Curso
Implantação e ciclo de vida em MLOps
4 h
12K
O machine learning automático (AutoML) é muitas vezes mal interpretado.
Muita gente na área de tecnologia acha que as ferramentas AutoML são só pra quem trabalha com negócios ou equipes que não entendem como os modelos de machine learning são treinados ou implantados. Essa suposição está errada.
Na prática, cientistas de dados e engenheiros de machine learning usam regularmente estruturas AutoML para reduzir o tempo de experimentação, melhorar o desempenho do modelo e automatizar etapas repetitivas do ciclo de vida do machine learning.
Essas ferramentas AutoML dão suporte a tarefas como engenharia de recursos, seleção de modelos, ajuste de hiperparâmetros e automação de pipeline de ponta a ponta, permitindo que as equipes se concentrem em trabalhos de maior valor.
Neste artigo, vou explorar algumas das principais estruturas AutoML disponíveis atualmente, projetadas para usuários com diferentes níveis de especialização. As ferramentas estão divididas em três categorias bem claras:
Para cada estrutura, destacamos suas principais características e fornecemos exemplos de código para que você possa começar a usá-la imediatamente.
AutoML é quando a gente tem ferramentas e sistemas que automatizam todo o processo de desenvolvimento de modelos de machine learning, desde os dados brutos até um modelo treinado e pronto pra ser usado.
As estruturas AutoML cuidam de várias tarefas repetitivas e técnicas que fazem parte da criação de modelos de machine learning, pra que tanto os profissionais experientes quanto os usuários menos técnicos possam trabalhar de forma mais eficiente.
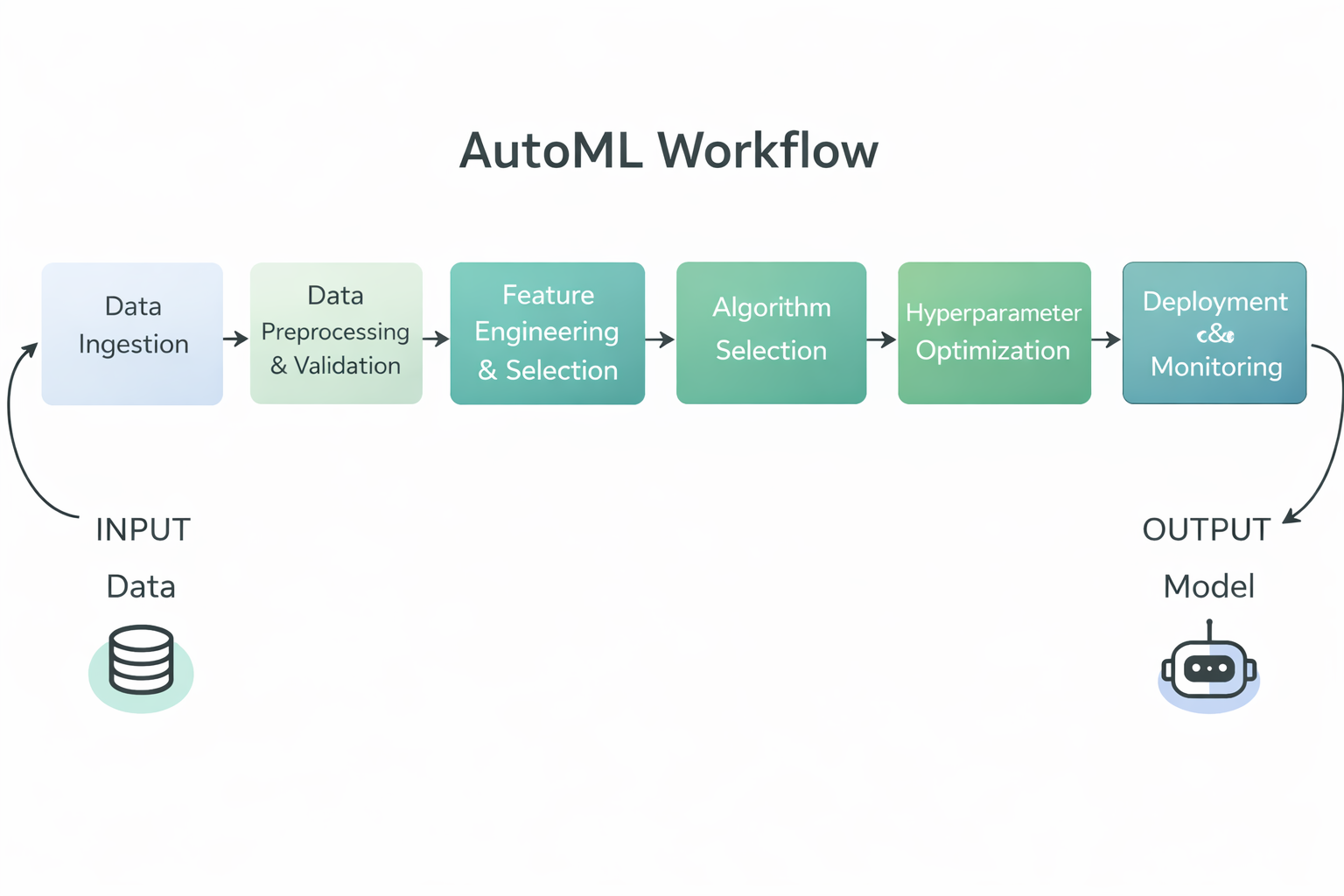
Diagrama do fluxo de trabalho do AutoML
Especificamente, as estruturas AutoML normalmente automatizam as seguintes etapas no fluxo de trabalho de machine learning:
Ao automatizar essas tarefas, as estruturas AutoML reduzem o esforço manual, melhoram a consistência e a reprodutibilidade e permitem que equipes técnicas e não técnicas criem modelos de machine learning de alta qualidade mais rapidamente.
