¿Qué es el Aprendizaje Profundo?
El aprendizaje profundo es un tipo de aprendizaje automático que enseña a los ordenadores a realizar tareas aprendiendo a partir de ejemplos, de forma muy parecida a como lo hacen los humanos. Imagina que enseñas a un ordenador a reconocer gatos: en lugar de decirle que busque bigotes, orejas y cola, le enseñas miles de fotos de gatos. El ordenador encuentra por sí mismo los patrones comunes y aprende a identificar a un gato. Esta es la esencia del aprendizaje profundo.
En términos técnicos, el aprendizaje profundo utiliza algo llamado "redes neuronales", que se inspiran en el cerebro humano. Estas redes están formadas por capas de nodos interconectados que procesan la información. Cuantas más capas, más "profunda" es la red, lo que le permite aprender características más complejas y realizar tareas más sofisticadas.
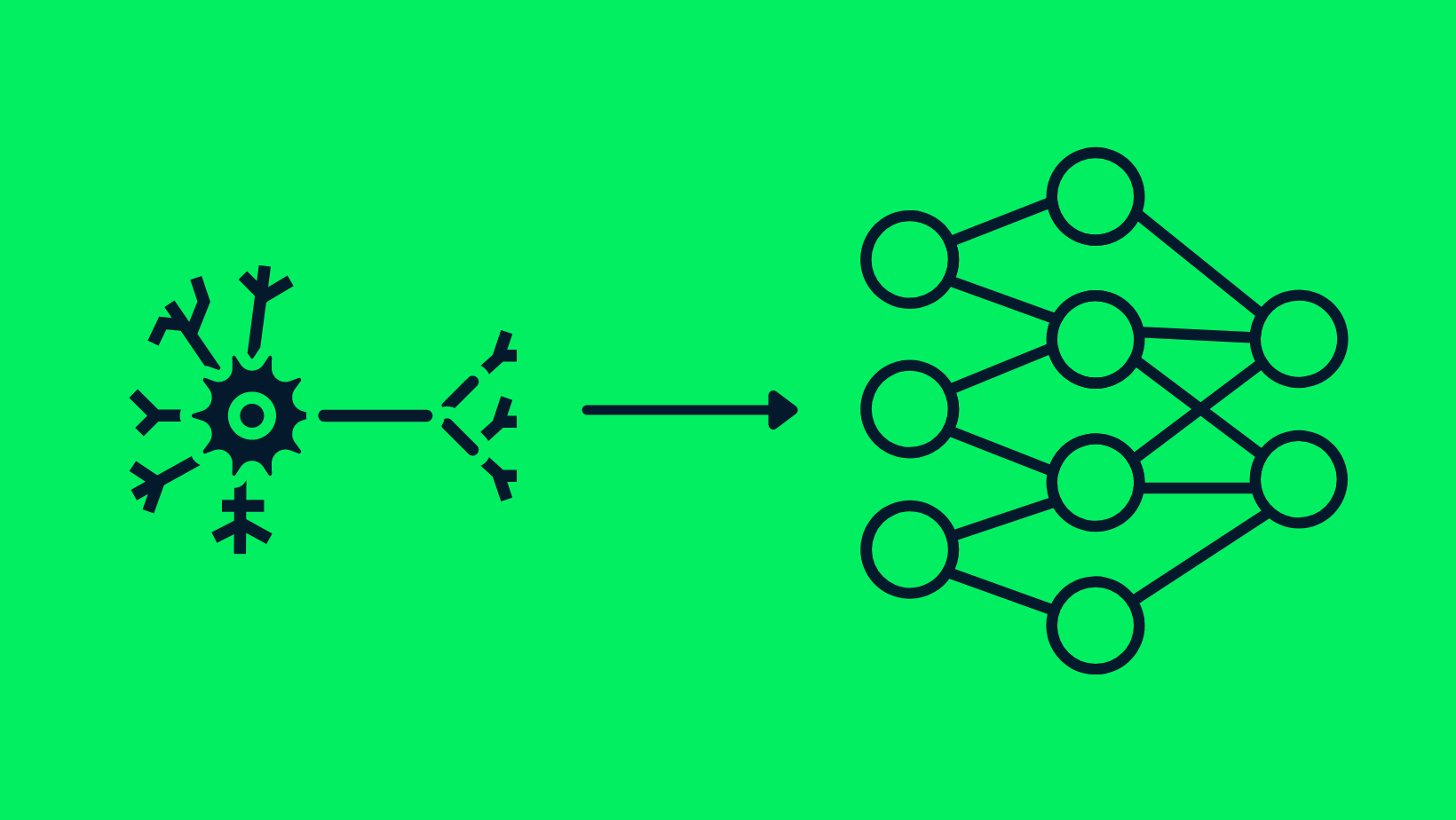
La similitud entre neuronas y redes neuronales
La evolución del aprendizaje automático al aprendizaje profundo
¿Qué es el aprendizaje automático?
El aprendizaje automático es en sí mismo un subconjunto de la inteligencia artificial (IA) que permite a los ordenadores aprender de los datos y tomar decisiones sin programación explícita. Abarca diversas técnicas y algoritmos que permiten a los sistemas reconocer patrones, hacer predicciones y mejorar el rendimiento a lo largo del tiempo. Puedes explorar la diferencia entre aprendizaje automático e IA en otro artículo.
En qué se diferencia el aprendizaje profundo del aprendizaje automático tradicional
Aunque el aprendizaje automático ha sido una tecnología transformadora por derecho propio, el aprendizaje profundo lo lleva un paso más allá automatizando muchas de las tareas que normalmente requieren experiencia humana.
El aprendizaje profundo es esencialmente un subconjunto especializado del aprendizaje automático, que se distingue por el uso de redes neuronales con tres o más capas. Estas redes neuronales intentan simular el comportamiento del cerebro humano -aunque están lejos de igualar su capacidad- para "aprender" a partir de grandes cantidades de datos. Puedes explorar el aprendizaje automático frente al aprendizaje profundo con más detalle en otro post.
La importancia de la ingeniería de características
La ingeniería de características es el proceso de seleccionar, transformar o crear las variables más relevantes, conocidas como "características", a partir de datos brutos para utilizarlas en modelos de aprendizaje automático.
Por ejemplo, si estás construyendo un modelo de predicción meteorológica, los datos brutos pueden incluir la temperatura, la humedad, la velocidad del viento y la presión barométrica. La ingeniería de características implicaría determinar cuáles de estas variables son más importantes para predecir el tiempo y, posiblemente, transformarlas (por ejemplo, convertir la temperatura de Fahrenheit a Celsius) para que sean más útiles para el modelo.
En el aprendizaje automático tradicional, la ingeniería de características suele ser un proceso manual que requiere mucho tiempo y conocimientos especializados. Sin embargo, una de las ventajas del aprendizaje profundo es que puede aprender automáticamente características relevantes a partir de los datos brutos, reduciendo la necesidad de intervención manual.
¿Por qué es importante el aprendizaje profundo?
Las razones por las que el aprendizaje profundo se ha convertido en el estándar de la industria:
- Tratamiento de datos no estructurados: Los modelos entrenados en datos estructurados pueden aprender fácilmente de los datos no estructurados, lo que reduce el tiempo y los recursos necesarios para normalizar los conjuntos de datos.
- Manejo de grandes datos: Gracias a la introducción de las unidades de procesamiento gráfico (GPU), los modelos de aprendizaje profundo pueden procesar grandes cantidades de datos a la velocidad del rayo.
- Alta precisión: Los modelos de aprendizaje profundo proporcionan los resultados más precisos en visiones por ordenador, procesamiento del lenguaje natural (PLN) y procesamiento de audio.
- Reconocimiento de patrones: La mayoría de los modelos requieren la intervención de ingenieros de aprendizaje automático, pero los modelos de aprendizaje profundo pueden detectar todo tipo de patrones automáticamente.
En este tutorial, vamos a sumergirnos en el mundo del aprendizaje profundo y a descubrir todos los conceptos clave necesarios para que puedas iniciar una carrera en inteligencia artificial (IA). Si quieres aprender con algunos ejercicios prácticos, consulta nuestro curso Introducción al Aprendizaje Profundo en Python.
Conceptos básicos del aprendizaje profundo
Antes de sumergirnos en las complejidades de los algoritmos de aprendizaje profundo y sus aplicaciones, es esencial comprender los conceptos fundamentales que hacen que esta tecnología sea tan revolucionaria. Esta sección te presentará los componentes básicos del aprendizaje profundo: redes neuronales, redes neuronales profundas y funciones de activación.
Redes neuronales
En el corazón del aprendizaje profundo están las redes neuronales, que son modelos computacionales inspirados en el cerebro humano. Estas redes están formadas por nodos interconectados, o "neuronas", que trabajan juntas para procesar la información y tomar decisiones. Al igual que nuestro cerebro tiene diferentes regiones para diferentes tareas, una red neuronal tiene capas designadas para funciones específicas.
Tenemos una guía completa, Qué son las redes neuronales, que cubre lo esencial con más detalle.
Redes neuronales profundas
Lo que hace que una red neuronal sea "profunda" es el número de capas que tiene entre la entrada y la salida. Una red neuronal profunda tiene múltiples capas, lo que le permite aprender características más complejas y hacer predicciones más precisas. La "profundidad" de estas redes es lo que da nombre al aprendizaje profundo y su poder para resolver problemas intrincados.
Nuestro tutorial de introducción a las redes neuronales profundas cubre la importancia de las DNN en el aprendizaje profundo y la inteligencia artificial.
Funciones de activación
En una red neuronal, las funciones de activación son como los que toman las decisiones. Determinan qué información debe transmitirse a la siguiente capa. Estas funciones añaden un nivel de complejidad, permitiendo a la red aprender de los datos y tomar decisiones matizadas.
Cómo funciona el aprendizaje profundo
El aprendizaje profundo utiliza la extracción de características para reconocer características similares de la misma etiqueta y luego utiliza límites de decisión para determinar qué características representan con precisión cada etiqueta. En la clasificación de gatos y perros, los modelos de aprendizaje profundo extraerán información como los ojos, la cara y la forma del cuerpo de los animales y los dividirán en dos clases.
El modelo de aprendizaje profundo consiste en redes neuronales profundas. La red neuronal simple consta de una capa de entrada, una capa oculta y una capa de salida. Los modelos de aprendizaje profundo constan de varias capas ocultas, con capas adicionales que la precisión del modelo ha mejorado.
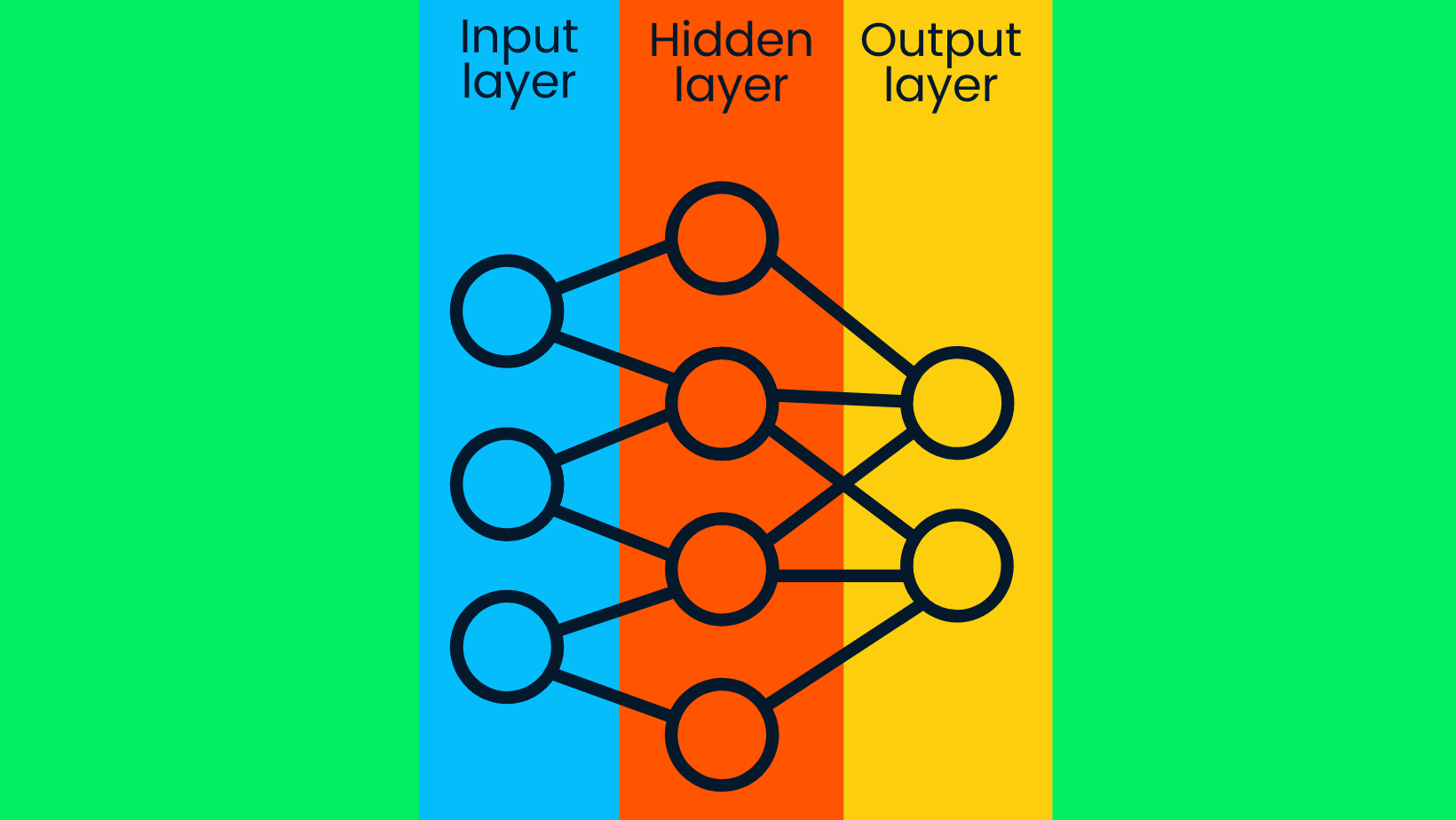 Red neuronal simple
Red neuronal simple
Las capas de entrada contienen datos brutos, y transfieren los datos a los nodos de las capas ocultas. Los nodos de las capas ocultas clasifican los puntos de datos basándose en la información objetivo más amplia, y con cada capa posterior, el alcance del valor objetivo se estrecha para producir suposiciones precisas. La capa de salida utiliza la información de la capa oculta para seleccionar la etiqueta más probable. En nuestro caso, predecir con precisión la imagen de un perro en lugar de la de un gato.
Inteligencia Artificial vs. Aprendizaje profundo
Vamos a responder a una de las preguntas más frecuentes en Internet: "¿Es el aprendizaje profundo inteligencia artificial?". La respuesta corta es sí. El aprendizaje profundo es un subconjunto del aprendizaje automático, y el aprendizaje automático es un subconjunto de la IA.
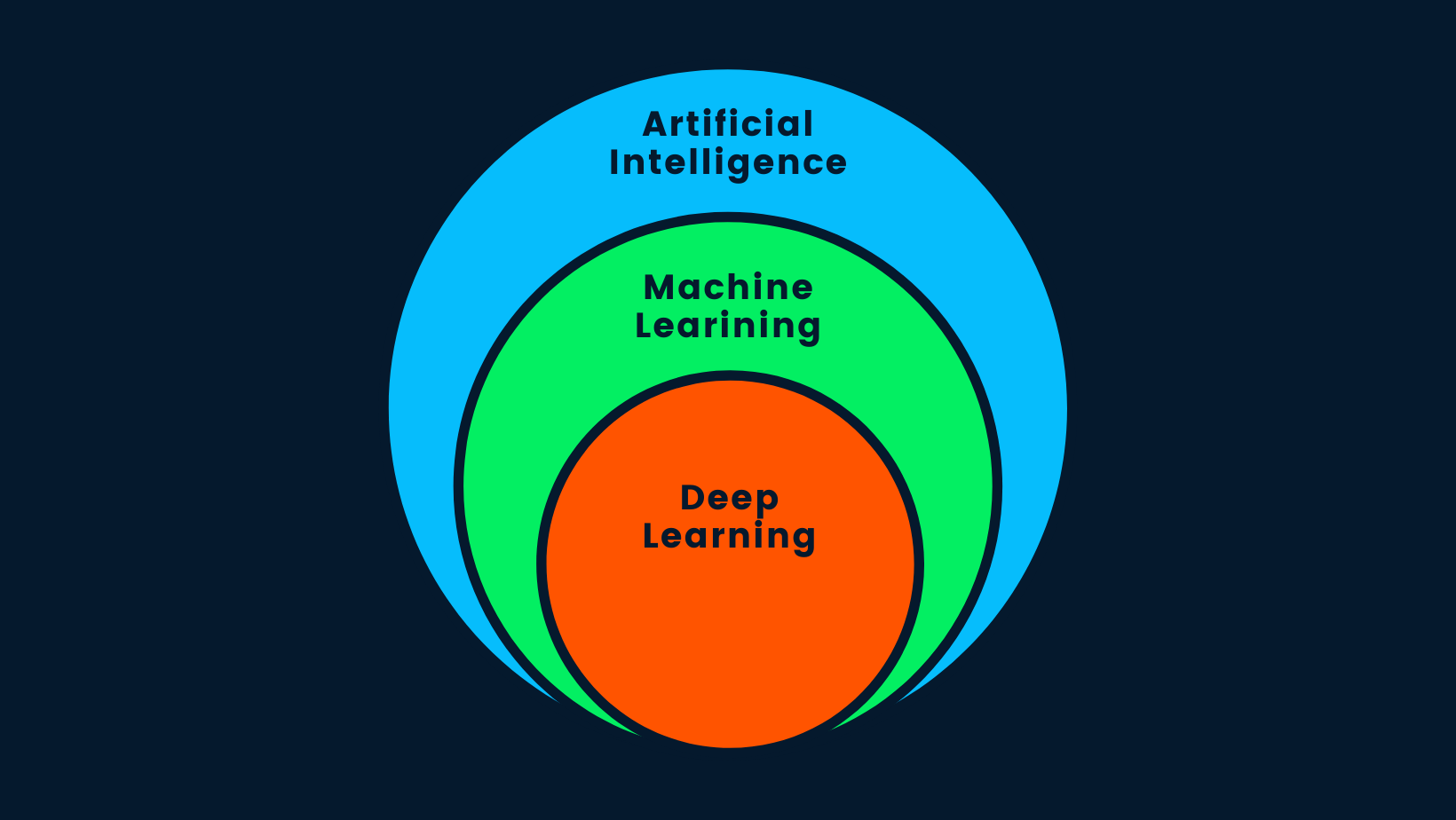 IA IA vs ML vs. DL
IA IA vs ML vs. DL
La inteligencia artificial es el concepto de que se pueden construir máquinas inteligentes que imiten el comportamiento humano o superen la inteligencia humana. La IA utiliza métodos de aprendizaje automático y aprendizaje profundo para realizar tareas humanas. En resumen, la IA es aprendizaje profundo, ya que es el algoritmo más avanzado capaz de tomar decisiones inteligentes.
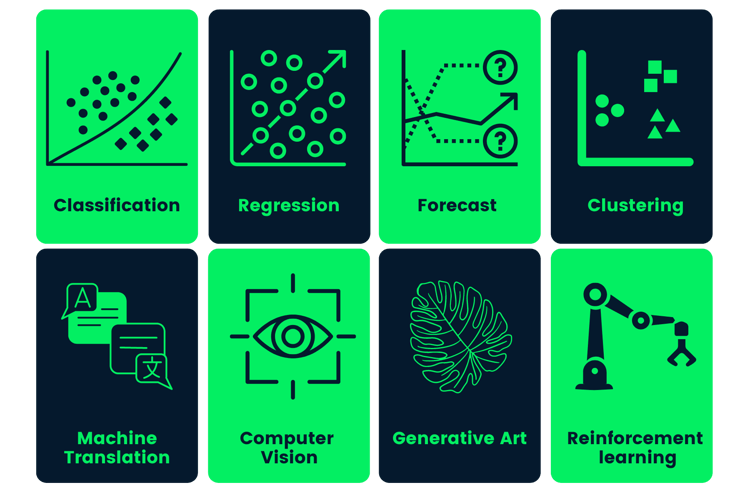
¿Para qué se utiliza el aprendizaje profundo?
Recientemente, el mundo de la tecnología ha visto un aumento de las aplicaciones de inteligencia artificial, y todas ellas están impulsadas por modelos de aprendizaje profundo. Las aplicaciones van desde la recomendación de películas en Netflix a los sistemas de gestión de almacenes de Amazon.
En esta sección, vamos a conocer algunas de las aplicaciones más famosas construidas utilizando el aprendizaje profundo. Esto te ayudará a aprovechar todo el potencial de las redes neuronales profundas.
Visión por ordenador
La visión por ordenador (VC) se utiliza en los coches autoconducidos para detectar objetos y evitar colisiones. También se utiliza para el reconocimiento facial, la estimación de la pose, la clasificación de imágenes y la detección de anomalías.
 Reconocimiento facial
Reconocimiento facial
Reconocimiento automático del habla
El reconocimiento automático del habla (ASR) es utilizado por miles de millones de personas en todo el mundo. Está en nuestros teléfonos y se activa habitualmente diciendo "Oye, Google" o "Hola, Siri". Estas aplicaciones de audio también se utilizan para la conversión de texto a voz, la clasificación de audio y la detección de actividades vocales.
 Reconocimiento de patrones del habla
Reconocimiento de patrones del habla
IA Generativa
La IA Generativa ha experimentado un aumento de la demanda, ya que CryptoPunk NFT acaba de venderse por 1 millón de dólares. CryptoPunk es una colección de arte generativo que se creó utilizando modelos de aprendizaje profundo. La introducción del modelo GPT-4 por OpenAI ha revolucionado el ámbito de la generación de textos con su potente herramienta ChatGPT; ahora, puedes enseñar a los modelos a escribir una novela entera o incluso a escribir código para tus proyectos de ciencia de datos.
 Arte Generativo
Arte Generativo
Traducción
La traducción con aprendizaje profundo no se limita a la traducción de idiomas, ya que ahora podemos traducir fotos a texto utilizando OCR, o traducir texto a imágenes utilizando NVIDIA GauGAN2.
 Traducción de idiomas
Traducción de idiomas
Previsión de series temporales
La previsión de series temporales se utiliza para predecir las caídas del mercado, los precios de las acciones y los cambios en el tiempo. El sector financiero sobrevive gracias a la especulación y a las proyecciones de futuro. El aprendizaje profundo y los modelos de series temporales son mejores que los humanos para detectar patrones, por lo que son herramientas fundamentales en este sector y en otros similares.
 Previsión de series temporales
Previsión de series temporales
Automatización
El aprendizaje profundo se utiliza para automatizar tareas, por ejemplo, entrenar robots para la gestión de almacenes. La aplicación más popular es jugar a videojuegos y mejorar resolviendo rompecabezas. Recientemente, la IA de Dota de OpenAI venció al equipo profesional OG, lo que conmocionó al mundo, ya que la gente no esperaba que los cinco bots superaran a los campeones del mundo.
 Brazo robótico impulsado por el aprendizaje por refuerzo
Brazo robótico impulsado por el aprendizaje por refuerzo
Comentarios de los clientes
El aprendizaje profundo se utiliza para gestionar las opiniones y reclamaciones de los clientes. Se utiliza en todas las aplicaciones de chatbot para proporcionar servicios de atención al cliente sin fisuras.
 Opinión del cliente
Opinión del cliente
Biomedical
Este campo es el que más se ha beneficiado con la introducción del aprendizaje profundo. El DL se utiliza en biomedicina para detectar el cáncer, construir medicamentos estables, para la detección de anomalías en las radiografías de tórax y para ayudar a los equipos médicos.
 Analizar secuencias de ADN
Analizar secuencias de ADN
Modelos de aprendizaje profundo
Conozcamos los distintos tipos de modelos de aprendizaje profundo y cómo funcionan.
Aprendizaje supervisado
El aprendizaje supervisado utiliza un conjunto de datos etiquetados para entrenar modelos que clasifiquen datos o predigan valores. El conjunto de datos contiene características y etiquetas objetivo, que permiten al algoritmo aprender con el tiempo minimizando la pérdida entre las etiquetas previstas y las reales. El aprendizaje supervisado puede dividirse en problemas de clasificación y de regresión.
Clasificación
El algoritmo de clasificación divide el conjunto de datos en varias categorías basándose en las extracciones de características. Los modelos populares de aprendizaje profundo son ResNet50 para la clasificación de imágenes y BERT (modelo de lenguaje)) para la clasificación de textos.
 Clasificación
Clasificación
Regresión
En lugar de dividir el conjunto de datos en categorías, el modelo de regresión aprende la relación entre las variables de entrada y salida para predecir el resultado. Los modelos de regresión se utilizan habitualmente para el análisis predictivo, la previsión meteorológica y la predicción del rendimiento del mercado bursátil. LSTM y RNN son modelos populares de regresión de aprendizaje profundo.
 Regresión lineal
Regresión lineal
Aprendizaje no supervisado
Los algoritmos de aprendizaje no supervisado aprenden el patrón dentro de un conjunto de datos sin etiquetar y crean clusters. Los modelos de aprendizaje profundo pueden aprender patrones ocultos sin intervención humana y estos modelos se utilizan a menudo en motores de recomendación.
El aprendizaje no supervisado se utiliza para agrupar diversas especies, imágenes médicas e investigación de mercados. El modelo de aprendizaje profundo más común para la agrupación es el algoritmo de agrupación profunda incrustada.
 Agrupación de datos
Agrupación de datos
Aprendizaje por Refuerzo
El aprendizaje por refuerzo (RL) es un método de aprendizaje automático en el que los agentes aprenden diversos comportamientos del entorno. Este agente realiza acciones aleatorias y obtiene recompensas. El agente aprende a conseguir objetivos por ensayo y error en un entorno complejo sin intervención humana.
Igual que un bebé con el estímulo de sus padres aprende a andar, la IA aprende a realizar determinadas tareas maximizando las recompensas, y el diseñador establece la política de recompensas. Recientemente, la RL ha visto grandes demandas en automatización debido a los avances en robótica, coches autoconducidos, derrotar a jugadores profesionales en juegos y aterrizar cohetes de vuelta a la tierra.
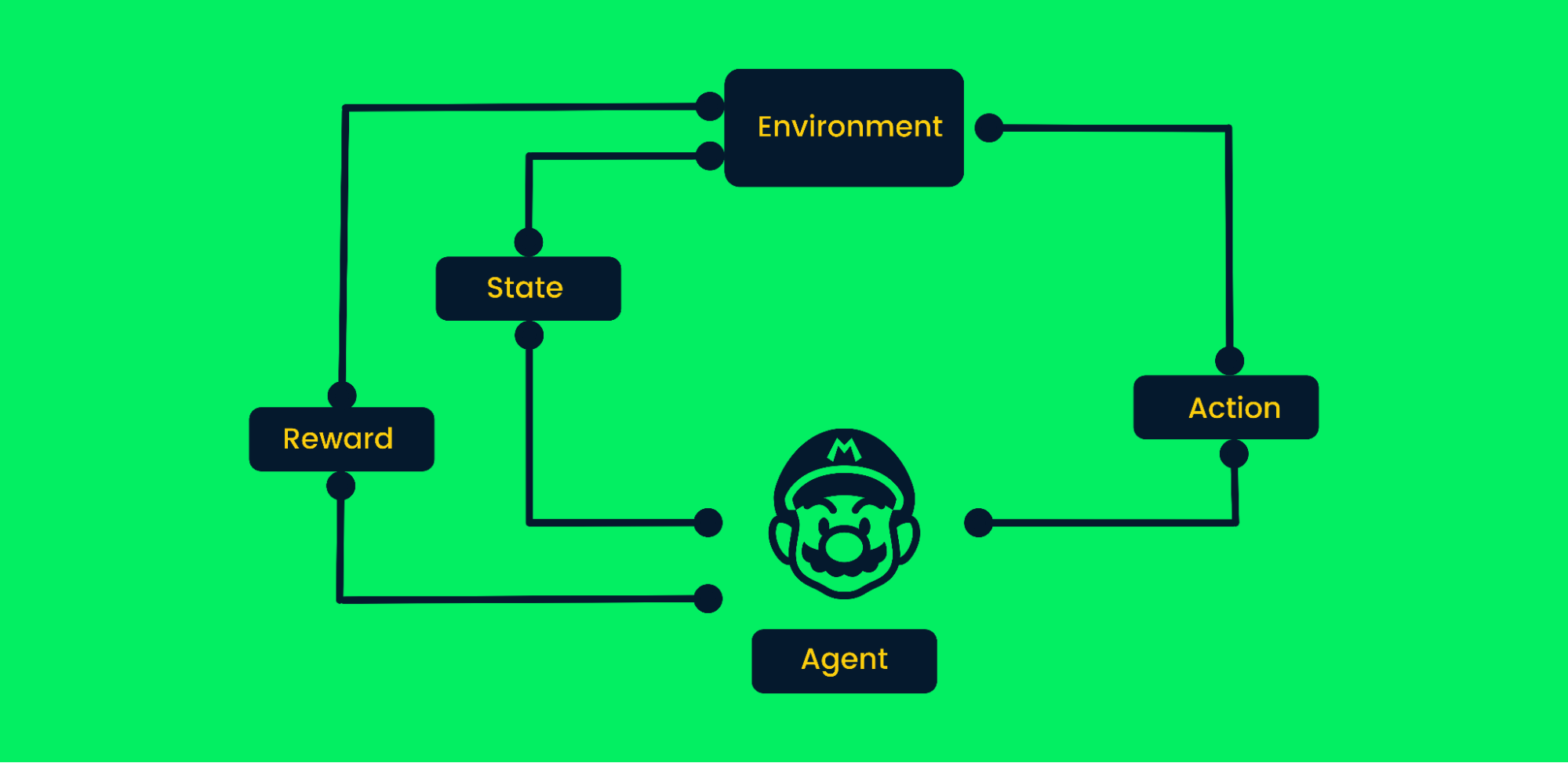 Marco de aprendizaje por refuerzo
Marco de aprendizaje por refuerzo
Tomemos como ejemplo el videojuego Mario:
- Al principio, el agente (personaje Mario) recibe el estado cero del entorno.
- En función del estado, un agente realizará una acción, en nuestro caso, Mario se movió hacia la derecha.
- Ahora el estado ha cambiado, y el personaje se encuentra en un nuevo fotograma.
- El agente recibe una recompensa, ya que al moverse hacia la derecha el personaje no está muerto. Nuestro principal objetivo es maximizar las recompensas.
El agente continuará el bucle de realizar acciones y maximizar las recompensas hasta que llegue al final de la etapa o muera. Más información en Introducción al aprendizaje por refuerzo.
Redes Generativas Adversariales
Las redes generativas adversariales (GAN) utilizan dos redes neuronales y, juntas, producen instancias sintéticas de los datos originales. Los GAN han ganado mucha popularidad en los últimos años, ya que son capaces de imitar a algunos de los grandes artistas para producir obras maestras. Se utilizan mucho para generar arte sintético, vídeo, música y textos. Obtén más información sobre aplicaciones reales de trabajo en Tutorial de Redes Generativas Adversariales.
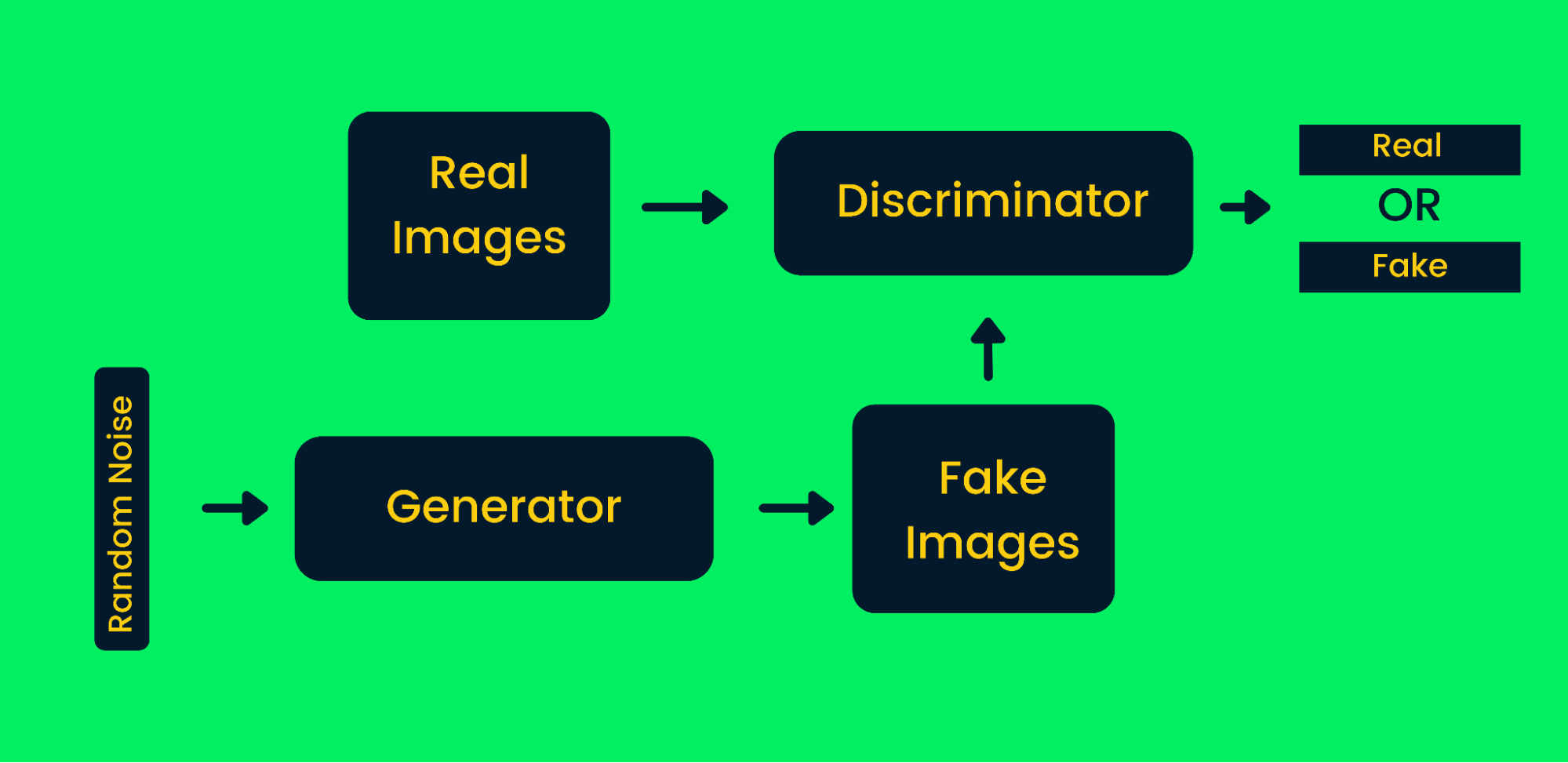 Marco de la Red Generativa Adversarial
Marco de la Red Generativa Adversarial
Cómo funcionan las GAN en la generación de imágenes sintéticas:
- En primer lugar, las redes generadoras toman la entrada de ruido aleatorio y generan imágenes falsas.
- Las imágenes generadas y las reales se introducen en el discriminador.
- El discriminador decide si la imagen generada es real o no. Devuelve probabilidades de cero a uno, donde cero representa una imagen falsa y uno representa una imagen auténtica. La arquitectura de las GAN contiene dos bucles de retroalimentación. El discriminador está en un bucle de realimentación con imágenes reales, mientras que el generador está en un bucle de realimentación con un discriminador. Trabajan en sincronía para producir imágenes más auténticas.
Red neuronal gráfica
Un grafo es una estructura de datos formada por aristas y vértices. Las aristas pueden ser dirigidas si existen dependencias direccionales entre los vértices(nodos), lo que también se conoce como grafos dirigidos. Los círculos verdes del diagrama siguiente son nodos, y las flechas representan las aristas.
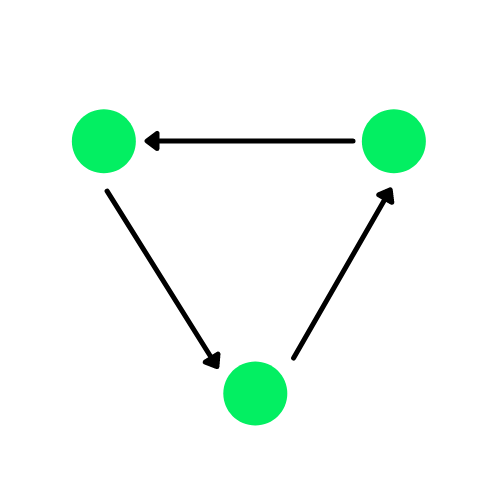
Un grafo dirigido
Una red neuronal gráfica (GNN) es un tipo de arquitectura de aprendizaje profundo que opera directamente sobre estructuras gráficas. Las GNN se aplican en análisis de grandes conjuntos de datos, sistemas de recomendación y visiones informáticas.
 Una red gráfica
Una red gráfica
También se utilizan para la clasificación de nodos, la predicción de enlaces y la agrupación. En algunos casos, las redes neuronales gráficas han obtenido mejores resultados que las redes neuronales de convolución, por ejemplo al reconocer objetos y predecir relaciones semánticas.
Procesamiento del Lenguaje Natural
El procesamiento del lenguaje natural (PLN) utiliza tecnología de aprendizaje profundo para ayudar a los ordenadores a aprender un lenguaje humano natural. La PNL utiliza el aprendizaje profundo para leer, descifrar y comprender el lenguaje humano. Se utiliza ampliamente para procesar voz, texto e imágenes. La introducción del aprendizaje por transferencia ha llevado la PNL al siguiente nivel, ya que podemos afinar el modelo con unas pocas muestras y conseguir un rendimiento de vanguardia.
 Subcategorías de la PNL
Subcategorías de la PNL
La PNL puede dividirse en múltiples campos:
- Traducción: traducir idiomas, estructura molecular y ecuaciones matemáticas
- Resumir: resumir grandes trozos de texto en unas pocas líneas manteniendo la información clave.
- Clasificación: dividir el texto en varias categorías.
- Generación: generación de texto a texto; puede utilizarse para generar redacciones enteras con una sola línea de texto.
- Conversacional: Asistente virtual, que retiene el conocimiento pasado de la conversación e imita las conversaciones humanas.
- Responder a las preguntas: La IA responde a las preguntas utilizando datos de preguntas y respuestas.
- Extracción de características: para detectar patrones en el texto o extraer información, como el "reconocimiento de entidad de nombre" y la "parte de voz".
- Semejanzas oracionales: evaluar las semejanzas entre varios textos.
- Texto a voz: convertir texto en voz audible.
- Reconocimiento automático del habla: comprender varios sonidos y convertirlos en texto.
- Reconocimiento óptico de caracteres: extracción de datos de texto a partir de imágenes.
Si quieres probar las distintas aplicaciones de la PNL, prueba los Espacios de Caras Abrazadas. Los Spaces albergan todo tipo de aplicaciones web con las que puedes jugar para inspirarte en tu proyecto de PNL.
Una mirada más profunda a los conceptos del aprendizaje profundo
Funciones de activación
En las redes neuronales, la función de activación produce límites de decisión de salida y se utiliza para mejorar el rendimiento del modelo. La función de activación es una expresión matemática que decide si la entrada debe pasar o no por una neurona en función de su significado. También proporciona no linealidad a las redes. Sin función de activación, la red neuronal se convierte en un simple modelo de regresión lineal.
Existen varios tipos de funciones de activación:
- Tanh
- ReLU
- Sigmoide
- Lineal
- Softmax
- Swish
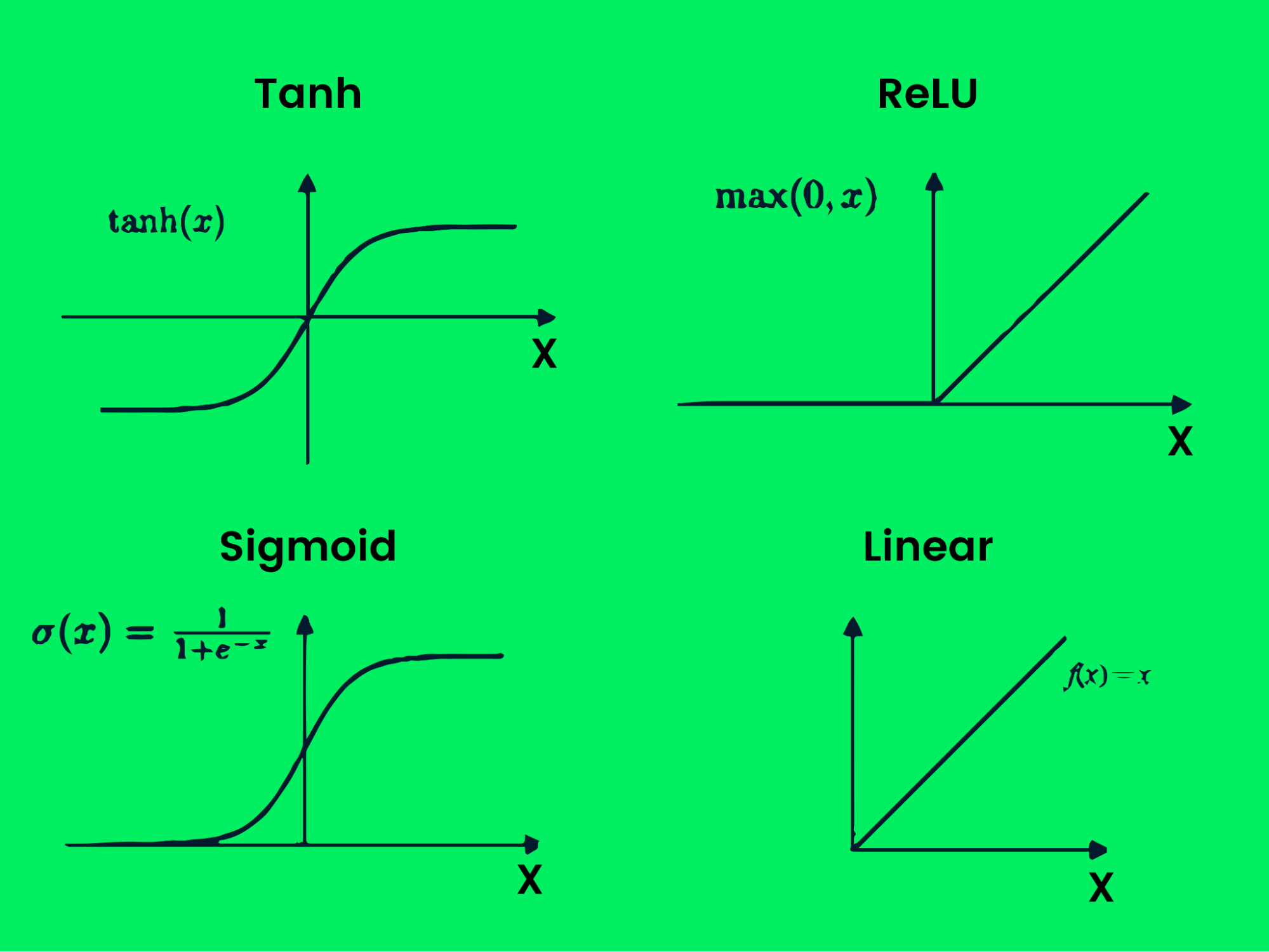 Función de activación
Función de activación
Estas funciones producen varios límites de salida, como se muestra en la imagen anterior. Con múltiples capas y funciones de activación, puedes resolver cualquier problema complejo. Más información sobre ¿qué son las funciones de activación en el aprendizaje profundo?
Función de pérdida
La función de pérdida es la diferencia entre los valores reales y los predichos. Permite a las redes neuronales seguir el rendimiento general del modelo. En función de problemas concretos, elegimos un determinado tipo de función, por ejemplo, el error cuadrático medio.
Pérdida = Suma (Prevista - Real)²
Las funciones de pérdida más utilizadas en el aprendizaje profundo son:
- Entropía cruzada binaria
- Bisagra categórica
- Error cuadrático medio
- Huber
- Entropía cruzada categórica dispersa
Retropropagación
En la propagación de avance, inicializamos nuestra red neuronal con entradas aleatorias para producir una salida también aleatoria. Para que nuestro modelo funcione mejor, ajustamos los pesos aleatoriamente mediante retropropagación. Para seguir el rendimiento del modelo, necesitamos una función de pérdida que encuentre mínimos globales para maximizar la precisión del modelo.
Descenso Gradiente Estocástico
El descenso gradiente se utiliza para optimizar la función de pérdida cambiando los pesos de forma controlada para conseguir la pérdida mínima. Ahora tenemos un objetivo, pero necesitamos orientación sobre si aumentar o disminuir los pesos para conseguir un mejor rendimiento. La derivada de la función de pérdida nos dará la dirección y podremos utilizarla para actualizar los pesos de la red.
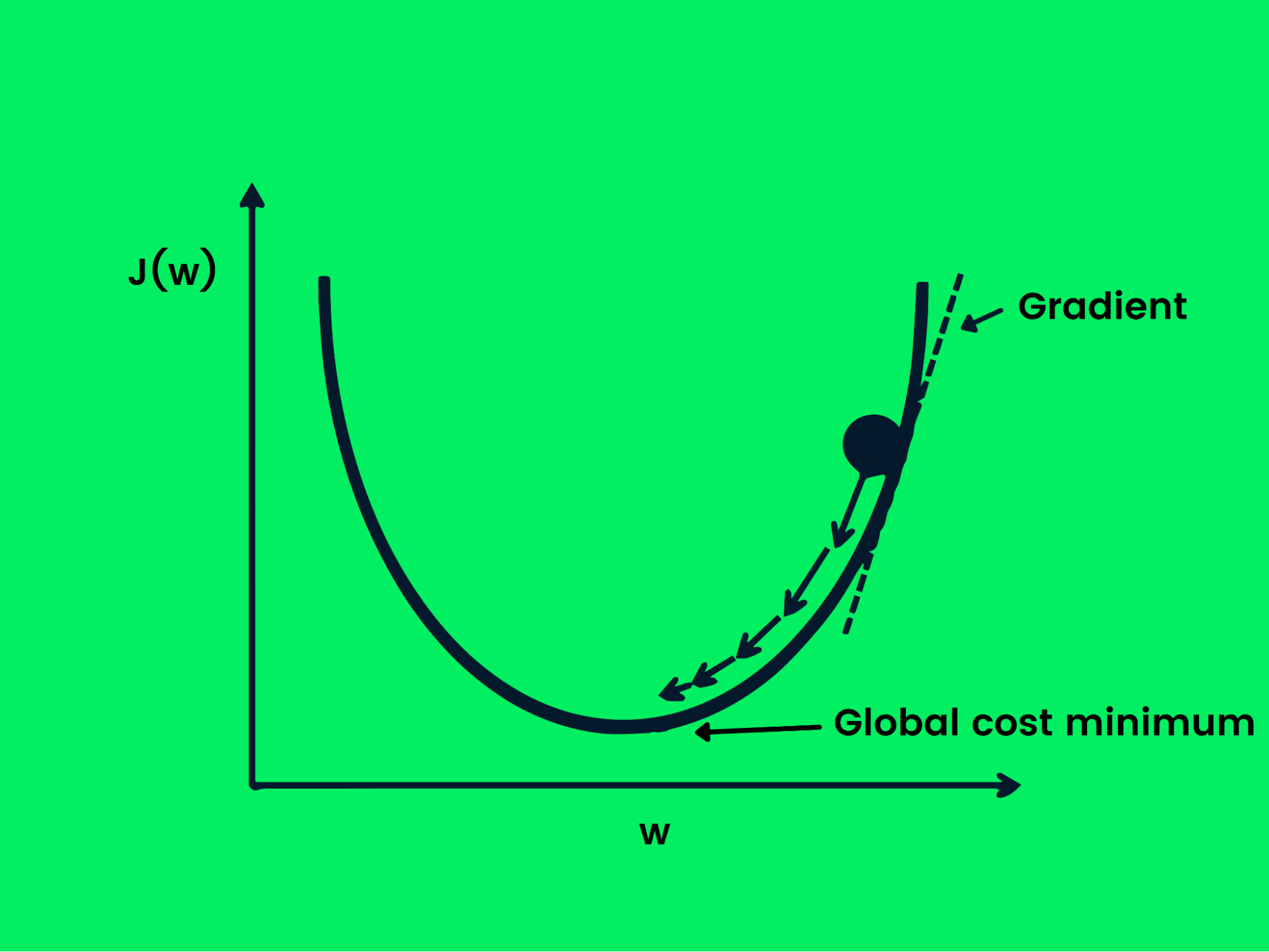 Descenso Gradiente
Descenso Gradiente
La ecuación siguiente muestra cómo se actualizan los pesos mediante el descenso gradiente.
w = w -Jw
En el descenso de gradiente estocástico, las muestras se dividen en lotes en lugar de utilizar todo el conjunto de datos para optimizar el descenso de gradiente. Esto es útil si quieres conseguir una pérdida mínima más rápidamente y optimizar la potencia de cálculo.
Hiperparámetro
Los hiperparámetros son los parámetros sintonizables que se ajustan antes de ejecutar el proceso de entrenamiento. Estos parámetros afectan directamente al rendimiento del modelo y te ayudan a alcanzar más rápidamente los mínimos globales.
Lista de los hiperparámetros más utilizados:
- Tasa de aprendizaje: tamaño del paso de cada iteración y puede ajustarse de 0,1 a 0,0001. En pocas palabras, determina la velocidad a la que aprende el modelo.
- Tamaño del lote: número de muestras que pasan a la vez por una red neuronal.
- Número de épocas: una iteración de cuántas veces el modelo cambia los pesos. Demasiadas épocas pueden hacer que los modelos se sobreajusten y muy pocas pueden hacer que los modelos se infraajusten, así que tenemos que elegir un número medio.
Aprende más sobre cómo funcionan juntos estos componentes siguiendo Keras Tutorial: Aprendizaje profundo en Python.
Algoritmos populares
Redes neuronales convolucionales
La red neuronal convolucional (CNN) es una red neuronal feed-forward capaz de procesar un conjunto estructurado de datos. Se utiliza mucho en aplicaciones de visión por ordenador, como la clasificación de imágenes.
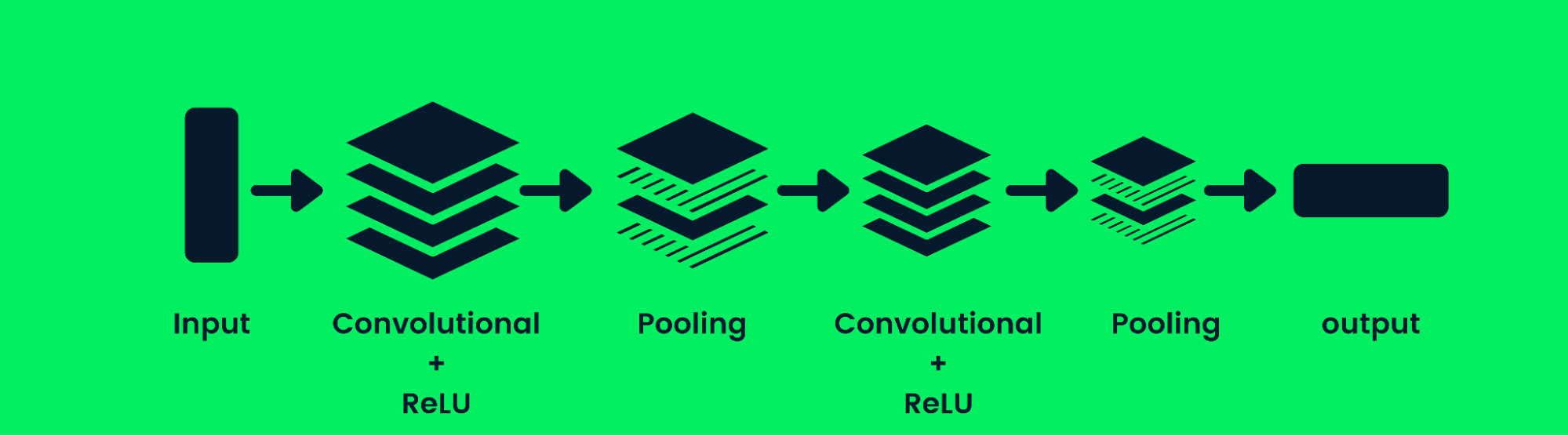 Arquitectura de la red neuronal de convolución
Arquitectura de la red neuronal de convolución
Las CNN son buenas reconociendo patrones, líneas y formas. La CNN consta de una capa convolucional, una capa de agrupamiento y una capa de salida (capas totalmente conectadas). Los modelos de clasificación de imágenes suelen contener varias capas de convolución, seguidas de capas de agrupación, ya que las capas adicionales aumentan la precisión del modelo. Aprende más sobre las capas convolucionales aquí: Redes neuronales convolucionales en Python.
Redes neuronales recurrentes
Las redes neuronales recurrentes (RNN) se diferencian de las redes feed-forward en que la salida de la capa se realimenta en la entrada para predecir la salida de la capa. Esto le ayuda a funcionar mejor con datos secuenciales, ya que puede almacenar la información de muestras anteriores para predecir muestras futuras. Más información en Tutorial de Redes Neuronales Recurrentes (RNN): Tipos y ejemplos.
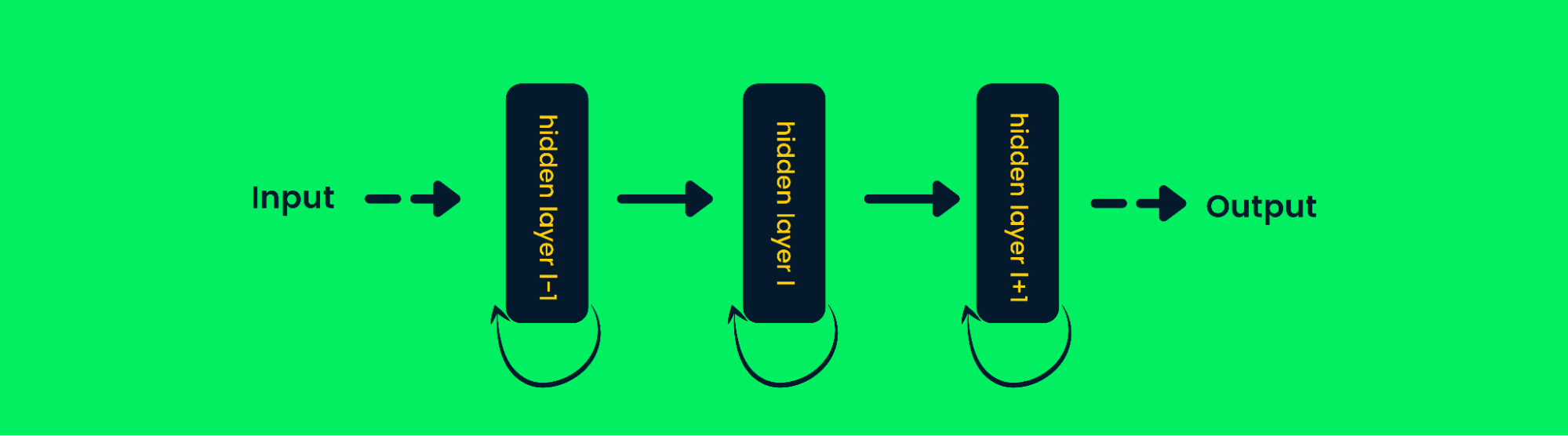 Arquitectura de la red neuronal recurrente
Arquitectura de la red neuronal recurrente
En las redes neuronales tradicionales, la salida de las capas se calcula en función de los valores de entrada actuales, pero en las RNN la salida se calcula también en función de las entradas anteriores. Esto lo hace bastante bueno en la predicción de la próxima palabra, en la previsión de los precios de las acciones, en los chatbots de IA y en la detección de anomalías.
Redes de memoria a corto plazo
Las redes de memoria a largo plazo (LSTM) son tipos avanzados de redes neuronales recurrentes que pueden retener mayor información sobre valores pasados. Resuelve los problemas de gradiente evanescente que existen en las RNN simples.
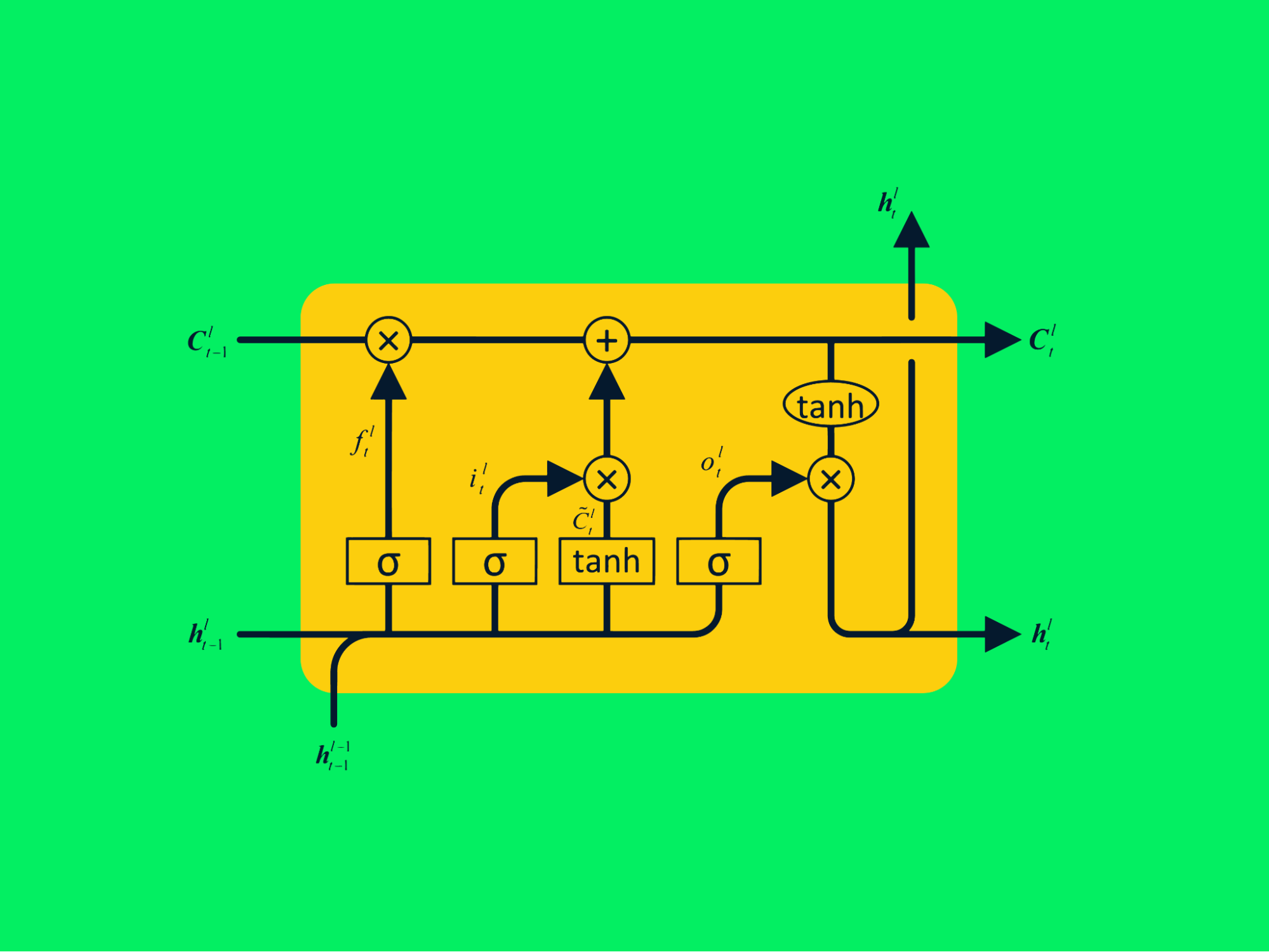 Arquitectura LSTM
Arquitectura LSTM
La RNN típica consiste en redes neuronales repetitivas con una sola capa tanh, mientras que la LSTM consta de cuatro capas interactivas que se comunican para procesar grandes secuencias de datos.
Puedes adquirir experiencia práctica con el siguiente tutorial de : LSTM para predicciones bursátiles o el curso de aprendizaje profundo avanzado con Keras si quieres aprender más sobre modelos de aprendizaje profundo.
Marcos de aprendizaje profundo
Existen múltiples marcos de aprendizaje profundo, como MxNet, CNTK y Caffe2, pero aprenderemos sobre los marcos más populares.
Tensorflow
Tensorflow (TF) es una biblioteca de código abierto utilizada para crear aplicaciones de aprendizaje profundo. Incluye todas las herramientas necesarias para que experimentes y desarrolles productos comerciales de IA. Admite CPU, GPU y TPU para entrenar modelos complejos. TF fue desarrollado originalmente por el equipo de IA de Google para uso interno y ahora está disponible para el público.
La API de Tensorflow está disponible para aplicaciones basadas en navegador, dispositivos móviles, y TensorFlow Extended es ideal para producción. El TF se ha convertido en la norma del sector, y se utiliza tanto para la investigación académica como para el despliegue de modelos de aprendizaje profundo en producción.
TF también viene con Tensorboard, que es un panel capaz de analizar tus experimentos de aprendizaje automático. Recientemente, los desarrolladores de Tensorflow han integrado Keras en su marco, que es popular para desarrollar redes neuronales profundas. Obtén más información en el Curso de Introducción a TensorFlow en Python.
Keras
Keras es un marco de trabajo de redes neuronales escrito en Python y capaz de ejecutarse en múltiples marcos de trabajo, como Tensorflow y Theano. Keras es una biblioteca de código abierto desarrollada para permitir una rápida experimentación en el aprendizaje profundo, de modo que puedas convertir fácilmente tus conceptos en aplicaciones de IA que funcionen.
La documentación es bastante fácil de entender, y la API es similar a la de Numpy, lo que te permite integrarla fácilmente en cualquier proyecto de ciencia de datos. Al igual que TF, Keras también puede ejecutarse en CPU, GPU y TPU, en función del hardware disponible. Más información en Introducción al Aprendizaje Profundo con Keras.
PyTorch
PyTorch es el marco de aprendizaje profundo más popular y sencillo. Utiliza un tensor en lugar de una matriz Numpy para realizar cálculos numéricos rápidos con la ayuda de la GPU. PyTorch se utiliza principalmente para el aprendizaje profundo y el desarrollo de modelos complejos de aprendizaje automático.
Los investigadores académicos prefieren utilizar PyTorch por su flexibilidad y facilidad de uso. Está escrito en C++ y Python, y también viene con aceleración de GPUs y TPUs. Se ha convertido en una solución integral para todos los problemas del aprendizaje profundo. Si quieres saber más sobre PyTorch, prueba a seguir el curso Introducción al Aprendizaje Profundo con PyTorch.
Conclusión
En este tutorial, hemos cubierto todo lo que es el aprendizaje profundo, algunos de sus fundamentos, cómo funciona y sus aplicaciones. También hemos aprendido cómo funcionan las redes neuronales profundas y sobre los distintos tipos de modelos de aprendizaje profundo. Por último, se te han presentado algunos marcos populares de aprendizaje profundo.
Este tutorial te ha proporcionado toda la información clave necesaria para iniciarte en el campo del aprendizaje profundo. Para profundizar en tu aprendizaje, la Vía de Aprendizaje Profundo en Python te preparará para trabajar en proyectos del mundo real. También puedes echar un vistazo al aprendizaje profundo con Keras en R si te sientes cómodo con el lenguaje de programación R.