
programa
Fundamentos de la IA
10 h
Qwen3 es una de las suites de modelos de peso abierto más completas publicadas hasta la fecha.
Procede del equipo Qwen de Alibaba e incluye modelos que alcanzan un rendimiento de nivel de investigación, así como versiones más pequeñas que pueden ejecutarse localmente en un hardware más modesto.
En este blog, te daré una rápida visión general del conjunto completo de Qwen3, te explicaré cómo se desarrollaron los modelos, recorreré los resultados de las pruebas comparativas y te mostraré cómo puedes acceder a ellos y empezar a utilizarlos.
Nuestro equipo también está trabajando en tutoriales que muestren cómo ejecutar Qwen3 localmente y cómo afinar los modelos de Qwen3. Me aseguraré de actualizar este artículo en cuanto estén listos, así que si vuelves aquí en los próximos 2-3 días, encontrarás enlaces a esos recursos añadidos en esta introducción.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
Qwen3 es la última familia de grandes modelos lingüísticos del equipo Qwen de Alibaba. Todos los modelos de la gama son de licencia abierta Apache 2.0.
Lo que me llamó la atención de inmediato fue la introducción de un presupuesto pensante que los usuarios pueden controlar directamente dentro de la aplicación Qwen. Esto proporciona a los usuarios normales un control granular sobre el proceso de razonamiento, algo que antes sólo podía hacerse mediante programación.
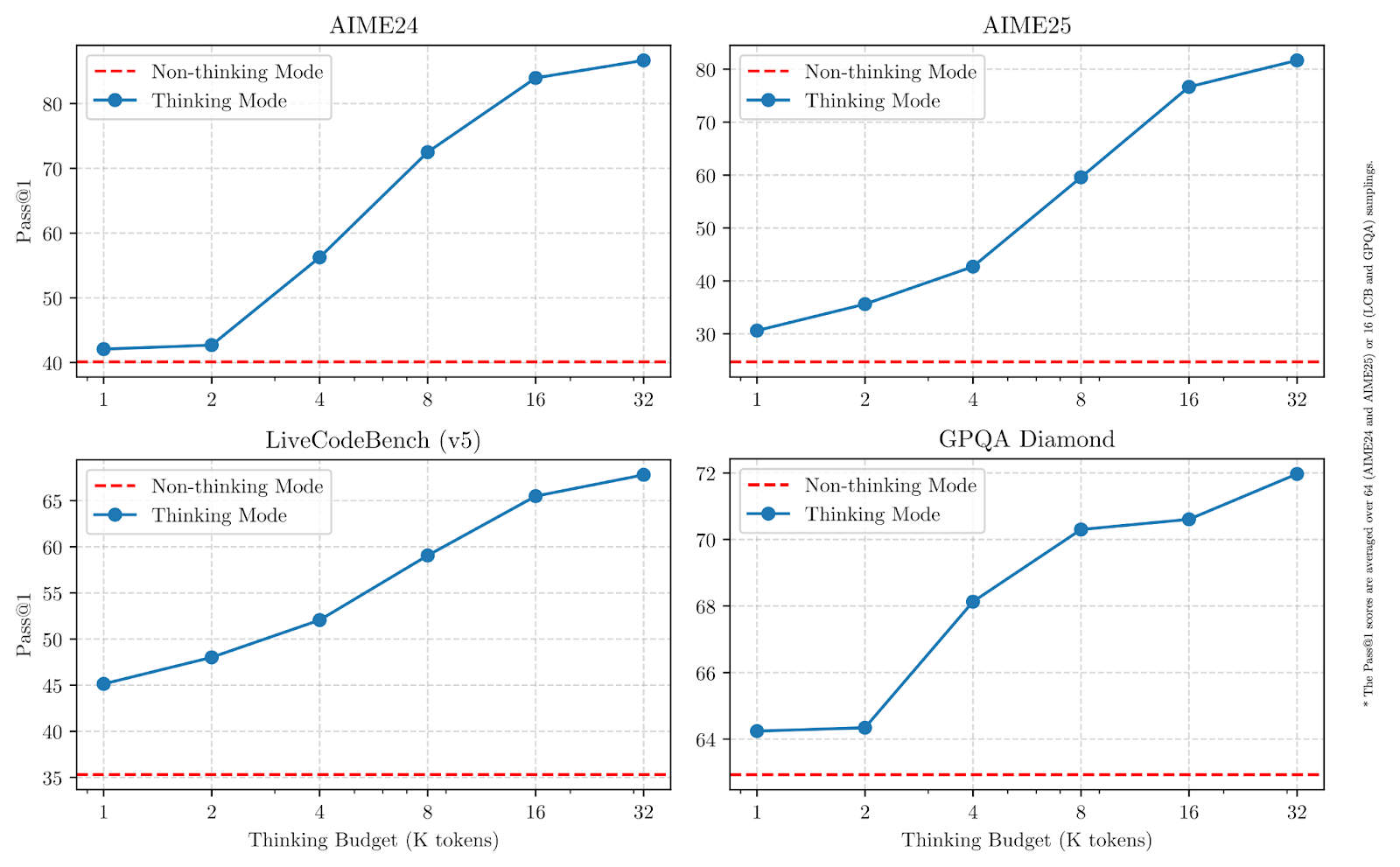
Como podemos ver en los gráficos siguientes, aumentar los presupuestos de pensamiento mejora significativamente el rendimiento, especialmente en matemáticas, codificación y ciencias.
Fuente: Qwen
En las pruebas comparativas, el buque insignia Qwen3-235B-A22B compite con otros modelos de gama alta y obtiene mejores resultados que DeepSeek-R1 en codificación, matemáticas y razonamiento general. Exploremos rápidamente cada modelo y entendamos para qué está diseñado.
Es el modelo más grande de la gama Qwen3. Utiliza una mezcla de expertos (MdE) con 235.000 millones de parámetros totales y 22.000 millones activos por paso de generación.
En un modelo MoE, sólo se activa un pequeño subconjunto de parámetros en cada paso, lo que lo hace más rápido y barato de ejecutar en comparación con los modelos densos (como el GPT-4o), en los que siempre se utilizan todos los parámetros.
El modelo rinde bien en tareas matemáticas, de razonamiento y de codificación, y en las comparaciones de referencia supera a modelos como DeepSeek-R1.
Qwen3-30B-A3B es un modelo MoE más pequeño, con 30.000 millones de parámetros totales y sólo 3.000 millones activos en cada paso. A pesar del bajo recuento de activos, su rendimiento es comparable al de modelos mucho más densos como el QwQ-32B. Es una opción práctica para los usuarios que quieren una mezcla de capacidad de razonamiento y menores costes de inferencia. Al igual que el modelo 235B, admite una ventana contextual de 128K y está disponible bajo Apache 2.0.
Los seis modelos densos de la versión Qwen3 siguen una arquitectura más tradicional, en la que todos los parámetros están activos en cada paso. Cubren una amplia gama de casos de uso:
Qwen3-32B, 14B, 8B admiten ventanas contextuales de 128K, mientras que Qwen3-4B, 1,7B, 0,6B admiten 32K. Todos son de ponderación abierta y tienen licencia Apache 2.0. Los modelos más pequeños de este grupo son adecuados para implantaciones ligeras, mientras que los más grandes se acercan más a los LLM de uso general.
Qwen3 ofrece distintos modelos en función de la profundidad de razonamiento, la velocidad y el coste computacional que necesites. Aquí tienes un resumen rápido de :
|
Modelo |
Tipo |
Contexto Longitud |
Lo mejor para |
|
Qwen3-235B-A22B |
MoE |
128K |
Tareas de investigación, flujos de trabajo de agentes, largas cadenas de razonamiento |
|
Qwen3-30B-A3B |
MoE |
128K |
Razonamiento equilibrado con menor coste de inferencia |
|
Qwen3-32B |
Denso |
128K |
Despliegues de uso general de gama alta |
|
Qwen3-14B |
Denso |
128K |
Aplicaciones de gama media que necesitan un razonamiento sólido |
|
Qwen3-8B |
Denso |
128K |
Tareas de razonamiento ligero |
|
Qwen3-4B |
Denso |
32K |
Aplicaciones más pequeñas, inferencia más rápida |
|
Qwen3-1.7B |
Denso |
32K |
Casos de uso móviles e integrados |
|
Qwen3-0,6B |
Denso |
32K |
Ajustes muy ligeros o restringidos |
Sitrabajas en tareas que requieren un razonamiento más profundo, el uso de herramientas de agente o el manejo de contextos largos, Qwen3-235B-A22B te proporcionará la mayor flexibilidad.
Para los casos en los que quieras mantener la inferencia más rápida y barata sin dejar de manejar tareas moderadamente complejas, Qwen3-30B-A3B es una opción sólida.
Los modelos densos ofrecen despliegues más sencillos y una latencia predecible, lo que los hace más adecuados para aplicaciones a menor escala.
Los modelos Qwen3 se construyeron mediante una fase de preentrenamiento de tres etapas, seguida de un proceso de postentrenamiento de cuatro etapas.
El preentrenamiento es cuando el modelo aprende patrones generales a partir de cantidades masivas de datos (lenguaje, lógica, matemáticas, código) sin que se le diga exactamente lo que tiene que hacer. El post-entrenamiento es donde se afina el modelo para que se comporte de formas específicas, como razonar cuidadosamente o seguir instrucciones.
Recorreré ambas partes en términos sencillos, sin entrar demasiado en detalles técnicos.
En comparación con Qwen2.5, el conjunto de datos de preentrenamiento de Qwen3 se amplió considerablemente. Se utilizaron unos 36 billones de fichas, el doble que en la generación anterior. Los datos incluían contenido web, texto extraído de documentos y ejemplos sintéticos de matemáticas y código generados por modelos Qwen2.5 .
El proceso de formación previa siguió tres etapas:
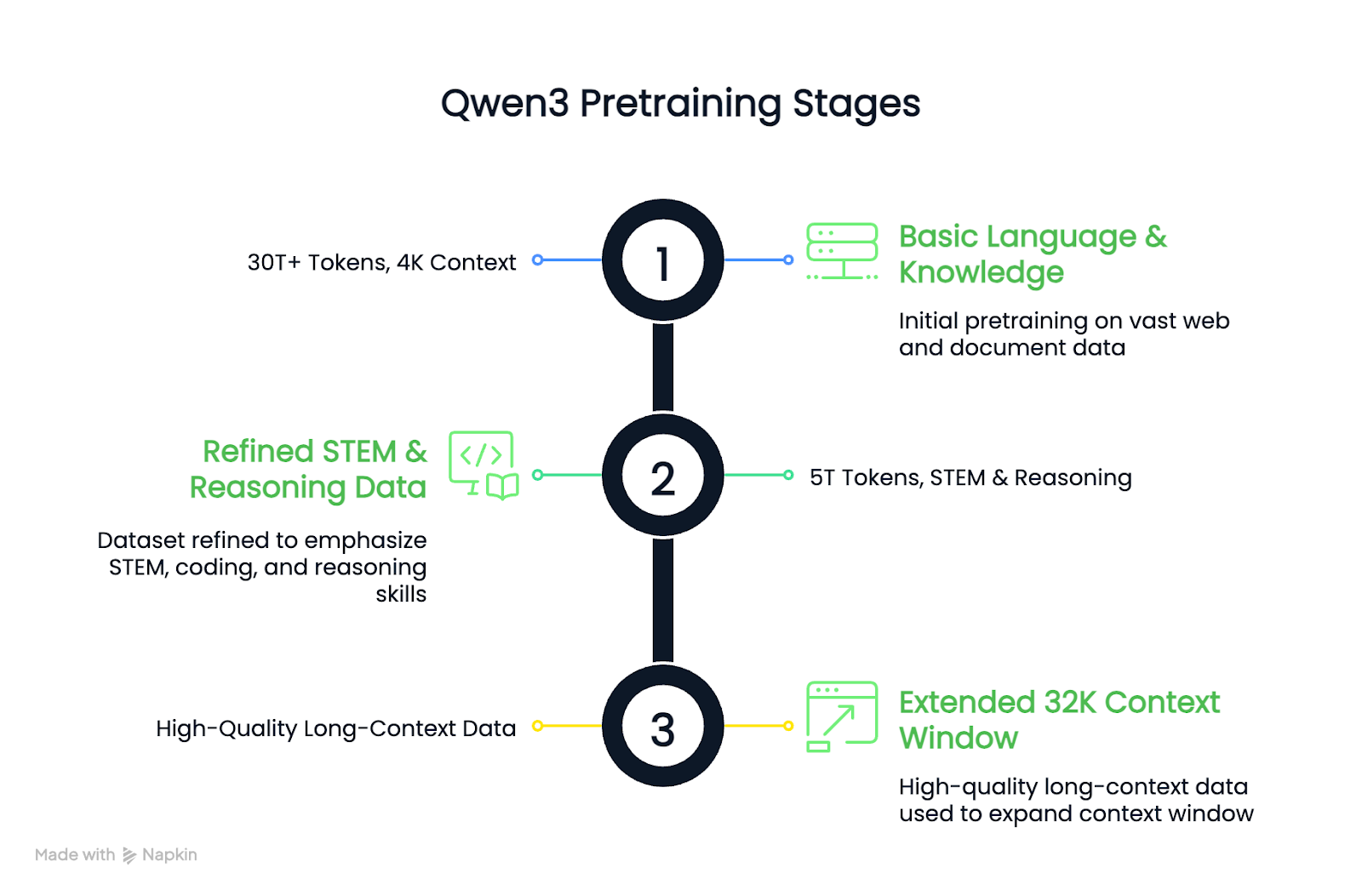
El resultado es que los modelos base Qwen3 densos igualan o superan a los modelos base Qwen2.5 más grandes utilizando menos parámetros, especialmente en las tareas STEM y de razonamiento.
El pipeline de post-entrenamiento de Qwen3 se centró en integrar el razonamiento profundo y las capacidades de respuesta rápida en un único modelo. Primero echemos un vistazo al diagrama de abajo, y luego te lo explicaré paso a paso:
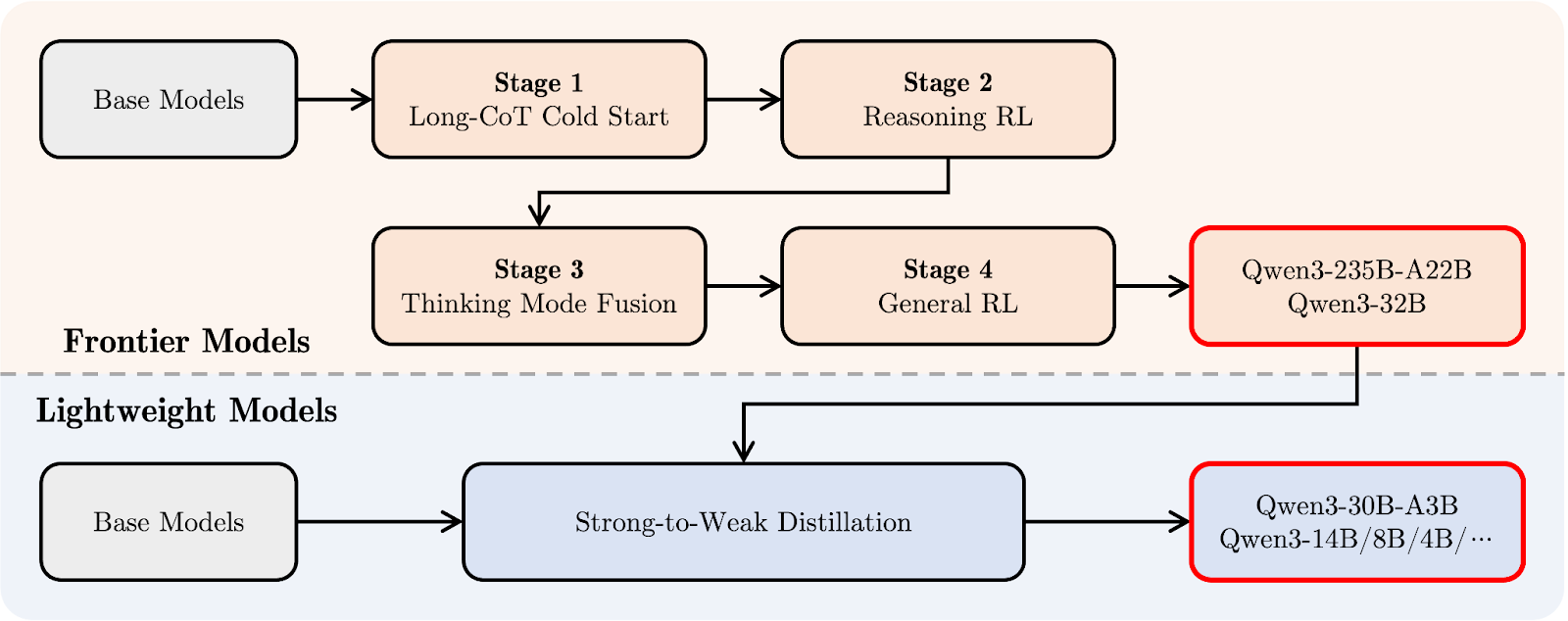
Qwen 3 tubería post-entrenamiento. Fuente: Qwen
En la parte superior (en naranja), puedes ver la ruta de desarrollo de los "modelos frontera" más grandes, como Qwen3-235B-A22B y Qwen3-32B. Comienza con una Larga Cadena de Pensamiento Arranque en frío (etapa 1), en la que el modelo aprende a razonar paso a paso en tareas más difíciles.
Le sigue el Razonamiento Aprendizaje por Refuerzo (RL) (etapa 2) para fomentar mejores estrategias de resolución de problemas. En la etapa 3, denominada Fusión del Modo de Pensamiento, Qwen3 aprende a equilibrar el razonamiento lento y cuidadoso con respuestas más rápidas. Por último, una etapade RL General mejora su comportamiento en una amplia gama de tareas, como el seguimiento de instrucciones y los casos de uso agéntico.
Debajo (en azul claro), verás la ruta para los "Modelos ligeros", como Qwen3-30B-A3B y los modelos densos más pequeños. Estos modelos se entrenan utilizando destilaciónun proceso en el que el conocimiento de los modelos más grandes se comprime en modelos más pequeños y rápidos sin perder demasiada capacidad de razonamiento.
En términos sencillos: primero se entrenaron los modelos grandes y luego se destilaron de ellos los ligeros. De este modo, toda la familia Qwen3 comparte un estilo de pensamiento similar, incluso en modelos de tamaños muy diferentes.
Los modelos Qwen3 se evaluaron en una serie de pruebas de razonamiento, codificación y conocimientos generales. Los resultados muestran que el Qwen3-235B-A22B lidera la gama en la mayoría de las tareas, pero los modelos más pequeños Qwen3-30B-A3B y Qwen3-4B también ofrecen un buen rendimiento.
En la mayoría de las pruebas comparativas, el Qwen3-235B-A22B se encuentra entre los modelos de mejor rendimiento, aunque no siempre es el líder.
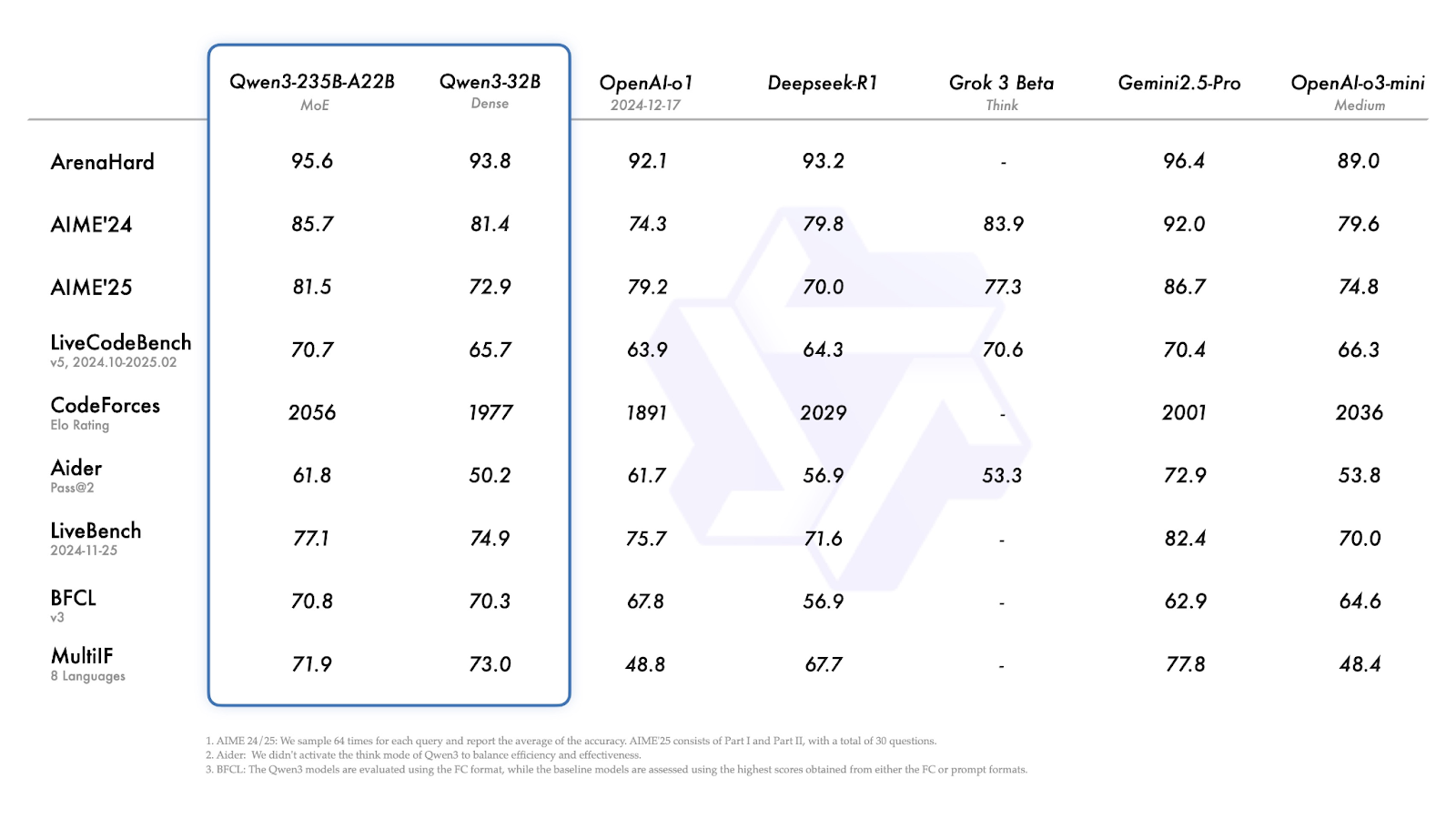
Fuente: Qwen
Exploremos rápidamente los resultados anteriores:
Qwen3-30B-A3B (el modelo MoE más pequeño) obtiene buenos resultados en casi todas las pruebas comparativas, igualando o superando sistemáticamente a los modelos densos de tamaño similar.
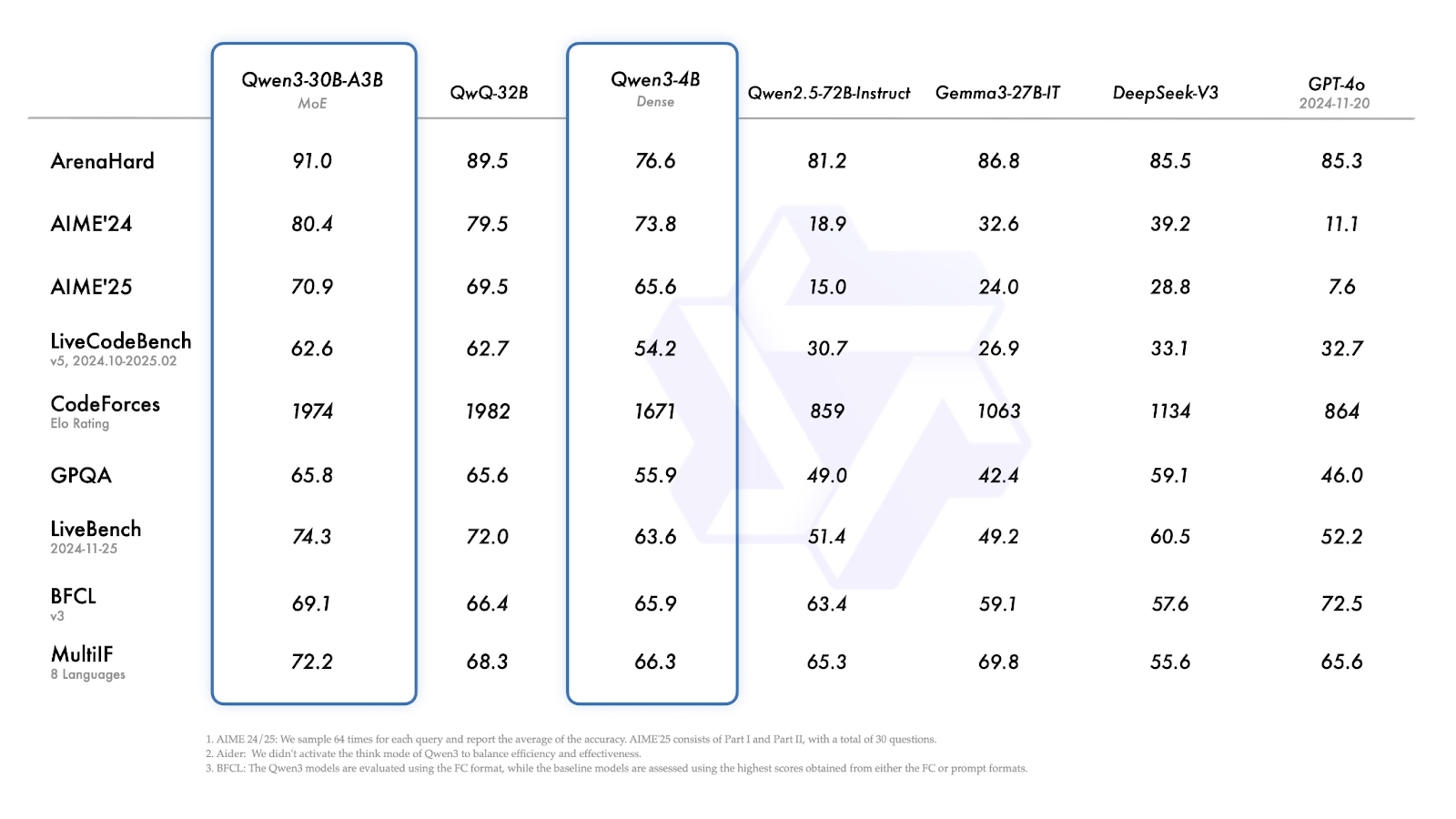
Fuente: Qwen
Qwen3-4B muestra un rendimiento sólido para su tamaño:
Los modelos Qwen3 están disponibles públicamente y pueden utilizarse en la aplicación de chat, a través de la API, descargarse para su despliegue local o integrarse en configuraciones personalizadas.
Puedes probar Qwen3 directamente en chat.qwen.ai.
Sólo podrás acceder a tres modelos de la familia Qwen 3 en la aplicación de chat: Qwen3-235B, Qwen3-30B y Qwen3-32B:
Qwen3 funciona con formatos de API compatibles con OpenAI a través de proveedores como ModelScope o DashScope. Herramientas como vLLM y SGLang ofrecen un servicio eficaz para el despliegue local o autoalojado. El blog oficial de Qwen 3 tiene más detalles al respecto.
Todos los modelos Qwen3 -tanto los MoE como los densos- se publican bajo licencia Apache 2.0. Están disponibles en:
También puedes ejecutar Qwen3 localmente utilizando:
Qwen3 es una de las suites de modelos de peso abierto más completas publicadas hasta la fecha.
El modelo insignia 235B MoE rinde bien en tareas de razonamiento, matemáticas y codificación, mientras que las versiones 30B y 4B ofrecen alternativas prácticas para implantaciones a menor escala o con un presupuesto ajustado. La posibilidad de ajustar el presupuesto de pensamiento del modelo añade una capa extra de flexibilidad para los usuarios habituales.
En su estado actual, Qwen3 es una versión muy completa que cubre una amplia gama de casos de uso y está lista para utilizarse tanto en entornos de investigación como de producción.
Aprende IA con estos cursos
programa
programa
programa
blog
Abid Ali Awan
9 min
blog
Ryan Ong
8 min
blog
Josep Ferrer
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan


