
Curso
Building Agentic Workflows with LlamaIndex
2 h
1.2K
MetaStone AI ha lanzado recientemente XBai-o4, un modelo de razonamiento de código abierto que introduce el escalado paralelo en tiempo de prueba y una arquitectura generativa reflexiva. Con 32 800 millones de parámetros y un cabezal de autoevaluación integrado, XBai o4 supera al o3-mini (modo medio) de OpenAI en las pruebas básicas de razonamiento matemático cuando se ejecuta localmente.
En este blog me centraré en las capacidades únicas de razonamiento reflexivo de XBai o4, demostrando cómo genera y evalúa múltiples trayectorias de solución para problemas matemáticos a través de una interfaz Streamlit implementada localmente y alimentada por LM Studio.
En este tutorial, explicaré paso a paso cómo:
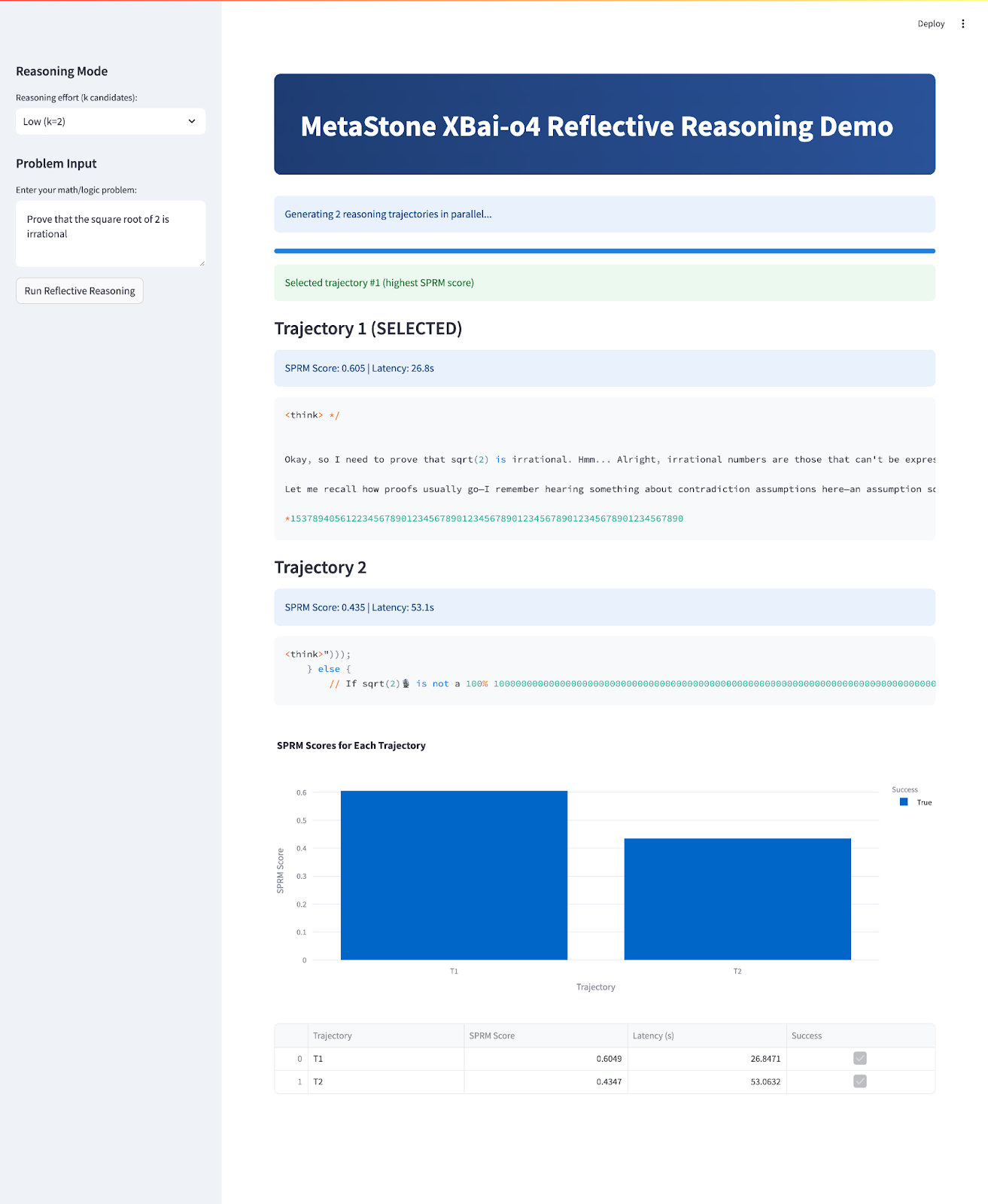
Al final, tu aplicación tendrá este aspecto:
XBai-o4 es el modelo de razonamiento de código abierto de cuarta generación de MetaStone AI, que introduce una arquitectura generativa reflexiva que intenta redefinir la forma en que la IA aborda la resolución de problemas complejos. A diferencia de los LLM tradicionales, que tratan la generación y la evaluación de respuestas como dos procesos distintos, XBai o4 fusiona ambos en un modelo unificado mediante un modelo de recompensa de procesos compartidos (SPRM). Este diseño permite al modelo generar, puntuar y seleccionar múltiples rutas de razonamiento en paralelo.
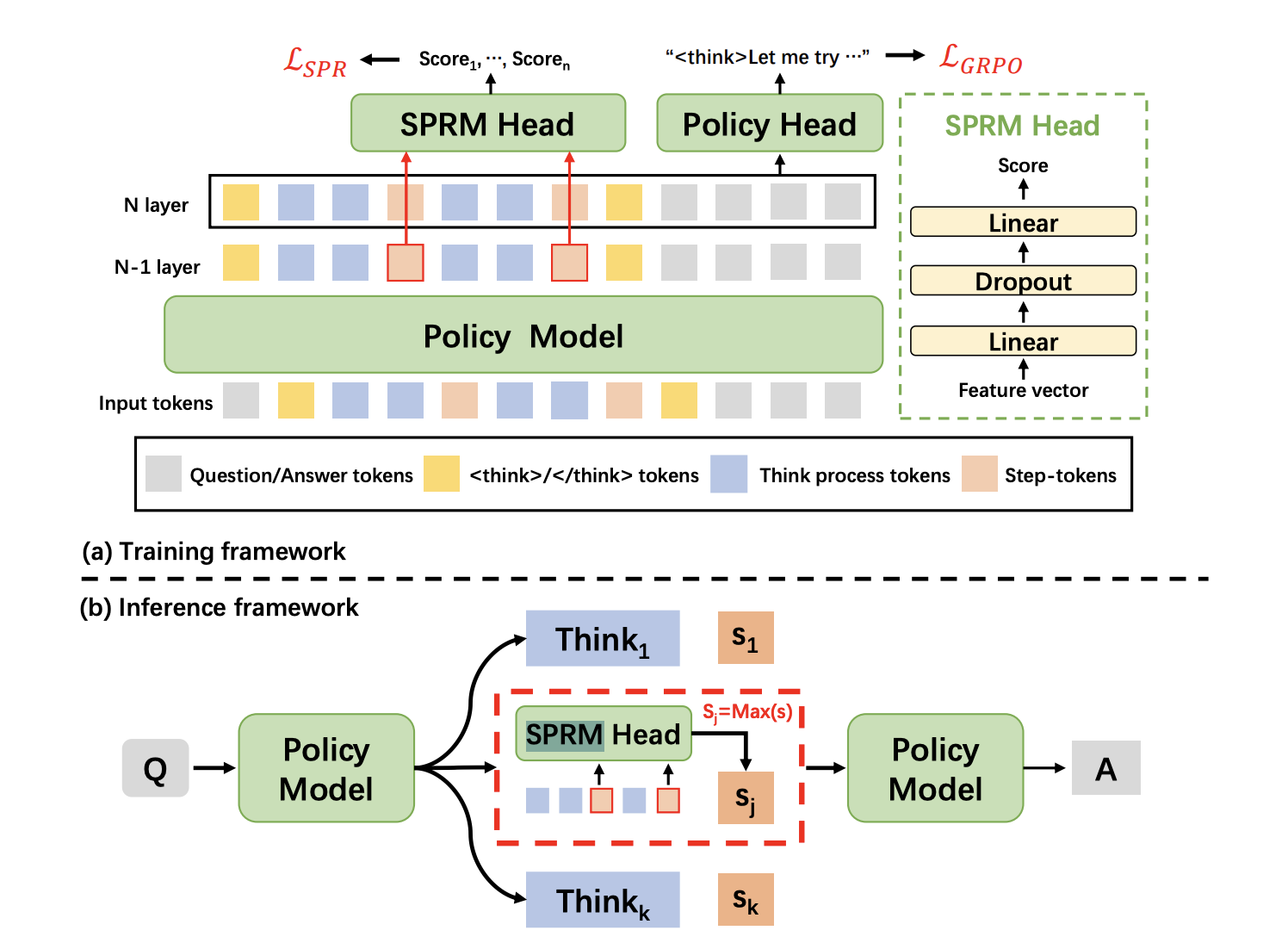
Fuente: Jefe de SPRM
En esencia, XBai o4 combina el aprendizaje por refuerzo de cadena de pensamiento larga (Long-CoT) y el aprendizaje por recompensa de procesos ( ) en un único proceso de entrenamiento. Estas son algunas de las innovaciones clave introducidas en este modelo:
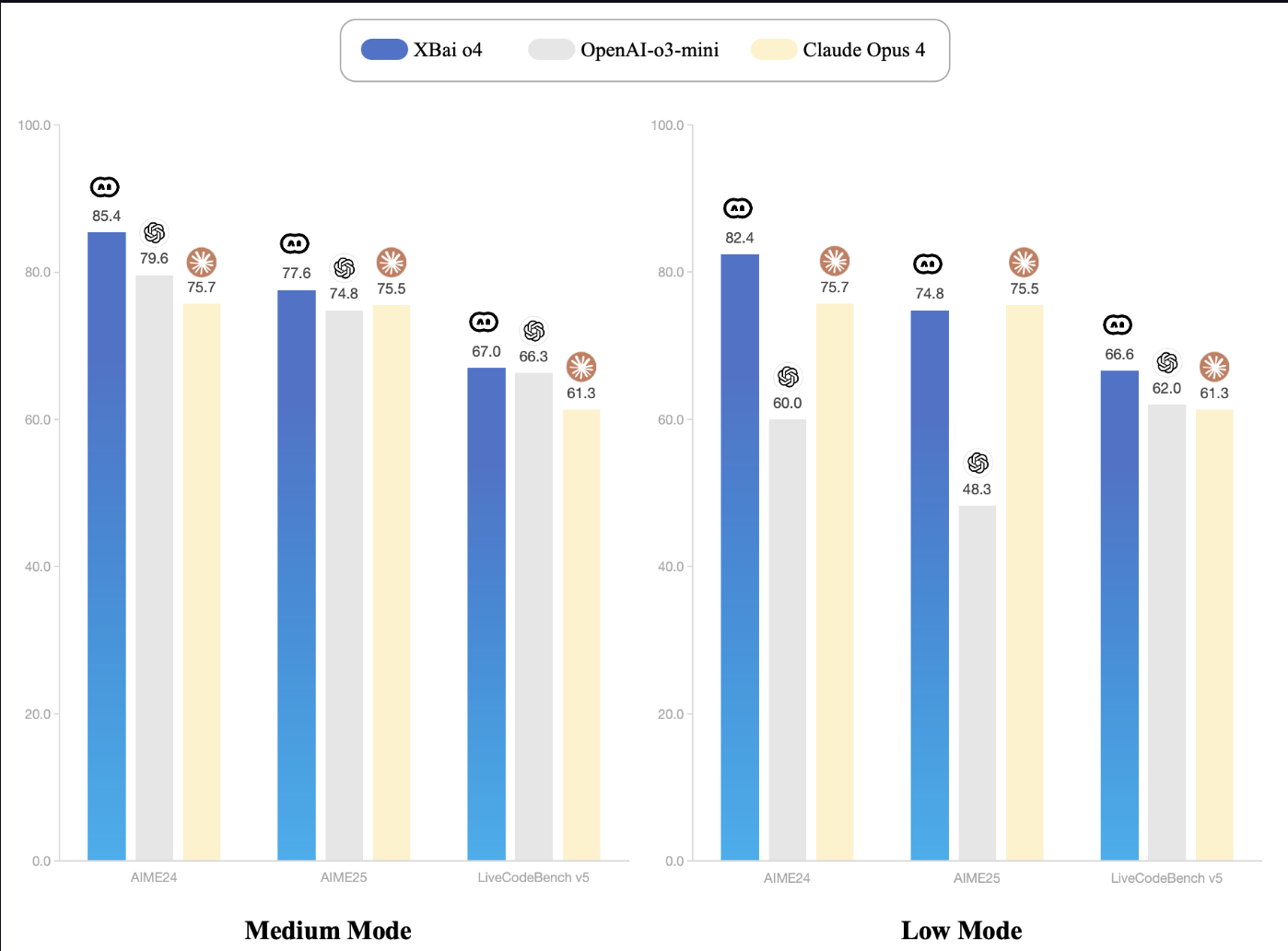
Fuente: Documentación de XBai-O4
Puedes ejecutar XBai o4 localmente utilizando LM Studio, que utiliza automáticamente la aceleración de la GPU de tu sistema o Apple Silicon (Metal/MLX) cuando está disponible (no es necesaria ninguna configuración manual). Para obtener un rendimiento y una compatibilidad óptimos, te recomiendo utilizar la versión cuantificada GGUF del modelo.
El estándar GGUF (formato unificado generado por GPT) permite una inferencia local muy eficiente al reducir la precisión de los pesos del modelo. En este proyecto, utilizaremos la variante cuantificada Q3_K_S, que es una opción muy popular por su excelente equilibrio entre calidad y uso de memoria.
Q3_K_S ofrece un gran rendimiento de razonamiento con una pérdida mínima de calidad en comparación con los modelos de precisión completa.Veamos paso a paso el proceso de configuración del modelo GGUF cuantificado para una inferencia local eficiente con LM Studio.
LM Studio ofrece compatibilidad con GGUF y selecciona automáticamente el backend de inferencia óptimo para tu hardware, ya sea Metal, GPU o CPU.
Si aún no has instalado LM Studio, solo tienes que descargarlo desde lmstudio.ai y seguir las instrucciones de instalación.
En LM Studio:
mradermacher/XBai-o4-GGUFXBai-o4.Q3_K_S.gguf (14,39 GB).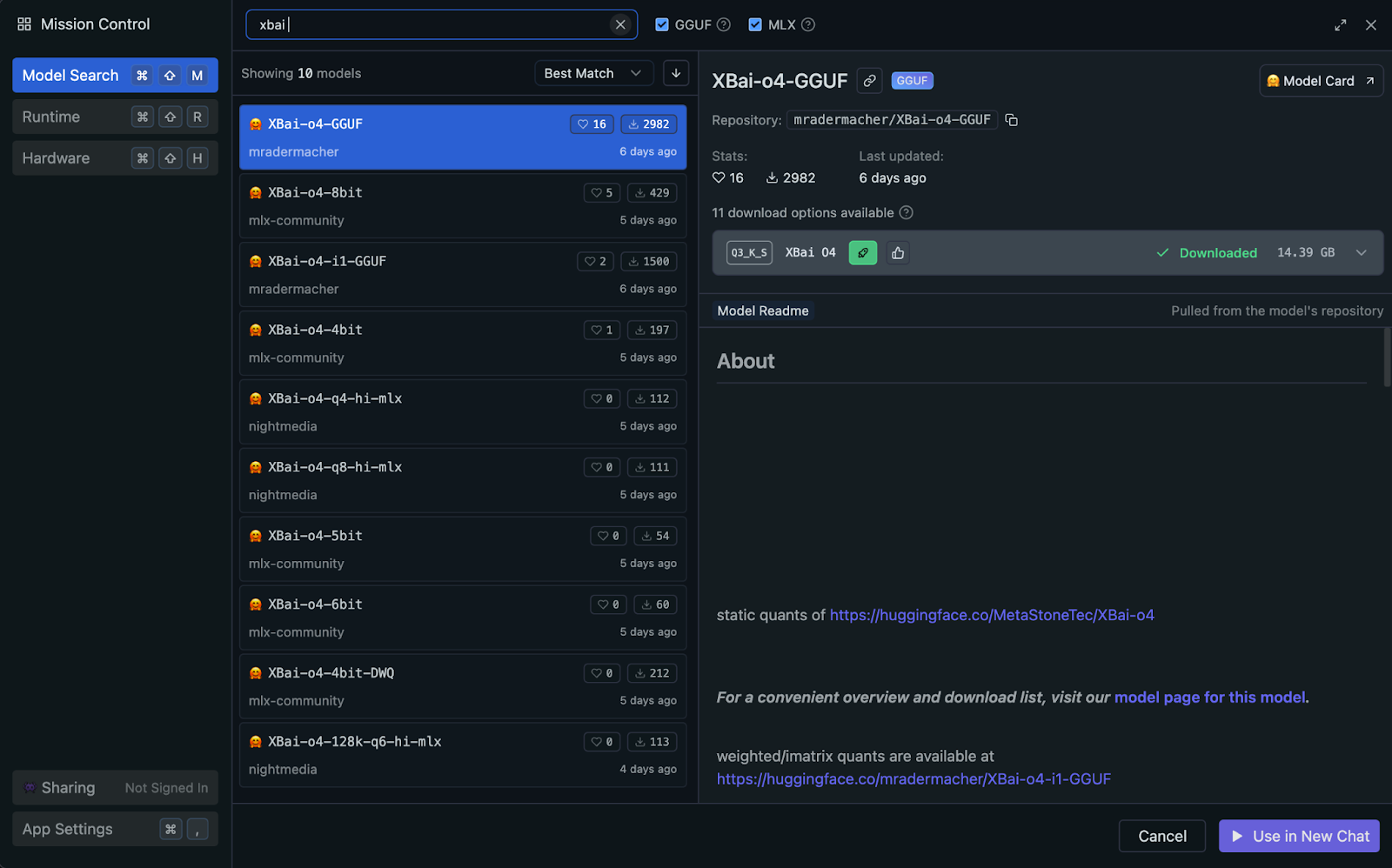
Una vez instalado LM Studio, cargamos y configuramos el modelo XBai o4 para la inferencia local:
XBai-o4.Q3_K_S.gguf » de la lista de modelos descargados.Una vez en funcionamiento, tu sistema estará listo para el razonamiento multitrayectoria con XBai o4.
Ahora crearemos una aplicación Streamlit que muestra las capacidades de razonamiento reflexivo de XBai o4 con una comparación de rendimiento en tiempo real.
Comienza instalando las dependencias:
pip install streamlit plotly pandas numpy requestsEste comando garantiza que tengas todas las dependencias básicas para la interfaz de usuario, el manejo de datos, el gráfico y las solicitudes de API.
A continuación, importa todas las bibliotecas necesarias y configura el diseño de la página de Streamlit y los ajustes básicos.
import streamlit as st
import time
import requests
import numpy as np
import pandas as pd
import plotly.express as px
from typing import List, Dict, Any
LM_STUDIO_URL = "http://localhost:1234/v1" # change as per your server
REASONING_MODES = {"Low (k=2)": 2, "Medium (k=8)": 8, "High (k=32)": 8}
st.set_page_config(page_title="MetaStone-XBai-o4 Reflective Reasoning Demo", layout="wide")
st.markdown("""
<style>
.main-header {
background: linear-gradient(90deg, #1e3c72 0%, #2a5298 100%);
border-radius: 10px;
color: white;
text-align: center;
}
</style>
""", unsafe_allow_html=True)Este bloque de código importa todas las bibliotecas principales necesarias para nuestra demostración, incluyendo Streamlit para la interfaz de usuario web, así como otras bibliotecas básicas como time, requests, numpy, pandas, plotly.express y herramientas de tipado.
A continuación, establece el punto final de la API del modelo LM_STUDIO_URL para que la aplicación sepa dónde enviar las solicitudes, y define los modos de razonamiento (REASONING_MODES) para que los usuarios puedan seleccionar fácilmente cuántas ramas de solución generar.
Por último, utilizamos st.set_page_config() para configurar la interfaz de usuario de Streamlit con un título personalizado, un diseño amplio y un encabezado con degradado en estilo CSS.
Nota: LM_STUDIO_URL es la URL base del servidor LLM, que puedes copiar desde LM Studio. Normalmente es «http://localhost:1234/v1"», pero puede variar. Además, elige los modos de razonamiento según la capacidad de tu servidor.
Ahora, creemos un conjunto de funciones auxiliares que impulsen la lógica central de «razonamiento reflexivo» de nuestra aplicación. Estas funciones facilitan el trabajo con múltiples trayectorias, la selección de la mejor solución y la puntuación de cada respuesta.
Este paso introduce una función auxiliar sencilla que comprueba automáticamente si nuestro servidor LM Studio puede gestionar el muestreo multitrayectoria. Algunos servidores admiten la solicitud de completado asíncrono ( n parameter), lo que nos permite solicitar varias completaciones independientes en una sola llamada a la API, lo que acelera considerablemente el proceso.
def supports_n_param():
payload = {
"messages": [{"role": "user", "content": "What is 1+1?"}],
"max_tokens": 80,
"temperature": 0.1,
"n": 2,
"stream": False
}
try:
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
if resp.status_code == 200 and len(resp.json().get("choices", [])) == 2:
return True
except Exception:
pass
return FalseEsta función comprueba si tu servidor LM Studio admite la generación de múltiples respuestas («trayectorias») en una sola llamada API utilizando el parámetro n. Envía una solicitud de prueba rápida y devuelve True si la función está disponible, lo que permite un muestreo «Best-of-N» real para un razonamiento más rápido y escalable.
Una vez que hayamos determinado si nuestro backend admite el muestreo multitrayectoria, el siguiente paso es generar múltiples rutas de razonamiento para un problema determinado. Esta sección presenta un conjunto de funciones auxiliares que utilizan el multimuestreo del lado del servidor (cuando está disponible) o paralelizan de manera eficiente las finalizaciones individuales, lo que garantiza que la aplicación siga siendo rápida y escalable.
def lm_studio_generate_multiple(problem, k, temperature=0.8, seed=2025):
prompt = f"<think> {problem}\n</think>"
payload = {
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 196,
"temperature": temperature,
"top_p": 0.9,
"top_k": 30,
"n": k,
"stream": False,
"seed": seed
}
start = time.time()
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
latency = time.time() - start
if resp.status_code == 200:
result = resp.json()
return [{
"content": choice["message"]["content"].strip(),
"latency": latency / k,
"success": True,
} for choice in result.get("choices", [])]
else:
raise RuntimeError(f"LM Studio error: {resp.status_code}: {resp.text}")
def lm_studio_generate_single(problem, temperature, seed=None):
prompt = f"<think> {problem}\n</think>"
payload = {
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 196,
"temperature": temperature,
"top_p": 0.9,
"top_k": 30,
"stream": False,
"seed": seed
}
start = time.time()
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
latency = time.time() - start
if resp.status_code == 200:
content = resp.json()["choices"][0]["message"]["content"].strip()
return {"content": content, "latency": latency, "success": True}
else:
return {"success": False, "error": f"HTTP {resp.status_code}: {resp.text}", "latency": latency}
def parallel_candidate_generation(problem, k, progress_cb=None):
import concurrent.futures
temperatures = np.linspace(0.1, 1.0, k)
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=min(8, k)) as executor:
futures = []
for i in range(k):
seed = 2025 + i * 31
futures.append(executor.submit(lm_studio_generate_single, problem, temperatures[i], seed))
for i, future in enumerate(concurrent.futures.as_completed(futures)):
res = future.result()
res["trajectory_id"] = i + 1
results.append(res)
if progress_cb:
progress_cb(i + 1, k)
results.sort(key=lambda x: x.get("trajectory_id", 0))
return resultsA continuación se explica cómo encaja cada función en el proceso de múltiples trayectorias:
lm_studio_generate_multiple() función: Cuando el servidor LM Studio admite el parámetro n, esta función envía una única solicitud API para generar k soluciones diversas a la vez. Este es el modo más eficiente, ya que permite una verdadera escalabilidad en tiempo de prueba.lm_studio_generate_single() función: Si el servidor no admite el muestreo múltiple, esta función proporciona una alternativa que genera una trayectoria de solución por solicitud, lo que permite diferentes temperaturas y reproducibilidad mediante semillas.parallel_candidate_generation() función: Para mantener el rendimiento en modo de reserva, esta utilidad activa varias llamadas a lm_studio_generate_single() en paralelo, cada una con diferentes temperaturas de muestreo, y luego agrega todas las respuestas. Esto garantiza que sigamos obteniendo una amplia gama de soluciones rápidamente, incluso si no se dispone de un muestreo múltiple real.Después de generar múltiples vías de razonamiento, necesitamos una forma estructurada de identificar la solución más sólida. Este paso introduce herramientas de puntuación y selección que imitan las técnicas de modelado de recompensas (SPRM) utilizadas en el artículo MetaStone Reflective Reasoning.
def step_tokenize(trajectory: str) -> List[str]:
steps = [step.strip() for step in trajectory.split('.\n\n') if step.strip()]
return steps
def dummy_sprm_score(trajectory: str, problem: str) -> float:
steps = step_tokenize(trajectory)
n = len(steps)
def step_score(step):
s = 0.2
if any(x in step.lower() for x in ["therefore", "thus", "so", "finally", "conclude"]): s += 0.15
if any(sym in step for sym in ["=", "+", "-", "*", "/", "(", ")"]): s += 0.1
if len(step.split()) > 10: s += 0.1
return min(1.0, s)
step_scores = [step_score(s) for s in steps] or [0.01]
geometric_mean = np.exp(np.mean(np.log(np.maximum(step_scores, 1e-3))))
return min(1.0, geometric_mean + 0.05 * np.log1p(n))
def best_of_n_selection(candidates: List[Dict]) -> int:
best_idx = int(np.argmax([c["sprm_score"] for c in candidates]))
return best_idxEsto es lo que hace cada función:
step_tokenize() función: Esta función divide una trayectoria de razonamiento en pasos o segmentos lógicos, lo que permite realizar un análisis y una puntuación paso a paso.dummy_sprm_score() función: Esta función asigna una puntuación de recompensa a cada trayectoria candidata y fomenta las respuestas que constan de varios pasos, están bien estructuradas y utilizan el razonamiento matemático. Actúa como sustituto del Modelo de Recompensa por Procesos Compartidos (SPRM) del periódico, que evalúa internamente sus soluciones.best_of_n_selection() function: Dado un lote de respuestas candidatas, esta función selecciona la mejor trayectoria única basándose en la puntuación SPRM más alta, al igual que el modelo reflexivo del artículo elige automáticamente la respuesta más sólida en el momento de la prueba.En este paso, reunimos todas las piezas para crear una demostración interactiva de razonamiento con Streamlit.
st.markdown("""
<div class="main-header">
<h1> MetaStone XBai-o4 Reflective Reasoning Demo</h1>
</div>
""", unsafe_allow_html=True)
st.sidebar.header("Reasoning Mode")
mode = st.sidebar.selectbox("Reasoning effort (k candidates):", list(REASONING_MODES.keys()))
k = REASONING_MODES[mode]
st.sidebar.header("Problem Input")
problem = st.sidebar.text_area("Enter your math/logic problem:", "Prove that the square root of 2 is irrational")
if st.sidebar.button("Run Reflective Reasoning"):
st.session_state.run = True
st.session_state.results = None
st.session_state.best_idx = None
if "run" not in st.session_state:
st.session_state.run = False
if st.session_state.run:
st.info(f"Generating {k} reasoning trajectories in parallel...")
progress = st.progress(0)
def update_progress(done, total):
progress.progress(done / total)
try:
if supports_n_param():
results = lm_studio_generate_multiple(problem, k, temperature=0.7)
for idx, res in enumerate(results):
res["trajectory_id"] = idx + 1
else:
results = parallel_candidate_generation(problem, k, progress_cb=update_progress)
for res in results:
if res.get("success"):
res["sprm_score"] = dummy_sprm_score(res["content"], problem)
else:
res["sprm_score"] = 0.0
best_idx = best_of_n_selection(results)
st.session_state.results = results
st.session_state.best_idx = best_idx
st.session_state.run = False
except Exception as e:
st.error(f"Failed to generate trajectories: {str(e)}")
st.session_state.run = False
if st.session_state.get("results"):
results = st.session_state.results
best_idx = st.session_state.best_idx
st.success(f"Selected trajectory #{best_idx+1} (highest SPRM score)")
df = pd.DataFrame({
"Trajectory": [f"T{i+1}" for i in range(len(results))],
"SPRM Score": [r["sprm_score"] for r in results],
"Latency (s)": [r.get("latency", 0.0) for r in results],
"Success": [r.get("success", False) for r in results]
})
for i, res in enumerate(results):
is_best = (i == best_idx)
st.markdown(f"### {'' if is_best else ''} Trajectory {i+1} {'(SELECTED)' if is_best else ''}")
if res.get("success"):
st.info(f"SPRM Score: {res['sprm_score']:.3f} | Latency: {res['latency']:.1f}s")
st.code(res["content"])
else:
st.error(f"Failed: {res.get('error', 'Unknown error')}")
fig = px.bar(df, x="Trajectory", y="SPRM Score", color="Success", title="SPRM Scores for Each Trajectory")
st.plotly_chart(fig, use_container_width=True)
st.dataframe(df)El flujo principal de la aplicación cumple varios objetivos clave:
dummy_sprm_score), que imita el modelo de recompensa por proceso compartido (SPRM). best_of_n_selection). Todas las soluciones generadas, junto con sus respectivas puntuaciones SPRM y latencias de generación, se presentan en formato textual y gráfico para poder analizarlas en paralelo.Para probarlo tú mismo, guarda el código como xbai_demo.py y ejecútalo:
streamlit run xbai_demo.py¡Aprende IA con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita
Tutorial
Moez Ali



