
programa
Científico especializado en machine learning en Python
85 h
El aprendizaje por refuerzo (RL) es un potente paradigma de aprendizaje automático. En la RL, el software, normalmente llamado agente, aprende a interactuar con los entornos para resolver problemas complejos mediante ensayo y error, todo ello sin intervención humana. Entre los algoritmos de RL, SARSA destaca por su eficacia en la política.
SARSA significa Estado-Acción-Recompensa-Estado-Acción, y representa un ciclo que sigue el agente para resolver problemas. Este ciclo permite al agente aprender de sus errores pasados y aventurarse de vez en cuando a probar cosas nuevas. Este comportamiento hace que el algoritmo sea especialmente eficaz en determinados tipos de problemas y lo diferencia de los algoritmos sin política, como el aprendizaje Q.
En este tutorial, aprenderás cómo funciona SARSA y cómo puedes implementarlo en Python. Para concretar tu comprensión, utilizaremos en todo momento un problema clásico de Viaje en Taxi. También hablaremos de las ventajas, limitaciones y aplicaciones reales de SARSA.
SARSA, abreviatura de Estado-Acción-Recompensa-Estado-Acción describe una secuencia de acontecimientos en un proceso de aprendizaje. Es un método de aprendizaje eficaz para que los programas informáticos (agentes) tomen buenas decisiones en diversos escenarios.
La idea principal de SARSA es el ensayo y error. El agente realiza una acción en una situación, observa el resultado y ajusta su estrategia en función del resultado (bueno o malo). Este proceso se repite muchas veces, lo que conduce a mejoras en las decisiones del agente a lo largo del tiempo.
Lo que hace especial a SARSA entre los algoritmos de RL es que SARSA aprende de las elecciones reales que hace el agente, incluso cuando está probando cosas nuevas. Este enfoque es especialmente útil cuando el camino de aprendizaje es tan importante como el resultado final.
Es como si un robot aprendiera a montar en bicicleta conduciéndola de verdad, con caídas y todo, en lugar de encontrar el camino más corto de A a B utilizando ruedas de entrenamiento protectoras.
En este tutorial, utilizaremos ampliamente Numpy y la biblioteca de aprendizaje por refuerzo Gymnasium. Mientras que Numpy nos ayudará a escribir el algoritmo SARSA, Gymnasium nos proporciona entornos integrados para probar nuestro trabajo.
Vamos a instalarlos en un nuevo entorno virtual con los siguientes comandos:
$ conda create -n sarsa python=3.9 -y
$ conda activate sarsa
$ pip install "gymnasium[atari]" numpy matplotlib
$ pip install autorom[accept-rom-license] # Downloading Gym env data files
$ AutoROM --accept-license # Accepting the license for data files
$ pip install ipykernel # Install Jupyter kernel manager
$ ipython kernel install --user --name=sarsa # Add the new Conda env to JupyterAntes de continuar, te recomiendo encarecidamente que leas nuestra Introducción al aprendizaje por refuerzo artículo. Abarca las ideas fundamentales de la RF, como los agentes, los entornos, el dilema exploración versus explotación y el aprendizaje Q.
A lo largo del tutorial, utilizaremos el entorno Taxi-v3, que es un problema clásico de aprendizaje por refuerzo proporcionado por la biblioteca Gymnasium. Simula un taxista que navega por un mundo cuadriculado de 5x5 para recoger y dejar pasajeros.
Para cargar el entorno, utilizamos el método .make() de Gimnasio con un rgb_array modo de renderizado (para visualizar el entorno más tarde):
import gymnasium as gym
env = gym.make('Taxi-v3', render_mode='rgb_array')El entorno es una cuadrícula de 5x5 con cuatro ubicaciones designadas: rojo (R), verde (G), amarillo (Y) y azul (B). El taxi parte de una casilla aleatoria y debe recoger a un pasajero en uno de los lugares de color y dejarlo en otro.
El taxi puede moverse hacia el Norte, Sur, Este u Oeste y también puede intentar recoger o dejar a un pasajero.
He aquí cómo podemos visualizar el estado inicial del entorno con Matplotlib:
import matplotlib.pyplot as plt
# Reset the environment to get an initial state
# Each time we reset the environment, we get a new random state
initial_state, _ = env.reset()
# Render the initial state
img = env.render()
# Create a figure and display the environment
fig, ax = plt.subplots(figsize=(8, 8))
ax.imshow(img)
# Remove axis ticks
ax.set_xticks([])
ax.set_yticks([]);
Primero, reiniciamos el entorno para obtener un estado inicial. A continuación, mostramos este estado inicial con la función render, recibiendo una matriz de imágenes Numpy. La función imshow() de Matplotlib toma esta matriz y produce una visualización limpia sin marcas en los ejes.
Tómate un momento para comprender la disposición del mundo cuadriculado de Taxi-v3, fijándote en la posición del taxi, las barreras, la ubicación de los pasajeros y el destino.
El agente (el taxi) recibe +20 puntos por dejar con éxito a un pasajero. Recoger o dejar objetos ilegalmente conlleva una recompensa de -10. Todo el tiempo, cada paso temporal produce -1 recompensa para animar al taxi a completar la tarea rápidamente.
Un episodio del entorno Taxi-v3 finaliza en caso de que se produzca un abandono o cuando se alcance el número máximo de pasos temporales.
# The number of states and actions
n_states = env.observation_space.n
n_actions = env.action_space.n
print(n_states)
print(n_actions)500
6Hay 500 estados en el espacio de estados del entorno. Cada estado está representado por:
Los códigos de acción son:
El objetivo es que el agente aprenda una política óptima para maximizar su recompensa total recogiendo y dejando pasajeros de forma eficiente.
Antes de escribir el algoritmo completo, veamos cómo funciona el ciclo Estado-Acción-Recompensa-Estado-Acción utilizando nuestro entorno.
Primero, definimos cuántos episodios queremos que continúe la interacción. Un episodio representa una ejecución completa de la tarea de taxi, desde el estado inicial hasta que se consigue dejar al pasajero o se alcanza el número máximo de pasos temporales. Cada episodio permite al agente aprender de sus experiencias y mejorar su estrategia con el tiempo.
n_episodes = 5000Ahora escribimos el bucle de interacción:
for episode in range(n_episodes):
state, _ = env.reset()
done = False
total_reward = 0
steps = 0
while not done:
# Choose a random action
action = env.action_space.sample()
# Take the action and observe the result
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# Update total reward and step count
total_reward += reward
steps += 1
# Move to the next state
state = next_state
if episode % 1000 == 0:
print(f"Episode {episode}, Total Reward: {total_reward}, Steps: {steps}")Episode 0, Total Reward: -812, Steps: 200
Episode 1000, Total Reward: -830, Steps: 200
Episode 2000, Total Reward: -902, Steps: 200
Episode 3000, Total Reward: -522, Steps: 129
Episode 4000, Total Reward: -767, Steps: 200El código anterior demuestra el ciclo básico de interacción SARSA sin implementar ningún algoritmo de aprendizaje:
env.reset().env.step(action). Esta versión utiliza acciones aleatorias para demostrar el bucle de interacción.next_state, reward, ... = env.take(action).En el bucle de interacción anterior, el taxi sigue moviéndose por el entorno en todas direcciones y realizando acciones aleatorias hasta que se agotan los pasos de tiempo.
Antes de continuar, vamos a implementar una función para animar nuestros bucles de interacción. Esto nos permite ver visualmente al taxi interactuando con el entorno.
Crear la animación será un proceso sencillo:
env.render() funciónmoviepyconcatenamos todas las matrices de imágenes para crear un único GIF.Modifiquemos el código:
env = gym.make("Taxi-v3", render_mode="rgb_array")
n_episodes = 1
frames = [] # for animation
for episode in range(n_episodes):
# Reset the environment
state, _ = env.reset()
# Capture the state as an image
img = env.render()
frames.append(img)
done = False
total_reward = 0
steps = 0
while not done:
# Choose a random action
action = env.action_space.sample()
# Take the action and observe the result
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# Capture the next state as an image
img = env.render()
frames.append(img)
# Update total reward and step count
total_reward += reward
steps += 1
# Move to the next state
state = next_stateEn esta versión, fijamos el número de episodios en sólo uno, ya que renderizar los estados del entorno como imágenes lleva demasiado tiempo. También creamos una lista vacía para almacenar nuestras matrices de imágenes. Después, el bucle de interacción continúa como antes. La única diferencia son las dos líneas de código adicionales en las que representamos el entorno como una imagen y lo añadimos a frames.
Ahora, debemos tener 201 imágenes dentro de los marcos (una imagen extra para el estado adicional):
>>> len(frames)
201Convirtamos estas imágenes en un GIF utilizando moviepy biblioteca:
from moviepy.editor import ImageSequenceClip # pip install moviepy
def create_gif(frames: list, filename, fps=5):
"""
Creates a GIF animation from a list of RGBA NumPy arrays.
Args:
frames: A list of RGBA NumPy arrays representing the animation frames.
filename: The output filename for the GIF animation.
fps: The frames per second of the animation (default: 10).
"""
clip = ImageSequenceClip(frames, fps=fps)
clip.write_gif(filename, fps=fps)
# Example usage
create_gif(frames, "animation.gif", fps=25) # saves the GIF locallyLa función create_gif() toma una lista de fotogramas y los convierte en un GIF utilizando la clase ImageSequenceClip de moviepy. Un parámetro importante son los fotogramas por segundo, fps, que controlan la duración del GIF. Cuantos más fotogramas por segundo, más corto será el GIF.
Al final, convertimos los fotogramas de un episodio en un GIF a 25 FPS. He aquí el resultado:
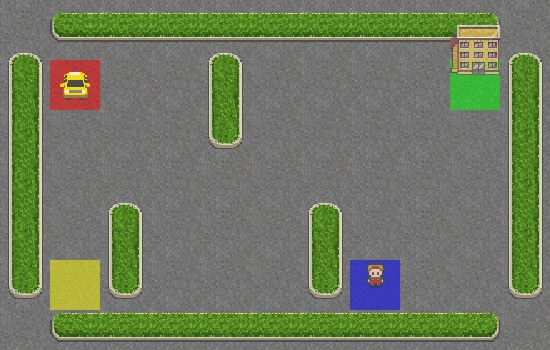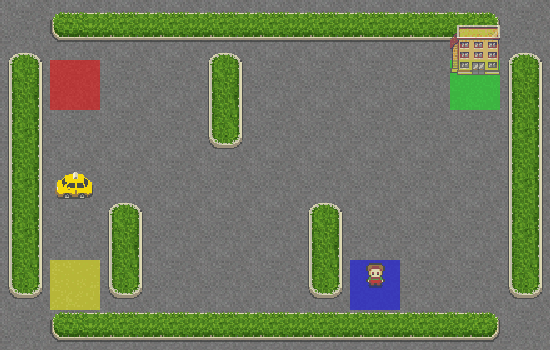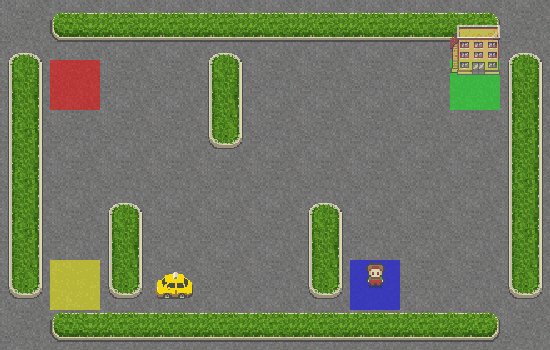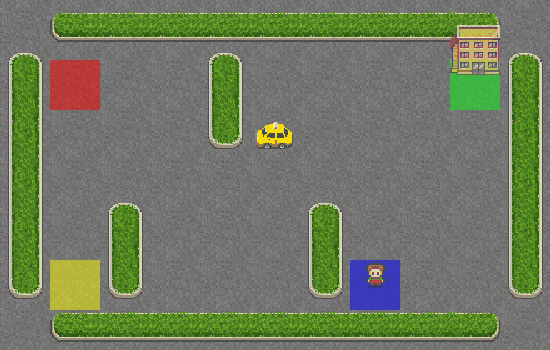
Como puedes ver, el taxi no tiene ni idea de lo que hace y ni siquiera se acercó al pasajero. Démosle un poco de cerebro añadiendo SARSA a su sistema de navegación.
Construiremos el código de SARSA desde cero para que recuerdes cada paso con claridad.
1. Configurar el entorno del Gimnasio:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
# Create the Taxi environment
env = gym.make("Taxi-v3", render_mode="rgb_array")2. Inicializar una tabla Q
# Initialize Q-table
n_states = env.observation_space.n
n_actions = env.action_space.n
Q_table = np.zeros((n_states, n_actions))En este paso, introducimos una nueva estructura de datos: la tabla Q. Tiene las dimensiones (número de estados) x (número de acciones). La mesa tendría este aspecto para nuestro agente, el taxista:
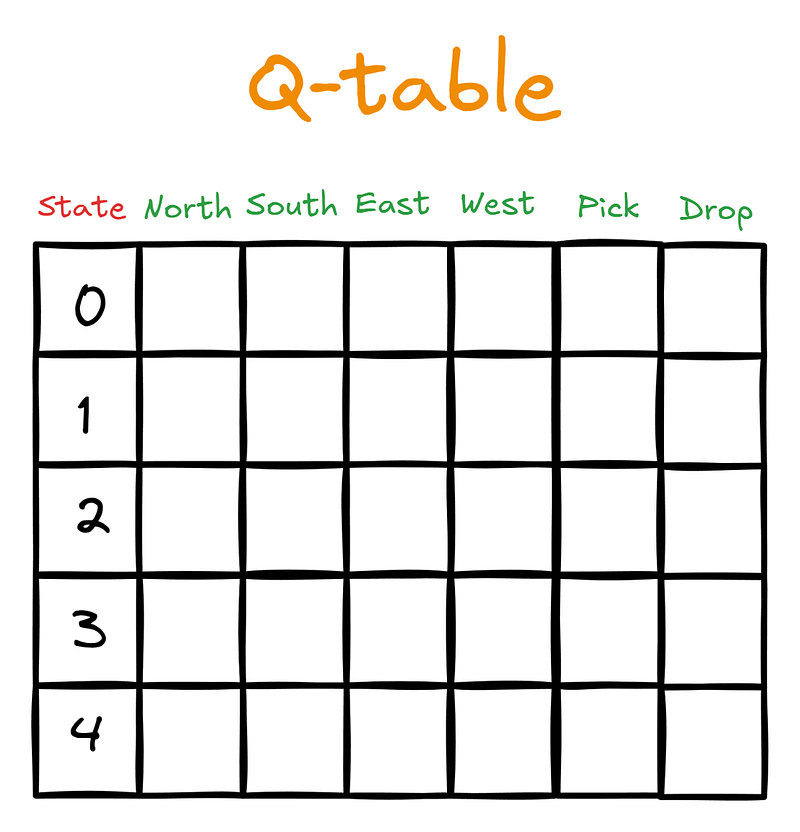
Inicialmente, la tabla Q se rellenará con ceros:
>>> Q_table.shape
(500, 6)Después, cuando el agente empiece a interactuar con el entorno guiado por SARSA, actualizará la tabla Q con los valores Q. Los valores Q son puntuaciones que indican al agente qué acción es la mejor que puede realizar, dado el estado actual.
3. Definición de los hiperparámetros SARSA
Tras inicializar la tabla Q, fijamos los hiperparámetros de SARSA en valores comunes (más adelante hablaremos de ellos):
# SARSA parameters
alpha = 0.1 # Learning rate
gamma = 0.99 # Discount factor
epsilon = 0.1 # Exploration rate for epsilon-greedy policy
n_episodes = 200004. Definir el almacenamiento para las métricas de rendimiento
A continuación, definimos dos listas para almacenar las métricas de rendimiento: la recompensa total y el número de pasos temporales de cada episodio. El objetivo del agente es recoger la mayor cantidad de recompensa posible en el menor tiempo posible:
# Lists to store performance metrics
episode_rewards = []
episode_lengths = []5. Política Epsilon-greedy para tomar medidas
En la sección anterior, nuestro agente no estaba guiado: realizaba acciones aleatorias. Queremos cambiar eso dando al conductor una estrategia Epsilon-Greedy:
def epsilon_greedy(state, epsilon):
if np.random.random() < epsilon:
# Take random action - explore
return env.action_space.sample()
else:
# Take action with the highest Q-value - exploit
return np.argmax(Q_table[state])Esta estrategia pretende controlar el equilibrio crucial entre exploración y explotación. Con la probabilidad epsilon, el agente explora el entorno realizando una acción aleatoria, mientras que con la probabilidad 1-epsilon, explota su conocimiento actual eligiendo la acción con el valor Q más alto de la tabla Q. Este enfoque permite al agente descubrir nuevas estrategias, potencialmente mejores, a la vez que utiliza lo que ya ha aprendido.
6. Escribir el bucle de formación SARSA
Por último, escribimos el bucle de entrenamiento SARSA. El principio del bucle ya nos es familiar. La única diferencia es que utilizamos la función epsilon_greedy() para que nos diga qué acción realizar en el estado actual:
# SARSA training loop
for episode in range(n_episodes):
state, _ = env.reset()
action = epsilon_greedy(state, epsilon)
done = False
total_reward = 0
steps = 0
...A continuación, iniciamos el bucle while bucle que nos permite ejecutar el ciclo de interacción hasta alcanzar un estado de terminación:
# SARSA training loop
for episode in range(n_episodes):
...
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
next_action = epsilon_greedy(next_state, epsilon)Dentro del bucle while tomamos la acción devuelta por epsilon_greedy() y recibimos el siguiente estado, la recompensa por nuestra acción y un valor booleano para saber si el episodio ha terminado o no.
A continuación, llegamos a la parte crucial: la regla de actualización de SARSA:
# SARSA training loop
for episode in range(n_episodes):
...
