehr, wenn sich Formate ändern, benutzerdefinierter Parsing-Code übersieht Zusammenhänge, die Menschen leicht erkennen, und diese Lösungen müssen ständig angepasst werden, wenn sich deine Datenquellen ändern.
LangExtract löst dieses Problem durch den Einsatz von KI-Modellen, die Texte wie Menschen lesen und genau nachverfolgen können, woher die Infos kommen. Du sagst ihm einfach, welche Daten du willst, mit ein paar Beispielen, und es macht die harte Arbeit, diese Infos zu verstehen und rauszuziehen.
In diesem Tutorial zeige ich dir Schritt für Schritt, wie du LangExtract für die Erkennung benannter Entitäten einrichtest, Beziehungen zwischen Entitäten extrahierst, mit verschiedenen Anbietern von KI-Modellen arbeitest und den Ansatz von LangExtract mit traditionellen NLP-Bibliotheken vergleichst. Außerdem lernst du, wie du Extraktionsaufgaben definierst, Trainingsbeispiele bereitstellst und die strukturierten Ergebnisse für deine Analyse-Workflows verarbeitest.
LangExtract ist eine Python-Bibliothek, die mit KI-Modellen chaotischen Text in ordentliche Daten verwandelt. Alte Textverarbeitungsprogramme sind manchmal verwirrt vom Kontext – sie sehen vielleicht „Apple“ und denken, es geht um die Frucht, obwohl du über das Tech-Unternehmen liest, oder sie finden „500 $“ und denken, es ist ein Preis, obwohl es eigentlich eine Mitarbeiter-ID ist. Mit einfachen Mustervergleichen kann man zwar E-Mail-Adressen finden, aber nicht sagen, ob „john.doe@company.com“ ein aktueller Mitarbeiter ist oder nur jemand, der in einer alten E-Mail erwähnt wurde.
Um diese Probleme mit dem Kontext und der Genauigkeit zu lösen, bietet LangExtract dir:
Quelle: GitHub
Diese Tools helfen dir dabei, wie du Infos aus Texten rausholst. Anstatt komplizierte Regeln zu schreiben, die leicht kaputtgehen, sagst du der KI einfach mit einfachen Beispielen, was du willst. Die KI liest den Text wie ein Mensch und behält den Überblick darüber, woher alles kommt. Damit kannst du komplexe Infos und Zusammenhänge herausziehen, für die man früher hunderte von Codezeilen gebraucht hätte.
LangExtract ist super, wenn du bestimmte Infos extrahieren musst, die mit normalen NLP-Tools nicht so gut klappen. Wenn du mit Fachtexten arbeitest, bei denen die Standarderkennung benannter Entitäten nicht ausreicht, kannst du mit LangExtract genau festlegen, was für dein Unternehmen wichtig ist, ohne komplizierte Regeln zu schreiben oder Modelle neu zu trainieren. Das ist echt praktisch, wenn du den Zusammenhang und die Beziehungen zwischen verschiedenen Infos verstehen willst und nicht nur einzelne Sachen finden musst.
LangExtract ist eine gute Wahl, wenn du:
Du solltest andere Tools in Betracht ziehen, wenn du mit gängigen NLP-Aufgaben wie der grundlegenden Erkennung benannter Entitäten für allgemeine Kategorien arbeitest, extrem schnelle Verarbeitung einfacher Muster brauchst oder strenge Anforderungen hast, um externe API-Aufrufe zu vermeiden. Traditionelle Bibliotheken wie spaCy sind super bei Standard-NLP-Aufgaben mit vielen Daten, während LangExtract dann richtig gut ist, wenn du intelligente, angepasste Extraktion mit minimalem Einrichtungsaufwand brauchst.
Bevor du mit der Datenextraktion loslegen kannst, musst du LangExtract installieren und den Zugriff auf KI-Modelle einrichten. Die Bibliothek unterstützt mehrere Installationsmethoden und funktioniert mit verschiedenen KI-Anbietern.
Installier LangExtract mit pip oder uv. Für OpenAI benutze das Extras-Paket:
# Using pip
pip install langextract[openai]
# Using uv
uv add langextract[openai]Das Extra „ [openai] “ hat den OpenAI Python-Client dabei. Bei anderen Anbietern kannst du das Basispaket installieren und bei Bedarf anbieterspezifische Bibliotheken hinzufügen.
LangExtract arbeitet mit mehreren KI-Anbietern zusammen. Richte API-Schlüssel als Umgebungsvariablen ein:
# OpenAI (get your key from https://platform.openai.com/api-keys)
export OPENAI_API_KEY="your-openai-key-here"
# Anthropic (get your key from https://console.anthropic.com/settings/keys)
export ANTHROPIC_API_KEY="your-anthropic-key-here"
# Google AI (get your key from https://aistudio.google.com/app/apikey)
export GOOGLE_API_KEY="your-google-key-here"Du brauchst nur die Schlüssel für die Anbieter, die du nutzen willst. Für lokale Modelle über Ollama brauchst du keine API-Schlüssel – installiere einfach Ollama auf deinem Rechner und starte es.
Überprüfe deine Einstellungen mit einem einfachen Test:
import langextract as lx
import textwrap
# 1. Define the prompt and extraction rules
prompt = textwrap.dedent(
"""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context."""
)
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
],
)
]
# The input text to be processed
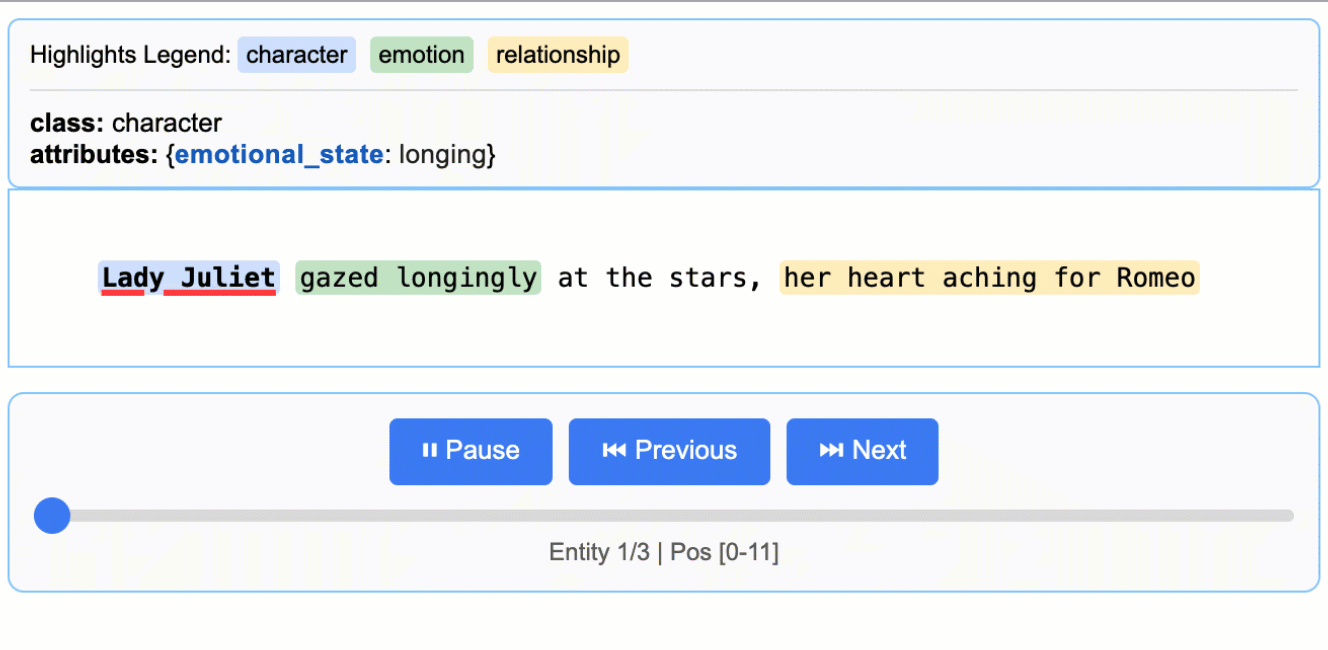
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# Run the extraction
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini",
)
print("Extraction successful!")Die Named Entity Recognition (NER) findet und sortiert bestimmte Infos in Texten, zum Beispiel alle Firmennamen, Personen und Orte, die in einem Geschäftsbericht erwähnt werden.
Herkömmliche NER-Tools arbeiten mit vordefinierten Kategorien wie „PERSON“ oder „ORGANISATION“, übersehen aber oft kontextspezifische Entitäten, die für dein Unternehmen wichtig sind. Mit LangExtract kannst du eigene Entitätstypen festlegen und der KI beibringen, bestimmte Muster in deinem Bereich zu erkennen.
Schauen wir uns mal an, wie man Entitäten aus Kundensupport-E-Mails herausholt. Statt allgemeiner Kategorien schauen wir uns lieber support-spezifische Sachen an, wie zum Beispiel Beschwerdearten, Produktnamen und Lösungsfristen, die dabei helfen, Tickets zu priorisieren.
Der erste Schritt besteht darin, mit einer klaren Eingabeaufforderung zu beschreiben, was du extrahieren möchtest. Diese Eingabeaufforderung ist wie eine Anleitung für einen menschlichen Analysten – je genauer du bist, desto besser sind die Ergebnisse:
import langextract as lx
import textwrap
# Define what we want to extract from support emails
prompt = textwrap.dedent("""
Extract customer support entities from email text.
Focus on actionable information that helps prioritize and route tickets.
Use exact text from the email - don't paraphrase or summarize.
Include helpful attributes that add context for support agents.
""")Die Funktion „ textwrap.dedent() “ entfernt überflüssige Einrückungen aus mehrzeiligen Zeichenfolgen, sodass deine Eingabeaufforderungen im Code besser lesbar sind und gleichzeitig beim Senden an die KI übersichtlich bleiben. Ohne das würde die KI alle zusätzlichen Leerzeichen aus deiner Code-Einrückung sehen.
Diese Eingabeaufforderung sagt der KI, dass sie nach support-spezifischen Infos suchen, genaue Zitate aus dem Text verwenden und durch Attribute Kontext hinzufügen soll. Der Schlüssel liegt darin, genau zu sagen, worum es bei deinem Bereich (Kundensupport) geht und was Infos nützlich macht (hilft bei der Priorisierung und Weiterleitung von Tickets).
Beispiele zeigen der KI genau, was du willst und wie die Ergebnisse formatiert werden sollen. Jedes Beispiel zeigt der KI einen Text und genau die Teile, die du daraus extrahieren willst:
# Create examples that show the AI what to extract
examples = [
lx.data.ExampleData(
text="My laptop screen keeps flickering. I bought it 3 months ago and need this fixed urgently for my presentation tomorrow.",
extractions=[
lx.data.Extraction(
extraction_class="product",
extraction_text="laptop",
attributes={"issue": "screen flickering", "urgency": "high"}
),
lx.data.Extraction(
extraction_class="timeline",
extraction_text="3 months ago",
attributes={"context": "purchase_date"}
),
lx.data.Extraction(
extraction_class="urgency_indicator",
extraction_text="urgently for my presentation tomorrow",
attributes={"priority": "high", "deadline": "tomorrow"}
)
]
)
]Jedes „ ExampleData “-Objekt hat ein Textbeispiel und eine Liste von „ Extraction “-Objekten. Die Objekte „ Extraction “ sagen drei Sachen:
extraction_class: Die Art der Entität (wie „Produkt“ oder „Zeitleiste“)extraction_text: Die genauen Worte aus dem Originaltextattributes: Zusätzlicher Kontext, der hilft, die Entität besser zu verstehenDie Attribute machen LangExtract anders als herkömmliche NER. Anstatt einfach nur „Laptop“ zu suchen, können wir festhalten, dass es ein Problem mit „Bildschirmflackern“ gibt, und es als sehr dringend markieren.
Jetzt kannst du die Extraktion für neuen Text mit deiner Eingabeaufforderung und deinen Beispielen machen. LangExtract nutzt das Gelernte, um ähnliche Entitäten zu finden:
# Sample support email to analyze
support_email = """
Subject: WiFi adapter not working after Windows update
Hi support team,
My USB WiFi adapter stopped working completely after yesterday's Windows update.
I've tried restarting my computer multiple times but no luck. This is blocking me
from working from home today. I have an important client call at 2 PM and really
need internet access. The adapter worked perfectly before the update.
Thanks,
Mike Chen
"""
# Run the extraction
result = lx.extract(
text_or_documents=support_email,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini"
)
print("Extraction completed successfully!")Ausgabe:
INFO:absl:Finalizing annotation for document ID doc_435b1cd5.
INFO:absl:Document annotation completed.
✓ Extracted 4 entities (3 unique types)
• Time: 3.34s
• Speed: 123 chars/sec
• Chunks: 1
Extraction completed successfully!Die Funktion „ lx.extract() “ nimmt deinen Text, wendet die Eingabeaufforderungen an und nutzt die Beispiele, um die Extraktion zu steuern. Es gibt ein Ergebnisobjekt zurück, das alle gefundenen Entitäten zusammen mit ihren genauen Positionen im Originaltext enthält.
Du kannst mit verschiedenen Modellen experimentieren, indem du den Parameter „ model_id “ änderst. Modelle wie "claude-3-haiku" oder "gpt-4o" können je nach Komplexität deines Textes und deinen Anforderungen unterschiedliche Ergebnisse liefern.
Sobald die Extraktion fertig ist, gibt LangExtract ein Ergebnisobjekt zurück, das alle gefundenen Entitäten mit ihren genauen Positionen und Attributen enthält. Die wahre Stärke liegt darin, wie du auf diese strukturierten Daten zugreifen, sie analysieren und teilen kannst.
Das Ergebnisobjekt speichert alle gefundenen Entitäten in der Eigenschaft „ extractions “. Jede Extraktion hat den Entitätstext, seinen Typ, die Position im Originaldokument und alle Attribute:
# Look at all extracted entities
for extraction in result.extractions:
print(f"Type: {extraction.extraction_class}")
print(f"Text: '{extraction.extraction_text}'")
print(f"Location: chars {extraction.char_interval.start_pos}-{extraction.char_interval.end_pos}")
print(f"Attributes: {extraction.attributes}")
print("---")Ausgabe:
Type: product
Text: 'USB WiFi adapter'
Location: chars 78-94
Attributes: {'issue': 'not working after Windows update', 'previous_status': 'worked perfectly before the update'}
---
Type: timeline
Text: 'yesterday'
Location: chars 128-137
Attributes: {'context': 'Windows update'}
---
Type: urgency_indicator
Text: 'blocking me from working from home today'
Location: chars 227-268
Attributes: {'priority': 'high', 'context': 'work from home'}
---
Type: urgency_indicator
Text: 'important client call at 2 PM'
Location: chars 280-309
Attributes: {'priority': 'high', 'deadline': '2 PM today'}
---Jedes Extraktionsobjekt verfolgt genau, woher die Infos kommen, indem es „ char_interval “ nutzt, das die Start- und Endpositionen im Originaltext anzeigt. Mit dieser Quellenverfolgung kannst du Ergebnisse überprüfen und den Kontext verstehen.
Du kannst Entitäten gruppieren und zählen, um Muster in deinen Daten zu erkennen:
from collections import Counter
# Count different entity types
entity_types = Counter(e.extraction_class for e in result.extractions)
print("Entity breakdown:")
for entity_type, count in entity_types.items():
percentage = (count / len(result.extractions)) * 100
print(f" {entity_type}: {count} entities ({percentage:.1f}%)")
# Find high-priority support tickets
urgent_entities = [
e for e in result.extractions
if e.extraction_class == "urgency_indicator"
and e.attributes.get("priority") == "high"
]
print(f"\nFound {len(urgent_entities)} high-priority indicators")Ausgabe:
Entity breakdown:
product: 1 entities (25.0%)
timeline: 1 entities (25.0%)
urgency_indicator: 2 entities (50.0%)
Found 2 high-priority indicatorsMit dieser Analyse kannst du schnell Muster erkennen, z. B. welche Produkttypen die meisten Support-Tickets verursachen oder wie viele dringende Anfragen du bekommst.
LangExtract speichert die Ergebnisse im JSONL-Format (JSON Lines), wobei jede Zeile die Extraktionsdaten eines Dokuments enthält. Dieses Format passt super zu Datenverarbeitungstools und macht es einfach, Ergebnisse aus mehreren Extraktionen zusammenzufassen:
# Save results to a JSONL file
lx.io.save_annotated_documents(
[result],
output_name="support_ticket_extractions.jsonl",
output_dir="."
)JSONL speichert jedes Dokument in einer eigenen Zeile als komplettes JSON-Objekt. Im Gegensatz zu normalen JSON-Dateien, die ein großes Array haben, können JSONL-Dateien Zeile für Zeile verarbeitet werden, was sie super für große Datensätze macht. Du kannst diese Dateien in jedem Texteditor öffnen oder in Datenanalyse-Tools wie pandas laden.
Die HTML-Visualisierung ist das, was LangExtract wirklich auszeichnet. Es erstellt einen interaktiven Bericht, der die extrahierten Entitäten im Originaltext hervorhebt und es dir ermöglicht, dich durch die Ergebnisse zu klicken:
# Generate interactive HTML visualization
html_content = lx.visualize("support_ticket_extractions.jsonl")
# Save the HTML file
with open("support_analysis.html", "w") as f:
if hasattr(html_content, "data"):
f.write(html_content.data) # For Jupyter notebooks
else:
f.write(html_content) # For regular Python scripts
print("HTML visualization saved as 'support_analysis.html'")Ausgabe:
HTML visualization saved as 'support_analysis.html'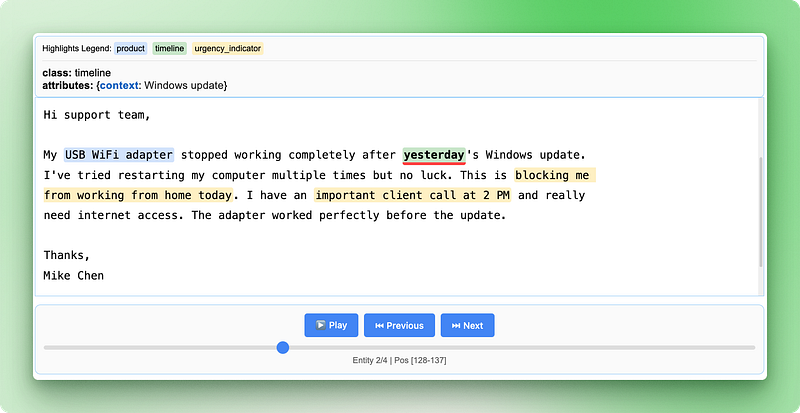
Die HTML-Visualisierung zeigt deinen Originaltext mit farbigen Markierungen für jeden Entitätstyp. Du kannst auf den hervorgehobenen Text klicken, um die extrahierten Attribute anzuzeigen, mit den Steuerelementen zwischen verschiedenen Entitäten navigieren und überprüfen, ob die KI wichtige Informationen richtig erkannt hat. So kannst du die Ergebnisse ganz einfach stichprobenartig überprüfen und Vertrauen in deine Extraktionspipeline aufbauen.
Die Visualisierung hat eine Legende, die jeden Entitätstyp zeigt, Navigationssteuerelemente, um zwischen den Entitäten zu wechseln, und detaillierte Attributinfos für jede Extraktion. Dieser interaktive Ansatz macht es viel einfacher, deine Ergebnisse zu verstehen und zu überprüfen, als wenn du dir nur die rohen JSON-Daten anschaust.
Die Kundensupport-Einheiten, die wir herausgearbeitet haben, funktionieren einzeln gut, aber sie zeigen nicht das ganze Bild. Wenn ein Kunde sagt: „Mein MacBook Pro von 2021 hat Probleme mit dem Akku“, musst du wissen, dass das Produkt, das Modelljahr und das Problem alle zusammen einen Supportfall bilden. Es bringt nichts, diese Teile einzeln zu suchen – du brauchst die Beziehungen zwischen ihnen.
Traditionelle NLP-Verfahren kommen damit nicht gut klar, weil sie jede Entität als isolierte Information behandeln. Du könntest „MacBook Pro“, „2021“ und „Batterieprobleme“ als separate Begriffe herausziehen, aber dann brauchst du komplizierte Regeln, um rauszufinden, welche Details zu welchen Produkten passen. Dieser Ansatz funktioniert nicht gut, wenn man mehrere Produkte oder Kunden im selben Text hat.
LangExtract löst das, indem es die Beziehungen schon beim ersten Durchlauf herauszieht, anstatt später zu versuchen, die Entitäten zu verbinden. Du kannst ähnliche Infos über gemeinsame Attribute gruppieren und trotzdem genau nachverfolgen, woher jedes Element im Originaltext kommt. Lass uns mal schauen, wie wir Mitarbeiterinfos aus HR-Dokumenten rausziehen können, wo wir Leute mit ihren Rollen, Abteilungen und Kontaktdaten verknüpfen müssen.
In diesem Beispiel holen wir Mitarbeiterinfos aus Unternehmensankündigungen raus, wo mehrere Details zu jeder Person miteinander verknüpft werden müssen:
import langextract as lx
import textwrap
# Define relationship extraction prompt
prompt = textwrap.dedent("""
Extract employee information from company announcements.
Group related details about each person using employee_group attributes.
Connect names, titles, departments, and contact info for each employee.
Use exact text from the announcement - don't paraphrase.
""")
# Create examples showing how to group related information
examples = [
lx.data.ExampleData(
text="Sarah Johnson, our new Marketing Director, will lead the digital campaigns team. You can reach Sarah at sarah.j@company.com for any marketing questions.",
extractions=[
lx.data.Extraction(
extraction_class="person",
extraction_text="Sarah Johnson",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="job_title",
extraction_text="Marketing Director",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="department",
extraction_text="digital campaigns team",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="contact",
extraction_text="sarah.j@company.com",
attributes={"employee_group": "Sarah Johnson", "type": "email"}
)
]
)
]Das Attribut „ employee_group “ ist wie ein Verbindungssystem – alle Entitäten mit dem gleichen Wert für „ employee_group “ gehören zu derselben Person. Damit kannst du komplexe, mehrteilige Infos herausziehen und gleichzeitig im Blick behalten, welche Details zusammen gehören.
Jetzt schauen wir uns mal eine Unternehmensmitteilung mit mehreren Mitarbeitern an:
# Sample HR announcement with multiple employees
hr_announcement = """
We're excited to announce two new hires joining our team this month.
Mike Chen joins us as Senior Software Engineer in our Backend Development group. Mike brings 8 years of Python experience and will focus on API architecture. Please welcome Mike - he'll be working from our Seattle office and you can reach him at m.chen@company.com.
Additionally, Lisa Rodriguez starts as Product Manager for our Mobile Apps division. Lisa previously worked at TechStart Inc and has extensive experience with user research. Her office phone is 555-0199 and email is lisa.r@company.com.
"""
# Extract relationships
result = lx.extract(
text_or_documents=hr_announcement,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini"
)
print(f"Extracted {len(result.extractions)} entities")Ausgabe:
✓ Extraction processing complete
INFO:absl:Finalizing annotation for document ID doc_a349ae1d.
INFO:absl:Document annotation completed.
✓ Extracted 10 entities (4 unique types)
• Time: 8.57s
• Speed: 67 chars/sec
• Chunks: 1
Extracted 10 entitiesNach der Extraktion kannst du die zugehörigen Entitäten gruppieren, um die vollständigen Infos zu jedem Mitarbeiter anzuzeigen. Dafür braucht man Python-Code, um die verstreuten Entitäten wieder in logische Gruppen zu sortieren:
from collections import defaultdict
# Group entities by employee_group
employee_groups = defaultdict(list)
for extraction in result.extractions:
group_id = extraction.attributes.get("employee_group")
if group_id:
employee_groups[group_id].append(extraction)
# Print organized employee information
for employee, details in employee_groups.items():
print(f"\n=== {employee} ===")
for detail in details:
print(f"{detail.extraction_class}: {detail.extraction_text}")
if detail.attributes.get("type"):
print(f" Type: {detail.attributes['type']}")Ausgabe:
=== Mike Chen ===
person: Mike Chen
job_title: Senior Software Engineer
department: Backend Development group
contact: m.chen@company.com
Type: email
contact: Seattle office
Type: location
=== Lisa Rodriguez ===
person: Lisa Rodriguez
job_title: Product Manager
department: Mobile Apps division
contact: lisa.r@company.com
Type: email
contact: 555-0199
Type: phoneHier ist, was dieser Code Schritt für Schritt macht:
defaultdict(list) Erstellt ein Wörterbuch, in dem jeder neue Eintrag automatisch als leere Liste anfängt.extraction.attributes.get("employee_group") holt sicher die Gruppen-ID aus den Attributen jeder Entität und gibt sie zurück None zurück, wenn sie nicht da ist.employee_groups[group_id].append(extraction) fügt jede Entität zur Liste ihrer Gruppe hinzuDie Python-Sammlung „ defaultdict ” macht automatisch fehlende Einträge. Wenn du zum ersten Mal auf employee_groups["Mike Chen"] zugreifst, wird automatisch eine leere Liste für diesen Mitarbeiter erstellt. So musst du nicht für jeden Mitarbeiter checken, ob er schon im Wörterbuch steht.
Mit diesem Gruppierungsansatz kannst du aus den verstreuten Infos im Originaltext komplette Mitarbeiterprofile erstellen und dabei die genauen Quellenangaben für jede einzelne Info beibehalten.
Die HTML-Visualisierung wird mit Beziehungsdaten noch wertvoller, weil sie sowohl einzelne Entitäten als auch deren Verbindungen zeigt:
# Save the relationship extraction results
lx.io.save_annotated_documents(
[result],
output_name="employee_relationships.jsonl",
output_dir="."
)
# Generate HTML visualization showing relationships
html_content = lx.visualize("employee_relationships.jsonl")
with open("employee_relationships.html", "w") as f:
if hasattr(html_content, "data"):
f.write(html_content.data)
else:
f.write(html_content)
print("Relationship visualization saved as 'employee_relationships.html'")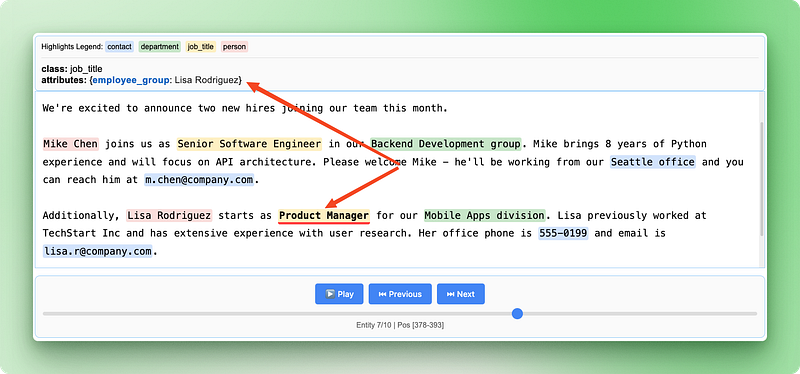
Die Visualisierung der Beziehungen zeigt, wie verschiedene Infos zusammenpassen, um vollständige Mitarbeiterdaten zu bilden. So kann man leicht überprüfen, ob die KI die relevanten Details aus der ursprünglichen Ankündigung richtig erkannt und gruppiert hat.
LangExtract arbeitet mit mehreren Anbietern von KI-Modellen zusammen, die alle unterschiedliche Kompromisse zwischen Kosten, Geschwindigkeit und Genauigkeit bieten. Die Gemini-Modelle von Google funktionieren sofort mit integrierter Schema-Unterstützung und sind damit die einfachste Option für die meisten Extraktionsaufgaben. Die GPT-Modelle von OpenAI ( ) sind oft genauer, brauchen aber zusätzliche Einstellungen und kosten mehr pro Extraktion.
# Using Google Gemini (default and recommended)
result_gemini = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash" # Fast and cost-effective
)
# Using OpenAI GPT models
result_openai = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini",
fence_output=True, # Required for OpenAI
use_schema_constraints=False # OpenAI doesn't support constraints
)Für die lokale Verarbeitung oder wenn du API-Kosten vermeiden willst, kannst du Modelle lokal mit Ollama ausführen. Lokale Modelle eignen sich gut für einfachere Extraktionsaufgaben und geben dir die volle Kontrolle über deine Daten, laufen aber normalerweise langsamer und sind möglicherweise weniger genau als Cloud-Optionen.
# Using local models with Ollama (requires Ollama installed)
result_local = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gemma2:2b", # Local Gemma model
model_url="http://localhost:11434", # Ollama server
fence_output=False, # Local models don't need fencing
use_schema_constraints=False # Disable constraints
)Echte Texte sehen überhaupt nicht so aus wie unsere sauberen Beispiele. Du kriegst 50-seitige Berichte mit chaotischer Formatierung, Kunden-E-Mails voller Tippfehler und PDFs mit komischen Abständen. Manche Dokumente haben echt viele Wörter, die über verschiedene Abschnitte verteilt sind, und die wichtigen Infos können überall versteckt sein.
LangExtract geht mit diesen schwierigen Situationen mit drei Hauptwerkzeugen um: mehrere Dokumente gleichzeitig verarbeiten, die Extraktion mehrmals versuchen und große Dokumente in kleinere Teile aufteilen. Anstatt ein Dokument nach dem anderen zu bearbeiten, kannst du mehrere Dokumente gleichzeitig bearbeiten, was den Vorgang erheblich beschleunigt.
# Settings for processing lots of real documents
result = lx.extract(
text_or_documents=document_batch,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
max_workers=20, # Work on many documents at once
extraction_passes=3, # Try extraction 3 times
max_char_buffer=1000 # Break big text into small pieces
)Die Einstellung „ max_workers “ bestimmt, wie viele Dokumente gleichzeitig bearbeitet werden. Mehr Leute bedeuten schnellere Ergebnisse, aber es kostet auch mehr Geld und könnte die API-Limits erreichen. Fang mit 10 bis 20 Leuten an und schau mal, wie's läuft.
Mehrere Extraktionsdurchläufe helfen dabei, Infos zu finden, die beim ersten Mal vielleicht übersehen wurden. LangExtract macht die Extraktion mehrmals und setzt die Ergebnisse zusammen. Das fängt mehr Details ein, dauert aber länger und kostet mehr.
Dokumente in kleinere Teile aufzuteilen ist bei langen Texten echt hilfreich. Die Option „ max_char_buffer “ teilt große Dokumente in kleinere Teile auf, die besser mit KI-Modellen funktionieren. Kleine Abschnitte (1000–2000 Zeichen) fangen mehr Details ein, während große Abschnitte (3000–5000 Zeichen) mehr Kontext behalten, aber möglicherweise Dinge übersehen.
# Different settings for different types of documents
# For important documents that need careful review
detailed_result = lx.extract(
text_or_documents=legal_documents,
extraction_passes=5, # Try 5 times for accuracy
max_char_buffer=800, # Small chunks for detail
max_workers=10 # Fewer workers to avoid limits
)
# For quick processing of simple documents
quick_result = lx.extract(
text_or_documents=email_batch,
extraction_passes=1, # Single pass for speed
max_char_buffer=3000, # Bigger chunks for speed
max_workers=30 # More workers for faster results
)Produktionsarbeit heißt, sich mit Problemen auseinanderzusetzen. Dokumente können Fehler in der Kodierung haben, Netzwerkverbindungen können abstürzen und APIs können die Verarbeitungsgeschwindigkeit einschränken. Behalte deine Extraktionsaufträge im Auge, füge eine Wiederholungslogik für fehlgeschlagene Dokumente hinzu und verfolge, wie viel du für verschiedene KI-Anbieter ausgibst.
Wenn du mit verschiedenen Dokumenttypen arbeitest, richte für jeden Typ unterschiedliche Extraktionsregeln ein. Verträge brauchen andere Vorlagen als Kunden-E-Mails. Finanzberichte brauchen andere Textlängen als Social-Media-Beiträge. Mach für jeden Dokumenttyp eigene Pipelines, statt zu versuchen, alles mit einem einzigen System zu regeln.
LangExtract macht es anders als die üblichen NLP-Bibliotheken. Während die meisten Bibliotheken auf vorab trainierte Modelle oder regelbasierte Systeme setzen, nutzt LangExtract große Sprachmodelle, die Kontext und Bedeutung wie Menschen verstehen können. Vergleichen wir es mal mit drei beliebten Python-NLP-Bibliotheken, um zu sehen, wann man LangExtract anderen Optionen vorziehen würde.
spaCy konzentriert sich auf Geschwindigkeit und produktionsreife NLP-Aufgaben wie Tokenisierung, Part-of-Speech-Tagging und Named-Entity-Erkennung. Es kommt mit vorab trainierten Modellen, die gängige Entitäten wie Personen, Organisationen und Orte erkennen, hat aber Probleme mit domänenspezifischen Entitäten oder benutzerdefinierten Kategorien. spaCy ist super darin, große Textmengen schnell zu verarbeiten, aber du musst die Modelle neu trainieren oder komplexe Regeln schreiben, um benutzerdefinierte Infos zu extrahieren.
LangExtract macht Schluss mit dieser Komplexität, indem es dir erlaubt, benutzerdefinierte Entitäten anhand einfacher Beispiele und Eingabeaufforderungen zu definieren, und gleichzeitig genaue Quellpositionen angibt, die spaCy nicht verfolgt.
NLTK (Natural Language Toolkit) ist für Bildung und Forschung gedacht und hat eine große Auswahl an NLP-Algorithmen und Datensätzen. Es bietet Bausteine für die Textverarbeitung, aber man braucht schon einiges an Programmierwissen, um komplette Lösungen zu erstellen. NLTK eignet sich gut zum Lernen von NLP-Konzepten und zum Prototyping, aber um produktionsreife Extraktionssysteme zu bauen, muss man mehrere NLTK-Komponenten kombinieren und ziemlich viel Code schreiben.
LangExtract bietet dir eine komplette Lösung, die sofort einsatzbereit ist – du legst anhand von Beispielen fest, was du willst, anstatt Algorithmen zu programmieren, und bekommst interaktive Visualisierungen ohne zusätzliche Entwicklungsarbeit.
Transformatoren (Hugging Face) bietet Zugang zu den neuesten Transformer-Modellen für verschiedene NLP-Aufgaben, wie zum Beispiel die Erkennung benannter Entitäten und die Beantwortung von Fragen. Obwohl es echt leistungsstark ist, braucht man Fachwissen im Bereich maschinelles Lernen, um die Modelle für bestimmte Bereiche genau anzupassen, und es hat keine integrierte Quellenverfolgung oder Beziehungsextraktion. Du musst die Bereitstellung von Modellen organisieren, verschiedene Modellformate verwalten und deine eigenen Visualisierungstools entwickeln.
LangExtract macht die Arbeit mit verschiedenen KI-Modellen einfacher, kümmert sich automatisch um die Quellenverfolgung und extrahiert Beziehungen durch einfache Attributgruppierung statt durch komplizierte Modellarchitekturen.
|
Feature |
LangExtract |
spaCy |
NLTK |
Transformatoren |
|
Komplexität der Einrichtung |
Einfache Anweisungen + Beispiele |
Modelltraining/Regeln |
Algorithmus-Codierung |
Modelloptimierung |
|
Benutzerdefinierte Entitäten |
Definition in natürlicher Sprache |
Umschulung nötig |
Manuelles Schreiben von Regeln |
Modelloptimierung |
|
Quellverfolgung |
Automatisch mit genauen Positionen |
Nicht verfügbar |
Manuelle Umsetzung |
Manuelle Umsetzung |
|
Beziehung extrahieren |
Eingebaute Gruppierung |
Komplexe Regelsetzung |
Manuelle Codierung |
Entwicklung von kundenspezifischen Modellen |
|
Verständnis des Kontexts |
LLM-basiert |
Musterbasiert |
Regelbasiert |
Modellabhängig |
|
Visualisierung |
Interaktives HTML |
Benötigte externe Tools |
Benötigte externe Tools |
Benötigte externe Tools |
|
Lernkurve |
Niedrig (mit Beispielen) |
Mittlere Kenntnisse (NLP-Kenntnisse) |
Hoch (Algorithmen) |
Hoch (ML-Fachwissen) |
|
Am besten geeignet für |
Domänenspezifische Extraktion |
Allgemeine NLP-Pipelines |
Forschung/Lernen |
Individuelle KI-Anwendungen |
LangExtract macht das Auslesen von Texten einfacher, indem man nicht mehr komplizierte Regeln schreiben muss, sondern einfach mit der KI über deine Daten quatschen kann. Du hast gelernt, wie du mit einfachen Eingabeaufforderungen und Beispielen eine benutzerdefinierte Entitätsextraktion einrichtest, verwandte Infos durch Beziehungsextraktion gruppierst und interaktive Visualisierungen erstellst, die genau zeigen, woher die einzelnen Daten stammen. Die Bibliothek kümmert sich um Produktionsherausforderungen wie Parallelverarbeitung und Dokumentaufteilung, was sie praktisch für echte Anwendungen mit chaotischem, inkonsistentem Text macht.
Egal, ob du Kundensupport-Tickets bearbeitest, juristische Dokumente analysierst oder Erkenntnisse aus Forschungsarbeiten gewinnst – LangExtract bietet dir einen intuitiveren Ansatz als herkömmliche NLP-Bibliotheken. Anstatt Zeit mit dem Trainieren von Modellen oder dem Schreiben von Regeln zu verbringen, kannst du dich darauf konzentrieren, zu definieren, welche Infos für deinen speziellen Anwendungsfall wichtig sind. Fang mit einfachen Extraktionen deiner eigenen Textdaten an und mach dann weiter mit den Produktionstechniken, die in diesem Tutorial behandelt werden.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Tutorial
Allan Ouko
Tutorial
Derrick Mwiti
Tutorial
Moez Ali
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
