
Programa
Cientista de machine learning em Python
85 h
O aprendizado por reforço (RL) é um poderoso paradigma de aprendizado de máquina. Na RL, o software, geralmente chamado de agente, aprende a interagir com ambientes para resolver problemas complexos por meio de tentativa e erro, tudo sem intervenção humana. Entre os algoritmos de RL, o SARSA se destaca por sua natureza eficiente na política.
SARSA significa State-Action-Reward-State-Action (Estado-Ação-Recompensa-Estado-Ação), representando um ciclo que o agente segue para resolver problemas. Esse ciclo permite que o agente aprenda com os erros do passado e, ocasionalmente, se aventure a tentar coisas novas. Esse comportamento torna o algoritmo particularmente eficaz em tipos de problemas específicos e o diferencia dos algoritmos fora da política, como o Q-learning.
Neste tutorial, você aprenderá como funciona a SARSA e como implementá-la em Python. Para que você entenda melhor, usaremos um problema clássico de Taxi Ride durante todo o processo. Também discutiremos as vantagens, limitações e aplicações reais da SARSA.
SARSA, abreviação de State-Action-Reward-State-Action (Estado-Ação-Recompensa-Estado-Ação), descreve uma sequência de eventos em um processo de aprendizagem. É um método de aprendizado eficaz para que os programas de computador (agentes) tomem boas decisões em vários cenários.
A principal ideia por trás da SARSA é a tentativa e erro. O agente realiza uma ação em uma situação, observa o resultado e ajusta sua estratégia com base no resultado (bom ou ruim). Esse processo é repetido várias vezes, o que leva a melhorias nas decisões do agente ao longo do tempo.
O que torna o SARSA especial entre os algoritmos de RL é que o SARSA aprende com as escolhas reais feitas pelo agente, inclusive quando ele está experimentando coisas novas. Essa abordagem é particularmente útil quando a jornada de aprendizado é tão importante quanto o resultado final.
É como um robô que aprende a andar de bicicleta andando de fato, com quedas e tudo, em vez de encontrar o caminho mais curto de A a B usando rodinhas de proteção.
Neste tutorial, usaremos extensivamente o Numpy e a biblioteca de aprendizado por reforço Gymnasium. Enquanto o Numpy nos ajudará a escrever o algoritmo SARSA, o Gymnasium nos fornece ambientes integrados para testar nosso trabalho.
Vamos instalá-los em um novo ambiente virtual com os seguintes comandos:
$ conda create -n sarsa python=3.9 -y
$ conda activate sarsa
$ pip install "gymnasium[atari]" numpy matplotlib
$ pip install autorom[accept-rom-license] # Downloading Gym env data files
$ AutoROM --accept-license # Accepting the license for data files
$ pip install ipykernel # Install Jupyter kernel manager
$ ipython kernel install --user --name=sarsa # Add the new Conda env to JupyterAntes de continuar, recomendo que você leia nossa Introdução ao aprendizado por reforço que você leu. Ele aborda as ideias fundamentais por trás da RF, como agentes, ambientes, dilema de exploração versus exploração e Q-learning.
Ao longo do tutorial, usaremos o ambiente Taxi-v3, que é um problema clássico de aprendizado por reforço fornecido pela biblioteca Gymnasium. Ele simula um motorista de táxi navegando em um mundo de grade 5x5 para pegar e deixar passageiros.
Para carregar o ambiente, usamos o método .make() do Gymnasium com um modo de renderização rgb_array (para visualizar o ambiente posteriormente):
import gymnasium as gym
env = gym.make('Taxi-v3', render_mode='rgb_array')O ambiente é uma grade de 5x5 com quatro locais designados: vermelho (R), verde (G), amarelo (Y) e azul (B). O táxi começa em um quadrado aleatório e deve pegar um passageiro em um dos locais coloridos e deixá-lo em outro.
O táxi pode se mover para o norte, sul, leste ou oeste e também pode tentar pegar ou deixar um passageiro.
Veja como podemos visualizar o estado inicial do ambiente com o Matplotlib:
import matplotlib.pyplot as plt
# Reset the environment to get an initial state
# Each time we reset the environment, we get a new random state
initial_state, _ = env.reset()
# Render the initial state
img = env.render()
# Create a figure and display the environment
fig, ax = plt.subplots(figsize=(8, 8))
ax.imshow(img)
# Remove axis ticks
ax.set_xticks([])
ax.set_yticks([]);
Primeiro, redefinimos o ambiente para obter um estado inicial. Em seguida, exibimos esse estado inicial com a função render, recebendo uma matriz de imagem Numpy. A função imshow() do Matplotlib usa essa matriz e produz uma visualização limpa, sem ticks nos eixos.
Reserve um momento para entender o layout do mundo da grade do Taxi-v3, observando a posição do táxi, as barreiras, os locais dos passageiros e o destino.
O agente (o táxi) recebe +20 pontos por deixar um passageiro com sucesso. A coleta ou entrega ilegal resulta em uma recompensa de -10. Durante todo o tempo, cada etapa de tempo produz -1 recompensa para incentivar o táxi a concluir a tarefa rapidamente.
Um único episódio do ambiente do Taxi-v3 termina no caso de uma desistência bem-sucedida ou quando o número máximo de etapas de tempo é atingido.
# The number of states and actions
n_states = env.observation_space.n
n_actions = env.action_space.n
print(n_states)
print(n_actions)500
6Há 500 estados no espaço de estado do ambiente. Cada estado é representado por você:
Os códigos de ação são:
O objetivo é que o agente aprenda uma política ideal para maximizar sua recompensa total ao pegar e deixar passageiros de forma eficiente.
Antes de escrevermos o algoritmo completo, vamos ver como o ciclo Estado-Ação-Recompensa-Estado-Ação funciona usando nosso ambiente.
Primeiro, definimos quantos episódios queremos que a interação continue. Um único episódio representa uma execução completa da tarefa de táxi, desde o estado inicial até o momento em que você consegue deixar o passageiro ou atingir o número máximo de etapas de tempo. Cada episódio permite que o agente aprenda com suas experiências e melhore sua estratégia ao longo do tempo.
n_episodes = 5000Agora, escrevemos o loop de interação:
for episode in range(n_episodes):
state, _ = env.reset()
done = False
total_reward = 0
steps = 0
while not done:
# Choose a random action
action = env.action_space.sample()
# Take the action and observe the result
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# Update total reward and step count
total_reward += reward
steps += 1
# Move to the next state
state = next_state
if episode % 1000 == 0:
print(f"Episode {episode}, Total Reward: {total_reward}, Steps: {steps}")Episode 0, Total Reward: -812, Steps: 200
Episode 1000, Total Reward: -830, Steps: 200
Episode 2000, Total Reward: -902, Steps: 200
Episode 3000, Total Reward: -522, Steps: 129
Episode 4000, Total Reward: -767, Steps: 200O código acima demonstra o ciclo básico de interação SARSA sem implementar nenhum algoritmo de aprendizado:
env.reset().env.step(action). Essa versão usa ações aleatórias para demonstrar o loop de interação.next_state, reward, ... = env.take(action).No loop de interação acima, o táxi continua se movendo pelo ambiente em todas as direções e executando ações aleatórias até que as etapas de tempo se esgotem.
Antes de continuarmos, vamos implementar um recurso para animar nossos loops de interação. Isso nos permite ver visualmente o táxi interagindo com o ambiente.
A criação da animação será um processo simples:
env.render() função.moviepyconcatenamos todas as matrizes de imagens para criar um único GIF.Vamos modificar o código:
env = gym.make("Taxi-v3", render_mode="rgb_array")
n_episodes = 1
frames = [] # for animation
for episode in range(n_episodes):
# Reset the environment
state, _ = env.reset()
# Capture the state as an image
img = env.render()
frames.append(img)
done = False
total_reward = 0
steps = 0
while not done:
# Choose a random action
action = env.action_space.sample()
# Take the action and observe the result
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# Capture the next state as an image
img = env.render()
frames.append(img)
# Update total reward and step count
total_reward += reward
steps += 1
# Move to the next state
state = next_stateNesta versão, definimos o número de episódios para apenas um, pois a renderização de estados de ambiente como imagens leva muito tempo. Também criamos uma lista vazia para armazenar nossas matrizes de imagens. Em seguida, o loop de interação continua como antes. A única diferença são as duas linhas extras de código em que renderizamos o ambiente como uma imagem e a anexamos a frames.
Agora, precisamos ter 201 imagens dentro dos quadros (uma imagem extra para o estado adicional):
>>> len(frames)
201Vamos transformar essas imagens em um GIF usando moviepy biblioteca:
from moviepy.editor import ImageSequenceClip # pip install moviepy
def create_gif(frames: list, filename, fps=5):
"""
Creates a GIF animation from a list of RGBA NumPy arrays.
Args:
frames: A list of RGBA NumPy arrays representing the animation frames.
filename: The output filename for the GIF animation.
fps: The frames per second of the animation (default: 10).
"""
clip = ImageSequenceClip(frames, fps=fps)
clip.write_gif(filename, fps=fps)
# Example usage
create_gif(frames, "animation.gif", fps=25) # saves the GIF locallyA função create_gif() pega uma lista de quadros e os converte em um GIF usando a classe ImageSequenceClip de moviepy. Um parâmetro importante são os quadros por segundo, fps, que controlam a duração do GIF. Quanto mais quadros por segundo, mais curto será o GIF.
No final, convertemos os quadros de um único episódio em um GIF com 25 FPS. Aqui está o resultado:
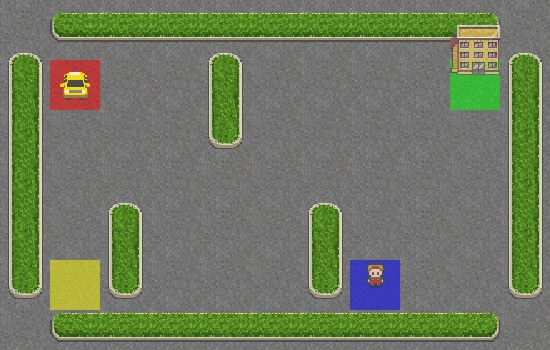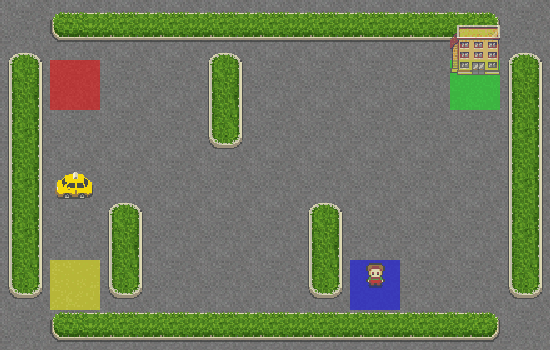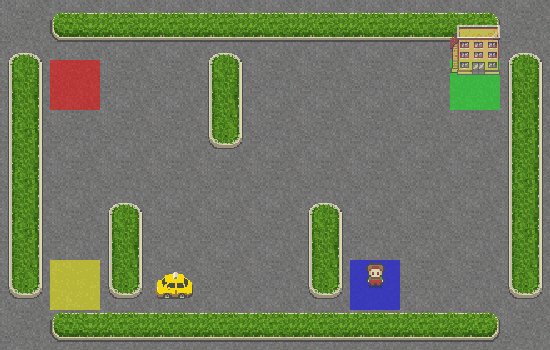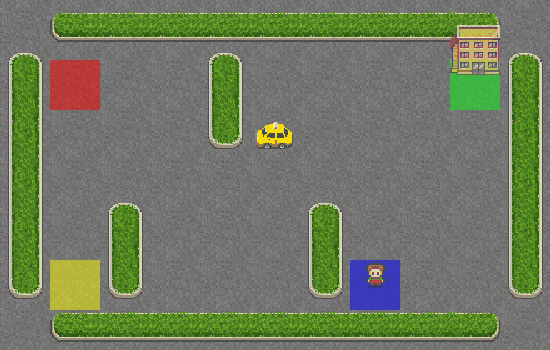
Como você pode ver, o táxi não tem ideia do que está fazendo e nem sequer se aproximou do passageiro. Vamos dar a ele um pouco de inteligência, adicionando a SARSA ao seu sistema de navegação.
Criaremos o código para a SARSA do zero para que você se lembre de cada etapa com clareza.
1. Configuração do ambiente do Gymnasium:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
# Create the Taxi environment
env = gym.make("Taxi-v3", render_mode="rgb_array")2. Inicialização de um Q-table
# Initialize Q-table
n_states = env.observation_space.n
n_actions = env.action_space.n
Q_table = np.zeros((n_states, n_actions))Nesta etapa, apresentamos uma nova estrutura de dados: o Q-table. Ele tem dimensões de (número de estados) x (número de ações). A tabela ficaria assim para o nosso agente, o motorista de táxi:
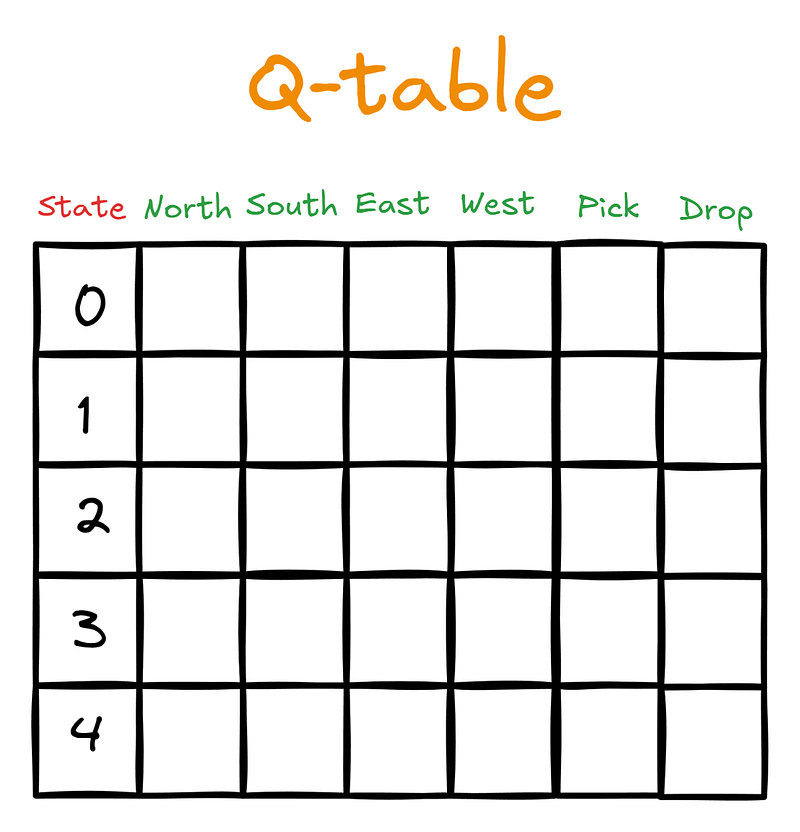
Inicialmente, o Q-table será preenchido com zeros:
>>> Q_table.shape
(500, 6)Em seguida, quando o agente começar a interagir com o ambiente guiado pela SARSA, ele atualizará o Q-table com os valores Q. Os valores Q são pontuações que informam ao agente qual ação é a melhor a ser tomada, considerando o estado atual.
3. Definição dos hiperparâmetros da SARSA
Depois de inicializar o Q-table, definimos os hiperparâmetros do SARSA com valores comuns (falaremos mais sobre eles posteriormente):
# SARSA parameters
alpha = 0.1 # Learning rate
gamma = 0.99 # Discount factor
epsilon = 0.1 # Exploration rate for epsilon-greedy policy
n_episodes = 200004. Definição de armazenamento para métricas de desempenho
Em seguida, definimos duas listas para armazenar métricas de desempenho: a recompensa total e o número de etapas de tempo para cada episódio. O objetivo do agente é coletar o máximo possível de recompensas no menor tempo possível:
# Lists to store performance metrics
episode_rewards = []
episode_lengths = []5. Política de Epsilon-greedy para tomar medidas
Na seção anterior, nosso agente não era guiado - ele tomava ações aleatórias. Queremos mudar isso, oferecendo ao motorista uma estratégia Epsilon-Greedy:
def epsilon_greedy(state, epsilon):
if np.random.random() < epsilon:
# Take random action - explore
return env.action_space.sample()
else:
# Take action with the highest Q-value - exploit
return np.argmax(Q_table[state])Essa estratégia tem o objetivo de controlar o equilíbrio crucial entre exploração e aproveitamento. Com probabilidade epsilon, o agente explora o ambiente tomando uma ação aleatória, enquanto com probabilidade 1-epsilon, ele explora seu conhecimento atual escolhendo a ação com o valor Q mais alto da tabela Q. Essa abordagem permite que o agente descubra estratégias novas e potencialmente melhores e, ao mesmo tempo, use o que já aprendeu.
6. Escrever o loop de treinamento da SARSA
Por fim, escrevemos o loop de treinamento da SARSA. O início do loop já é familiar para nós. A única diferença é que usamos a função epsilon_greedy() para nos dizer qual ação tomar no estado atual:
# SARSA training loop
for episode in range(n_episodes):
state, _ = env.reset()
action = epsilon_greedy(state, epsilon)
done = False
total_reward = 0
steps = 0
...Em seguida, iniciamos o while que nos permite executar o ciclo de interação até atingirmos um estado de encerramento:
# SARSA training loop
for episode in range(n_episodes):
...
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
next_action = epsilon_greedy(next_state, epsilon)Dentro do loop while tomamos a ação retornada por epsilon_greedy() e recebemos o próximo estado, a recompensa por nossa ação e um valor booleano para saber se o episódio foi encerrado ou não.
Em seguida, chegamos à parte crucial: a regra de atualização do SARSA:
# SARSA training loop
for episode in range(n_episodes):
...
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
next_action = epsilon_greedy(next_state, epsilon)
# SARSA update rule
Q_table[state, action] += alpha * (
reward + gamma * Q_table[next_state, next_action] - Q_table[state, action]
)A regra de atualização vem da seguinte fórmula:
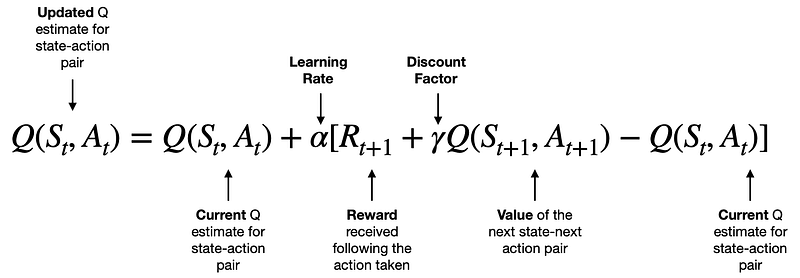
[Fonte]
Aprenderemos a intuição por trás dessa fórmula na próxima seção. Neste momento, considere a fórmula como uma mágica matemática que atualiza os valores Q de nossa tabela Q de acordo com as regras da SARSA.
Depois de fazermos a atualização do Q, alteramos o state e action para o estado e a ação resultantes, adicionamos a recompensa recebida à recompensa total do episódio e aumentamos o número de etapas de tempo.
# SARSA training loop
for episode in range(n_episodes):
...
while not done:
...
state = next_state
action = next_action
total_reward += reward
steps += 1O loop while continua até atingirmos o máximo de etapas de tempo (200 para o ambiente do táxi) ou quando o táxi deixa o passageiro no local correto.
Quando o loop termina, registramos a recompensa total do episódio e a duração do episódio. Também imprimimos a recompensa e a duração média dos episódios a cada 1.000 episódios:
# SARSA training loop
for episode in range(n_episodes):
...
while not done:
...
episode_rewards.append(total_reward)
episode_lengths.append(steps)
if episode % 1000 == 0:
avg_reward = np.mean(episode_rewards[-1000:])
avg_length = np.mean(episode_lengths[-1000:])
print(f"Episode {episode}, Avg Reward: {avg_reward:.2f}, Avg Length: {avg_length:.2f}")Aqui está o loop de interação completo executado:
# SARSA training loop
for episode in range(n_episodes):
state, _ = env.reset()
action = epsilon_greedy(state, epsilon)
done = False
total_reward = 0
steps = 0
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
next_action = epsilon_greedy(next_state, epsilon)
Q_table[state, action] += alpha * (
reward + gamma * Q_table[next_state, next_action] - Q_table[state, action]
)
state = next_state
action = next_action
total_reward += reward
steps += 1
episode_rewards.append(total_reward)
episode_lengths.append(steps)
if episode % 2000 == 0:
avg_reward = np.mean(episode_rewards[-1000:])
avg_length = np.mean(episode_lengths[-1000:])
print(f"Episode {episode}, Avg Reward: {avg_reward:.2f}, Avg Length: {avg_length:.2f}")Episode 0, Avg Reward: -551.00, Avg Length: 185.00
Episode 2000, Avg Reward: -4.37, Avg Length: 19.47
Episode 4000, Avg Reward: 1.98, Avg Length: 15.09
Episode 6000, Avg Reward: 2.29, Avg Length: 14.79
Episode 8000, Avg Reward: 2.06, Avg Length: 14.80
Episode 10000, Avg Reward: 2.16, Avg Length: 14.78
Episode 12000, Avg Reward: 2.06, Avg Length: 14.89
Episode 14000, Avg Reward: 2.33, Avg Length: 14.81
Episode 16000, Avg Reward: 2.36, Avg Length: 14.66
Episode 18000, Avg Reward: 2.53, Avg Length: 14.72Como você pode ver no resultado, a recompensa média e o número de etapas de tempo por episódio diminuíram drasticamente à medida que executamos mais e mais episódios.
Podemos ver isso visualmente traçando o gráfico de episode_rewards e episode_lengths :
# Plot the learning curve
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(episode_rewards)
plt.title("Episode Rewards")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.subplot(1, 2, 2)
plt.plot(episode_lengths)
plt.title("Episode Lengths")
plt.xlabel("Episode")
plt.ylabel("Number of Steps")
plt.tight_layout()
plt.show()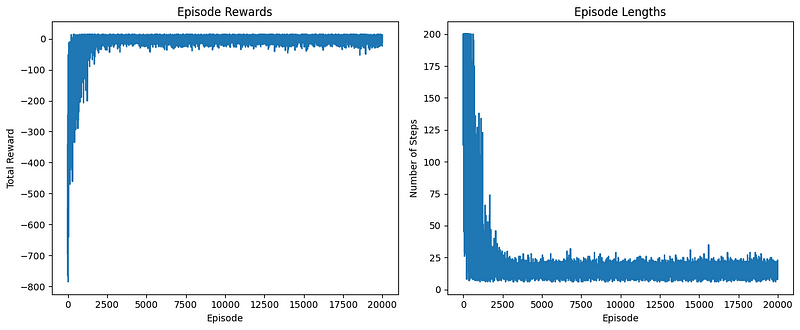
O gráfico à esquerda exibe a recompensa total obtida em cada episódio. Podemos observar isso:
O gráfico à direita mostra o número de etapas realizadas em cada episódio. Podemos ver isso:
Em um curto período, cobrimos uma grande quantidade de terreno. Agora vamos dar um passo atrás e organizar tudo o que escrevemos. Criaremos funções para cada uma das etapas que seguimos para implementar a SARSA.
Primeiro, uma função para criar um ambiente:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from moviepy.editor import ImageSequenceClip
def create_environment(env_name="Taxi-v3", render_mode="rgb_array"):
"""Create and return a Gymnasium environment."""
return gym.make(env_name, render_mode=render_mode)Em seguida, uma função para inicializar um Q-table com um ambiente:
def initialize_q_table(env):
"""Initialize and return a Q-table for the given environment."""
n_states = env.observation_space.n
n_actions = env.action_space.n
return np.zeros((n_states, n_actions))A estratégia Epsilon-greedy que aceita um ambiente, um Q-table, o estado atual e o epsilon:
def epsilon_greedy(env, Q_table, state, epsilon=0.1):
"""Epsilon-greedy action selection."""
if np.random.random() < epsilon:
return env.action_space.sample()
else:
return np.argmax(Q_table[state])A regra de atualização da SARSA, que exige uma tabela Q, o estado atual, a ação realizada nesse estado, a recompensa pela ação, o próximo estado e a ação:
def sarsa_update(Q_table, state, action, reward, next_state, next_action, alpha, gamma):
"""Perform SARSA update on Q-table."""
Q_table[state, action] += alpha * (
reward + gamma * Q_table[next_state, next_action] - Q_table[state, action]
)Por fim, uma grande função para treinar o agente com SARSA que requer um ambiente, o número de episódios a serem executados, parâmetros alfa, gama e épsilon:
def train_sarsa(env, n_episodes=20000, alpha=0.1, gamma=0.99, epsilon=0.1):
"""Train the agent using SARSA algorithm."""
Q_table = initialize_q_table(env)
episode_rewards = []
episode_lengths = []
for episode in range(n_episodes):
state, _ = env.reset()
action = epsilon_greedy(env, Q_table, state, epsilon)
done = False
total_reward = 0
steps = 0
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
next_action = epsilon_greedy(env, Q_table, next_state, epsilon)
sarsa_update(
Q_table, state, action, reward, next_state, next_action, alpha, gamma
)
state = next_state
action = next_action
total_reward += reward
steps += 1
episode_rewards.append(total_reward)
episode_lengths.append(steps)
return Q_table, episode_rewards, episode_lengthsAlém disso, uma função para plotar métricas de desempenho:
def plot_learning_curve(episode_rewards, episode_lengths):
"""Plot the learning curve."""
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(episode_rewards)
plt.title("Episode Rewards")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.subplot(1, 2, 2)
plt.plot(episode_lengths)
plt.title("Episode Lengths")
plt.xlabel("Episode")
plt.ylabel("Number of Steps")
plt.tight_layout()
plt.show()Nossa função anterior create_gif() função:
def create_gif(frames, filename, fps=5):
"""Creates a GIF animation from a list of frames."""
clip = ImageSequenceClip(frames, fps=fps)
clip.write_gif(filename, fps=fps)E uma outra função para executar um único episódio com renderização usando um Q-table completo e aprendido (para fins de animação):
def run_episode(env, Q_table, epsilon=0):
"""Run a single episode using the learned Q-table."""
state, _ = env.reset()
done = False
total_reward = 0
frames = [env.render()]
while not done:
action = epsilon_greedy(env, Q_table, state, epsilon)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
frames.append(env.render())
total_reward += reward
state = next_state
return frames, total_rewardAgora, vamos executar tudo:
if __name__ == "__main__":
env = create_environment()
Q_table, episode_rewards, episode_lengths = train_sarsa(env, n_episodes=20000)
plot_learning_curve(episode_rewards, episode_lengths)
frames, total_reward = run_episode(env, Q_table)
create_gif(frames, "images/sarsa_final_animation.gif", fps=1)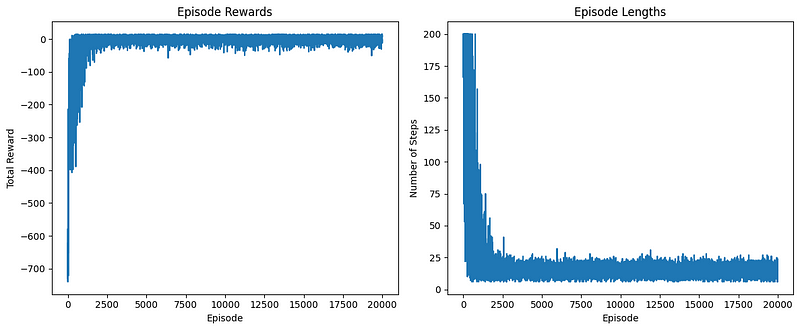
Os gráficos de desempenho parecem bons. Agora, vamos dar uma olhada no GIF gerado:
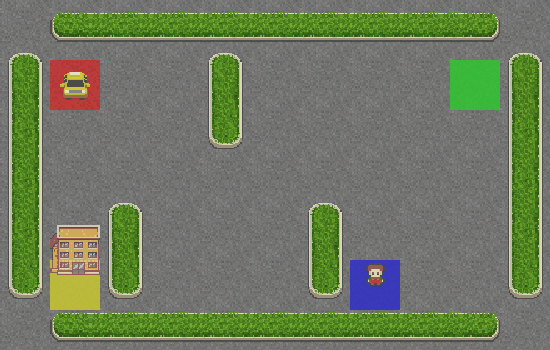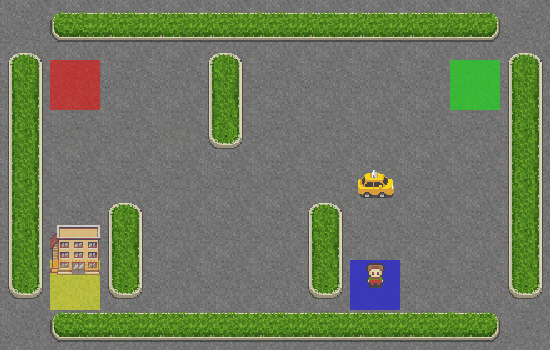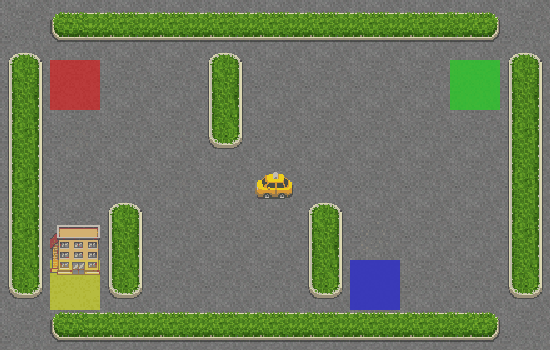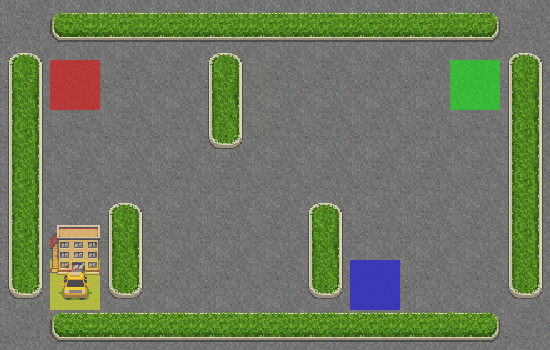
Viva! O táxi está pegando corretamente o passageiro no quadrado azul e deixando-o no quadrado amarelo.
Eu colei o código todo o código organizado para a implementação da SARSA em um gist do GitHub para que você possa voltar a ele sempre que quiser.
No centro da SARSA está sua regra de atualização, que controla como o agente aprende com suas experiências. Vamos detalhar essa regra e explorar a intuição por trás dela:
Q(s, a) = Q(s, a) + α [R + γ Q(s', a') - Q(s, a)]
A regra de atualização da SARSA tem como objetivo refinar a compreensão do ambiente pelo agente, ajustando os valores Q com base em novas experiências. Veja como funciona:
O termo [R + γ * Q(s', a') - Q(s, a)] é conhecido como erro de diferença temporal (TD). Pense nisso como uma medida de surpresa:
Esse erro ajuda o agente a refinar continuamente suas estimativas, conduzindo o processo de aprendizagem para uma política ideal.
