
Cursus
Principes fondamentaux de l'intelligence artificielle dans le monde des affaires
12 h
Les modèles de raisonnement deviennent de plus en plus importants et courants, et nous comprenons pourquoi. Si vous regardez le graphique ci-dessous, vous remarquerez que 37,2 % des utilisateurs s'appuient sur Claude pour des questions de codage et de mathématiques, d'après l'Indice économique anthropique. Cela me dit une chose : des modèles de raisonnement solides peuvent apporter une réelle valeur ajoutée aux entreprises, d'autant plus que l'adoption de l'IA dans les entreprises reste faible.
Source : Indice économique antrophique
En même temps, Claude 3.7 n'est pas seulement un modèle de raisonnement, c'est un hybride. Nous pouvons basculer entre le mode réflexion (pour les tâches de raisonnement structuré) et un mode de discussion standard pour la conversation générale, la rédaction et le résumé.
Claude 3.7 Sonnet est une mise à jour bien plus importante que ne le laisse supposer le numéro de version. Les données de référence confirment qu'il surpasse Claude 3.5 Sonnet en matière de raisonnement, de codage et d'exécution de tâches dans le monde réel.
Claude 3.7 Sonnet montre un net avantage dans le domaine du génie logiciel, avec un score de précision de 62,3% dans le banc SWE vérifié, un bond significatif par rapport aux 49,0% de Claude 3.5 Sonnet. En utilisant un échafaudage personnalisé (une invite structurée ou un contexte supplémentaire qui aide à guider la réponse du modèle vers une solution plus précise), cette précision passe à 70,3 %, ce qui en fait le modèle le plus performant dans cette catégorie.
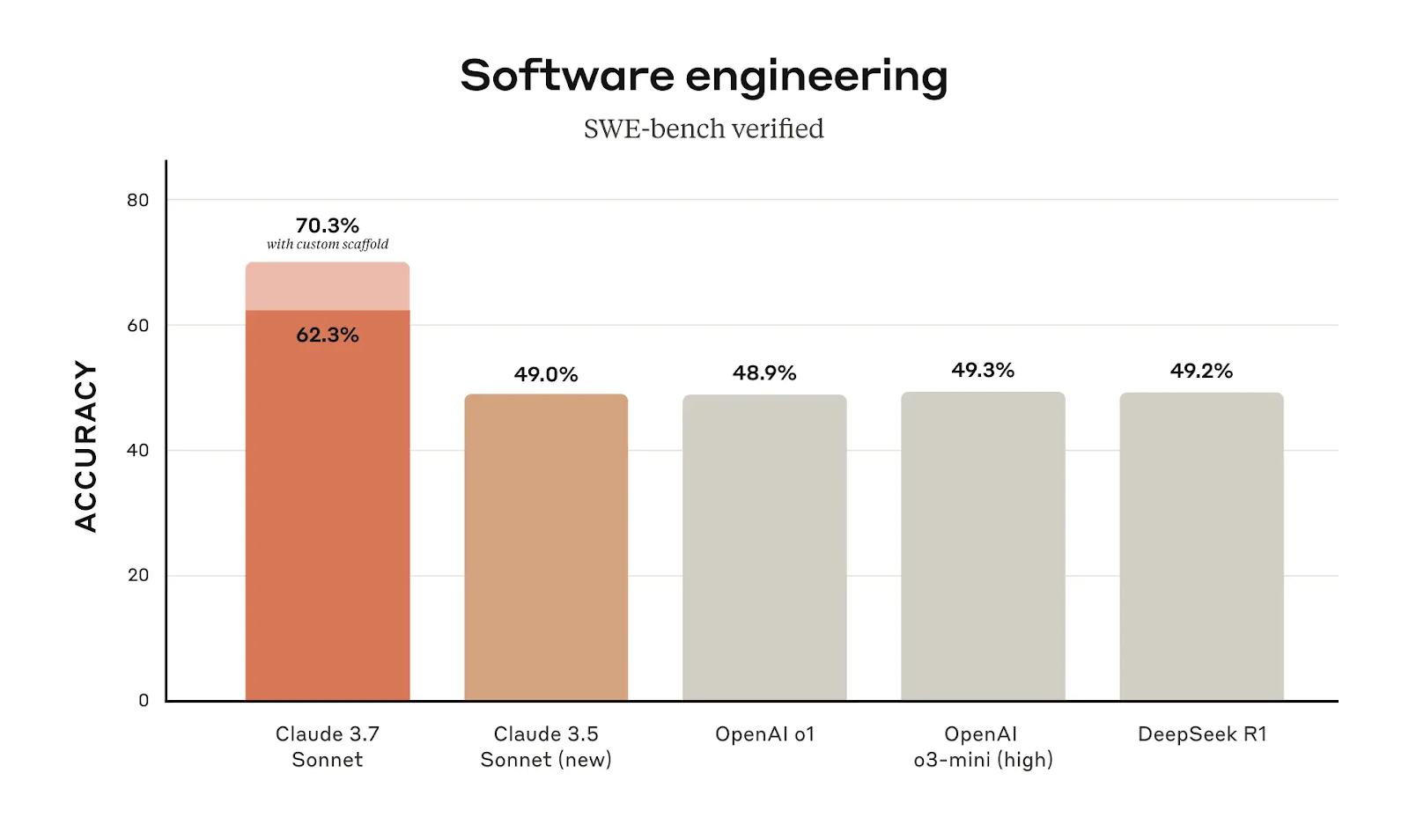
Source : Anthropique
Une amélioration de près de 13 % de la précision entre les versions du modèle n'est pas un simple raffinement. Cela suggère que Claude 3.7 Sonnet a été optimisé pour une meilleure compréhension et exécution des tâches liées à la programmation. Pour les utilisateurs qui utilisent Claude pour l'ingénierie logicielle, le débogage ou l'automatisation, la mise à jour fait une différence tangible.
La performance dans l'utilisation des outils agentiques est un autre domaine dans lequel Claude 3.7 Sonnet surpasse son prédécesseur. Dans les tâches liées à la vente au détail, il atteint une précision de 81,2 %, contre 71,5 % pour Claude 3.5 Sonnet. Dans les tâches liées aux compagnies aériennes, il obtient un score de 58,4 %, soit une amélioration de près de dix points par rapport à la version précédente.
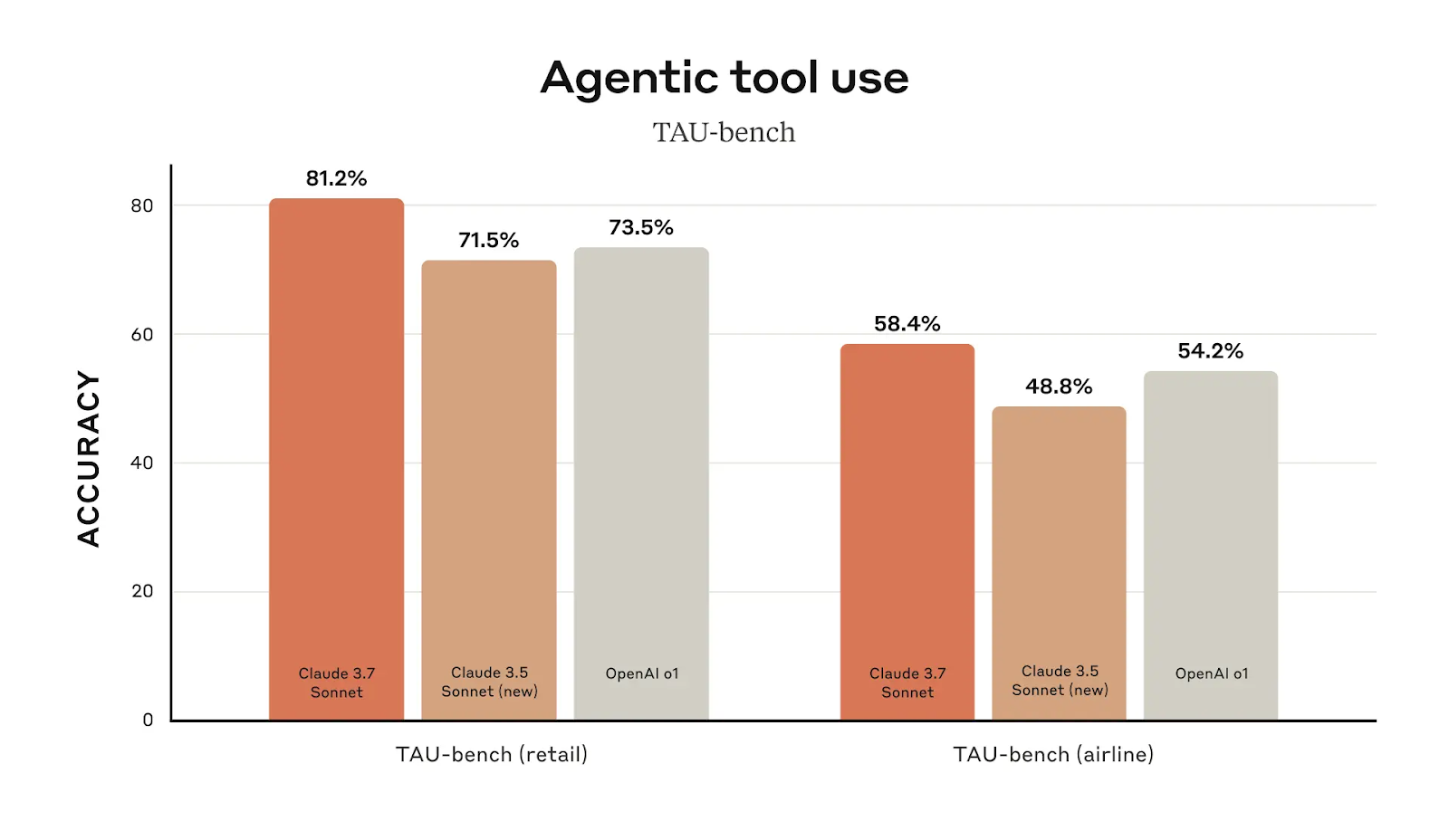
Source : Anthropique
Sur l'ensemble des critères, les gains les plus importants proviennent du mode de réflexion étendu, qui permet à Claude 3.7 d'atteindre un niveau de performance beaucoup plus élevé dans les tâches de raisonnement complexes. Les utilisateurs qui s'appuient sur l'IA pour des flux de travail structurés, le codage ou la résolution de problèmes verront une nette différence entre Claude 3.5 et Claude 3.7, en particulier lors de l'utilisation de la pensée élargie.
Source : Anthropique
La plupart de ces progrès sont dus à la pensée élargie de Claude.
Lorsqu'il est activé, le mode de réflexion approfondie augmente le nombre d'étapes de raisonnement que Claude effectue avant de finaliser une réponse. Les développeurs peuvent affiner ce processus en fixant un budget de réflexion, qui définit le nombre de jetons que le modèle peut utiliser pour résoudre un problème. Comme le montre le graphique des performances de l'AIME 2024 ci-dessous, la précision s'améliore au fur et à mesure que le nombre de jetons alloués augmente, suivant une tendance logarithmique.
Source : Anthropique
Cette approche reflète l'effort cognitif humain : pour les tâches simples, des réponses rapides suffisent, mais pour les tâches complexes, une analyse plus approfondie permet d'obtenir de meilleurs résultats. Claude peut désormais décider de faire une pause, de réévaluer et d'affiner son raisonnement plutôt que de réagir immédiatement par défaut.
L'un des aspects les plus intéressants du mode de réflexion étendu est que le processus de raisonnement de Claude est visible pour l'utilisateur. Cette caractéristique soulève toutefois quelques difficultés. Bien qu'il donne un aperçu du raisonnement de l'IA, le processus de pensée affiché ne correspond pas toujours parfaitement à la façon dont le modèle prend réellement ses décisions. Le "problème de la fidélité" - à savoir si les pensées déclarées par une IA représentent fidèlement ses mécanismes internes - reste une question de recherche ouverte.
Claude 3.7 La capacité de Sonnet à s'engager dans un raisonnement itératif à long terme est testée dans des évaluations telles que OSWorld et le jeu Pokémon Red. Dans Pokémon Rouge, par exemple, Claude 3.7 Sonnet progresse beaucoup plus vite dans le jeu que les versions précédentes, franchissant plusieurs étapes alors que les modèles antérieurs restaient bloqués au début du jeu.
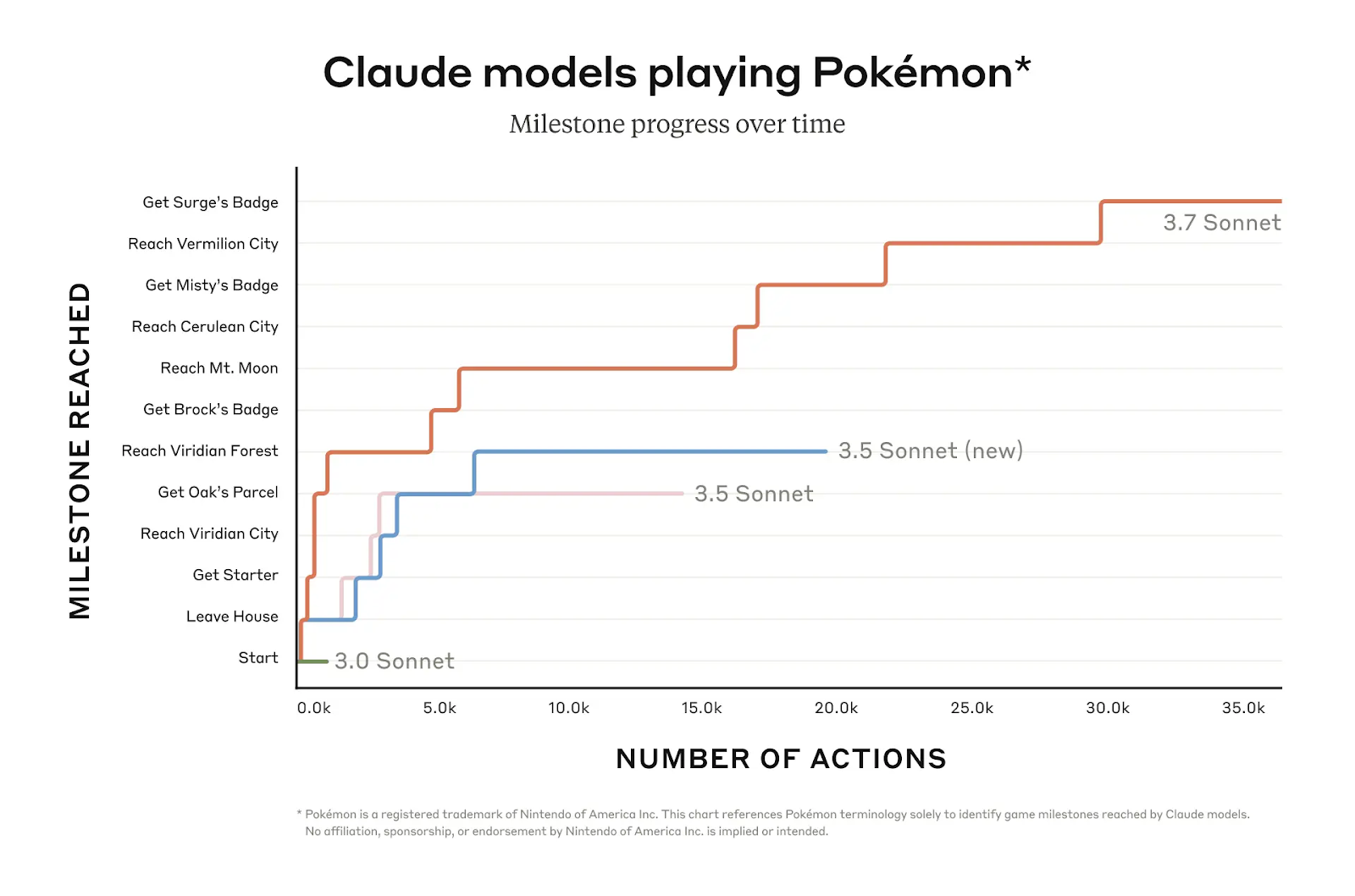
Source : Anthropique
Nous avons vu comment Claude 3.7 Sonnet se comporte par rapport à sa version précédente, mais comment se compare-t-il à o3-mini d'OpenAI, DeepSeek-R1, ou Grok 3 ?
Si l'on examine les nouveaux critères, Claude 3.7 Sonnet s'est positionné comme l'un des modèles les plus performants, en particulier pour les tâches de raisonnement, le codage et l'utilisation d'outils agentiques.
Dans le raisonnement de niveau supérieur (GPQA Diamond), Claude 3.7 Sonnet obtient un score de 68,0 % en mode standard et de 84,8 % en mode de réflexion étendue, ce qui en fait l'un des modèles les plus forts dans cette catégorie. Il surpasse o1 (78,0 %) et DeepSeek-R1 (71,5 %) d'OpenAI d'une manière significative et Grok 3 Beta (84,6 %) d'une petite marge .
|
Référence |
Claude 3.7 Sonnet (standard) |
Claude 3.7 Sonnet (réflexion approfondie) |
OpenAI o1 |
OpenAI o3-mini (haut) |
DeepSeek R1 |
Grok 3 Beta |
|
GPQA Diamond (raisonnement au niveau du diplôme) |
68.0% |
84.8% |
78.0% |
79.7% |
71.5% |
84.6% |
|
AIME 2024 (Concours de mathématiques pour les lycées) |
23.3% |
80.0% |
83.3% |
87.3% |
79.8% |
93.3% |
|
Résolution de problèmes mathématiques (MATH 500) |
82.2% |
96.2% |
96.4% |
97.9% |
97.3% |
- |
L'indice de référence AIME 2024, qui teste les problèmes de concours de mathématiques de l'enseignement secondaire, montre une tendance similaire. Claude 3.7 Sonnet fait un grand bond en avant par rapport aux versions précédentes, obtenant un score de 80,0 % avec l'option de réflexion étendue activée. Bien qu'il dépasse DeepSeek-R1 (79,8 %) d'une petite marge, il reste à la traîne derrière o3-mini d'OpenAI (87,3 %) et Grok 3 Beta (93,3 %).
En résolution de problèmes mathématiques (MATH 500), Claude 3.7 Sonnet obtient 96,2 %, ce qui le rapproche de OpenAI's o3-mini (97,9 %) et de DeepSeek R1 (97,3 %).
Claude 3.7 Sonnet réalise ses gains les plus importants dans les benchmarks de codage. Sur SWE-bench Verified (qui évalue les modèles d'IA sur des tâches de génie logiciel), Claude 3.7 Sonnet obtient un score de 62,3 %, qui passe à 70,3 % avec un échafaudage personnalisé. Il devance ainsi largement les modèles o1 (48,9 %) et o3-mini (49,3 %) d'OpenAI, ainsi que DeepSeek R1 (49,2 %), qui a été conçu dans une optique de codage. Cela confirme que Claude 3.7 est désormais l'un des meilleurs models d'IA pour les tâches liées à la programmation.
|
Référence |
Claude 3.7 Sonnet (standard) |
Claude 3.7 Sonnet (échafaudage personnalisé) |
OpenAI o1 |
OpenAI o3-mini (haut) |
DeepSeek R1 |
|
Banc d'essai SWE vérifié (codage) |
62.3% |
70.3% |
48.9% |
49.3% |
49.2% |
|
TAU-bench Retail (Tool Use) |
81.2% |
- |
73.5% |
- |
- |
|
TAU-bench Airline (utilisation d'outils) |
58.4% |
- |
54.2% |
- |
- |
Au-delà du codage, Claude 3.7 Sonnet est en tête pour l'utilisation d'outils agentiques, ce qui en fait un choix judicieux pour l'automatisation et l'exécution de flux de travail. Sur TAU-bench (qui teste la capacité de l'IA à interagir avec des outils externes dans des environnements structurés), Claude 3.7 obtient un score de 81,2 % dans les tâches liées au commerce de détail, dépassant OpenAI o1 (73,5 %). Dans les tâches liées aux compagnies aériennes, Claude 3.7 atteint 58,4 %, dépassant à nouveau OpenAI o1 (54,2 %).
Cela suggère que Claude 3.7 est bien adapté aux applications professionnelles et aux flux de travail structurés, ce qui en fait un choix judicieux pour les utilisateurs professionnels qui cherchent à intégrer l'IA dans leurs processus décisionnels et opérationnels.
Claude 3.7 Sonnet est disponible via plusieurs canaux, notamment l'interface web d'Anthropic, l'intégration de Claude dans diverses applications et l'accès API pour les développeurs. Bien que ce modèle constitue une mise à jour importante, sa disponibilité s'accompagne de certaines limitations, en particulier si vous souhaitez utiliser le mode Réflexion, qui est actuellement réservé à un niveau payant.
Pour les utilisateurs généraux, Claude 3.7 Sonnet est accessible via le site officiel d'Anthropic (claude.ai) et l'application Claude. Il est disponible dans la version gratuite, mais avec des restrictions :
Pour activer le mode réflexion, vous devez cliquer sur Étendu dans le menu déroulant du modèle :
Les développeurs peuvent intégrer Claude 3.7 Sonnet dans leurs applications en utilisant l'API d'Anthropic, accessible via le portail développeur d'Anthropic. L'API prend en charge un modèle de tarification à la carte basé sur l'utilisation de jetons.
Voici un aperçu de l'offre d'API d'Anthropic :
|
Fonctionnalité |
Claude 3.7 Sonnet |
Claude 3.5 Sonnet |
Claude 3.5 Haïku |
Claude 3 Opus |
Claude 3 Haiku |
|
Description |
Notre modèle le plus intelligent |
Notre précédent modèle le plus intelligent |
Notre modèle le plus rapide |
Un modèle puissant pour des tâches complexes |
Modèle le plus rapide et le plus compact pour une réactivité quasi instantanée |
|
Points forts |
Le niveau le plus élevé d'intelligence et de capacité avec la possibilité de basculer vers un mode de pensée élargi |
Niveau élevé d'intelligence et de capacité |
L'intelligence à la vitesse de l'éclair |
Intelligence, aisance et compréhension de haut niveau |
Des performances ciblées, rapides et précises |
|
Multilingue |
Oui |
Oui |
Oui |
Oui |
Oui |
|
Vision |
Oui |
Oui |
Oui |
Oui |
Oui |
|
Oui |
Non |
Non |
Non |
Non |
|
|
Nom du modèle API |
claude-3-7-sonnet-20250219 |
Version mise à jour : claude-3-5-sonnet-20241022 Version précédente : claude-3-5-sonnet-20240620 |
claude-3-5-haiku-20241022 |
claude-3-opus-20240229 |
claude-3-haiku-20240307 |
|
Temps de latence comparatif |
Rapide |
Rapide |
Fastest |
Moyennement rapide |
Fastest |
|
Fenêtre contextuelle |
200K |
200K |
200K |
200K |
200K |
|
Sortie maximale |
Normal : 8192 jetons Réflexion élargie: 64000 jetons |
8192 jetons |
8192 jetons |
4096 jetons |
4096 jetons |
|
Coût (intrants / extrants par MTok) |
$3.00 / $15.00 |
$3.00 / $15.00 |
$0.80 / $4.00 |
$15.00 / $75.00 |
$0.25 / $1.25 |
|
Coupure des données d'apprentissage |
Oct. 2024 |
Avril 2024 |
juillet 2024 |
Août 2023 |
Août 2023 |
Source: Anthropique
Veillez à toujours vérifier les derniers prix de l'API.
Anthropic vient de faire sa plus grande avancée depuis un certain temps avec Claude 3.7 Sonnet, un modèle qui l'amène enfin dans l'espace de l'IA raisonnante. Sur la base des benchmarks, nous pouvons constater qu'il s'agit d'un concurrent légitime des OpenAI o3-mini, DeepSeek-R1 et Grok 3, avec de solides performances en matière de codage, de résolution de problèmes structurés et d'utilisation d'outils agentiques.
La possibilité de basculer entre le mode généraliste et le mode raisonnement le rend plus polyvalent, mais enfermer le Mode Réflexion derrière un mur payant semble être une erreur, surtout si l'on considère les alternatives gratuites disponibles. Claude 3.7 constitue néanmoins une avancée majeure.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours
blog
Kurtis Pykes
15 min
blog
Tutoriel
Mark Pedigo
Tutoriel
Samuel Shaibu
Tutoriel
Moez Ali
