
Kurs
MLOps-Bereitstellung und Lebenszyklus
4 Std.
12.1K
Automatisiertes maschinelles Lernen (AutoML) wird oft falsch verstanden.
Viele Leute in der Tech-Branche denken, dass AutoML-Tools nur für Geschäftsleute oder nicht-technische Teams gedacht sind, die nicht verstehen, , wie Machine-Learning-Modelle trainiert oder eingesetzt werden. Diese Annahme ist falsch.
In der Praxis nutzen Datenwissenschaftler und Machine-Learning-Ingenieure regelmäßig AutoML-Frameworks, um die Experimentierzeit zu verkürzen, die Modellleistung zu verbessern und sich wiederholende Phasen des Machine-Learning-Lebenszyklus zu automatisieren.
Diese AutoML-Tools helfen bei Sachen wie Feature Engineering, Modellauswahl, Hyperparameter-Optimierung und der Automatisierung der ganzen Pipeline, sodass sich die Teams auf wichtigere Aufgaben konzentrieren können.
In diesem Artikel schaue ich mir ein paar der besten AutoML-Frameworks an, die es gerade gibt und die für Leute mit unterschiedlichen Kenntnissen gemacht sind. Die Tools sind in drei übersichtliche Kategorien eingeteilt:
Für jedes Framework zeigen wir die wichtigsten Funktionen und geben Beispielcode, damit du sofort loslegen kannst.
AutoML sind Tools und Systeme, die den ganzen Prozess der Entwicklung von Machine-Learning-Modellen automatisieren, von den Rohdaten bis hin zu einem trainierten, einsatzbereiten Modell.
AutoML-Frameworks übernehmen viele der sich wiederholenden und technischen Aufgaben beim Erstellen von Machine-Learning-Modellen, sodass sowohl erfahrene Praktiker als auch weniger technisch versierte Nutzer effizienter arbeiten können.
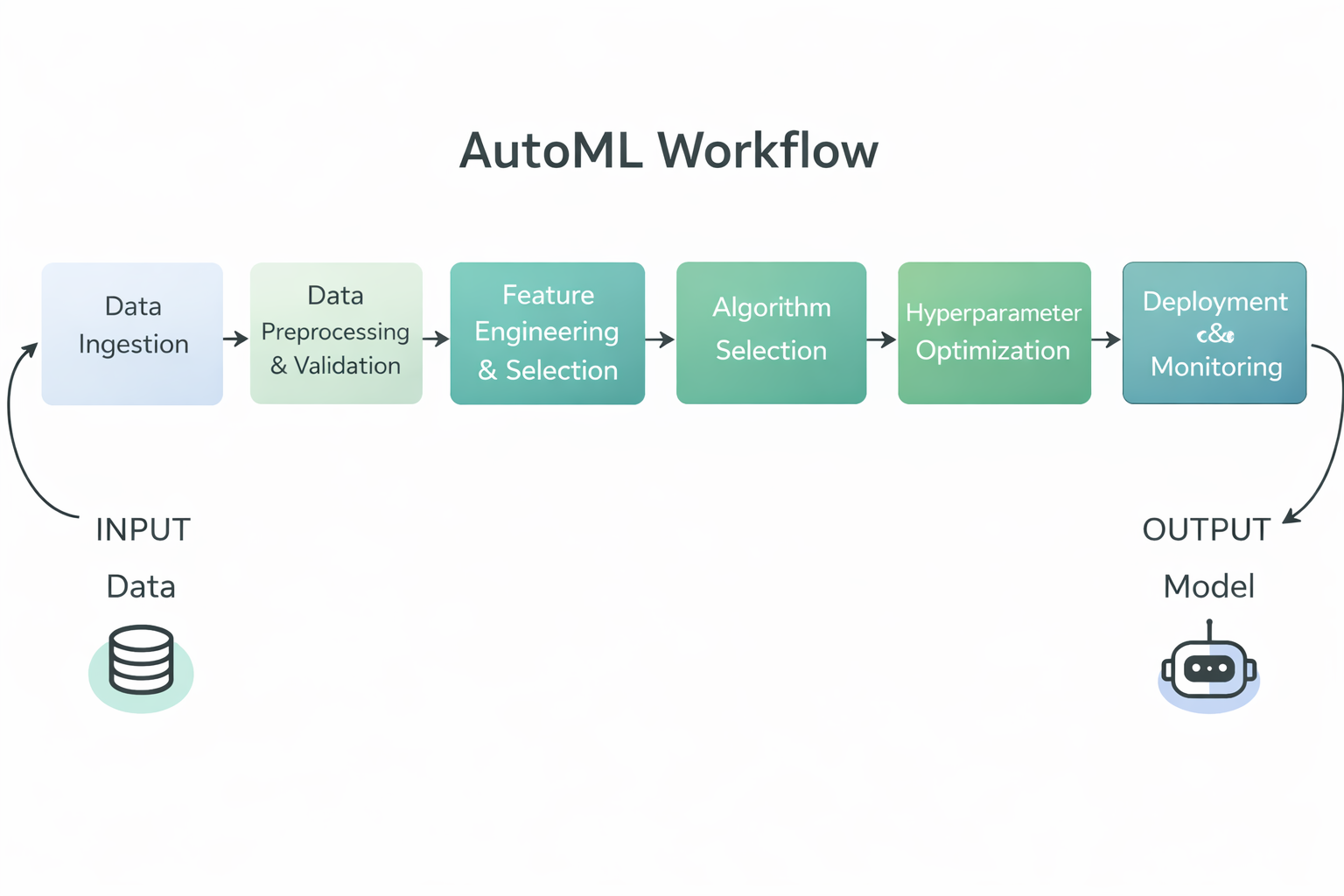
AutoML-Workflow-Diagramm
Genauer gesagt, automatisieren AutoML-Frameworks normalerweise die folgenden Schritte im Machine-Learning-Workflow:
Durch die Automatisierung dieser Aufgaben sparen AutoML-Frameworks manuelle Arbeit, machen die Ergebnisse konsistenter und besser reproduzierbar und helfen sowohl Technikern als auch Nicht-Technikern, schnellere und hochwertigere Machine-Learning-Modelle zu entwickeln.
Open-Source-AutoML-Frameworks bieten flexible, transparente und entwicklerfreundliche Tools, mit denen man die Modellerstellung automatisieren kann, während man die volle Kontrolle über Daten, Pipelines und Bereitstellungsabläufe behält.
TPOT ist ein Open-Source-Python-AutoML-Framework, das genetische Programmierung nutzt, um komplette Machine-Learning-Pipelines automatisch zu finden und zu optimieren.
Es betrachtet das Pipeline-Design als ein evolutionäres Suchproblem und untersucht Kombinationen aus Vorverarbeitungsschritten, Modellen und Hyperparametern, um leistungsstarke Lösungen zu finden.
TPOT ist besonders gut für Aufgaben mit tabellarischen Daten, wo man schnell experimentieren und starke Basiswerte brauchen kann. Dabei kann man die resultierenden Pipelines trotzdem in den normalen scikit-learn-Workflows checken, exportieren und wiederverwenden.
Wichtigste Funktionen:
Code-Beispiel:
Dieses Beispiel zeigt, wie du TPOT mit minimalem Aufwand einrichten kannst. Die Datensatzmerkmale und Beschriftungen werden geladen, ein „ TPOTClassifier ” wird mit den Standardeinstellungen gestartet und die Anpassungsmethode löst den automatischen Suchprozess aus.
Während des Trainings checkt TPOT mehrere Pipeline-Kandidaten mit genetischer Programmierung und sucht sich ein leistungsstarkes Modell nach den vorgegebenen Bewertungskriterien aus.
import tpot
X, y = load_my_data()
est = tpot.TPOTClassifier()
est.fit(X, y)AutoGluon ist ein Open-Source-Python-AutoML-Framework, das von AWS AI entwickelt wurde und Machine-Learning-Aufgaben automatisiert. Es legt Wert auf hohe Genauigkeit, minimalen Code und unterstützt Tabellen-, Text- und Bilddaten.
Es erstellt eine Vielzahl unterschiedlicher Modelle und nutzt automatisierte Modellauswahl, Hyperparameter-Optimierung und Ensemble-Lernen, um eine starke Vorhersageleistung für verschiedene Datentypen zu erzielen.
Wichtigste Funktionen:
Code-Beispiel:
Dieser Code lädt die Trainings- und Testdatensätze als AutoGluon-Tabellendatensätze. Dann wird ein „ TabularPredictor “-Objekt erstellt, das das Ziel-Label angibt, und „fit “ aufgerufen , um AutoGluon anhand der tabellarischen Trainingsdaten zu trainieren. Nach dem Training nutzt es das trainierte Modell, um Vorhersagen für den Testsatz zu machen.
from autogluon.tabular import TabularDataset, TabularPredictor
label = "signature"
train_data = TabularDataset("train.csv")
predictor = TabularPredictor(label=label).fit(train_data)
test_data = TabularDataset("test.csv")
predictions = predictor.predict(test_data.drop(columns=[label]))FLAML (Fast Lightweight AutoML) ist eine von Microsoft Research entwickelte Open-Source-Python-AutoML-Bibliothek, die darauf ausgelegt ist, automatisch und effizient hochwertige Machine-Learning-Modelle zu finden und dabei die Rechenkosten und den Ressourcenverbrauch zu minimieren. Damit eignet sie sich ideal für Umgebungen, in denen Geschwindigkeit und Effizienz am wichtigsten sind.
Wichtigste Funktionen:
Code-Beispiel:
Dieses Codebeispiel zeigt, wie man FLAMLs AutoML verwendet wird, um eine automatisierte Klassifizierungsaufgabe für den Iris-Datensatz durchzuführen, wobei vor dem Training ein Zeitbudget und eine Bewertungsmetrik festgelegt werden und anschließend das trainierte Modell verwendet wird, um Vorhersagewahrscheinlichkeiten zu erhalten.
from flaml import AutoML
from sklearn.datasets import load_iris
X_train, y_train = load_iris(return_X_y=True)
automl = AutoML()
automl_settings = {
"time_budget": 1,
"metric": "accuracy",
"task": "classification",
"log_file_name": "iris.log",
}
automl.fit(X_train=X_train, y_train=y_train, **automl_settings)
print(automl.predict_proba(X_train))AutoKeras ist eine Open-Source-AutoML-Bibliothek, die auf dem Keras Deep-Learning-Framework basiert und automatisch hochwertige neuronale Netze für viele Aufgaben sucht und trainiert, wie strukturierte Daten, Bilder und Text, und das mit minimalem Programmieraufwand.
Es nutzt eine effiziente neuronale Architektursuche, um passende Modellarchitekturen und Hyperparameter zu finden, was Deep Learning sowohl für Anfänger als auch für erfahrene Anwender zugänglicher macht.
Wichtigste Funktionen:
StructuredDataClassifier machen das Training komplexer Deep-Learning-Modelle mit nur wenigen Zeilen Code einfacher.Code-Beispiel:
Dieses Code-Beispiel holt die benötigten Bibliotheken rein und lädt Trainings- und Testdatensätze von den angegebenen URLs. Es trennt Features und Labels und erstellt dann ein „ ak.StructuredDataClassifier “-Objekt, das automatisch nach einem starken Deep-Learning-Modell sucht. Das Modell wird für eine bestimmte Anzahl von Versuchen und Epochen trainiert, und das endgültige Bewertungsergebnis für den Testsatz wird ausgegeben.
import keras
import pandas as pd
import autokeras as ak
TRAIN_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/train.csv"
TEST_DATA_URL = "https://storage.googleapis.com/tf-datasets/titanic/eval.csv"
train_file_path = keras.utils.get_file("train.csv", TRAIN_DATA_URL)
test_file_path = keras.utils.get_file("eval.csv", TEST_DATA_URL)
train_df = pd.read_csv(train_file_path)
test_df = pd.read_csv(test_file_path)
y_train = train_df["survived"].values
x_train = train_df.drop("survived", axis=1).values
y_test = test_df["survived"].values
x_test = test_df.drop("survived", axis=1).values
clf = ak.StructuredDataClassifier(overwrite=True, max_trials=3)
clf.fit(x_train, y_train, epochs=10)
print(clf.evaluate(x_test, y_test))No-Code- und Low-Code-AutoML-Plattformen machen die Modellentwicklung einfacher, indem sie komplizierte Abläufe vereinfachen und so schnelles Testen und Bereitstellen für technische Teams und Geschäftsanwender ermöglichen.
PyCaret ist eine Open-Source-Bibliothek für maschinelles Lernen in Python, die den kompletten Workflow für Aufgaben wie Klassifizierung, Regression, Clustering, Anomalieerkennung und Zeitreihenprognosen automatisiert. Damit kann man mit nur wenigen Zeilen Code schnell Prototypen erstellen und es gibt auch eine grafische Benutzeroberfläche für alle, die Low-Code- oder Click-Through-Erfahrungen bevorzugen.
Wichtigste Funktionen:
compare_models ” trainiert und bewertet viele Modelle mithilfe von Kreuzvalidierung und stellt eine Rangliste der Leistung bereit, um bei der Auswahl des besten Modells zu helfen.Code-Beispiel:
Dieser Codeausschnitt zeigt, wie man einen integrierten Datensatz lädt, das PyCaret-Regressionsmodul mit „ setup ” initialisiert (was die Daten vorverarbeitet und die ML-Umgebung initialisiert) und dann mit „compare_models” automatisch verschiedene Regressionsmodelle trainiert, bewertet und einstuft, um dann das Modell mit der besten Leistung zurückzugeben.
from pycaret.datasets import get_data
from pycaret.regression import *
data = get_data("insurance")
s = setup(data, target="charges", session_id=123)
best_model = compare_models()MLJAR Studio ist eine No-Code- und Low-Code-AutoML-Umgebung, mit der du Machine-Learning-Modelle über eine geführte Oberfläche trainieren und vergleichen kannst. Außerdem gibt's einen optionalen Python-Workflow über das Open-Source-Projekt mljar-supervised .
Wichtigste Funktionen:
Code-Beispiel:
Du brauchst keinen Code, um MLJAR Studio zu nutzen, weil du AutoML über die Benutzeroberfläche ausführen kannst. Der Code unten zeigt aber den optionalen programmatischen Ansatz mit der Bibliothek „ mljar-supervised “. Es lädt einen Datensatz, teilt ihn in Merkmale und Ziele auf, führt das AutoML-Training durch und erstellt dann Vorhersagen mit dem trainierten Modell.
import pandas as pd
from supervised.automl import AutoML
df = pd.read_csv(
"https://raw.githubusercontent.com/pplonski/datasets-for-start/master/adult/data.csv",
skipinitialspace=True,
)
X = df[df.columns[:-1]]
y = df["income"]
automl = AutoML(results_path="mljar_results")
automl.fit(X, y)
predictions = automl.predict(X)H2O AutoML ist eine Open-Source-AutoML-Funktion innerhalb der H2O-Plattform, die skalierbares, automatisiertes maschinelles Lernen mit Unterstützung für Python, R und einer no-code-Grafikschnittstelle namens H2O Flow bietet , sodass sowohl technische als auch nicht-technische Benutzer mit minimalem Programmieraufwand Modelle erstellen, bewerten und auswählen können. Benutzer können über die webbasierte Flow-Oberfläche Daten importieren, AutoML-Experimente durchführen, Ergebnisse auswerten und Modelle exportieren, ohne Code schreiben zu müssen.
Wichtigste Funktionen:
Code-Beispiel:
Dieses Beispiel zeigt, wie man H2O AutoML mit Python benutzt. Es macht die H2O-Umgebung startklar, holt Trainings- und Testdatensätze rein, legt Feature- und Zielspalten fest, startet einen AutoML-Lauf mit einer Begrenzung der Anzahl der Modelle und zeigt dann eine Rangliste mit den leistungsstärksten Modellen an.
Anmerkung: Das ist zwar der programmatische Ansatz, aber die gleichen Aufgaben kannst du auch über die H2O Flow-Weboberfläche erledigen, ohne Code schreiben zu müssen.
import h2o
from h2o.automl import H2OAutoML
h2o.init()
train = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/smalldata/higgs/higgs_train_10k.csv"
)
test = h2o.import_file(
"https://s3.amazonaws.com/h2o-public-test-data/smalldata/higgs/higgs_test_5k.csv"
)
x = train.columns
y = "response"
x.remove(y)
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
aml = H2OAutoML(max_models=20, seed=1)
aml.train(x=x, y=y, training_frame=train)
aml.leaderboardAutoML-Lösungen für Unternehmen bieten skalierbare, sichere und kontrollierte Machine-Learning-Plattformen, die für den Einsatz in der Produktion, die Einhaltung von Vorschriften und den großflächigen operativen Einsatz entwickelt wurden.
DataRobot ist eine AutoML-Plattform für Unternehmen, die ohne oder mit wenig Programmieraufwand auskommt. Damit können Geschäftsleute, Analysten und Datenteams Machine-Learning-Modelle erstellen, einsetzen und verwalten, ohne viel programmieren zu müssen.
Die Plattform macht den ganzen Machine-Learning-Lebenszyklus automatisch, von der Datenerfassung und Feature Engineering bis hin zum Modelltraining, der Bereitstellung und Überwachung. Dabei bietet sie die starke Governance, Erklärbarkeit und Betriebskontrollen, die in regulierten Umgebungen gebraucht werden.
Wichtigste Funktionen:
Code-Beispiel:
Obwohl DataRobot hauptsächlich über seine No-Code-Oberfläche genutzt wird, gibt's auch eine Python-API für die programmatische Steuerung und Automatisierung. Das folgende Beispiel zeigt, wie du dich bei DataRobot anmeldest, ein Projekt aus einem Datensatz erstellst und AutoPilot ausführst, um Modelle automatisch zu trainieren und zu bewerten.
import datarobot as dr
dr.Client(config_path="./drconfig.yaml")
dataset = dr.Dataset.create_from_file("auto-mpg.csv")
project = dr.Project.create_from_dataset(
dataset.id,
project_name="Auto MPG Project"
)
from datarobot import AUTOPILOT_MODE
project.analyze_and_model(
target="mpg",
mode=AUTOPILOT_MODE.QUICK
)
project.wait_for_autopilot()Amazon SageMaker Autopilot ist eine komplett verwaltete AutoML-Lösung von AWS, mit der man den kompletten Machine-Learning-Workflow ohne ohne oder mit nur wenig Programmierung, vor allem über eine Webschnittstelle in Amazon SageMaker Canvas oder SageMaker Studio.
Benutzer können mit wenigen Klicks in der Konsole Daten importieren, die Zielvariable konfigurieren, Kandidatenmodelle bewerten und Modelle bereitstellen, während das Python SDK und die APIs weiterhin als optionale Möglichkeit zur Verfügung stehen, um Experimente reproduzierbar zu machen oder in andere Systeme zu integrieren.
Wichtigste Funktionen:
Code-Beispiel:
Der Code unten zeigt, wie man Amazon SageMaker Autopilot mit dem Python SDK programmiert ausführt. Dieser Ansatz ist optional und kann verwendet werden, um Ergebnisse zu reproduzieren oder in automatisierte Pipelines zu integrieren.
from sagemaker import AutoML, AutoMLInput
automl = AutoML(
role=execution_role,
target_attribute_name=target_attribute_name,
sagemaker_session=pipeline_session,
total_job_runtime_in_seconds=3600,
mode="ENSEMBLING",
)
automl.fit(
inputs=[
AutoMLInput(
inputs=s3_train_val,
target_attribute_name=target_attribute_name,
channel_type="training",
)
]
)Google Cloud AutoML ist Teil von Vertex AI, der einheitlichen Machine-Learning-Plattform von Google Cloud, mit der Nutzer hochwertige Modelle mithilfe einer vollständig verwalteten Infrastruktur erstellen, trainieren, bewerten und bereitstellen können.
Vertex AI AutoML kann mit tabellarischen Daten, natürlicher Sprachverarbeitung, Computer Vision und Videoaufgaben umgehen und ist so gemacht, dass man es über eine Web-Oberfläche ohne Programmierung in der Google Cloud Console nutzen kann.
Alle wichtigen Schritte, wie zum Beispiel das Erstellen von Datensätzen, die Auswahl von Aufgaben, das Training, die Bewertung und die Bereitstellung, kannst du über die Benutzeroberfläche erledigen, ohne Code schreiben zu müssen.
Wichtigste Funktionen:
Code-Beispiel:
Obwohl Vertex AI AutoML eigentlich für No-Code-Workflows gedacht ist, kann man das Python SDK nutzen, um Experimente reproduzierbar zu machen oder das AutoML-Training in automatisierte Pipelines einzubauen.
Der folgende kurze Code-Ausschnitt startet ein Vertex AI-Projekt, macht einen Bilddatensatz aus einem CSV-Index, der in Cloud Storage gespeichert ist, und startet einen AutoML-Bildtrainingsjob.
from google.cloud import aiplatform
aiplatform.init(
project="YOUR_PROJECT_ID",
location="us-central1",
staging_bucket="gs://YOUR_BUCKET",
)
dataset = aiplatform.ImageDataset.create(
display_name="flowers",
gcs_source=["gs://cloud-samples-data/ai-platform/flowers/flowers.csv"],
import_schema_uri=aiplatform.schema.dataset.ioformat.image.single_label_classification,
)
training_job = aiplatform.AutoMLImageTrainingJob(
display_name="flowers_automl",
prediction_type="classification",
)
model = training_job.run(
dataset=dataset,
model_display_name="flowers_model",
budget_milli_node_hours=8000,
)Diese Tabelle vergleicht beliebte AutoML-Frameworks nach ihrem Automatisierungsgrad, ihrem Schnittstellenstil und ihrer Eignung für Open-Source-Experimente, Low-Code-Workflows und den Einsatz in Unternehmen.
|
Rahmen |
Kategorie |
Code-Ebene |
Schnittstellenoptionen |
Hauptanwendungsfall |
|
TPOT |
Open Source |
Hoch |
Python API |
Automatische Erkennung und Optimierung von Pipelines für tabellarische Daten |
|
AutoGluon |
Open Source |
Niedrig |
Python API |
Schnelle, supergenaue Modelle für die Produktion, die für alle Modalitäten geeignet sind |
|
FLAML |
Open Source |
Niedrig |
Python API |
Kosteneffiziente und ressourcenbewusste Modelloptimierung |
|
AutoKeras |
Open Source |
Mittel |
Python API |
Suche nach neuronalen Architekturen und Automatisierung des Deep Learning |
|
PyCaret |
Low Code |
Sehr niedrig |
Python-API, optionale GUI-Tools |
Schnelle Experimente und datengesteuerte Arbeitsabläufe |
|
MLJAR Studio |
Kein Code |
Keiner |
Web-Benutzeroberfläche, Python optional |
Einfaches Experimentieren mit AutoML und Modellvergleich für Unternehmen |
|
H2O AutoML |
Hybrid |
Niedrig |
Web-Benutzeroberfläche (H2O Flow), Python, R |
Skalierbares AutoML für große Datensätze und den Einsatz in Unternehmen |
|
DataRobot |
Unternehmen |
Keine bis gering |
Web-Benutzeroberfläche, Python-API |
Enterprise ML mit Governance, Erklärbarkeit und MLOps |
|
SageMaker Autopilot |
Unternehmen |
Keine bis gering |
AWS-Konsole, Python SDK |
AWS-eigene AutoML, eingebaut in Produktionspipelines |
|
Google Cloud AutoML |
Unternehmen |
Keiner |
Vertex AI-Konsole, optionales SDK |
Vision, NLP und tabellarisches AutoML auf verwalteter GCP-Infrastruktur |
AutoML-Frameworks sind mittlerweile ausgereifte Tools, die Teams während des gesamten Machine-Learning-Lebenszyklus unterstützen. In der Praxis sind sie nicht nur auf Experimente oder Prototypen beschränkt.
Ich habe AutoML-Frameworks benutzt, um bei Kaggle-Wettbewerben mitzumachen, komplette End-to-End-Pipelines für maschinelles Lernen für echte Projekte zu bauen und mich sogar auf technische Vorstellungsgespräche vorzubereiten und diese erfolgreich zu meistern.
Aus der Sicht eines Datenwissenschaftlers ist AutoML eine super Möglichkeit, um mit wenig Aufwand ein starkes und unvoreingenommenes Basismodell zu erstellen.
Man muss nur die Daten bereitstellen, und diese Frameworks kümmern sich um Feature Engineering, Modellauswahl, Hyperparameter-Tuning und Auswertung. So können sich die Leute darauf konzentrieren, das Problem zu verstehen, Annahmen zu überprüfen und die Ergebnisse zu verbessern, anstatt viel Zeit damit zu verbringen, Modelle von Grund auf neu zu erforschen und zu testen.
AutoML ersetzt nicht das Fachwissen. Stattdessen macht es den Arbeitsablauf schneller, indem es einen zuverlässigen Ausgangspunkt bietet, der immer weiter verbessert werden kann.
Das Modell zu bauen ist nur der erste Schritt. Lerne im Kurs „MLOps-Konzepte“, wie du deine AutoML-Modelle in der Produktion einsetzt und überwachst. Kurs „MLOps-Konzepte“.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Javier Canales Luna
Tutorial
Derrick Mwiti
Tutorial
DataCamp Team
