
Curso
Building Agentic Workflows with LlamaIndex
2 h
1.2K
A MetaStone AI lançou recentemente o XBai-o4, um modelo de raciocínio de código aberto que traz escalabilidade paralela em tempo de teste e uma arquitetura generativa reflexiva. Com 32,8 bilhões de parâmetros e um cabeçote de autoavaliação integrado, o XBai o4 supera o o3-mini (modo médio) da OpenAI em todos os benchmarks de raciocínio matemático básico enquanto é executado localmente.
Neste blog, vou focar nas capacidades únicas de raciocínio reflexivo do XBai o4, mostrando como ele gera e avalia várias trajetórias de solução para problemas matemáticos por meio de uma interface Streamlit implantada localmente e desenvolvida pela LM Studio.
Neste tutorial, vou explicar passo a passo como:
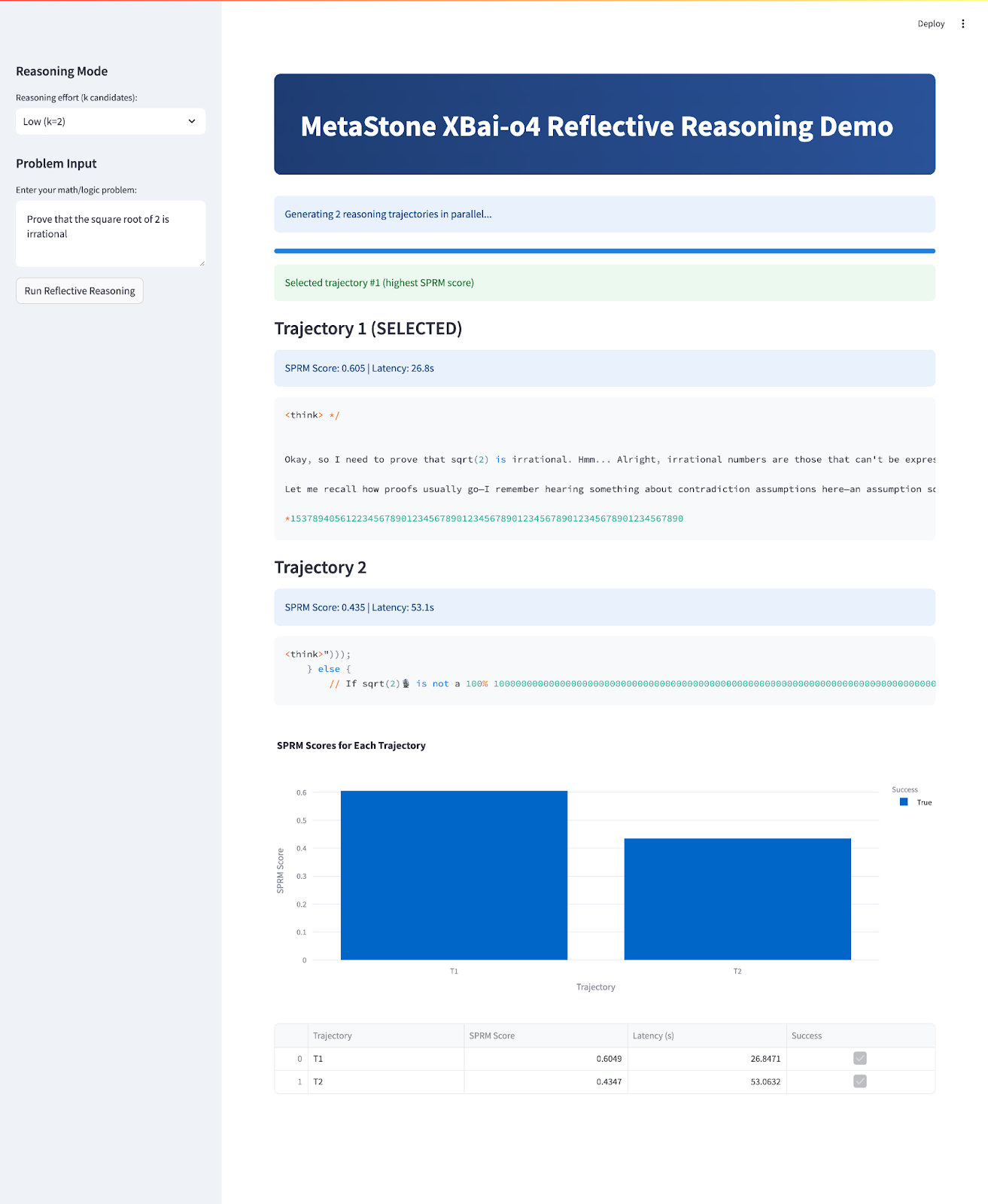
No final, seu aplicativo vai ficar assim:
XBai-o4 é o modelo de raciocínio de código aberto de quarta geração da MetaStone AI, que traz uma arquitetura generativa reflexiva que tenta redefinir como a IA lida com a resolução de problemas complexos. Diferente dos LLMs tradicionais, que tratam a geração e a avaliação de respostas como dois processos diferentes, o XBai o4 junta os dois em um modelo único usando um Modelo de Recompensa de Processo Compartilhado (SPRM). Esse design permite que o modelo gere, avalie e selecione vários caminhos de raciocínio ao mesmo tempo.
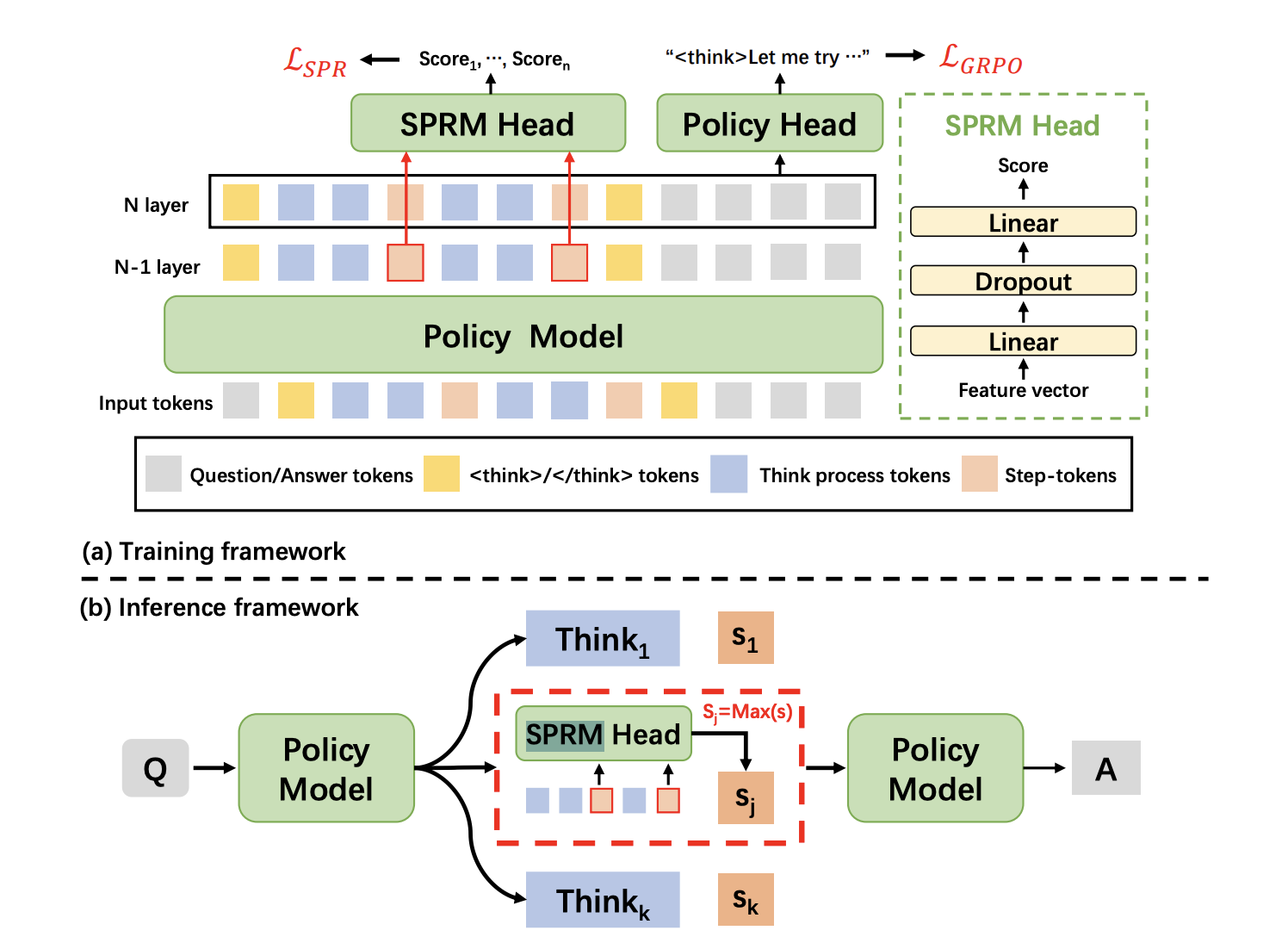
Fonte: Chefe do SPRM
Basicamente, o XBai o4 junta o aprendizado por reforço de cadeia longa de pensamento (Long-CoT) e o aprendizado por recompensa de processo ( ) em um único pipeline de treinamento. Aqui estão algumas das principais novidades deste modelo:
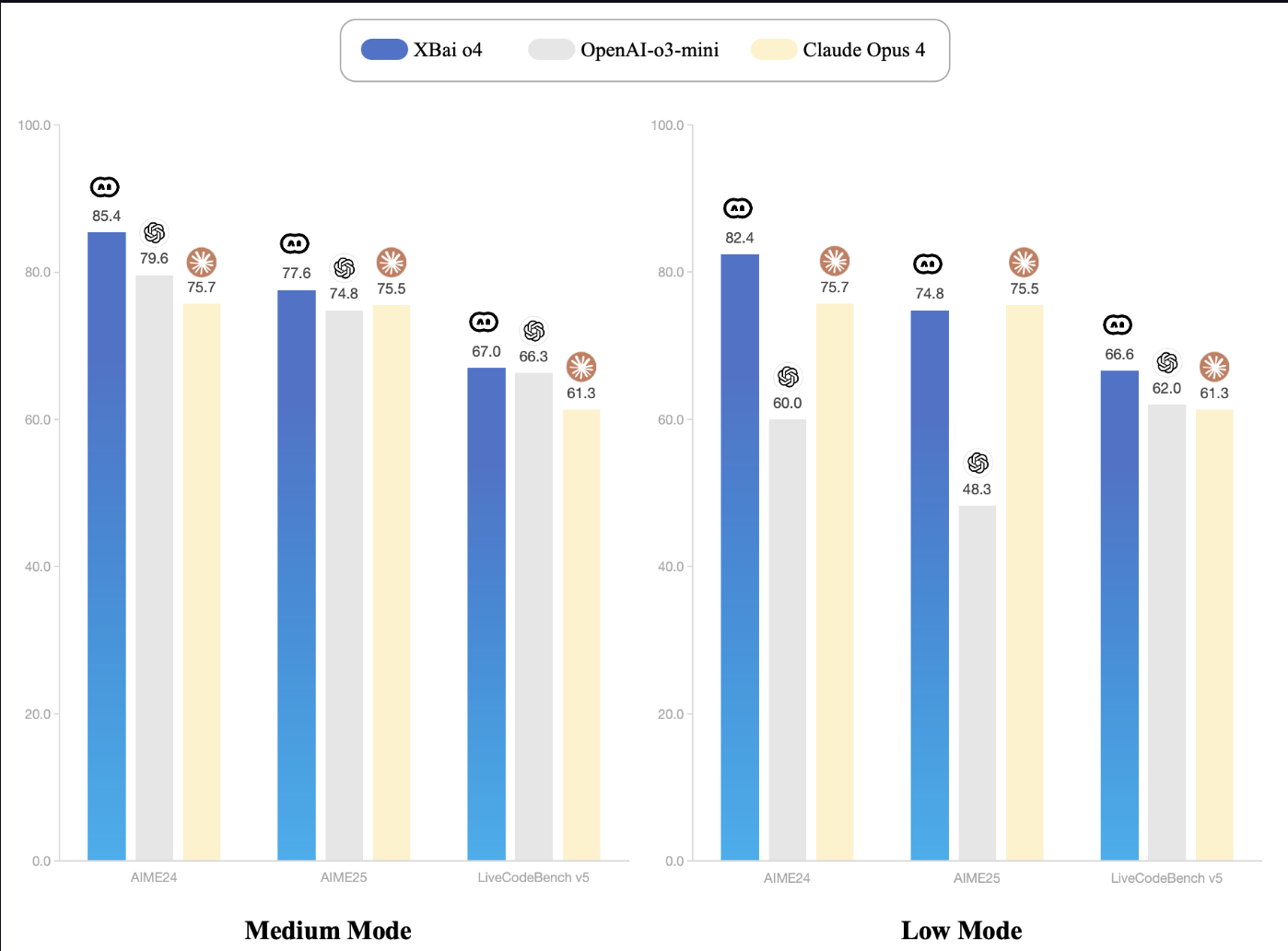
Fonte: Documentação do XBai-O4
Você pode rodar o XBai o4 localmente usando o LM Studio, que usa automaticamente a GPU do seu sistema ou a aceleração Apple Silicon (Metal/MLX) quando disponível (sem precisar de configuração manual). Pra um desempenho e compatibilidade ótimos, recomendo usar a versão quantizada GGUF do modelo.
O padrão GGUF (Formato Unificado Gerado por GPT) permite uma inferência local super eficiente, reduzindo a precisão dos pesos do modelo. Neste projeto, vamos usar a variante quantizada Q3_K_S, que é uma escolha popular por seu excelente equilíbrio entre qualidade e uso de memória.
Q3_K_S dá um desempenho de raciocínio forte com perda mínima de qualidade em comparação com modelos de precisão total.Vamos ver passo a passo como configurar o modelo GGUF quantizado para inferência local eficiente usando o LM Studio.
O LM Studio oferece suporte a GGUF e escolhe automaticamente o backend de inferência ideal para o seu hardware, seja Metal, GPU ou CPU.
Se você ainda não instalou o LM Studio, é só baixar em lmstudio.ai e seguir as instruções de instalação.
No LM Studio:
mradermacher/XBai-o4-GGUFXBai-o4.Q3_K_S.gguf (14,39 GB).
Depois que o LM Studio estiver instalado, carregamos e configuramos o modelo XBai o4 para inferência local:
XBai-o4.Q3_K_S.gguf ” da sua lista de modelos baixados.Depois de rodar, seu sistema tá pronto pra raciocínio multitrajetória com o XBai o4.
Agora vamos criar um aplicativo Streamlit que mostra como o XBai o4 é bom em raciocínio reflexivo com comparação de desempenho em tempo real.
Comece instalando as dependências:
pip install streamlit plotly pandas numpy requestsEsse comando garante que você tenha todas as dependências principais para a interface do usuário, tratamento de dados, plotagem e solicitações de API.
Depois, importa todas as bibliotecas necessárias e configura o layout da página do Streamlit e as configurações básicas.
import streamlit as st
import time
import requests
import numpy as np
import pandas as pd
import plotly.express as px
from typing import List, Dict, Any
LM_STUDIO_URL = "http://localhost:1234/v1" # change as per your server
REASONING_MODES = {"Low (k=2)": 2, "Medium (k=8)": 8, "High (k=32)": 8}
st.set_page_config(page_title="MetaStone-XBai-o4 Reflective Reasoning Demo", layout="wide")
st.markdown("""
<style>
.main-header {
background: linear-gradient(90deg, #1e3c72 0%, #2a5298 100%);
border-radius: 10px;
color: white;
text-align: center;
}
</style>
""", unsafe_allow_html=True)Esse bloco de código importa todas as bibliotecas principais necessárias para a nossa demonstração, incluindo Streamlit para a interface do usuário da web, além de outras bibliotecas básicas, como time, requests, numpy, pandas, plotly.express e typing tools.
Em seguida, define o endpoint da API do modelo LM_STUDIO_URL para que o aplicativo saiba para onde enviar as solicitações e define os modos de raciocínio (REASONING_MODES) para que os usuários possam selecionar facilmente quantas ramificações de solução gerar.
Por fim, usamos st.set_page_config() para configurar a interface do Streamlit com um título personalizado, layout amplo e um cabeçalho com gradiente no estilo CSS.
Observação: LM_STUDIO_URL é a URL base do servidor LLM, que você pode copiar do LM Studio. Normalmente é “http://localhost:1234/v1"”, mas pode variar. Além disso, escolha os modos de raciocínio de acordo com a capacidade do seu servidor.
Agora, vamos criar um conjunto de funções auxiliares que alimentam a lógica central de “raciocínio reflexivo” do nosso aplicativo. Essas funções facilitam o trabalho com várias trajetórias, a escolha da melhor solução e a pontuação de cada resposta.
Esta etapa apresenta uma função auxiliar simples que verifica automaticamente se o nosso servidor LM Studio consegue lidar com amostragem multitrajetória. Alguns servidores aceitam o n parameter, que permite pedir várias conclusões independentes em uma chamada de API, o que deixa o processo bem mais rápido.
def supports_n_param():
payload = {
"messages": [{"role": "user", "content": "What is 1+1?"}],
"max_tokens": 80,
"temperature": 0.1,
"n": 2,
"stream": False
}
try:
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
if resp.status_code == 200 and len(resp.json().get("choices", [])) == 2:
return True
except Exception:
pass
return FalseEssa função verifica se o servidor LM Studio suporta a geração de várias respostas (“trajetórias”) em uma única chamada de API usando o parâmetro n. Ele manda um pedido de teste rápido e mostra “Verdadeiro” se o recurso estiver disponível, permitindo uma amostragem “Melhor de N” de verdade para um raciocínio mais rápido e escalável.
Depois de ver se o nosso backend dá suporte à amostragem de múltiplas trajetórias, o próximo passo é criar vários caminhos de raciocínio para um problema específico. Essa seção mostra um conjunto de funções auxiliares que usam multiamostragem do lado do servidor (quando disponível) ou paralelizam de forma eficiente conclusões únicas, garantindo que o aplicativo continue rápido e escalável.
def lm_studio_generate_multiple(problem, k, temperature=0.8, seed=2025):
prompt = f"<think> {problem}\n</think>"
payload = {
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 196,
"temperature": temperature,
"top_p": 0.9,
"top_k": 30,
"n": k,
"stream": False,
"seed": seed
}
start = time.time()
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
latency = time.time() - start
if resp.status_code == 200:
result = resp.json()
return [{
"content": choice["message"]["content"].strip(),
"latency": latency / k,
"success": True,
} for choice in result.get("choices", [])]
else:
raise RuntimeError(f"LM Studio error: {resp.status_code}: {resp.text}")
def lm_studio_generate_single(problem, temperature, seed=None):
prompt = f"<think> {problem}\n</think>"
payload = {
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 196,
"temperature": temperature,
"top_p": 0.9,
"top_k": 30,
"stream": False,
"seed": seed
}
start = time.time()
resp = requests.post(f"{LM_STUDIO_URL}/chat/completions", json=payload, timeout=120)
latency = time.time() - start
if resp.status_code == 200:
content = resp.json()["choices"][0]["message"]["content"].strip()
return {"content": content, "latency": latency, "success": True}
else:
return {"success": False, "error": f"HTTP {resp.status_code}: {resp.text}", "latency": latency}
def parallel_candidate_generation(problem, k, progress_cb=None):
import concurrent.futures
temperatures = np.linspace(0.1, 1.0, k)
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=min(8, k)) as executor:
futures = []
for i in range(k):
seed = 2025 + i * 31
futures.append(executor.submit(lm_studio_generate_single, problem, temperatures[i], seed))
for i, future in enumerate(concurrent.futures.as_completed(futures)):
res = future.result()
res["trajectory_id"] = i + 1
results.append(res)
if progress_cb:
progress_cb(i + 1, k)
results.sort(key=lambda x: x.get("trajectory_id", 0))
return resultsVeja como cada função se encaixa no pipeline de trajetórias múltiplas:
lm_studio_generate_multiple() função: Quando o servidor LM Studio suporta o parâmetro n, essa função manda uma única solicitação API pra gerar k soluções diferentes de uma vez só. Esse é o modo mais eficiente, permitindo uma verdadeira escalabilidade no tempo de teste.lm_studio_generate_single() função: Se o servidor não suportar amostragem múltipla, essa função oferece uma alternativa que gera uma trajetória de solução por solicitação, permitindo diferentes temperaturas e reprodutibilidade por meio de sementes.parallel_candidate_generation() função: Para manter o desempenho no modo de fallback, esse utilitário dispara várias chamadas de “ lm_studio_generate_single() ” em paralelo, cada uma com diferentes temperaturas de amostragem, e depois junta todas as respostas. Isso garante que a gente ainda tenha várias opções de soluções rapidinho, mesmo que não tenha uma amostragem múltipla de verdade.Depois de criar vários caminhos de raciocínio, precisamos de uma maneira organizada de identificar a solução mais forte. Esta etapa apresenta ferramentas de pontuação e seleção que imitam as técnicas de modelagem de recompensa (SPRM) usadas no artigo MetaStone Reflective Reasoning.
def step_tokenize(trajectory: str) -> List[str]:
steps = [step.strip() for step in trajectory.split('.\n\n') if step.strip()]
return steps
def dummy_sprm_score(trajectory: str, problem: str) -> float:
steps = step_tokenize(trajectory)
n = len(steps)
def step_score(step):
s = 0.2
if any(x in step.lower() for x in ["therefore", "thus", "so", "finally", "conclude"]): s += 0.15
if any(sym in step for sym in ["=", "+", "-", "*", "/", "(", ")"]): s += 0.1
if len(step.split()) > 10: s += 0.1
return min(1.0, s)
step_scores = [step_score(s) for s in steps] or [0.01]
geometric_mean = np.exp(np.mean(np.log(np.maximum(step_scores, 1e-3))))
return min(1.0, geometric_mean + 0.05 * np.log1p(n))
def best_of_n_selection(candidates: List[Dict]) -> int:
best_idx = int(np.argmax([c["sprm_score"] for c in candidates]))
return best_idxAqui tá o que cada função faz:
step_tokenize() função: Essa função divide uma trajetória de raciocínio em etapas ou segmentos lógicos, permitindo uma análise e pontuação passo a passo.dummy_sprm_score() função: Essa função dá uma nota de recompensa pra cada trajetória dos candidatos e incentiva respostas com várias etapas, bem organizadas e que usam raciocínio matemático. Ele funciona como um substituto do Modelo de Recompensa de Processo Compartilhado (SPRM) do jornal, que avalia internamente suas soluções.best_of_n_selection() function: Dado um monte de respostas possíveis, essa função escolhe a melhor trajetória com base na pontuação SPRM mais alta, assim como o modelo reflexivo do artigo escolhe automaticamente a resposta mais robusta na hora do teste.Nesta etapa, juntamos todas as peças para criar uma demonstração interativa de raciocínio com o Streamlit.
st.markdown("""
<div class="main-header">
<h1> MetaStone XBai-o4 Reflective Reasoning Demo</h1>
</div>
""", unsafe_allow_html=True)
st.sidebar.header("Reasoning Mode")
mode = st.sidebar.selectbox("Reasoning effort (k candidates):", list(REASONING_MODES.keys()))
k = REASONING_MODES[mode]
st.sidebar.header("Problem Input")
problem = st.sidebar.text_area("Enter your math/logic problem:", "Prove that the square root of 2 is irrational")
if st.sidebar.button("Run Reflective Reasoning"):
st.session_state.run = True
st.session_state.results = None
st.session_state.best_idx = None
if "run" not in st.session_state:
st.session_state.run = False
if st.session_state.run:
st.info(f"Generating {k} reasoning trajectories in parallel...")
progress = st.progress(0)
def update_progress(done, total):
progress.progress(done / total)
try:
if supports_n_param():
results = lm_studio_generate_multiple(problem, k, temperature=0.7)
for idx, res in enumerate(results):
res["trajectory_id"] = idx + 1
else:
results = parallel_candidate_generation(problem, k, progress_cb=update_progress)
for res in results:
if res.get("success"):
res["sprm_score"] = dummy_sprm_score(res["content"], problem)
else:
res["sprm_score"] = 0.0
best_idx = best_of_n_selection(results)
st.session_state.results = results
st.session_state.best_idx = best_idx
st.session_state.run = False
except Exception as e:
st.error(f"Failed to generate trajectories: {str(e)}")
st.session_state.run = False
if st.session_state.get("results"):
results = st.session_state.results
best_idx = st.session_state.best_idx
st.success(f"Selected trajectory #{best_idx+1} (highest SPRM score)")
df = pd.DataFrame({
"Trajectory": [f"T{i+1}" for i in range(len(results))],
"SPRM Score": [r["sprm_score"] for r in results],
"Latency (s)": [r.get("latency", 0.0) for r in results],
"Success": [r.get("success", False) for r in results]
})
for i, res in enumerate(results):
is_best = (i == best_idx)
st.markdown(f"### {'' if is_best else ''} Trajectory {i+1} {'(SELECTED)' if is_best else ''}")
if res.get("success"):
st.info(f"SPRM Score: {res['sprm_score']:.3f} | Latency: {res['latency']:.1f}s")
st.code(res["content"])
else:
st.error(f"Failed: {res.get('error', 'Unknown error')}")
fig = px.bar(df, x="Trajectory", y="SPRM Score", color="Success", title="SPRM Scores for Each Trajectory")
st.plotly_chart(fig, use_container_width=True)
st.dataframe(df)O fluxo principal do aplicativo faz várias coisas importantes:
dummy_sprm_score), que imita o Modelo de Recompensa de Processo Compartilhado (SPRM). best_of_n_selection). Todas as soluções geradas, junto com suas respectivas pontuações SPRM e latências de geração, são apresentadas em formatos textual e gráfico para análise lado a lado.Para experimentar, salva o código como xbai_demo.py e abre:
streamlit run xbai_demo.pyAprenda IA com esses cursos!
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali
Tutorial
Zoumana Keita