1. Taxa de aprendizado (α):
2. Fator de desconto (γ):
3. Taxa de exploração (ε):
A regra de atualização da SARSA permite que o agente aprenda com suas experiências, ajustando constantemente suas estimativas de valores de ação de estado. A cada interação, o agente se torna um pouco mais sábio sobre seu ambiente. Ao longo de muitos episódios, esse processo leva ao desenvolvimento de uma política ideal para navegar no ambiente.
Ao ajustar os hiperparâmetros, podemos controlar vários aspectos do processo de aprendizagem, permitindo que a SARSA se adapte a diferentes tipos de problemas e ambientes. Essa flexibilidade, combinada com sua regra de atualização intuitiva, torna o SARSA um algoritmo de aprendizagem por reforço poderoso e amplamente utilizado.
Embora o SARSA e o Q-learning sejam algoritmos de aprendizado por reforço amplamente usados, eles têm algumas diferenças importantes. E essas diferenças são fundamentais para que você entenda quando e como usar cada algoritmo.
Um algoritmo na política, o SARSA, aprende o valor da política que segue, incluindo até mesmo as etapas realizadas durante a exploração. O Q-learning está fora da política; ele aprende o valor da política ideal - mesmo quando não está seguindo essa política, ele ainda aprende o valor da política ideal quando chega ao final do episódio. É por isso que mencionamos no início que a SARSA deve ser usada quando a jornada de aprendizagem é tão importante quanto o próprio resultado. O Q-learning não se preocupa muito com a jornada de aprendizagem.
A principal diferença é que a SARSA usa o valor Q da próxima ação efetivamente tomada (a'), enquanto o Q-learning usa o valor Q máximo do próximo estado (max(Q(s', a'))).
Ao atualizar os valores Q, a SARSA não ignora a política de exploração e, portanto, é mais conservadora. Em comparação, o Q-learning sempre pressupõe que o agente tomará a ação ideal no futuro e, portanto, é mais agressivo.
Embora ambos os algoritmos acabem chegando à política ideal, o Q-learning pode aprender mais rapidamente, principalmente em ambientes determinísticos.
Em ambientes em que a exploração pode levar a resultados ruins, a SARSA geralmente aprende políticas mais seguras porque leva em conta a política real que está sendo seguida.
No problema clássico de "caminhada no penhasco", a SARSA normalmente aprende um caminho mais seguro que fica longe da borda do penhasco, enquanto o Q-learning pode aprender um caminho mais arriscado que caminha ao longo da borda.
Em determinados ambientes aleatórios, a SARSA pode ser mais estável porque leva em conta a próxima ação real, mesmo quando essa ação é uma ação exploratória abaixo do ideal.
O Q-learning pode ser mais sensível à escolha da taxa de aprendizado e da taxa de exploração, especialmente em ambientes com estocasticidade significativa.
Quando se trata de robótica ou outros sistemas físicos em que a exploração do ambiente é cara e queremos implementar políticas mais seguras, podemos preferir o algoritmo SARSA na política. Quando estamos em um mundo simulado, em jogos ou em outros ambientes em que podemos obter muito feedback e onde queremos encontrar a política ideal de forma rápida e segura, talvez gostemos muito mais do Q-learning.
Portanto, você pode pensar que a SARSA é uma espécie de província mais segura, e que o Q-learning é a abordagem mais rápida e imprudente. Na prática, isso geralmente depende do problema específico. Ambos os algoritmos são muito fortes, e sempre faz sentido saber quais são as diferenças entre eles.
Neste guia abrangente, exploramos o algoritmo SARSA, abordando seus principais conceitos, detalhes de implementação e aplicações práticas usando o ambiente Taxi-v3.
As principais conclusões incluem:
A capacidade do SARSA de aprender políticas mais seguras o torna adequado para aplicações do mundo real em que os custos de exploração são altos, embora ele possa convergir mais lentamente do que algoritmos fora da política, como o Q-learning, em alguns cenários.
Lembre-se de que a escolha entre o SARSA e outros algoritmos depende de seu problema e ambiente específicos. A experimentação e o ajuste fino são cruciais para obter os melhores resultados.
Incentivamos você a desenvolver essa base explorando ambientes mais complexos, implementando o SARSA com aproximação de funções ou mergulhando em outros algoritmos de aprendizagem por reforço.
Aqui estão alguns recursos relacionados para ajudar você ao longo do caminho:
Principais cursos da DataCamp
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev

