
Cours
Déploiement MLOps et cycle de vie
4 h
12K
L'apprentissage automatique (AutoML) est souvent mal compris.
De nombreux professionnels du secteur technologique supposent que les outils AutoML sont uniquement destinés aux utilisateurs professionnels ou aux équipes non techniques qui ne comprennent pas comment les modèles d'apprentissage automatique sont formés ou déployés. Cette hypothèse est incorrecte.
Dans la pratique, les scientifiques des données et les ingénieurs en apprentissage automatique utilisent régulièrement des cadres AutoML pour réduire le temps d'expérimentation, améliorer les performances des modèles et automatiser les étapes répétitives du cycle de vie de l'apprentissage automatique.
Ces outils AutoML prennent en charge des tâches telles que l'ingénierie des fonctionnalités, la sélection de modèles, le réglage des hyperparamètres et l'automatisation de bout en bout des pipelines, permettant ainsi aux équipes de se concentrer sur des tâches à plus forte valeur ajoutée.
Dans cet article, j'examinerai certains des principaux frameworks AutoML disponibles à l'heure actuelle, conçus pour des utilisateurs ayant différents niveaux d'expertise. Les outils sont classés en trois catégories distinctes :
Pour chaque framework, nous mettons en avant ses principales fonctionnalités et fournissons des exemples de code afin que vous puissiez commencer à l'utiliser immédiatement.
AutoML désigne les outils et les systèmes qui automatisent l'ensemble du processus de développement de modèles d'apprentissage automatique, depuis les données brutes jusqu'à l'obtention d'un modèle entraîné et déployable.
Les frameworks AutoML gèrent de nombreuses tâches répétitives et techniques liées à la création de modèles d'apprentissage automatique, permettant ainsi aux experts et aux utilisateurs moins expérimentés de travailler plus efficacement.
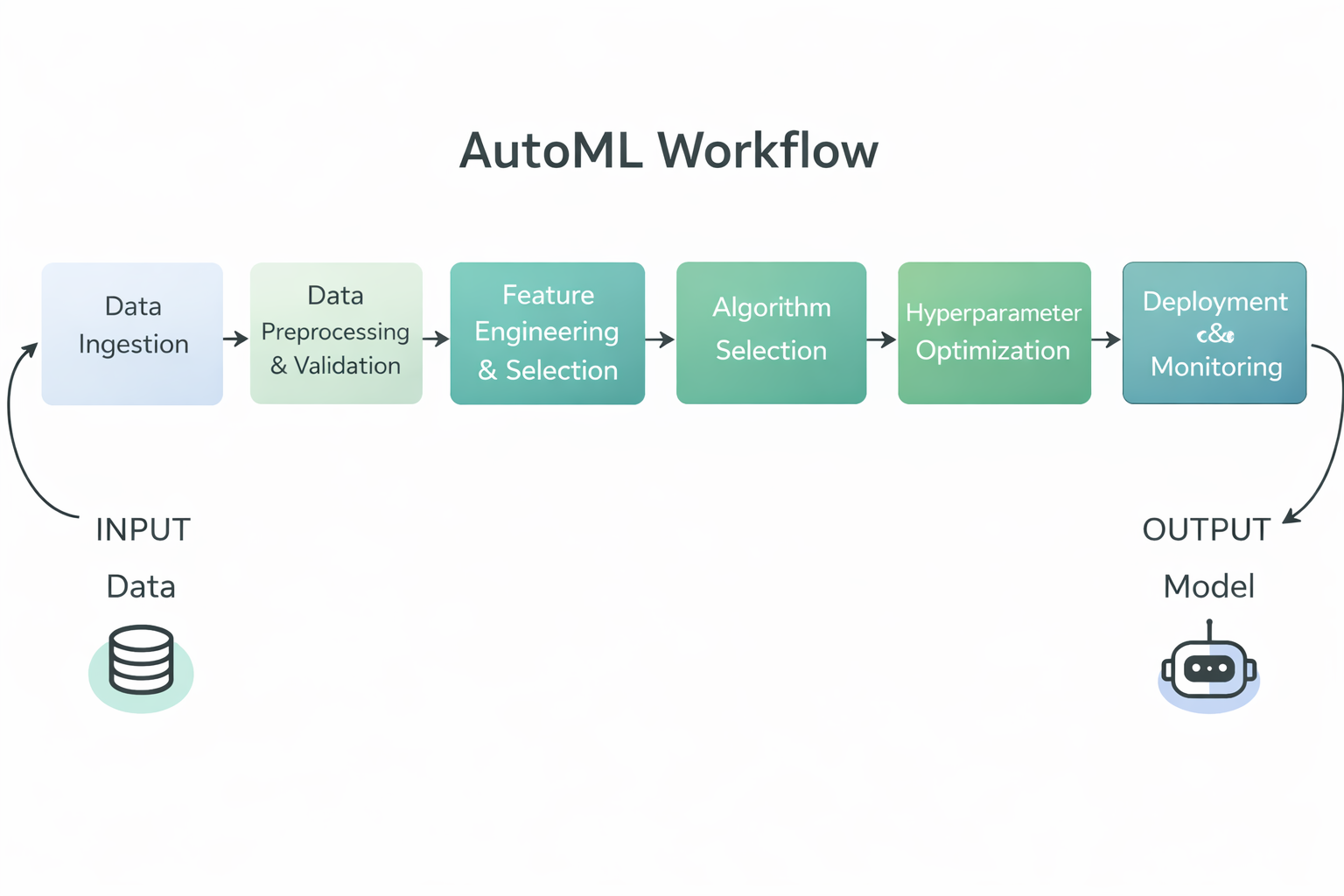
Diagramme du flux de travail AutoML
Plus précisément, les frameworks AutoML automatisent généralement les étapes suivantes du processus d'apprentissage automatique :
En automatisant ces tâches, les frameworks AutoML réduisent les efforts manuels, améliorent la cohérence et la reproductibilité, et permettent aux équipes techniques et non techniques de créer plus rapidement des modèles d'apprentissage automatique de haute qualité.
Les frameworks AutoML open source offrent des outils flexibles, transparents et conviviaux pour les développeurs, qui permettent aux professionnels d'automatiser la création de modèles tout en conservant un contrôle total sur les données, les pipelines et les workflows de déploiement.
TPOT est un framework AutoML Python open source qui utilise la programmation génétique pour découvrir et optimiser automatiquement des pipelines complets d'apprentissage automatique.
Il considère la conception de pipelines comme un problème de recherche évolutif, explorant des combinaisons d'étapes de prétraitement, de modèles et d'hyperparamètres afin d'identifier des solutions hautement performantes.
TPOT est particulièrement efficace pour les tâches liées aux données tabulaires qui nécessitent des expérimentations rapides et des bases de référence solides, tout en permettant aux praticiens d'inspecter, d'exporter et de réutiliser les pipelines résultants dans le cadre des workflows scikit-learn standard.
Caractéristiques principales :
Exemple de code :
Cet exemple illustre la configuration minimale requise pour utiliser TPOT. Les caractéristiques et les étiquettes de l'ensemble de données sont chargées, un modèle d'apprentissage automatique ( TPOTClassifier ) est initialisé avec les paramètres par défaut, et la méthoded'ajustement déclenche le processus de recherche automatisé.
Au cours de la formation, TPOT évalue plusieurs pipelines candidats à l'aide de la programmation génétique et sélectionne un modèle hautement performant en fonction du critère d'évaluation spécifié.
import tpot
X, y = load_my_data()
est = tpot.TPOTClassifier()
est.fit(X, y)AutoGluon est un framework AutoML Python open source développé par AWS AI qui automatise les tâches d'apprentissage automatique en mettant l'accent sur une grande précision, un code minimal et la prise en charge des données tabulaires, textuelles et image.
Il construit un ensemble diversifié de modèles et utilise la sélection automatisée de modèles, le réglage des hyperparamètres et l'apprentissage par ensemble pour offrir de solides performances prédictives sur différents types de données.
Caractéristiques principales :
Exemple de code :
Ce code charge les ensembles de données d'entraînement et de test sous forme d'ensembles de données tabulaires AutoGluon. Il crée ensuite un objet TabularPredictor spécifiant l'étiquette cible et appelle fit pour entraîner AutoGluon sur les données d'entraînement tabulaires. Une fois la formation terminée, il utilise le modèle formé pour générer des prédictions sur l'ensemble de test.
from autogluon.tabular import TabularDataset, TabularPredictor
label = "signature"
train_data = TabularDataset("train.csv")
predictor = TabularPredictor(label=label).fit(train_data)
test_data = TabularDataset("test.csv")
predictions = predictor.predict(test_data.drop(columns=[label]))FLAML (Fast Lightweight AutoML) est une bibliothèque Python AutoML open source développée par Microsoft Research. Elle est conçue pour trouver automatiquement et efficacement des modèles d'apprentissage automatique de haute qualité tout en minimisant les coûts de calcul et l'utilisation des ressources, ce qui la rend idéale pour les environnements où la vitesse et l'efficacité sont primordiales.
Caractéristiques principales :
Exemple de code :
Cet exemple de code illustre comment utiliser AutoML de FLAML. AutoML de FLAML pour effectuer une tâche de classification automatisée sur l'ensemble de données Iris, en spécifiant un budget temps et une métrique d'évaluation avant l'entraînement, puis en utilisant le modèle entraîné pour obtenir des probabilités de prédiction.
from flaml import AutoML
from sklearn.datasets import load_iris
X_train, y_train = load_iris(return_X_y=True)
automl = AutoML()
automl_settings = {
"time_budget": 1,
"metric": "accuracy",
"task": "classification",
"log_file_name": "iris.log",
}
automl.fit(X_train=X_train, y_train=y_train, **automl_settings)
print(automl.predict_proba(X_train))AutoKeras est une bibliothèque AutoML open source développée à partir de l' cadre d'apprentissage profond Keras qui recherche et forme automatiquement des réseaux neuronaux de haute qualité pour un large éventail de tâches, notamment les données structurées, les images et le texte, avec un minimum de codage requis.
Il utilise une recherche efficace d'architecture neuronale pour trouver des architectures de modèles et des hyperparamètres adaptés, rendant ainsi l'apprentissage profond plus accessible aux débutants comme aux praticiens expérimentés.
Caractéristiques principales :
StructuredDataClassifier permettent de simplifier l'entraînement de modèles d'apprentissage profond complexes à l'aide de quelques lignes de code seulement.Exemple de code :
Cet exemple de code importe les bibliothèques nécessaires et charge les ensembles de données d'entraînement et de test à partir des URL fournies. Il sépare les caractéristiques et les étiquettes, puis crée un objet d'ak.StructuredDataClassifier qui recherche automatiquement un modèle d'apprentissage profond performant. Le modèle est entraîné pour un nombre défini d'essais et d'époques, et le résultat final de l'évaluation sur l'ensemble de test est affiché.
import keras
import pandas as pd
import autokeras as ak
TRAIN_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/train.csv"
TEST_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/eval.csv"
train_file_path = keras.utils.get_file("train.csv", TRAIN_DATA_URL)
test_file_path = keras.utils.get_file("eval.csv", TEST_DATA_URL)
train_df = pd.read_csv(train_file_path)
test_df = pd.read_csv(test_file_path)
y_train = train_df["survived"].values
x_train = train_df.drop("survived", axis=1).values
y_test = test_df["survived"].values
x_test = test_df.drop("survived", axis=1).values
clf = ak.StructuredDataClassifier(overwrite=True, max_trials=3)
clf.fit(x_train, y_train, epochs=10)
print(clf.evaluate(x_test, y_test))Les plateformes AutoML sans code et à faible code simplifient le développement de modèles en simplifiant les workflows complexes, ce qui permet une expérimentation et un déploiement rapides tant pour les équipes techniques que pour les utilisateurs professionnels.
PyCaret est une bibliothèque open source de machine learning en Python qui automatise le workflow de machine learning de bout en bout pour des tâches telles que la classification, la régression, le clustering, la détection d'anomalies et la prévision de séries chronologiques. Elle permet un prototypage rapide avec seulement quelques lignes de code tout en prenant en charge une interface utilisateur graphique pour ceux qui préfèrent les expériences low-code ou click-through.
Caractéristiques principales :
compare_models e entraîne et évalue de nombreux modèles à l'aide de la validation croisée et fournit un classement des performances afin de faciliter le choix du meilleur modèle.Exemple de code :
Cet extrait de code montre comment charger un ensemble de données intégré, initialiser le module de régression PyCaret avec setup (qui prétraite les données et initialise l'environnement ML), puis utiliser compare_models pour entraîner, évaluer et classer automatiquement divers modèles de régression, en renvoyant celui qui est le plus performant.
from pycaret.datasets import get_data
from pycaret.regression import *
data = get_data("insurance")
s = setup(data, target="charges", session_id=123)
best_model = compare_models()MLJAR Studio est un environnement AutoML sans code et à faible code qui vous permet de former et de comparer des modèles d'apprentissage automatique via une interface guidée, tout en offrant un flux de travail Python optionnel via le logiciel open source mljar-supervised .
Caractéristiques principales :
Exemple de code :
Il n'est pas nécessaire de connaître le langage de programmation pour utiliser MLJAR Studio, car AutoML peut être exécuté via l'interface graphique. Cependant, le code ci-dessous présente l'approche programmatique facultative utilisant la bibliothèque mljar-supervised. Il charge un ensemble de données, le divise en caractéristiques et en cibles, exécute la formation AutoML, puis génère des prédictions à l'aide du modèle formé.
import pandas as pd
from supervised.automl import AutoML
df = pd.read_csv(
"https://raw.githubusercontent.com/pplonski/datasets-for-start/master/adult/data.csv",
skipinitialspace=True,
)
X = df[df.columns[:-1]]
y = df["income"]
automl = AutoML(results_path="mljar_results")
automl.fit(X, y)
predictions = automl.predict(X)H2O AutoML est une fonctionnalité AutoML open source intégrée à la plateforme H2O qui offre un apprentissage automatique évolutif et automatisé avec prise en charge de Python, R et une interface graphique sans code appelée H2O Flow, permettant aux utilisateurs techniques et non techniques de créer, d'évaluer et de sélectionner des modèles avec un minimum de codage. Les utilisateurs peuvent utiliser l'interface Web Flow pour importer des données, exécuter des expériences AutoML, explorer les résultats et exporter des modèles sans avoir à écrire de code.
Caractéristiques principales :
Exemple de code :
Cet exemple illustre comment utiliser H2O AutoML via Python. Il initialise l'environnement H2O, importe les ensembles de données d'entraînement et de test, spécifie les colonnes de caractéristiques et de cibles, lance une exécution AutoML avec une limite sur le nombre de modèles, puis affiche un classement des modèles les plus performants.
Remarque : Bien qu'il s'agisse de l'approche programmatique, les mêmes tâches peuvent être effectuées via l'interface Web H2O Flow sans avoir à écrire de code.
import h2o
from h2o.automl import H2OAutoML
h2o.init()
train = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/smalldata/higgs/higgs_train_10k.csv"
)
test = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/smalldata/higgs/higgs_test_5k.csv"
)
x = train.columns
y = "response"
x.remove(y)
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
aml = H2OAutoML(max_models=20, seed=1)
aml.train(x=x, y=y, training_frame=train)
aml.leaderboardLes solutions AutoML de niveau entreprise offrent des plateformes d'apprentissage automatique évolutives, sécurisées et réglementées, conçues pour le déploiement en production, la conformité et l'utilisation opérationnelle à grande échelle.
DataRobot est une plateforme AutoML sans code et à faible code destinée aux entreprises, qui permet aux utilisateurs professionnels, aux analystes et aux équipes chargées des données de créer, de déployer et de gérer des modèles d'apprentissage automatique sans avoir besoin de connaissances approfondies en programmation.
La plateforme automatise l'ensemble du cycle de vie de l'apprentissage automatique, depuis l'ingestion des données et l'ingénierie des fonctionnalités jusqu'à la formation, le déploiement et la surveillance des modèles, tout en offrant une gouvernance solide, une explicabilité et des contrôles opérationnels nécessaires dans les environnements réglementés.
Caractéristiques principales :
Exemple de code :
Bien que DataRobot soit principalement utilisé via son interface sans code, il fournit également une API Python pour le contrôle programmatique et l'automatisation. L'exemple ci-dessous montre comment s'authentifier auprès de DataRobot, créer un projet à partir d'un ensemble de données et exécuter AutoPilot pour former et évaluer automatiquement des modèles.
import datarobot as dr
dr.Client(config_path="./drconfig.yaml")
dataset = dr.Dataset.create_from_file("auto-mpg.csv")
project = dr.Project.create_from_dataset(
dataset.id,
project_name="Auto MPG Project"
)
from datarobot import AUTOPILOT_MODE
project.analyze_and_model(
target="mpg",
mode=AUTOPILOT_MODE.QUICK
)
project.wait_for_autopilot()Amazon SageMaker Autopilot est une solution AutoML entièrement gérée par AWS qui permet aux utilisateurs d'automatiser le processus de machine learning de bout en bout. est une solution AutoML entièrement gérée par AWS qui permet aux utilisateurs d'automatiser le flux de travail de machine learning de bout en bout sans sans code ou avec peu de code, notamment via une interface web dans Amazon SageMaker Canvas ou SageMaker Studio.
Les utilisateurs peuvent importer des données, configurer la variable cible, évaluer les modèles candidats et déployer des modèles en quelques clics dans la console, tandis que le SDK Python et les API restent disponibles en option pour rendre les expériences reproductibles ou pour les intégrer à d'autres systèmes.
Caractéristiques principales :
Exemple de code :
Le code ci-dessous montre comment exécuter Amazon SageMaker Autopilot de manière programmatique à l'aide du SDK Python. Cette approche est facultative et peut être utilisée pour reproduire des résultats ou s'intégrer dans des pipelines automatisés.
from sagemaker import AutoML, AutoMLInput
automl = AutoML(
role=execution_role,
target_attribute_name=target_attribute_name,
sagemaker_session=pipeline_session,
total_job_runtime_in_seconds=3600,
mode="ENSEMBLING",
)
automl.fit(
inputs=[
AutoMLInput(
inputs=s3_train_val,
target_attribute_name=target_attribute_name,
channel_type="training",
)
]
)Google Cloud AutoML fait partie de Vertex AI, la plateforme d'apprentissage automatique unifiée de Google Cloud qui permet aux utilisateurs de créer, former, évaluer et déployer des modèles de haute qualité à l'aide d'une infrastructure entièrement gérée.
Vertex AI AutoML prend en charge les données tabulaires, le traitement du langage naturel, la vision par ordinateur et les tâches vidéo. Il est conçu pour être accessible via une interface Web sans code dans Google Cloud Console.
Toutes les étapes essentielles, telles que la création d'ensembles de données, la sélection des tâches, la formation, l'évaluation et le déploiement, peuvent être réalisées via l'interface utilisateur sans qu'il soit nécessaire d'écrire du code.
Caractéristiques principales :
Exemple de code :
Bien que Vertex AI AutoML soit principalement conçu pour les workflows sans code, le SDK Python peut être utilisé pour rendre les expériences reproductibles ou intégrer la formation AutoML dans des pipelines automatisés.
Le court extrait suivant initialise un projet Vertex AI, crée un ensemble de données d'images à partir d'un index CSV stocké dans Cloud Storage et lance une tâche de formation d'images AutoML.
from google.cloud import aiplatform
aiplatform.init(
project="YOUR_PROJECT_ID",
location="us-central1",
staging_bucket="gs://YOUR_BUCKET",
)
dataset = aiplatform.ImageDataset.create(
display_name="flowers",
gcs_source=["gs://cloud-samples-data/ai-platform/flowers/flowers.csv"],
import_schema_uri=aiplatform.schema.dataset.ioformat.image.single_label_classification,
)
training_job = aiplatform.AutoMLImageTrainingJob(
display_name="flowers_automl",
prediction_type="classification",
)
model = training_job.run(
dataset=dataset,
model_display_name="flowers_model",
budget_milli_node_hours=8000,
)Ce tableau compare les frameworks AutoML populaires en fonction de leur niveau d'automatisation, du style de leur interface et de leur adéquation à l'expérimentation open source, aux workflows low-code et au déploiement à l'échelle de l'entreprise.
|
Cadre |
Catégorie |
Niveau de code |
Options d'interface |
Cas d'utilisation principal |
|
TPOT |
Open Source |
Élevé |
API Python |
Détection et optimisation automatisées des pipelines pour les données tabulaires |
|
AutoGluon |
Open Source |
Faible |
API Python |
Modèles rapides, hautement précis et prêts pour la production dans toutes les modalités |
|
FLAML |
Open Source |
Faible |
API Python |
Optimisation de modèles économique et respectueuse des ressources |
|
AutoKeras |
Open Source |
Moyen |
API Python |
Recherche d'architecture neuronale et automatisation de l'apprentissage profond |
|
PyCaret |
Low Code |
Très faible |
API Python, outils GUI optionnels |
Expérimentation rapide et processus axés sur l'analyse |
|
Studio MLJAR |
Sans code |
Aucun |
Interface utilisateur Web, Python en option |
Expérimentation AutoML et comparaison de modèles adaptées aux entreprises |
|
H2O AutoML |
Hybride |
Faible |
Interface utilisateur Web (H2O Flow), Python, R |
AutoML évolutif pour les grands ensembles de données et le déploiement en entreprise |
|
DataRobot |
Entreprise |
Aucun à faible |
Interface utilisateur Web, API Python |
Apprentissage automatique d'entreprise avec gouvernance, explicabilité et MLOps |
|
Pilote automatique SageMaker |
Entreprise |
Aucun à faible |
Console AWS, SDK Python |
AutoML natif AWS intégré aux pipelines de production |
|
Google Cloud AutoML |
Entreprise |
Aucun |
Console Vertex AI, SDK facultatif |
Vision, NLP et AutoML tabulaire sur une infrastructure GCP gérée |
Les frameworks AutoML ont évolué pour devenir des outils de production qui accompagnent les équipes tout au long du cycle de vie du machine learning. Dans la pratique, leur utilisation ne se limite pas à l'expérimentation ou au prototypage.
J'ai utilisé les frameworks AutoML pour participer à des concours Kaggle, pour créer des pipelines complets de machine learning de bout en bout pour des projets réels, et même pour me préparer et réussir des entretiens techniques.
Du point de vue d'un data scientist, AutoML constitue un moyen efficace d'établir un modèle de référence solide et impartial avec très peu de frais généraux.
Il suffit de fournir les données pour que ces cadres se chargent de l'ingénierie des caractéristiques, de la sélection des modèles, du réglage des hyperparamètres et de l'évaluation. Cela permet aux praticiens de se concentrer sur la compréhension du problème, la validation des hypothèses et l'amélioration des résultats, plutôt que de consacrer un temps excessif à la recherche et à l'expérimentation de modèles à partir de zéro.
L'AutoML ne remplace pas l'expertise. Au contraire, cela accélère le flux de travail en fournissant un point de départ fiable qui peut être amélioré de manière itérative.
La construction du modèle n'est que la première étape. Découvrez comment déployer et surveiller vos modèles AutoML en production grâce au cours cours Concepts MLOps.
Meilleurs cours DataCamp
Cours
Cours
Cours