
Kurs
Building Agentic Workflows with LlamaIndex
2 Std.
1.2K
MetaStone AI hat kürzlich XBai-o4veröffentlicht , ein Open-Source-Modell für logisches Denken, das parallele Skalierung während der Testphase und eine reflektierende generative Architektur einführt. Mit 32,8 Milliarden Parametern und einem eingebauten Selbstbewertungskopf ist XBai o4 beim lokalen Betrieb in allen wichtigen mathematischen Denkaufgaben besser als OpenAI's o3-mini (mittlerer Modus).
In diesem Blog werde ich mich auf die einzigartigen Fähigkeiten von XBai o4 zum reflektierenden Denken konzentrieren und zeigen, wie es über eine lokal bereitgestellte Streamlit-Schnittstelle, die von LM Studio unterstützt wird, mehrere Lösungswege für mathematische Probleme generiert und bewertet.
In diesem Tutorial zeige ich dir Schritt für Schritt, wie du:
Am Ende sieht deine App so aus:
XBai-o4 ist das vierte Open-Source-Modell von MetaStone AI zum logischen Denken. Es hat eine reflektierende generative Architektur, die versucht, die Herangehensweise von KI an komplexe Probleme neu zu definieren. Im Gegensatz zu herkömmlichen LLMs, die die Generierung und Bewertung von Antworten als zwei separate Prozesse behandeln, kombiniert XBai o4 beide in einem einheitlichen Modell mithilfe eines Shared Process Reward Model (SPRM). Mit diesem Design kann das Modell mehrere Argumentationspfade gleichzeitig erstellen, bewerten und auswählen.
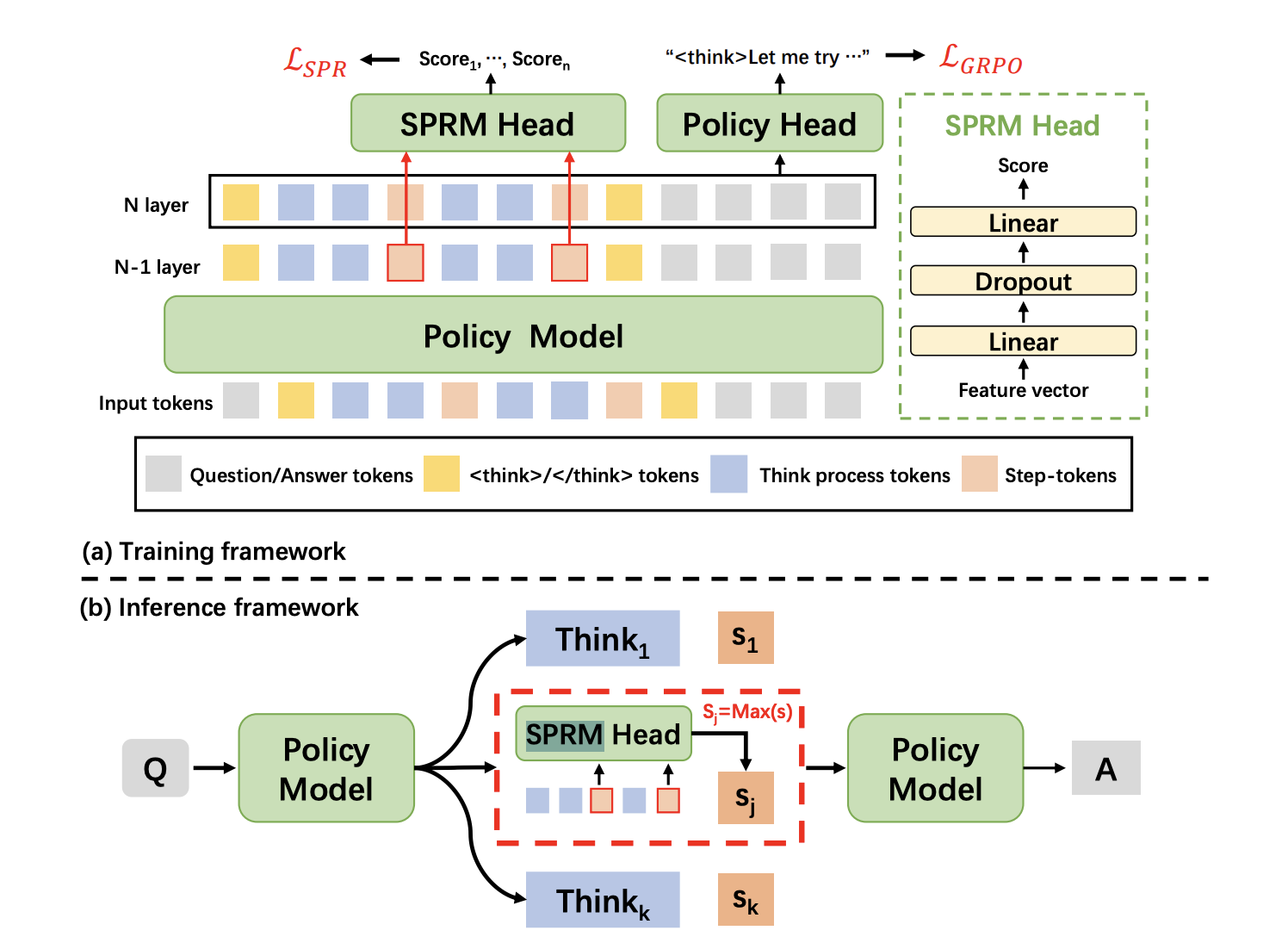
Quelle: SPRM Head
Im Grunde genommen kombiniert XBai o4 das Long-CoT-Verstärkungslernen (Long-CoT) und das Prozessbelohnungslern , zu einer einzigen Trainingspipeline. Hier sind ein paar wichtige Neuerungen, die in diesem Modell eingeführt wurden:
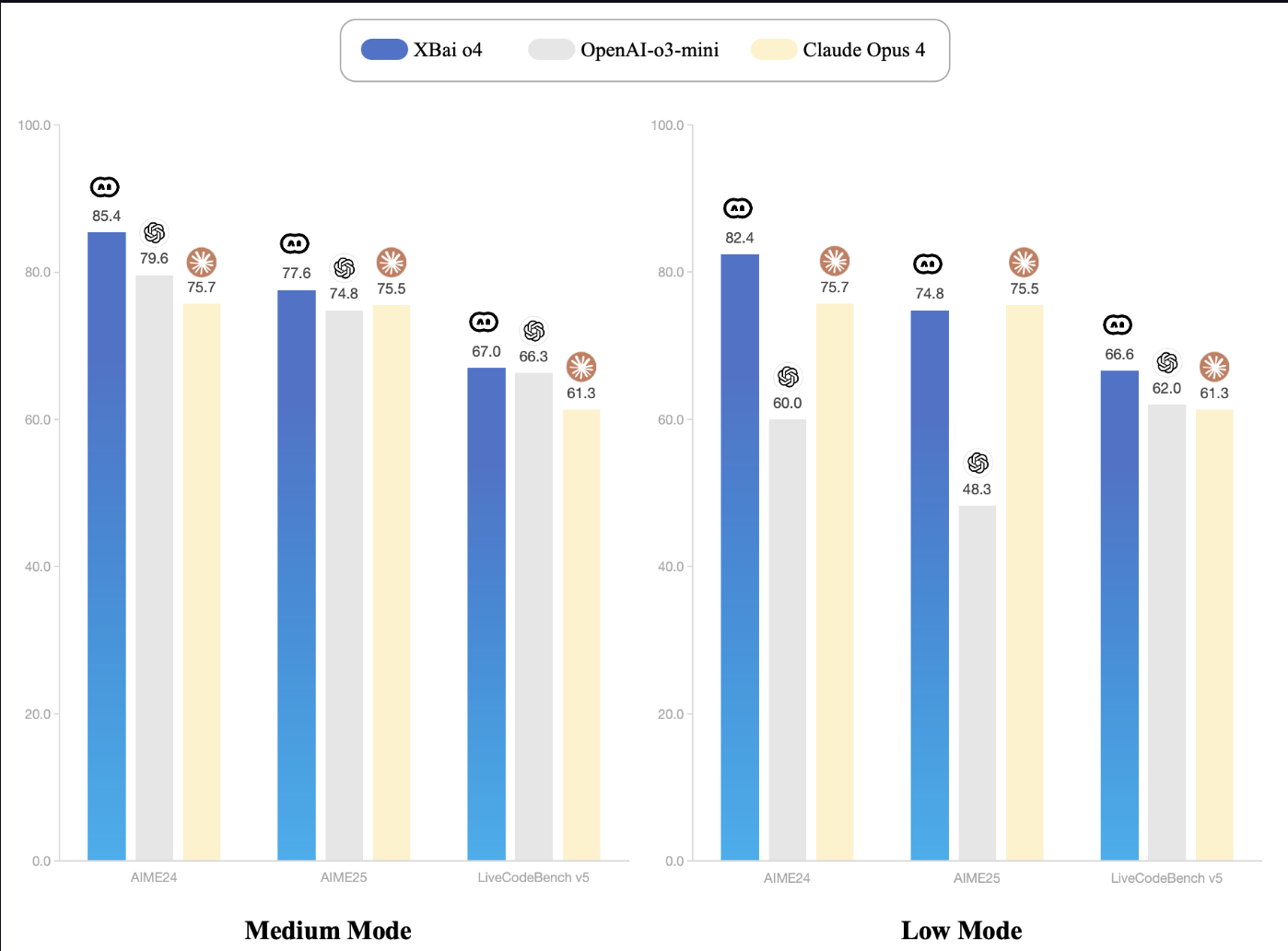
Quelle: XBai-O4 Dokumentation
Du kannst XBai o4 lokal mit LM Studio ausführen, das automatisch die GPU deines Systems oder die Apple Silicon (Metal/MLX)-Beschleunigung nutzt, wenn verfügbar (keine manuelle Einrichtung nötig). Für beste Leistung und Kompatibilität empfehle ich die quantisierte Version des Modells von GGUF.
Der GGUF-Standard (GPT-Generated Unified Format) macht lokale Inferenz super effizient, indem er die Genauigkeit der Modellgewichte reduziert. In diesem Projekt verwenden wir die quantisierte Variante „ Q3_K_S “, die wegen ihrer guten Balance zwischen Qualität und Speicherverbrauch oft gewählt wird.
Q3_K_S “ eine starke Schlussfolgerungsleistung bei minimalem Qualitätsverlust im Vergleich zu Modellen mit voller Genauigkeit.Schauen wir uns mal Schritt für Schritt an, wie man das quantisierte GGUF-Modell für effiziente lokale Inferenz mit LM Studio einrichtet.
LM Studio bietet GGUF-Unterstützung und wählt automatisch das beste Inferenz-Backend für deine Hardware aus, egal ob Metal, GPU oder CPU.
Wenn du LM Studio noch nicht installiert hast, kannst du es einfach von lmstudio.ai runterladen und den Installationsanweisungen folgen.
In LM Studio:
mradermacher/XBai-o4-GGUFXBai-o4.Q3_K_S.gguf “ runter (14,39 GB).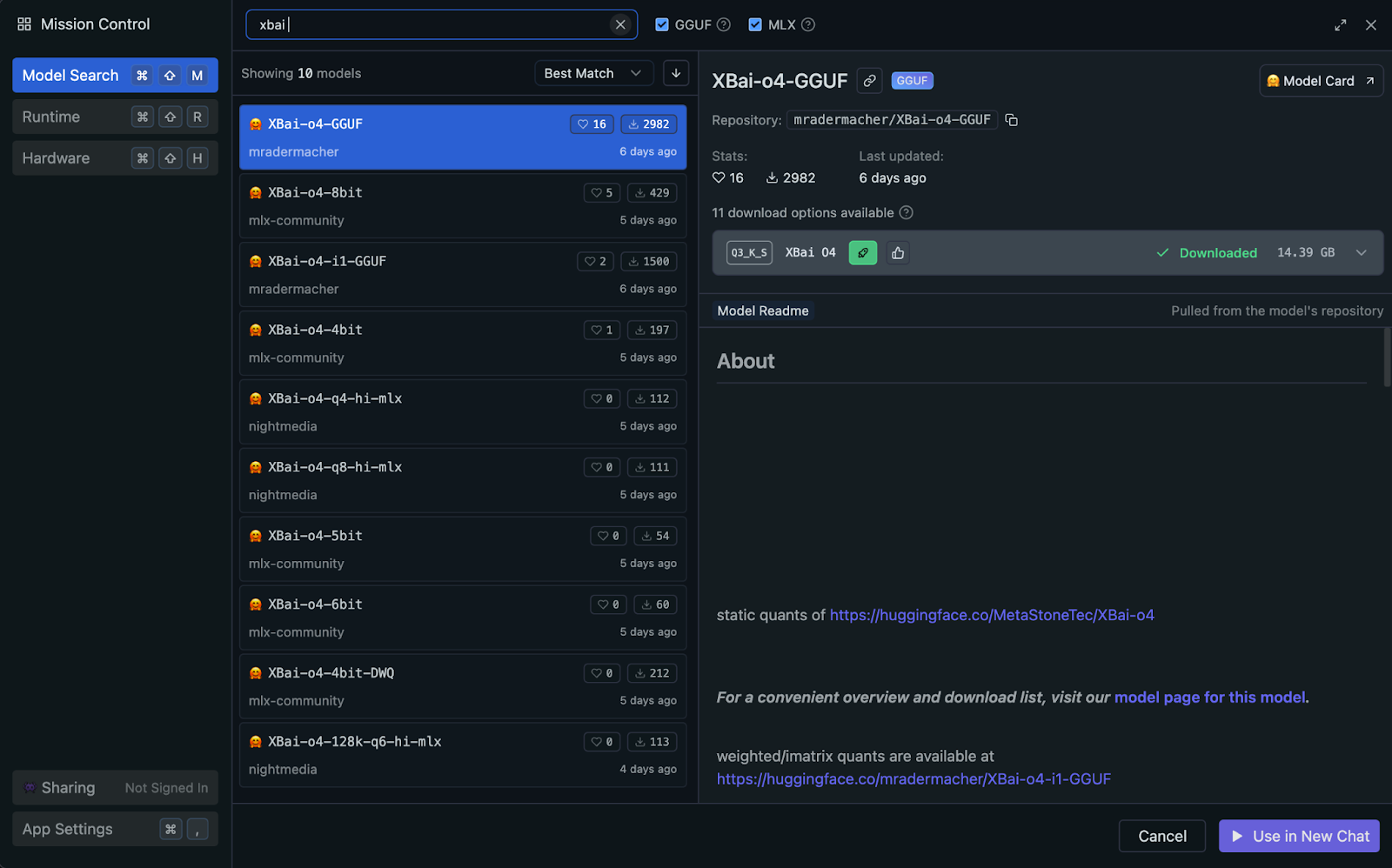
Sobald LM Studio installiert ist, laden wir das XBai o4-Modell für die lokale Inferenz und richten es ein:
XBai-o4.Q3_K_S.gguf “ aus deiner Liste der heruntergeladenen Modelle und lade es.Sobald das System läuft, kannst du mit XBai o4 mehrere Trajektorien gleichzeitig berechnen.
Jetzt bauen wir eine Streamlit-App, die die reflektierenden Fähigkeiten von XBai o4 mit einem Echtzeit-Leistungsvergleich zeigt.
Zuerst musst du die Abhängigkeiten installieren:
pip install streamlit plotly pandas numpy requestsDieser Befehl stellt sicher, dass du alle wichtigen Abhängigkeiten für die Benutzeroberfläche, die Datenverarbeitung, die Darstellung und API-Anfragen hast.
Als Nächstes importierst du alle benötigten Bibliotheken und richtest das Layout und die Grundeinstellungen deiner Streamlit-Seite ein.
import streamlit as st
import time
import requests
import numpy as np
import pandas as pd
import plotly.express as px
from typing import List, Dict, Any
LM_STUDIO_URL = "http://localhost:1234/v1" # change as per your server
REASONING_MODES = {"Low (k=2)": 2, "Medium (k=8)": 8, "High (k=32)": 8}
st.set_page_config(page_title="MetaStone-XBai-o4 Reflective Reasoning Demo", layout="wide")
st.markdown("""
<style>
.main-header {
background: linear-gradient(90deg, #1e3c72 0%, #2a5298 100%);
border-radius: 10px;
color: white;
text-align: center;
}
</style>
""", unsafe_allow_html=True)Dieser Code-Block holt alle wichtigen Bibliotheken rein, die wir für unsere Demo brauchen, wie Streamlit für die Web-Benutzeroberfläche und andere grundlegende Bibliotheken wie time, requests, numpy, pandas, plotly.express und typing tools.
Dann wird der Modell-API-Endpunkt LM_STUDIO_URL gesetzt, damit die App weiß, wohin sie Anfragen schicken soll, und es werden Argumentationsmodi (REASONING_MODES) definiert, damit die Nutzer ganz einfach auswählen können, wie viele Lösungszweige generiert werden sollen.
Zum Schluss nehmen wir „ st.set_page_config() “, um die Streamlit-Benutzeroberfläche mit einem eigenen Titel, einem breiten Layout und einer CSS-gestylten Kopfzeile mit Farbverlauf einzurichten.
Hinweis: Die „ LM_STUDIO_URL “ ist die Basis-URL des LLM-Servers, die du aus LM Studio kopieren kannst. Normalerweise heißt es „http://localhost:1234/v1"”, aber das kann variieren. Wähl auch die Argumentationsmodi entsprechend der Leistung deines Servers aus.
Jetzt erstellen wir ein paar Hilfsfunktionen, die die Kernlogik des „reflektierenden Denkens” unserer App unterstützen. Mit diesen Funktionen kannst du ganz einfach mit mehreren Trajektorien arbeiten, die beste Lösung auswählen und jede Antwort bewerten.
In diesem Schritt stellen wir eine einfache Hilfsfunktion vor, die automatisch checkt, ob unser LM Studio-Server Multi-Trajectory-Sampling kann. Einige Server unterstützen das „ n parameter “, mit dem wir mehrere unabhängige Vervollständigungen in einem API-Aufruf anfordern können, was den Prozess deutlich beschleunigt.
def supports_n_param():
payload = {
"messages": [{"role": "user", "content": "What is 1+1?"}],
"max_tokens": 80,
"temperature": 0.1,
"n": 2,
"stream": False
}
try:
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
if resp.status_code == 200 and len(resp.json().get("choices", [])) == 2:
return True
except Exception:
pass
return FalseDiese Funktion checkt, ob dein LM Studio-Server die Generierung mehrerer Antworten („Trajektorien“) in einem einzigen API-Aufruf mit dem Parameter n unterstützt. Es sendet eine schnelle Testanfrage und gibt „True“ zurück, wenn die Funktion verfügbar ist. So wird echtes „Best-of-N“-Sampling für schnellere und besser skalierbare Schlussfolgerungen möglich.
Sobald wir wissen, ob unser Backend Multi-Trajectory-Sampling unterstützt, müssen wir mehrere Argumentationspfade für ein bestimmtes Problem erstellen. In diesem Abschnitt werden ein paar Hilfsfunktionen vorgestellt, die entweder serverseitiges Multi-Sampling nutzen (wenn verfügbar) oder einzelne Abschlüsse effizient parallelisieren, damit die App schnell und skalierbar bleibt.
def lm_studio_generate_multiple(problem, k, temperature=0.8, seed=2025):
prompt = f"<think> {problem}\n</think>"
payload = {
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 196,
"temperature": temperature,
"top_p": 0.9,
"top_k": 30,
"n": k,
"stream": False,
"seed": seed
}
start = time.time()
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
latency = time.time() - start
if resp.status_code == 200:
result = resp.json()
return [{
"content": choice["message"]["content"].strip(),
"latency": latency / k,
"success": True,
} for choice in result.get("choices", [])]
else:
raise RuntimeError(f"LM Studio error: {resp.status_code}: {resp.text}")
def lm_studio_generate_single(problem, temperature, seed=None):
prompt = f"<think> {problem}\n</think>"
payload = {
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 196,
"temperature": temperature,
"top_p": 0.9,
"top_k": 30,
"stream": False,
"seed": seed
}
start = time.time()
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
latency = time.time() - start
if resp.status_code == 200:
content = resp.json()["choices"][0]["message"]["content"].strip()
return {"content": content, "latency": latency, "success": True}
else:
return {"success": False, "error": f"HTTP {resp.status_code}: {resp.text}", "latency": latency}
def parallel_candidate_generation(problem, k, progress_cb=None):
import concurrent.futures
temperatures = np.linspace(0.1, 1.0, k)
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=min(8, k)) as executor:
futures = []
for i in range(k):
seed = 2025 + i * 31
futures.append(executor.submit(lm_studio_generate_single, problem, temperatures[i], seed))
for i, future in enumerate(concurrent.futures.as_completed(futures)):
res = future.result()
res["trajectory_id"] = i + 1
results.append(res)
if progress_cb:
progress_cb(i + 1, k)
results.sort(key=lambda x: x.get("trajectory_id", 0))
return resultsSo passt jede Funktion in die Multi-Trajectory-Pipeline:
lm_studio_generate_multiple() Funktion: Wenn der LM Studio-Server den Parameter n unterstützt, sendet diese Funktion eine einzige API-Anfrage, um k verschiedene Lösungen auf einmal zu generieren. Das ist der effizienteste Modus, der eine echte Skalierung der Testzeit ermöglicht.lm_studio_generate_single() Funktion: Wenn der Server Multi-Sampling nicht unterstützt, gibt's eine Ausweichfunktion, die pro Anfrage eine Lösungstrajektorie generiert, wobei verschiedene Temperaturen und Reproduzierbarkeit über Seeds möglich sind.parallel_candidate_generation() Funktion: Um die Leistung im Fallback-Modus aufrechtzuerhalten, startet dieses Dienstprogramm mehrere „ lm_studio_generate_single() “-Aufrufe gleichzeitig, jeder mit unterschiedlichen Abtasttemperaturen, und fasst dann alle Antworten zusammen. So stellen wir sicher, dass wir auch dann schnell eine breite Palette an Lösungen bekommen, wenn echtes Multi-Sampling nicht verfügbar ist.Nachdem wir mehrere Argumentationspfade erstellt haben, brauchen wir eine strukturierte Methode, um die beste Lösung zu finden. In diesem Schritt werden Bewertungs- und Auswahltools vorgestellt, die die im MetaStone Reflective Reasoning-Papier verwendeten Techniken der Belohnungsmodellierung (SPRM) nachahmen.
def step_tokenize(trajectory: str) -> List[str]:
steps = [step.strip() for step in trajectory.split('.\n\n') if step.strip()]
return steps
def dummy_sprm_score(trajectory: str, problem: str) -> float:
steps = step_tokenize(trajectory)
n = len(steps)
def step_score(step):
s = 0.2
if any(x in step.lower() for x in ["therefore", "thus", "so", "finally", "conclude"]): s += 0.15
if any(sym in step for sym in ["=", "+", "-", "*", "/", "(", ")"]): s += 0.1
if len(step.split()) > 10: s += 0.1
return min(1.0, s)
step_scores = [step_score(s) for s in steps] or [0.01]
geometric_mean = np.exp(np.mean(np.log(np.maximum(step_scores, 1e-3))))
return min(1.0, geometric_mean + 0.05 * np.log1p(n))
def best_of_n_selection(candidates: List[Dict]) -> int:
best_idx = int(np.argmax([c["sprm_score"] for c in candidates]))
return best_idxHier ist, was jede Funktion macht:
step_tokenize() Funktion: Diese Funktion teilt einen Denkprozess in logische Schritte oder Abschnitte auf, sodass man ihn Schritt für Schritt analysieren und bewerten kann.dummy_sprm_score() Funktion: Diese Funktion gibt jeder Kandidatenbahn eine Belohnungspunktezahl und fördert Antworten, die mehrere Schritte umfassen, gut strukturiert sind und mathematische Überlegungen enthalten. Es ersetzt das Shared Process Reward Model (SPRM) der Zeitung, das ihre Lösungen intern bewertet.best_of_n_selection() function: Aus einer Reihe von Antwortkandidaten wählt diese Funktion die beste Antwort aus, basierend auf dem höchsten SPRM-Wert, genau wie das reflektierende Modell in der Veröffentlichung automatisch die robusteste Antwort zum Testzeitpunkt auswählt.In diesem Schritt setzen wir alles zusammen, um mit Streamlit eine interaktive Demo zum logischen Denken zu erstellen.
st.markdown("""
<div class="main-header">
<h1> MetaStone XBai-o4 Reflective Reasoning Demo</h1>
</div>
""", unsafe_allow_html=True)
st.sidebar.header("Reasoning Mode")
mode = st.sidebar.selectbox("Reasoning effort (k candidates):", list(REASONING_MODES.keys()))
k = REASONING_MODES[mode]
st.sidebar.header("Problem Input")
problem = st.sidebar.text_area("Enter your math/logic problem:", "Prove that the square root of 2 is irrational")
if st.sidebar.button("Run Reflective Reasoning"):
st.session_state.run = True
st.session_state.results = None
st.session_state.best_idx = None
if "run" not in st.session_state:
st.session_state.run = False
if st.session_state.run:
st.info(f"Generating {k} reasoning trajectories in parallel...")
progress = st.progress(0)
def update_progress(done, total):
progress.progress(done / total)
try:
if supports_n_param():
results = lm_studio_generate_multiple(problem, k, temperature=0.7)
for idx, res in enumerate(results):
res["trajectory_id"] = idx + 1
else:
results = parallel_candidate_generation(problem, k, progress_cb=update_progress)
for res in results:
if res.get("success"):
res["sprm_score"] = dummy_sprm_score(res["content"], problem)
else:
res["sprm_score"] = 0.0
best_idx = best_of_n_selection(results)
st.session_state.results = results
st.session_state.best_idx = best_idx
st.session_state.run = False
except Exception as e:
st.error(f"Failed to generate trajectories: {str(e)}")
st.session_state.run = False
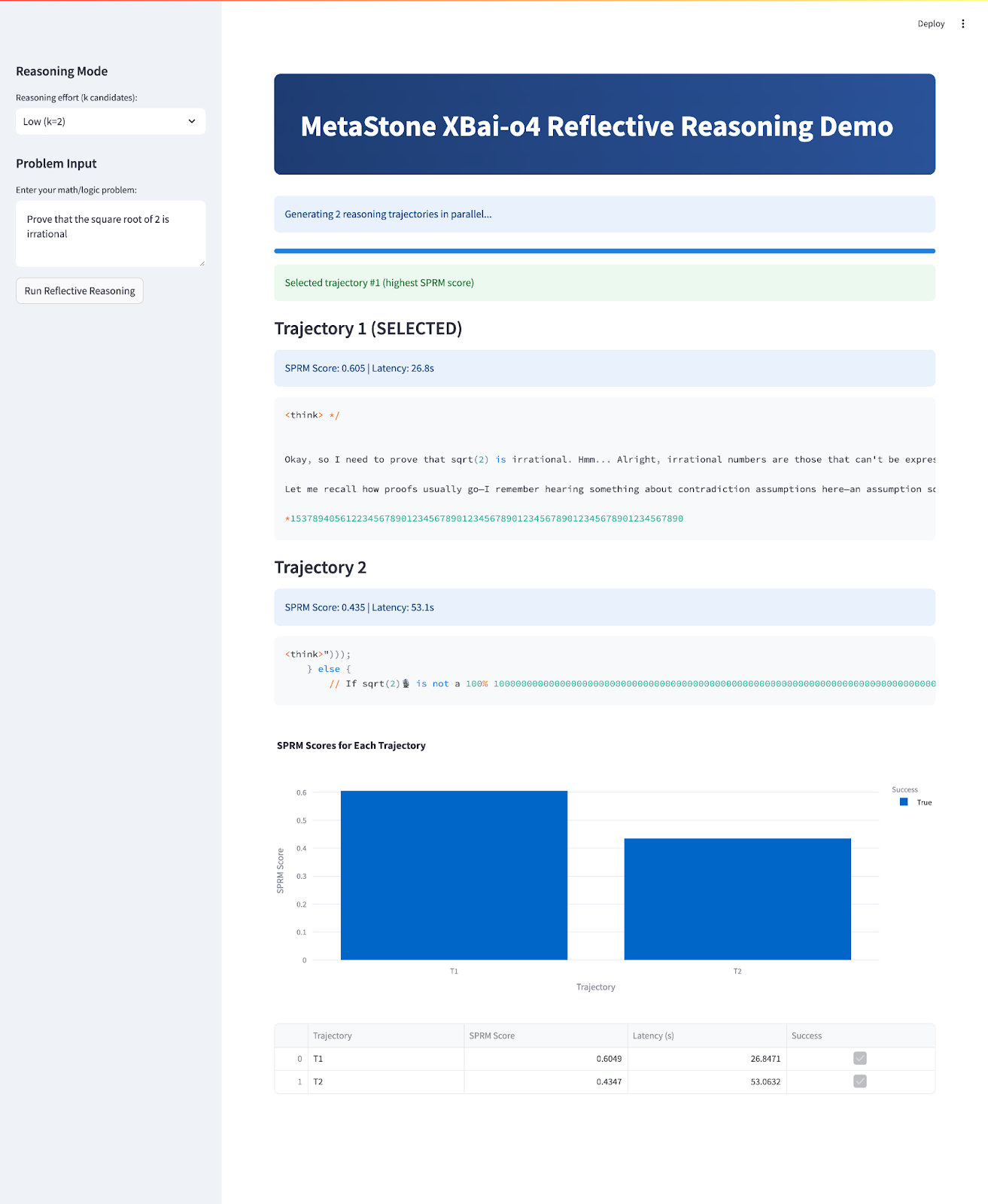
if st.session_state.get("results"):
results = st.session_state.results
best_idx = st.session_state.best_idx
st.success(f"Selected trajectory #{best_idx+1} (highest SPRM score)")
df = pd.DataFrame({
"Trajectory": [f"T{i+1}" for i in range(len(results))],
"SPRM Score": [r["sprm_score"] for r in results],
"Latency (s)": [r.get("latency", 0.0) for r in results],
"Success": [r.get("success", False) for r in results]
})
for i, res in enumerate(results):
is_best = (i == best_idx)
st.markdown(f"### {'' if is_best else ''} Trajectory {i+1} {'(SELECTED)' if is_best else ''}")
if res.get("success"):
st.info(f"SPRM Score: {res['sprm_score']:.3f} | Latency: {res['latency']:.1f}s")
st.code(res["content"])
else:
st.error(f"Failed: {res.get('error', 'Unknown error')}")
fig = px.bar(df, x="Trajectory", y="SPRM Score", color="Success", title="SPRM Scores for Each Trajectory")
st.plotly_chart(fig, use_container_width=True)
st.dataframe(df)Der Hauptanwendungsablauf erfüllt mehrere wichtige Ziele:
dummy_sprm_score) bewertet, das das Shared Process Reward Model (SPRM) nachahmt. best_of_n_selection). Alle gefundenen Lösungen, zusammen mit ihren SPRM-Werten und der Zeit, die sie gebraucht haben, um gefunden zu werden, werden in Text und als Grafik angezeigt, damit man sie direkt vergleichen kann.Um es selbst auszuprobieren, speicher den Code als „ xbai_demo.py “ und starte:
streamlit run xbai_demo.pyLerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal