Cursus
ChatGPT : les fondamentaux
3 h
La plateforme AutoGPT est une plateforme qui permet aux utilisateurs de créer, de déployer et de gérer des agents d'intelligence artificielle en continu. Il utilise une interface utilisateur à code bas pour permettre aux utilisateurs d'automatiser des milliers de processus numériques, avec des agents fonctionnant de manière autonome en coulisses.
La plateforme AutoGPT est composée de deux éléments principaux : le serveur AutoGPT, la logique et l'infrastructure principales, et le frontal AutoGPT, l'interface utilisateur permettant de créer les agents, de gérer les flux de travail et de mettre en œuvre des programmes récurrents.
Il est pré-intégré avec des fournisseurs de LLM tels que OpenAI, Anthropic, Groq et Llama, ce qui permet d'automatiser un large éventail de tâches telles que le traitement des données, la création de contenu ou même des activités ludiques.
Dans ce tutoriel, nous allons guider les professionnels techniques sur la façon de mettre en place la plateforme AutoGPT localement et de créer leur premier agent. Vous pouvez lire notre guide complet sur la compréhension des agents d'IA pour en savoir plus, et découvrir les différents types d'agents d'IA dans un article séparé.
AutoGPT est une plateforme/un logiciel d'IA qui permet aux utilisateurs de créer, de déployer et de gérer des agents d'IA autonomes. Ces agents peuvent effectuer diverses tâches avec une supervision humaine minimale grâce à une interface à code bas installée sur la machine de l'utilisateur.
À l'heure où nous écrivons ces lignes, il existe une liste d'attente ouverte pour une prochaine version cloud d'AutoGPT si vous souhaitez éviter les tracas de l'installation locale.
Les principales caractéristiques et capacités de l'AutGPT sont les suivantes :
La plateforme AutoGPT se compose de deux éléments principaux :
1. Serveur AutoGPT:
2. Frontend AutoGPT:
Le backend d'AutoGPT utilise Python avec FastAPI comme cadre web et PostgreSQL avec Prisma ORM pour le stockage des données. Il utilise des websockets pour la communication en temps réel et comprend des gestionnaires pour l'exécution, la programmation et les notifications.
Cette conception améliore l'évolutivité et la maintenance au fur et à mesure que la plateforme se développe.
Le frontend utilise Next.js 14 avec TypeScript, les composants Radix, et Tailwind CSS, avec une visualisation du flux de travail utilisant xyflow. Cela crée une interface intuitive à code bas où les utilisateurs peuvent construire des agents d'intelligence artificielle sans avoir de connaissances approfondies en programmation.
La plateforme comprend les services clés suivants :
Lorsqu'il a été annoncé pour la première fois aux alentours de 2023, AutoGPT a connu une popularité fulgurante et a été considéré comme le tueur open-source de ChatGPT. Bien sûr, ce n'était qu'un battage médiatique mené par les influenceurs des médias sociaux, car nous sommes en 2025 maintenant, et le ChatGPT est toujours là. Mais l'AutoGPT a marqué le changement d'orientation de la communauté de l'IA vers les agents d'IA.
Les premières versions d'AutoGPT promettaient des agents entièrement autonomes pouvant être construits à la volée à partir d'une simple invite. Il serait capable de diviser l'invite en tâches gérables et de rassembler une variété d'outils, de logiciels et d'API pour accomplir le travail, tout en ayant une mémoire à court et à long terme stimulée par une boucle de rétroaction auto-réfléchissante.
Cependant, en cours de route, ils ont dû se rendre compte des limites de cette approche en raison de l'imprévisibilité inhérente aux LLM dans les scénarios de production.
Aujourd'hui, AutoGPT n'est pas une plateforme "prompt-to-agent" mais quelque chose de bien mieux - une plateforme "low-code" qui permet aux utilisateurs de contrôler la façon dont leurs agents sont construits. Vous pouvez voir ce changement de la version originale d'AutoGPT à la plateforme que nous avons en 2025 si vous lisez les articles d'il y a 1 ou 2 ans ou si vous regardez les vidéos YouTube.
Ces articles présentent des instructions d'installation et des exemples de flux de travail complètement différents de ce que je vais vous apprendre.
Sans plus attendre, voyons comment vous pouvez configurer la plateforme sur votre machine.
La mise en place d'AutoGPT en local nécessite une configuration adéquate de votre environnement de développement et une compréhension des outils de conteneurisation - consultez notre cours sur la conteneurisation et la virtualisation avec Docker et Kubernetes si vous avez besoin d'une remise à niveau. Cette section vous guide tout au long du processus, des conditions préalables à l'utilisation de la plateforme pour la première fois.
Avant d'installer AutoGPT, assurez-vous que vous disposez des conditions préalables suivantes :
1. Node.js et NPM
brew install nodesudo apt update sudo apt install nodejs npmnode -v npm -v2. Docker et Docker Compose
sudo apt update sudo apt install docker.io docker-compose sudo systemctl enable --now dockerdocker -v docker compose -v3. Git
brew install gitsudo apt update sudo apt install gitgit clone https://github.com/Significant-Gravitas/AutoGPT.gitCes conditions préalables sont essentielles à l'exécution efficace d'AutoGPT. Node.js et NPM sont nécessaires pour l'application frontale, ce qui vous permet d'interagir avec AutoGPT par le biais d'une interface conviviale.
Docker et Docker Compose créent des conteneurs isolés qui garantissent des performances constantes sur différents systèmes et simplifient le déploiement des services dorsaux. Git vous permet de cloner le dépôt et de rester informé des dernières améliorations.
Après cette étape, vous devez avoir le répertoire AutoGPT sur votre machine, qui contient tout ce qu'il faut pour faire fonctionner l'application. Il ne reste plus que la configuration.
Docker fournit un environnement isolé et cohérent pour l'exécution d'AutoGPT, garantissant que toutes les dépendances fonctionnent correctement quel que soit votre système hôte.
cd AutoGPT/autogpt_platform
cp .env.example .env
docker compose up -d --buildLe nouveau fichier .env est accompagné de variables d'environnement dont les valeurs par défaut sont judicieuses. Vous n'êtes pas tenu de configurer ce fichier vous-même, mais sa présence est indispensable. Il sera utilisé par l'application frontale lorsque vous fournirez diverses clés et secrets lors de la création de vos agents personnalisés.
La dernière commande docker compose peut prendre jusqu'à 15 minutes en fonction de votre vitesse Internet lors de la première exécution. Il met en place les composants du backend auxquels le frontend se connectera.
cd frontend
cp .env.example .env
npm install
npm run devCes commandes configurent le fichier d'environnement pour le frontend, installent ses dépendances avec Node.js et démarrent l'interface utilisateur.
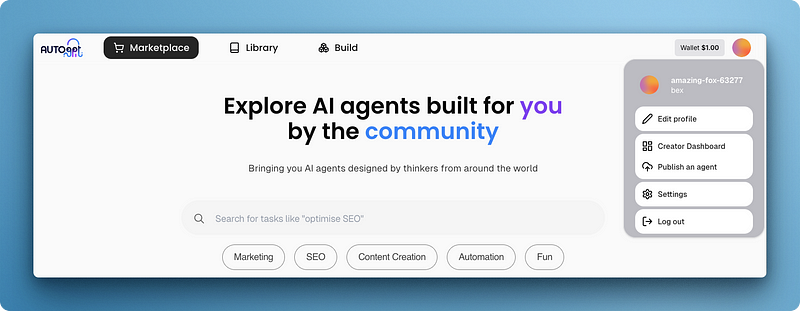
La visite du port 3000 doit vous montrer l'interface utilisateur de Marketplace, qui vous permet de créer votre compte et de vous connecter.
# Generate a new key with Python
from cryptography.fernet import Fernet
Fernet.generate_key().decode()
# Or use the built-in CLI
poetry run cli gen-encrypt-keyRemplacez la clé existante dans autogpt_platform/backend/.env par votre nouvelle clé.
Note pour les utilisateurs de Windows: Lorsque vous utilisez Docker sur Windows, sélectionnez WSL2 au lieu d'Hyper-V pendant l'installation pour éviter les problèmes de compatibilité avec Supabase. Si vous avez déjà installé Hyper-V, vous pouvez passer à WSL 2 dans les paramètres de Docker Desktop.
Avant de créer un agent fonctionnel, nous allons nous familiariser avec l'interface du constructeur de l'AutGPT.
L'interface est une grande toile blanche avec quatre boutons principaux :
En cliquant sur "Blocks", vous accédez à un menu de composants réutilisables intégrés à AutoGPT, regroupés par catégories.
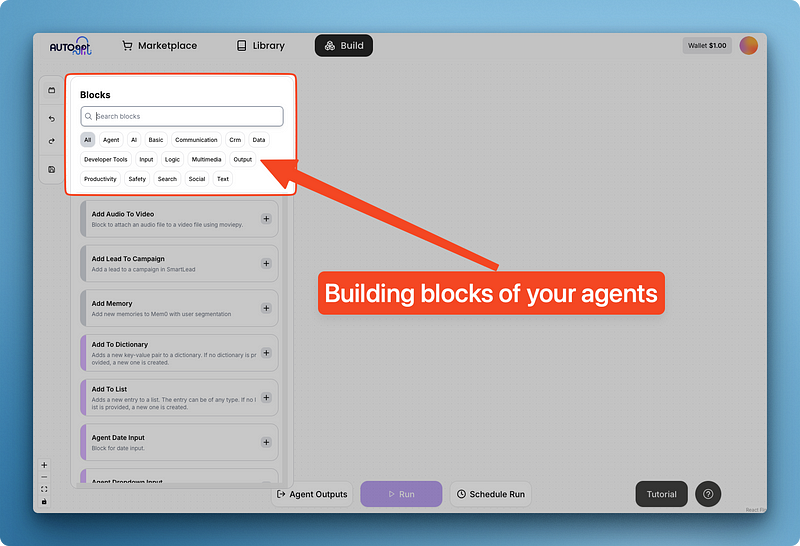
Ces blocs fournissent des outils essentiels qui peuvent être appliqués universellement dans de nombreux scénarios d'agents.
Par exemple, ci-dessous, j'ai recherché et ajouté deux blocs - entrée de texte long et générateur de texte AI. Ces deux composants me suffisent pour recréer la version de base de l'interface du ChatGPT :
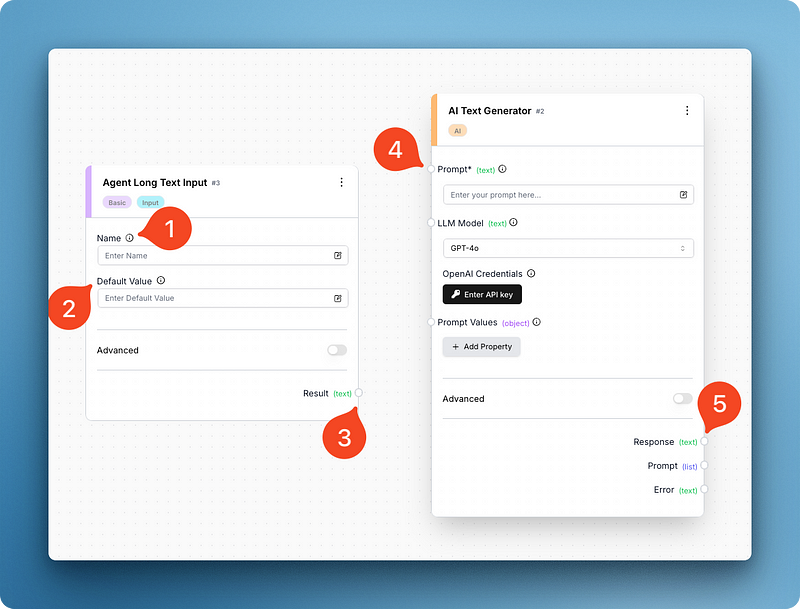
En regardant l'image, vous pouvez voir que chaque bloc a des parties mobiles différentes. Le bloc d'entrée comporte des champs pour le nom du bloc et une valeur par défaut, tandis que le générateur de texte comporte un champ pour l'invite, le modèle et les variables de l'invite.
Ce dernier comporte également un champ de saisie unique pour votre clé API OpenAI, que vous devez fournir avant de lancer l'agent (faites-le maintenant). Le champ de la clé API change en fonction du modèle que vous choisissez et AutoGPT prend en charge la plupart des fournisseurs majeurs et mineurs.
Si vous le remarquez, les deux blocs ont de petites arêtes (regardez 3 et 5) qui vous permettent de les relier :
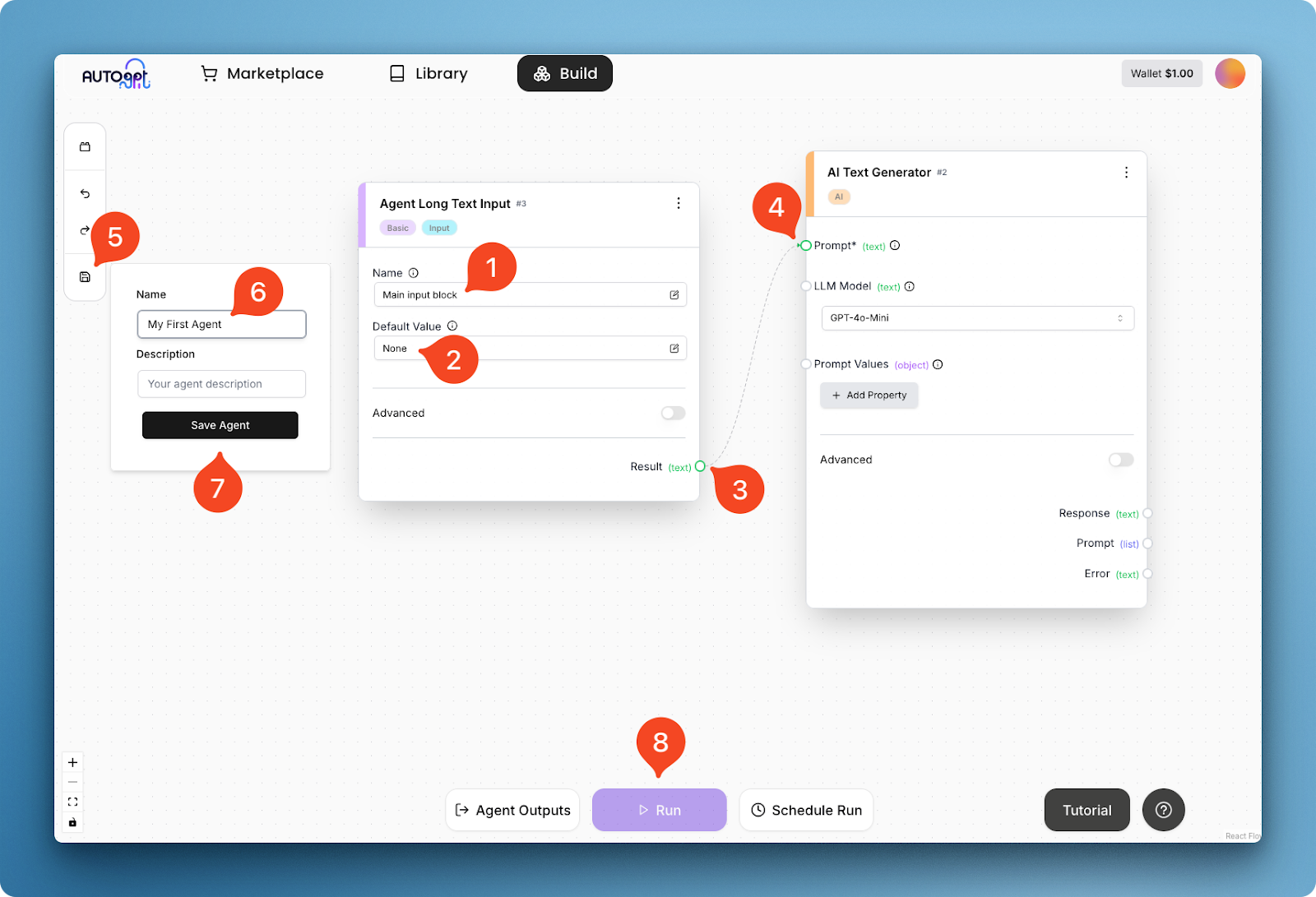
Dans l'image ci-dessus, je donne au bloc de saisie un nom (1) et une valeur par défaut (2), et je connecte son résultat textuel (3) au champ d'invite (4) du générateur de texte. Cette connexion crée un flux de travail de base pour l'agent, qui peut être exécuté après l'enregistrement de l'agent lui-même (étapes 5 à 8).
Après avoir cliqué sur "Exécuter", vous verrez apparaître un menu "Paramètres d'exécution" pour le champ de saisie :
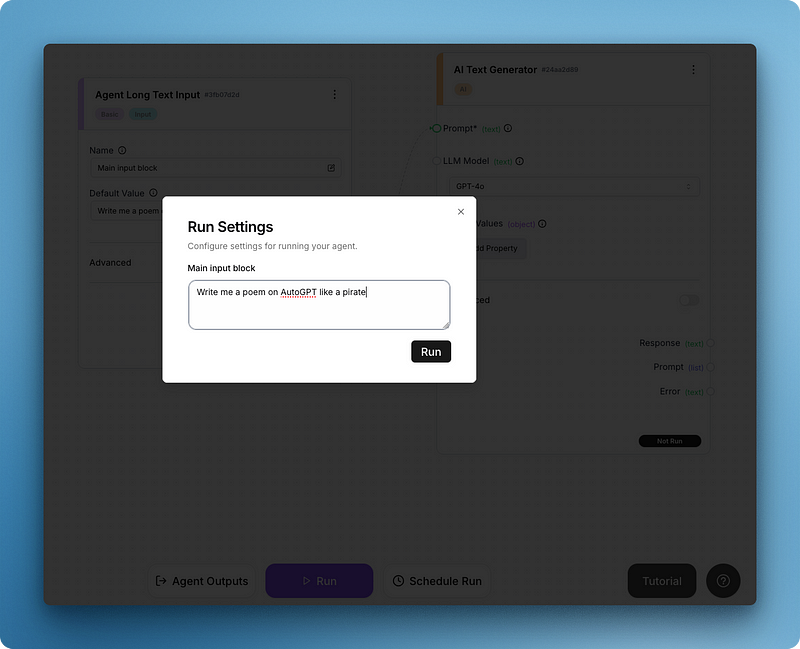
Écrivez votre invite et exécutez le tout pour obtenir votre premier résultat comme ci-dessous :
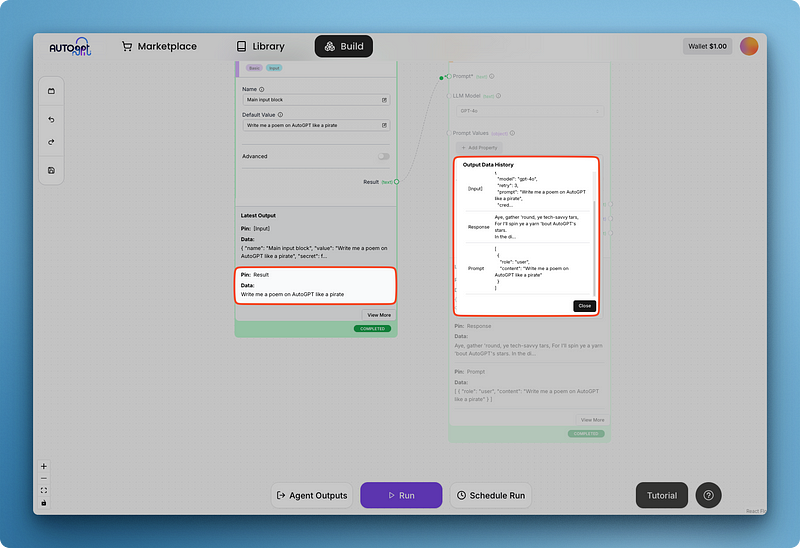
Vous remarquerez peut-être que la réponse du modèle est difficile à lire dans le bloc de génération de texte plus grand. C'est pourquoi AutoGPT dispose de blocs pour les sorties d'agents, que j'ajoute ci-dessous :
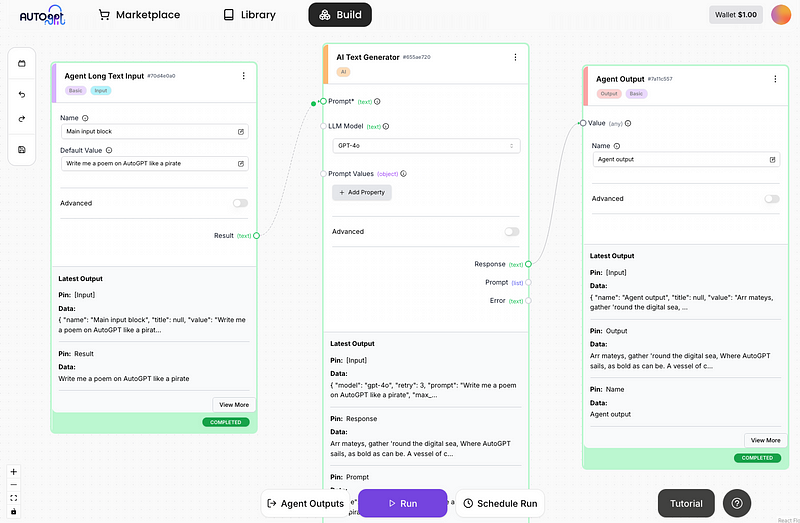
Remarquez que j'ai connecté le champ de réponse du générateur de texte à la valeur du bloc de sortie de l'agent. L'ajout d'un bloc de sortie vous permet également de visualiser en un seul endroit toutes les sorties d'agents provenant de différents blocs à l'aide du volet "Sorties d'agents" :
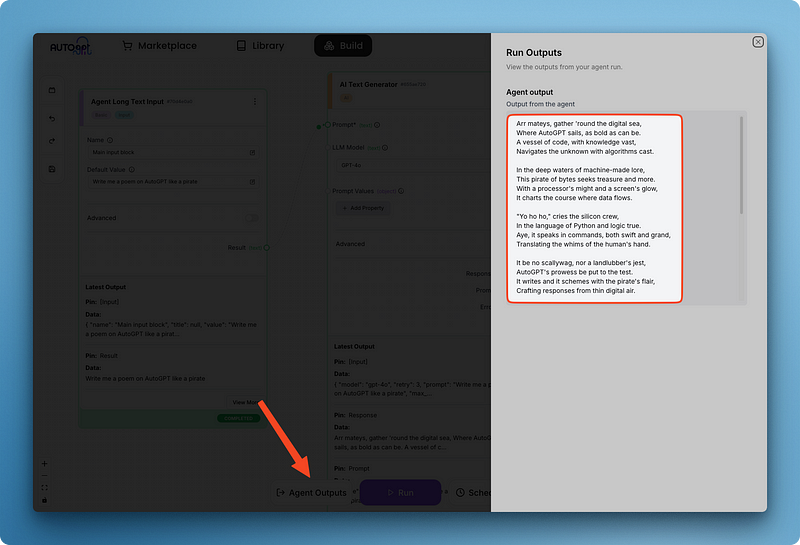
Une fois que vous aurez enregistré votre agent, il sera sauvegardé dans votre bibliothèque. De plus, cet agent entier peut ensuite être utilisé comme bloc dans d'autres agents que vous créez. Cette approche modulaire présente plusieurs avantages :
Cette approche modulaire vous permet de créer des systèmes d'IA de plus en plus puissants en superposant les capacités.
La puissance d'AutoGPT provient de son système de blocs modulaires. Bien que la plateforme comprenne de nombreux blocs intégrés utiles, vous pouvez étendre ses capacités en créant vos propres blocs personnalisés en Python. Cette fonction vous permet d'intégrer toute API, tout service ou tout outil accessible par programme.
La création d'un bloc personnalisé comporte les étapes essentielles suivantes :
autogpt_platform/backend/backend/blocks en utilisant le nom snake_caseBlockBlockSchema pour définir la structure des données__init__ avec un identifiant unique et des données de test.run qui contient la logique de base de votre bloc.Examinons chaque élément en détail :
Chaque bloc doit hériter de la classe de base Block et définir ses schémas d'entrée/sortie :
from backend.data.block import Block, BlockSchema, BlockOutput
class MyCustomBlock(Block):
class Input(BlockSchema):
# Define input fields with types
field1: str
field2: int
class Output(BlockSchema):
# Define output fields with types
result: str
error: str # Always include an error field
def __init__(self):
super().__init__(
id="xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", # Generate proper UUID
input_schema=MyCustomBlock.Input,
output_schema=MyCustomBlock.Output,
test_input={"field1": "test", "field2": 42},
test_output=("result", "expected output"),
test_mock=None # Only needed for external API calls
)
def run(self, input_data: Input, **kwargs) -> BlockOutput:
try:
# Your block logic here
result = f"Processed {input_data.field1} and {input_data.field2}"
yield "result", result
except Exception as e:
raise RuntimeError(f"Error in block: {str(e)}")yield pour obtenir les résultats un par un.Créons un exemple détaillé d'un bloc personnalisé qui effectue une analyse des sentiments à l'aide de l'API OpenAI. Vous découvrirez ainsi comment intégrer des services d'intelligence artificielle externes et gérer les clés d'API en toute sécurité.
Avant d'utiliser ce bloc, vous devez configurer votre clé API OpenAI :
1. Installez les paquets nécessaires :
pip install openai python-dotenv2. Créez un fichier .env dans le répertoire autogpt_platform/backend/blocks avec votre clé API OpenAI :
OPENAI_API_KEY=your_api_key_hereMaintenant, créons le bloc :
Commençons par les importations et la configuration de l'environnement :
# autogpt_platform/backend/blocks/sentiment_analyzer.py
from backend.data.block import Block, BlockSchema, BlockOutput
from typing import Dict, Any, List
import os
from dotenv import load_dotenv
from openai import OpenAI
import json
# Load environment variables from .env file
load_dotenv()Cette section importe les bibliothèques nécessaires et charge les variables d'environnement à partir du fichier .env. La fonction load_dotenv() garantit que votre clé API est disponible via os.getenv().
Ensuite, nous définissons la classe de bloc avec des schémas d'entrée et de sortie :
class OpenAISentimentBlock(Block):
"""Block to analyze sentiment of text using OpenAI API"""
class Input(BlockSchema):
text: str # Text to analyze
model: str = "gpt-3.5-turbo" # OpenAI model to use
detailed_analysis: bool = False # Whether to return detailed analysis
class Output(BlockSchema):
sentiment: str # Positive, Negative, or Neutral
confidence: float # Confidence score of the prediction
explanation: str # Brief explanation of the sentiment
detailed_analysis: Dict[str, Any] # Optional detailed analysis
error: str # Error message if analysis failsLe schéma d'entrée définit trois paramètres :
text: Le contenu à analyser (obligatoire)model: Le modèle OpenAI à utiliser (par défaut "gpt-3.5-turbo")detailed_analysis: Indiquer s'il faut renvoyer des détails supplémentaires (valeur par défaut : False)Le schéma de sortie définit la structure des résultats, y compris la catégorie de sentiment, la note de confiance, l'explication et l'analyse détaillée facultative.
La méthode __init__ met en place le bloc avec des données de test et initialise le client OpenAI:
def __init__(self):
super().__init__(
id="8f67d394-9f52-4352-a78b-175d5d1d7182", # Generated UUID
input_schema=OpenAISentimentBlock.Input,
output_schema=OpenAISentimentBlock.Output,
test_input={
"text": "I really enjoyed this product, it exceeded my expectations!",
"detailed_analysis": True
},
test_output=[
("sentiment", str),
("confidence", float),
("explanation", str),
("detailed_analysis", dict)
],
test_mock={
"_analyze_sentiment": lambda text, model, detailed: {
"sentiment": "positive",
"confidence": 0.92,
"explanation": "The text expresses clear enjoyment and states that expectations were exceeded.",
"detailed_analysis": {
"emotions": {
"joy": "high",
"satisfaction": "high",
"disappointment": "none"
},
"key_phrases": ["really enjoyed", "exceeded expectations"],
"tone": "enthusiastic"
}
}
}
)
# Initialize OpenAI client
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise RuntimeError("OpenAI API key not found. Please set OPENAI_API_KEY in .env file.")
self.client = OpenAI(api_key=api_key)Cette méthode :
La fonctionnalité de base est mise en œuvre dans la méthode _analyze_sentiment:
@staticmethod
def _analyze_sentiment(self, text: str, model: str, detailed: bool) -> Dict[str, Any]:
"""Analyze sentiment using OpenAI API"""
# Create prompt based on whether detailed analysis is requested
if detailed:
system_prompt = """
You are a sentiment analysis expert. Analyze the following text and provide:
1. The overall sentiment (positive, negative, or neutral)
2. A confidence score from 0.0 to 1.0
3. A brief explanation of your assessment
4. A detailed analysis including:
- Key emotions detected and their intensity
- Key phrases that influenced your assessment
- Overall tone of the text
Format your response as a JSON object with the following structure:
{
"sentiment": "positive|negative|neutral",
"confidence": 0.0-1.0,
"explanation": "brief explanation",
"detailed_analysis": {
"emotions": {"emotion1": "intensity", "emotion2": "intensity"},
"key_phrases": ["phrase1", "phrase2"],
"tone": "description of tone"
}
}
"""
else:
system_prompt = """
You are a sentiment analysis expert. Analyze the following text and provide:
1. The overall sentiment (positive, negative, or neutral)
2. A confidence score from 0.0 to 1.0
3. A brief explanation of your assessment
Format your response as a JSON object with the following structure:
{
"sentiment": "positive|negative|neutral",
"confidence": 0.0-1.0,
"explanation": "brief explanation"
}
"""
try:
# Make API call using the latest OpenAI API syntax
response = self.client.chat.completions.create(
model=model,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": text}
],
temperature=0.2 # Low temperature for more consistent results
)
# Extract and parse JSON response
content = response.choices[0].message.content
result = json.loads(content)
return result
except Exception as e:
raise RuntimeError(f"OpenAI API error: {str(e)}")Cette méthode :
Enfin, la méthode run fait le lien entre tous les éléments :
def run(self, input_data: Input, **kwargs) -> BlockOutput:
try:
# Validate input
if not input_data.text or not isinstance(input_data.text, str):
raise ValueError("Text must be a non-empty string")
# Process through OpenAI
results = self._analyze_sentiment(
input_data.text,
input_data.model,
input_data.detailed_analysis
)
# Yield the results
yield "sentiment", results["sentiment"]
yield "confidence", results["confidence"]
yield "explanation", results["explanation"]
# Only return detailed analysis if requested and available
if input_data.detailed_analysis and "detailed_analysis" in results:
yield "detailed_analysis", results["detailed_analysis"]
except ValueError as e:
raise RuntimeError(f"Input validation error: {str(e)}")
except Exception as e:
raise RuntimeError(f"Sentiment analysis failed: {str(e)}")Cette méthode :
dotenvCe bloc montre comment intégrer des services d'IA de pointe pour améliorer les capacités de vos agents. L'intégration d'OpenAI permet une analyse de texte sophistiquée qui serait difficile à mettre en œuvre avec de simples approches basées sur des règles.
Lorsque vous rédigez vos propres blocs, tenez toujours compte de ce qui suit :
Pour obtenir des informations plus détaillées sur la création de blocs personnalisés, notamment sur les types de champs, l'authentification, l'intégration des webhooks et les meilleures pratiques, consultez la documentation officielle sur les blocs AutoGPT.
AutoGPT offre une plateforme puissante pour créer et déployer des agents d'IA autonomes grâce à son interface intuitive basée sur des blocs. Ce tutoriel vous a guidé tout au long du processus, depuis l'installation et la configuration locales jusqu'à la compréhension de l'interface utilisateur, la création d'agents de base et l'extension des fonctionnalités à l'aide de blocs personnalisés.
En adoptant l'architecture modulaire d'AutoGPT, les professionnels techniques peuvent automatiser des flux de travail complexes sans avoir de connaissances approfondies en matière de codage, tout en ayant la possibilité d'ajouter des fonctionnalités personnalisées en cas de besoin.
Pour ceux qui souhaitent s'appuyer sur cette base et explorer plus avant les agents d'IA, la documentation officielle de l'AutoGPT fournit des conseils complets, tandis que DataCamp propose des ressources complémentaires telles que Comprendre les agents d'IA et Principes de base du ChatGPT.
Le cours Introduction to GPTs peut vous aider à consolider votre compréhension des grands modèles de langage, tandis que le cours Building RAG Chatbots for Technical Documentation démontre une autre application pratique des agents d'intelligence artificielle. Si vous continuez à expérimenter avec des agents d'intelligence artificielle, vous pouvez également consulter de nouveaux outils tels que Mistral Agents API, Dify AI et Langflow.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach