
Curso
Analyzing Marketing Campaigns with pandas
4 h
33.7K
When you need to perform operations in a Pandas DataFrame row by row, you need to use row iteration. While Pandas is enhanced for vectorized operations, row iterations are essential when applying logic that is not vectorized, especially in complex data manipulations or conditional row processing.
There are various methods you can apply to a Pandas DataFrame to perform row iterations.
.iterrows(): Use this for simple row-wise operations, where index and row data are needed. It returns index-series pairs, which can be slow for large dataframes and is not suitable for heavy computations.
.itertuples(): Use this as a faster alternative to .iterrows(), especially when you don’t need a Pandas Series. It returns a namedtuple of row values and is more memory-efficient than .iterrows().
.apply(axis=1): This applies a function to each row, and is usually used with the axis = 1 argument. It is slower than vectorized methods, but often faster than explicit loops.
Although Pandas is designed to run optimally using column-based operations, various Python methods facilitate row-wise iteration, especially when working with individual rows.
Pandas works with DataFrames in a columnar format, hence making it efficient in applying transformations to DataFrame columns simultaneously.
This is also one of the reasons why vectorized operations are efficient in Pandas and are usually encouraged over row iterations, which can become slow when working with large DataFrames.
The following are the primary row iteration methods:
.iterrows(): This returns each row as a tuple of (index, Series).
.itertuples(): Faster than .iterrows() and yields each row as a namedtuple.
.items(): Not a row iteration, but iterates over a Pandas DataFrame columns, returning a column label and Series, and is usually used for column-wise operations.
Based on benchmarks of moderately sized DataFrames with 100,000 rows, .itertuples() is 5-10 times faster than .iterrows() in terms of speed and memory efficiency. This is because .itertuples() avoids creating Series objects for each row and instead yields lightweight namedtuples.
Vectorized operations are faster than any form of iteration because they are implemented in optimized C code. They eliminate Python-level loops, reducing overhead. For example, adding two columns using datacamp_rows[“A”] + is faster than using a datacamp_rows[“B”]for loop with .iterrows().
.iterrows() has a large memory footprint since it returns a complete Pandas Series object, and these Series may suffer from dtype inconsistencies since they are derived from different columns with varying data types.
For a smaller dataset, it is recommended you use .iterrows(), while for larger datasets, you can use .itertuples().
You might find yourself in situations where you can't apply vectorized operations, and you may have to fall back to row iteration. In case of such situations, you will learn in this section when and when not to use row iterations.
Typical scenarios for row iterations include:
Despite the use cases of row-wise iterations, you should avoid them in some cases, such as:
Instead of iterating, consider the following alternatives:
Use vectorized operations wherever possible.
Leverage .apply() with optimized functions for complex but still vectorizable tasks.
Consider batch processing or parallelization if you must iterate but have performance constraints.
You must avoid the following common pitfalls of row-wise loops, such as:
.iterrows() returns a copy, not a reference to the original row; hence, modifying it does not change the original DataFrame.
It’s harder to read and maintain when compared to vectorized operations.
You can implement row iteration in Pandas DataFrames using various methods, which depend on either your use case or the nature of the DataFrame. Here are the methods for iterating over Pandas DataFrames rows.
The .iterrows() method involves iterating over individual rows of a DataFrame. The syntax is as follows:
for index, row in datacamp_rows.iterrows():
# code to process each rowWhere datacamp_rows is the dataframe, iterated, index is the row index, and row is the Pandas Series containing the row data.
Here is a basic usage example:
import pandas as pd
students = {"Name": ["Mary", "Joseph"], "Age": [25, 30]}
students = pd.DataFrame(students)
for index, row in students.iterrows():
print(f"Index: {index}, Name: {row['Name']}, Age: {row['Age']}")Index: 0, Name: Mary, Age: 25
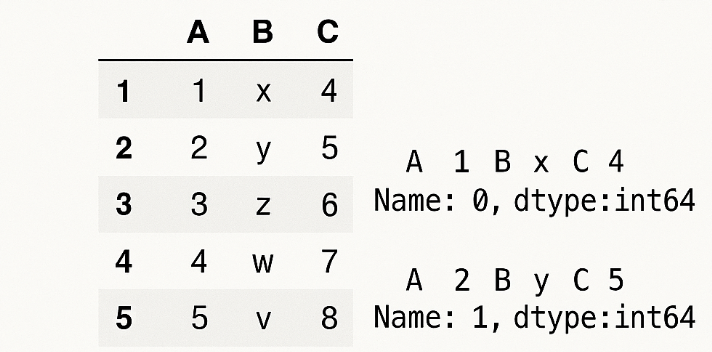
Index: 1, Name: Joseph, Age: 30The .iterows() method returns a generator that yields the index of a row, along with a Series object representing the rows. The keys of this Series object are column names, and the values are the corresponding data in each row.
Internally, this is what the .iterrows() returns.
(index_0, Series_0)
(index_1, Series_1).itertuples() is faster and more memory-efficient than .iterrows(), and it returns each row as a namedtuple, allowing access to column values using dot notation. The syntax is represented as follows:
for row in datacamp_rows.itertuples(index=True, name="Pandas"):
# process each rowWhere index=True includes the DataFrame index as the first element of each tuple, and name="Pandas" sets the name of the returned namedtuple class. If name=None, the for loop returns a regular tuple with no access to its attributes.

Here is a practical example of how the .itertuples() works:
import pandas as pd
students= {"Name": ["Mary", "Joseph"], "Age": [25, 30]}
students = pd.DataFrame(students)
for row in students.itertuples():
print(f"Index: {row.Index}, Name: {row.Name}, Age: {row.age}")Index: 0, Name: Mary, Age: 25
Index: 1, Name: Joseph, Age: 30.itertuples() returns a generator yielding namedtuples, where each row is represented as a lightweight object.
You can access each row field using dot notation, such as row.Name and row.age, which is preceded by the index.
Internally, this is what it returns:
Pandas(Index=0, Name='Mary', Age=25)
Pandas(Index=1, Name='Joseph', Age=30)The .apply() method in Pandas is useful when applying functions to rows to perform row-wise iterations, as seen when using the axis=1 argument. The syntax is given as follows:
df.apply(func, axis=1)Where the function to apply on the row is func, while the argument axis=1 is set.
Here is a practical example illustrating its application.
import pandas as pd
students = pd.DataFrame({"Name": ["Mary", "Joseph"], "Math": [85, 90], "Science": [95, 88]})
# Add a new column with average score
students["Average"] = students.apply(lambda row: (row["Math"] + row["Science"]) / 2, axis=1)
students.head()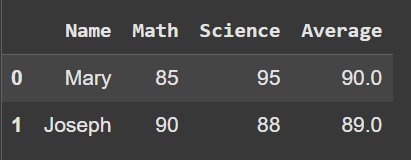
Use the .apply() method when creating new columns based on existing ones, or when applying custom calculations or transformations.
In terms of row-iteration, you can use it to create conditional logic per row, such as if-else statements. When axis=1 is set, the function is passed as a Series with column names as indices. This function processes the rows and returns a scalar value in a new column or series in multiple columns.
Although .apply(axis=1) is slower than vectorized operations, it is faster and cleaner than .iterrows().
Another workaround for row iterations is for you to use .loc[] or .iloc[] manually with for loops to iterate over a Pandas DataFrame.
This works similarly to the .iterrows() or .itertuples() methods. An advantage of this approach is that you gain complete control over the rows. The syntax is given as follows:
# positional indexing
for i in range(len(df)):
row = df.iloc[i]
# process row
# label indexing
for idx in df.index:
row = df.loc[idx]
# process rowHere is a practical example showing how it is implemented.
import pandas as pd
students = pd.DataFrame({"Name": ["Mary", "Joseph"], "Age": [25, 30]})
# Using iloc
for i in range(len(students)):
print(f"Name: {students.iloc[i]['Name']}, Age: {students.iloc[i]['Age']}")
# Using loc
for idx in students.index:
print(f"Name: {students.loc[idx, 'Name']}, Age: {students.loc[idx, 'Age']}")Name: Mary, Age: 25
Name: Joseph, Age: 30One of the use cases for this method of row iteration is when you need precise control over row order, or when writing a step-by-step logic for debugging. Although this approach becomes inefficient for large dataframes, it is also slower than vectorized operations.
It’s essential to use .loc[] when you need label-based lookup or .iloc[] when you need position-based access, especially with range-based loops.
Here is a table summarizing the differences between the three methods.
|
Features |
iterows() |
itertuples() |
apply(axis=1) |
|
Syntax |
for idx, row in df.iterrows: |
for row in df.itertuples(): |
df.apply(func, axis=1) |
|
Output |
(index, Series) |
namedtuple |
Returns a value of the function (scalar or Series) |
|
Speed |
Slow |
Fastest |
Moderated |
|
Memory Usage |
Medium |
Low |
Medium |
|
Readability |
Moderate |
High |
High |
|
Best use cases |
Quick prototyping or debugging |
Large datasets |
Columns derivation |
|
Limitations |
Slower |
Can’t handle complex row logic |
Slower than full vectorization |
While the .iterrows() method is a straightforward way to iterate over a Pandas DataFrame's rows, it has its limitations that can impact performance.
Iteration with .iterrows() yields each row of a DataFrame as a tuple containing the row index, which is the table, and a Series object that contains the data in the row.
Despite its simplicity, it has a drawback in terms of dtype conversion; for example, it converts integers into floats if the Series needs to accommodate mixed types, which can lead to subtle bugs in calculations or comparisons.
Additionally, because .iterrows() returns a Series for each row, this results in memory overhead, which slows performance compared to vectorized operations.
Data modification within a loop using .iterrows() is discouraged, as changes to the Series object do not propagate back to the dataframe.
Despite the above limitations, .iterrows() remains useful in some scenarios, such as:
.iterrows() method for non-vectorizable operations, such as making API calls, writing to files, or interacting with databases on a row-by-row basis..iterrows() method.To maintain dtype consistency, consider switching to .itertuples(), as it returns named tuples without type conversion.
.itertuples() method is faster and more memory efficient than .iterrows() because it returns a namedtuple. Let’s examine how some of its features make it superior to the .iterrows() method.
Some of the advantages of .itertuples() include:
Performance gains: Instead of creating Series objects like .iterrows(), which consume memory and reduce performance, .itertuples() avoids memory overhead and improves performance by using a generator that yields namedtuples.
Customizability: The index=False argument in .itertuples() omits the index from the tuple, and setting the name= 'Custom' argument allows for setting a custom namedtuple class name, improving readability or integration with other systems.
When using .itertuples(), it is essential to be aware of the following limitations.
Column naming constraints: Column names containing special characters or spaces can result in invalid Python identifiers. These are either modified to valid names or accessed using index-based tuple unpacking.
Immutability: Namedtuples are immutable, which means you can’t modify their values in-place. This implies that any transformations require building a new structure or collecting the desired values into a separate list or dataframe.
Here are some best practices to adhere to when using .itertuples():
While the primary methods for row iterations are .iterrows() and .itertuples(), pandas provides other alternatives that are more efficient for large-scale data manipulation, such as vectorization, which is memory-efficient and faster.
Vectorized operations involve applying operations across entire arrays or DataFrame columns at once, leveraging low-level optimizations in NumPy and Pandas. It is cleaner and more readable, and drastically reduces execution time.
Below are some common vectorization techniques and examples:
Arithmetic operations: datacamp_rows[‘total’] = datacamp_rows[‘price’] * datacamp_rows[quantity’]
Conditional logic: datacamp_rows[‘flag’] = np.where(datacamp_rows[‘value’] > 10, ‘high’, ‘low’)
String methods: datacamp_rows[‘cleaned’] = datacamp_rows[‘text’].str.lower().str.strip()
Datetime manipulations: datacamp_rows[‘year’] =datacamp_rows[‘date’].dt.year
Vectorized operations are backed by compiled C code and optimized memory management, often outperforming Python loops by orders of magnitude, especially for large DataFrames.
When implementing row-wise logic, it is recommended you use the .apply(axis=1) method. Although it is not as fast as vectorization, it is more efficient and expressive than row iteration. .apply() is sometimes slow on large DataFrames because it still loops internally in C. However, it is manageable for moderately complex logic.
There are various tools you can consider using for optimization of .apply(), such as:
Swifter: This automatically decides the fastest execution .apply() methods.
Pandarallel: Enables you to easily perform parallel execution of .apply() across multiple CPU cores with just a single line of code.
Numba: Is a JIT compiler that speeds up numeric Python functions. When you use it inside .apply(), it can drastically reduce computation time for numerically intensive operations.
A powerful strategy in Pandas is to create temporary columns to break down complex operations into manageable vectorized steps, which avoids the need for explicit row-by-row iteration.
There are various optimization strategies and comparative benchmarks to explore, ensuring scalable and memory-efficient handling, especially when working with large datasets.
Different iteration methods in Python can have varying performance. For example, the for and while loops, when used in conjunction with Pandas methods such as .itertuples() and .iterrows(), are significantly slower than vectorized operations.
Benchmarks typically show that .itertuples() is faster and more memory efficient than .iterrows() because it returns namedtuples instead of Series. Vectorized operations outperform all other forms of iteration due to their underlying C-based implementations.
As data scales to millions of rows, these differences become critical as inefficient methods can lead to bottlenecks and increased memory consumption.
For larger datasets, do consider using some of these techniques:
Chunk processing: Use the chunksize parameter in .read_csv() to process data in manageable blocks instead of loading everything into memory all at once.
Dtype optimization: Try using different data types, such as float32 instead of float64, to reduce memory usage.
Memory management: Drop unused columns early, filter data before merging, and periodically free memory with gc.collect().
Out-of-core computing: Use tools like Dask and Vaex to enable parallel, out-of-core computations on datasets that exceed memory capacity.
There are various scenarios where using iteration comes in handy. Here are some practical examples that demonstrate common iteration patterns and best practices when working with Pandas.
Here is an example showing basic usage of .iterrows(), .itertuples(), and .apply(axis=1).
import pandas as pd
students = pd.DataFrame({"name": ["Mary", "Joseph"], "age": [25, 30]})
# Using iterrows()
for index, row in students.iterrows():
print(f"{row['name']} is {row['age']} years old")
# Using itertuples()
for row in students.itertuples(index=False):
print(f"{row.name} is {row.age} years old")
# Using apply()
students.apply(lambda row: print(f"{row['name']} is {row['age']} years old"), axis=1)Mary is 25 years old
Joseph is 30 years old
Mary is 25 years old
Joseph is 30 years old
Mary is 25 years old
Joseph is 30 years oldYou can use row iteration methods to modify DataFrame values in a loop; however, this approach is not efficient when working with large datasets.
The following examples show how to implement this.
for index, row in students.iterrows():
students.at[index, 'age'] = row['age'] + 1
students.head()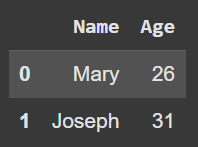
When working with large dataframes, consider using a vectorized operation to increase performance, as shown in the example below.
# Better approach using a vectorized method
students["age"] = students["age"] + 1To process only specific rows, consider using a conditional check inside the loop, like in the following example, where rows with age greater than 25 are printed.
for row in students.itertuples(index=False):
if row.age > 25:
print(f"{row.Name} is older than 25")Joseph is older than 25Though the vectorized option below is better and more performant.
students_greater_than_5 = students[students["age"] > 25]It’s also possible to compute summary statistics during row-wise processing; however, Pandas offers built-in methods like .sum() and .mean(), which are faster.
# Manual aggregation
total_age = 0
for row in students.itertuples(index=False):
total_age += row.age
average_age = total_age / len(students)
print(f"Average age: {average_age}")
# Preferred vectorized method
average_age =students["age"].mean()Average age: 27.5When performing row iteration in Pandas, it’s essential to understand the trade-offs between the different available methods.
Use .iterrows() when you need a simple solution and are not working with a large dataset, and .itertuples() when you require a faster alternative and improved performance.
Always make vectorized operations your first choice when applicable, especially with larger datasets, as they are faster and more efficient due to their underlying C-based operations.
Use .apply() to provide a middle ground when a row-or column-wise operation is needed that is not easily vectorizable.
Here are some of our resources to learn more about Pandas:
You can also check out our following course pages to accelerate your learning:
Learn Python with DataCamp
Curso
Curso
Curso
Tutorial
Aditya Sharma
Tutorial
DataCamp Team
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
Adel Nehme
Tutorial
DataCamp Team
