
Cours
Introduction à MongoDB en Python
3 h
24K
Les données sont omniprésentes - des dossiers des clients aux transactions des applications - et il est très important de les organiser. En fait, la quantité de données créées, capturées, copiées et consommées () devrait atteindre 394 zettaoctets d'ici à 2028. Il s'agit d'une quantité phénoménale d'informations, et sans système pour les gérer, les choses deviendraient rapidement confuses.
C'est pourquoi nous utilisons un système de gestion de base de données (SGBD). Il permet de stocker et de gérer les données afin que les entreprises et les applications puissent fonctionner sans problème. Dans ce guide, je vais vous expliquer ce qu'est un SGBD, comment il fonctionne, quels sont ses différents types et pourquoi il est essentiel pour le stockage et la gestion des données modernes.
Un système de gestion de base de données (SGBD) stocke, organise et gère efficacement les données. Sans SGBD, les données seraient dispersées dans de multiples fichiers, ce qui rendrait difficile leur localisation ou leur mise à jour. Un SGBD simplifie ces tâches en fournissant un système centralisé, permettant aux utilisateurs d'ajouter, de modifier ou de supprimer facilement des données tout en garantissant leur exactitude et leur cohérence.
Un SGBD s'occupe d'une grande partie de la gestion des données. Il organise et protège les informations afin que nous puissions trouver ce dont nous avons besoin, quand nous en avons besoin, sans nous casser la tête. Examinons ses principales fonctions en détail.
Les bases de données stockent les informations de manière structurée à l'aide du langage DDL (Data Definition Language). Le langage DDL permet de créer des tableaux, d'ajouter des champs et de les relier entre eux, par exemple en établissant une liste de clients avec des noms, des numéros de téléphone et des adresses électroniques.
Voici quelques commandes DDL courantes :
1) CREATE crée de nouveaux tableaux, champs et relations. Il nous aide à définir le type de données que nous allons stocker. Supposons que vous construisiez une base de données clients. Dans ce cas, voici comment créer un tableau pour stocker les coordonnées des clients :
CREATE TABLE Customers (
ID INT PRIMARY KEY,
Name VARCHAR(100)
);2) ALTER modifie un tableau existant (ajoute, supprime ou modifie des colonnes). Ici, j'ai ajouté un nouveau champ (email) dans mon tableau Customers:
ALTER TABLE Customers ADD Email VARCHAR(255);3) DROP supprime définitivement un objet de la base de données. Voici comment je supprime le tableau Customers:
DROP TABLE Customers;4) TRUNCATE supprime tous les enregistrements d'un tableau mais conserve sa structure. Contrairement à DROP, le tableau reste intact et peut donc toujours être utilisé. Voici comment vous pouvez utiliser cette commande :
TRUNCATE TABLE Customers;5) RENAME modifie le nom d'un tableau ou d'une colonne. Par exemple, pour renommer le tableau Customers en Clients, voici ce que je ferais :
RENAME TABLE Customers TO Clients;Une fois la base de données configurée, vous pouvez commencer à manipuler les données - ajouter, mettre à jour ou supprimer des enregistrements - à l'aide du langage de manipulation de données (DML).
Voici quelques commandes DML courantes :
1) INSERT ajoute une nouvelle ligne de données à un tableau. Par exemple, pour ajouter un nouveau client à notre tableau Customers, j'utilise ce code :
INSERT INTO Customers
(ID, Name, Email)
VALUES
(1, Drake White, 'drake@example.com');Cette opération ajoute au tableau un client dont l'ID est 1, le nom Drake White et l'adresse électronique drake@example.com.
2) UPDATE modifie les tableaux existants. Pour modifier l'adresse électronique d'un client, je mets à jour son dossier comme suit :
UPDATE Customers SET Email = 'drake .new@example.com' WHERE ID = 1;L'adresse électronique du client avec l'ID 1 est ainsi mise à jour et devient drake .new@example.com.
3) DELETE supprime des données spécifiques d'un tableau. Pour supprimer un client dont l'ID est 1, j'utilise la commande suivante :
DELETE FROM Customers WHERE ID = 1;NOTE : Faites attention avec DELETE - une fois que les données disparaissent, elles disparaissent (à moins que vous n'ayez une sauvegarde).
4) SELECT extrait les données d'un tableau. Par exemple, pour voir tous les clients de mon tableau, j'utilise :
SELECT * FROM Customers;`Si je ne veux voir que les clients portant un nom spécifique, je peux utiliser :
SELECT * FROM Customers WHERE Name = 'Drake White';Seuls les enregistrements dont le champ Name correspond à Drake White seront renvoyés.
Comme nous l'avons vu dans la section précédente, un SGBD permet de récupérer rapidement des informations à l'aide de SQL ou d'autres langages d'interrogation. Au lieu de rechercher manuellement des milliers d'enregistrements, nous pouvons utiliser des requêtes pour trouver exactement ce dont nous avons besoin en quelques secondes.
Supposons que je veuille trouver tous les clients de New York. Ainsi, au lieu de faire défiler des milliers d'enregistrements, j'utilise simplement une requête SQL comme celle-ci :
SELECT * FROM customers WHERE city = 'New York';Un SGBD assure l'exactitude des données en attribuant à chaque enregistrement un identifiant unique et en reliant les tableaux connexes. Il relie les lignes avec des clés primaires et maintient la cohérence entre les tableaux avec des clés étrangères. Pour assurer la sécurité des données, il utilise :
Un SGBD stocke les données de manière efficace et conserve les sauvegardes. Il utilise l'indexation pour accélérer les recherches et comprend des fonctions de sauvegarde et de récupération pour éviter les pertes de données dues à des suppressions accidentelles ou à des défaillances du système. Ainsi, en cas de problème, nous pouvons restaurer les données sans perdre d'informations importantes.
Tous les SGBD ne fonctionnent pas de la même manière. En fait, il en existe différents types, chacun conçu pour des types de données et des cas d'utilisation spécifiques. Nous allons les décomposer à l'aide de quelques exemples faciles à suivre.
Un SGBD hiérarchique structure les données comme un arbre généalogique, où chaque enregistrement a un parent, et chaque parent peut avoir plusieurs enfants. Cependant, chaque enfant ne peut avoir qu'un seul parent (relation de type "un à plusieurs").
Pensez à l'organigramme d'une entreprise : Un responsable (parent) supervise plusieurs employés (enfants), mais chaque employé ne rend compte qu'à un seul responsable.
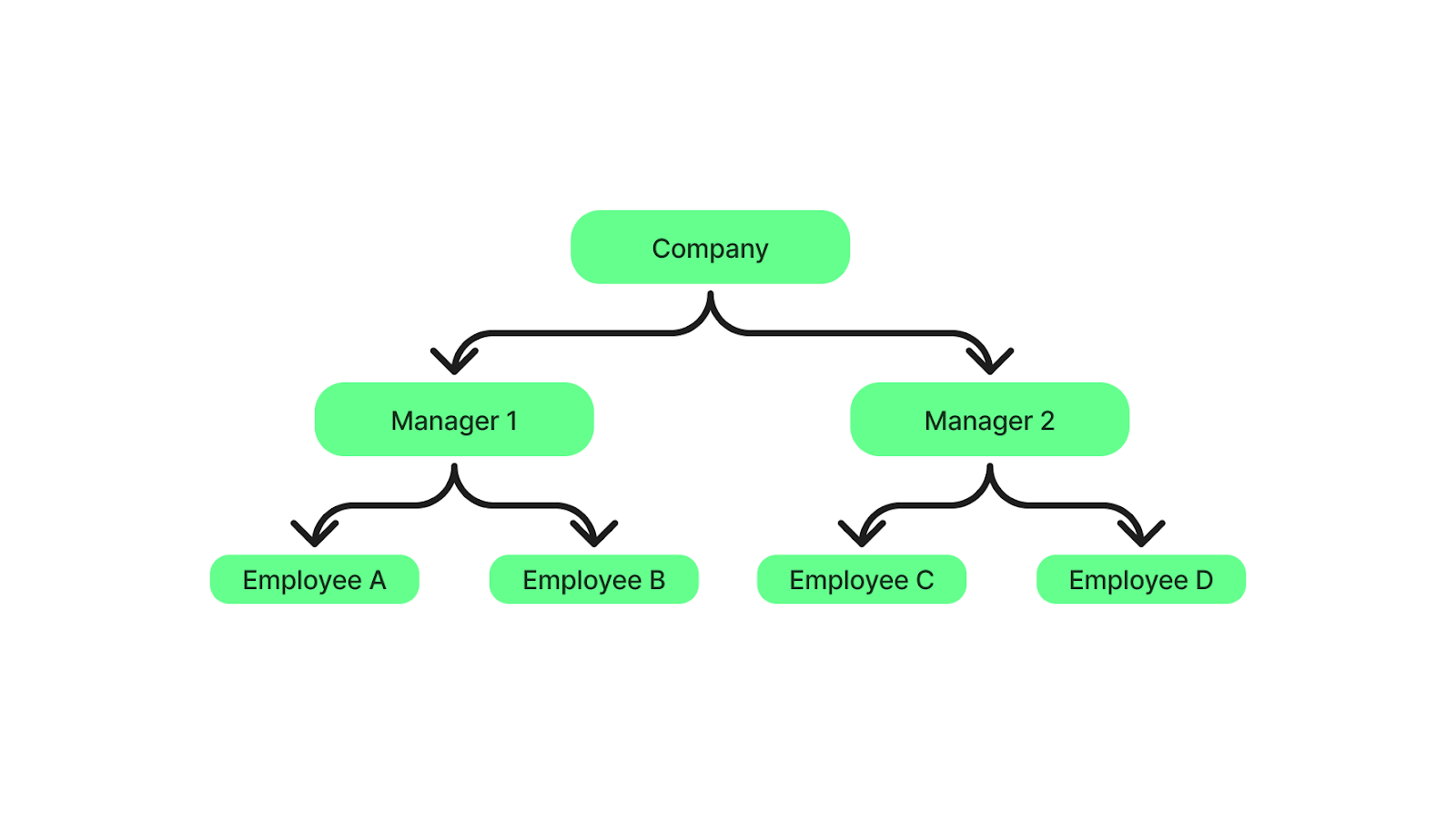
Structure hiérarchique des SGBD. Image par l'auteur.
Un exemple bien connu de SGBD hiérarchiqueest le système de gestion de l'information (IMS) d'IBM, l'un des premiers à utiliser cette structure pour traiter de grandes quantités de données.
UnSGBD en réseauest plus souple qu'un SGBD hiérarchique car il permet aux enregistrements d'avoir plusieurs parents et plusieurs enfants (relation de plusieurs à plusieurs). Il est ainsi plus facile de gérer des relations complexes. Un exemple de ce type est le magasin de données intégré.
Par exemple, dans une base de données universitaire, les étudiants peuvent s'inscrire à plusieurs cours et chaque cours peut avoir plusieurs étudiants.
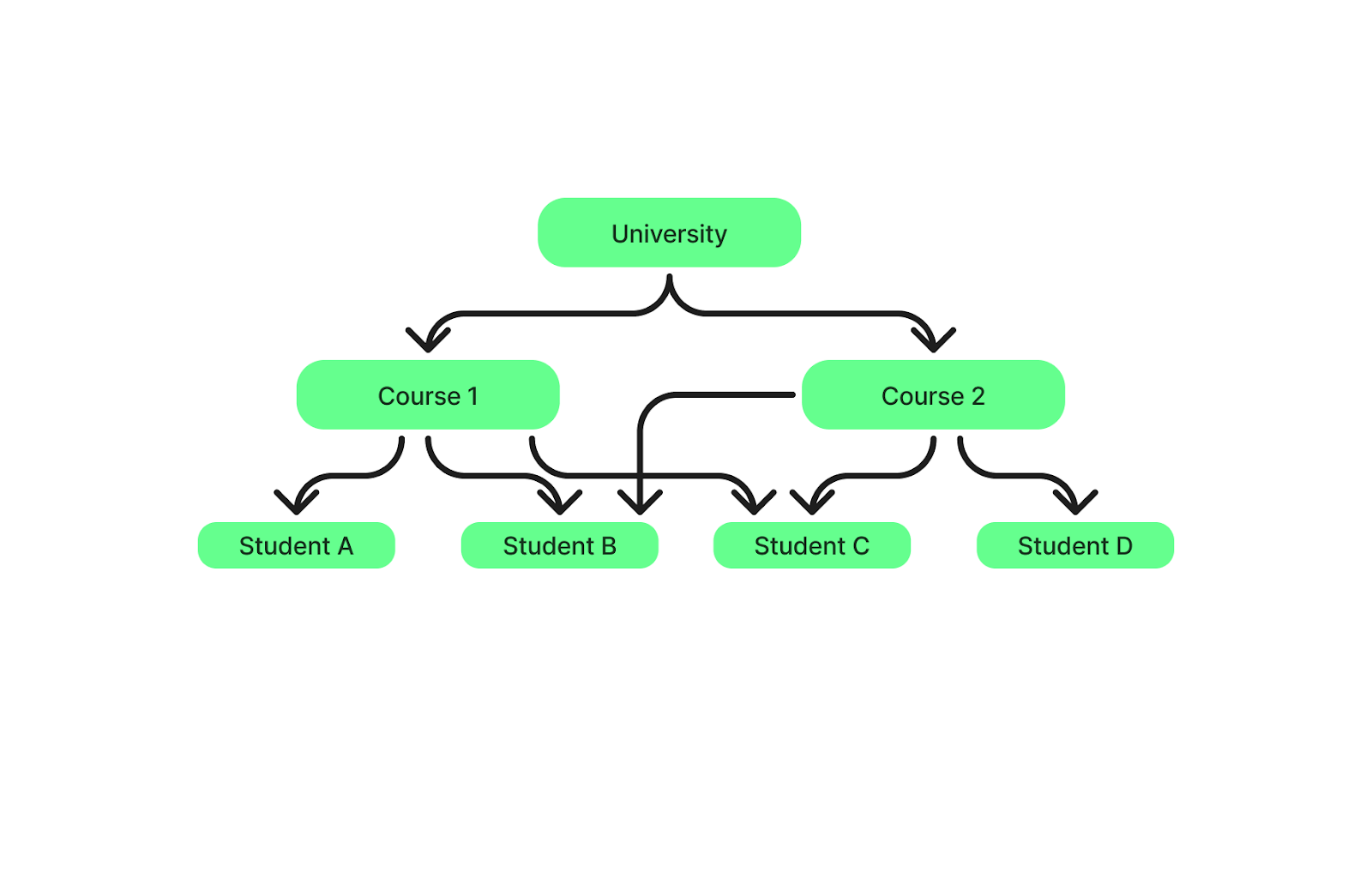
Structure d'un SGBD en réseau. Image par l'auteur.
Un SGBD relationnel stocke les donnéesa dans des tableaux, où chaque tableau est constitué de lignes et de colonnes (comme les feuilles de calcul). Ces tableaux sont liés par des clés uniques, ce qui facilite l'organisation et la récupération des données :
Ce type de SGBD est largement utilisé sur le site car il est fiable, évolutif et facile à gérer. Parmi les exemples les plus populaires, on trouveude MySQL, PostgreSQL et Oracle.
Supposons que nous ayons deux tableaux :
StudentsLa base de données des étudiants : elle contient les noms des étudiants, leurs numéros de matricule et les cours qu'ils suivent.MarksLe système de gestion des examens : il stocke les numéros d'appel et les notes d'examen correspondantes.La colonne Roll No. du tableau Students est la clé primaire, tandis que dans le tableau Marks, il s'agit d'une clé étrangère qui renvoie au tableau Students.
SELECT Students.Name, Students.Course, Marks.Marks
FROM Students
JOIN Marks ON Students.RollNo = Marks.RollNo;La requête ci-dessus renvoie une vue combinée des noms des étudiants, des cours auxquels ils sont inscrits et de leurs notes.
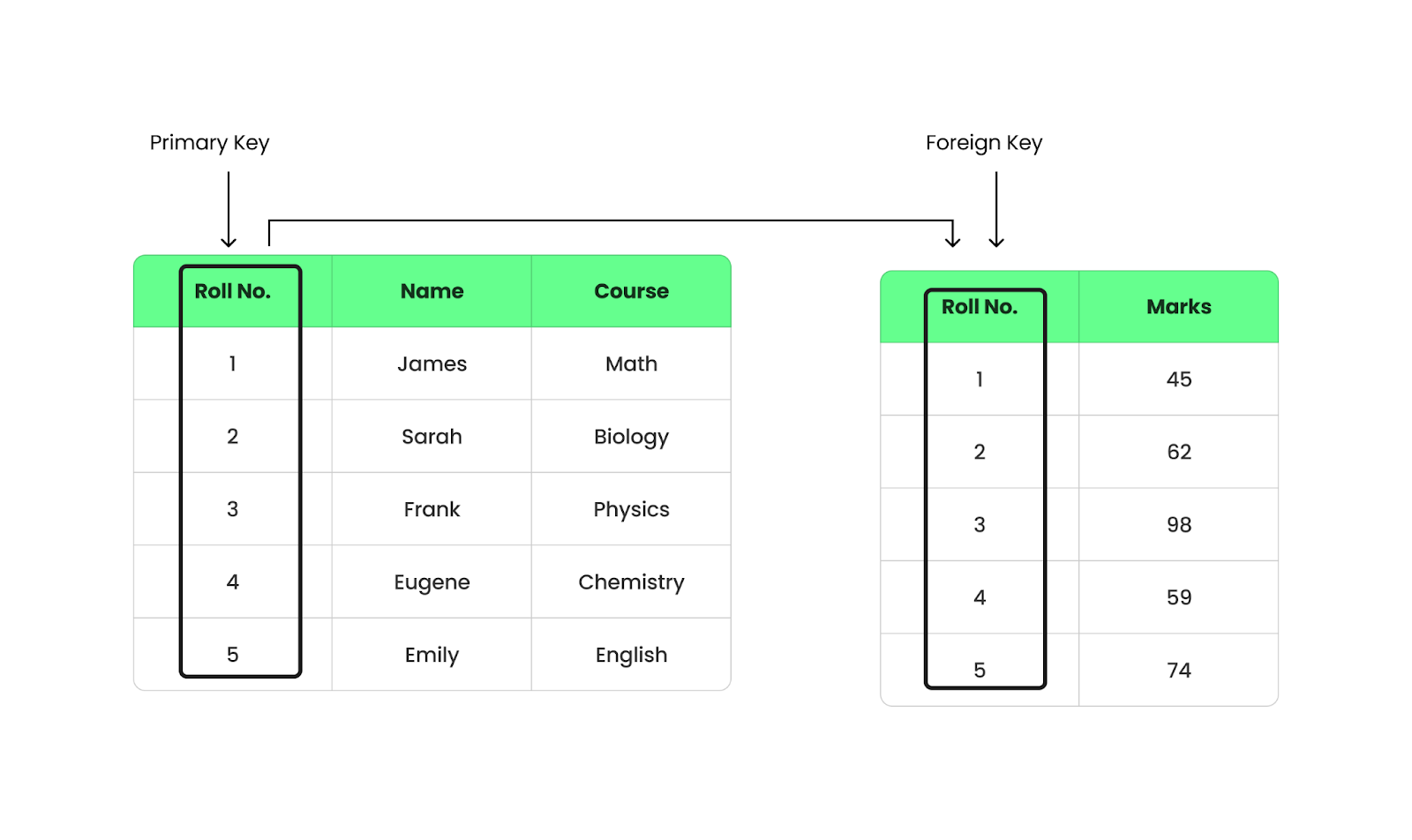
Structure d'un SGBD relationnel. Image par l'auteur.
Un SGBD orienté objet stocke les données sous forme d'objets, de la même manière que les langages de programmation tels que Java ou Python gèrent les objets. Ces objets contiennent à la fois les données et les méthodes utilisées pour les traiter. Un exemple courant est db4o, une base de données open-source pour les développeurs Java et .NET.
Par exemple, une université stocke les informations relatives aux étudiants sous forme d'objets, chaque objet Student ayant des attributs tels que Name, Age et Student ID et des comportements tels que Enroll() et Drop_Course(). Les élèves sont liés aux objets Course avec des détails tels que Course_Name, Instructor, Credits_hours, et Enrollment qui suivent Enrollment_Date et Grades.
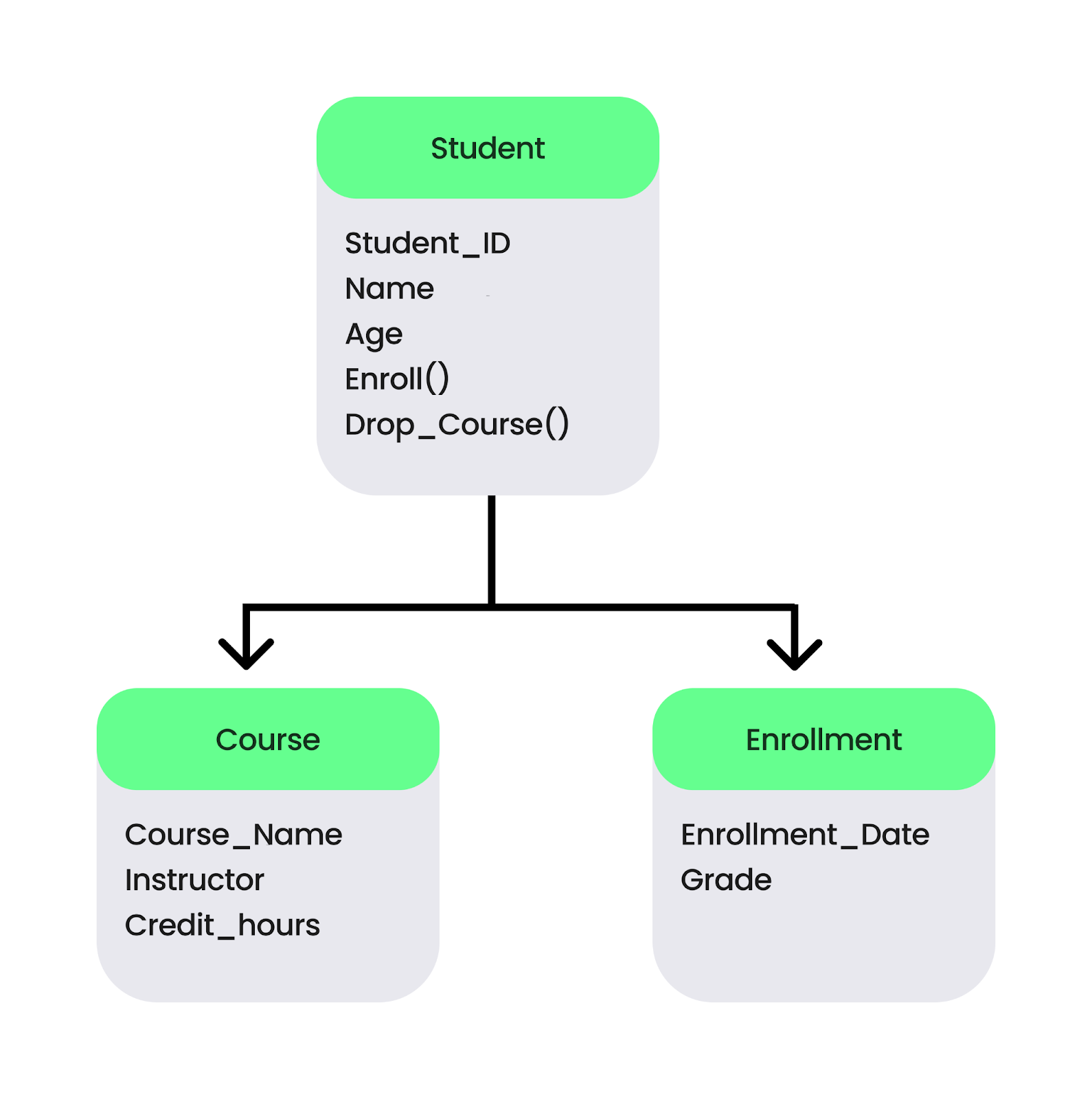
Structure d'un SGBD orienté objet. Image par l'auteur.
Un SGBD NoSQL stocke les données à l'aide de modèles non relationnels, tels que des structures basées sur des documents, des clés-valeurs, des familles de colonnes ou des graphes. Il utilise principalement la structure JSON (JavaScript Object Notation) pour traiter de grandes quantités de données non structurées ou semi-structurées.
Contrairement aux bases de données relationnelles, elle n'utilise pas de tableaux fixes et permet des méthodes plus souples de stockage et d'extraction des données. Il est donc idéal pour les big data, les applications en temps réel et les systèmes basés sur le cloud. Parmi ses principaux exemples, citons MongoDB, Apache Cassandra et Couchbase.
Voici comment nous pouvons stocker les données des élèves en utilisant le format JSON :
{
"student_id": "101",
"name": "Emma",
"age": 16,
"grade": 11,
"subjects": ["Math", "Science", "English"]
}Les différents SGBD sont conçus pour répondre à des besoins différents. Certains sont gratuits et parfaits pour les sites web, tandis que d'autres sont conçus pour les grandes entreprises qui ont besoin d'une sécurité et de performances de premier ordre. Examinons quelques-uns des logiciels de SGBD les plus populaires et la manière dont ils sont utilisés.
MySQL est l'un des systèmes de gestion de bases de données relationnelles (SGBDR) open-source les plus utilisés. Il est utilisé dans les sites web et les applications parce qu'il est rapide et évolutif. Les grandes plateformes comme WordPress et les sites de commerce électronique s'appuient sur MySQL pour gérer efficacement de grandes quantités de données sans ralentissement.
PostgreSQL est un système de gestion de base de données relationnelle objet (ORDBMS) open-source avancé, extrêmement flexible et puissant. Il prend en charge les requêtes complexes et fonctionne avec plusieurs langages de programmation comme Java et Python. De grands noms comme Netflix et Instagram utilisent PostgreSQLparce qu'il peut gérer des quantités massives de données structurées et non structurées sur différentes plateformes, notamment Windows, macOS et Linux.
👉 Téléchargez l' aide-mémoire sur les bases de PostgreSQL!
Microsoft SQL Server (SQL Server) est un SGBDR commercial conçu par Microsoft pour des performances et une sécurité de niveau professionnel. C'est un choix de premier ordre pour les entreprises qui s'appuient sur les produits Microsoft, car il s'intègre de manière transparente à des outils comme Azure et Power BI. En effet, il conserve les données proprement organisées dans des tableaux structurés et utilise Transact-SQL (T-SQL) et le protocole Tabular Data Stream pour traiter les transactions sans erreur.
MongoDB est une base de données NoSQL ouverterce, ce qui signifie qu'elle n'utilise pas de tableaux traditionnels comme MySQL ou SQL Server. Au lieu de cela, il stocke les informations dans des documents (similaires au format JSON). Il est donc très flexible et évolutif, ce qui est parfait pour traiter de grands volumes de données dynamiques ou non structurées. En raison de sa vitesse et de son évolutivité, MongoDB est un choix de premier ordre pour les applications en temps réel, les applications mobiles et le traitement des données volumineuses.
En 1977, Larry Ellison, Bob Miner et Ed Oates ont développé la base de données Oracle, qui a ensuite été intégrée à Oracle Corporation. Il s'agit d'un SGBDR haute performance conçu pour les grandes entreprises qui ont besoin d'une sécurité et d'une automatisation à toute épreuve.
Il peut traiter des quantités massives de données tout en optimisant lui-même les performances, ce qui permet aux entreprises de gagner dutemps et de réduire les coûts de calcul jusqu'à 87 %. Grâce aucryptage intégré, aux contrôles d'accès et aux outils de surveillance, Oracle protège les données sensibles contre les accès non autorisés.
Les systèmes de gestion de base de données (SGBD) constituent l'épine dorsale d'un traitement organisé, sûr et efficace des données. Sans eux, la gestion de grandes quantités d'informations serait lente et sujette à des erreurs.
Pour les entreprises, un SGBD garantit que les données restent exactes, protégées et faciles d'accès en cas de besoin.
Si vous êtes prêt à passer à l'étape suivante de votre apprentissage, envisagez de vous plonger dans les principes fondamentaux du langage SQL et des bases de données. Commencez par le cours SQL Fundamentals pour construire une base solide, explorez le cours Database Design pour comprendre comment structurer vos données efficacement, ou suivez le cours Introduction to Relational Databases in SQL pour approfondir votre compréhension des concepts RDBMS !
Apprenez-en plus sur les bases de données et le langage SQL grâce à ces cours !
Cours
Cours
Cours