
programa
Desarrollo de aplicaciones de IA
21 h
Los grandes modelos lingüísticos (LLM) a menudo se quedan cortos cuando se trata de tareas intensivas en conocimiento que requieren información actualizada y precisa. Aquí es donde generación aumentada por recuperación (RAG) combinando las capacidades generativas de los LLM con bases de conocimiento externas para mejorar la precisión y la relevancia.
A pesar de su eficacia, los sistemas tradicionales de GAR se enfrentan a dificultades a la hora de gestionar documentos largos y complejos, lo que provoca un aumento de la latencia y, a veces, resultados menos precisos. Para abordar estos problemas, el concepto de RAG especulativa ha surgido como una solución prometedora. Averigüemos más sobre ello.
La generación especulativa de recuperación aumentada (RAG) es un marco innovador diseñado para mejorar la eficacia y precisión de los sistemas RAG dividiendo el proceso de generación en dos pasos distintos:
Comprendamos mejor la RAG especulativa examinando este diagrama:
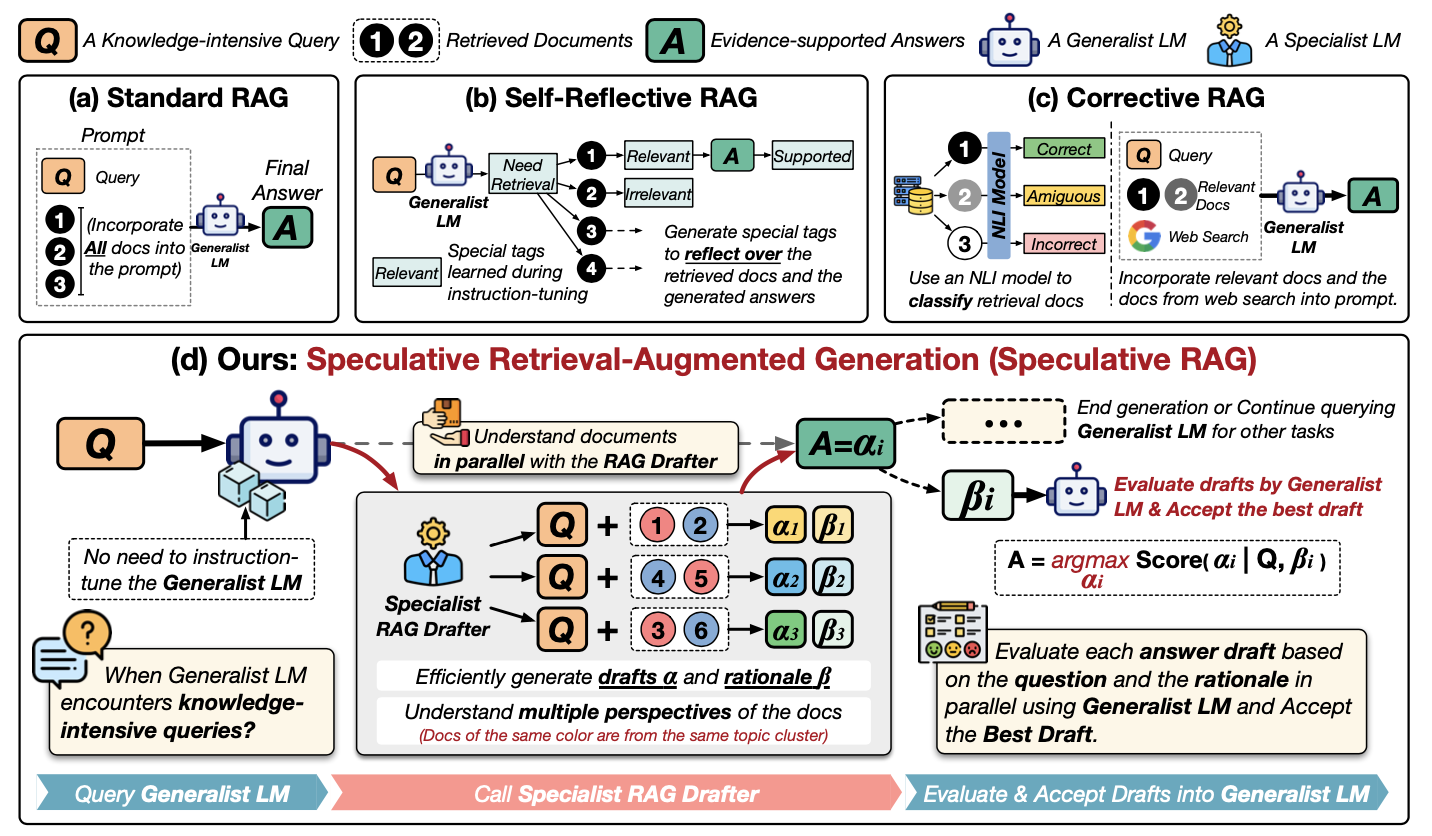
Fuente: Wang et al., 2024
Vamos a recorrer este esquema paso a paso. Muestra distintas formas de utilizar información externa para ayudar a un LLM a responder preguntas, centrándose en un nuevo método llamado GAR Especulativo. Examinemos los métodos de la primera fila:
Ahora, veamos de cerca (d) GAR Especulativo:
Esencialmente, el GAR especulativo es como tener un equipo de expertos: el redactor crea opciones, y el LLM generalista toma la decisión final. Esto hace que el proceso sea más rápido y potencialmente más preciso.
El GAR Especulativo ofrece varias ventajas clave sobre los sistemas de GAR tradicionales:
Al utilizar un Redactor RAG especializado para generar múltiples borradores a partir de diversos subconjuntos de documentos, el RAG Especulativo mejora la precisión del resultado final. Este enfoque permite al sistema considerar múltiples perspectivas, reduciendo las posibilidades de generar respuestas incorrectas o sesgadas. En los experimentos, la RAG Especulativa demostró hasta un 12,97% de mejora en la precisión en puntos de referencia como PubHealth, en comparación con los sistemas de RAG convencionales.
Uno de los retos más importantes de los sistemas tradicionales de GAR es el aumento de la latencia causado por el procesamiento de documentos largos y complejos. El GAR Especulativo aborda este problema descargando el proceso de redacción a un LM más pequeño y eficiente, que puede generar borradores en paralelo. Este enfoque reduce el tiempo total de procesamiento, con mejoras de latencia de hasta el 51% en algunos casos.
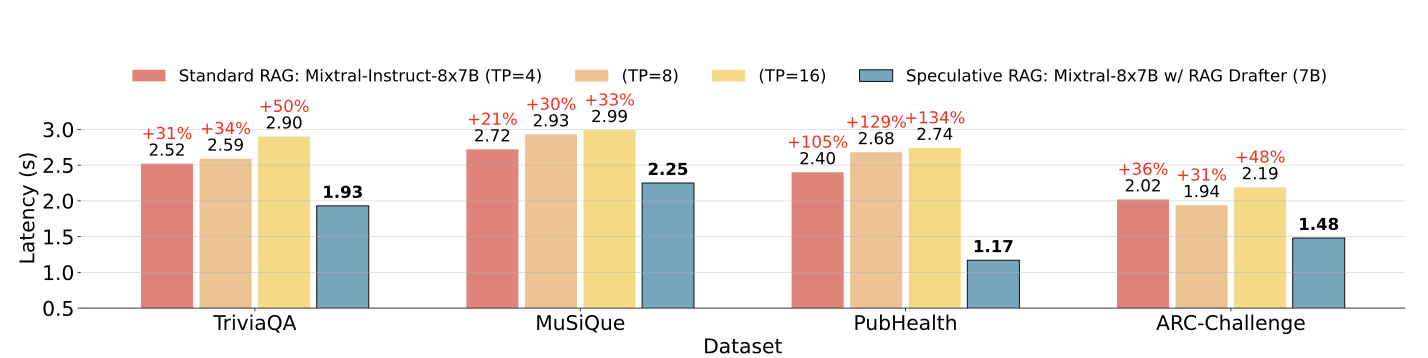
Latencia RAG especulativa frente a latencia RAG estándar en diferentes conjuntos de datos. Fuente: Wang y otros, 2024
La RAG especulativa optimiza el uso de recursos delegando la tarea de redacción a un LM más pequeño, que es menos intensivo computacionalmente que el LM generalista más grande utilizado en los sistemas RAG tradicionales. Esta división del trabajo no sólo acelera el proceso de generación, sino que también reduce la carga computacional total, lo que la convierte en una solución más eficiente desde el punto de vista de los recursos.
El marco RAG Especulativo es muy adaptable y puede aplicarse a diversas tareas intensivas en conocimiento sin necesidad de grandes ajustes. Esta escalabilidad la convierte en una solución ideal para una amplia gama de aplicaciones, desde la respuesta a preguntas hasta el análisis de documentos complejos.
Para aplicar una versión simplificada de la GAR Especulativa a una tarea básica de respuesta a preguntas, utilizaremos un conjunto de datos pequeño y una configuración sencilla con dos modelos: uno más pequeño para la redacción y otro más grande para la verificación.
Para simplificar, utilizaremos los Transformadores de caras abrazadas biblioteca. Demostraremos cómo utilizar un modelo lingüístico más pequeño para generar varios borradores y un modelo más grande para verificar y seleccionar el mejor borrador.
En primer lugar, vamos a instalar las bibliotecas necesarias. Tendrás que reiniciar la sesión después de instalar la biblioteca de transformadores de HuggingFace. Asegúrate de que has añadido las credenciales de HuggingFace bajo una clave secreta en Collab o en cualquier otro editor.
!pip install transformers torch datasetsPara este ejemplo, utilizaremos la función SQuAD (Conjunto de datos de respuesta a preguntas de Stanford) disponible en la biblioteca de conjuntos de datos de Cara Abrazada.
from datasets import load_dataset
# Load the SQuAD dataset
dataset = load_dataset("squad", split="train[:100]") # Using a small subsetUtilizaremos dos modelos preentrenados de la biblioteca Caras Abrazadas. Un modelo más pequeño (distilbert-base-uncased-distilled-squad) actuará como nuestro Redactor RAG y un modelo más grande (bert-large-uncased-whole-word-masking-finetuned-squad) actuará como Verificador RAG.
A continuación, construiremos un Redactor y un canal de verificación con los modelos seleccionados.
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
# Initialize the smaller model (RAG Drafter)
drafter_model_name = "distilbert-base-uncased-distilled-squad"
drafter_model = AutoModelForQuestionAnswering.from_pretrained(drafter_model_name)
drafter_tokenizer = AutoTokenizer.from_pretrained(drafter_model_name)
# Initialize the larger model (RAG Verifier)
verifier_model_name = "bert-large-uncased-whole-word-masking-finetuned-squad"
verifier_model = AutoModelForQuestionAnswering.from_pretrained(verifier_model_name)
verifier_tokenizer = AutoTokenizer.from_pretrained(verifier_model_name)
# Set up pipelines
drafter_pipeline = pipeline("question-answering", model=drafter_model, tokenizer=drafter_tokenizer)
verifier_pipeline = pipeline("question-answering", model=verifier_model, tokenizer=verifier_tokenizer)A continuación, definiremos una función para generar varios borradores utilizando el modelo más pequeño con la canalización predefinida de Drafter.
def generate_drafts(question, context, num_drafts=3):
drafts = []
for _ in range(num_drafts):
draft = Drafter_pipeline(question=question, context=context)
drafts.append(draft)
return draftsAhora definiremos unafunción verify_drafts() que utiliza el modelo mayor para verificar y seleccionar el mejor borrador basándose en las puntuaciones de confianza.
Funciona asignando las posiciones de inicio y fin de carácter de cada borrador a las posiciones de símbolo correspondientes en el contexto simbolizado mediante una asignación de desplazamiento. A continuación, el modelo verificador puntúa cada borrador en función de su confianza en que estas posiciones sean la respuesta correcta. El borrador con la puntuación de confianza más alta se selecciona como la mejor respuesta, lo que garantiza que el resultado final sea preciso y fiable.
El manejo cuidadoso de la alineación y puntuación de fichas por parte de esta función es clave para mejorar el rendimiento del GAR Especulativo.
def verify_drafts(question, context, drafts):
best_draft = None
highest_score = 0
# Tokenize the context using the verifier's tokenizer, keeping track of offsets
inputs = verifier_tokenizer(question, context, return_tensors="pt", return_offsets_mapping=True)
offset_mapping = inputs['offset_mapping'][0] # This will give us the character-to-token mapping
input_ids = inputs['input_ids'][0]
for draft in drafts:
start_char = draft['start']
end_char = draft['end']
# Find the corresponding token positions using offset mapping
start_index = None
end_index = None
for idx, (start, end) in enumerate(offset_mapping):
if start_index is None and start_char >= start and start_char < end:
start_index = idx
if end_index is None and end_char > start and end_char <= end:
end_index = idx
if start_index is not None and end_index is not None:
break
# Ensure indices were found and are within bounds
if (start_index is None or end_index is None or
start_index >= len(input_ids) or end_index >= len(input_ids)):
print(f"Draft skipped: Out of bounds or no matching tokens. "
f"Start Index: {start_index}, End Index: {end_index}")
continue
# Get the confidence score using the larger model
outputs = verifier_model(input_ids=input_ids.unsqueeze(0))
score = (outputs.start_logits[0, start_index].item() +
outputs.end_logits[0, end_index].item())
if score > highest_score:
highest_score = score
best_draft = draft
if best_draft is None:
print("No valid draft found after verification.")
return best_draftAhora, apliquemos nuestro proceso RAG Especulativo a 10 preguntas de muestra del conjunto de datos.
correct = 0
total = 10 # Evaluate on 10 samples for simplicity
for i in range(total):
sample = dataset[i]
question = sample['question']
context = sample['context']
drafts = generate_drafts(question, context)
best_answer = verify_drafts(question, context, drafts)
print(f"Q: {question}")
if best_answer is not None:
print(f"A: {best_answer['answer']}\n")
# For simplicity, compare with the first answer (gold) provided in the dataset
if best_answer['answer'].lower() in sample['answers']['text'][0].lower():
correct += 1
else:
print("No valid draft found.\n")
accuracy = correct / total * 100
print(f"Accuracy: {accuracy}%")Este fragmento de código evalúa la precisión de una aplicación RAG especulativa simplificada en 10 muestras de un conjunto de datos. Para cada muestra, genera múltiples borradores de respuesta basados en una pregunta y un contexto dados y luego selecciona el mejor borrador mediante una función de verificación. Si se encuentra una respuesta válida, compara esta respuesta con la respuesta de oro (correcta) proporcionada en el conjunto de datos. Si la respuesta coincide, se incrementa el recuento deaciertos de .
Por último, el código calcula e imprime la precisión como porcentaje de respuestas correctas sobre el total de muestras. Este código arroja una precisión del 90% en este conjunto de datos simplificado.
Aunque el GAR especulativo da buenos resultados, presenta algunos retos:
El GAR Especulativo puede aplicarse a una amplia gama de ámbitos en los que es fundamental recuperar información de forma precisa y eficaz. He aquí algunas aplicaciones potenciales:
La RAG especulativa mejora la generación aumentada por recuperación con mayor precisión, menor latencia, eficiencia de recursos y escalabilidad. Demostramos su aplicación utilizando Transformadores de Cara Abrazados.
Aunque existen retos, el potencial del GAR especulativo en diversos ámbitos lo hace prometedor para futuras investigaciones.
Si quieres saber más sobre la implementación de RAG, te recomiendo los siguientes tutoriales:
Aprende IA con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Zoumana Keita
Tutorial
Ryan Ong
Tutorial
Ryan Ong
Tutorial
Zoumana Keita

