
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Große Sprachmodelle (LLMs) greifen oft zu kurz, wenn es um wissensintensive Aufgaben geht, die aktuelle und präzise Informationen erfordern. Hier ist die Retrieval-augmented Generation (RAG) ein und kombiniert die generativen Fähigkeiten von LLMs mit externen Wissensdatenbanken, um die Genauigkeit und Relevanz zu verbessern.
Trotz ihrer Effektivität haben herkömmliche RAG-Systeme Probleme bei der Verwaltung langer und komplexer Dokumente, was zu einer erhöhten Latenzzeit und manchmal zu weniger genauen Ergebnissen führt. Um diese Probleme zu lösen, hat sich das Konzept der spekulativen RAG als vielversprechende Lösung erwiesen. Lass uns mehr darüber herausfinden.
Speculative retrieval-augmented generation (RAG) ist ein innovatives Framework, das die Effizienz und Genauigkeit von RAG-Systemen verbessern soll, indem es den Generierungsprozess in zwei verschiedene Schritte unterteilt:
Um die spekulativen RAG besser zu verstehen, schau dir dieses Diagramm an:
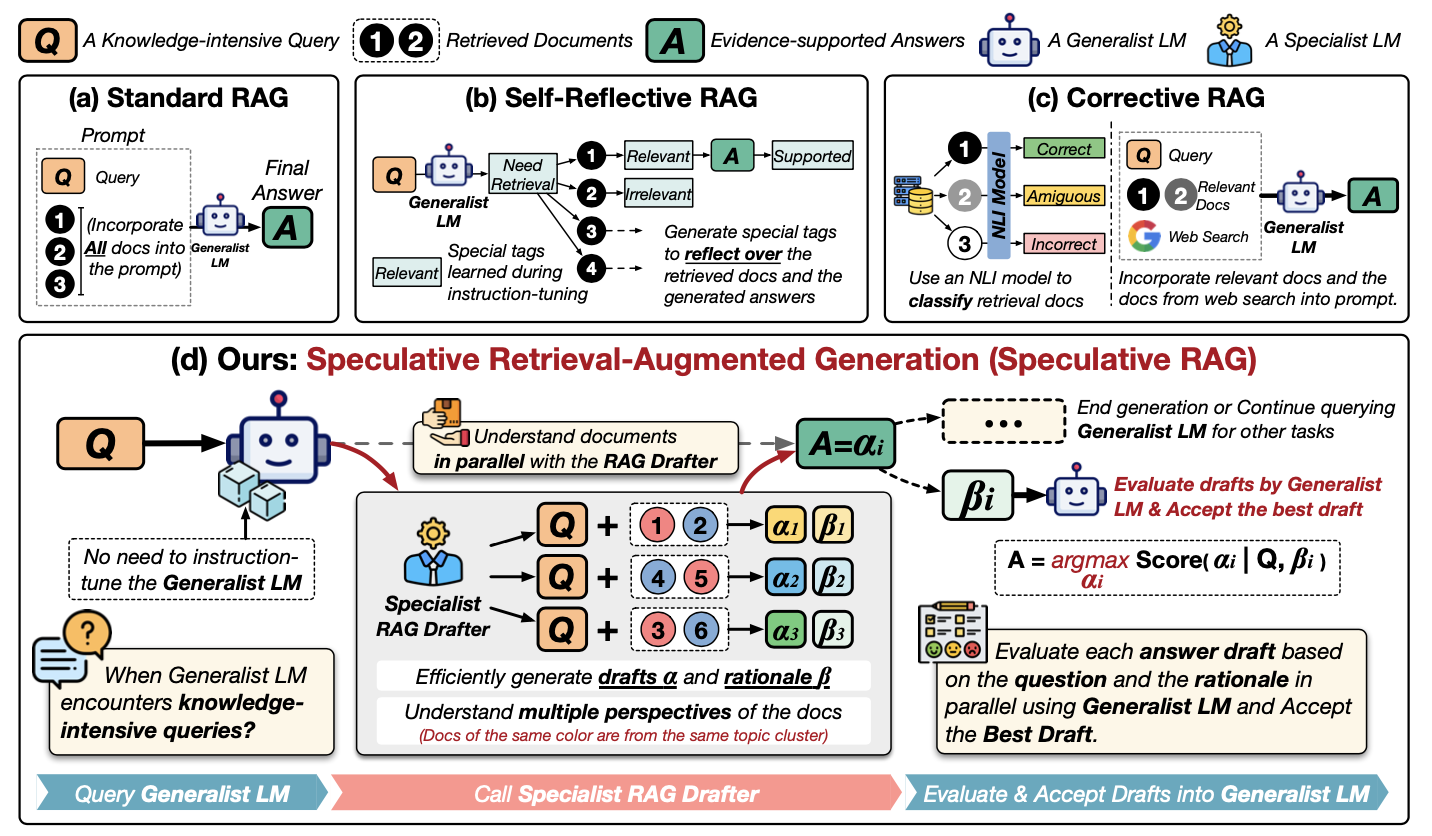
Quelle: Wang et al., 2024
Lass uns dieses Diagramm Schritt für Schritt durchgehen. Er zeigt verschiedene Möglichkeiten auf, wie man externe Informationen nutzen kann, um einem LLM bei der Beantwortung von Fragen zu helfen, und konzentriert sich dabei auf eine neue Methode namens Speculative RAG. Schauen wir uns die Methoden in der ersten Reihe an:
Werfen wir nun einen genauen Blick auf (d) Spekulative RAG:
Im Grunde ist die spekulative RAG wie ein Expertenteam: Der Verfasser erstellt Optionen, und der Generalist LLM trifft die endgültige Entscheidung. Das macht den Prozess schneller und möglicherweise genauer.
Die spekulative RAG bietet mehrere entscheidende Vorteile gegenüber traditionellen RAG-Systemen:
Durch den Einsatz eines speziellen RAG Drafters, der mehrere Entwürfe aus verschiedenen Teilmengen von Dokumenten erstellt, verbessert Speculative RAG die Genauigkeit der endgültigen Ausgabe. Dieser Ansatz ermöglicht es dem System, mehrere Perspektiven zu berücksichtigen, was die Wahrscheinlichkeit falscher oder voreingenommener Antworten verringert. In Experimenten zeigte Speculative RAG bei Benchmarks wie PubHealth eine Verbesserung der Genauigkeit um bis zu 12,97% im Vergleich zu herkömmlichen RAG-Systemen.
Eine der größten Herausforderungen bei herkömmlichen RAG-Systemen ist die erhöhte Latenzzeit, die durch die Verarbeitung langer und komplexer Dokumente entsteht. Die spekulative RAG löst dieses Problem, indem sie den Entwurfsprozess an eine kleinere, effizientere LM auslagert, die parallel Entwürfe erstellen kann. Dieser Ansatz verkürzt die Gesamtverarbeitungszeit, wobei die Latenzzeit in einigen Fällen um bis zu 51% verbessert wird.
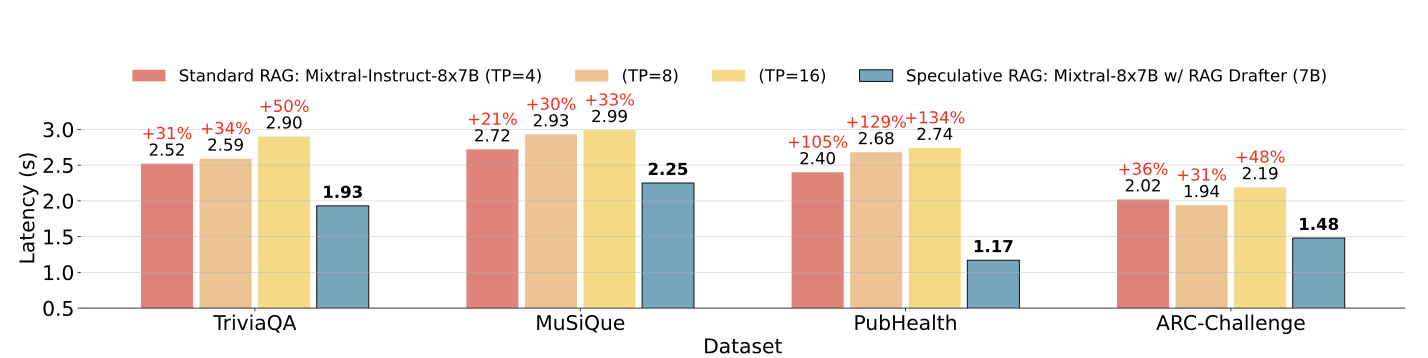
Spekulative RAG-Latenz im Vergleich zur Standard-RAG-Latenz bei verschiedenen Datensätzen. Quelle: Wang et al., 2024
Die spekulative RAG optimiert die Ressourcennutzung, indem sie die Entwurfsaufgabe an einen kleineren LM delegiert, der weniger rechenintensiv ist als der größere generalistische LM, der in traditionellen RAG-Systemen verwendet wird. Diese Arbeitsteilung beschleunigt nicht nur den Generierungsprozess, sondern reduziert auch die gesamte Rechenlast und ist damit eine ressourceneffizientere Lösung.
Das spekulative RAG-Framework ist sehr anpassungsfähig und kann auf verschiedene wissensintensive Aufgaben angewendet werden, ohne dass ein umfangreiches Tuning erforderlich ist. Diese Skalierbarkeit macht sie zu einer idealen Lösung für eine Vielzahl von Anwendungen, von der Beantwortung von Fragen bis hin zur komplexen Dokumentenanalyse.
Um eine vereinfachte Version von Speculative RAG für eine einfache Frage-Antwort-Aufgabe zu implementieren, verwenden wir einen kleinen Datensatz und ein einfaches Setup mit zwei Modellen - ein kleineres Modell zum Entwerfen und ein größeres zur Überprüfung.
Der Einfachheit halber verwenden wir die Umarmende Gesichtstransformatoren Bibliothek. Wir zeigen dir, wie du ein kleineres Sprachmodell verwendest, um mehrere Entwürfe zu erstellen, und ein größeres Modell, um den besten Entwurf zu überprüfen und auszuwählen.
Installieren wir zunächst die notwendigen Bibliotheken. Du musst die Sitzung neu starten, nachdem du die Transformatoren-Bibliothek von HuggingFace installiert hast. Vergewissere dich, dass du die HuggingFace-Anmeldedaten unter einem geheimen Schlüssel in Collab oder einem anderen Editor hinzugefügt hast.
!pip install transformers torch datasetsFür dieses Beispiel verwenden wir die SQuAD (Stanford Question Answering Dataset), das in der Hugging Face Datasets Library verfügbar ist.
from datasets import load_dataset
# Load the SQuAD dataset
dataset = load_dataset("squad", split="train[:100]") # Using a small subsetWir werden zwei vortrainierte Modelle aus der Hugging Face Bibliothek verwenden. Ein kleineres Modell (distilbert-base-uncased-distilled-squad) wird als unser RAG Drafter fungieren und ein größeres Modell (bert-large-uncased-whole-word-masking-finetuned-squad) wird als RAG-Prüfer fungieren.
Dann bauen wir einen Zeichner und eine Verifier-Pipeline mit den ausgewählten Modellen.
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
# Initialize the smaller model (RAG Drafter)
drafter_model_name = "distilbert-base-uncased-distilled-squad"
drafter_model = AutoModelForQuestionAnswering.from_pretrained(drafter_model_name)
drafter_tokenizer = AutoTokenizer.from_pretrained(drafter_model_name)
# Initialize the larger model (RAG Verifier)
verifier_model_name = "bert-large-uncased-whole-word-masking-finetuned-squad"
verifier_model = AutoModelForQuestionAnswering.from_pretrained(verifier_model_name)
verifier_tokenizer = AutoTokenizer.from_pretrained(verifier_model_name)
# Set up pipelines
drafter_pipeline = pipeline("question-answering", model=drafter_model, tokenizer=drafter_tokenizer)
verifier_pipeline = pipeline("question-answering", model=verifier_model, tokenizer=verifier_tokenizer)Als Nächstes definieren wir eine Funktion, um mehrere Entwürfe zu erstellen, indem wir das kleinere Modell mit der vordefinierten Drafter-Pipeline verwenden.
def generate_drafts(question, context, num_drafts=3):
drafts = []
for _ in range(num_drafts):
draft = Drafter_pipeline(question=question, context=context)
drafts.append(draft)
return draftsWir werden nun eine verify_drafts() Funktion definieren, die das größere Modell verwendet, um den besten Entwurf auf der Grundlage der Konfidenzwerte zu überprüfen und auszuwählen.
Dabei werden die Positionen der Anfangs- und Endzeichen der einzelnen Entwürfe mithilfe einer Offset-Zuordnung auf die entsprechenden Token-Positionen im tokenisierten Kontext abgebildet. Das Verifizierungsmodell bewertet dann jeden Entwurf auf der Grundlage seines Vertrauens, dass diese Positionen die richtige Antwort sind. Der Entwurf mit dem höchsten Konfidenzwert wird als beste Antwort ausgewählt, um sicherzustellen, dass die endgültige Ausgabe sowohl genau als auch zuverlässig ist.
Die sorgfältige Handhabung der Token-Ausrichtung und der Punktevergabe durch diese Funktion ist der Schlüssel zur verbesserten Leistung von Speculative RAG.
def verify_drafts(question, context, drafts):
best_draft = None
highest_score = 0
# Tokenize the context using the verifier's tokenizer, keeping track of offsets
inputs = verifier_tokenizer(question, context, return_tensors="pt", return_offsets_mapping=True)
offset_mapping = inputs['offset_mapping'][0] # This will give us the character-to-token mapping
input_ids = inputs['input_ids'][0]
for draft in drafts:
start_char = draft['start']
end_char = draft['end']
# Find the corresponding token positions using offset mapping
start_index = None
end_index = None
for idx, (start, end) in enumerate(offset_mapping):
if start_index is None and start_char >= start and start_char < end:
start_index = idx
if end_index is None and end_char > start and end_char <= end:
end_index = idx
if start_index is not None and end_index is not None:
break
# Ensure indices were found and are within bounds
if (start_index is None or end_index is None or
start_index >= len(input_ids) or end_index >= len(input_ids)):
print(f"Draft skipped: Out of bounds or no matching tokens. "
f"Start Index: {start_index}, End Index: {end_index}")
continue
# Get the confidence score using the larger model
outputs = verifier_model(input_ids=input_ids.unsqueeze(0))
score = (outputs.start_logits[0, start_index].item() +
outputs.end_logits[0, end_index].item())
if score > highest_score:
highest_score = score
best_draft = draft
if best_draft is None:
print("No valid draft found after verification.")
return best_draftWenden wir nun unseren spekulativen RAG-Prozess auf 10 Beispielfragen aus dem Datensatz an.
correct = 0
total = 10 # Evaluate on 10 samples for simplicity
for i in range(total):
sample = dataset[i]
question = sample['question']
context = sample['context']
drafts = generate_drafts(question, context)
best_answer = verify_drafts(question, context, drafts)
print(f"Q: {question}")
if best_answer is not None:
print(f"A: {best_answer['answer']}\n")
# For simplicity, compare with the first answer (gold) provided in the dataset
if best_answer['answer'].lower() in sample['answers']['text'][0].lower():
correct += 1
else:
print("No valid draft found.\n")
accuracy = correct / total * 100
print(f"Accuracy: {accuracy}%")Dieser Codeschnipsel bewertet die Genauigkeit einer vereinfachten spekulativen RAG-Implementierung anhand von 10 Stichproben aus einem Datensatz. Für jede Probe werden mehrere Antwortentwürfe auf der Grundlage einer gegebenen Frage und eines gegebenen Kontexts erstellt und dann der beste Entwurf mithilfe einer Überprüfungsfunktion ausgewählt. Wenn eine gültige Antwort gefunden wird, vergleicht sie diese Antwort mit der goldenen (richtigen) Antwort aus dem Datensatz. Wenn die Antwort übereinstimmt, wird die Anzahl derrichtigen erhöht.
Zum Schluss berechnet und druckt der Code die Genauigkeit als Prozentsatz der richtigen Antworten im Verhältnis zur Gesamtzahl der Stichproben. Mit diesem Code wird eine Genauigkeit von 90 % für diesen vereinfachten Datensatz erreicht.
Obwohl die spekulative RAG gute Ergebnisse liefert, bringt sie einige Herausforderungen mit sich:
Spekulative RAG kann in einer Vielzahl von Bereichen eingesetzt werden, in denen eine genaue und effiziente Informationsbeschaffung entscheidend ist. Hier sind einige mögliche Anwendungen:
Spekulative RAG verbessert die abruferweiterte Generierung mit verbesserter Genauigkeit, reduzierter Latenz, Ressourceneffizienz und Skalierbarkeit. Wir haben die Umsetzung mit Hugging Face Transformers demonstriert.
Es gibt zwar noch Herausforderungen, aber das Potenzial der spekulativen RAG in verschiedenen Bereichen macht sie vielversprechend für weitere Forschung.
Wenn du mehr über die RAG-Implementierung erfahren möchtest, empfehle ich dir die folgenden Tutorials:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
