Curso
Introducción al Deep Learning en Python
4 h
263.5K
Tanto si eres un aspirante a científico de datos como si simplemente te interesan los últimos avances en inteligencia artificial, es probable que hayas oído términos como aprendizaje automático y aprendizaje profundo. Pero, ¿qué significan realmente? ¿Y cuáles son las diferencias entre ellos? En este post, examinamos el aprendizaje automático frente al aprendizaje profundo para determinar las similitudes, diferencias, casos de uso y ventajas de estas dos disciplinas cruciales.
Disponemos de una completa Guía rápida de IA para principiantes que profundiza en este tema. Sin embargo, como introducción rápida, la inteligencia artificial (IA) es un campo de la informática cuyo objetivo es crear sistemas inteligentes que puedan realizar tareas que normalmente requieren niveles humanos de inteligencia. Esto puede incluir cosas como reconocer el lenguaje natural, reconocer patrones y tomar decisiones para resolver problemas complejos.
Podemos pensar en la IA como un conjunto de herramientas que podemos utilizar para hacer que los ordenadores se comporten de forma inteligente y automaticen las tareas. Entre los usos de la inteligencia artificial están los coches autoconducidos, los sistemas de recomendación y los asistentes de voz.
Como veremos, términos como aprendizaje automático y aprendizaje profundo son facetas del campo más amplio del aprendizaje automático. Puedes consultar nuestra guía independiente sobre inteligencia artificial frente a aprendizaje automático para profundizar en el tema.
Al igual que con la IA, tenemos una guía dedicada a lo que es el aprendizaje automático. En resumen, el aprendizaje automático (AM) es una forma de aplicar la inteligencia artificial; de hecho, es una rama especializada dentro del amplio campo de la IA, que a su vez es una rama de la informática.
Con el aprendizaje automático, podemos desarrollar algoritmos que tienen la capacidad de aprender sin ser programados explícitamente. Estos algoritmos incluyen:
Entonces, ¿cómo aprenden automáticamente los ordenadores?
La clave son los datos. Proporcionas datos, caracterizados por diversos atributos o rasgos, para que los algoritmos los analicen y comprendan. Estos algoritmos crean un límite de decisión basado en los datos proporcionados, lo que les permite hacer predicciones o clasificaciones. Una vez que el algoritmo ha procesado y comprendido los datos -esencialmente se ha entrenado a sí mismo-, puedes pasar a la fase de prueba. Aquí, introduces nuevos puntos de datos en el algoritmo, y éste te dará resultados sin necesidad de programar más.Ejemplo:
Imagina que quieres predecir el precio de la vivienda. Tienes un conjunto de datos que contiene información sobre 1000 casas, incluido el precio y el número de habitaciones: éstas son tus características. Tu tarea consiste en introducir estas características en un algoritmo, por ejemplo, un algoritmo de árbol de decisión, para que pueda aprender la relación entre el número de habitaciones y el precio de la casa.
En este caso, introduces el número de habitaciones y el algoritmo predice el precio de la casa. Por ejemplo, durante la fase de prueba, si introduces "tres" para el número de habitaciones, el algoritmo debería predecir con exactitud el precio correspondiente de la casa, tras haber aprendido de la relación entre el número de habitaciones y los precios de las casas en los datos de entrenamiento.
El aprendizaje profundo es una subcategoría del aprendizaje automático centrada en estructurar un proceso de aprendizaje para los ordenadores en el que puedan reconocer patrones y tomar decisiones, de forma muy parecida a como lo hacen los humanos. Por ejemplo, si estamos enseñando a un ordenador a distinguir entre distintos animales, empezamos con conceptos básicos más sencillos, como el número de patas, e introducimos gradualmente otros más complejos, como hábitats y comportamientos.
En el ámbito del aprendizaje automático, el aprendizaje profundo se distingue por el uso de redes neuronales con tres o más capas. Estas redes neuronales multicapa se esfuerzan por replicar los patrones de aprendizaje del cerebro humano, permitiendo al ordenador analizar y aprender de grandes volúmenes de datos. Una red de una sola capa puede hacer predicciones rudimentarias, pero a medida que añadimos más capas, la red se vuelve capaz de comprender patrones y relaciones intrincados, mejorando su precisión predictiva.
El aprendizaje profundo es esencialmente un tipo de filtro sofisticado de varias capas. Introducimos datos brutos, no organizados, en la parte superior, y éstos atraviesan varias capas de la red neuronal, refinándose y analizándose en cada nivel. Al final, lo que emerge en el fondo es una información coherente y estructurada o una "predicción" precisa.
Este proceso destaca en el descifrado de datos con múltiples niveles de abstracción, lo que lo hace indispensable para tareas como el reconocimiento de imágenes y del habla, el procesamiento del lenguaje natural y el diseño de estrategias de juego. Es la columna vertebral de muchas innovaciones, desde los asistentes virtuales de nuestros teléfonos hasta el desarrollo de vehículos autónomos.
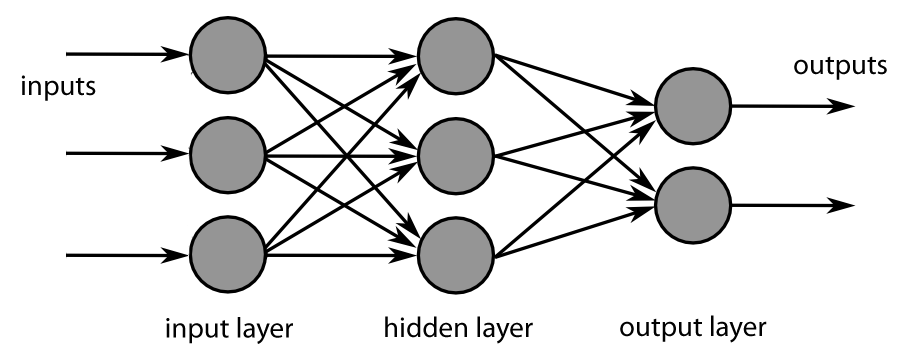
Como puedes ver en la figura anterior, esta red neuronal superficial tiene varias capas:
Así pues, la red neuronal es una función de aproximación en la que la red intenta aprender los parámetros (pesos) en las capas ocultas, que cuando se multiplican con la entrada, te dan una salida prevista cercana a la salida deseada.
El aprendizaje profundo es el apilamiento de múltiples capas ocultas de este tipo entre la capa de entrada y la de salida, de ahí el nombre de aprendizaje profundo.
Como hemos establecido, el aprendizaje profundo es un subconjunto especializado del aprendizaje automático que emplea redes neuronales artificiales con múltiples capas para analizar datos y tomar decisiones inteligentes. Profundiza en el análisis de los datos, de ahí el término "profundo", lo que permite perspectivas más matizadas y sofisticadas. En cambio, el aprendizaje automático, que engloba el aprendizaje profundo, se centra en el desarrollo de algoritmos capaces de aprender de los datos y hacer predicciones o tomar decisiones basadas en ellos, utilizando diversos métodos que incluyen, entre otros, las redes neuronales.
El Aprendizaje Profundo extrae de forma autónoma características significativas de los datos brutos. En este contexto, un "rasgo" es una propiedad o característica individual mensurable del fenómeno observado. El Aprendizaje Profundo no depende de métodos de extracción de características programados manualmente, como los patrones binarios locales o los histogramas de gradientes, que son formas predefinidas de resumir los datos en bruto. En lugar de ello, aprende las características más útiles para realizar la tarea que se le ha encomendado, empezando por las más sencillas y aprendiendo progresivamente representaciones más complejas. El aprendizaje automático tradicional, por otra parte, a menudo se basa en estas características creadas a mano y requiere una cuidadosa ingeniería para funcionar de forma óptima.

Los modelos de aprendizaje profundo están hambrientos de datos; rinden mejor con acceso a datos abundantes. En cambio, muchos algoritmos de aprendizaje automático pueden ofrecer resultados satisfactorios incluso con conjuntos de datos más pequeños. Esto es crucial para que los aspirantes a científicos de datos lo tengan en cuenta a la hora de elegir entre metodologías, especialmente cuando se enfrentan a limitaciones en la disponibilidad de datos.
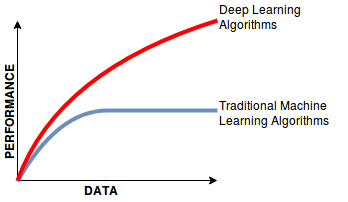
En la figura anterior, puedes ver que, a medida que aumentan los datos, aumenta el rendimiento de los algoritmos de aprendizaje profundo, en comparación con el algoritmo de aprendizaje automático tradicional, en el que el rendimiento casi se satura al cabo de un tiempo aunque aumenten los datos.
El aprendizaje profundo requiere capacidades computacionales avanzadas, normalmente proporcionadas por Unidades de Procesamiento Gráfico (GPU), debido a su gran cantidad de datos y profundidad (número de capas en las redes neuronales). Los algoritmos tradicionales de aprendizaje automático a menudo pueden ejecutarse con Unidades Centrales de Procesamiento (CPU) estándar, lo que los hace más accesibles para los principiantes en la ciencia de datos.
El entrenamiento de una red de aprendizaje profundo puede ser largo y prolongarse durante meses. "Entrenamiento" se refiere al proceso de enseñar al modelo a hacer predicciones precisas alimentándolo con datos. El "tiempo de inferencia", o el tiempo que tarda el modelo en hacer predicciones una vez entrenado, también puede ser sustancial en el aprendizaje profundo debido a la complejidad de los modelos. En cambio, los algoritmos tradicionales de aprendizaje automático suelen tener tiempos de entrenamiento más rápidos y tiempos de inferencia más variados.
En el aprendizaje automático, resolver un problema implica dividirlo en partes y aplicar algoritmos específicos a cada parte. Por ejemplo, reconocer objetos en una imagen puede implicar encontrar primero los objetos y luego aplicar un algoritmo para identificarlos. En el aprendizaje profundo, la red aprende a realizar ambas tareas a la vez, lo que la convierte en una solución más integrada y holística.
Los algoritmos de aprendizaje automático están muy extendidos en diversos sectores debido a su interpretabilidad. Sin embargo, el rendimiento superior de los modelos de aprendizaje profundo en determinadas tareas a veces se ve ensombrecido por su naturaleza de "caja negra", que los hace menos preferibles en situaciones en las que la interpretabilidad del modelo es crucial, como en la sanidad o las finanzas.
Mientras que el aprendizaje automático suele producir resultados en valores numéricos, puntuaciones o clasificaciones, el aprendizaje profundo puede producir una amplia gama de resultados, incluidos texto y voz, ofreciendo soluciones más versátiles en campos como el procesamiento del lenguaje natural y el reconocimiento del habla.
| Criterios | Aprendizaje Automático (AM) | Aprendizaje profundo (AD) |
|---|---|---|
| Funcionamiento | Se centra en el desarrollo de algoritmos capaces de aprender de los datos y hacer predicciones o tomar decisiones basadas en ellos. | Un subconjunto especializado del ML que emplea redes neuronales artificiales multicapa para analizar datos y tomar decisiones inteligentes. Profundiza en el análisis de datos. |
| Extracción de características | A menudo se basa en características artesanales y requiere una cuidadosa ingeniería para funcionar de forma óptima. | Extrae de forma autónoma características significativas de los datos brutos, aprendiendo progresivamente las características más útiles para la tarea. |
| Dependencia de los datos | Puede ofrecer resultados satisfactorios incluso con conjuntos de datos pequeños. | Requiere abundantes datos y funciona mejor con acceso a amplios conjuntos de datos. |
| Potencia de cálculo | A menudo pueden ejecutarse con Unidades Centrales de Proceso (CPU) estándar. | Requiere capacidades computacionales avanzadas, normalmente proporcionadas por Unidades de Procesamiento Gráfico (GPU). |
| Tiempo de entrenamiento e inferencia | Suelen tener tiempos de entrenamiento más rápidos y tiempos de inferencia más variados. | El entrenamiento puede ser extenso, extendiéndose potencialmente a meses, y el tiempo de inferencia también puede ser sustancial debido a la complejidad del modelo. |
| Técnica de resolución de problemas | Resuelve un problema dividiéndolo en partes y aplicando algoritmos específicos a cada parte. | La red aprende a realizar tareas conjuntamente, proporcionando una solución más integrada y holística. |
| Usos industriales | Ampliamente utilizados debido a su interpretabilidad. Adecuado cuando la interpretabilidad del modelo es crucial. | Rendimiento superior en determinadas tareas, pero menos preferibles cuando la interpretabilidad es crucial, debido a su naturaleza de "caja negra". |
| Salida | Suele producir resultados en valores numéricos, puntuaciones o clasificaciones. | Puede producir una amplia gama de resultados, incluidos texto y voz. |
El aprendizaje automático y el aprendizaje profundo son la columna vertebral de una miríada de aplicaciones en diversos ámbitos, cada una con sus requisitos y retos únicos. Aquí tienes un análisis más detallado de cuándo utilizar cada uno, ilustrado con ejemplos:
Cuando decidas si utilizar el Aprendizaje Automático o el Aprendizaje Profundo, ten en cuenta los siguientes aspectos:
Al comprender los puntos fuertes y las limitaciones del aprendizaje automático y el aprendizaje profundo en diferentes escenarios, los aspirantes a científicos de datos pueden tomar decisiones informadas sobre el enfoque más adecuado para sus necesidades y limitaciones específicas.
En esta guía, hemos navegado por los intrincados paisajes del aprendizaje automático (ML) y el aprendizaje profundo (DL), dos subconjuntos fundamentales de la inteligencia artificial (IA). Hemos explorado los conceptos fundamentales, las características distintivas y la miríada de aplicaciones que cada uno de ellos tiene en el mundo tecnológico actual. Desde la comprensión de los matices de los algoritmos hasta el discernimiento de los casos de uso óptimos en diversos ámbitos como la medicina y el procesamiento del lenguaje natural, nos hemos esforzado por proporcionar claridad y comprensión a los entusiastas que se adentran en el reino de la IA.
Esta exploración no es más que una ojeada al vasto y siempre cambiante mundo de la IA. El viaje de aprendizaje y descubrimiento es extenso, con innumerables matices y facetas que esperan tu exploración. Para quienes deseen profundizar y ampliar sus conocimientos, nuestro curso de habilidades de Aprendizaje Profundo en Python es un paso siguiente muy recomendable.
Más información sobre Aprendizaje Automático y Aprendizaje Profundo
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Bharath K
