Course
Introduction to Deep Learning in Python
4 hr
263.5K
Whether you’re an aspiring data scientist or simply someone with an interest in the latest developments in artificial intelligence, you’ve likely heard terms such as machine learning and deep learning. But what do they really mean? And what are the differences between them? In this post, we look at machine learning vs deep learning to determining the similarities, differences, use cases, and benefits of these two crucial disciplines.
We have a comprehensive AI Quick-Start Guide for Beginners which explores this topic in more depth. However, as a quick primer, artificial intelligence (AI) is a field of computer science that aims to create intelligent systems that can perform tasks that typically require human levels of intelligence. This can include things like recognizing natural language, recognizing patterns, and making decisions to solve complex problems.
We can think of AI as a set of tools we can use to make computers behave intelligently and automate tasks. Uses of artificial intelligence include self-driving cars, recommendation systems, and voice assistants.
As we’ll see, terms like machine learning and deep learning are facets of the wider field of machine learning. You can check out our separate guide on artificial intelligence vs machine learning for a deeper look at the topic.
As with AI, we have a dedicated guide covering what machine learning is. To summarise, machine learning (ML) is a way to implement artificial intelligence; effectively it’s a specialized branch within the expansive field of AI, which in turn is a branch of computer science.
With machine learning, we can develop algorithms that have the ability to learn without being explicitly programmed. These algorithms include:
So how do computers learn automatically?
The key is data. You provide data, characterized by various attributes or features, for the algorithms to analyze and understand. These algorithms create a decision boundary based on the provided data, allowing them to make predictions or classifications. Once the algorithm has processed and understood the data—essentially training itself—you can move to the testing phase. Here, you introduce new data points to the algorithm, and it will give you results without any further programming.Example:
Imagine you want to predict house prices. You have a dataset containing information on 1000 houses, including the price and the number of rooms—these are your features. Your task is to input these features into an algorithm, say, a decision tree algorithm, to enable it to learn the relationship between the number of rooms and the price of the house.
In this scenario, you input the number of rooms, and the algorithm predicts the house price. For instance, during the testing phase, if you input ‘three’ for the number of rooms, the algorithm should accurately predict the corresponding price of the house, having learned from the relationship between the number of rooms and house prices in the training data.
Deep learning is a sub-category of machine learning focused on structuring a learning process for computers where they can recognize patterns and make decisions, much like humans do. For instance, if we are teaching a computer to distinguish between different animals, we start with simpler, foundational concepts like the number of legs and gradually introduce more complex ones like habitats and behaviors.
In the realm of machine learning, deep learning is distinguished by the use of neural networks with three or more layers. These multi-layered neural networks strive to replicate the learning patterns of the human brain, enabling the computer to analyze and learn from vast volumes of data. A single-layered network can make rudimentary predictions, but as we add more layers, the network becomes capable of understanding intricate patterns and relationships, enhancing its predictive accuracy.
Deep learning is essentially a type of sophisticated, multi-layered filter. We input raw, unorganized data at the top, and it traverses through various layers of the neural network, getting refined and analyzed at each level. Eventually, what emerges at the bottom is a coherent, structured piece of information or a precise ‘prediction.’
This process excels in deciphering data with multiple abstraction levels, making it indispensable for tasks like image and speech recognition, natural language processing, and devising game strategies. It’s the backbone of many innovations, from the virtual assistants on our phones to the development of autonomous vehicles.
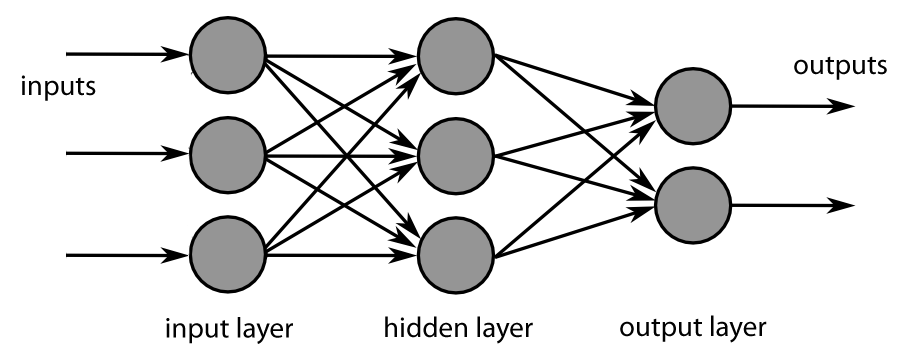
As you can see from the above figure, this shallow neural network has several layers:
So, the neural network is an approximation function in which the network tries to learn the parameters (weights) in hidden layers, which when multiplied with the input, gives you a predicted output close to the desired output.
Deep learning is the stacking of multiple such hidden layers between the input and the output layer, hence the name deep learning.
As we’ve established, deep learning is a specialized subset of machine learning which employs artificial neural networks with multiple layers to analyze data and make intelligent decisions. It delves deeper into data analysis, hence the term "deep," allowing for more nuanced and sophisticated insights. In contrast, machine learning, which encompasses deep learning, focuses on developing algorithms capable of learning from and making predictions or decisions based on data, utilizing a variety of methods including, but not limited to, neural networks.
Deep Learning autonomously extracts meaningful features from raw data. A “feature” in this context is an individual measurable property or characteristic of the phenomenon being observed. Deep Learning does not depend on manually programmed feature extraction methods, such as local binary patterns or histograms of gradients, which are predefined ways to summarize the raw data. Instead, it learns the most useful features for accomplishing the task at hand, starting with simple ones and progressively learning more complex representations. Traditional Machine Learning, on the other hand, often relies on these hand-crafted features and requires careful engineering to perform optimally.

Deep learning models are data-hungry; they perform better with access to abundant data. In contrast, many machine learning algorithms can deliver satisfactory results even with smaller datasets. This is crucial for aspiring data scientists to consider when choosing between methodologies, especially when dealing with limitations in data availability.
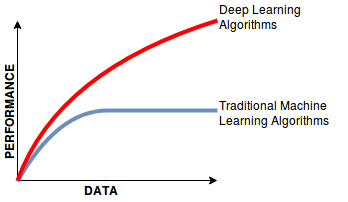
From the above figure, you can see that as the data increases, the performance of deep learning algorithms increases compared to traditional machine learning algorithm, in which the performance almost saturates after a while even if the data is increased.
Deep learning requires advanced computational capabilities, typically provided by Graphical Processing Units (GPUs), due to its extensive data and depth (number of layers in neural networks). Traditional machine learning algorithms can often be executed with standard Central Processing Units (CPUs), making them more accessible for beginners in data science.
Training a deep learning network can be extensive, potentially extending to months. “Training” refers to the process of teaching the model to make accurate predictions by feeding it data. The “inference time,” or the time it takes for the model to make predictions once it’s trained, can also be substantial in deep learning due to the complexity of the models. In contrast, traditional machine learning algorithms usually have faster training times and varied inference times.
In machine learning, solving a problem involves breaking it down into parts and applying specific algorithms to each part. For instance, recognizing objects in an image might involve finding the objects first and then applying an algorithm to identify them. In deep learning, the network learns to perform both tasks together, making it a more integrated and holistic solution.
Machine learning algorithms are widely deployed in various industries due to their interpretability. However, the superior performance of deep learning models in certain tasks is sometimes overshadowed by their “black box” nature, making them less preferable in situations where model interpretability is crucial, such as in healthcare or finance.
While machine learning typically yields outputs in numerical values, scores, or classifications, deep learning can produce a diverse range of outputs including text and speech, offering more versatile solutions in fields like natural language processing and speech recognition.
| Criteria | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|
| Functioning | Focuses on developing algorithms capable of learning from and making predictions or decisions based on data. | A specialized subset of ML that employs multi-layered artificial neural networks to analyze data and make intelligent decisions. It delves deeper into data analysis. |
| Feature Extraction | Often relies on hand-crafted features and requires careful engineering to perform optimally. | Autonomously extracts meaningful features from raw data, learning the most useful features for the task progressively. |
| Data Dependency | Can deliver satisfactory results even with smaller datasets. | Requires abundant data and performs better with access to extensive datasets. |
| Computation Power | Can often be executed with standard Central Processing Units (CPUs). | Requires advanced computational capabilities, typically provided by Graphical Processing Units (GPUs). |
| Training and Inference Time | Usually have faster training times and varied inference times. | Training can be extensive, potentially extending to months, and inference time can also be substantial due to model complexity. |
| Problem-solving Technique | Solves a problem by breaking it down into parts and applying specific algorithms to each part. | The network learns to perform tasks together, providing a more integrated and holistic solution. |
| Industry Uses | Widely deployed due to their interpretability. Suitable where model interpretability is crucial. | Superior performance in certain tasks but less preferable where interpretability is crucial due to their “black box” nature. |
| Output | Typically yields outputs in numerical values, scores, or classifications. | Can produce a diverse range of outputs including text and speech. |
Machine learning and deep learning serve as the backbone of a myriad of applications across diverse domains, each having its unique requirements and challenges. Here’s a more detailed exploration of when to use each, illustrated with examples:
When deciding whether to use Machine Learning or Deep Learning, consider the following aspects:
By understanding the strengths and limitations of machine learning and deep learning in different scenarios, aspiring data scientists can make informed decisions on the most suitable approach for their specific needs and constraints.
In this guide, we’ve navigated the intricate landscapes of machine learning (ML) and deep lLearning (DL), two pivotal subsets of artificial intelligence (AI). We’ve explored the foundational concepts, the distinctive characteristics, and the myriad of applications each holds in today’s technologically driven world. From understanding the nuances of algorithms to discerning the optimal use cases across various domains like medicine and natural language processing, we’ve endeavored to provide clarity and insight for enthusiasts stepping into the realm of AI.
This exploration is merely a glimpse into the vast and ever-evolving world of AI. The journey of learning and discovery is extensive, with countless nuances and facets awaiting your exploration. For those eager to delve deeper and expand their knowledge, our Deep Learning in Python skill track is a highly recommended next step.
Learn more about Machine Learning and Deep Learning
Course
Course
Course
blog
Matt Crabtree
10 min
blog
Richie Cotton
5 min
blog
Javier Canales Luna
7 min
blog
Kurtis Pykes
12 min
Tutorial
Abid Ali Awan
Tutorial
Bharath K