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
next_action = epsilon_greedy(next_state, epsilon)
# SARSA update rule
Q_table[state, action] += alpha * (
reward + gamma * Q_table[next_state, next_action] - Q_table[state, action]
)La regla de actualización procede de la siguiente fórmula:
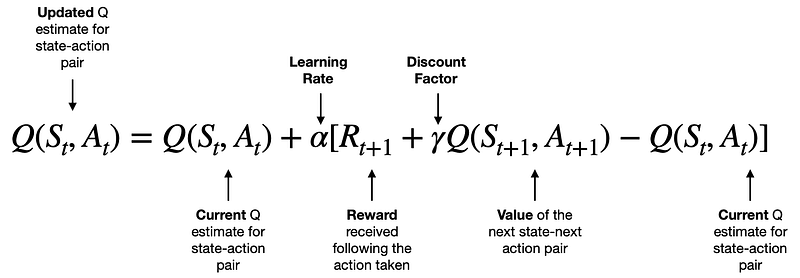
[Source]
Aprenderemos la intuición que hay detrás de esta fórmula en el siguiente apartado. En este momento, considera la fórmula como algo de magia matemática que actualiza los valores Q de nuestra tabla Q según las reglas de SARSA.
Una vez realizada la actualización Q, cambiamos el state y action por el estado y la acción resultantes, añadimos la recompensa recibida a la recompensa total del episodio y aumentamos el número de pasos temporales.
# SARSA training loop
for episode in range(n_episodes):
...
while not done:
...
state = next_state
action = next_action
total_reward += reward
steps += 1El bucle while continúa hasta que alcanzamos el máximo de pasos de tiempo (200 para el entorno del taxi) o cuando el taxi deja con éxito a su pasajero en el lugar correcto.
Una vez finalizado el bucle, registramos la recompensa total por episodio y la duración del episodio. También imprimimos la recompensa y la duración medias de los episodios cada 1000 episodios:
# SARSA training loop
for episode in range(n_episodes):
...
while not done:
...
episode_rewards.append(total_reward)
episode_lengths.append(steps)
if episode % 1000 == 0:
avg_reward = np.mean(episode_rewards[-1000:])
avg_length = np.mean(episode_lengths[-1000:])
print(f"Episode {episode}, Avg Reward: {avg_reward:.2f}, Avg Length: {avg_length:.2f}")Aquí tienes el bucle de interacción completo ejecutado:
# SARSA training loop
for episode in range(n_episodes):
state, _ = env.reset()
action = epsilon_greedy(state, epsilon)
done = False
total_reward = 0
steps = 0
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
next_action = epsilon_greedy(next_state, epsilon)
Q_table[state, action] += alpha * (
reward + gamma * Q_table[next_state, next_action] - Q_table[state, action]
)
state = next_state
action = next_action
total_reward += reward
steps += 1
episode_rewards.append(total_reward)
episode_lengths.append(steps)
if episode % 2000 == 0:
avg_reward = np.mean(episode_rewards[-1000:])
avg_length = np.mean(episode_lengths[-1000:])
print(f"Episode {episode}, Avg Reward: {avg_reward:.2f}, Avg Length: {avg_length:.2f}")Episode 0, Avg Reward: -551.00, Avg Length: 185.00
Episode 2000, Avg Reward: -4.37, Avg Length: 19.47
Episode 4000, Avg Reward: 1.98, Avg Length: 15.09
Episode 6000, Avg Reward: 2.29, Avg Length: 14.79
Episode 8000, Avg Reward: 2.06, Avg Length: 14.80
Episode 10000, Avg Reward: 2.16, Avg Length: 14.78
Episode 12000, Avg Reward: 2.06, Avg Length: 14.89
Episode 14000, Avg Reward: 2.33, Avg Length: 14.81
Episode 16000, Avg Reward: 2.36, Avg Length: 14.66
Episode 18000, Avg Reward: 2.53, Avg Length: 14.72Como puedes ver en el resultado, la recompensa media y el número de pasos temporales por episodio disminuyeron drásticamente a medida que ejecutábamos más y más episodios.
Podemos comprobarlo visualmente trazando la curva episode_rewards y episode_lengths matrices:
# Plot the learning curve
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(episode_rewards)
plt.title("Episode Rewards")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.subplot(1, 2, 2)
plt.plot(episode_lengths)
plt.title("Episode Lengths")
plt.xlabel("Episode")
plt.ylabel("Number of Steps")
plt.tight_layout()
plt.show()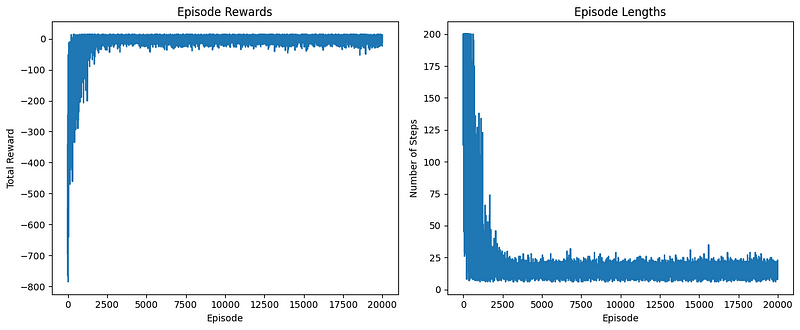
El gráfico de la izquierda muestra la recompensa total obtenida en cada episodio. Podemos observar que:
El gráfico de la derecha muestra el número de pasos dados en cada episodio. Podemos verlo:
En poco tiempo, hemos cubierto mucho terreno. Demos ahora un paso atrás y organicemos todo lo que hemos escrito. Crearemos funciones para cada uno de los pasos que dimos para implantar SARSA.
En primer lugar, una función para crear un entorno:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from moviepy.editor import ImageSequenceClip
def create_environment(env_name="Taxi-v3", render_mode="rgb_array"):
"""Create and return a Gymnasium environment."""
return gym.make(env_name, render_mode=render_mode)A continuación, una función para inicializar una tabla Q dado un entorno:
def initialize_q_table(env):
"""Initialize and return a Q-table for the given environment."""
n_states = env.observation_space.n
n_actions = env.action_space.n
return np.zeros((n_states, n_actions))La estrategia Epsilon-greedy que acepta un entorno, una tabla Q, el estado actual y epsilon:
def epsilon_greedy(env, Q_table, state, epsilon=0.1):
"""Epsilon-greedy action selection."""
if np.random.random() < epsilon:
return env.action_space.sample()
else:
return np.argmax(Q_table[state])La regla de actualización de SARSA, que requiere una tabla Q, el estado actual, la acción realizada en ese estado, la recompensa por la acción, el estado y la acción siguientes:
def sarsa_update(Q_table, state, action, reward, next_state, next_action, alpha, gamma):
"""Perform SARSA update on Q-table."""
Q_table[state, action] += alpha * (
reward + gamma * Q_table[next_state, next_action] - Q_table[state, action]
)Por último, una gran función para entrenar al agente con SARSA que requiere un entorno, el número de episodios a ejecutar y los parámetros alfa, gamma y épsilon:
def train_sarsa(env, n_episodes=20000, alpha=0.1, gamma=0.99, epsilon=0.1):
"""Train the agent using SARSA algorithm."""
Q_table = initialize_q_table(env)
episode_rewards = []
episode_lengths = []
for episode in range(n_episodes):
state, _ = env.reset()
action = epsilon_greedy(env, Q_table, state, epsilon)
done = False
total_reward = 0
steps = 0
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
next_action = epsilon_greedy(env, Q_table, next_state, epsilon)
sarsa_update(
Q_table, state, action, reward, next_state, next_action, alpha, gamma
)
state = next_state
action = next_action
total_reward += reward
steps += 1
episode_rewards.append(total_reward)
episode_lengths.append(steps)
return Q_table, episode_rewards, episode_lengthsAdemás, una función para trazar métricas de rendimiento:
def plot_learning_curve(episode_rewards, episode_lengths):
"""Plot the learning curve."""
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(episode_rewards)
plt.title("Episode Rewards")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.subplot(1, 2, 2)
plt.plot(episode_lengths)
plt.title("Episode Lengths")
plt.xlabel("Episode")
plt.ylabel("Number of Steps")
plt.tight_layout()
plt.show()Nuestra anterior create_gif() función:
def create_gif(frames, filename, fps=5):
"""Creates a GIF animation from a list of frames."""
clip = ImageSequenceClip(frames, fps=fps)
clip.write_gif(filename, fps=fps)Y otra función para ejecutar un único episodio con renderizado utilizando una tabla Q completa y aprendida (con fines de animación):
def run_episode(env, Q_table, epsilon=0):
"""Run a single episode using the learned Q-table."""
state, _ = env.reset()
done = False
total_reward = 0
frames = [env.render()]
while not done:
action = epsilon_greedy(env, Q_table, state, epsilon)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
frames.append(env.render())
total_reward += reward
state = next_state
return frames, total_rewardAhora, vamos a ejecutarlo todo:
if __name__ == "__main__":
env = create_environment()
Q_table, episode_rewards, episode_lengths = train_sarsa(env, n_episodes=20000)
plot_learning_curve(episode_rewards, episode_lengths)
frames, total_reward = run_episode(env, Q_table)
create_gif(frames, "images/sarsa_final_animation.gif", fps=1)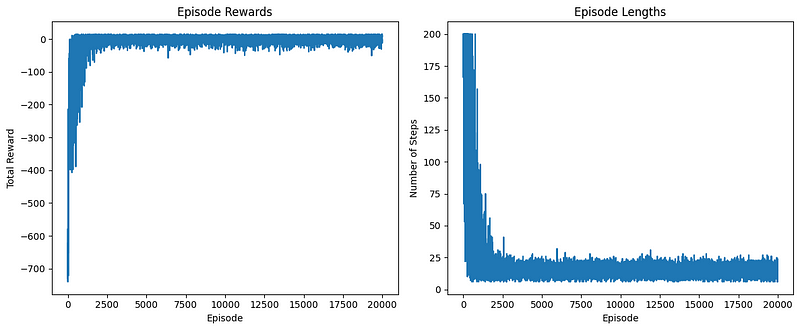
Los gráficos de rendimiento tienen buen aspecto. Ahora, veamos el GIF generado:
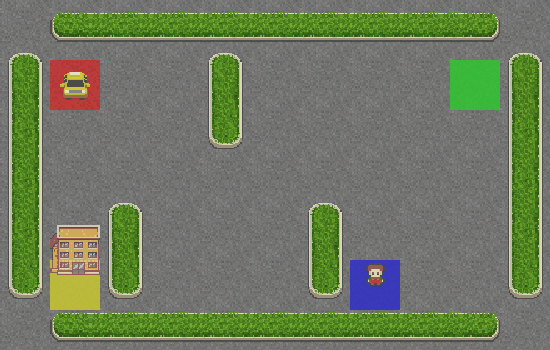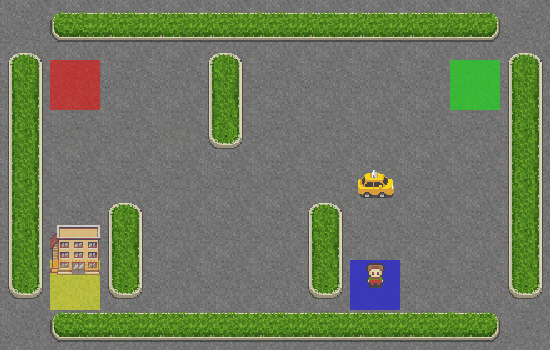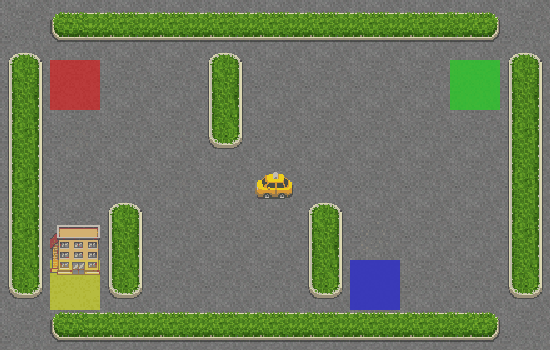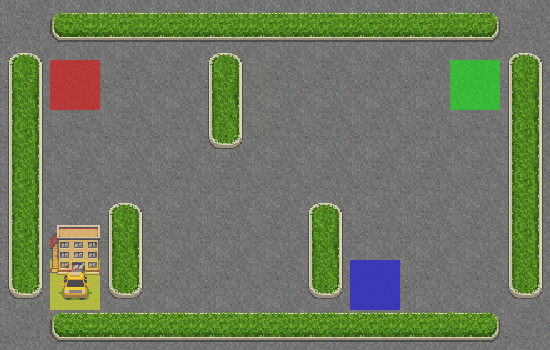
¡Hurra! El taxi recoge correctamente al pasajero en el cuadrado azul y lo deja en el cuadrado amarillo.
He pegado el todo el código organizado para implementar SARSA en un gist de GitHub para que puedas volver a él cuando quieras.
En el corazón de SARSA se encuentra su regla de actualización, que controla cómo aprende el agente de sus experiencias. Desglosemos esta regla y exploremos la intuición que hay detrás de ella:
Q(s, a) = Q(s, a) + α [R + γ Q(s', a') - Q(s, a)].
La regla de actualización de SARSA pretende refinar la comprensión del entorno por parte del agente ajustando los valores Q en función de las nuevas experiencias. Funciona así:
El término [R + γ * Q(s', a') - Q(s, a)] se conoce como error de diferencia temporal (TD). Piensa en ello como una medida de sorpresa:
Este error ayuda al agente a refinar continuamente sus estimaciones, impulsando el proceso de aprendizaje hacia una política óptima.
1. Tasa de aprendizaje (α):
2. Factor de descuento (γ):
3. Tasa de exploración (ε):
La regla de actualización de SARSA permite al agente aprender de sus experiencias ajustando constantemente sus estimaciones de los valores estado-acción. Con cada interacción, el agente se vuelve un poco más sabio sobre su entorno. A lo largo de muchos episodios, este proceso conduce al desarrollo de una política óptima para navegar por el entorno.
Afinando los hiperparámetros, podemos controlar varios aspectos del proceso de aprendizaje, lo que permite a SARSA adaptarse a distintos tipos de problemas y entornos. Esta flexibilidad, combinada con su intuitiva regla de actualización, hace de SARSA un algoritmo de aprendizaje por refuerzo potente y muy utilizado.
Aunque SARSA y Q-learning son algoritmos de aprendizaje por refuerzo muy utilizados, tienen algunas diferencias importantes. Y esas diferencias son fundamentales para comprender cuándo y cómo utilizar cada algoritmo.
Un algoritmo sobre política, SARSA, aprende el valor de la política que sigue, incluyendo incluso los pasos dados durante la exploración. El aprendizaje Q está fuera de la política; aprende el valor de la política óptima; incluso cuando no sigue esa política, sigue aprendiendo el valor de la política óptima cuando finalmente llega al final del episodio. Por eso mencionamos al principio que SARSA debe utilizarse cuando el viaje de aprendizaje es tan importante como el propio resultado. Al Q-learning no le importa mucho el itinerario de aprendizaje.
La diferencia clave es que SARSA utiliza el valor Q de la siguiente acción realmente realizada (a'), mientras que el aprendizaje Q utiliza el valor Q máximo del siguiente estado (max(Q(s', a')).
Al actualizar los valores Q, SARSA no ignora la política de exploración y, por tanto, es más conservador. En comparación, el aprendizaje Q siempre supone que el agente realizará la acción óptima en el futuro y, por tanto, es más agresivo.
Aunque ambos algoritmos alcanzan finalmente la política óptima, el aprendizaje Q a menudo puede aprender más rápidamente, sobre todo en entornos deterministas.
En entornos en los que la exploración puede conducir a malos resultados, SARSA suele aprender políticas más seguras porque tiene en cuenta la política real que se sigue.
En el problema clásico de "caminar por el acantilado", SARSA suele aprender un camino más seguro que se aleja del borde del acantilado, mientras que Q-learning podría aprender un camino más arriesgado que camina por el borde.
En ciertos entornos aleatorios, SARSA puede ser más estable porque tiene en cuenta la acción siguiente real, incluso cuando esa acción es una acción exploratoria subóptima.
El aprendizaje Q puede ser más sensible a la elección de la tasa de aprendizaje y la tasa de exploración, especialmente en entornos con una estocasticidad significativa.
Cuando se trata de robótica u otros sistemas físicos en los que explorar el entorno es costoso y queremos aplicar políticas más seguras, podríamos preferir el algoritmo sobre políticas SARSA. Cuando estamos en el mundo simulado, en juegos o en otros entornos en los que podemos obtener mucha retroalimentación y en los que queremos encontrar la política óptima de una forma que sea rápida y algo segura, puede que nos guste mucho más el aprendizaje Q.
Así que podrías pensar que SARSA es una especie de provincia más segura, y Q-learning es el enfoque más rápido y temerario. En la práctica, suele depender del problema concreto. Ambos algoritmos son muy potentes, y siempre tiene sentido saber cuáles son las diferencias entre ellos.
En esta completa guía, hemos explorado el algoritmo SARSA, cubriendo sus conceptos básicos, detalles de implementación y aplicaciones prácticas utilizando el entorno Taxi-v3.
Los puntos clave son:
La capacidad de SARSA para aprender políticas más seguras lo hace adecuado para aplicaciones del mundo real en las que los costes de exploración son elevados, aunque puede converger más lentamente que los algoritmos sin políticas, como el aprendizaje Q, en algunos escenarios.
Recuerda que elegir entre SARSA y otros algoritmos depende de tu problema y entorno específicos. La experimentación y el ajuste son cruciales para obtener resultados óptimos.
Te animamos a que amplíes esta base explorando entornos más complejos, implementando SARSA con aproximación de funciones o sumergiéndote en otros algoritmos de aprendizaje por refuerzo.
Aquí tienes algunos recursos relacionados que te ayudarán en el camino:
Los mejores cursos de DataCamp
programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Moez Ali
