

programa
Tratamiento de imágenes en Python
12 h
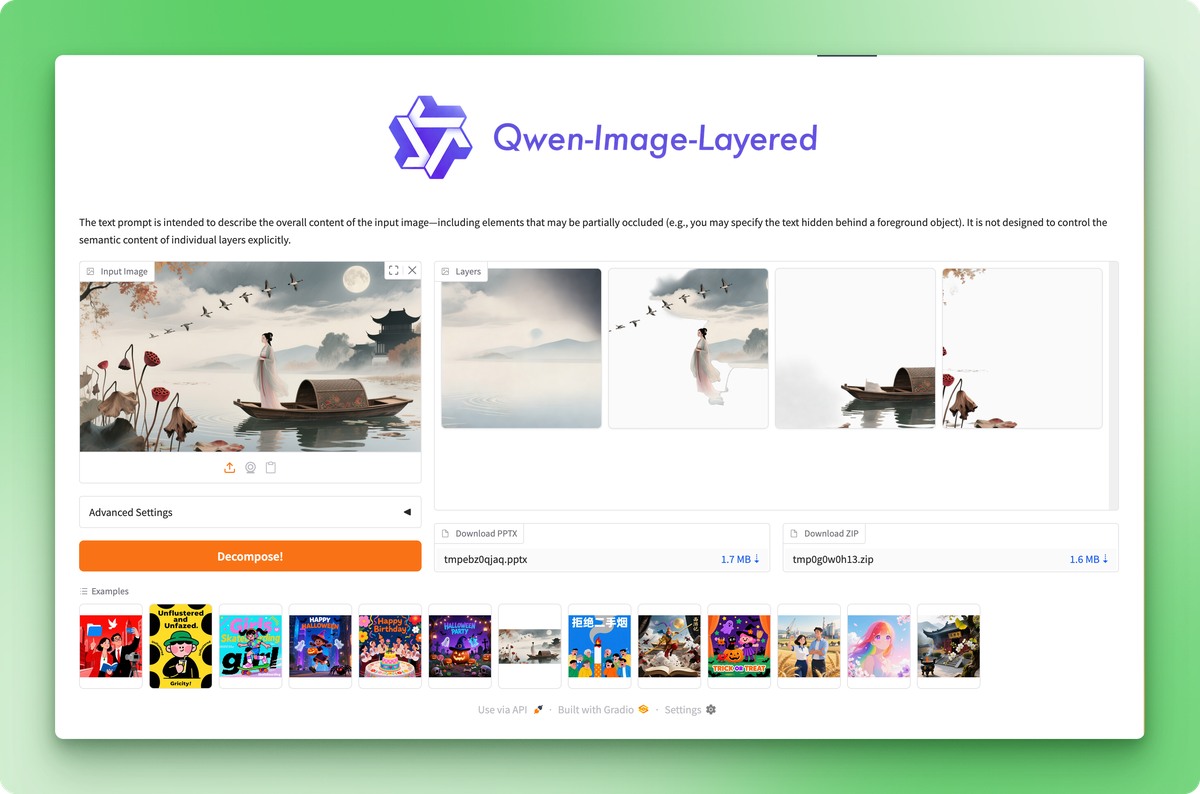
Los usuarios de Photoshop pasan horas enmascarando objetos y pintando fondos manualmente. Qwen-Image-Layered, un nuevo modelo del equipo Qwen de Alibaba, hace esto automáticamente: le proporcionas una sola imagen y te devuelve varias capas RGBA con fondos transparentes.
Este tutorial explica qué es Qwen-Image-Layered, en qué se diferencia de herramientas de segmentación como SAM y cómo ejecutarlo en Python. Descompondrás una imagen en capas, luego editarás y volverás a combinar esas capas en una nueva composición. Al final, tendrás un flujo de trabajo funcional para la edición programática de imágenes que elimina por completo el enmascaramiento manual.
Si eres nuevo en el manejo de datos de imágenes y transparencia en código, consulta nuestro Procesamiento de imágenes en Python para adquirir una base sólida antes de lanzarte a ello.
Qwen-Image-Layered se basa en Qwen2.5-VL, un modelo de lenguaje visual de Alibaba. La columna vertebral VL significa que el modelo entiende lo que hay en una imagen semánticamente: puede distinguir un producto de su sombra y de la superficie sobre la que se encuentra, no solo detectar bordes. Como Vision Transformers, procesa las imágenes mediante mecanismos de atención en lugar de los enfoques convolucionales tradicionales.
Cuando ejecutas la inferencia, especificas cuántas capas deseas. Pide 4 y el modelo distribuirá el contenido de la imagen en 4 salidas RGBA. Pide 8 y obtendrás una separación más precisa. El modelo decide qué va en cada sitio basándose en la estructura de la escena.
Así es como se ve la descomposición en el anuncio de Qwen:
El modelo toma una imagen compuesta y la separa en capas RGBA editables individualmente con transparencia.
La imagen promocional del caramelo se divide en cuatro capas distintas: el fondo con estrellas, la persona vestida de naranja, el texto y la marca «Sour Candy» y los caramelos individuales. Cada capa aparece con un fondo transparente (mostrado con el patrón de tablero de ajedrez), lista para editarla o reorganizarla.
El modelo distribuye los elementos visuales entre capas basándose en la profundidad y la comprensión semántica. Los gráficos de fondo van a la capa 0, el sujeto principal (persona) va a la capa 1, las superposiciones de texto van a la capa 2 y los objetos pequeños en primer plano (trozos de caramelo) van a la capa 3. Cada elemento está claramente separado con la transparencia adecuada.
Si ya has trabajado con segmentación de imágenes, quizá te preguntes en qué se diferencia Qwen-Image-Layered de las herramientas existentes, en particular del modelo Segment Anything Model (SAM).
SAM y modelos de segmentación similares generan máscaras: mapas binarios que indican qué píxeles pertenecen a cada objeto. Es útil, pero una máscara solo te indica dónde está algo. Al extraer el objeto, sigue quedando un agujero en la imagen original.
Por otro lado, Qwen-Image-Layered genera capas completas. El objeto en primer plano aparece con transparencia y la capa de fondo que hay detrás ya está rellenada. Cuando eliminas o mueves una capa más tarde, no hay nada que reparar.
|
Característica |
Qwen-Imagen-En capas |
Modelo Segment Anything 2 (SAM 2) |
|
Objetivo principal |
Descomposición de capas (crear activos editables) |
Segmentación (identificar y aislar píxeles) |
|
Resultado clave |
Pila de imágenes RGBA (capas transparentes) |
Máscaras binarias (contornos en blanco y negro) |
|
Gestión en segundo plano |
Relleno de oclusiones: Genera píxeles para rellenar el «hueco» detrás de un objeto. |
Ninguno: Deja el fondo vacío/negro donde se ha eliminado el objeto. |
|
Modalidad de entrada |
Imagen + texto (opcional) |
Imagen/vídeo + puntos, cuadros o máscaras |
|
Tipo de arquitectura |
Generativo (basado en difusión, Qwen2.5-VL) |
Discriminativo (basado en transformadores) |
|
Soporte de vídeo |
Limitado (aplicación fotograma a fotograma) |
Nativo (seguimiento de objetos de última generación en vídeo) |
|
Control del usuario |
Capas variables (por ejemplo, «dividir esto en 4 capas frente a 8 capas») |
Promptable (haz clic en puntos o dibuja cuadros para seleccionar objetos específicos) |
|
Mejor caso de uso |
Diseño gráfico, creación de activos, edición «sin Photoshop». |
Edición de vídeo, seguimiento de objetos, análisis científico, robótica. |
SAM utiliza un enfoque discriminativo, analizando los píxeles existentes para definir con precisión los límites de los objetos. Qwen-Image-Layered, por el contrario, emplea una arquitectura generativa basada en la difusión que reconstruye las regiones ocluidas u ocultas mediante la generación de imágenes aprendidas.
Mientras que SAM genera máscaras que definen qué eliminar, Qwen-Image-Layered genera contenido de fondo plausible para completar la descomposición en capas. Cabe destacar que SAM puede lograr un relleno de fondo similar cuando se combina con modelos de relleno dedicados, pero Qwen-Image-Layered integra esta capacidad de principio a fin en su proceso de descomposición.
El mecanismo de control de entrada también es diferente: SAM se basa en indicaciones interactivas precisas, que requieren que hagas clic en puntos o dibujes cuadros delimitadores para seleccionar un objetivo específico. Qwen-Image-Layered funciona de forma más holística, permitiéndote simplemente especificar el número deseado de capas (por ejemplo, «dividir esto en 4 capas») para organizar automáticamente toda la estructura de la imagen.
Hay que señalar que SAM 2 está diseñado explícitamente para vídeo, y es capaz de rastrear objetos a través de secuencias utilizando una arquitectura de streaming con memoria aumentada (mantiene ~6 fotogramas recientes) con una alta consistencia temporal. Qwen-Image-Layered está especializado en la composición de imágenes estáticas decy actualmente no ofrece seguimiento de objetos nativo para la edición de vídeo.
Ahora pasemos a la parte práctica. Antes de escribir cualquier código, hay que tener en cuenta una consideración práctica: dónde ejecutar el modelo.
Qwen-Image-Layered requiere más de 57 GB de pesos de modelo y una GPU de gama alta con mucha VRAM.
Probé a ejecutarlo localmente en Google Colab con una GPU T4, y la sesión se quedó sin RAM antes de que el modelo eterminara de descargarse. El uso del disco aumentó hasta los 90 GB de los 112 GB disponibles en el tiempo de ejecución de la GPU. El modelo es simplemente demasiado grande para entornos de nube de nivel gratuito.
Los grandes modelos generativos como Stable Diffusion se enfrentan a retos de alojamiento similares, por lo que las API alojadas se han convertido en algo habitual.
Para este tutorial, utilizaremos la API alojada de Replicate. Cada descomposición cuesta alrededor de 0,03 dólares, lo que te permite obtener un funcionamiento estable y reproducible sin preocuparte por los límites de memoria o los conflictos de dependencia. Si solo deseas probar el modelo sin escribir código, el Hugging Face Space ofrece una interfaz web gratuita donde puedes subir imágenes y descargar capas manualmente.
Hugging Face Space te permite probar el modelo sin código, pero la API te ofrece control programático.
Crea un nuevo directorio para el proyecto e instala los paquetes necesarios:
pip install replicate python-dotenvObtén tu token API en la configuración de la cuenta de Replicate y guárdalo en un archivo .env:
REPLICATE_API_TOKEN=your_token_hereLos anuncios oficiales de los modelos suelen mostrar ejemplos cuidadosamente seleccionados en los que el modelo ofrece su mejor rendimiento. Probemos con una imagen real para ver el rendimiento realista.
Esta es la imagen que descompondremos en capas:

Foto de Karola G en Pexels
La fotografía muestra tres productos para el cuidado de la piel sobre una superficie de color menta con un fondo lavanda: una caja de regalo blanca con un lazo negro, un frasco de sérum rosa y un pequeño tarro de crema. Composición limpia, objetos diferenciados, sombras sutiles. Un buen caso de prueba para la separación de capas.
import replicate
from dotenv import load_dotenv
load_dotenv()
with open("data/healthcare_products.jpg", "rb") as f:
output = replicate.run(
"qwen/qwen-image-layered",
input={
"image": f,
"num_layers": 4,
"go_fast": True,
"output_format": "png",
"seed": 42,
}
)El parámetro « num_layers » controla la precisión con la que el modelo divide la imagen. Los valores pueden oscilar entre 2 y 8. Con 4 capas, se obtiene un equilibrio razonable entre granularidad y facilidad de gestión. Establecer seed en un valor fijo hace que la salida sea reproducible.
La API también acepta URL directamente, por lo que puedes omitir el manejo de archivos si tu imagen está alojada en algún lugar:
output = replicate.run(
"qwen/qwen-image-layered",
input={
"image": "https://example.com/photo.jpg",
"num_layers": 4,
"go_fast": True,
"output_format": "png",
}
)La API devuelve una lista de objetos FileOutput. Cada uno tiene un método ` .read() ` que te proporciona los bytes de la imagen:
for i, layer in enumerate(output):
with open(f"layer_{i}.png", "wb") as f:
f.write(layer.read())Las capas se ordenan de abajo hacia arriba: el índice 0 es el fondo y los índices superiores se apilan encima de él. Cada PNG es una imagen RGBA con transparencia, en la que se pueden ver las demás capas.
Aquí está el resultado:

El modelo colocó el fondo (pared lavanda y superficie menta) en la capa 0, el tarro de crema en la capa 1, la caja de regalo en la capa 2 y el frasco de sérum en la capa 3. Cada producto salió con bordes limpios y una transparencia precisa.
Sin embargo, si observas la capa de fondo, verás restos de sombras tenues donde antes estaban los productos. Esto se observó de manera sistemática en mis pruebas: el modelo gestiona bien el aislamiento de objetos, pero tiene dificultades con la reconstrucción del fondo cuando hay sombras.
Cuanto más prominentes sean las sombras en la imagen original, más visibles serán estos artefactos. Es el primer modelo de este tipo, así que es de esperar que el equipo de Qwen lo perfeccione en futuras actualizaciones.
La descomposición es solo la mitad del flujo de trabajo. Las capas resultan útiles cuando las editas y las vuelves a ensamblar para crear algo nuevo.
Los fotógrafos de productos a menudo necesitan la misma toma con diferentes fondos para pruebas A/B, campañas de temporada o requisitos específicos de cada plataforma. Con capas separadas, esto requiere unas pocas líneas de código.
from PIL import Image
# Load the decomposed layers
layers = [Image.open(f"layer_{i}.png") for i in range(4)]
# Create a new background (solid coral)
new_bg = Image.new("RGBA", layers[0].size, (255, 180, 162, 255))
# Replace the original background layer
layers[0] = new_bg
# Composite from bottom to top
result = layers[0]
for layer in layers[1:]:
result = Image.alpha_composite(result, layer)
result.save("coral_background.png")La función alpha_composite() gestiona automáticamente la mezcla RGBA. Respeta la transparencia en cada capa, por lo que los objetos en primer plano se sitúan de forma natural sobre cualquier fondo que proporciones.
PIL facilita la manipulación de imágenes, y si necesitas aplicar transformaciones más complejas, las capacidades de procesamiento de imágenes de PyTorch se integran bien con los flujos de trabajo de PIL.
Aquí está el resultado:

Los mismos productos, un entorno diferente, sin enmascaramiento manual. Podrías cambiarlo por un degradado, una textura u otra fotografía completamente diferente. El proceso sigue siendo el mismo: reemplazar la capa 0 y componer el resto.
El mismo patrón se aplica a otras ediciones. Elimina un objeto saltándote su capa:
# Composite without the cream jar (layer 1)
layers_without_jar = [layers[0], layers[2], layers[3]]
result = layers_without_jar[0]
for layer in layers_without_jar[1:]:
result = Image.alpha_composite(result, layer)
Para reposicionar un objeto pegándolo en diferentes coordenadas, utiliza el método paste() con el desplazamiento x/y que elijas:
# Move the serum bottle 50 pixels left
canvas = Image.new("RGBA", layers[0].size, (0, 0, 0, 0))
canvas.paste(layers[3], (-50, 0), layers[3])
layers[3] = canvas
# Then composite as usualEl flujo de trabajo es siempre el mismo:
Cada operación se realiza en una capa aislada, por lo que las ediciones permanecen contenidas.
Ejecutar estas operaciones en un cuaderno funciona para ediciones puntuales, pero el ciclo de retroalimentación es lento. Escribes código, ejecutas una celda, compruebas el resultado, ajustas y repites. Para trabajos iterativos en los que deseas activar y desactivar capas, comparar composiciones y descargar resultados sin volver a ejecutar celdas, lo más adecuado es una interfaz gráfica de usuario ligera.
Crearemos una aplicación Streamlit en unas 160 líneas que te permitirá cargar una imagen, descomponerla, alternar capas y ver una vista previa en directo. Crea un archivo llamado streamlit_app.py en el directorio de tu proyecto.
Comienza con las importaciones y la configuración básica:
import os
import io
import time
from typing import List
import streamlit as st
from PIL import Image, ImageDraw
from dotenv import load_dotenv
import replicate
load_dotenv()
# Constants
MAX_LAYERS, MIN_LAYERS, DEFAULT_LAYERS = 8, 2, 4
THUMBNAIL_SIZE = (150, 150)
# Initialize session state
if "layers" not in st.session_state:
st.session_state.layers = []
st.session_state.layer_visibility = []
st.session_state.original_image = None
st.set_page_config(page_title="Qwen-Image-Layered", page_icon="🎨", layout="wide")
st.title("🎨 Qwen-Image-Layered")
st.markdown("Decompose images into editable RGBA layers")El estado de la sesión persiste entre las repeticiones de Streamlit. Sin él, tus capas desaparecerían cada vez que alguien hiciera clic en un botón.
Antes de llamar a Replicate, asegúrate de que el token existe:
token = os.environ.get("REPLICATE_API_TOKEN")
if not token:
st.error("REPLICATE_API_TOKEN not found. Set it in your .env file.")
st.code("export REPLICATE_API_TOKEN=your_token_here", language="bash")
st.stop()st.stop() detiene la ejecución si falta el token. No tiene sentido renderizar el resto de la interfaz de usuario.
La API de descomposición cuesta 0,03 $ por llamada y tarda entre 30 y 60 segundos. El almacenamiento en caché evita llamadas redundantes:
@st.cache_data(show_spinner=False)
def decompose_image(_image_bytes: bytes, num_layers: int, seed: int) -> List[bytes]:
"""Call Replicate API with retry logic for 502 errors."""
for attempt in range(3):
try:
output = replicate.run(
"qwen/qwen-image-layered",
input={
"image": io.BytesIO(_image_bytes),
"num_layers": num_layers,
"go_fast": True,
"output_format": "png",
"seed": seed,
},
)
return [layer.read() for layer in output]
except Exception as e:
if attempt < 2 and ("502" in str(e) or "Replicate" in str(type(e).__name__)):
time.sleep(5)
continue
raiseEl prefijo de subrayado en _image_bytes le indica a Streamlit que no realice el hash de ese parámetro (el hash de bytes es costoso). El bucle de reintento gestiona los errores 502 ocasionales de Replicate esperando 5 segundos e intentando hasta 3 veces.
A continuación, definimos pequeñas utilidades para la visualización y la composición:
def create_checkerboard(size: tuple) -> Image.Image:
"""Create a checkerboard pattern to show transparency."""
img = Image.new("RGBA", size, (220, 220, 220, 255))
draw = ImageDraw.Draw(img)
square = 10
for y in range(0, size[1], square):
for x in range(0, size[0], square):
if (x // square + y // square) % 2:
draw.rectangle(
[x, y, x + square, y + square],
fill=(255, 255, 255, 255),
)
return img
def composite_layers(
layers: List[Image.Image],
visibility: List[bool],
) -> Image.Image:
"""Composite visible layers from bottom to top."""
if not layers or not any(visibility):
return Image.new(
"RGBA",
layers[0].size if layers else (400, 400),
(0, 0, 0, 0),
)
result = None
for layer, visible in zip(layers, visibility):
if visible:
result = layer.copy() if result is None else Image.alpha_composite(result, layer)
return result or Image.new("RGBA", layers[0].size, (0, 0, 0, 0))El tablero de ajedrez hace visible la transparencia (convención estándar de los editores de imágenes). La función compuesta refleja lo que hicimos en el cuaderno, ahora impulsada por el estado de la casilla de verificación.
La barra lateral gestiona la configuración de carga y descomposición de imágenes:
with st.sidebar:
st.header("🖼️ Image Upload")
uploaded_file = st.file_uploader(
"Choose an image",
type=["png", "jpg", "jpeg"],
help="Upload an image to decompose",
)
if uploaded_file is not None:
st.session_state.original_image = uploaded_file
st.image(uploaded_file, caption="Uploaded", use_container_width=True)
st.divider()
st.header("⚙️ Settings")
num_layers = st.slider(
"Number of layers",
MIN_LAYERS,
MAX_LAYERS,
DEFAULT_LAYERS,
)
seed = st.number_input(
"Random seed",
0,
999999,
42,
help="For reproducibility",
)
# Decompose button
if st.button(
"🔄 Decompose Image",
disabled=uploaded_file is None,
use_container_width=True,
type="primary",
):
if st.session_state.original_image is not None:
image_bytes = st.session_state.original_image.getvalue()
with st.spinner(f"Decomposing into {num_layers} layers... (30-60s)"):
try:
layer_bytes = decompose_image(image_bytes, num_layers, seed)
st.session_state.layers = [
Image.open(io.BytesIO(lb)).convert("RGBA") for lb in layer_bytes
]
st.session_state.layer_visibility = [True] * len(
st.session_state.layers
)
st.success(
f"Decomposed into {len(st.session_state.layers)} layers!"
)
except Exception as e:
if "502" in str(e):
st.error(
"Replicate API error (502). Try again or use fewer layers."
)
else:
st.error(f"Error: {e}")
# Reset button
if st.session_state.layers and st.button("🗑️ Reset", use_container_width=True):
st.session_state.layers = []
st.session_state.layer_visibility = []
st.session_state.original_image = None
st.rerun()El botón «Descomponer» permanece desactivado hasta que se carga una imagen. Si se realiza correctamente, las capas se almacenan en el estado de la sesión y todas las opciones de visibilidad se establecen de forma predeterminada en True.
Dos columnas muestran los controles de capa y la vista previa en directo:
col1, col2 = st.columns([1, 1]) # two equal-width columns [web:61]
with col1:
st.subheader("📑 Layers")
if not st.session_state.layers:
st.info("Upload an image and decompose to see layers here.")
else:
st.caption("Toggle layers on/off. Layer 0 is the background.")
cols = st.columns(min(len(st.session_state.layers), 4))
for i, layer in enumerate(st.session_state.layers):
with cols[i % 4]:
thumb = layer.copy()
thumb.thumbnail(THUMBNAIL_SIZE)
checkerboard = create_checkerboard(thumb.size)
display = Image.alpha_composite(checkerboard, thumb)
st.image(display, caption=f"Layer {i}", use_container_width=True)
st.session_state.layer_visibility[i] = st.checkbox(
f"Show Layer {i}",
value=st.session_state.layer_visibility[i],
key=f"layer_{i}",
)
with col2:
st.subheader("👁️ Preview")
if not st.session_state.layers:
st.info("Composite preview will appear here.")
else:
composite = composite_layers(
st.session_state.layers,
st.session_state.layer_visibility,
)
visible = sum(st.session_state.layer_visibility)
st.caption(f"Showing {visible} of {len(st.session_state.layers)} layers")
st.image(composite, caption="Composite result", use_container_width=True)
if visible > 0:
buf = io.BytesIO()
composite.save(buf, format="PNG")
st.download_button(
"⬇️ Download Result",
data=buf.getvalue(),
file_name="composite.png",
mime="image/png",
use_container_width=True,
)Cuando desmarcas una capa, Streamlit vuelve a ejecutar el script. La casilla de verificación actualiza layer_visibility, la función compuesta vuelve a calcular la vista previa y la interfaz de usuario se actualiza automáticamente.
Guarda el archivo y ejecuta:
streamlit run streamlit_app.py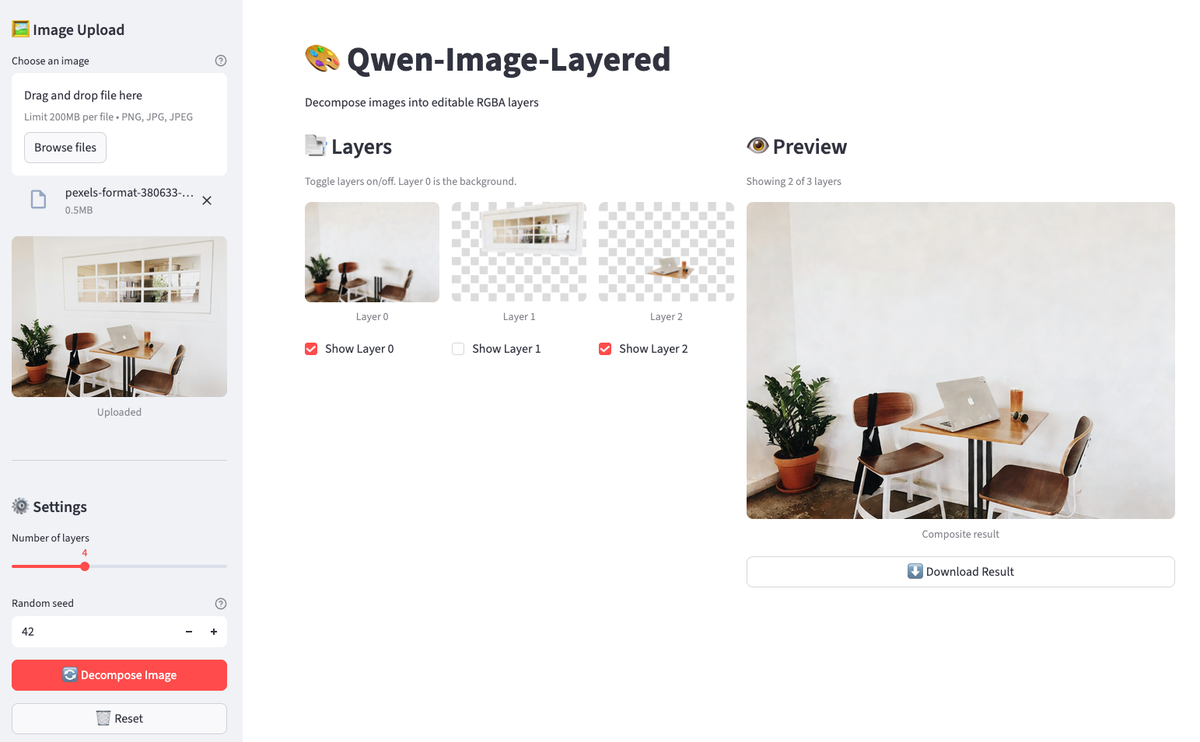
La aplicación tiene una imagen descompuesta. Desactiva las capas para eliminar objetos de la vista previa.
Sube una imagen, haz clic en «Descomponer» y, a continuación, activa y desactiva las capas. La vista previa se actualiza al instante. Descarga el resultado cuando encuentres una composición que te guste. Todo el flujo de trabajo se realiza en el navegador sin necesidad de volver a ejecutar las celdas del cuaderno.
Qwen-Image-Layered adopta un enfoque diferente para la edición de imágenes: en lugar de enmascarar píxeles, separa el contenido en capas RGBA completas con fondos rellenados. Se consigue el aislamiento de objetos sin necesidad de realizar tareas de limpieza. El modelo tiene dificultades con los artefactos de sombra en escenas complejas, pero la extracción de objetos en sí misma funciona bien.
El flujo de trabajo de Python es sencillo. Llama a la API de Replicate, obtén una lista de capas y combínalas con PIL. Los cambios de fondo y la eliminación de objetos se reducen a unas pocas líneas de código. La aplicación Streamlit envuelve esa lógica en una interfaz gráfica de usuario para acelerar la iteración.
Este es el primer modelo de este tipo. El equipo de Qwen lanza actualizaciones rápidamente, por lo que se esperan mejoras en la reconstrucción del fondo y un mejor manejo de las imágenes con muchas sombras. El artículo de investigación cubre la arquitectura si quieres entender cómo funciona la descomposición de capas variables bajo el capó.
¿Estás listo para explorar más modelos de IA de código abierto? Domina el ecosistema detrás de Qwen tomando el curso curso «Fundamentos de Hugging Face» en DataCamp.
Cursos de inteligencia artificial
programa
programa
Curso
Tutorial
Moez Ali
Tutorial
Josef Waples
Tutorial
Natassha Selvaraj
Tutorial
Moez Ali
Tutorial
Duong Vu
Tutorial
Aditya Sharma

