Cursus
Principes fondamentaux de l'IA
10 h
Selon les exemples de Meta, les modèles peuvent analyser les graphiques intégrés dans les documents et résumer les principales tendances. Ils peuvent également interpréter des cartes, déterminer la partie la plus escarpée d'un sentier de randonnée ou calculer la distance entre deux points.
Cette intégration du raisonnement sur le texte et l'image offre un large éventail d'applications potentielles, notamment :
Les modèles de vision de Llama 3.2 sont ouverts et personnalisables. Les développeurs peuvent peaufiner les versions pré-entraînées et alignées de ces modèles à l'aide du logiciel Meta Torchtune de Meta.
De plus, ces modèles peuvent être déployés localement via Torchchatréduisant ainsi la dépendance à l'égard de l'informatique en nuage ("cloud"). cloud cloud et fournir une solution aux développeurs qui cherchent à déployer des systèmes d'IA sur site ou dans des environnements à ressources limitées.
Les modèles de vision sont également disponibles pour être testés par Meta AI, l'assistant intelligent de Meta.
Pour permettre aux modèles de vision du Llama 3.2 de comprendre à la fois le texte et les images, Meta a intégré un encodeur d'images préappris. codeur d'images dans le modèle de langage existant à l'aide d'adaptateurs spéciaux. Ces adaptateurs relient les données d'image aux parties du modèle consacrées au traitement de texte, ce qui lui permet de traiter les deux types d'entrée.
Le processus de formation a commencé avec le modèle linguistique Llama 3.1. Tout d'abord, l'équipe a entraîné le modèle sur de vastes ensembles d'images associées à des descriptions textuelles afin de lui apprendre à faire le lien entre les deux. Ensuite, ils l'ont affiné en utilisant des données plus propres et plus spécifiques afin d'améliorer sa capacité à comprendre et à raisonner sur un contenu visuel.
Dans les phases finales, Meta a utilisé des techniques telles que la mise au point et les données synthétiques pour s'assurer que le modèle donne des réponses utiles et se comporte en toute sécurité.
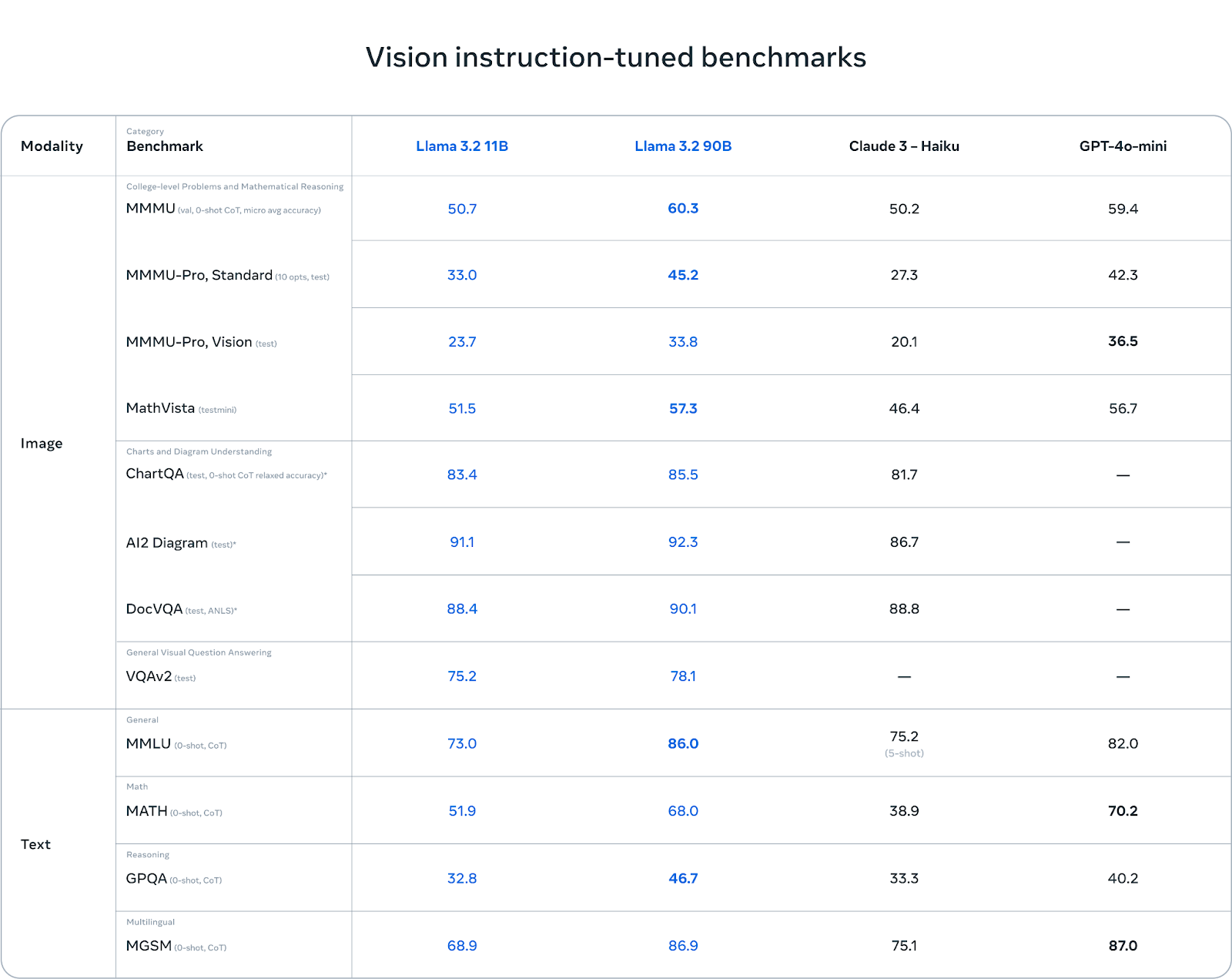
Les modèles de vision Llama 3.2 brillent par leur compréhension des graphiques et des diagrammes. Dans des tests de référence comme AI2 Diagram (92,3) et DocVQA (90,1), Llama 3.2 surpasse Claude 3 Haiku. Il s'agit donc d'un excellent choix pour les tâches impliquant la compréhension de documents, la réponse à des questions visuelles et l'extraction de données à partir de graphiques.
Dans les tâches multilingues (MGSM), Llama 3.2 obtient également de bons résultats, égalant presque GPT-4o-mini avec un score de 86,9, ce qui en fait une option solide pour les développeurs travaillant avec plusieurs langues.
Source : Meta AI
Si le Llama 3.2 obtient de bons résultats dans les tâches basées sur la vision, il est confronté à des difficultés dans d'autres domaines. Dans le MMMU-Pro Vision, qui teste le raisonnement mathématique sur des données visuelles, le GPT-4o-mini surpasse le Llama 3.2 avec un score de 36,5 contre 33,8 pour le Llama.
De même, dans le benchmark MATH, les performances de GPT-4o-mini (70,2) dépassent largement celles de Llama 3.2 (51,9), ce qui montre que Llama peut encore s'améliorer dans les tâches de raisonnement mathématique.
Une autre avancée significative de Llama 3.2 est l'introduction de modèles légers conçus pour les périphériques et les appareils mobiles. Ces modèles, avec 1 milliard et 3 milliards de paramètres, sont optimisés pour fonctionner sur du matériel plus petit tout en maintenant un compromis raisonnable sur la performance.
Ces modèles sont conçus pour fonctionner sur des appareils mobiles, offrant un traitement rapide et local sans qu'il soit nécessaire d'envoyer les données dans le cloud. L'exécution locale des modèles sur les appareils périphériques présente deux avantages principaux :
Les modèles légers de Llama 3.2 sont optimisés pour les processeurs Arm et sont compatibles avec le matériel Qualcomm et MediaTek, qui équipe de nombreux appareils mobiles et périphériques aujourd'hui.
Les modèles légers sont conçus pour une variété d'applications pratiques, sur l'appareil, telles que
1. Résumé : Les utilisateurs peuvent résumer de grandes quantités de texte, comme des courriels ou des notes de réunion, directement sur leur appareil sans dépendre de services cloud.
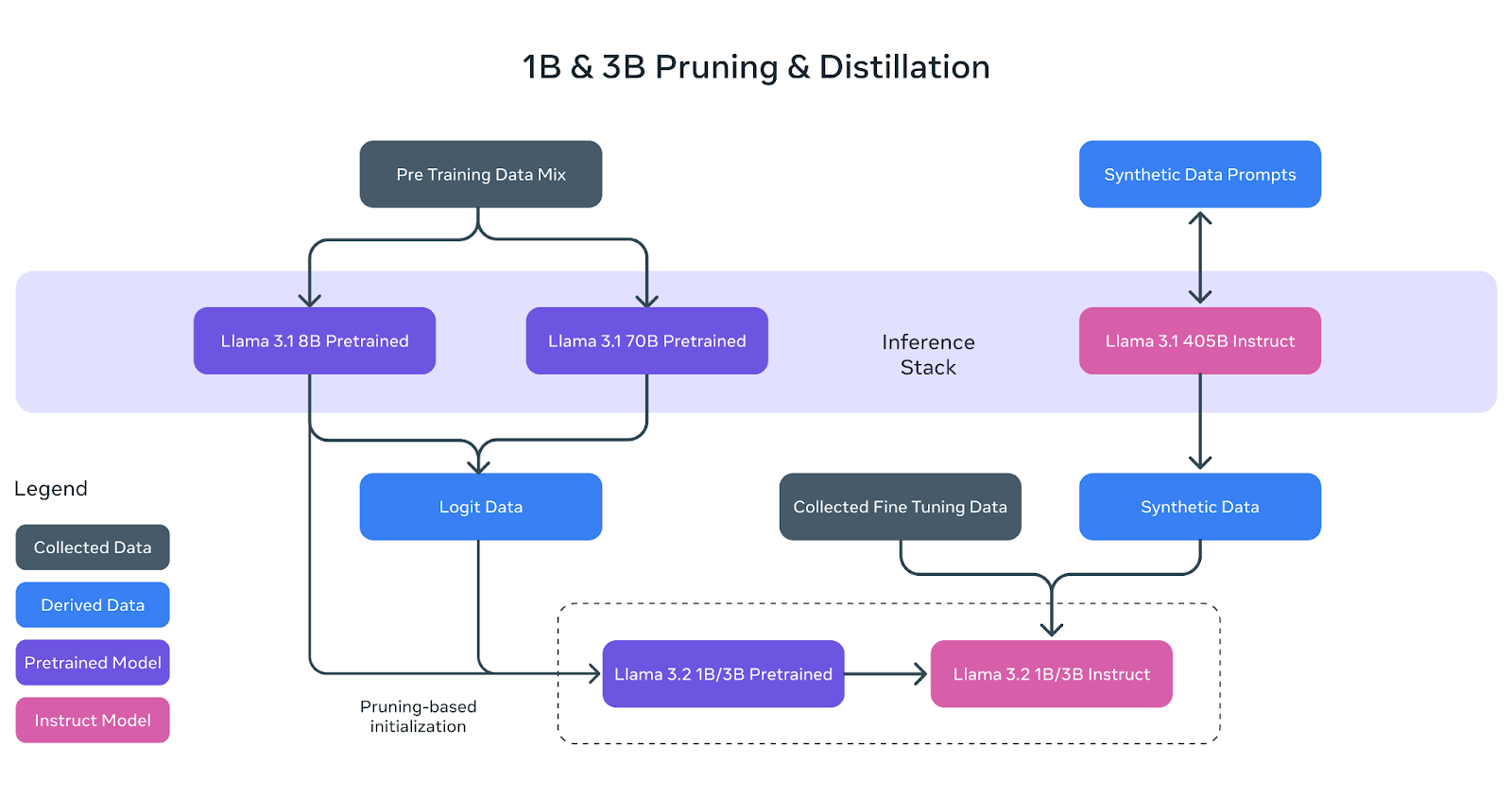
Les modèles légers Llama 3.2 (1B et 3B) ont été conçus pour s'adapter efficacement aux appareils mobiles et périphériques tout en conservant d'excellentes performances. Pour ce faire, Meta a utilisé deux techniques clés : l'élagage et la distillation.
Source : Meta AI
L'élagage permet de réduire la taille des modèles Llama originaux en supprimant les parties les moins critiques du réseau tout en conservant autant de connaissances que possible. Dans le cas des modèles 1B et 3B de Llama 3.2, ce processus a commencé par le modèle Llama 3.1 8B pré-entraîné.
En procédant à un élagage systématique, l'équipe de Meta AI a pu créer des versions plus petites et plus efficaces du modèle sans perte significative de performance. Ceci est représenté dans le diagramme ci-dessus où le modèle pré-entraîné 8B (boîte violette) est élagué et affiné pour devenir la base des petits modèles Llama 3.2 1B/3B.
La distillation est le processus de transfert des connaissances d'un modèle plus grand et plus puissant (le "professeur") à un modèle plus petit (l'"élève"). Dans le Llama 3.2, les logits (prédictions) des grands modèles Llama 3.1 8B et Llama 3.1 70B ont été utilisés pour enseigner les petits modèles.
De cette manière, les modèles 1B et 3B, plus petits, ont pu apprendre à effectuer des tâches plus efficacement, malgré leur taille réduite. Le diagramme ci-dessus montre comment ce processus utilise les données des logits des grands modèles pour guider les modèles 1B et 3B pendant le pré-entraînement.
Après l'élagage et la distillation, les modèles 1B et 3B ont fait l'objet d'un post-entraînement, comme les modèles Llama précédents. Cela a impliqué des techniques telles que l'ajustement supervisé, l'échantillonnage par rejet et l'optimisation des préférences directes pour aligner les résultats des modèles sur les attentes des utilisateurs.
Des données synthétiques ont également été générées pour s'assurer que les modèles pouvaient traiter un large éventail de tâches, telles que le résumé, la réécriture et le suivi des instructions.
Comme le montre le diagramme, les modèles d'instruction Llama 3.2 1B/3B finaux sont le résultat d'un élagage, d'une distillation et d'un post-entraînement intensif.
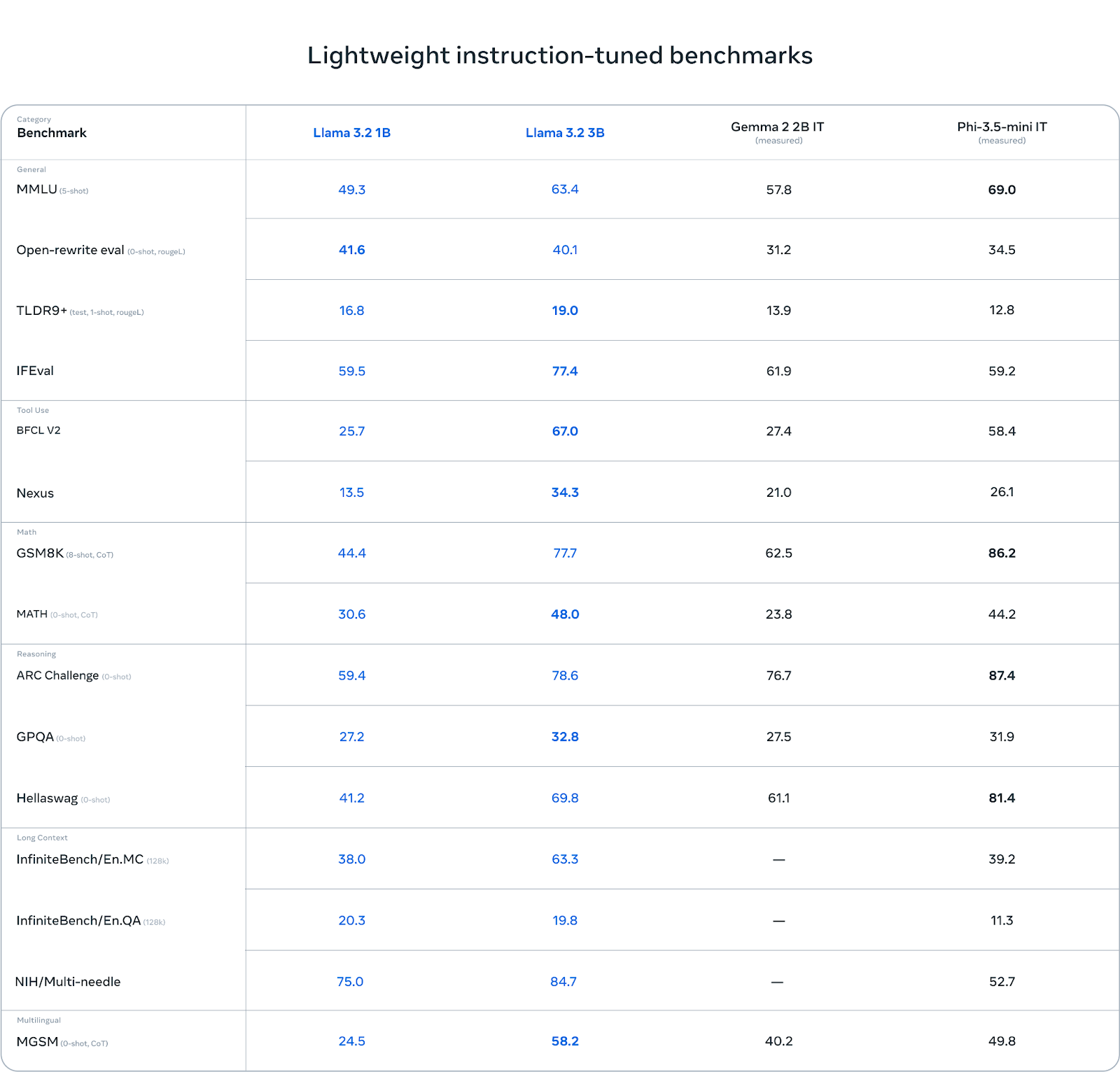
Le lama 3.2 3B se distingue dans certaines catégories, notamment dans les tâches de raisonnement. Par exemple, dans l'ARC Challenge, il obtient un score de 78,6, surpassant Gemma (76,7) et se situant légèrement derrière Phi-3.5-mini (87,4). De même, il obtient de bons résultats dans le benchmark Hellawag, avec 69,8, devançant Gemma et restant compétitif par rapport à Phi.
Dans les tâches d'utilisation d'outils comme BFCL V2, Llama 3.2 3B brille également avec un score de 67,0, devant ses deux concurrents. Cela montre que le modèle 3B gère efficacement le suivi des instructions et les tâches liées aux outils.
Source : Meta AI
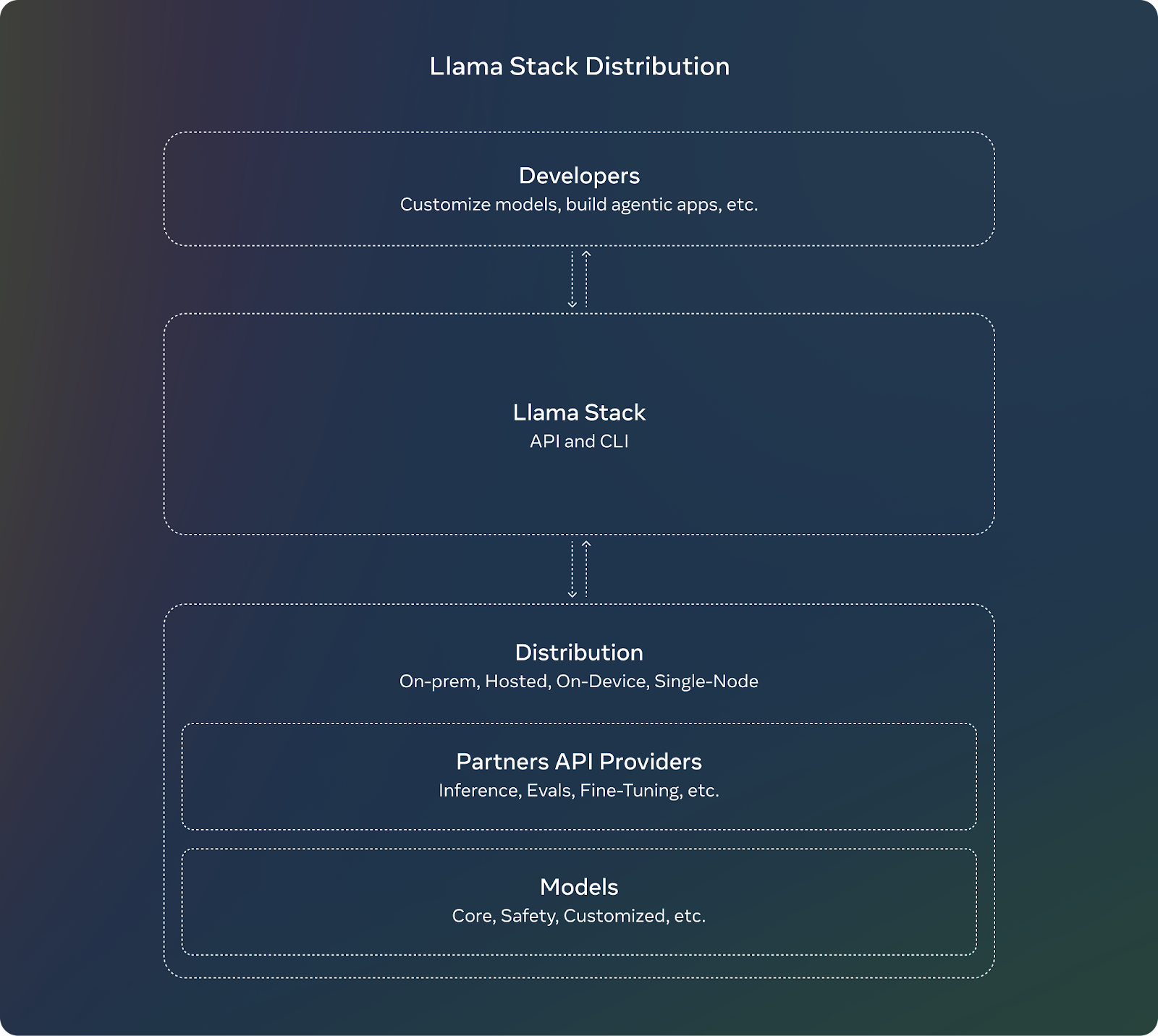
Pour compléter la sortie de Llama 3.2, Meta introduit la pile Llama. Pour les développeurs, l'utilisation de la pile Llama signifie qu'ils n'ont pas à se préoccuper des détails complexes de la mise en place ou du déploiement de grands modèles. Ils peuvent se concentrer sur la création de leurs applications et faire confiance à la pile Llama pour prendre en charge la plupart des tâches lourdes.
Telles sont les principales caractéristiques de la pile de lamas :
Source : Meta AI
Meta continue de mettre l'accent sur l l'IA responsable avec Llama 3.2. Le Llama Guard 3 a été mis à jour pour inclure une version avec vision qui prend en charge les nouvelles capacités multimodales du Llama 3.2. Cela permet de garantir que les applications utilisant les nouvelles fonctions de compréhension des images restent sûres et conformes aux principes suivants règles éthiques.
En outre, Llama Guard 3 1B a été optimisé pour être déployé dans des environnements où les ressources sont plus limitées, ce qui le rend plus petit et plus efficace que les versions précédentes.
L'accès aux modèles Llama 3.2 et leur téléchargement sont assez simples. Meta a mis ces modèles à disposition sur de multiples plateformes, notamment sur son propre site web et sur Hugging Face, une plateforme populaire d'hébergement et de partage de modèles d'IA.
Vous pouvez télécharger les modèles Llama 3.2 directement depuis le site officiel du Llama. Meta propose aux développeurs des modèles plus petits et légers (1B et 3B) et des modèles plus grands dotés d'une fonction de vision (11B et 90B).
Hugging Face est une autre plateforme où des modèles de lamas 3.2 sont disponibles. Il offre un accès facile et est couramment utilisé par les développeurs de la communauté de l'IA.
Les modèles Llama 3.2 sont disponibles pour un développement immédiat sur notre large écosystème de plateformes partenaires, notamment AMD, AWS, Databricks, Dell, Google Cloud, Groq, IBM, Intel, Microsoft Azure, NVIDIA, Oracle Cloud, Snowflake, et d'autres.
La version 3.2 de Llama de Meta présente les premiers modèles multimodaux de la série, en se concentrant sur deux domaines clés : les modèles basés sur la vision et les modèles légers pour les périphériques et les appareils mobiles.
Les modèles multimodaux 11B et 90B peuvent désormais traiter à la fois du texte et des images, tandis que les modèles 1B et 3B sont optimisés pour une utilisation locale efficace sur des appareils plus petits.
Dans cet article, je vous présente l'essentiel : le fonctionnement de ces modèles, leurs applications pratiques et la manière dont vous pouvez y accéder.
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min