As estruturas AutoML de código aberto oferecem ferramentas flexíveis, transparentes e fáceis de usar para desenvolvedores, que permitem automatizar a criação de modelos e ainda manter o controle total sobre os dados, pipelines e fluxos de trabalho de implantação.
TPOT é uma estrutura Python AutoML de código aberto que usa programação genética para descobrir e otimizar automaticamente pipelines completos de machine learning.
Ele encara o projeto de pipeline como um problema de pesquisa evolutiva, explorando combinações de etapas de pré-processamento, modelos e hiperparâmetros para identificar soluções de alto desempenho.
O TPOT é especialmente bom para tarefas com dados em tabelas, onde é preciso fazer experimentos rápidos e ter bases sólidas, ao mesmo tempo que permite que os profissionais vejam, exportem e reutilizem os pipelines resultantes dentro dos fluxos de trabalho padrão do scikit-learn.
Principais características:
Exemplo de código:
Esse exemplo mostra a configuração mínima necessária para usar o TPOT. As características e os rótulos do conjunto de dados são carregados, um TPOTClassifier é inicializado com as configurações padrão e o métodofit inicia o processo de pesquisa automática.
Durante o treinamento, o TPOT avalia vários pipelines candidatos usando programação genética e escolhe um modelo de alto desempenho com base na métrica de avaliação especificada.
import tpot
X, y = load_my_data()
est = tpot.TPOTClassifier()
est.fit(X, y)AutoGluon é uma estrutura Python AutoML de código aberto desenvolvida pela AWS AI que automatiza tarefas de machine learning com foco em alta precisão, código mínimo e suporte para dados tabulares, de texto e de imagem.
Ele cria um conjunto variado de modelos e usa seleção automática de modelos, ajuste de hiperparâmetros e aprendizado conjunto para oferecer um desempenho preditivo robusto em diferentes tipos de dados.
Principais características:
Exemplo de código:
Esse código carrega os conjuntos de dados de treinamento e teste como conjuntos de dados tabulares do AutoGluon. Em seguida, ele cria um objeto TabularPredictor especificando o rótulo de destino e chama fit para treinar o AutoGluon nos dados de treinamento tabulares. Depois que o treinamento termina, ele usa o modelo treinado para gerar previsões no conjunto de testes.
from autogluon.tabular import TabularDataset, TabularPredictor
label = "signature"
train_data = TabularDataset("train.csv")
predictor = TabularPredictor(label=label).fit(train_data)
test_data = TabularDataset("test.csv")
predictions = predictor.predict(test_data.drop(columns=[label]))FLAML (Fast Lightweight AutoML) é uma biblioteca Python AutoML de código aberto desenvolvida pela Microsoft Research, projetada para encontrar modelos de machine learning de alta qualidade de forma automática e eficiente, minimizando o custo computacional e o uso de recursos, tornando-a ideal para ambientes onde velocidade e eficiência são fundamentais.
Principais características:
Exemplo de código:
Esse exemplo de código mostra como usar o AutoML do FLAML. AutoML para fazer uma tarefa de classificação automática no conjunto de dados Iris, definindo um tempo e uma métrica de avaliação antes do treinamento e, depois, usando o modelo treinado para obter probabilidades de previsão.
from flaml import AutoML
from sklearn.datasets import load_iris
X_train, y_train = load_iris(return_X_y=True)
automl = AutoML()
automl_settings = {
"time_budget": 1,
"metric": "accuracy",
"task": "classification",
"log_file_name": "iris.log",
}
automl.fit(X_train=X_train, y_train=y_train, **automl_settings)
print(automl.predict_proba(X_train))AutoKeras é uma biblioteca AutoML de código aberto criada com base no Keras deep learning , que procura e treina automaticamente redes neurais de alta qualidade para uma ampla gama de tarefas, incluindo dados estruturados, imagens e texto, com o mínimo de codificação necessário.
Ele usa uma busca eficiente de arquitetura neural para encontrar arquiteturas de modelo e hiperparâmetros adequados, tornando o aprendizado profundo mais acessível tanto para iniciantes quanto para profissionais experientes.
Principais características:
StructuredDataClassifier, simplificam o treinamento de modelos complexos de deep learning com apenas algumas linhas de código.Exemplo de código:
Esse exemplo de código importa as bibliotecas necessárias e carrega os conjuntos de dados de treinamento e teste a partir dos URLs fornecidos. Ele separa características e rótulos e, em seguida, cria um objeto ak.StructuredDataClassifier que procura automaticamente um modelo de aprendizado profundo robusto. O modelo é treinado para um número definido de tentativas e épocas, e o resultado final da avaliação no conjunto de testes é impresso.
import keras
import pandas as pd
import autokeras as ak
TRAIN_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/train.csv"
TEST_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/eval.csv"
train_file_path = keras.utils.get_file("train.csv", TRAIN_DATA_URL)
test_file_path = keras.utils.get_file("eval.csv", TEST_DATA_URL)
train_df = pd.read_csv(train_file_path)
test_df = pd.read_csv(test_file_path)
y_train = train_df["survived"].values
x_train = train_df.drop("survived", axis=1).values
y_test = test_df["survived"].values
x_test = test_df.drop("survived", axis=1).values
clf = ak.StructuredDataClassifier(overwrite=True, max_trials=3)
clf.fit(x_train, y_train, epochs=10)
print(clf.evaluate(x_test, y_test))As plataformas AutoML sem código e com pouco código simplificam o desenvolvimento de modelos ao abstrair fluxos de trabalho complexos, permitindo experimentação e implantação rápidas tanto para equipes técnicas quanto para usuários comerciais.
PyCaret é uma biblioteca de machine learning de código aberto e baixo código em Python que automatiza o fluxo de trabalho completo de machine learning para tarefas como classificação, regressão, agrupamento, detecção de anomalias e previsão de séries temporais, permitindo a prototipagem rápida com apenas algumas linhas de código, ao mesmo tempo em que oferece suporte a uma interface gráfica de usuário para quem prefere experiências de baixo código ou cliques.
Principais características:
compare_models treina e avalia vários modelos usando validação cruzada e fornece um quadro de líderes de desempenho para ajudar a escolher o melhor modelo.Exemplo de código:
Esse trecho de código mostra como carregar um conjunto de dados embutido, inicializar o módulo de regressão PyCaret com setup (que pré-processa os dados e inicializa o ambiente ML) e, em seguida, usar compare_models para treinar, avaliar e classificar automaticamente uma variedade de modelos de regressão, retornando aquele com melhor desempenho.
from pycaret.datasets import get_data
from pycaret.regression import *
data = get_data("insurance")
s = setup(data, target="charges", session_id=123)
best_model = compare_models()O MLJAR Studio é um ambiente AutoML sem código e com pouco código que permite treinar e comparar modelos de machine learning por meio de uma interface guiada, além de oferecer um fluxo de trabalho Python opcional por meio do código aberto mljar-supervised .
Principais características:
Exemplo de código:
Você não precisa de código para usar o MLJAR Studio, porque pode rodar o AutoML pela interface gráfica. Mas, o código abaixo mostra a abordagem programática opcional usando a biblioteca mljar-supervised. Ele carrega um conjunto de dados, divide-o em características e alvo, executa o treinamento do AutoML e, em seguida, gera previsões usando o modelo treinado.
import pandas as pd
from supervised.automl import AutoML
df = pd.read_csv(
"https://raw.githubusercontent.com/pplonski/datasets-for-start/master/adult/data.csv",
skipinitialspace=True,
)
X = df[df.columns[:-1]]
y = df["income"]
automl = AutoML(results_path="mljar_results")
automl.fit(X, y)
predictions = automl.predict(X)H2O AutoML é um recurso AutoML de código aberto dentro da plataforma H2O que oferece machine learning escalável e automatizado com suporte para Python, R e uma interface gráfica sem código chamada H2O Flow, permitindo que usuários técnicos e não técnicos criem, avaliem e selecionem modelos com o mínimo de codificação. Os usuários podem usar a interface Flow baseada na web para importar dados, fazer experimentos com o AutoML, ver os resultados e exportar modelos sem precisar escrever nenhum código.
Principais características:
Exemplo de código:
Esse exemplo mostra como usar o H2O AutoML com Python. Inicializa o ambiente H2O, importa conjuntos de dados de treinamento e teste, especifica colunas de recursos e alvos, inicia uma execução do AutoML com um limite no número de modelos e, em seguida, exibe um quadro de líderes com a classificação dos modelos de melhor desempenho.
Observação: Embora essa seja a abordagem programática, as mesmas tarefas podem ser concluídas por meio da interface web do H2O Flow, sem precisar escrever nenhum código.
import h2o
from h2o.automl import H2OAutoML
h2o.init()
train = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/smalldata/higgs/higgs_train_10k.csv"
)
test = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/smalldata/higgs/higgs_test_5k.csv"
)
x = train.columns
y = "response"
x.remove(y)
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
aml = H2OAutoML(max_models=20, seed=1)
aml.train(x=x, y=y, training_frame=train)
aml.leaderboardAs soluções AutoML de nível empresarial oferecem plataformas de machine learning escaláveis, seguras e controladas, feitas para implantação em produção, conformidade e uso operacional em grande escala.
O DataRobot é uma plataforma AutoML sem código e com pouco código, feita pra empresas, que permite que usuários de negócios, analistas e equipes de dados criem, implementem e gerenciem modelos de machine learning sem precisar programar muito.
A plataforma automatiza todo o ciclo de vida do machine learning, desde a ingestão de dados e engenharia de recursos até o treinamento, a implantação e o monitoramento de modelos, ao mesmo tempo em que oferece governança, explicabilidade e controles operacionais robustos, necessários em ambientes regulamentados.
Principais características:
Exemplo de código:
Embora o DataRobot seja usado principalmente por meio de sua interface sem código, ele também oferece uma API Python para controle programático e automação. O exemplo abaixo mostra como fazer a autenticação no DataRobot, criar um projeto a partir de um conjunto de dados e usar o AutoPilot para treinar e avaliar modelos automaticamente.
import datarobot as dr
dr.Client(config_path="./drconfig.yaml")
dataset = dr.Dataset.create_from_file("auto-mpg.csv")
project = dr.Project.create_from_dataset(
dataset.id,
project_name="Auto MPG Project"
)
from datarobot import AUTOPILOT_MODE
project.analyze_and_model(
target="mpg",
mode=AUTOPILOT_MODE.QUICK
)
project.wait_for_autopilot()O Amazon SageMaker Autopilot é uma solução AutoML totalmente gerenciada da AWS que permite aos usuários automatizar o fluxo de trabalho completo de machine learning com sem código ou com pouco código, especialmente por meio de uma interface da web no Amazon SageMaker Canvas ou SageMaker Studio.
Os usuários podem importar dados, configurar a variável alvo, avaliar modelos candidatos e implantar modelos com apenas alguns cliques no console, enquanto o SDK Python e as APIs continuam disponíveis como uma forma opcional de tornar os experimentos reproduzíveis ou de integrar com outros sistemas.
Principais características:
Exemplo de código:
O código abaixo mostra como executar o Amazon SageMaker Autopilot programaticamente usando o SDK Python. Essa abordagem é opcional e pode ser usada para reproduzir resultados ou integrar em pipelines automatizados.
from sagemaker import AutoML, AutoMLInput
automl = AutoML(
role=execution_role,
target_attribute_name=target_attribute_name,
sagemaker_session=pipeline_session,
total_job_runtime_in_seconds=3600,
mode="ENSEMBLING",
)
automl.fit(
inputs=[
AutoMLInput(
inputs=s3_train_val,
target_attribute_name=target_attribute_name,
channel_type="training",
)
]
)O Google Cloud AutoML para nuvem faz parte do Vertex AI, a plataforma unificada de machine learning do Google Cloud que permite aos usuários criar, treinar, avaliar e implantar modelos de alta qualidade usando uma infraestrutura totalmente gerenciada.
O Vertex AI AutoML dá suporte a dados tabulares, processamento de linguagem natural, visão computacional e tarefas de vídeo, e foi feito pra ser acessível por meio de uma interface web sem código no Google Cloud Console.
Todas as etapas principais, como criação de conjuntos de dados, seleção de tarefas, treinamento, avaliação e implantação, podem ser concluídas por meio da interface do usuário, sem precisar escrever nenhum código.
Principais características:
Exemplo de código:
Embora o Vertex AI AutoML tenha sido criado principalmente para fluxos de trabalho sem código, o SDK Python pode ser usado para tornar os experimentos reproduzíveis ou integrar o treinamento do AutoML em pipelines automatizados.
O pequeno trecho a seguir inicializa um projeto do Vertex AI, cria um conjunto de dados de imagens a partir de um índice CSV armazenado no Cloud Storage e inicia uma tarefa de treinamento de imagens do AutoML.
from google.cloud import aiplatform
aiplatform.init(
project="YOUR_PROJECT_ID",
location="us-central1",
staging_bucket="gs://YOUR_BUCKET",
)
dataset = aiplatform.ImageDataset.create(
display_name="flowers",
gcs_source=["gs://cloud-samples-data/ai-platform/flowers/flowers.csv"],
import_schema_uri=aiplatform.schema.dataset.ioformat.image.single_label_classification,
)
training_job = aiplatform.AutoMLImageTrainingJob(
display_name="flowers_automl",
prediction_type="classification",
)
model = training_job.run(
dataset=dataset,
model_display_name="flowers_model",
budget_milli_node_hours=8000,
)Essa tabela compara frameworks populares de AutoML com base no nível de automação, estilo de interface e adequação para experimentação de código aberto, fluxos de trabalho com baixo código e implantação em escala empresarial.
|
Estrutura |
Categoria |
Nível do código |
Opções de interface |
Caso de uso principal |
|
TPOT |
Código aberto |
Alto |
API Python |
Descoberta e otimização automatizadas de pipeline para dados tabulares |
|
AutoGluon |
Código aberto |
Baixo |
API Python |
Modelos rápidos e de alta precisão, prontos para produção em todas as modalidades |
|
FLAML |
Código aberto |
Baixo |
API Python |
Ajuste de modelo econômico e consciente dos recursos |
|
AutoKeras |
Código aberto |
Médio |
API Python |
Pesquisa de arquitetura neural e automação de aprendizado profundo |
|
PyCaret |
Baixo código |
Muito baixo |
API Python, ferramentas GUI opcionais |
Experimentação rápida e fluxos de trabalho baseados em análises |
|
MLJAR Studio |
Sem código |
Nenhum |
Interface de usuário da Web, Python opcional |
Experimentação e comparação de modelos AutoML fáceis de usar para empresas |
|
H2O AutoML |
Híbrido |
Baixo |
Interface do usuário da Web (H2O Flow), Python, R |
AutoML escalável para grandes conjuntos de dados e implantação empresarial |
|
DataRobot |
Empresa |
Nenhum a baixo |
Interface do usuário da Web, API Python |
ML empresarial com governança, explicabilidade e MLOps |
|
SageMaker Autopilot |
Empresa |
Nenhum a baixo |
AWS Console, Python SDK |
AutoML nativo da AWS integrado com pipelines de produção |
|
Google Cloud AutoML |
Empresa |
Nenhum |
Console Vertex AI, SDK opcional |
Visão, PNL e AutoML tabular em infraestrutura GCP gerenciada |
As estruturas AutoML amadureceram e se tornaram ferramentas de nível de produção que dão suporte às equipes em todo o ciclo de vida do machine learning. Na prática, eles não se limitam a experimentação ou prototipagem.
Usei estruturas AutoML para participar de competições Kaggle, para construir pipelines completos de machine learning para projetos reais e até mesmo para me preparar e ter sucesso em entrevistas técnicas.
Do ponto de vista de um cientista de dados, o AutoML é uma maneira poderosa de criar um modelo de referência forte e imparcial com muito pouca sobrecarga.
Basta fornecer os dados, e essas estruturas cuidam da engenharia de recursos, seleção de modelos, ajuste de hiperparâmetros e avaliação. Isso permite que os profissionais se concentrem em entender o problema, validar suposições e melhorar os resultados, em vez de gastar muito tempo pesquisando e testando modelos do zero.
O AutoML não substitui a experiência. Em vez disso, acelera o fluxo de trabalho, oferecendo um ponto de partida confiável que pode ser melhorado de forma iterativa.
Construir o modelo é só o primeiro passo. Aprenda a implantar e monitorar seus modelos AutoML em produção com o curso curso Conceitos de MLOps.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Moez Ali
15 min
blog
Bekhruz Tuychiev
15 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev