
Curso
Sistemas Multiagentes com LangGraph
2 h 45 min
6.5K
Extrair dados estruturados de documentos de texto cria grandes problemas para as equipes de dados. As expressões regulares quebram quando os formatos mudam, o código de análise personalizado perde o contexto que os humanos percebem facilmente e essas soluções precisam de correções constantes à medida que suas fontes de dados mudam.
O LangExtract resolve isso usando modelos de IA que conseguem ler textos como os humanos e programam exatamente de onde vem a informação. Você diz quais dados quer de forma simples, com alguns exemplos, e ele faz o trabalho pesado de entender e extrair essas informações.
Neste tutorial, vou explicar passo a passo como configurar o LangExtract para reconhecimento de entidades nomeadas, extrair relações entre entidades, trabalhar com diferentes provedores de modelos de IA e comparar a abordagem do LangExtract com as bibliotecas tradicionais de NLP. Você também vai aprender a definir tarefas de extração, fornecer exemplos de treinamento e processar os resultados estruturados para seus fluxos de trabalho de análise.
LangExtract é uma biblioteca Python que transforma textos confusos em dados organizados usando modelos de IA. As ferramentas antigas de processamento de texto ficam confusas com o contexto — elas podem ver “Apple” e achar que é uma fruta quando você está lendo sobre a empresa de tecnologia, ou encontrar “$500” e chamar isso de preço quando, na verdade, é um número de identificação de funcionário. A correspondência de padrões básicos pode identificar endereços de e-mail, mas não consegue dizer se “john.doe@company.com” é um funcionário atual ou apenas alguém mencionado em um e-mail antigo.
Para resolver esses problemas de contexto e precisão, o LangExtract oferece:
Fonte: GitHub
Essas ferramentas funcionam juntas para mudar a forma como você extrai informações do texto. Em vez de escrever regras complicadas que quebram fácil, você diz pra IA o que você quer usando exemplos simples. A IA lê o texto como um humano faria e fica de olho na origem de tudo. Isso permite extrair informações e relações complexas que, da maneira antiga, exigiriam centenas de linhas de código para serem encontradas.
O LangExtract funciona melhor quando você precisa extrair informações personalizadas que as ferramentas tradicionais de PLN não conseguem lidar bem. Se você estiver trabalhando com textos específicos de um domínio em que o reconhecimento padrão de entidades nomeadas não é suficiente, o LangExtract permite definir exatamente o que é importante para o seu negócio sem precisar escrever regras complexas ou retreinar modelos. É super útil quando você precisa entender o contexto e as relações entre diferentes informações, não só encontrar entidades individuais.
O LangExtract é uma boa escolha quando você tem:
Você deve pensar em outras ferramentas se estiver trabalhando com tarefas de NLP bem estabelecidas, como reconhecimento básico de entidades nomeadas para categorias comuns, precisar de um processamento super rápido de padrões simples ou tiver requisitos rígidos para evitar chamadas de API externas. Bibliotecas tradicionais como spaCy são ótimas em tarefas padrão de NLP com processamento de alto volume, enquanto o LangExtract se destaca quando você precisa de uma extração inteligente e personalizada com o mínimo de complexidade de configuração.
Antes de começar a extrair dados, você precisa instalar o LangExtract e configurar o acesso aos modelos de IA. A biblioteca suporta vários métodos de instalação e funciona com diferentes fornecedores de IA.
Instale o LangExtract usando o pip ou o uv. Para integração com o OpenAI, use o pacote extras:
# Using pip
pip install langextract[openai]
# Using uv
uv add langextract[openai]O extra [openai] inclui o cliente Python OpenAI. Para outros provedores, você pode instalar o pacote básico e adicionar bibliotecas específicas do provedor, conforme necessário.
O LangExtract trabalha com vários fornecedores de IA. Configure as chaves API como variáveis de ambiente:
# OpenAI (get your key from https://platform.openai.com/api-keys)
export OPENAI_API_KEY="your-openai-key-here"
# Anthropic (get your key from https://console.anthropic.com/settings/keys)
export ANTHROPIC_API_KEY="your-anthropic-key-here"
# Google AI (get your key from https://aistudio.google.com/app/apikey)
export GOOGLE_API_KEY="your-google-key-here"Você só precisa das chaves dos provedores que pretende usar. Para modelos locais através do Ollama, não são necessárias chaves API — basta instalar e executar o Ollama na sua máquina.
Confira sua configuração com um teste simples:
import langextract as lx
import textwrap
# 1. Define the prompt and extraction rules
prompt = textwrap.dedent(
"""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context."""
)
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
],
)
]
# The input text to be processed
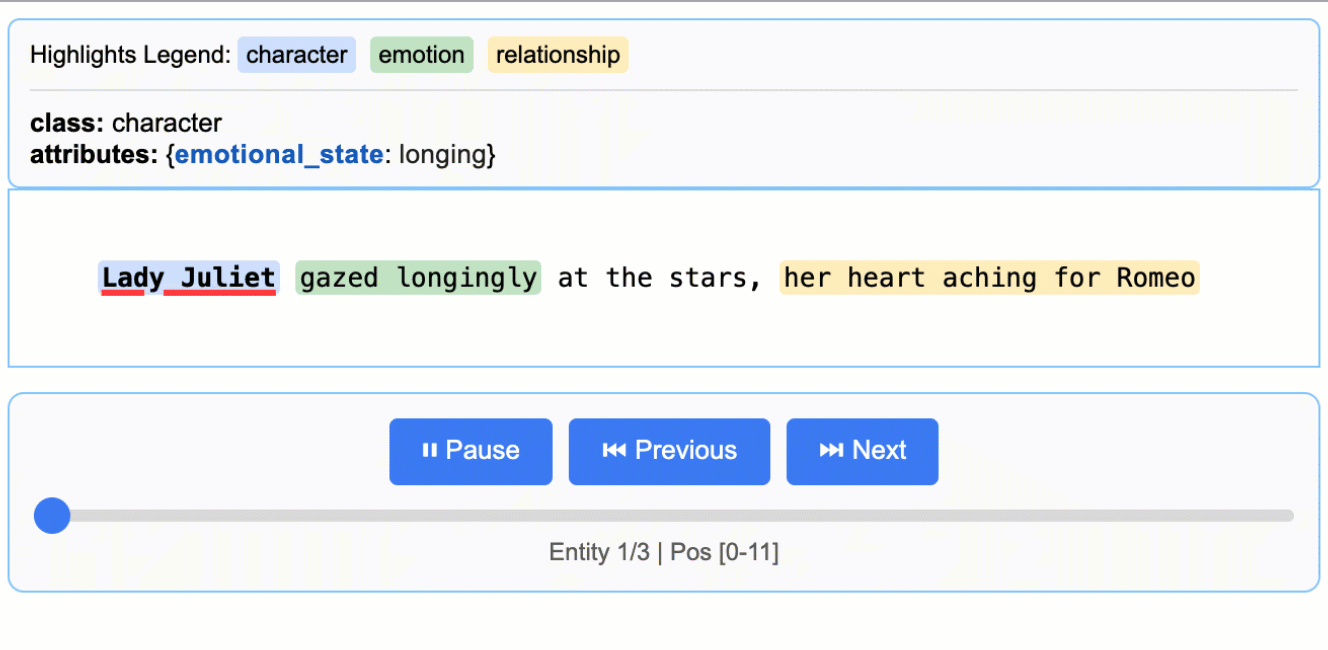
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# Run the extraction
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini",
)
print("Extraction successful!")O Reconhecimento de Entidades Nomeadas (NER) encontra e classifica informações específicas em um texto, tipo achar todos os nomes de empresas, pessoas e lugares mencionados em um relatório de negócios.
As ferramentas tradicionais de NER funcionam com categorias pré-definidas, como “PESSOA” ou “ORGANIZAÇÃO”, mas muitas vezes deixam passar entidades específicas do contexto que são importantes para o seu negócio. O LangExtract permite que você defina tipos de entidades personalizadas e ensine a IA a reconhecer padrões específicos do seu domínio.
Vamos ver como extrair entidades de e-mails de suporte ao cliente. Em vez de categorias genéricas, vamos identificar entidades específicas de suporte, como tipos de reclamações, nomes de produtos e prazos de resolução, que ajudam a priorizar os tickets.
O primeiro passo é descrever o que você quer extrair usando uma instrução clara. Essa solicitação funciona como instruções para um analista humano — quanto mais específico você for, melhores serão os resultados:
import langextract as lx
import textwrap
# Define what we want to extract from support emails
prompt = textwrap.dedent("""
Extract customer support entities from email text.
Focus on actionable information that helps prioritize and route tickets.
Use exact text from the email - don't paraphrase or summarize.
Include helpful attributes that add context for support agents.
""")A função ` textwrap.dedent() ` tira as indentações extras das strings com várias linhas, deixando suas instruções mais fáceis de ler no código e mantendo-as organizadas quando enviadas para a IA. Sem isso, a IA veria todos os espaços extras da indentação do seu código.
Esse prompt diz à IA para procurar informações específicas de suporte, usar citações exatas do texto e adicionar contexto por meio de atributos. O segredo é ser específico sobre o seu domínio (suporte ao cliente) e o que torna as informações úteis (ajuda a priorizar e encaminhar tickets).
Os exemplos ensinam à IA exatamente o que você quer e como formatar os resultados. Cada exemplo mostra à IA um trecho de texto e as entidades exatas que você quer extrair dele:
# Create examples that show the AI what to extract
examples = [
lx.data.ExampleData(
text="My laptop screen keeps flickering. I bought it 3 months ago and need this fixed urgently for my presentation tomorrow.",
extractions=[
lx.data.Extraction(
extraction_class="product",
extraction_text="laptop",
attributes={"issue": "screen flickering", "urgency": "high"}
),
lx.data.Extraction(
extraction_class="timeline",
extraction_text="3 months ago",
attributes={"context": "purchase_date"}
),
lx.data.Extraction(
extraction_class="urgency_indicator",
extraction_text="urgently for my presentation tomorrow",
attributes={"priority": "high", "deadline": "tomorrow"}
)
]
)
]Cada objeto ` ExampleData ` tem uma amostra de texto e uma lista de objetos ` Extraction `. Os objetos ` Extraction ` especificam três coisas:
extraction_class: O tipo de entidade (como “produto” ou “linha do tempo”)extraction_text: As palavras exatas do texto originalattributes: Informações adicionais que ajudam a entender melhor a entidadeOs atributos são o que diferenciam o LangExtract do NER tradicional. Em vez de só achar “laptop”, a gente pode ver que ele tem um problema de “tela piscando” e marcar isso como urgência alta.
Agora você pode fazer a extração em um novo texto usando seu prompt e exemplos. O LangExtract vai usar o que aprendeu para encontrar coisas parecidas:
# Sample support email to analyze
support_email = """
Subject: WiFi adapter not working after Windows update
Hi support team,
My USB WiFi adapter stopped working completely after yesterday's Windows update.
I've tried restarting my computer multiple times but no luck. This is blocking me
from working from home today. I have an important client call at 2 PM and really
need internet access. The adapter worked perfectly before the update.
Thanks,
Mike Chen
"""
# Run the extraction
result = lx.extract(
text_or_documents=support_email,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini"
)
print("Extraction completed successfully!")Resultado:
INFO:absl:Finalizing annotation for document ID doc_435b1cd5.
INFO:absl:Document annotation completed.
✓ Extracted 4 entities (3 unique types)
• Time: 3.34s
• Speed: 123 chars/sec
• Chunks: 1
Extraction completed successfully!A função “ lx.extract() ” pega seu texto, aplica as instruções do prompt e usa os exemplos para guiar a extração. Ele devolve um objeto de resultado com todas as entidades encontradas, junto com suas localizações exatas no texto original.
Você pode experimentar diferentes modelos alterando o parâmetro model_id. Modelos como "claude-3-haiku" ou "gpt-4o" podem dar resultados diferentes dependendo da complexidade do seu texto e dos seus requisitos.
Quando a extração terminar, o LangExtract vai devolver um objeto de resultado com todas as entidades encontradas, com suas localizações e atributos exatos. O verdadeiro poder vem de como você pode acessar, analisar e compartilhar esses dados estruturados.
O objeto resultado guarda todas as entidades encontradas na propriedade ` extractions `. Cada extração tem o texto da entidade, o tipo dela, a localização no documento original e quaisquer atributos:
# Look at all extracted entities
for extraction in result.extractions:
print(f"Type: {extraction.extraction_class}")
print(f"Text: '{extraction.extraction_text}'")
print(f"Location: chars {extraction.char_interval.start_pos}-{extraction.char_interval.end_pos}")
print(f"Attributes: {extraction.attributes}")
print("---")Resultado:
Type: product
Text: 'USB WiFi adapter'
Location: chars 78-94
Attributes: {'issue': 'not working after Windows update', 'previous_status': 'worked perfectly before the update'}
---
Type: timeline
Text: 'yesterday'
Location: chars 128-137
Attributes: {'context': 'Windows update'}
---
Type: urgency_indicator
Text: 'blocking me from working from home today'
Location: chars 227-268
Attributes: {'priority': 'high', 'context': 'work from home'}
---
Type: urgency_indicator
Text: 'important client call at 2 PM'
Location: chars 280-309
Attributes: {'priority': 'high', 'deadline': '2 PM today'}
---Cada objeto de extração rastreia exatamente de onde veio a informação usando char_interval, que mostra as posições inicial e final no texto original. Esse rastreamento de origem permite que você verifique os resultados e entenda o contexto.
Você pode agrupar e contar entidades para entender os padrões nos seus dados:
from collections import Counter
# Count different entity types
entity_types = Counter(e.extraction_class for e in result.extractions)
print("Entity breakdown:")
for entity_type, count in entity_types.items():
percentage = (count / len(result.extractions)) * 100
print(f" {entity_type}: {count} entities ({percentage:.1f}%)")
# Find high-priority support tickets
urgent_entities = [
e for e in result.extractions
if e.extraction_class == "urgency_indicator"
and e.attributes.get("priority") == "high"
]
print(f"\nFound {len(urgent_entities)} high-priority indicators")Resultado:
Entity breakdown:
product: 1 entities (25.0%)
timeline: 1 entities (25.0%)
urgency_indicator: 2 entities (50.0%)
Found 2 high-priority indicatorsEssa análise ajuda você a identificar rapidamente padrões, como quais tipos de produtos geram mais tickets de suporte ou quantas solicitações urgentes você está recebendo.
O LangExtract salva os resultados no formato JSONL (JSON Lines), onde cada linha tem os dados extraídos de um documento. Esse formato funciona bem com ferramentas de processamento de dados e facilita a combinação de resultados de várias extrações:
# Save results to a JSONL file
lx.io.save_annotated_documents(
[result],
output_name="support_ticket_extractions.jsonl",
output_dir="."
)O JSONL guarda cada documento numa linha separada como um objeto JSON completo. Diferente dos arquivos JSON normais, que têm um único array grande, os arquivos JSONL podem ser processados linha por linha, o que os torna perfeitos para conjuntos de dados grandes. Você pode abrir esses arquivos em qualquer editor de texto ou carregá-los em ferramentas de análise de dados, como o pandas.
A visualização HTML é onde o LangExtract realmente se destaca. Ele cria um relatório interativo que destaca as entidades extraídas do texto original e permite que você clique nos resultados:
# Generate interactive HTML visualization
html_content = lx.visualize("support_ticket_extractions.jsonl")
# Save the HTML file
with open("support_analysis.html", "w") as f:
if hasattr(html_content, "data"):
f.write(html_content.data) # For Jupyter notebooks
else:
f.write(html_content) # For regular Python scripts
print("HTML visualization saved as 'support_analysis.html'")Resultado:
HTML visualization saved as 'support_analysis.html'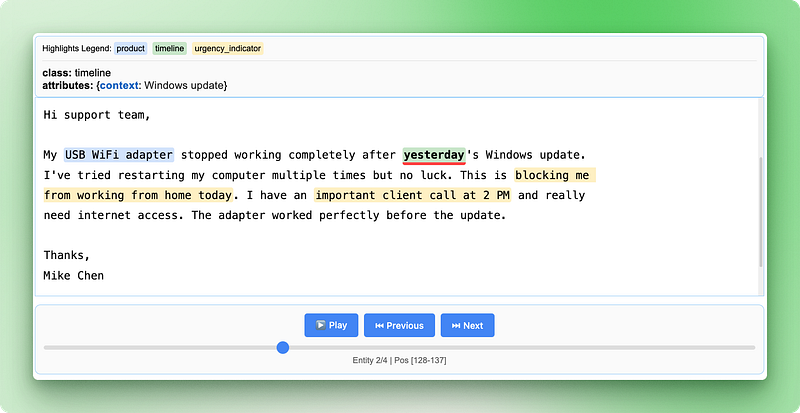
A visualização HTML mostra o seu texto original com destaques codificados por cores para cada tipo de entidade. Você pode clicar no texto destacado para ver os atributos extraídos, navegar entre diferentes entidades usando os controles e verificar se a IA identificou corretamente as informações importantes. Isso facilita a verificação pontual dos resultados e aumenta a confiança no seu pipeline de extração.
A visualização inclui uma legenda mostrando cada tipo de entidade, controles de navegação para se mover entre as entidades e informações detalhadas sobre os atributos de cada extração. Essa abordagem interativa facilita muito a compreensão e a validação dos seus resultados em comparação com a análise de dados JSON brutos.
As entidades de suporte ao cliente que extraímos funcionam bem individualmente, mas não contam a história completa. Quando um cliente diz “meu MacBook Pro de 2021 tá com problemas de bateria”, você precisa entender que o produto, o ano do modelo e o problema fazem parte de um único caso de suporte. Encontrar essas peças separadamente não ajuda — você precisa das relações entre elas.
A PNL tradicional não lida muito bem com isso porque trata cada entidade como informação isolada. Você pode extrair “MacBook Pro”, “2021” e “problemas com a bateria” como coisas separadas, mas aí vai precisar de regras complicadas pra descobrir quais detalhes vão com quais produtos. Essa abordagem não funciona muito bem quando se lida com vários produtos ou clientes no mesmo texto.
O LangExtract resolve isso extraindo as relações durante a passagem inicial, em vez de tentar conectar as entidades posteriormente. Você pode juntar informações relacionadas usando atributos em comum, sem deixar de acompanhar exatamente de onde cada parte veio no texto original. Vamos trabalhar na extração de informações dos funcionários a partir de documentos de RH, onde precisamos conectar as pessoas com suas funções, departamentos e detalhes de contato.
Neste exemplo, vamos pegar as informações dos funcionários dos comunicados da empresa, onde vários detalhes sobre cada pessoa precisam ser conectados:
import langextract as lx
import textwrap
# Define relationship extraction prompt
prompt = textwrap.dedent("""
Extract employee information from company announcements.
Group related details about each person using employee_group attributes.
Connect names, titles, departments, and contact info for each employee.
Use exact text from the announcement - don't paraphrase.
""")
# Create examples showing how to group related information
examples = [
lx.data.ExampleData(
text="Sarah Johnson, our new Marketing Director, will lead the digital campaigns team. You can reach Sarah at sarah.j@company.com for any marketing questions.",
extractions=[
lx.data.Extraction(
extraction_class="person",
extraction_text="Sarah Johnson",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="job_title",
extraction_text="Marketing Director",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="department",
extraction_text="digital campaigns team",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="contact",
extraction_text="sarah.j@company.com",
attributes={"employee_group": "Sarah Johnson", "type": "email"}
)
]
)
]O atributo employee_group funciona como um sistema de ligação — todas as entidades com o mesmo valor employee_group pertencem à mesma pessoa. Isso permite extrair informações complexas e com várias partes, mantendo o controle dos detalhes que estão relacionados.
Agora vamos extrair de um anúncio da empresa com vários funcionários:
# Sample HR announcement with multiple employees
hr_announcement = """
We're excited to announce two new hires joining our team this month.
Mike Chen joins us as Senior Software Engineer in our Backend Development group. Mike brings 8 years of Python experience and will focus on API architecture. Please welcome Mike - he'll be working from our Seattle office and you can reach him at m.chen@company.com.
Additionally, Lisa Rodriguez starts as Product Manager for our Mobile Apps division. Lisa previously worked at TechStart Inc and has extensive experience with user research. Her office phone is 555-0199 and email is lisa.r@company.com.
"""
# Extract relationships
result = lx.extract(
text_or_documents=hr_announcement,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini"
)
print(f"Extracted {len(result.extractions)} entities")Resultado:
✓ Extraction processing complete
INFO:absl:Finalizing annotation for document ID doc_a349ae1d.
INFO:absl:Document annotation completed.
