
Cours
Building Agentic Workflows with LlamaIndex
2 h
1.2K
MetaStone AI a récemment publié XBai-o4, un modèle de raisonnement open source qui introduit la mise à l'échelle parallèle au moment du test et une architecture générative réflexive. Avec 32,8 milliards de paramètres et une tête d'auto-évaluation intégrée, XBai o4 surpasse o3-mini (mode moyen) d'OpenAI dans tous les tests de raisonnement mathématique de base lorsqu'il est exécuté localement.
Dans cet article, je me concentrerai sur les capacités uniques de raisonnement réflexif de XBai o4, en démontrant comment il génère et évalue plusieurs trajectoires de solutions pour des problèmes mathématiques via une interface Streamlit déployée localement et optimisée par LM Studio.
Dans ce tutoriel, je vais vous expliquer étape par étape comment :
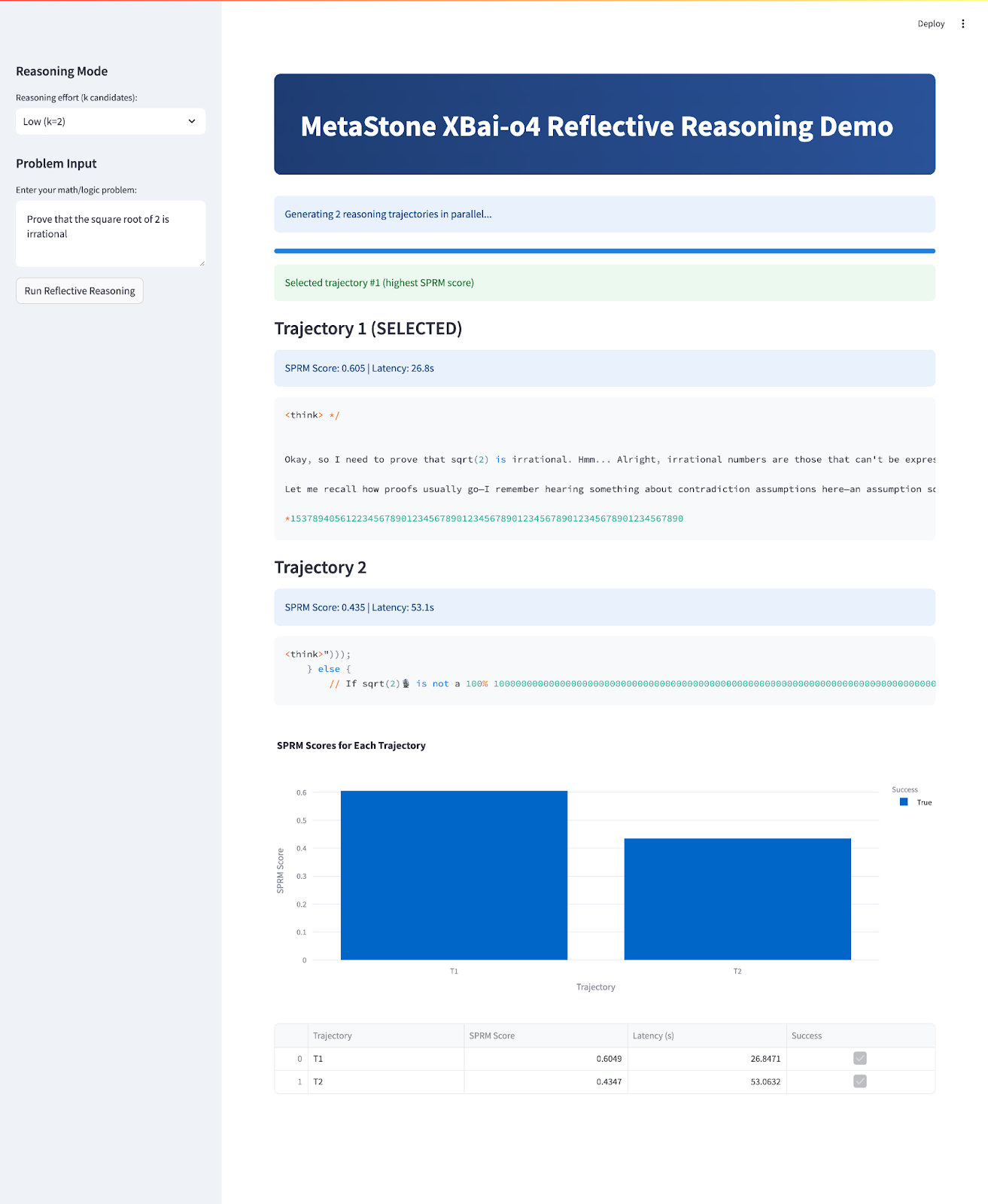
À la fin, votre application ressemblera à ceci :
XBai-o4 est le modèle de raisonnement open source de quatrième génération de MetaStone AI. Il introduit une architecture générative réflexive qui vise à redéfinir la manière dont l'IA aborde la résolution de problèmes complexes. Contrairement aux LLM traditionnels qui traitent la génération et l'évaluation des réponses comme deux processus distincts, XBai o4 fusionne les deux dans un modèle unifié à l'aide d'un modèle de récompense de processus partagé (SPRM). Cette conception permet au modèle de générer, noter et sélectionner plusieurs chemins de raisonnement en parallèle.
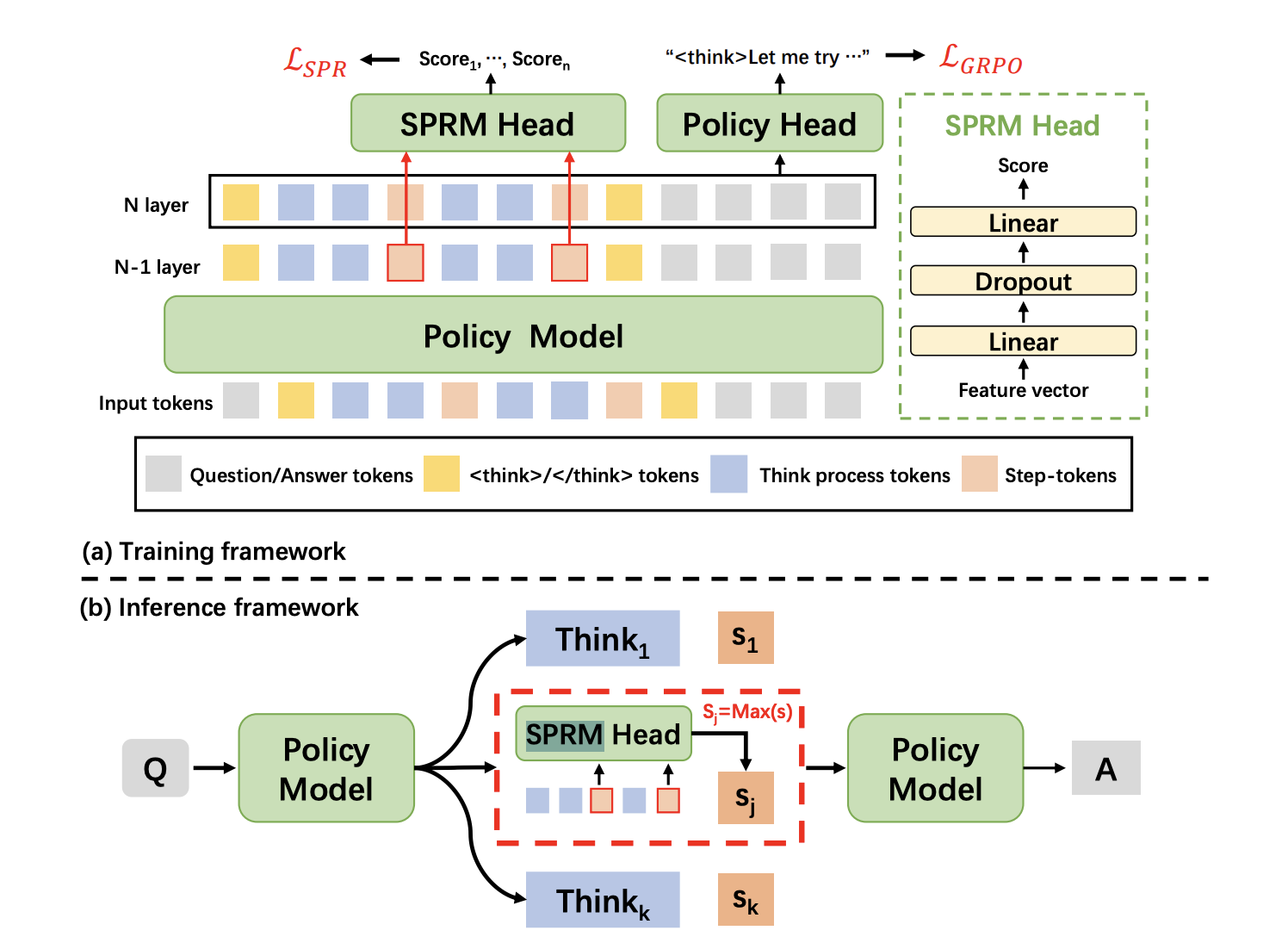
Source : Directeur du SPRM
À la base, XBai o4 combine l'apprentissage par renforcement à longue chaîne de pensée (Long-CoT) et l' ed'apprentissage par récompense de processus en un seul pipeline de formation. Voici quelques innovations clés introduites dans ce modèle :
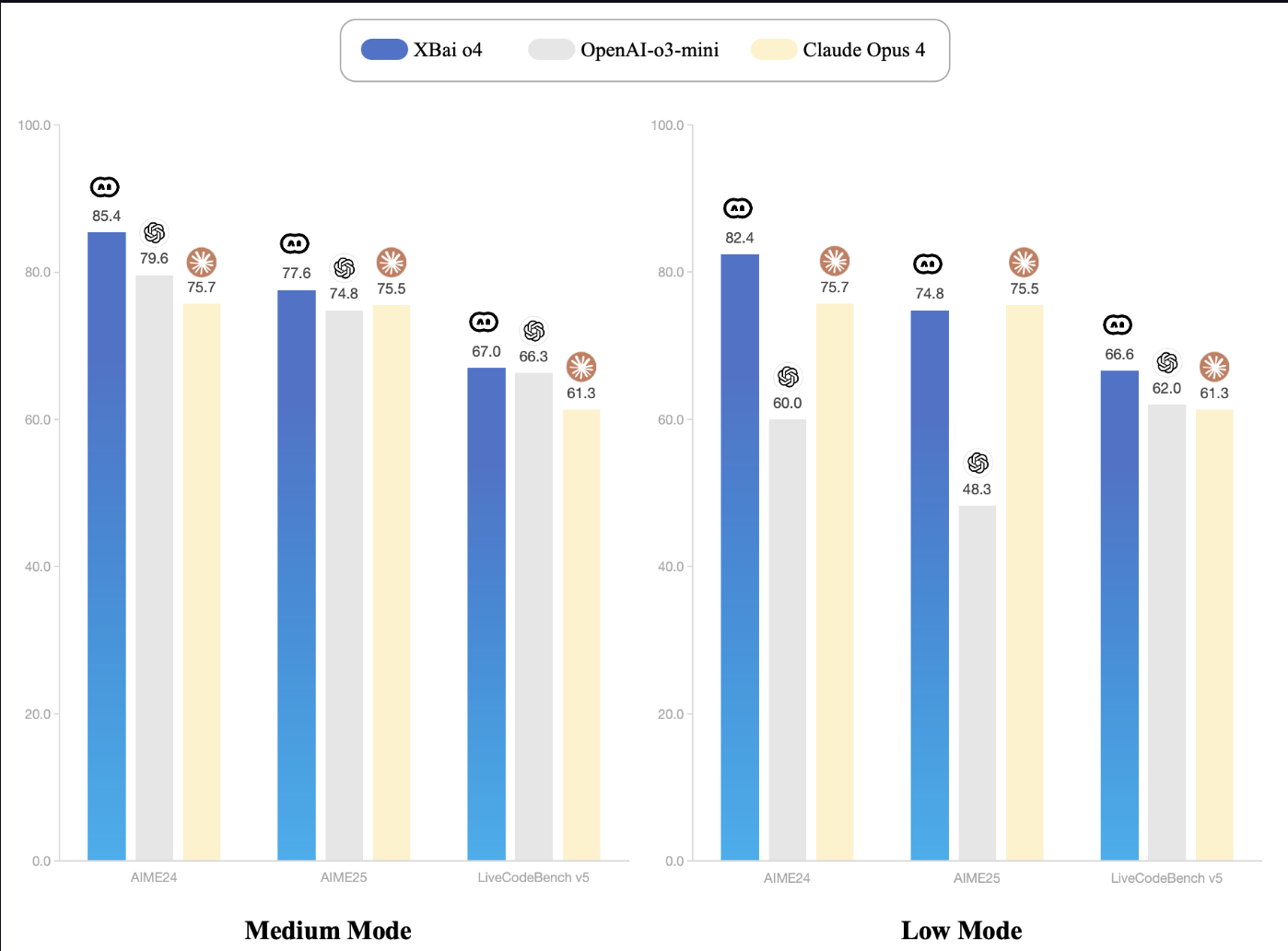
Source : Documentation XBai-O4
Vous pouvez exécuter XBai o4 localement à l'aide de LM Studio, qui utilise automatiquement l'accélération GPU ou Apple Silicon (Metal/MLX) de votre système lorsqu'elle est disponible (aucune configuration manuelle n'est requise). Pour des performances et une compatibilité optimales, je recommande d'utiliser la version quantifiée GGUF du modèle.
La norme GGUF (GPT-Generated Unified Format) permet une inférence locale très efficace en réduisant la précision des poids des modèles. Dans ce projet, nous utiliserons la variante quantifiée d'Q3_K_S, qui est un choix populaire pour son excellent compromis entre qualité et utilisation de la mémoire.
Q3_K_S offre de solides performances de raisonnement avec une perte de qualité minimale par rapport aux modèles à précision totale.Nous allons maintenant parcourir étape par étape le processus de configuration du modèle GGUF quantifié pour une inférence locale efficace à l'aide de LM Studio.
LM Studio prend en charge GGUF et sélectionne automatiquement le backend d'inférence optimal pour votre matériel, qu'il s'agisse de Metal, d'un GPU ou d'un CPU.
Si vous n'avez pas encore installé LM Studio, veuillez le télécharger depuis lmstudio.ai et suivre les instructions d'installation.
Dans LM Studio :
mradermacher/XBai-o4-GGUFXBai-o4.Q3_K_S.gguf. (14,39 Go).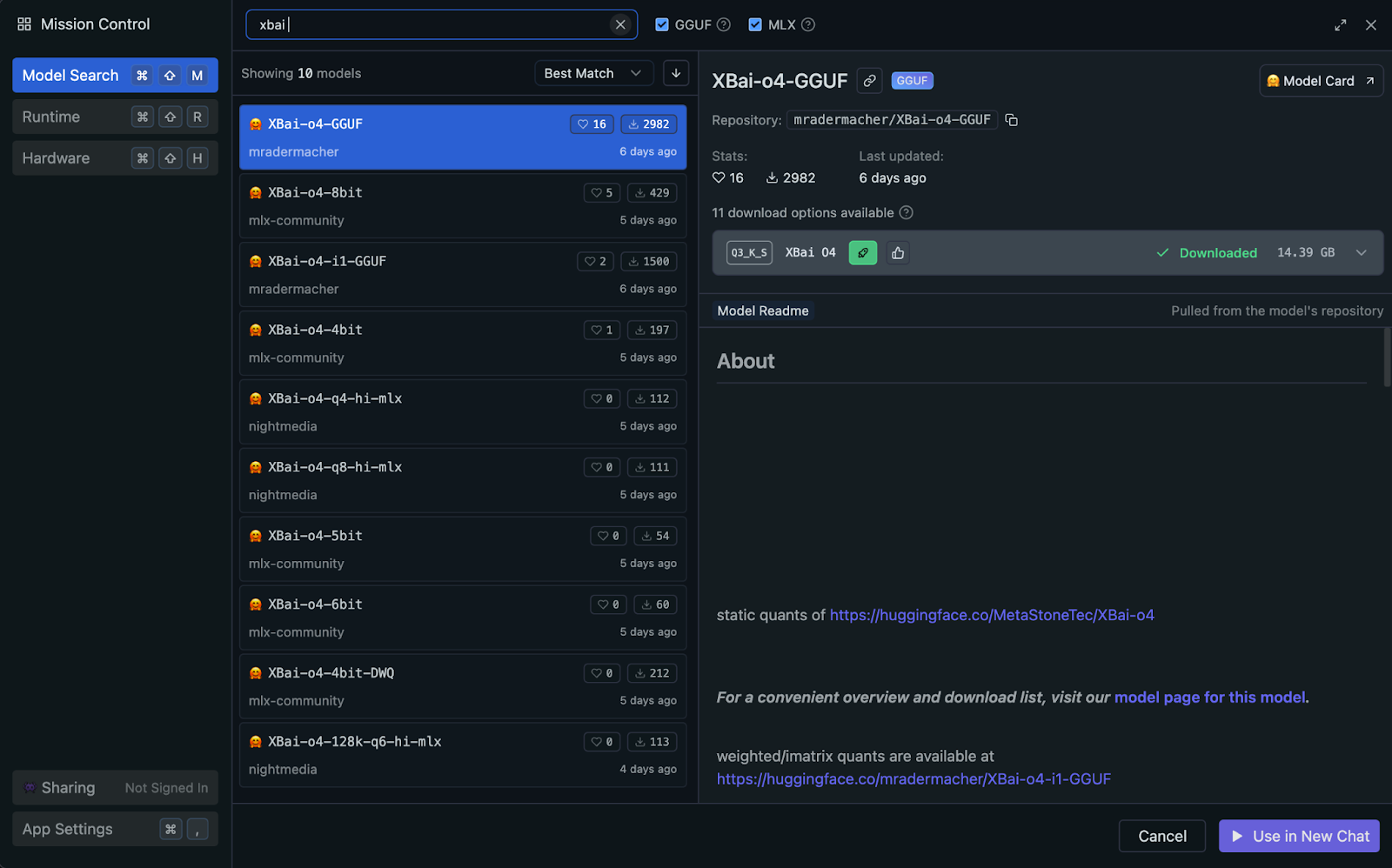
Une fois LM Studio installé, nous chargeons et configurons le modèle XBai o4 pour l'inférence locale :
XBai-o4.Q3_K_S.gguf » à partir de la liste des modèles téléchargés.Une fois lancé, votre système est prêt pour le raisonnement multi-trajectoire avec XBai o4.
Nous allons maintenant créer une application Streamlit qui démontre les capacités de raisonnement réflexif de XBai o4 avec une comparaison des performances en temps réel.
Commencez par installer les dépendances :
pip install streamlit plotly pandas numpy requestsCette commande garantit que vous disposez de toutes les dépendances essentielles pour l'interface utilisateur, le traitement des données, les graphiques et les requêtes API.
Ensuite, importez toutes les bibliothèques requises et configurez la mise en page et les paramètres de base de votre page Streamlit.
import streamlit as st
import time
import requests
import numpy as np
import pandas as pd
import plotly.express as px
from typing import List, Dict, Any
LM_STUDIO_URL = "http://localhost:1234/v1" # change as per your server
REASONING_MODES = {"Low (k=2)": 2, "Medium (k=8)": 8, "High (k=32)": 8}
st.set_page_config(page_title="MetaStone-XBai-o4 Reflective Reasoning Demo", layout="wide")
st.markdown("""
<style>
.main-header {
background: linear-gradient(90deg, #1e3c72 0%, #2a5298 100%);
border-radius: 10px;
color: white;
text-align: center;
}
</style>
""", unsafe_allow_html=True)Ce bloc de code importe toutes les bibliothèques principales requises pour notre démonstration, y compris Streamlit pour l'interface utilisateur Web, ainsi que d'autres bibliothèques de base telles que time, requests, numpy, pandas, plotly.express et typing tools.
Il définit ensuite le point de terminaison de l'API du modèle LM_STUDIO_URL afin que l'application sache où envoyer les requêtes, et définit les modes de raisonnement (REASONING_MODES) afin que les utilisateurs puissent facilement sélectionner le nombre de branches de solution à générer.
Enfin, nous utilisons st.set_page_config() pour configurer l'interface utilisateur Streamlit avec un titre personnalisé, une mise en page large et un en-tête dégradé de style CSS.
Remarque : LM_STUDIO_URL est l'URL de base du serveur LLM, que vous pouvez copier depuis LM Studio. Il s'agit généralement de « http://localhost:1234/v1" », mais cela peut varier. De plus, veuillez sélectionner les modes de raisonnement en fonction des capacités de votre serveur.
Maintenant, créons un ensemble de fonctions d'aide qui alimentent la logique centrale de « raisonnement réflexif » de notre application. Ces fonctions facilitent le travail avec plusieurs trajectoires, la sélection de la meilleure solution et la notation de chaque réponse.
Cette étape présente une fonction d'aide simple qui vérifie automatiquement si notre serveur LM Studio est capable de gérer l'échantillonnage multi-trajectoire. Certains serveurs prennent en charge l'n parameter, qui nous permet de demander plusieurs complétions indépendantes en un seul appel API, ce qui accélère considérablement le processus.
def supports_n_param():
payload = {
"messages": [{"role": "user", "content": "What is 1+1?"}],
"max_tokens": 80,
"temperature": 0.1,
"n": 2,
"stream": False
}
try:
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
if resp.status_code == 200 and len(resp.json().get("choices", [])) == 2:
return True
except Exception:
pass
return FalseCette fonction vérifie si votre serveur LM Studio prend en charge la génération de plusieurs réponses (« trajectoires ») dans un seul appel API à l'aide du paramètre n. Il envoie une requête de test rapide et renvoie « True » si la fonctionnalité est disponible, permettant ainsi un véritable échantillonnage « Best-of-N » pour un raisonnement plus rapide et plus évolutif.
Une fois que nous avons déterminé si notre backend prend en charge l'échantillonnage multi-trajectoire, l'étape suivante consiste à générer plusieurs chemins de raisonnement pour un problème donné. Cette section présente un ensemble de fonctions d'aide qui utilisent soit le multi-échantillonnage côté serveur (lorsqu'il est disponible), soit parallélisent efficacement les achèvements uniques, garantissant ainsi la rapidité et l'évolutivité de l'application.
def lm_studio_generate_multiple(problem, k, temperature=0.8, seed=2025):
prompt = f"<think> {problem}\n</think>"
payload = {
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 196,
"temperature": temperature,
"top_p": 0.9,
"top_k": 30,
"n": k,
"stream": False,
"seed": seed
}
start = time.time()
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
latency = time.time() - start
if resp.status_code == 200:
result = resp.json()
return [{
"content": choice["message"]["content"].strip(),
"latency": latency / k,
"success": True,
} for choice in result.get("choices", [])]
else:
raise RuntimeError(f"LM Studio error: {resp.status_code}: {resp.text}")
def lm_studio_generate_single(problem, temperature, seed=None):
prompt = f"<think> {problem}\n</think>"
payload = {
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 196,
"temperature": temperature,
"top_p": 0.9,
"top_k": 30,
"stream": False,
"seed": seed
}
start = time.time()
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
latency = time.time() - start
if resp.status_code == 200:
content = resp.json()["choices"][0]["message"]["content"].strip()
return {"content": content, "latency": latency, "success": True}
else:
return {"success": False, "error": f"HTTP {resp.status_code}: {resp.text}", "latency": latency}
def parallel_candidate_generation(problem, k, progress_cb=None):
import concurrent.futures
temperatures = np.linspace(0.1, 1.0, k)
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=min(8, k)) as executor:
futures = []
for i in range(k):
seed = 2025 + i * 31
futures.append(executor.submit(lm_studio_generate_single, problem, temperatures[i], seed))
for i, future in enumerate(concurrent.futures.as_completed(futures)):
res = future.result()
res["trajectory_id"] = i + 1
results.append(res)
if progress_cb:
progress_cb(i + 1, k)
results.sort(key=lambda x: x.get("trajectory_id", 0))
return resultsVoici comment chaque fonction s'intègre dans le pipeline multi-trajectoire :
lm_studio_generate_multiple() fonction : Lorsque le serveur LM Studio prend en charge le paramètre n, cette fonction envoie une seule requête API pour générer simultanément k solutions différentes. Il s'agit du mode le plus efficace, permettant une véritable mise à l'échelle en temps réel.lm_studio_generate_single() fonction : Si le serveur ne prend pas en charge le multi-échantillonnage, cette fonction fournit une solution de secours qui génère une trajectoire de solution par requête, permettant ainsi différentes températures et une reproductibilité via des graines.parallel_candidate_generation() fonction : Afin de maintenir les performances en mode de secours, cet utilitaire lance plusieurs appels d'lm_studio_generate_single() en parallèle, chacun avec des températures d'échantillonnage différentes, puis agrège toutes les réponses. Cela nous permet de disposer rapidement d'une large gamme de solutions, même si le multi-échantillonnage n'est pas disponible.Après avoir généré plusieurs chemins de raisonnement, nous avons besoin d'une méthode structurée pour identifier la solution la plus solide. Cette étape présente des outils de notation et de sélection qui imitent les techniques de modélisation de la récompense (SPRM) utilisées dans l'article MetaStone Reflective Reasoning.
def step_tokenize(trajectory: str) -> List[str]:
steps = [step.strip() for step in trajectory.split('.\n\n') if step.strip()]
return steps
def dummy_sprm_score(trajectory: str, problem: str) -> float:
steps = step_tokenize(trajectory)
n = len(steps)
def step_score(step):
s = 0.2
if any(x in step.lower() for x in ["therefore", "thus", "so", "finally", "conclude"]): s += 0.15
if any(sym in step for sym in ["=", "+", "-", "*", "/", "(", ")"]): s += 0.1
if len(step.split()) > 10: s += 0.1
return min(1.0, s)
step_scores = [step_score(s) for s in steps] or [0.01]
geometric_mean = np.exp(np.mean(np.log(np.maximum(step_scores, 1e-3))))
return min(1.0, geometric_mean + 0.05 * np.log1p(n))
def best_of_n_selection(candidates: List[Dict]) -> int:
best_idx = int(np.argmax([c["sprm_score"] for c in candidates]))
return best_idxVoici ce que fait chaque fonction :
step_tokenize() fonction : Cette fonction divise une trajectoire de raisonnement en étapes ou segments logiques, permettant ainsi une analyse et une notation étape par étape.dummy_sprm_score() fonction : Cette fonction attribue une note de récompense à chaque trajectoire candidate et encourage les réponses en plusieurs étapes, bien structurées et utilisant un raisonnement mathématique. Il remplace le modèle SPRM (Shared Process Reward Model) du journal, qui évalue en interne ses solutions.best_of_n_selection() function: À partir d'un ensemble de réponses candidates, cette fonction sélectionne la meilleure trajectoire en fonction du score SPRM le plus élevé, tout comme le modèle réflexif présenté dans l'article choisit automatiquement la réponse la plus robuste au moment du test.Dans cette étape, nous assemblons tous les éléments pour créer une démonstration interactive de raisonnement avec Streamlit.
st.markdown("""
<div class="main-header">
<h1> MetaStone XBai-o4 Reflective Reasoning Demo</h1>
</div>
""", unsafe_allow_html=True)
st.sidebar.header("Reasoning Mode")
mode = st.sidebar.selectbox("Reasoning effort (k candidates):", list(REASONING_MODES.keys()))
k = REASONING_MODES[mode]
st.sidebar.header("Problem Input")
problem = st.sidebar.text_area("Enter your math/logic problem:", "Prove that the square root of 2 is irrational")
if st.sidebar.button("Run Reflective Reasoning"):
st.session_state.run = True
st.session_state.results = None
st.session_state.best_idx = None
if "run" not in st.session_state:
st.session_state.run = False
if st.session_state.run:
st.info(f"Generating {k} reasoning trajectories in parallel...")
progress = st.progress(0)
def update_progress(done, total):
progress.progress(done / total)
try:
if supports_n_param():
results = lm_studio_generate_multiple(problem, k, temperature=0.7)
for idx, res in enumerate(results):
res["trajectory_id"] = idx + 1
else:
results = parallel_candidate_generation(problem, k, progress_cb=update_progress)
for res in results:
if res.get("success"):
res["sprm_score"] = dummy_sprm_score(res["content"], problem)
else:
res["sprm_score"] = 0.0
best_idx = best_of_n_selection(results)
st.session_state.results = results
st.session_state.best_idx = best_idx
st.session_state.run = False
except Exception as e:
st.error(f"Failed to generate trajectories: {str(e)}")
st.session_state.run = False
if st.session_state.get("results"):
results = st.session_state.results
best_idx = st.session_state.best_idx
st.success(f"Selected trajectory #{best_idx+1} (highest SPRM score)")
df = pd.DataFrame({
"Trajectory": [f"T{i+1}" for i in range(len(results))],
"SPRM Score": [r["sprm_score"] for r in results],
"Latency (s)": [r.get("latency", 0.0) for r in results],
"Success": [r.get("success", False) for r in results]
})
for i, res in enumerate(results):
is_best = (i == best_idx)
st.markdown(f"### {'' if is_best else ''} Trajectory {i+1} {'(SELECTED)' if is_best else ''}")
if res.get("success"):
st.info(f"SPRM Score: {res['sprm_score']:.3f} | Latency: {res['latency']:.1f}s")
st.code(res["content"])
else:
st.error(f"Failed: {res.get('error', 'Unknown error')}")
fig = px.bar(df, x="Trajectory", y="SPRM Score", color="Success", title="SPRM Scores for Each Trajectory")
st.plotly_chart(fig, use_container_width=True)
st.dataframe(df)Le flux principal de l'application permet d'atteindre plusieurs objectifs clés :
dummy_sprm_score), qui imite le modèle de récompense de processus partagé (SPRM). best_of_n_selection). Toutes les solutions générées, ainsi que leurs scores SPRM respectifs et leurs latences de génération, sont présentées sous forme textuelle et graphique pour permettre une analyse comparative.Pour l'essayer vous-même, enregistrez le code sous le nom xbai_demo.py et lancez :
streamlit run xbai_demo.pyApprenez l'IA grâce à ces cours !
Cours
Cours
Cours