
Cursus
Développer des applications d'IA
21 h
Les grands modèles de langage (LLM) sont souvent insuffisants lorsqu'il s'agit de tâches à forte intensité de connaissances qui requièrent des informations actualisées et précises. C'est là que génération augmentée par la recherche (RAG) intervient, en combinant les capacités génératives des LLM avec des bases de connaissances externes pour améliorer la précision et la pertinence.
Malgré leur efficacité, les systèmes traditionnels de RAG rencontrent des difficultés dans la gestion de documents longs et complexes, ce qui se traduit par des temps de latence accrus et des résultats parfois moins précis. Pour résoudre ces problèmes, le concept de speculative RAG est apparu comme une solution prometteuse. Voyons ce qu'il en est.
La génération spéculative augmentée (RAG) est un cadre innovant conçu pour améliorer l'efficacité et la précision des systèmes RAG en divisant le processus de génération en deux étapes distinctes :
Pour mieux comprendre le RAG spéculatif, examinons ce diagramme :
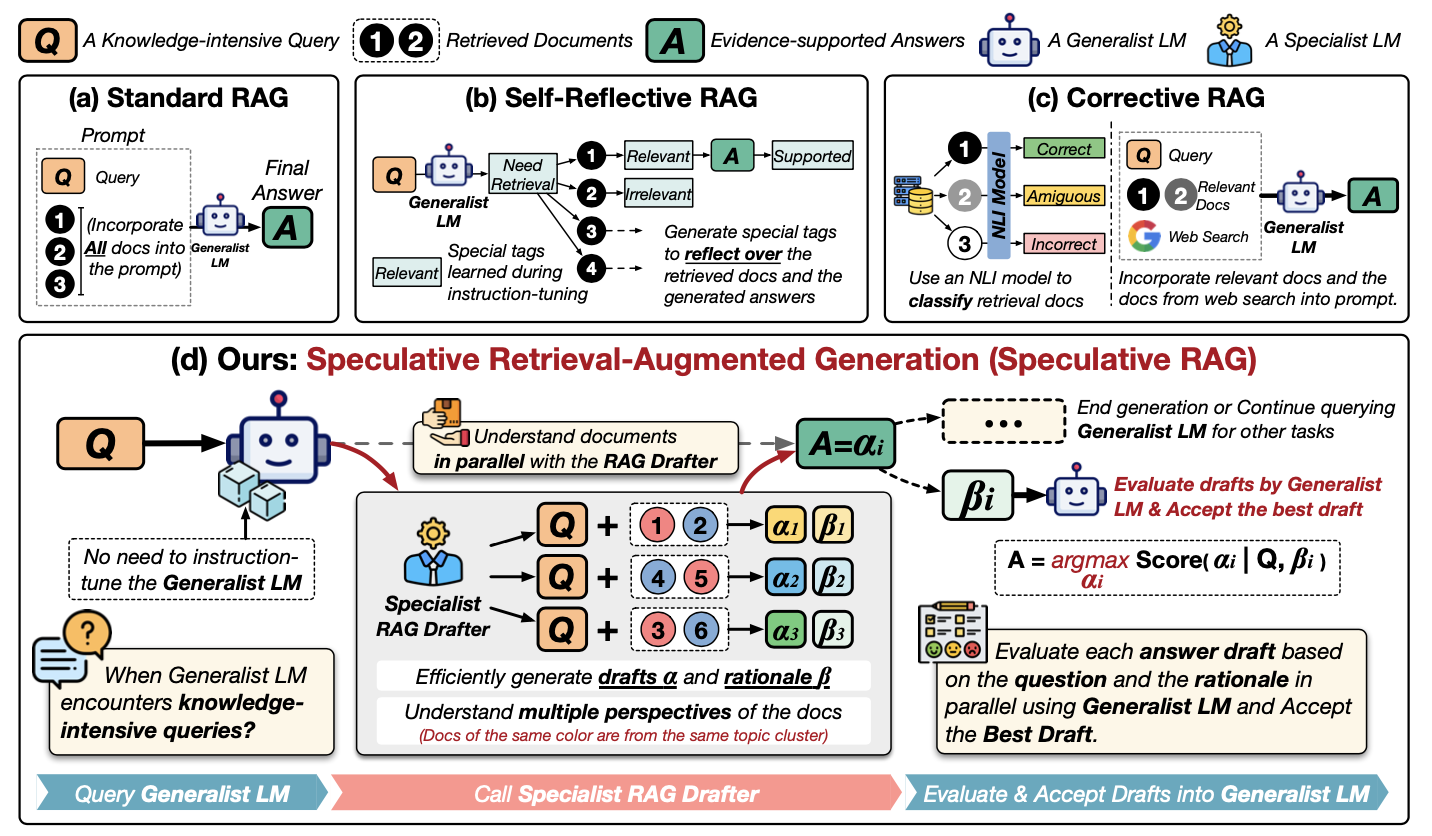
Source : Wang et al., 2024
Examinons ce diagramme étape par étape. Il montre différentes façons d'utiliser des informations externes pour aider un LLM à répondre à des questions, en se concentrant sur une nouvelle méthode appelée Speculative RAG. Examinons les méthodes de la première ligne :
Examinons maintenant de plus près (d) Le RAG spéculatif:
Pour l'essentiel, la GCR spéculative revient à disposer d'une équipe d'experts : le rédacteur crée des options et le généraliste prend la décision finale. Le processus est ainsi plus rapide et potentiellement plus précis.
Le système RAG spéculatif offre plusieurs avantages clés par rapport aux systèmes RAG traditionnels :
En utilisant un rédacteur RAG spécialisé pour générer plusieurs projets à partir de divers sous-ensembles de documents, le RAG spéculatif améliore la précision du résultat final. Cette approche permet au système de prendre en compte de multiples perspectives, réduisant ainsi les risques de générer des réponses incorrectes ou biaisées. Lors d'expériences, le système RAG spéculatif a démontré une amélioration de 12,97 % de la précision sur des critères de référence tels que PubHealth, par rapport aux systèmes RAG conventionnels.
L'un des défis les plus importants que posent les systèmes RAG traditionnels est la latence accrue causée par le traitement de documents longs et complexes. Le RAG spéculatif résout ce problème en déchargeant le processus de rédaction à un LM plus petit et plus efficace, qui peut générer des projets en parallèle. Cette approche permet de réduire le temps de traitement global, avec des améliorations de la latence pouvant atteindre 51 % dans certains cas.
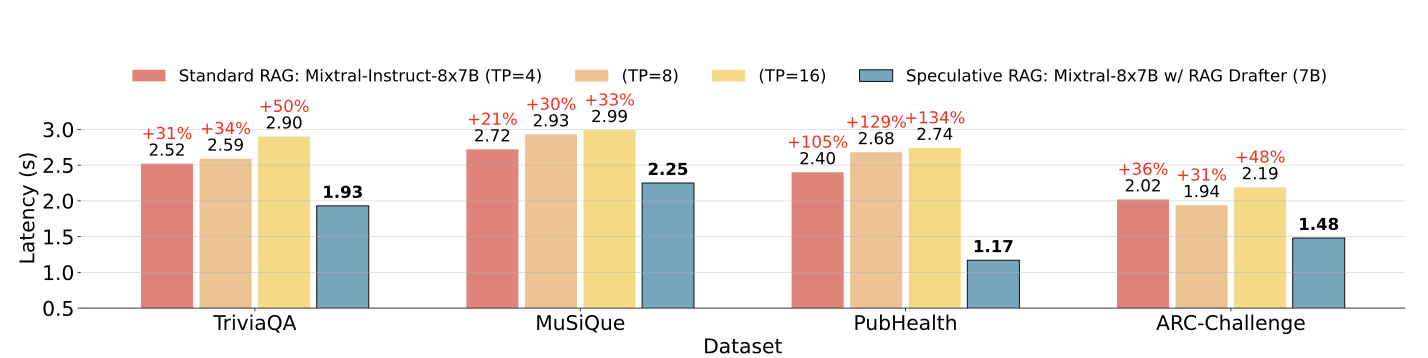
Temps de latence du RAG spéculatif par rapport au temps de latence du RAG standard sur différents ensembles de données. Source : Wang et al., 2024
Le système RAG spéculatif optimise l'utilisation des ressources en déléguant la tâche de rédaction à un LM plus petit, moins gourmand en ressources informatiques que le LM généraliste plus grand utilisé dans les systèmes RAG traditionnels. Cette division du travail permet non seulement d'accélérer le processus de génération, mais aussi de réduire la charge de calcul globale, ce qui en fait une solution plus économe en ressources.
Le cadre RAG spéculatif est très adaptable et peut être appliqué à diverses tâches à forte intensité de connaissances sans qu'il soit nécessaire de procéder à des réglages approfondis. Cette évolutivité en fait une solution idéale pour un large éventail d'applications, de la réponse aux questions à l'analyse de documents complexes.
Pour mettre en œuvre une version simplifiée du RAG spéculatif pour une tâche de réponse à une question de base, nous utiliserons un petit ensemble de données et une configuration simple avec deux modèles - un petit modèle pour la rédaction et un plus grand pour la vérification.
Pour plus de simplicité, nous utiliserons les transformateurs Transformateurs Hugging Face de la bibliothèque. Nous vous montrerons comment utiliser un modèle linguistique plus petit pour générer plusieurs projets et un modèle plus grand pour vérifier et sélectionner le meilleur projet.
Commençons par installer les bibliothèques nécessaires. Vous devrez redémarrer la session après avoir installé la bibliothèque de transformateurs de HuggingFace. Assurez-vous d'avoir ajouté les identifiants HuggingFace sous une clé secrète dans Collab ou tout autre éditeur.
!pip install transformers torch datasetsPour cet exemple, nous utiliserons l'outil SQuAD (Stanford Question Answering Dataset) disponible dans la bibliothèque Hugging Face datasets.
from datasets import load_dataset
# Load the SQuAD dataset
dataset = load_dataset("squad", split="train[:100]") # Using a small subsetNous utiliserons deux modèles pré-entraînés de la bibliothèque Hugging Face. Un modèle plus petit (distilbert-base-uncased-distilled-squad) servira de rédacteur du GCR et un modèle plus grand (bert-large-uncased-whole-word-masking-finetuned-squad) jouera le rôle de vérificateur des lignes directrices.
Ensuite, nous construirons un Dessinateur et un pipeline de vérification avec les modèles sélectionnés.
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
# Initialize the smaller model (RAG Drafter)
drafter_model_name = "distilbert-base-uncased-distilled-squad"
drafter_model = AutoModelForQuestionAnswering.from_pretrained(drafter_model_name)
drafter_tokenizer = AutoTokenizer.from_pretrained(drafter_model_name)
# Initialize the larger model (RAG Verifier)
verifier_model_name = "bert-large-uncased-whole-word-masking-finetuned-squad"
verifier_model = AutoModelForQuestionAnswering.from_pretrained(verifier_model_name)
verifier_tokenizer = AutoTokenizer.from_pretrained(verifier_model_name)
# Set up pipelines
drafter_pipeline = pipeline("question-answering", model=drafter_model, tokenizer=drafter_tokenizer)
verifier_pipeline = pipeline("question-answering", model=verifier_model, tokenizer=verifier_tokenizer)Ensuite, nous définirons une fonction permettant de générer plusieurs versions à l'aide du modèle plus petit et du pipeline Drafter prédéfini.
def generate_drafts(question, context, num_drafts=3):
drafts = []
for _ in range(num_drafts):
draft = Drafter_pipeline(question=question, context=context)
drafts.append(draft)
return draftsNous allons maintenant définir unefonction verify_drafts() qui utilise le modèle le plus large pour vérifier et sélectionner la meilleure ébauche sur la base des scores de confiance.
Il fonctionne en mettant en correspondance les positions des caractères de début et de fin de chaque brouillon avec les positions des jetons correspondants dans le contexte tokenisé à l'aide d'une mise en correspondance de décalage. Le modèle vérificateur attribue ensuite une note à chaque projet en fonction de la confiance qu'il a dans le fait que ces positions constituent la bonne réponse. L'ébauche ayant le score de confiance le plus élevé est sélectionnée comme la meilleure réponse, ce qui garantit que le résultat final est à la fois précis et fiable.
Le traitement minutieux de l'alignement et de la notation des jetons par cette fonction est la clé de l'amélioration des performances du RAG spéculatif.
def verify_drafts(question, context, drafts):
best_draft = None
highest_score = 0
# Tokenize the context using the verifier's tokenizer, keeping track of offsets
inputs = verifier_tokenizer(question, context, return_tensors="pt", return_offsets_mapping=True)
offset_mapping = inputs['offset_mapping'][0] # This will give us the character-to-token mapping
input_ids = inputs['input_ids'][0]
for draft in drafts:
start_char = draft['start']
end_char = draft['end']
# Find the corresponding token positions using offset mapping
start_index = None
end_index = None
for idx, (start, end) in enumerate(offset_mapping):
if start_index is None and start_char >= start and start_char < end:
start_index = idx
if end_index is None and end_char > start and end_char <= end:
end_index = idx
if start_index is not None and end_index is not None:
break
# Ensure indices were found and are within bounds
if (start_index is None or end_index is None or
start_index >= len(input_ids) or end_index >= len(input_ids)):
print(f"Draft skipped: Out of bounds or no matching tokens. "
f"Start Index: {start_index}, End Index: {end_index}")
continue
# Get the confidence score using the larger model
outputs = verifier_model(input_ids=input_ids.unsqueeze(0))
score = (outputs.start_logits[0, start_index].item() +
outputs.end_logits[0, end_index].item())
if score > highest_score:
highest_score = score
best_draft = draft
if best_draft is None:
print("No valid draft found after verification.")
return best_draftAppliquons maintenant notre processus de RAG spéculatif à 10 exemples de questions tirées de l'ensemble de données.
correct = 0
total = 10 # Evaluate on 10 samples for simplicity
for i in range(total):
sample = dataset[i]
question = sample['question']
context = sample['context']
drafts = generate_drafts(question, context)
best_answer = verify_drafts(question, context, drafts)
print(f"Q: {question}")
if best_answer is not None:
print(f"A: {best_answer['answer']}\n")
# For simplicity, compare with the first answer (gold) provided in the dataset
if best_answer['answer'].lower() in sample['answers']['text'][0].lower():
correct += 1
else:
print("No valid draft found.\n")
accuracy = correct / total * 100
print(f"Accuracy: {accuracy}%")Cet extrait de code évalue la précision d'une implémentation spéculative simplifiée de RAG sur 10 échantillons d'un ensemble de données. Pour chaque échantillon, il génère plusieurs ébauches de réponses sur la base d'une question et d'un contexte donnés, puis sélectionne la meilleure ébauche à l'aide d'une fonction de vérification. Si une réponse valide est trouvée, elle est comparée à la réponse en or (correcte) fournie dans l'ensemble de données. Si la réponse correspond, le nombre deréponses correctes sur est incrémenté.
Enfin, le code calcule et imprime la précision en pourcentage de réponses correctes sur l'ensemble des échantillons. Ce code permet d'obtenir une précision de 90 % sur cet ensemble de données simplifié.
Bien que le RAG spéculatif donne de bons résultats, il présente quelques difficultés :
Le RAG spéculatif peut être appliqué à un large éventail de domaines dans lesquels une recherche d'informations précise et efficace est essentielle. Voici quelques applications potentielles :
Le RAG spéculatif améliore la génération augmentée par la recherche en améliorant la précision, en réduisant la latence, l'efficacité des ressources et l'évolutivité. Nous avons démontré sa mise en œuvre en utilisant les transformateurs Hugging Face.
Bien qu'il y ait des défis à relever, le potentiel du RAG spéculatif dans divers domaines le rend prometteur pour la poursuite des recherches.
Si vous souhaitez en savoir plus sur la mise en œuvre de RAG, je vous recommande les tutoriels suivants :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours