programa
Desarrollar grandes modelos lingüísticos
16 h
Ejecutar Llama 3 localmente puede parecer desalentador debido a los elevados requisitos de RAM, GPU y potencia de procesamiento. Sin embargo, los avances en los marcos de trabajo y la optimización de modelos han hecho que esto sea más accesible que nunca. He aquí por qué deberías considerarlo:
Lee nuestro artículo, Los pros y los contras de utilizar grandes modelos lingüísticos (LLM) en la nube frente a los LLM en la nube. Ejecutar los LLM localmente, para saber más sobre si utilizar los LLM localmente es para ti.
GPT4ALL es un software de código abierto que te permite ejecutar modelos lingüísticos populares de gran tamaño en tu máquina local, incluso sin una GPU. Es fácil de usar, lo que la hace accesible a personas sin formación técnica.
Empezaremos descargando e instalando el GPT4ALL en Windows yendo a la página oficial de descargas.
Tras instalar la aplicación, ejecútala y haz clic en el botón "Descargas" para abrir el menú de modelos. Allí, puedes desplazarte hacia abajo y seleccionar el modelo "Llama 3 Instruct", y luego hacer clic en el botón "Descargar".
Una vez finalizada la descarga, cierra la pestaña y selecciona el modelo Llama 3 Instruct haciendo clic en el menú desplegable "Elegir un modelo".
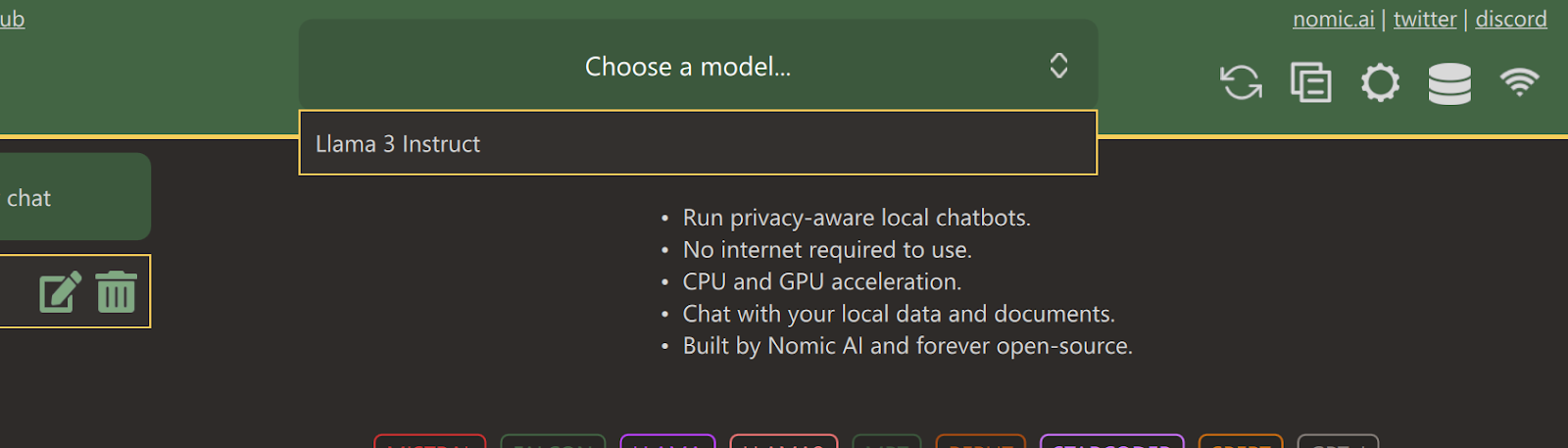
Escribe un mensaje y empieza a utilizarlo como ChatGPT. El sistema tiene instalado el kit de herramientas CUDA, por lo que utiliza la GPU para generar una respuesta más rápida.
Ahora, vamos a probar la forma más sencilla de utilizar Llama 3 localmente descargando e instalando Ollama.
Ollama es una potente herramienta que te permite utilizar LLMs localmente. Es rápido y tiene montones de funciones.
Tras instalar Ollama en tu sistema, inicia el terminal/PowerShell y escribe el comando
ollama run llama3Nota: Descargar el archivo del modelo e iniciar el chatbot dentro del terminal te llevará unos minutos.
Escribe indicaciones o empieza a hacer preguntas, y Ollama generará la respuesta dentro de tu terminal. La respuesta del chat es superrápida, y puedes seguir haciendo preguntas de seguimiento para profundizar en el tema.
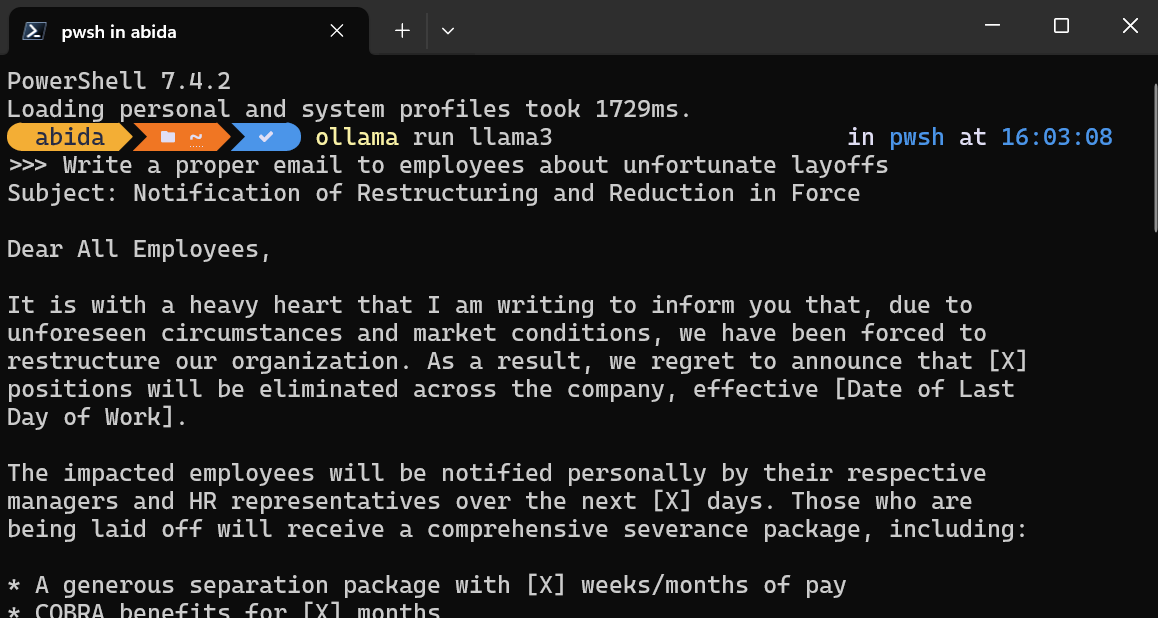
Para salir del chatbot, escribe /bye .
Además de estos dos programas, puedes consultar la página Ejecutar LLM localmente: 7 Métodos Sencillos guía para explorar aplicaciones y marcos adicionales.
Ejecutar un servidor local te permite integrar Llama 3 en otras aplicaciones y crear tu propia aplicación para tareas específicas.
Inicia el servidor local de inferencia de modelos escribiendo el siguiente comando en el terminal.
ollama servePara comprobar si el servidor funciona correctamente, ve a la bandeja del sistema, busca el icono de Ollama y haz clic con el botón derecho para ver los registros.
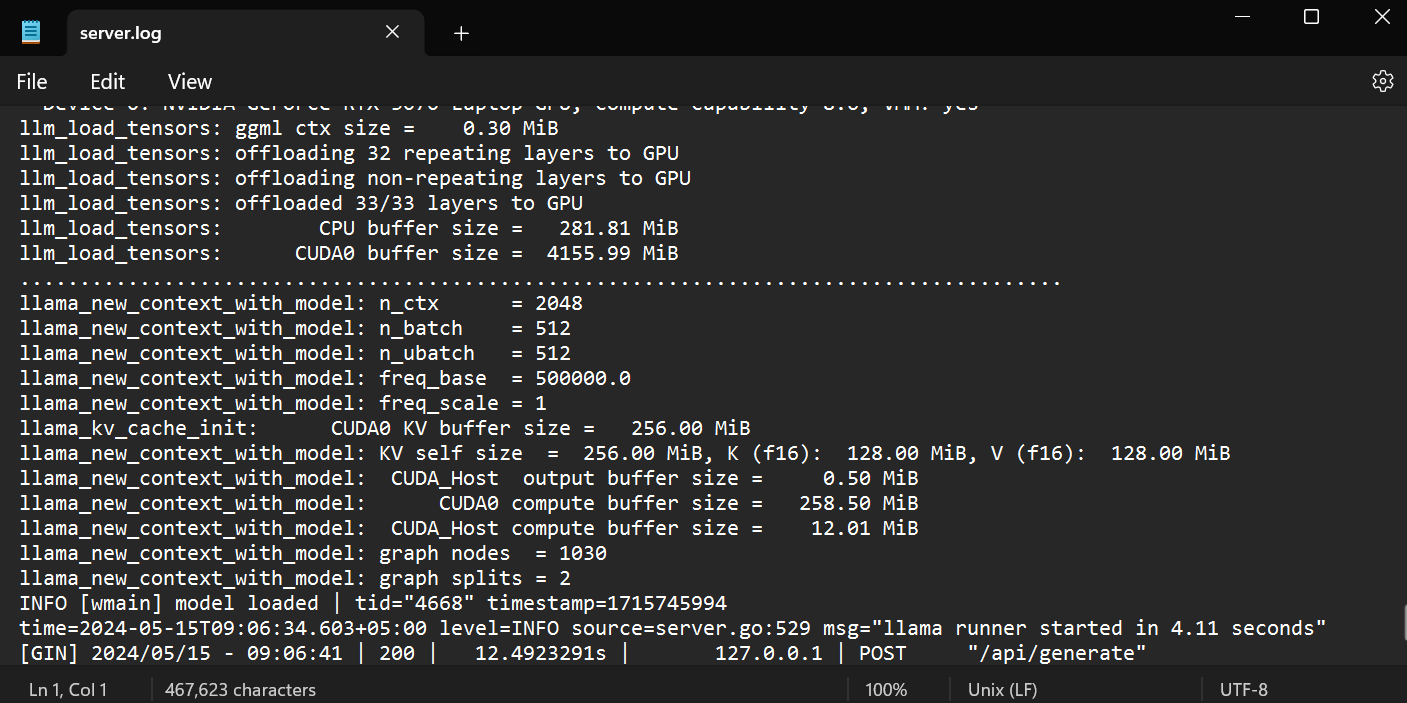
Te llevará a la carpeta Ollama, donde podrás abrir el archivo `server.log` para ver información sobre las peticiones del servidor a través de las API e información del servidor con marcas de tiempo.
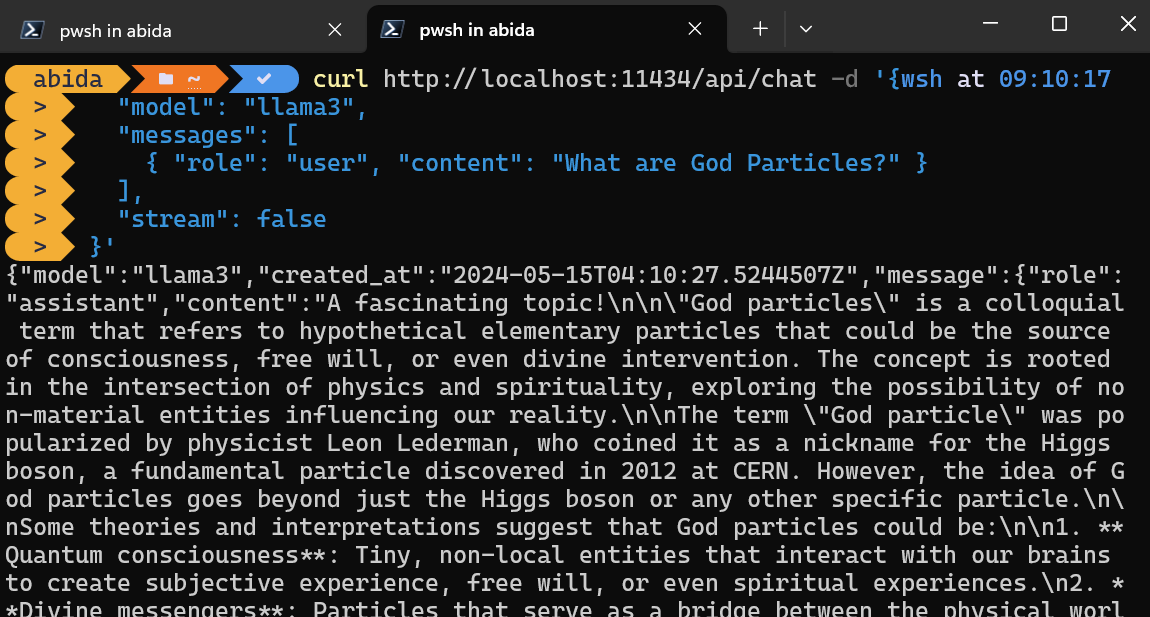
Puedes acceder simplemente al servidor de inferencia utilizando el comando CURL.
Sólo tienes que indicar el nombre del modelo y la indicación, y asegurarte de que la transmisión está desactivada para obtener el mensaje completo.
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "What are God Particles?" }
],
"stream": false
}'El comando CURL es nativo de Linux, pero también puedes utilizarlo en Windows PowerShell, como se muestra a continuación.
También puedes instalar el paquete Ollama Python utilizando PIP para acceder al servidor de inferencia.
pip install ollamaAcceder a la API en Python te da el poder de crear aplicaciones y herramientas potenciadas por la IA, y es muy fácil de usar.
Sólo tienes que proporcionar a las funciones `ollama.chat` el nombre del modelo y el mensaje, y generará la respuesta.
Nota: En el argumento del mensaje, también puedes añadir un aviso del sistema y un aviso del asistente para añadir el contexto.
import ollama
response = ollama.chat(
model="llama3",
messages=[
{
"role": "user",
"content": "Tell me an interesting fact about elephants",
},
],
)
print(response["message"]["content"])
El paquete Python de Ollama también proporciona funciones como las llamadas asíncronas y el streaming, que permiten una gestión eficaz de las peticiones a la API y aumentan la velocidad percibida del modelo.
De forma similar a la API de OpenAI, puedes crear una función de chat asíncrona y luego escribir código de transmisión utilizando la función asíncrona, lo que permite interacciones eficientes y rápidas con el modelo.
import asyncio
from ollama import AsyncClient
async def chat():
"""
Stream a chat from Llama using the AsyncClient.
"""
message = {
"role": "user",
"content": "Tell me an interesting fact about elephants"
}
async for part in await AsyncClient().chat(
model="llama3", messages=[message], stream=True
):
print(part["message"]["content"], end="", flush=True)
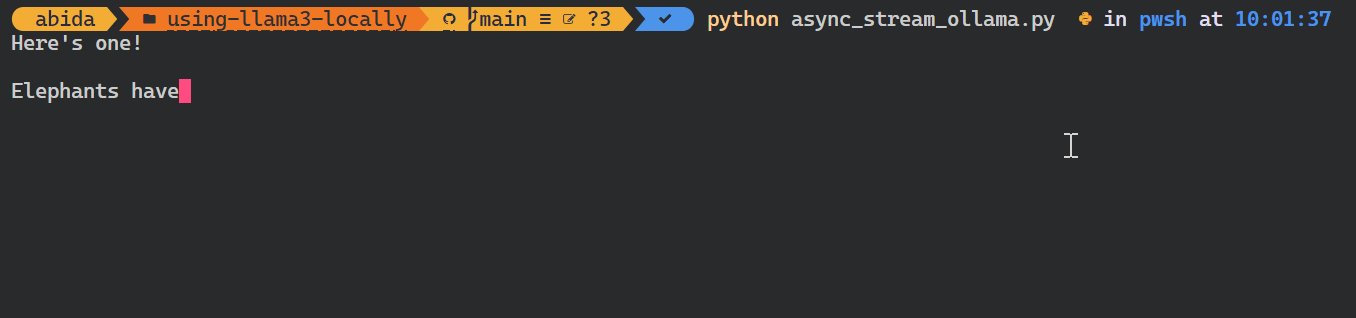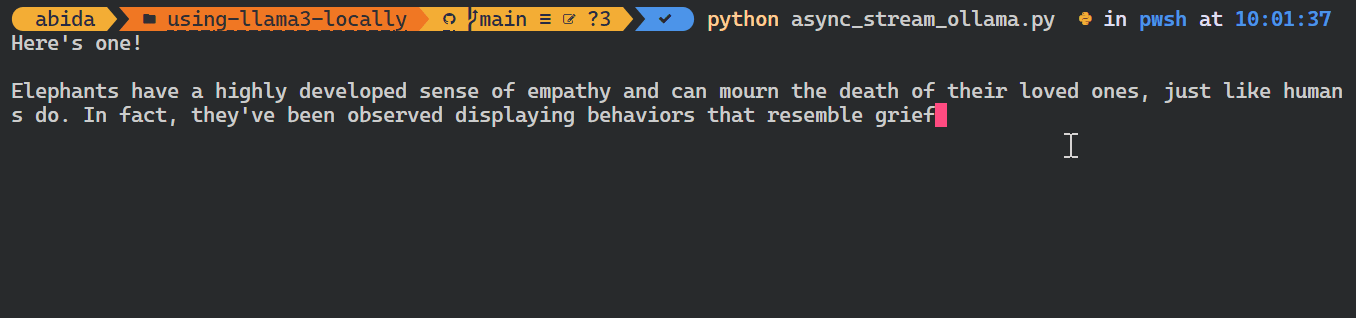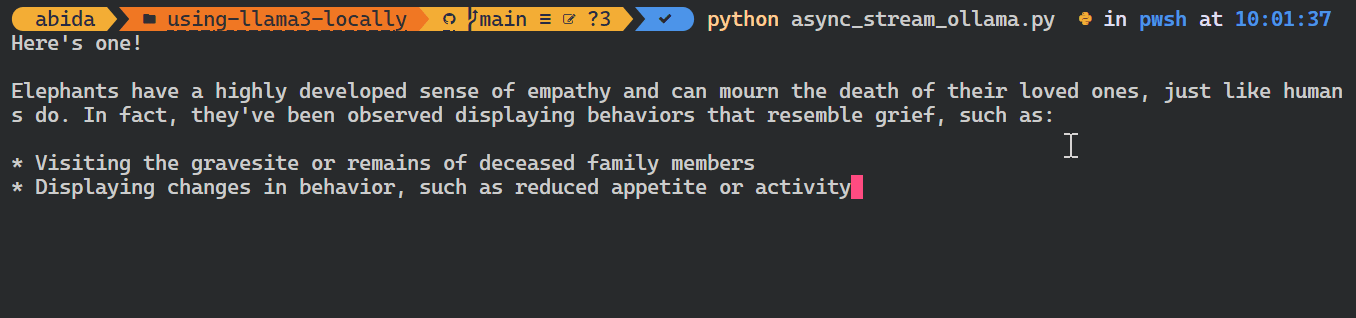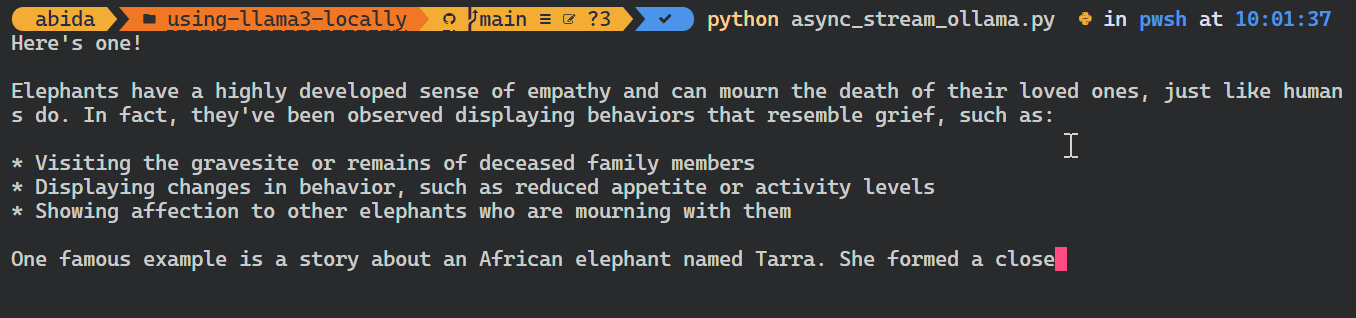
asyncio.run(chat())Como puedes ver, el modelo muestra las fichas a medida que se generan.
También puedes utilizar la API de Python para crear el modelo personalizado, convertir el texto en incrustaciones y gestionar los errores. También puedes copiar, borrar, extraer y empujar los modelos.
Además de utilizar Ollama como chatbot o para generar respuestas, puedes integrarlo en VSCode y utilizar Llama 3 para funciones como el autocompletado, las sugerencias de código contextualizadas, la escritura de código, la generación de docstrings, las pruebas unitarias, etc.
1. En primer lugar, tenemos que inicializar el servidor de inferencia Ollama escribiendo el siguiente comando en el terminal.
ollama serve2. Ve a Extensiones VSCode, busca la herramienta "CodeGPT" e instálala. CodeGPT te permite conectar cualquier proveedor de modelos utilizando la clave API.

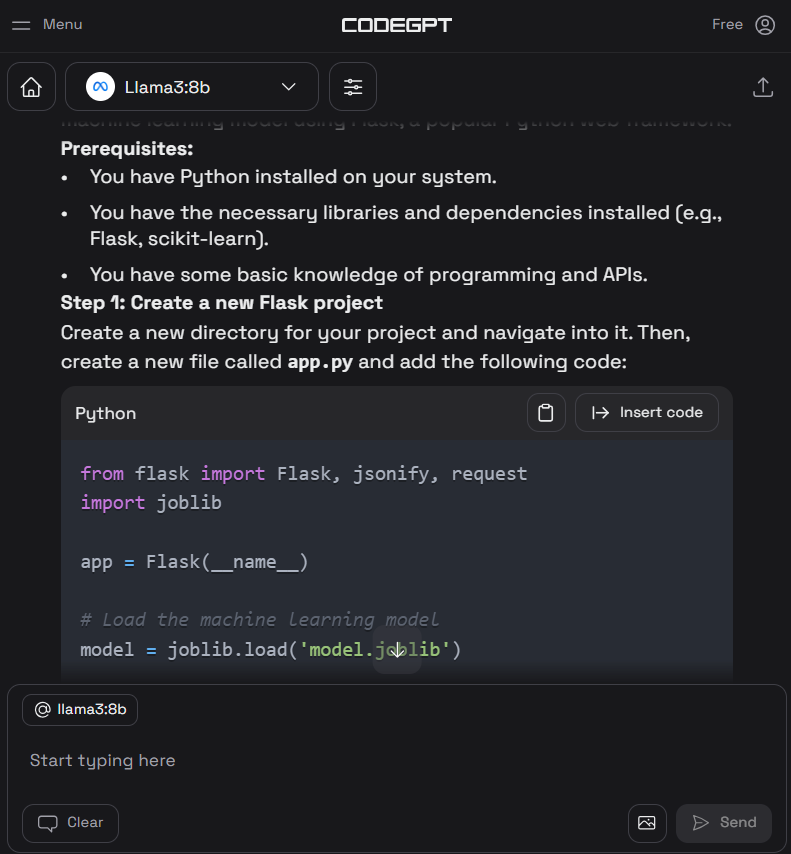
3. Configura el CodeGPT haciendo clic en el icono de chat del CodeGPT en el panel izquierdo. Cambia el proveedor del modelo a Ollama y selecciona el modelo llama3:8b. No tienes que proporcionar una clave API, ya que lo ejecutamos localmente.
4. Escribe el prompt para generar el código Python y luego pulsa el botón "Insertar el código" para transferir el código a tu archivo Python. También puedes escribir instrucciones de seguimiento para mejorar el código.
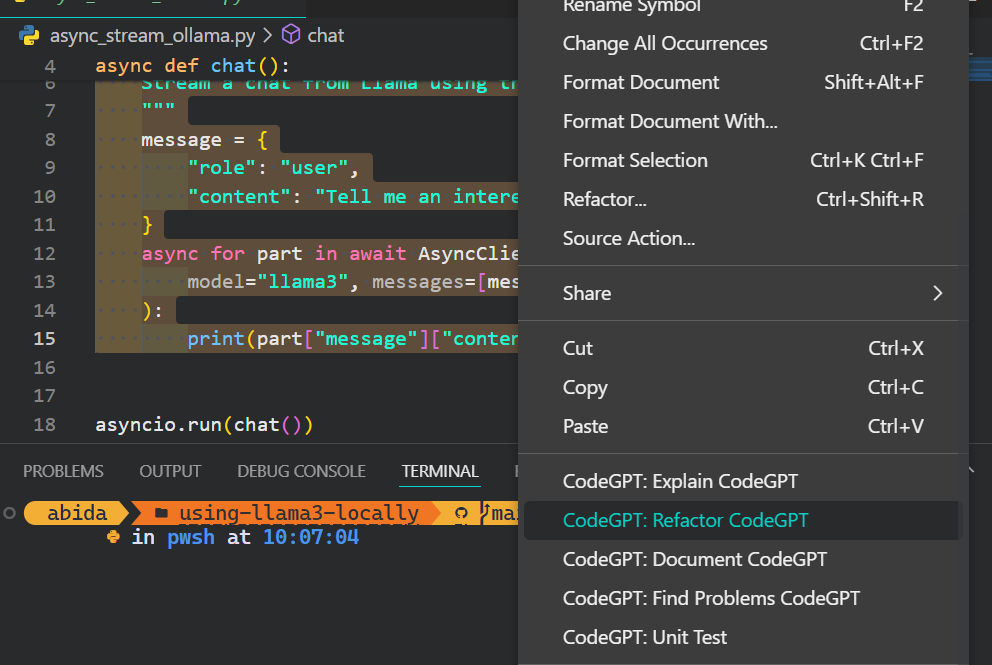
5. Además del asistente de codificación, puedes utilizar CodeGPT para comprender el código, refactorizarlo, documentarlo, generar las pruebas unitarias y resolver los problemas.
Si quieres sentirte como un profesional de Python, consulta la guía Configurar VSCode para Python para conocer la función principal de VSCode y personalizarla según tus necesidades.
En esta sección, desarrollaremos una aplicación potenciada por IA que lee archivos docx de una carpeta designada, los convierte en incrustaciones y los almacena en un almacén vectorial.
Después, utilizaremos una búsqueda por similitud para recuperar significados relevantes y dar respuestas contextuales a tus preguntas.
Esta aplicación te permitirá comprender rápidamente la esencia de los libros y profundizar en el desarrollo de los personajes.
En primer lugar, instalaremos todos los paquetes Python necesarios para cargar los documentos, el almacén vectorial y los marcos LLM.
pip install unstructured[docx] langchain langchainhub langchain_community langchain-chromaA continuación, inicia el servidor de inferencia Ollama.
ollama serveEs una buena práctica desarrollar y probar tu código en Jupyter Notebook antes de crear la aplicación.
Cargaremos todos los archivos docx de la carpeta utilizando la dirección DirectoryLoader.
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("C:/Users/abida/Desktop/Books", glob="**/*.docx")
books = loader.load()
len(books)4Puedes crear tu propio chatbot consciente del contexto siguiendo el tutorial, Desarrollo de Chatbot con ChatGPT y LangChain: Un enfoque consciente del contexto.
Alimentar el modelo con un libro entero no es factible, ya que sobrepasaría su ventana de contexto. Para superar esta limitación, debemos dividir el texto en trozos más pequeños y manejables que quepan cómodamente en la ventana contextual del modelo.
En nuestro caso, convertiremos los cuatro libros a un tamaño de trozo de 500 caracteres.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(books)
Utilizaremos Langchain para convertir el texto en la incrustación y almacenarlo en la base de datos Chroma.
Utilizamos el modelo Ollama Llama 3 como modelo de incrustación.
from langchain_chroma import Chroma
from langchain_community.embeddings import OllamaEmbeddings
vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=OllamaEmbeddings(model="llama3", show_progress=True),
persist_directory="./chroma_db",
)OllamaEmbeddings: 100%|██████████| 23/23 [01:00<00:00, 2.63s/it]Vamos a probar nuestra base de datos vectorial realizando algunas búsquedas de similitud.
question = "Who is Zahra?"
docs = vectorstore.similarity_search(question)
docsObtuvimos cuatro resultados similares a la pregunta.

Puedes sumergirte en el mundo de las bases de datos vectoriales y Chroma DB leyendo el tutorial, Aprende a utilizar Chroma DB: Guía paso a paso.
Para construir un sistema adecuado de recuperación de preguntas y respuestas, utilizaremos cadenas de Langchain y empezaremos a añadir los módulos.
En nuestra cadena de preguntas y respuestas
En pocas palabras, antes de pasarla por el modelo Llama 3, tu pregunta se contextualizará mediante la búsqueda de similitudes y la indicación RAG.
from langchain import hub
from langchain_community.llms import Ollama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
llm = Ollama(model="llama3")
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_prompt = hub.pull("rlm/rag-prompt")
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)Puedes construir una aplicación similar utilizando LLamaIndex. Para ello, sigue el enlace LlamaIndex: Un marco de datos para las aplicaciones basadas en grandes modelos lingüísticos (LLM) tutorial.
Haz preguntas relevantes sobre los libros para comprender mejor la historia.
question = "What is the story of the 'Gené is Missing' book?"
qa_chain.invoke(question)Como vemos, utilizar los libros como contexto proporciona una respuesta precisa.
'Based on the provided context, "Gené is Missing" appears to be a mystery novel that revolves around uncovering the truth about Gené\'s life and potential involvement in murders. The story follows different perspectives, including Simon trying to prove his innocence, flashbacks of Gené\'s past, and detective Jacob investigating the case.'Hagamos ahora una pregunta sobre el personaje.
question = "Who is Arslan?"
qa_chain.invoke(question)Se generó una respuesta precisa.
'Arslan is Zahra\'s brother\'s best friend. He is someone that Zahra visits in the book "A Boy with Honest Dreams" by Abid Ali Awan to gather information about Ali.'Para crear una aplicación de IA completa que se ejecute sin problemas en tu terminal, combinaremos todo el código de las secciones anteriores en un único archivo Python.
code AI_app.pyAdemás, mejoraremos el código para permitir la consulta interactiva, lo que te permitirá plantear preguntas a la aplicación repetidamente hasta que termines explícitamente la sesión escribiendo "salir".
from langchain_chroma import Chroma
from langchain_community.embeddings import OllamaEmbeddings
from langchain import hub
from langchain_community.llms import Ollama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# loading the vectorstore
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=OllamaEmbeddings(model="llama3"))
# loading the Llama3 model
llm = Ollama(model="llama3")
# using the vectorstore as the retriever
retriever = vectorstore.as_retriever()
# formating the docs
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# loading the QA chain from langchain hub
rag_prompt = hub.pull("rlm/rag-prompt")
# creating the QA chain
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# running the QA chain in a loop until the user types "exit"
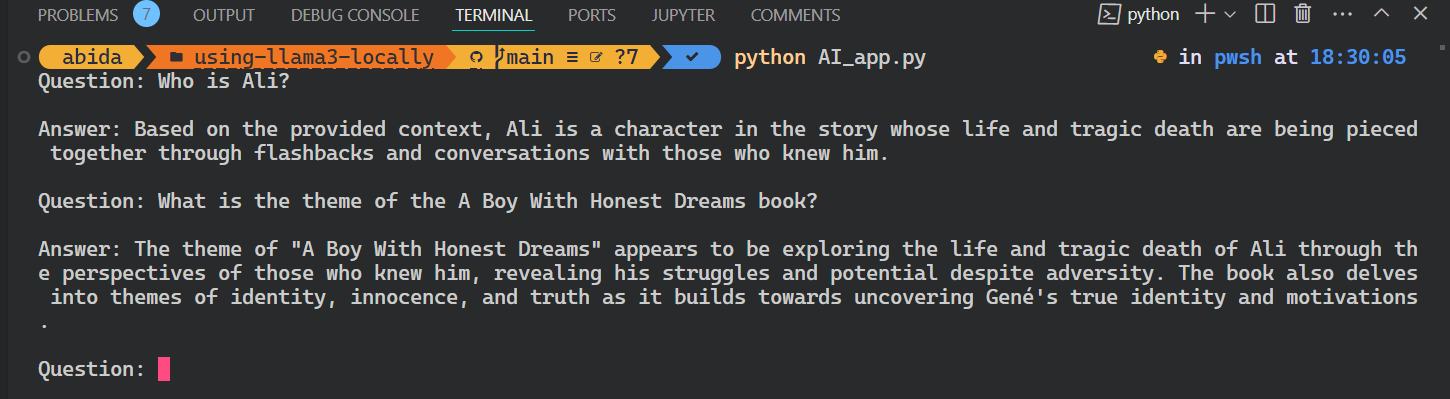
while True:
question = input("Question: ")
if question.lower() == "exit":
break
answer = qa_chain.invoke(question)
print(f"\nAnswer: {answer}\n")
Ejecuta la aplicación escribiendo `Python` y el nombre del archivo en el terminal.
python AI_app.pyEsto es genial. Hemos creado nuestra propia aplicación RAG AI localmente con pocas líneas de código.
Todo el código fuente de este tutorial está disponible en el repositorio GitHub kingabzpro/using-llama3-locally. Por favor, compruébalo y recuerda poner una estrella ⭐en el repositorio.
En este tutorial, hemos aprendido a utilizar Llama 3 localmente en un ordenador portátil. También hemos aprendido sobre el servidor de inferencia y cómo podemos utilizarlo para integrar Llama 3 en VSCode.
Finalmente, construimos el sistema de recuperación de preguntas y respuestas utilizando Langchain, Chroma y Ollama. Los datos nunca salieron del sistema local, y ni siquiera tuviste que pagar un solo dólar para construirlo. Aparte de las aplicaciones más sencillas, puedes construir sistemas complejos utilizando las mismas herramientas que hemos empleado en este tutorial.
Para saber más, te recomiendo estos tutoriales:
¡Aprende IA con DataCamp!
programa
programa
Curso
blog
Abid Ali Awan
9 min
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze
Tutorial
Adel Nehme