✓ Extracted 10 entities (4 unique types)
• Time: 8.57s
• Speed: 67 chars/sec
• Chunks: 1
Extracted 10 entitiesDepois de extrair, você pode juntar as entidades relacionadas para ver as informações completas de cada funcionário. Isso precisa de um código Python pra organizar as entidades espalhadas de novo em grupos lógicos:
from collections import defaultdict
# Group entities by employee_group
employee_groups = defaultdict(list)
for extraction in result.extractions:
group_id = extraction.attributes.get("employee_group")
if group_id:
employee_groups[group_id].append(extraction)
# Print organized employee information
for employee, details in employee_groups.items():
print(f"\n=== {employee} ===")
for detail in details:
print(f"{detail.extraction_class}: {detail.extraction_text}")
if detail.attributes.get("type"):
print(f" Type: {detail.attributes['type']}")Resultado:
=== Mike Chen ===
person: Mike Chen
job_title: Senior Software Engineer
department: Backend Development group
contact: m.chen@company.com
Type: email
contact: Seattle office
Type: location
=== Lisa Rodriguez ===
person: Lisa Rodriguez
job_title: Product Manager
department: Mobile Apps division
contact: lisa.r@company.com
Type: email
contact: 555-0199
Type: phoneAqui está o que esse código faz passo a passo:
defaultdict(list) Cria um dicionário onde cada nova entrada começa automaticamente como uma lista vazia.extraction.attributes.get("employee_group") obtém com segurança o ID do grupo a partir dos atributos de cada entidade, retornando None se ele não existir.employee_groups[group_id].append(extraction) adiciona cada entidade à lista do seu grupoO defaultdict é uma coleção Python que cria automaticamente entradas que estão faltando. Quando você entra pela primeira vez em employee_groups["Mike Chen"], ele automaticamente cria uma lista vazia para esse funcionário. Isso evita que você precise verificar se cada funcionário já está no dicionário.
Essa abordagem de agrupamento permite reconstruir perfis completos de funcionários a partir das informações espalhadas no texto original, mantendo as localizações exatas de cada dado.
A visualização HTML fica ainda mais valiosa com dados de relacionamento, pois mostra tanto entidades individuais quanto suas conexões:
# Save the relationship extraction results
lx.io.save_annotated_documents(
[result],
output_name="employee_relationships.jsonl",
output_dir="."
)
# Generate HTML visualization showing relationships
html_content = lx.visualize("employee_relationships.jsonl")
with open("employee_relationships.html", "w") as f:
if hasattr(html_content, "data"):
f.write(html_content.data)
else:
f.write(html_content)
print("Relationship visualization saved as 'employee_relationships.html'")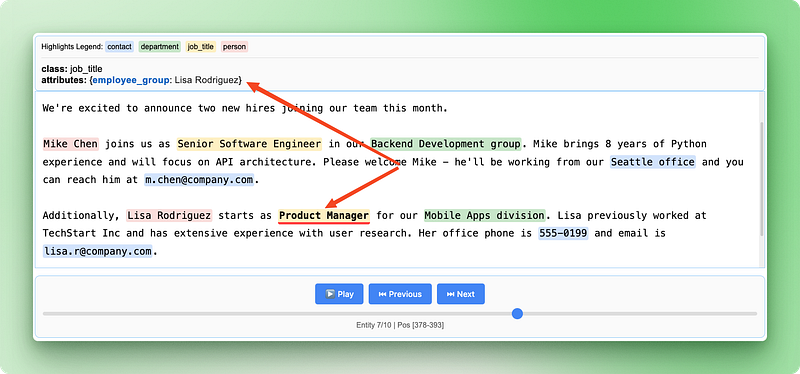
A visualização das relações mostra como diferentes informações se conectam para formar registros completos dos funcionários, facilitando a verificação de que a IA identificou e agrupou corretamente os detalhes relacionados do anúncio original.
O LangExtract trabalha com vários fornecedores de modelos de IA, cada um oferecendo diferentes combinações entre custo, velocidade e precisão. Os modelos Gemini do Google funcionam direto com suporte integrado a esquemas, o que os torna a opção mais fácil para a maioria das tarefas de extração. Os modelos GPT ( ) da OpenAI costumam oferecer maior precisão, mas exigem configuração adicional e têm um custo mais elevado por extração.
# Using Google Gemini (default and recommended)
result_gemini = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash" # Fast and cost-effective
)
# Using OpenAI GPT models
result_openai = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini",
fence_output=True, # Required for OpenAI
use_schema_constraints=False # OpenAI doesn't support constraints
)Para processamento local ou quando você quiser evitar custos de API, você pode executar modelos localmente usando o Ollama. Os modelos locais funcionam bem para tarefas de extração mais simples e oferecem controle total sobre seus dados, embora normalmente sejam mais lentos e possam ser menos precisos do que as opções baseadas em nuvem.
# Using local models with Ollama (requires Ollama installed)
result_local = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gemma2:2b", # Local Gemma model
model_url="http://localhost:11434", # Ollama server
fence_output=False, # Local models don't need fencing
use_schema_constraints=False # Disable constraints
)O texto do mundo real não se parece em nada com os nossos exemplos simples. Você recebe relatórios de 50 páginas com formatação confusa, e-mails de clientes cheios de erros de digitação e PDFs com espaçamento estranho. Alguns documentos têm milhares de palavras espalhadas por diferentes seções, e as informações importantes podem estar escondidas em qualquer lugar.
O LangExtract lida com essas situações complicadas usando três ferramentas principais: executando vários documentos ao mesmo tempo, tentando a extração várias vezes e dividindo documentos grandes em partes menores. Em vez de processar um documento de cada vez, você pode trabalhar em vários documentos ao mesmo tempo, o que torna tudo muito mais rápido.
# Settings for processing lots of real documents
result = lx.extract(
text_or_documents=document_batch,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
max_workers=20, # Work on many documents at once
extraction_passes=3, # Try extraction 3 times
max_char_buffer=1000 # Break big text into small pieces
)A configuração “ max_workers ” controla quantos documentos são processados ao mesmo tempo. Mais trabalhadores significa resultados mais rápidos, mas também custa mais dinheiro e pode atingir os limites da API. Comece com 10 a 20 funcionários e veja como corre.
Várias passagens de extração ajudam a encontrar informações que podem ter sido perdidas na primeira vez. O LangExtract faz a extração várias vezes e junta os resultados. Isso capta mais detalhes, mas leva mais tempo e custa mais caro.
Dividir os documentos em partes ajuda com textos longos. A configuração “ max_char_buffer ” divide documentos grandes em partes menores que funcionam melhor com modelos de IA. Pequenos trechos (1000-2000 caracteres) capturam mais detalhes, enquanto trechos grandes (3000-5000 caracteres) mantêm mais contexto, mas podem deixar passar algumas coisas.
# Different settings for different types of documents
# For important documents that need careful review
detailed_result = lx.extract(
text_or_documents=legal_documents,
extraction_passes=5, # Try 5 times for accuracy
max_char_buffer=800, # Small chunks for detail
max_workers=10 # Fewer workers to avoid limits
)
# For quick processing of simple documents
quick_result = lx.extract(
text_or_documents=email_batch,
extraction_passes=1, # Single pass for speed
max_char_buffer=3000, # Bigger chunks for speed
max_workers=30 # More workers for faster results
)Trabalhar na produção significa lidar com problemas. Os documentos podem ter erros de codificação, as conexões de rede podem falhar e as APIs podem limitar a velocidade de processamento. Fique de olho nos seus trabalhos de extração, adicione uma lógica de repetição para documentos com falha e programe quanto você está gastando com diferentes provedores de IA.
Quando estiver trabalhando com diferentes tipos de documentos, defina regras de extração diferentes para cada tipo. Os contratos legais precisam de avisos diferentes dos e-mails dos clientes. Os relatórios financeiros precisam de tamanhos de blocos diferentes dos posts nas redes sociais. Crie pipelines separados para cada tipo de documento, em vez de tentar fazer com que um único sistema lide com tudo.
O LangExtract tem uma abordagem diferente das bibliotecas tradicionais de NLP. Enquanto a maioria das bibliotecas usa modelos pré-treinados ou sistemas baseados em regras, o LangExtract usa Modelos de Linguagem Grandes que conseguem entender o contexto e o significado como os humanos. Vamos comparar com três bibliotecas populares de PNL em Python pra entender quando você escolheria o LangExtract em vez de outras opções.
O spaCy foca em velocidade e tarefas de NLP prontas para produção, como tokenização, marcação de partes do discurso e reconhecimento de entidades nomeadas. Ele vem com modelos pré-treinados que reconhecem entidades comuns, como pessoas, organizações e locais, mas tem dificuldade com entidades específicas de domínios ou categorias personalizadas. O spaCy é ótimo para processar grandes quantidades de texto rapidamente, mas você precisa treinar novamente os modelos ou escrever regras complexas para extrair informações personalizadas.
O LangExtract elimina essa complexidade, permitindo que você defina entidades personalizadas por meio de exemplos e prompts simples, além de fornecer localizações exatas da fonte que o spaCy não programa.
NLTK (Natural Language Toolkit) foi criado para educação e pesquisa, oferecendo uma ampla variedade de algoritmos e conjuntos de dados de PLN. Ele fornece os blocos de construção para o processamento de texto, mas requer um conhecimento significativo de programação para criar soluções completas. O NLTK é ótimo pra aprender conceitos de NLP e fazer protótipos, mas pra montar sistemas de extração prontos pra produção, é preciso juntar vários componentes do NLTK e escrever bastante código.
O LangExtract oferece uma solução completa pronta para usar — você define o que deseja por meio de exemplos, em vez de algoritmos de codificação, e obtém visualizações interativas sem trabalho de desenvolvimento adicional.
Transformadores (Hugging Face) dá acesso a modelos transformadores de última geração para várias tarefas de PLN, incluindo reconhecimento de entidades nomeadas e resposta a perguntas. Embora seja poderoso, ele precisa de experiência em machine learning para ajustar os modelos para áreas específicas e não oferece rastreamento de fonte ou extração de relacionamentos integrados. Você precisa cuidar da implantação do modelo, gerenciar diferentes formatos de modelo e criar suas próprias ferramentas de visualização.
O LangExtract simplifica a complexidade de trabalhar com diferentes modelos de IA, lida com o rastreamento de fontes automaticamente e faz a extração de relações por meio de agrupamentos simples de atributos, em vez de arquiteturas de modelos complicadas.
|
Recurso |
LangExtract |
spaCy |
NLTK |
Transformadores |
|
Complexidade da configuração |
Sugestões simples + exemplos |
Treinamento/regras do modelo |
Codificação de algoritmos |
Ajustes finos do modelo |
|
Entidades personalizadas |
Definição em linguagem natural |
É preciso fazer um novo treinamento |
Criação manual de regras |
Ajustes finos do modelo |
|
Rastreamento da fonte |
Automático com posições exatas |
Não disponível |
Implementação manual |
Implementação manual |
|
Extração de relacionamentos |
Agrupamento integrado |
Criação de regras complexas |
Codificação manual |
Desenvolvimento de modelos personalizados |
|
Compreensão do contexto |
Com tecnologia LLM |
Baseado em padrões |
Baseado em regras |
Dependente do modelo |
|
Visualização |
HTML interativo |
Ferramentas externas necessárias |
Ferramentas externas necessárias |
Ferramentas externas necessárias |
|
Curva de aprendizagem |
Baixo (baseado em exemplos) |
Médio (conhecimento em PNL) |
Alto (algoritmos) |
Alto (especialização em ML) |
|
Ideal para |
Extração específica do domínio |
Pipelines gerais de PNL |
Pesquisa/aprendizagem |
Aplicativos de IA personalizados |
O LangExtract muda a extração de texto de escrever regras complicadas para conversar com a IA sobre seus dados. Você aprendeu a configurar a extração de entidades personalizadas usando prompts e exemplos simples, agrupar informações relacionadas por meio da extração de relacionamentos e criar visualizações interativas que mostram exatamente de onde cada dado veio. A biblioteca lida com desafios de produção, como processamento paralelo e fragmentação de documentos, tornando-a prática para aplicações do mundo real com textos confusos e inconsistentes.
Seja pra lidar com tickets de suporte ao cliente, analisar documentos jurídicos ou extrair insights de artigos de pesquisa, o LangExtract oferece uma abordagem mais intuitiva do que as bibliotecas tradicionais de NLP. Em vez de gastar tempo com treinamento de modelos ou criação de regras, você pode se concentrar em definir quais informações são importantes para o seu caso específico. Comece com extrações simples em seus próprios dados de texto e, em seguida, amplie usando as técnicas de produção abordadas neste tutorial.
Aprenda IA com esses cursos!
Curso
Curso
Curso
blog
Matt Crabtree
11 min
Tutorial
Josep Ferrer
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Moez Ali

