Curso
Despliegue y ciclo de vida en MLOps
4 h
12K
El machine learning (AutoML) suele ser malinterpretado.
Muchas personas del sector tecnológico dan por sentado que las herramientas de AutoML solo están destinadas a usuarios empresariales o equipos sin conocimientos técnicos que no entienden cómo se entrenan o implementan los modelos de machine learning. Esta suposición es incorrecta.
En la práctica, los científicos de datos y los ingenieros de machine learning utilizan habitualmente marcos AutoML para reducir el tiempo de experimentación, mejorar el rendimiento de los modelos y automatizar las etapas repetitivas del ciclo de vida del machine learning.
Estas herramientas de AutoML admiten tareas como la ingeniería de características, la selección de modelos, el ajuste de hiperparámetros y la automatización integral de procesos, lo que permite a los equipos centrarse en trabajos de mayor valor.
En este artículo, exploraré algunos de los mejores marcos de AutoML disponibles en la actualidad, diseñados para usuarios con diferentes niveles de experiencia. Las herramientas se agrupan en tres categorías claras:
Para cada marco, destacamos sus características principales y proporcionamos código de ejemplo para que puedas empezar a utilizarlo inmediatamente.
AutoML hace referencia a las herramientas y sistemas que automatizan todo el proceso de desarrollo de modelos de machine learning, desde los datos sin procesar hasta un modelo entrenado y listo para implementar.
Los marcos AutoML se encargan de muchas de las tareas repetitivas y técnicas que conlleva la creación de modelos de machine learning, de modo que tanto los profesionales expertos como los usuarios con menos conocimientos técnicos puedan trabajar de forma más eficiente.
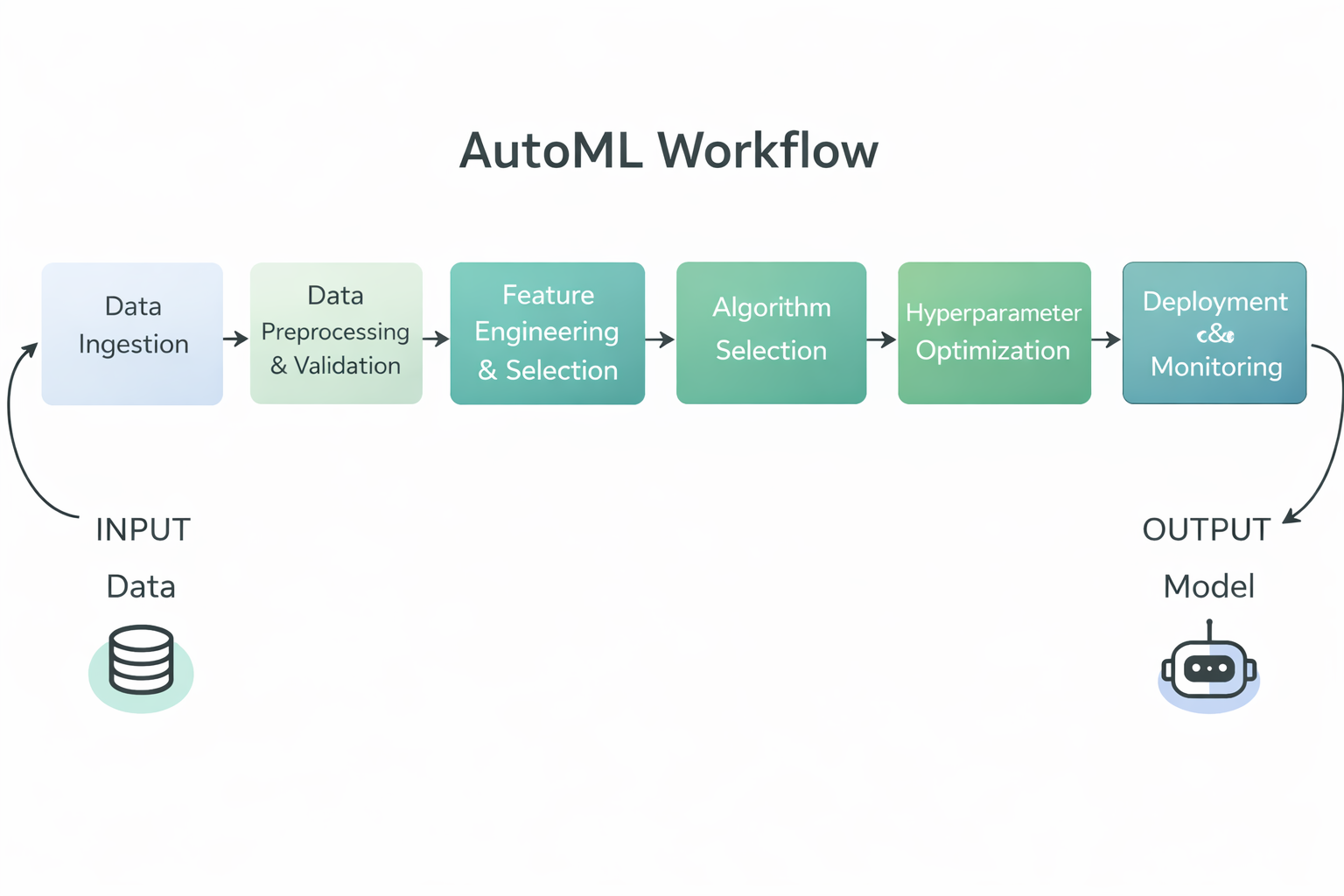
Diagrama del flujo de trabajo de AutoML
En concreto, los marcos de AutoML suelen automatizar los siguientes pasos del flujo de trabajo del machine learning:
Al automatizar estas tareas, los marcos de AutoML reducen el esfuerzo manual, mejoran la coherencia y la reproducibilidad, y permiten que tanto los equipos técnicos como los no técnicos puedan crear modelos de machine learning de alta calidad con mayor rapidez.
Los marcos AutoML de código abierto proporcionan herramientas flexibles, transparentes y fáciles de usar para los programadores, que permiten a los profesionales automatizar la creación de modelos sin perder el control total sobre los datos, los procesos y los flujos de trabajo de implementación.
TPOT es un marco AutoML de Python de código abierto que utiliza programación genética para descubrir y optimizar automáticamente procesos completos de machine learning.
Enmarca el diseño de tuberías como un problema de búsqueda evolutiva, explorando combinaciones de pasos de preprocesamiento, modelos e hiperparámetros para identificar soluciones de alto rendimiento.
TPOT es especialmente eficaz para tareas con datos tabulares en las que se necesita una experimentación rápida y bases sólidas, al tiempo que permite a los profesionales inspeccionar, exportar y reutilizar los procesos resultantes dentro de los flujos de trabajo estándar de scikit-learn.
Características principales:
Ejemplo de código:
Este ejemplo muestra la configuración mínima necesaria para utilizar TPOT. Se cargan las características y etiquetas del conjunto de datos, se inicializa un modelo de regresión lineal ( TPOTClassifier ) con la configuración predeterminada y el métodode ajuste activa el proceso de búsqueda automatizado.
Durante el entrenamiento, TPOT evalúa múltiples candidatas utilizando programación genética y selecciona un modelo de alto rendimiento basado en la métrica de evaluación especificada.
import tpot
X, y = load_my_data()
est = tpot.TPOTClassifier()
est.fit(X, y)AutoGluon es un marco AutoML de código abierto desarrollado por AWS AI que automatiza las tareas de machine learning centrándose en la alta precisión, el código mínimo y la compatibilidad con datos tabulares, de texto e imágenes.
Crea un conjunto diverso de modelos y utiliza la selección automatizada de modelos, el ajuste de hiperparámetros y el aprendizaje conjunto para ofrecer un sólido rendimiento predictivo en diferentes tipos de datos.
Características principales:
Ejemplo de código:
Este código carga los conjuntos de datos de entrenamiento y prueba como conjuntos de datos tabulares de AutoGluon. A continuación, crea un objeto TabularPredictor especificando la etiqueta de destino y llama a fit para entrenar AutoGluon con los datos de entrenamiento tabulares. Una vez completado el entrenamiento, utiliza el modelo entrenado para generar predicciones sobre el conjunto de pruebas.
from autogluon.tabular import TabularDataset, TabularPredictor
label = "signature"
train_data = TabularDataset("train.csv")
predictor = TabularPredictor(label=label).fit(train_data)
test_data = TabularDataset("test.csv")
predictions = predictor.predict(test_data.drop(columns=[label]))FLAML (Fast Lightweight AutoML) es una biblioteca AutoML de Python de código abierto desarrollada por Microsoft Research que está diseñada para encontrar modelos de machine learning de alta calidad de forma automática y eficiente, al tiempo que minimiza el coste computacional y el uso de recursos, lo que la hace ideal para entornos en los que la velocidad y la eficiencia son fundamentales.
Características principales:
Ejemplo de código:
Este ejemplo de código muestra cómo utilizar AutoML de FLAML. AutoML de FLAML para realizar una tarea de clasificación automatizada en el conjunto de datos Iris, especificando un presupuesto de tiempo y una métrica de evaluación antes del entrenamiento y, a continuación, utilizando el modelo entrenado para obtener probabilidades de predicción.
from flaml import AutoML
from sklearn.datasets import load_iris
X_train, y_train = load_iris(return_X_y=True)
automl = AutoML()
automl_settings = {
"time_budget": 1,
"metric": "accuracy",
"task": "classification",
"log_file_name": "iris.log",
}
automl.fit(X_train=X_train, y_train=y_train, **automl_settings)
print(automl.predict_proba(X_train))AutoKeras es una biblioteca AutoML de código abierto basada en marco de aprendizaje profundo Keras , que busca y entrena automáticamente redes neuronales de alta calidad para una amplia gama de tareas, incluyendo datos estructurados, imágenes y texto, con un mínimo de codificación.
Utiliza una búsqueda eficiente de arquitectura neuronal para encontrar arquitecturas de modelos e hiperparámetros adecuados, lo que hace que el aprendizaje profundo sea más accesible tanto para principiantes como para profesionales con experiencia.
Características principales:
StructuredDataClassifier, simplifican el entrenamiento de modelos complejos de aprendizaje profundo con solo unas pocas líneas de código.Ejemplo de código:
Este ejemplo de código importa las bibliotecas necesarias y carga los conjuntos de datos de entrenamiento y prueba desde las URL proporcionadas. Separa las características y las etiquetas, y luego crea un objeto ak.StructuredDataClassifier que busca automáticamente un modelo de aprendizaje profundo sólido. El modelo se entrena durante un número determinado de ensayos y épocas, y se imprime el resultado final de la evaluación en el conjunto de pruebas.
import keras
import pandas as pd
import autokeras as ak
TRAIN_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/train.csv"
TEST_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/eval.csv"
train_file_path = keras.utils.get_file("train.csv", TRAIN_DATA_URL)
test_file_path = keras.utils.get_file("eval.csv", TEST_DATA_URL)
train_df = pd.read_csv(train_file_path)
test_df = pd.read_csv(test_file_path)
y_train = train_df["survived"].values
x_train = train_df.drop("survived", axis=1).values
y_test = test_df["survived"].values
x_test = test_df.drop("survived", axis=1).values
clf = ak.StructuredDataClassifier(overwrite=True, max_trials=3)
clf.fit(x_train, y_train, epochs=10)
print(clf.evaluate(x_test, y_test))Las plataformas AutoML sin código y con poco código simplifican el desarrollo de modelos al abstraer flujos de trabajo complejos, lo que permite una rápida experimentación e implementación tanto para los equipos técnicos como para los usuarios empresariales.
PyCaret es una biblioteca de machine learning de código abierto y bajo código en Python que automatiza el flujo de trabajo de machine learning de extremo a extremo para tareas como clasificación, regresión, agrupación, detección de anomalías y predicción de series temporales, lo que permite la creación rápida de prototipos con solo unas pocas líneas de código, al tiempo que admite una interfaz gráfica de usuario para aquellos que prefieren experiencias de bajo código o de clic.
Características principales:
compare_models » entrena y evalúa muchos modelos mediante validación cruzada y proporciona una tabla de clasificación del rendimiento para ayudar a elegir el mejor modelo.Ejemplo de código:
Este fragmento de código muestra cómo cargar un conjunto de datos integrado, inicializar el módulo de regresión PyCaret con setup (que preprocesa los datos e inicializa el entorno de aprendizaje automático) y, a continuación, utilizar compare_models para entrenar, evaluar y clasificar automáticamente una variedad de modelos de regresión, devolviendo el que mejor rendimiento tenga.
from pycaret.datasets import get_data
from pycaret.regression import *
data = get_data("insurance")
s = setup(data, target="charges", session_id=123)
best_model = compare_models()MLJAR Studio es un entorno AutoML sin código y con poco código que te permite entrenar y comparar modelos de machine learning a través de una interfaz guiada, al tiempo que ofrece un flujo de trabajo Python opcional a través del código abierto mljar-supervised .
Características principales:
Ejemplo de código:
No necesitas código para utilizar MLJAR Studio, ya que puedes ejecutar AutoML a través de la interfaz gráfica de usuario. Sin embargo, el código siguiente muestra el enfoque programático opcional utilizando la biblioteca mljar-supervised. Carga un conjunto de datos, lo divide en características y objetivos, ejecuta el entrenamiento de AutoML y, a continuación, genera predicciones utilizando el modelo entrenado.
import pandas as pd
from supervised.automl import AutoML
df = pd.read_csv(
"https://raw.githubusercontent.com/pplonski/datasets-for-start/master/adult/data.csv",
skipinitialspace=True,
)
X = df[df.columns[:-1]]
y = df["income"]
automl = AutoML(results_path="mljar_results")
automl.fit(X, y)
predictions = automl.predict(X)H2O AutoML es una función AutoML de código abierto dentro de la plataforma H2O que proporciona machine learning escalable y automatizado con soporte para Python, R y una interfaz gráfica sin código llamada H2O Flow, lo que permite tanto a usuarios técnicos como no técnicos crear, evaluar y seleccionar modelos con un mínimo de codificación. Los usuarios pueden trabajar a través de la interfaz web Flow para importar datos, ejecutar experimentos AutoML, explorar resultados y exportar modelos sin necesidad de escribir código.
Características principales:
Ejemplo de código:
Este ejemplo muestra cómo utilizar H2O AutoML a través de Python. Inicializa el entorno H2O, importa conjuntos de datos de entrenamiento y prueba, especifica columnas de características y objetivos, inicia una ejecución de AutoML con un límite en el número de modelos y, a continuación, muestra una tabla de clasificación con los modelos de mejor rendimiento.
Nota: Aunque este es el enfoque programático, las mismas tareas se pueden completar a través de la interfaz web de H2O Flow sin necesidad de escribir código.
import h2o
from h2o.automl import H2OAutoML
h2o.init()
train = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/smalldata/higgs/higgs_train_10k.csv"
)
test = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/smalldata/higgs/higgs_test_5k.csv"
)
x = train.columns
y = "response"
x.remove(y)
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
aml = H2OAutoML(max_models=20, seed=1)
aml.train(x=x, y=y, training_frame=train)
aml.leaderboardLas soluciones AutoML de nivel empresarial proporcionan plataformas de machine learning escalables, seguras y reguladas, diseñadas para la implementación en producción, el cumplimiento normativo y el uso operativo a gran escala.
DataRobot es una plataforma AutoML sin código y con poco código de nivel empresarial que permite a los usuarios empresariales, analistas y equipos de datos crear, implementar y gestionar modelos de machine learning sin necesidad de realizar una programación exhaustiva.
La plataforma automatiza todo el ciclo de vida del machine learning, desde la ingesta de datos y la ingeniería de características hasta el entrenamiento, la implementación y la supervisión de modelos, al tiempo que proporciona una sólida gobernanza, explicabilidad y controles operativos necesarios en entornos regulados.
Características principales:
Ejemplo de código:
Aunque DataRobot se utiliza principalmente a través de su interfaz sin código, también proporciona una API de Python para el control programático y la automatización. El siguiente ejemplo muestra cómo autenticarse en DataRobot, crear un proyecto a partir de un conjunto de datos y ejecutar AutoPilot para entrenar y evaluar modelos automáticamente.
import datarobot as dr
dr.Client(config_path="./drconfig.yaml")
dataset = dr.Dataset.create_from_file("auto-mpg.csv")
project = dr.Project.create_from_dataset(
dataset.id,
project_name="Auto MPG Project"
)
from datarobot import AUTOPILOT_MODE
project.analyze_and_model(
target="mpg",
mode=AUTOPILOT_MODE.QUICK
)
project.wait_for_autopilot()Amazon SageMaker Autopilot es una solución AutoML totalmente gestionada de AWS que permite a los usuarios automatizar el flujo de trabajo de machine learning de principio a fin sin sin código o con poco código, especialmente a través de una interfaz web en Amazon SageMaker Canvas o SageMaker Studio.
Los usuarios pueden importar datos, configurar la variable objetivo, evaluar modelos candidatos e implementar modelos con unos pocos clics en la consola, mientras que el SDK y las API de Python siguen estando disponibles como una forma opcional de hacer que los experimentos sean reproducibles o de integrarlos con otros sistemas.
Características principales:
Ejemplo de código:
El código siguiente muestra cómo ejecutar Amazon SageMaker Autopilot mediante programación con el SDK de Python. Este enfoque es opcional y puede utilizarse para reproducir resultados o integrarse en procesos automatizados.
from sagemaker import AutoML, AutoMLInput
automl = AutoML(
role=execution_role,
target_attribute_name=target_attribute_name,
sagemaker_session=pipeline_session,
total_job_runtime_in_seconds=3600,
mode="ENSEMBLING",
)
automl.fit(
inputs=[
AutoMLInput(
inputs=s3_train_val,
target_attribute_name=target_attribute_name,
channel_type="training",
)
]
)Google Cloud AutoML forma parte de Vertex AI, la plataforma unificada de machine learning de Google Cloud que permite a los usuarios crear, entrenar, evaluar e implementar modelos de alta calidad utilizando una infraestructura totalmente gestionada.
Vertex AI AutoML admite datos tabulares, procesamiento del lenguaje natural, visión artificial y tareas de vídeo, y está diseñado para ser accesible a través de una interfaz web sin código en Google Cloud Console.
Todos los pasos fundamentales, como la creación del conjunto de datos, la selección de tareas, el entrenamiento, la evaluación y la implementación, pueden completarse a través de la interfaz de usuario sin necesidad de escribir código.
Características principales:
Ejemplo de código:
Aunque Vertex AI AutoML está diseñado principalmente para flujos de trabajo sin código, el SDK de Python se puede utilizar para que los experimentos sean reproducibles o para integrar el entrenamiento de AutoML en canalizaciones automatizadas.
El siguiente fragmento breve inicializa un proyecto de Vertex AI, crea un conjunto de datos de imágenes a partir de un índice CSV almacenado en Cloud Storage y lanza un trabajo de entrenamiento de imágenes de AutoML.
from google.cloud import aiplatform
aiplatform.init(
project="YOUR_PROJECT_ID",
location="us-central1",
staging_bucket="gs://YOUR_BUCKET",
)
dataset = aiplatform.ImageDataset.create(
display_name="flowers",
gcs_source=["gs://cloud-samples-data/ai-platform/flowers/flowers.csv"],
import_schema_uri=aiplatform.schema.dataset.ioformat.image.single_label_classification,
)
training_job = aiplatform.AutoMLImageTrainingJob(
display_name="flowers_automl",
prediction_type="classification",
)
model = training_job.run(
dataset=dataset,
model_display_name="flowers_model",
budget_milli_node_hours=8000,
)Esta tabla compara los marcos AutoML más populares en función de su nivel de automatización, estilo de interfaz e idoneidad para la experimentación con código abierto, flujos de trabajo con poco código y despliegue a escala empresarial.
|
Marco |
Categoría |
Nivel de código |
Opciones de interfaz |
Caso de uso principal |
|
TPOT |
Código abierto |
Alto |
API de Python |
Detección y optimización automatizadas de procesos para datos tabulares |
|
AutoGluon |
Código abierto |
Bajo |
API de Python |
Modelos rápidos y de alta precisión listos para la producción en todas las modalidades. |
|
FLAML |
Código abierto |
Bajo |
API de Python |
Ajuste de modelos rentable y consciente de los recursos |
|
AutoKeras |
Código abierto |
Medio |
API de Python |
Búsqueda de arquitectura neuronal y automatización del aprendizaje profundo |
|
PyCaret |
Código bajo |
Muy bajo |
API de Python, herramientas GUI opcionales |
Experimentación rápida y flujos de trabajo basados en análisis |
|
MLJAR Studio |
Sin código |
Ninguno |
Interfaz de usuario web, Python opcional |
Experimentación y comparación de modelos AutoML adaptadas a las necesidades empresariales |
|
H2O AutoML |
Híbrido |
Bajo |
Interfaz de usuario web (H2O Flow), Python, R |
AutoML escalable para grandes conjuntos de datos e implementación empresarial |
|
DataRobot |
Empresa |
Ninguno a bajo |
Interfaz de usuario web, API de Python |
ML empresarial con gobernanza, explicabilidad y MLOps |
|
SageMaker Autopilot |
Empresa |
Ninguno a bajo |
Consola de AWS, SDK de Python |
AutoML nativo de AWS integrado con los procesos de producción |
|
Google Cloud AutoML |
Empresa |
Ninguno |
Consola de Vertex AI, SDK opcional |
Visión, PNL y AutoML tabular en infraestructura GCP gestionada |
Los marcos de AutoML han madurado hasta convertirse en herramientas aptas para la producción que dan soporte a los equipos a lo largo de todo el ciclo de vida del machine learning. En la práctica, no se limitan a la experimentación o la creación de prototipos.
He utilizado los marcos de AutoML para participar en concursos de Kaggle, crear procesos completos de machine learning de principio a fin para proyectos reales e incluso prepararme y superar entrevistas técnicas.
Desde la perspectiva de un científico de datos, AutoML es una forma eficaz de establecer un modelo de referencia sólido e imparcial con muy pocos gastos generales.
Con solo proporcionar los datos, estos marcos se encargan de la ingeniería de características, la selección de modelos, el ajuste de hiperparámetros y la evaluación. Esto permite a los profesionales centrarse en comprender el problema, validar hipótesis y mejorar los resultados, en lugar de dedicar un tiempo excesivo a investigar y probar modelos desde cero.
AutoML no sustituye a la experiencia. En cambio, acelera el flujo de trabajo al proporcionar un punto de partida fiable que puede mejorarse de forma iterativa.
Construir el modelo es solo el primer paso. Aprende a implementar y supervisar tus modelos AutoML en producción con el curso Conceptos de MLOps.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Yuliya Melnik
15 min
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
8 min
blog
Natassha Selvaraj
15 min
Tutorial
Moez Ali
Tutorial
Bekhruz Tuychiev