
Cours
Systèmes multi‑agents avec LangGraph
2 h 45 min
6.5K
L'extraction de données structurées à partir de documents textuels pose des problèmes importants aux équipes chargées des données. Les expressions régulières ne fonctionnent plus lorsque les formats changent, le code d'analyse personnalisé ne tient pas compte du contexte que les humains perçoivent facilement, et ces solutions nécessitent des corrections constantes à mesure que vos sources de données évoluent.
LangExtract résout ce problème en utilisant des modèles d'IA capables de lire des textes comme le ferait un être humain et de suivre avec précision l'origine des informations. Vous lui indiquez les données que vous souhaitez obtenir en termes simples, à l'aide de quelques exemples, et il se charge de la tâche complexe consistant à comprendre et à extraire ces informations.
Dans ce tutoriel, je vais vous expliquer étape par étape comment configurer LangExtract pour la reconnaissance d'entités nommées, extraire les relations entre les entités, travailler avec différents fournisseurs de modèles d'IA et comparer l'approche de LangExtract à celle des bibliothèques NLP traditionnelles. Vous apprendrez également à définir des tâches d'extraction, à fournir des exemples de formation et à traiter les résultats structurés pour vos workflows d'analyse.
LangExtract est une bibliothèque Python qui transforme du texte désorganisé en données structurées à l'aide de modèles d'intelligence artificielle. Les anciens outils de traitement de texte sont susceptibles d'être induits en erreur par le contexte : ils peuvent interpréter « Apple » comme le nom d'un fruit alors que vous faites référence à l'entreprise technologique, ou considérer « 500 $ » comme un prix alors qu'il s'agit en réalité d'un numéro d'identification d'employé. La correspondance de motifs de base permet de détecter les adresses électroniques, mais elle ne permet pas de déterminer si « john.doe@company.com » est un employé actuel ou simplement une personne mentionnée dans un ancien courriel.
Pour résoudre ces problèmes de contexte et de précision, LangExtract vous propose :
Source : GitHub
Ces outils fonctionnent ensemble pour modifier la manière dont vous extrayez des informations à partir d'un texte. Au lieu de rédiger des règles complexes qui peuvent facilement être enfreintes, vous indiquez à l'IA ce que vous souhaitez à l'aide d'exemples simples. L'IA lit le texte comme le ferait un être humain et garde une trace de l'origine de chaque élément. Cela vous permet d'extraire des informations et des relations complexes qui nécessiteraient auparavant des centaines de lignes de code pour être identifiées.
LangExtract est particulièrement efficace lorsque vous avez besoin d'extraire des informations personnalisées que les outils traditionnels de traitement du langage naturel ne peuvent pas traiter correctement. Si vous travaillez avec des textes spécifiques à un domaine où la reconnaissance standard des entités nommées s'avère insuffisante, LangExtract vous permet de définir précisément ce qui est important pour votre entreprise sans avoir à rédiger de règles complexes ni à réentraîner des modèles. Cela est particulièrement utile lorsque vous avez besoin de comprendre le contexte et les relations entre différentes informations, et pas seulement de trouver des entités individuelles.
LangExtract est un choix judicieux lorsque vous rencontrez les situations suivantes :
Il est recommandé d'envisager d'autres outils si vous travaillez avec des tâches NLP bien établies telles que la reconnaissance d'entités nommées de base pour des catégories courantes, si vous avez besoin d'un traitement extrêmement rapide de modèles simples ou si vous avez des exigences strictes pour éviter les appels API externes. Les bibliothèques traditionnelles telles que spaCy excelle dans les tâches NLP standard avec un traitement à haut volume, tandis que LangExtract est particulièrement efficace lorsque vous avez besoin d'une extraction intelligente et personnalisée avec une configuration minimale.
Avant de pouvoir commencer à extraire des données, il est nécessaire d'installer LangExtract et de configurer l'accès aux modèles d'IA. La bibliothèque prend en charge plusieurs méthodes d'installation et fonctionne avec différents fournisseurs d'IA.
Veuillez installer LangExtract à l'aide de pip ou uv. Pour OpenAI, veuillez utiliser le package extras :
# Using pip
pip install langextract[openai]
# Using uv
uv add langextract[openai]L'extension [openai] comprend le client Python OpenAI. Pour les autres fournisseurs, vous pouvez installer le package de base et ajouter les bibliothèques spécifiques au fournisseur selon vos besoins.
LangExtract collabore avec plusieurs fournisseurs d'intelligence artificielle. Configurez les clés API en tant que variables d'environnement :
# OpenAI (get your key from https://platform.openai.com/api-keys)
export OPENAI_API_KEY="your-openai-key-here"
# Anthropic (get your key from https://console.anthropic.com/settings/keys)
export ANTHROPIC_API_KEY="your-anthropic-key-here"
# Google AI (get your key from https://aistudio.google.com/app/apikey)
export GOOGLE_API_KEY="your-google-key-here"Vous n'avez besoin que des clés des fournisseurs que vous prévoyez d'utiliser. Pour les modèles locaux via Ollama, aucune clé API n'est requise. Il suffit d'installer et d'exécuter Ollama sur votre ordinateur.
Veuillez vérifier votre configuration à l'aide d'un test simple :
import langextract as lx
import textwrap
# 1. Define the prompt and extraction rules
prompt = textwrap.dedent(
"""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context."""
)
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
],
)
]
# The input text to be processed
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# Run the extraction
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini",
)
print("Extraction successful!")La reconnaissance d'entités nommées (NER) identifie et classe des informations spécifiques dans un texte, par exemple en recherchant tous les noms d'entreprises, de personnes et de lieux mentionnés dans un rapport commercial.
Les outils NER traditionnels fonctionnent avec des catégories prédéfinies telles que « PERSONNE » ou « ORGANISATION », mais omettent souvent des entités spécifiques au contexte qui sont importantes pour votre entreprise. LangExtract vous permet de définir des types d'entités personnalisés et d'enseigner à l'IA à reconnaître des modèles spécifiques à votre domaine.
Examinons comment extraire des entités à partir d'e-mails du service client. Au lieu de catégories génériques, nous identifierons des entités spécifiques à l'assistance telles que les types de réclamations, les noms de produits et les délais de résolution qui permettent de hiérarchiser les tickets.
La première étape consiste à décrire clairement ce que vous souhaitez extraire à l'aide d'une invite claire. Cette invite fonctionne comme des instructions destinées à un analyste humain : plus vous êtes précis, meilleurs seront les résultats obtenus :
import langextract as lx
import textwrap
# Define what we want to extract from support emails
prompt = textwrap.dedent("""
Extract customer support entities from email text.
Focus on actionable information that helps prioritize and route tickets.
Use exact text from the email - don't paraphrase or summarize.
Include helpful attributes that add context for support agents.
""")La fonction « textwrap.dedent() » supprime les indentations supplémentaires des chaînes de caractères multilignes, ce qui rend vos invites plus lisibles dans le code tout en les conservant propres lorsqu'elles sont envoyées à l'IA. Sans cela, l'IA détecterait tous les espaces supplémentaires provenant de l'indentation de votre code.
Cette invite demande à l'IA de rechercher des informations spécifiques à l'assistance, d'utiliser des citations exactes tirées du texte et d'ajouter du contexte à l'aide d'attributs. Il est essentiel d'être précis concernant votre domaine (service client) et ce qui rend les informations utiles (aide à hiérarchiser et à acheminer les tickets).
Les exemples enseignent à l'IA exactement ce que vous souhaitez et comment formater les résultats. Chaque exemple présente à l'IA un extrait de texte et les entités précises que vous souhaitez extraire de celui-ci :
# Create examples that show the AI what to extract
examples = [
lx.data.ExampleData(
text="My laptop screen keeps flickering. I bought it 3 months ago and need this fixed urgently for my presentation tomorrow.",
extractions=[
lx.data.Extraction(
extraction_class="product",
extraction_text="laptop",
attributes={"issue": "screen flickering", "urgency": "high"}
),
lx.data.Extraction(
extraction_class="timeline",
extraction_text="3 months ago",
attributes={"context": "purchase_date"}
),
lx.data.Extraction(
extraction_class="urgency_indicator",
extraction_text="urgently for my presentation tomorrow",
attributes={"priority": "high", "deadline": "tomorrow"}
)
]
)
]Chaque objet ExampleData contient un échantillon de texte et une liste d'objets Extraction. Les objets Extraction spécifient trois éléments :
extraction_class: Le type d'entité (tel que « produit » ou « chronologie »)extraction_text: Les mots exacts du texte originalattributes: Informations supplémentaires permettant de mieux comprendre l'entitéLes attributs sont ce qui distingue LangExtract du NER traditionnel. Au lieu de simplement rechercher « ordinateur portable », nous pouvons identifier qu'il présente un problème de « scintillement de l'écran » et le marquer comme hautement urgent.
Vous pouvez désormais exécuter l'extraction sur un nouveau texte en utilisant votre invite et vos exemples. LangExtract appliquera ce qu'il a appris pour trouver des entités similaires :
# Sample support email to analyze
support_email = """
Subject: WiFi adapter not working after Windows update
Hi support team,
My USB WiFi adapter stopped working completely after yesterday's Windows update.
I've tried restarting my computer multiple times but no luck. This is blocking me
from working from home today. I have an important client call at 2 PM and really
need internet access. The adapter worked perfectly before the update.
Thanks,
Mike Chen
"""
# Run the extraction
result = lx.extract(
text_or_documents=support_email,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini"
)
print("Extraction completed successfully!")Résultat :
INFO:absl:Finalizing annotation for document ID doc_435b1cd5.
INFO:absl:Document annotation completed.
✓ Extracted 4 entities (3 unique types)
• Time: 3.34s
• Speed: 123 chars/sec
• Chunks: 1
Extraction completed successfully!La fonction « lx.extract() » (Extraction de texte) prend votre texte, applique les instructions de l'invite et utilise les exemples pour guider l'extraction. Il renvoie un objet résultat contenant toutes les entités trouvées, ainsi que leur emplacement exact dans le texte original.
Vous pouvez tester différents modèles en modifiant le paramètre model_id. Des modèles tels que "claude-3-haiku" ou "gpt-4o" peuvent fournir des résultats différents en fonction de la complexité de votre texte et de vos exigences.
Une fois l'extraction terminée, LangExtract renvoie un objet résultat contenant toutes les entités trouvées avec leur emplacement exact et leurs attributs. La véritable puissance réside dans la manière dont vous pouvez accéder à ces données structurées, les analyser et les partager.
L'objet résultat stocke toutes les entités trouvées dans la propriété extractions. Chaque extraction contient le texte de l'entité, son type, son emplacement dans le document original et tous ses attributs :
# Look at all extracted entities
for extraction in result.extractions:
print(f"Type: {extraction.extraction_class}")
print(f"Text: '{extraction.extraction_text}'")
print(f"Location: chars {extraction.char_interval.start_pos}-{extraction.char_interval.end_pos}")
print(f"Attributes: {extraction.attributes}")
print("---")Résultat :
Type: product
Text: 'USB WiFi adapter'
Location: chars 78-94
Attributes: {'issue': 'not working after Windows update', 'previous_status': 'worked perfectly before the update'}
---
Type: timeline
Text: 'yesterday'
Location: chars 128-137
Attributes: {'context': 'Windows update'}
---
Type: urgency_indicator
Text: 'blocking me from working from home today'
Location: chars 227-268
Attributes: {'priority': 'high', 'context': 'work from home'}
---
Type: urgency_indicator
Text: 'important client call at 2 PM'
Location: chars 280-309
Attributes: {'priority': 'high', 'deadline': '2 PM today'}
---Chaque objet d'extraction suit précisément l'origine des informations à l'aide d'char_interval, qui indique les positions de début et de fin dans le texte original. Ce suivi des sources vous permet de vérifier les résultats et de comprendre le contexte.
Vous pouvez regrouper et compter les entités afin de comprendre les modèles dans vos données :
from collections import Counter
# Count different entity types
entity_types = Counter(e.extraction_class for e in result.extractions)
print("Entity breakdown:")
for entity_type, count in entity_types.items():
percentage = (count / len(result.extractions)) * 100
print(f" {entity_type}: {count} entities ({percentage:.1f}%)")
# Find high-priority support tickets
urgent_entities = [
e for e in result.extractions
if e.extraction_class == "urgency_indicator"
and e.attributes.get("priority") == "high"
]
print(f"\nFound {len(urgent_entities)} high-priority indicators")Résultat :
Entity breakdown:
product: 1 entities (25.0%)
timeline: 1 entities (25.0%)
urgency_indicator: 2 entities (50.0%)
Found 2 high-priority indicatorsCette analyse vous permet d'identifier rapidement des tendances, telles que les types de produits qui génèrent le plus de tickets d'assistance ou le nombre de demandes urgentes que vous recevez.
LangExtract enregistre les résultats au format JSONL (JSON Lines), où chaque ligne contient les données d'extraction d'un document. Ce format est compatible avec les outils de traitement des données et facilite la combinaison des résultats de plusieurs extractions :
# Save results to a JSONL file
lx.io.save_annotated_documents(
[result],
output_name="support_ticket_extractions.jsonl",
output_dir="."
)JSONL stocke chaque document sur une ligne distincte en tant qu'objet JSON complet. Contrairement aux fichiers JSON classiques qui contiennent un seul grand tableau, les fichiers JSONL peuvent être traités ligne par ligne, ce qui les rend particulièrement adaptés aux ensembles de données volumineux. Vous pouvez ouvrir ces fichiers dans n'importe quel éditeur de texte ou les charger dans des outils d'analyse de données tels que pandas.
C'est dans la visualisation HTML que LangExtract se distingue véritablement. Il génère un rapport interactif qui met en évidence les entités extraites dans le texte original et vous permet de cliquer sur les résultats :
# Generate interactive HTML visualization
html_content = lx.visualize("support_ticket_extractions.jsonl")
# Save the HTML file
with open("support_analysis.html", "w") as f:
if hasattr(html_content, "data"):
f.write(html_content.data) # For Jupyter notebooks
else:
f.write(html_content) # For regular Python scripts
print("HTML visualization saved as 'support_analysis.html'")Résultat :
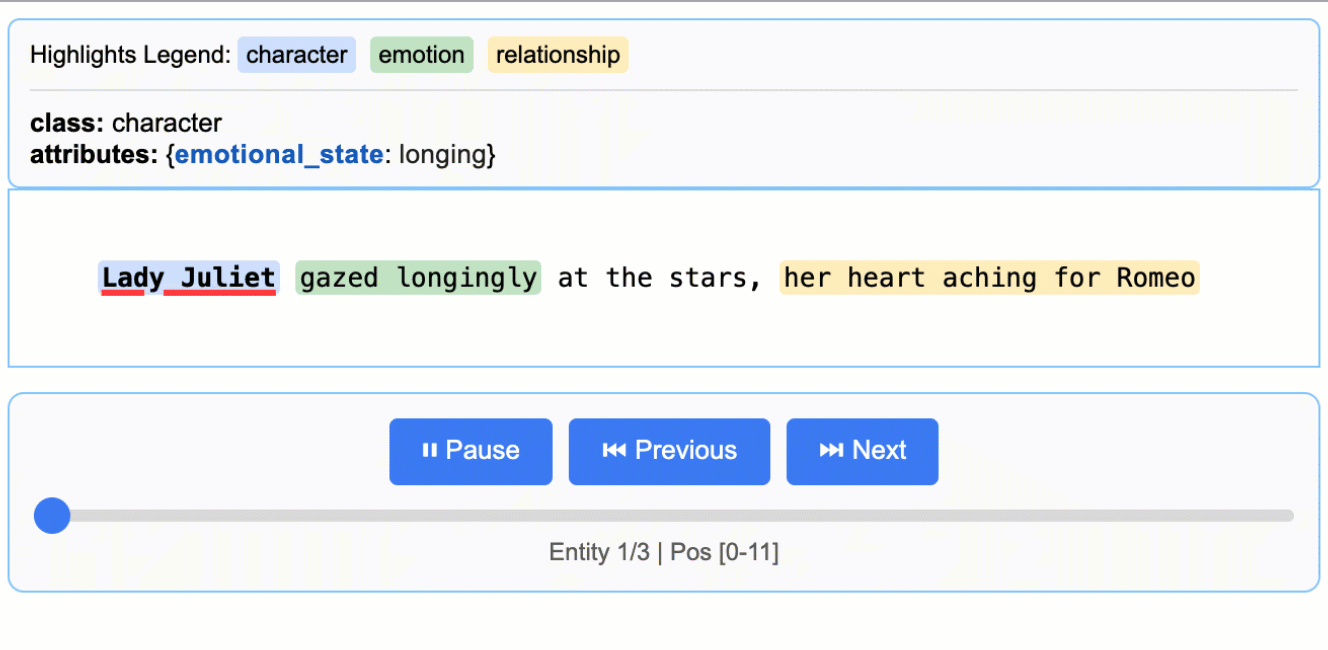
HTML visualization saved as 'support_analysis.html'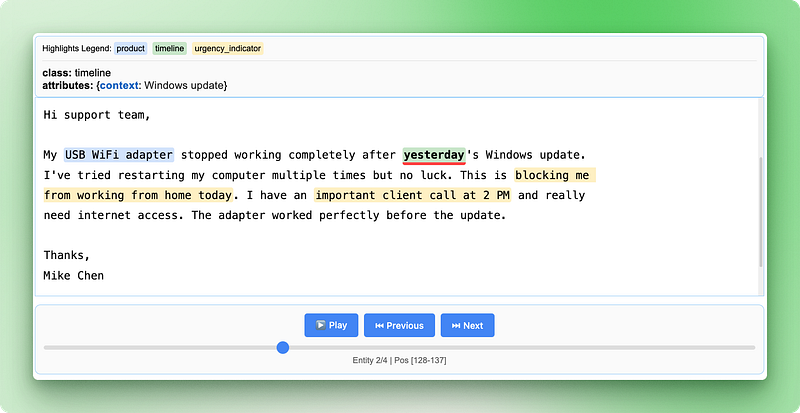
La visualisation HTML affiche votre texte original avec des surlignages codés par couleur pour chaque type d'entité. Vous pouvez cliquer sur le texte surligné pour afficher les attributs extraits, naviguer entre les différentes entités à l'aide des commandes et vérifier que l'IA a correctement identifié les informations importantes. Cela facilite la vérification ponctuelle des résultats et renforce la confiance dans votre pipeline d'extraction.
La visualisation comprend une légende indiquant chaque type d'entité, des commandes de navigation pour passer d'une entité à l'autre et des informations détaillées sur les attributs pour chaque extraction. Cette approche interactive facilite considérablement la compréhension et la validation de vos résultats par rapport à l'examen de données JSON brutes.
Les entités de service à la clientèle que nous avons identifiées fonctionnent efficacement individuellement, mais elles ne reflètent pas la situation dans son ensemble. Lorsqu'un client indique que « mon MacBook Pro de 2021 présente des problèmes de batterie », il est important de comprendre que le produit, l'année du modèle et le problème constituent ensemble un seul et même cas d'assistance. Il n'est pas utile de rechercher ces éléments séparément : il est nécessaire de comprendre les relations qui existent entre eux.
Le NLP traditionnel gère mal cette situation, car il traite chaque entité comme une information isolée. Vous pourriez extraire « MacBook Pro », « 2021 » et « problèmes de batterie » comme des entités distinctes, mais vous auriez alors besoin de règles complexes pour déterminer quels détails correspondent à quels produits. Cette approche devient rapidement inefficace lorsqu'il s'agit de traiter plusieurs produits ou clients dans un même texte.
LangExtract résout ce problème en extrayant les relations lors du premier passage, plutôt que d'essayer de relier les entités par la suite. Vous pouvez regrouper les informations connexes à l'aide d'attributs communs tout en continuant à suivre précisément l'origine de chaque élément dans le texte original. Nous allons procéder à l'extraction des informations relatives aux employés à partir des documents RH, où nous devons associer les personnes à leurs fonctions, leurs services et leurs coordonnées.
Dans cet exemple, nous extrairons les informations relatives aux employés à partir des annonces de l'entreprise, où plusieurs détails concernant chaque personne doivent être reliés :
import langextract as lx
import textwrap
# Define relationship extraction prompt
prompt = textwrap.dedent("""
Extract employee information from company announcements.
Group related details about each person using employee_group attributes.
Connect names, titles, departments, and contact info for each employee.
Use exact text from the announcement - don't paraphrase.
""")
# Create examples showing how to group related information
examples = [
lx.data.ExampleData(
text="Sarah Johnson, our new Marketing Director, will lead the digital campaigns team. You can reach Sarah at sarah.j@company.com for any marketing questions.",
extractions=[
lx.data.Extraction(
extraction_class="person",
extraction_text="Sarah Johnson",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="job_title",
extraction_text="Marketing Director",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="department",
extraction_text="digital campaigns team",
attributes={"employee_group": "Sarah Johnson"}
),
lx.data.Extraction(
extraction_class="contact",
extraction_text="sarah.j@company.com",
attributes={"employee_group": "Sarah Johnson", "type": "email"}
)
]
)
]L'attribut « employee_group » (attribut de liaison) agit comme un système de liaison : toutes les entités ayant la même valeur d'employee_group s appartiennent à la même personne. Cela vous permet d'extraire des informations complexes et fragmentées tout en gardant une trace des détails qui vont ensemble.
Maintenant, veuillez extraire d'une annonce d'entreprise avec plusieurs employés :
# Sample HR announcement with multiple employees
hr_announcement = """
We're excited to announce two new hires joining our team this month.
Mike Chen joins us as Senior Software Engineer in our Backend Development group. Mike brings 8 years of Python experience and will focus on API architecture. Please welcome Mike - he'll be working from our Seattle office and you can reach him at m.chen@company.com.
Additionally, Lisa Rodriguez starts as Product Manager for our Mobile Apps division. Lisa previously worked at TechStart Inc and has extensive experience with user research. Her office phone is 555-0199 and email is lisa.r@company.com.
"""
# Extract relationships
result = lx.extract(
text_or_documents=hr_announcement,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini"
)
print(f"Extracted {len(result.extractions)} entities")Résultat :
✓ Extraction processing complete
INFO:absl:Finalizing annotation for document ID doc_a349ae1d.
INFO:absl:Document annotation completed.
✓ Extracted 10 entities (4 unique types)
• Time: 8.57s
• Speed: 67 chars/sec
• Chunks: 1
Extracted 10 entitiesAprès l'extraction, vous pouvez regrouper les entités associées afin d'afficher les informations complètes pour chaque employé. Cela nécessite un peu de code Python pour réorganiser les entités dispersées en groupes logiques :
from collections import defaultdict
# Group entities by employee_group
employee_groups = defaultdict(list)
for extraction in result.extractions:
group_id = extraction.attributes.get("employee_group")
if group_id:
employee_groups[group_id].append(extraction)
# Print organized employee information
for employee, details in employee_groups.items():
print(f"\n=== {employee} ===")
for detail in details:
print(f"{detail.extraction_class}: {detail.extraction_text}")
if detail.attributes.get("type"):
print(f" Type: {detail.attributes['type']}")Résultat :
=== Mike Chen ===
person: Mike Chen
job_title: Senior Software Engineer
department: Backend Development group
contact: m.chen@company.com
Type: email
contact: Seattle office
Type: location
=== Lisa Rodriguez ===
person: Lisa Rodriguez
job_title: Product Manager
department: Mobile Apps division
contact: lisa.r@company.com
Type: email
contact: 555-0199
Type: phoneVoici ce que ce code effectue étape par étape :
defaultdict(list) crée un dictionnaire dans lequel chaque nouvelle entrée commence automatiquement par une liste videextraction.attributes.get("employee_group") obtient en toute sécurité l'ID de groupe à partir des attributs de chaque entité, renvoyant None s'il n'existe pas.employee_groups[group_id].append(extraction) ajoute chaque entité à la liste de son groupeL'defaultdict est une collection Python qui crée automatiquement les entrées manquantes. Lorsque vous accédez à employee_groups["Mike Chen"] pour la première fois, une liste vide est automatiquement créée pour cet employé. Cela vous évite de vérifier si chaque employé figure déjà dans le dictionnaire.
Cette approche de regroupement vous permet de reconstituer des profils complets d'employés à partir des informations dispersées dans le texte original, tout en conservant les emplacements sources exacts de chaque donnée.
La visualisation HTML devient encore plus utile avec les données relationnelles, car elle montre à la fois les entités individuelles et leurs connexions :
# Save the relationship extraction results
lx.io.save_annotated_documents(
[result],
output_name="employee_relationships.jsonl",
output_dir="."
)
# Generate HTML visualization showing relationships
html_content = lx.visualize("employee_relationships.jsonl")
with open("employee_relationships.html", "w") as f:
if hasattr(html_content, "data"):
f.write(html_content.data)
else:
f.write(html_content)
print("Relationship visualization saved as 'employee_relationships.html'")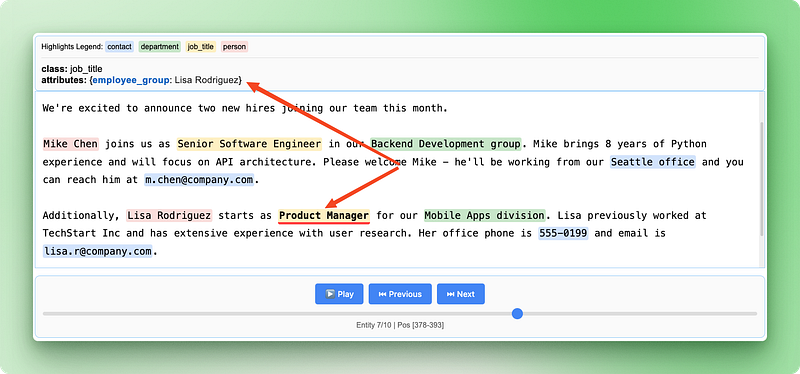
La visualisation des relations met en évidence la manière dont différentes informations s'assemblent pour former des dossiers complets sur les employés, ce qui permet de vérifier facilement que l'IA a correctement identifié et regroupé les détails connexes à partir de l'annonce initiale.
LangExtract collabore avec plusieurs fournisseurs de modèles d'IA, chacun offrant différents compromis entre coût, rapidité et précision. Les modèles Gemini de Google sont prêts à l'emploi et intègrent une prise en charge native des schémas, ce qui en fait l'option la plus simple pour la plupart des tâches d'extraction. Les modèles GPT ( ) d'OpenAI offrent souvent une plus grande précision, mais nécessitent une configuration supplémentaire et sont plus coûteux par extraction.
# Using Google Gemini (default and recommended)
result_gemini = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash" # Fast and cost-effective
)
# Using OpenAI GPT models
result_openai = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o-mini",
fence_output=True, # Required for OpenAI
use_schema_constraints=False # OpenAI doesn't support constraints
)Pour le traitement local ou lorsque vous souhaitez éviter les coûts liés à l'API, vous pouvez exécuter des modèles localement à l'aide d'Ollama. Les modèles locaux sont efficaces pour les tâches d'extraction plus simples et vous offrent un contrôle total sur vos données, bien qu'ils soient généralement plus lents et moins précis que les options cloud.
# Using local models with Ollama (requires Ollama installed)
result_local = lx.extract(
text_or_documents=employee_text,
prompt_description=prompt,
examples=examples,
model_id="gemma2:2b", # Local Gemma model
model_url="http://localhost:11434", # Ollama server
fence_output=False, # Local models don't need fencing
use_schema_constraints=False # Disable constraints
)Les textes réels ne ressemblent en rien à nos exemples soignés. Vous recevez des rapports de 50 pages avec une mise en page désordonnée, des e-mails clients contenant de nombreuses fautes de frappe et des PDF avec un espacement inhabituel. Certains documents contiennent des milliers de mots répartis dans différentes sections, et les informations importantes peuvent être dissimulées n'importe où.
LangExtract gère ces situations complexes à l'aide de trois outils principaux : exécution simultanée de plusieurs documents, tentatives d'extraction répétées et division des documents volumineux en plusieurs parties plus petites. Au lieu de traiter un document à la fois, vous pouvez travailler sur plusieurs documents simultanément, ce qui accélère considérablement le processus.
# Settings for processing lots of real documents
result = lx.extract(
text_or_documents=document_batch,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
max_workers=20, # Work on many documents at once
extraction_passes=3, # Try extraction 3 times
max_char_buffer=1000 # Break big text into small pieces
)Le paramètre « max_workers » (Nombre maximal de documents traités simultanément) détermine le nombre de documents traités simultanément. Un nombre plus important de travailleurs permet d'obtenir des résultats plus rapides, mais cela implique également des coûts plus élevés et peut entraîner des contraintes liées aux limites de l'API. Commencez avec 10 à 20 employés et observez comment cela se déroule.
Plusieurs passages d'extraction permettent de trouver des informations qui auraient pu être omises lors du premier passage. LangExtract effectue l'extraction à plusieurs reprises et combine les résultats. Cette méthode permet de recueillir davantage de détails, mais elle est plus longue et plus coûteuse.
Diviser les documents en plusieurs parties facilite la lecture des textes longs. Le paramètre « max_char_buffer » (Réduire la taille des documents) divise les documents volumineux en plusieurs parties plus petites qui sont plus adaptées aux modèles d'IA. Les petits morceaux (1 000 à 2 000 caractères) permettent de saisir davantage de détails, tandis que les grands morceaux (3 000 à 5 000 caractères) conservent davantage de contexte, mais peuvent omettre certains éléments.
# Different settings for different types of documents
# For important documents that need careful review
detailed_result = lx.extract(
text_or_documents=legal_documents,
extraction_passes=5, # Try 5 times for accuracy
max_char_buffer=800, # Small chunks for detail
max_workers=10 # Fewer workers to avoid limits
)
# For quick processing of simple documents
quick_result = lx.extract(
text_or_documents=email_batch,
extraction_passes=1, # Single pass for speed
max_char_buffer=3000, # Bigger chunks for speed
max_workers=30 # More workers for faster results
)Le travail de production implique la gestion de problèmes. Les documents peuvent présenter des erreurs d'encodage, les connexions réseau peuvent échouer et les API peuvent limiter la vitesse de traitement. Surveillez vos tâches d'extraction, ajoutez une logique de nouvelle tentative pour les documents ayant échoué et suivez vos dépenses auprès des différents fournisseurs d'IA.
Lorsque vous travaillez avec différents types de documents, veuillez définir des règles d'extraction distinctes pour chaque type. Les contrats juridiques nécessitent des invites différentes de celles utilisées pour les e-mails clients. Les rapports financiers nécessitent des tailles de blocs différentes de celles des publications sur les réseaux sociaux. Veuillez créer des pipelines distincts pour chaque type de document plutôt que de tenter de faire en sorte qu'un seul système gère tout.
LangExtract adopte une approche différente de celle des bibliothèques NLP traditionnelles. Alors que la plupart des bibliothèques s'appuient sur des modèles pré-entraînés ou des systèmes basés sur des règles, LangExtract utilise des modèles linguistiques de grande taille capables de comprendre le contexte et le sens comme le font les humains. Comparons-le à trois bibliothèques NLP populaires de Python afin de comprendre dans quels cas il serait préférable de choisir LangExtract plutôt que d'autres options.
spaCy se concentre sur la rapidité et les tâches de NLP prêtes à la production telles que la tokenisation, le marquage des parties du discours et la reconnaissance des entités nommées. Il est fourni avec des modèles pré-entraînés qui reconnaissent les entités courantes telles que les personnes, les organisations et les lieux, mais rencontre des difficultés avec les entités spécifiques à un domaine ou les catégories personnalisées. spaCy excelle dans le traitement rapide de grandes quantités de texte, mais il est nécessaire de réentraîner les modèles ou d'écrire des règles complexes pour extraire des informations personnalisées.
LangExtract élimine cette complexité en vous permettant de définir des entités personnalisées à l'aide d'exemples et d'invites simples, tout en fournissant les emplacements sources exacts que spaCy ne suit pas.
NLTK (Natural Language Toolkit) est conçu pour l'enseignement et la recherche, offrant une large gamme d'algorithmes et de jeux de données NLP. Il fournit les éléments de base pour le traitement de texte, mais nécessite des connaissances approfondies en programmation pour créer des solutions complètes. NLTK est particulièrement adapté à l'apprentissage des concepts du TALN et au prototypage, mais la création de systèmes d'extraction prêts à être mis en production nécessite la combinaison de plusieurs composants NLTK et l'écriture d'un code substantiel.
LangExtract offre une solution complète prête à l'emploi : vous définissez vos besoins à l'aide d'exemples plutôt que d'algorithmes de codage, et vous obtenez des visualisations interactives sans travail de développement supplémentaire.
Transformers (Hugging Face) fournit l'accès à des modèles de transformateurs de pointe pour diverses tâches de traitement du langage naturel, notamment la reconnaissance d'entités nommées et la réponse à des questions. Bien que puissant, il nécessite une expertise en apprentissage automatique pour affiner les modèles pour des domaines spécifiques et ne fournit pas de suivi intégré des sources ni d'extraction des relations. Il est nécessaire de gérer le déploiement des modèles, de prendre en charge différents formats de modèles et de développer vos propres outils de visualisation.
LangExtract simplifie la complexité liée à l'utilisation de différents modèles d'IA, gère automatiquement le suivi des sources et permet l'extraction de relations grâce à un regroupement simple des attributs plutôt qu'à des architectures de modèles complexes.
|
Caractéristique |
LangExtract |
spaCy |
NLTK |
Transformateurs |
|
Complexité de la configuration |
Instructions simples + exemples |
Formation des modèles/règles |
Codage d'algorithmes |
Ajustement du modèle |
|
Entités personnalisées |
Définition en langage naturel |
Une nouvelle formation est nécessaire. |
Rédaction manuelle des règles |
Ajustement du modèle |
|
Suivi des sources |
Automatique avec positions précises |
Non disponible |
Mise en œuvre manuelle |
Mise en œuvre manuelle |
|
Extraction des relations |
Regroupement intégré |
Rédaction de règles complexes |
Codage manuel |
Développement de modèles personnalisés |
|
Compréhension du contexte |
Propulsé par LLM |
Basé sur des modèles |
Basé sur des règles |
Model-dependent |
|
Visualisation |
HTML interactif |
Outils externes requis |
Outils externes requis |
Outils externes requis |
|
Courbe d'apprentissage |
Faible (basé sur des exemples) |
Moyen (connaissances en PNL) |
Élevé (algorithmes) |
Élevé (expertise en ML) |
|
Idéal pour |
Extraction spécifique à un domaine |
Pipelines NLP généraux |
Recherche/apprentissage |
Applications d'IA personnalisées |
LangExtract transforme l'extraction de texte, qui consistait auparavant à rédiger des règles complexes, en une conversation avec l'IA au sujet de vos données. Vous avez appris à configurer l'extraction d'entités personnalisées à l'aide d'invites et d'exemples simples, à regrouper des informations connexes grâce à l'extraction de relations et à créer des visualisations interactives qui indiquent précisément la provenance de chaque donnée. La bibliothèque gère les défis liés à la production, tels que le traitement parallèle et le découpage de documents, ce qui la rend pratique pour les applications concrètes impliquant des textes complexes et incohérents.
Que vous traitiez des tickets d'assistance client, analysiez des documents juridiques ou extrayez des informations à partir d'articles de recherche, LangExtract offre une approche plus intuitive que les bibliothèques NLP traditionnelles. Au lieu de consacrer du temps à la formation de modèles ou à la rédaction de règles, vous pouvez vous concentrer sur la définition des informations pertinentes pour votre cas d'utilisation spécifique. Commencez par des extractions simples sur vos propres données textuelles, puis développez-les à l'aide des techniques de production abordées dans ce tutoriel.
Apprenez l'IA grâce à ces cours.
Cours
Cours
Cours