
Programa
Desenvolvimento de aplicativos de IA
21 h
Modelos de linguagem grandes (LLMs) muitas vezes não são suficientes quando se trata de tarefas com uso intensivo de conhecimento que exigem informações atualizadas e precisas. É aqui que a geração aumentada por recuperação (RAG) combina os recursos generativos dos LLMs com bases de conhecimento externas para aumentar a precisão e a relevância.
Apesar de sua eficácia, os sistemas RAG tradicionais enfrentam desafios no gerenciamento de documentos longos e complexos, o que leva a uma maior latência e, às vezes, a resultados menos precisos. Para resolver esses problemas, o conceito de speculative RAG surgiu como uma solução promissora. Vamos descobrir mais sobre isso.
A geração de recuperação especulativa aumentada (RAG) é uma estrutura inovadora projetada para melhorar a eficiência e a precisão dos sistemas RAG, dividindo o processo de geração em duas etapas distintas:
Vamos entender melhor o RAG especulativo examinando este diagrama:
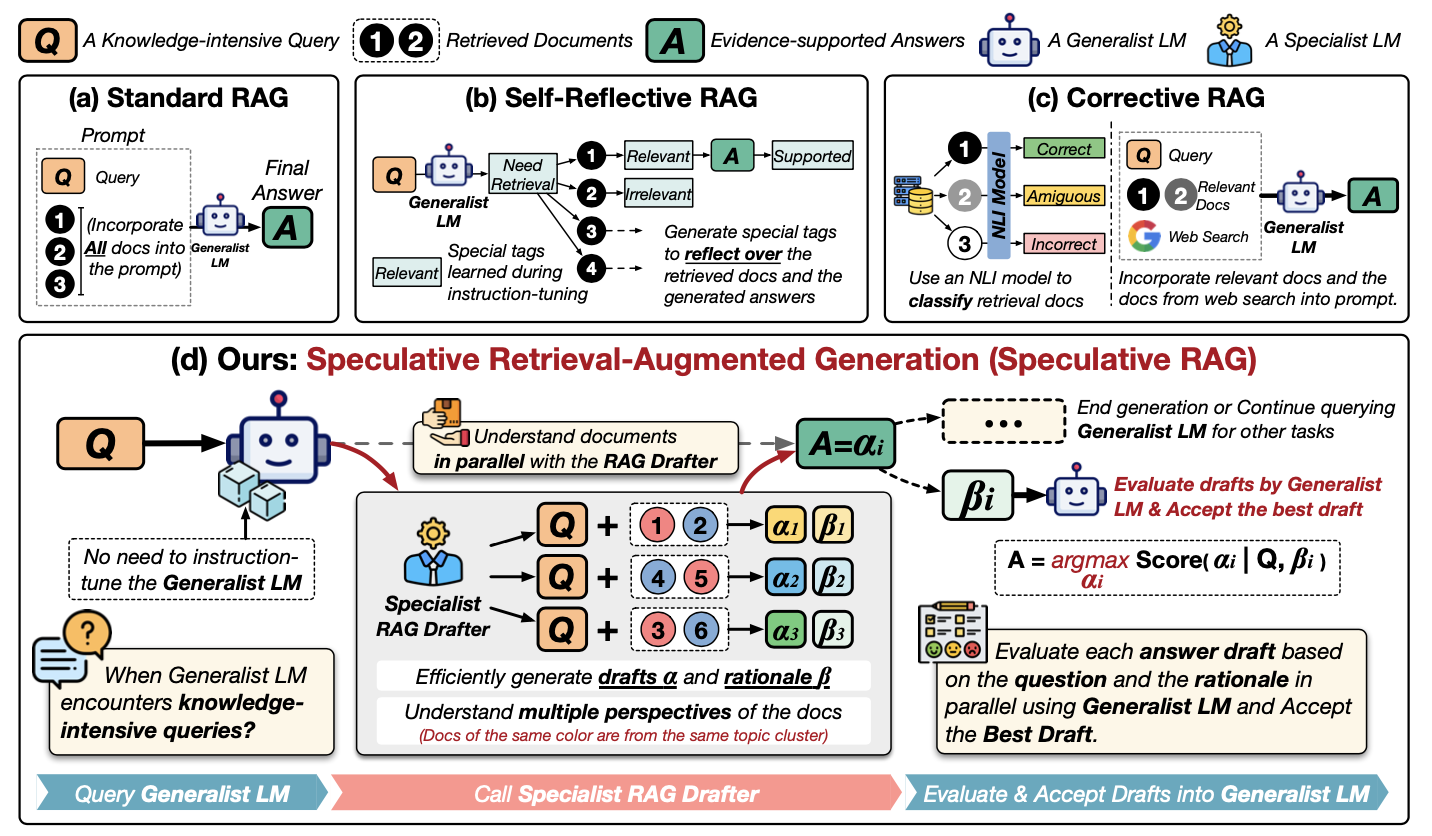
Fonte: Wang et al., 2024
Vamos examinar esse diagrama passo a passo. Ele mostra diferentes maneiras de usar informações externas para ajudar um LLM a responder perguntas, concentrando-se em um novo método chamado RAG especulativo. Vamos examinar os métodos na primeira linha:
Agora, vamos dar uma olhada mais de perto em (d) RAG especulativo:
Essencialmente, o RAG especulativo é como ter uma equipe de especialistas: o redator cria opções e o LLM generalista toma a decisão final. Isso torna o processo mais rápido e potencialmente mais preciso.
O RAG especulativo oferece várias vantagens importantes em relação aos sistemas RAG tradicionais:
Ao usar um RAG Drafter especializado para gerar vários rascunhos de diversos subconjuntos de documentos, o RAG especulativo melhora a precisão do resultado final. Essa abordagem permite que o sistema considere várias perspectivas, reduzindo as chances de gerar respostas incorretas ou tendenciosas. Em experimentos, o RAG especulativo demonstrou um aumento de até 12,97% na precisão em benchmarks como o PubHealth em comparação com os sistemas RAG convencionais.
Um dos desafios mais significativos dos sistemas RAG tradicionais é o aumento da latência causado pelo processamento de documentos longos e complexos. O RAG especulativo aborda esse problema transferindo o processo de elaboração para um módulo menor e mais eficiente, que pode gerar rascunhos em paralelo. Essa abordagem reduz o tempo total de processamento, com melhorias de latência de até 51% em alguns casos.
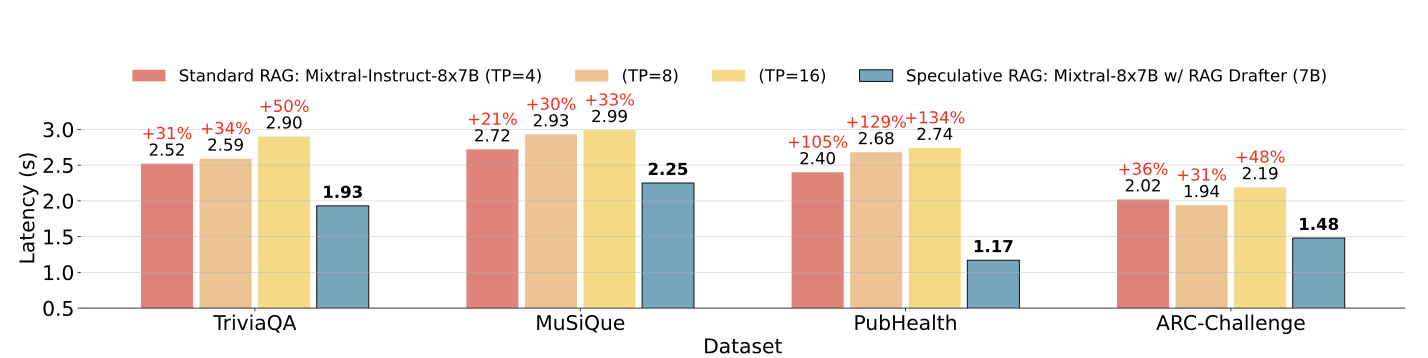
Latência do RAG especulativo versus latência do RAG padrão em diferentes conjuntos de dados. Fonte: Wang et al., 2024
O RAG especulativo otimiza o uso de recursos delegando a tarefa de elaboração a um LM menor, que é menos intensivo em termos de computação do que o LM generalista maior usado nos sistemas RAG tradicionais. Essa divisão de trabalho não apenas acelera o processo de geração, mas também reduz a carga computacional geral, tornando-a uma solução mais eficiente em termos de recursos.
A estrutura Speculative RAG é altamente adaptável e pode ser aplicada a várias tarefas de conhecimento intensivo sem a necessidade de ajustes extensivos. Essa escalabilidade o torna uma solução ideal para uma ampla gama de aplicativos, desde a resposta a perguntas até a análise de documentos complexos.
Para implementar uma versão simplificada do Speculative RAG para uma tarefa básica de resposta a perguntas, usaremos um pequeno conjunto de dados e uma configuração simples com dois modelos: um modelo menor para elaboração e um maior para verificação.
Para simplificar, usaremos os Transformadores de rosto de abraço biblioteca. Demonstraremos como usar um modelo de linguagem menor para gerar vários rascunhos e um modelo maior para verificar e selecionar o melhor rascunho.
Primeiro, vamos instalar as bibliotecas necessárias. Você precisará reiniciar a sessão depois de instalar a biblioteca de transformadores do HuggingFace. Certifique-se de que você adicionou as credenciais do HuggingFace em uma chave secreta no Collab ou em qualquer outro editor.
!pip install transformers torch datasetsPara este exemplo, usaremos o SQuAD (Stanford Question Answering Dataset) disponível na biblioteca de conjuntos de dados Hugging Face.
from datasets import load_dataset
# Load the SQuAD dataset
dataset = load_dataset("squad", split="train[:100]") # Using a small subsetUsaremos dois modelos pré-treinados da biblioteca Hugging Face. Um modelo menor (distilbert-base-uncased-distilled-squad) atuará como nosso RAG Drafter e um modelo maior (bert-large-uncased-whole-word-masking-finetuned-squad) atuará como o verificador de RAG.
Em seguida, criaremos um Drafter e um pipeline do verificador com os modelos selecionados.
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
# Initialize the smaller model (RAG Drafter)
drafter_model_name = "distilbert-base-uncased-distilled-squad"
drafter_model = AutoModelForQuestionAnswering.from_pretrained(drafter_model_name)
drafter_tokenizer = AutoTokenizer.from_pretrained(drafter_model_name)
# Initialize the larger model (RAG Verifier)
verifier_model_name = "bert-large-uncased-whole-word-masking-finetuned-squad"
verifier_model = AutoModelForQuestionAnswering.from_pretrained(verifier_model_name)
verifier_tokenizer = AutoTokenizer.from_pretrained(verifier_model_name)
# Set up pipelines
drafter_pipeline = pipeline("question-answering", model=drafter_model, tokenizer=drafter_tokenizer)
verifier_pipeline = pipeline("question-answering", model=verifier_model, tokenizer=verifier_tokenizer)Em seguida, definiremos uma função para gerar vários rascunhos usando o modelo menor com o pipeline predefinido do Drafter.
def generate_drafts(question, context, num_drafts=3):
drafts = []
for _ in range(num_drafts):
draft = Drafter_pipeline(question=question, context=context)
drafts.append(draft)
return draftsAgora, definiremos umafunção verify_drafts() que usa o modelo maior para verificar e selecionar o melhor rascunho com base nas pontuações de confiança.
Ele funciona mapeando as posições do caractere inicial e final de cada rascunho para as posições de token correspondentes no contexto tokenizado usando um mapeamento de deslocamento. Em seguida, o modelo do verificador pontua cada rascunho com base em sua confiança de que essas posições são a resposta correta. O rascunho com a maior pontuação de confiança é selecionado como a melhor resposta, garantindo que o resultado final seja preciso e confiável.
O manuseio cuidadoso dessa função de alinhamento e pontuação de tokens é fundamental para o desempenho aprimorado do RAG especulativo.
def verify_drafts(question, context, drafts):
best_draft = None
highest_score = 0
# Tokenize the context using the verifier's tokenizer, keeping track of offsets
inputs = verifier_tokenizer(question, context, return_tensors="pt", return_offsets_mapping=True)
offset_mapping = inputs['offset_mapping'][0] # This will give us the character-to-token mapping
input_ids = inputs['input_ids'][0]
for draft in drafts:
start_char = draft['start']
end_char = draft['end']
# Find the corresponding token positions using offset mapping
start_index = None
end_index = None
for idx, (start, end) in enumerate(offset_mapping):
if start_index is None and start_char >= start and start_char < end:
start_index = idx
if end_index is None and end_char > start and end_char <= end:
end_index = idx
if start_index is not None and end_index is not None:
break
# Ensure indices were found and are within bounds
if (start_index is None or end_index is None or
start_index >= len(input_ids) or end_index >= len(input_ids)):
print(f"Draft skipped: Out of bounds or no matching tokens. "
f"Start Index: {start_index}, End Index: {end_index}")
continue
# Get the confidence score using the larger model
outputs = verifier_model(input_ids=input_ids.unsqueeze(0))
score = (outputs.start_logits[0, start_index].item() +
outputs.end_logits[0, end_index].item())
if score > highest_score:
highest_score = score
best_draft = draft
if best_draft is None:
print("No valid draft found after verification.")
return best_draftAgora, vamos aplicar nosso processo de RAG especulativo a 10 exemplos de perguntas do conjunto de dados.
correct = 0
total = 10 # Evaluate on 10 samples for simplicity
for i in range(total):
sample = dataset[i]
question = sample['question']
context = sample['context']
drafts = generate_drafts(question, context)
best_answer = verify_drafts(question, context, drafts)
print(f"Q: {question}")
if best_answer is not None:
print(f"A: {best_answer['answer']}\n")
# For simplicity, compare with the first answer (gold) provided in the dataset
if best_answer['answer'].lower() in sample['answers']['text'][0].lower():
correct += 1
else:
print("No valid draft found.\n")
accuracy = correct / total * 100
print(f"Accuracy: {accuracy}%")Esse trecho de código avalia a precisão de uma implementação especulativa simplificada do RAG em 10 amostras de um conjunto de dados. Para cada amostra, ele gera vários rascunhos de respostas com base em uma determinada pergunta e contexto e, em seguida, seleciona o melhor rascunho usando uma função de verificação. Se uma resposta válida for encontrada, ela será comparada com a resposta "gold" (correta) fornecida no conjunto de dados. Se a resposta corresponder, a contagem de corretas será incrementada.
Por fim, o código calcula e imprime a precisão como uma porcentagem de respostas corretas em relação ao total de amostras. Esse código produz uma precisão de 90% nesse conjunto de dados simplificado.
Embora o RAG especulativo forneça bons resultados, ele apresenta alguns desafios:
O RAG especulativo pode ser aplicado em uma ampla gama de domínios em que a recuperação precisa e eficiente de informações é fundamental. Aqui estão alguns aplicativos em potencial:
O RAG especulativo aprimora a geração aumentada por recuperação com precisão aprimorada, latência reduzida, eficiência de recursos e escalabilidade. Demonstramos sua implementação usando o Hugging Face Transformers.
Embora existam desafios, o potencial do RAG especulativo em vários domínios o torna promissor para pesquisas futuras.
Se você quiser saber mais sobre a implementação do RAG, recomendo os seguintes tutoriais:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
11 min
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita


