
Cursus
Développer des applications d'IA
21 h
De nombreux scientifiques des données et ingénieurs en apprentissage automatique sont confrontés à des difficultés avec des outils tels que Docker, Kubernetes et Terraform, ainsi qu'à la mise en place d'une infrastructure sécurisée pour les modèles d'IA.
BentoML simplifie ce processus, en vous permettant de construire, servir et déployer des applications d'IA avec seulement quelques lignes de code Python.
Ce tutoriel est un guide étape par étape destiné aux personnes souhaitant déployer leur propre application d'IA, accessible partout via une simple commande CURL. Vous découvrirez le cadre BentoML, la création locale d'une application d'IA de réponse aux questions et le déploiement du mini-modèle Phi 3 sur BentoCloud.
BentoML est un cadre de service et de déploiement de l'apprentissage automatique qui rationalise le déploiement et la mise à l'échelle des modèles d'IA. Il automatise des tâches telles que la création d'images Docker, la configuration d'instances, la gestion de l'infrastructure et de la sécurité, ainsi que les fonctionnalités essentielles requises pour un serveur prêt à la production.
Avec BentoML, vous pouvez développer et déployer des modèles d'IA personnalisés, des modèles pré-entraînés ou des solutions affinées en quelques minutes avec un simple code Python. Il offre la flexibilité nécessaire pour évoluer efficacement au sein de votre environnement cloud tout en vous garantissant un contrôle total sur la sécurité et la conformité.
BentoML fait partie de l'ensemble d'outils MLOps. Découvrez d'autres outils MLOps de premier plan pour la formation, le suivi, le déploiement, l'orchestration, les tests, la surveillance et la gestion de l'infrastructure en lisant le blog Les 15 meilleurs outils LLMOps pour la création d'applications d'IA en 2024.
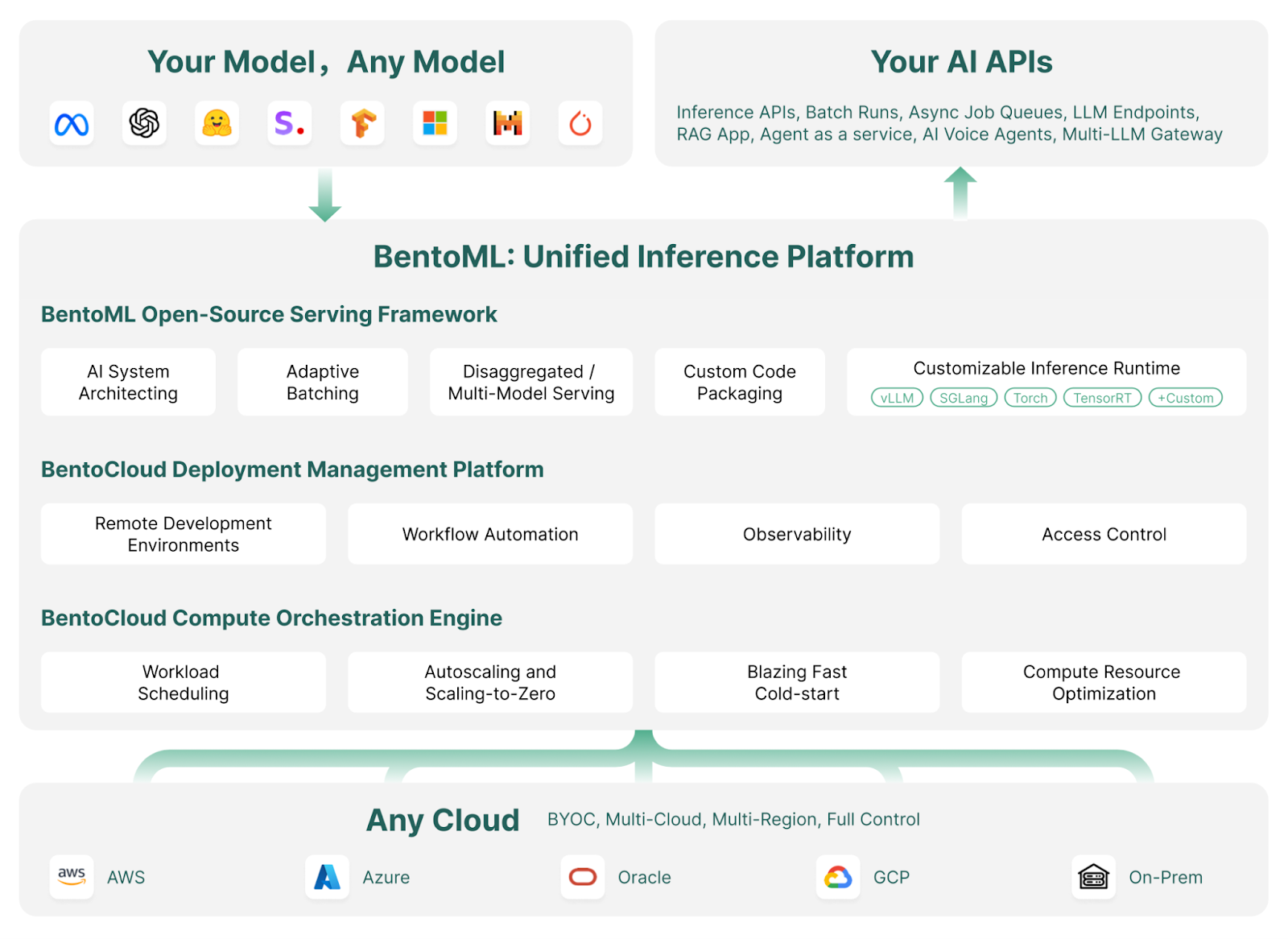
Comment fonctionne BentoML | Source de l'image : BentoML
L'étoile brillante de l'écosystème Bento est son cloud : BentoCloud est une extension du cadre de BentoML, offrant des outils et des services supplémentaires pour faciliter le déploiement, la surveillance et la mise à l'échelle des modèles d'IA.
En s'inscrivant, les utilisateurs peuvent accéder à des crédits gratuits pour commencer, ce qui en fait une option intéressante pour les développeurs et les entreprises.
Si vous êtes une personne non technique à la recherche d'une solution "no-code" ou "low-code" pour développer une application LLM, je vous recommande de suivre le guide Local AI with Docker, n8n, Qdrant, and Ollama.
Dans cette section, nous présenterons une application d'IA simple qui prend en compte les questions et le contexte de l'utilisateur et génère une réponse.
Nous commencerons par installer BentoML, PyTorch et la bibliothèque Transformers à l'aide de pip. Exécutez les commandes suivantes dans votre terminal :
$ pip install bentoml
$ pip install torch
$ pip install transformersEnsuite, nous allons créer un fichier service.py pour définir le serveur AI.
En utilisant les commandes BentoML, nous importerons le pipeline Transformers, qui nous permet de charger le modèle et d'effectuer l'inférence avec seulement deux lignes de code.
Nous allons mettre en place des exemples d'entrées de texte et de contexte, configurer le service BentoML avec des paramètres tels que le nombre de CPU et le délai d'attente du trafic, et initialiser la classe Question_Answering à l'aide du pipeline Transformers.
Enfin, nous allons créer une API appelée generate(), qui prend des entrées et des sorties et renvoie la réponse générée.
from __future__ import annotations
import bentoml
with bentoml.importing():
from transformers import pipeline
EXAMPLE_INPUT = "How can I generate a secure password?"
EXAMPLE_CONTEXT = """
To generate a secure password, you can use tools like the LastPass Password Generator.
These tools create strong, random passwords that help prevent security threats by ensuring your accounts are protected against hacking attempts.
A secure password typically includes a mix of uppercase and lowercase letters, numbers, and special characters. Avoid using easily guessable information like names or birthdays.
Using a password manager like LastPass can also help you store and manage these secure passwords effectively.
"""
@bentoml.service(
resources={"cpu": "4"},
traffic={"timeout": 10},
)
class Question_Answering:
def __init__(self) -> None:
# Load model into pipeline
self.pipe = pipeline(
"question-answering",
model="deepset/roberta-base-squad2",
)
@bentoml.api
def generate(
self,
text: str =EXAMPLE_INPUT,
doc: str = EXAMPLE_CONTEXT,
) -> str:
result = self.pipe(question=text, context=doc)
return result["answer"]Servez le service AI localement en tapant la commande suivante dans le terminal :
$ bentoml serve service:Question_Answering Comme vous pouvez le voir, nous avons fourni à la commande ci-dessus le nom du fichier (service) et le nom de la classe Python (Question_Answering ) pour l'inférence du modèle d'IA.
En quelques secondes, il génère une URL que vous pouvez copier et coller sur le navigateur pour accéder au serveur BentoML :
[cli] Starting production HTTP BentoServer from "app:Question_Answering" listening on http://localhost:3000 (Press CTRL+C to quit)Le serveur BentoML est assez similaire à l'interface swagger de FastAPI.
Testons notre serveur en utilisant l'option "Try it out".
Notre service d'IA fonctionne bien et a généré une réponse précise :
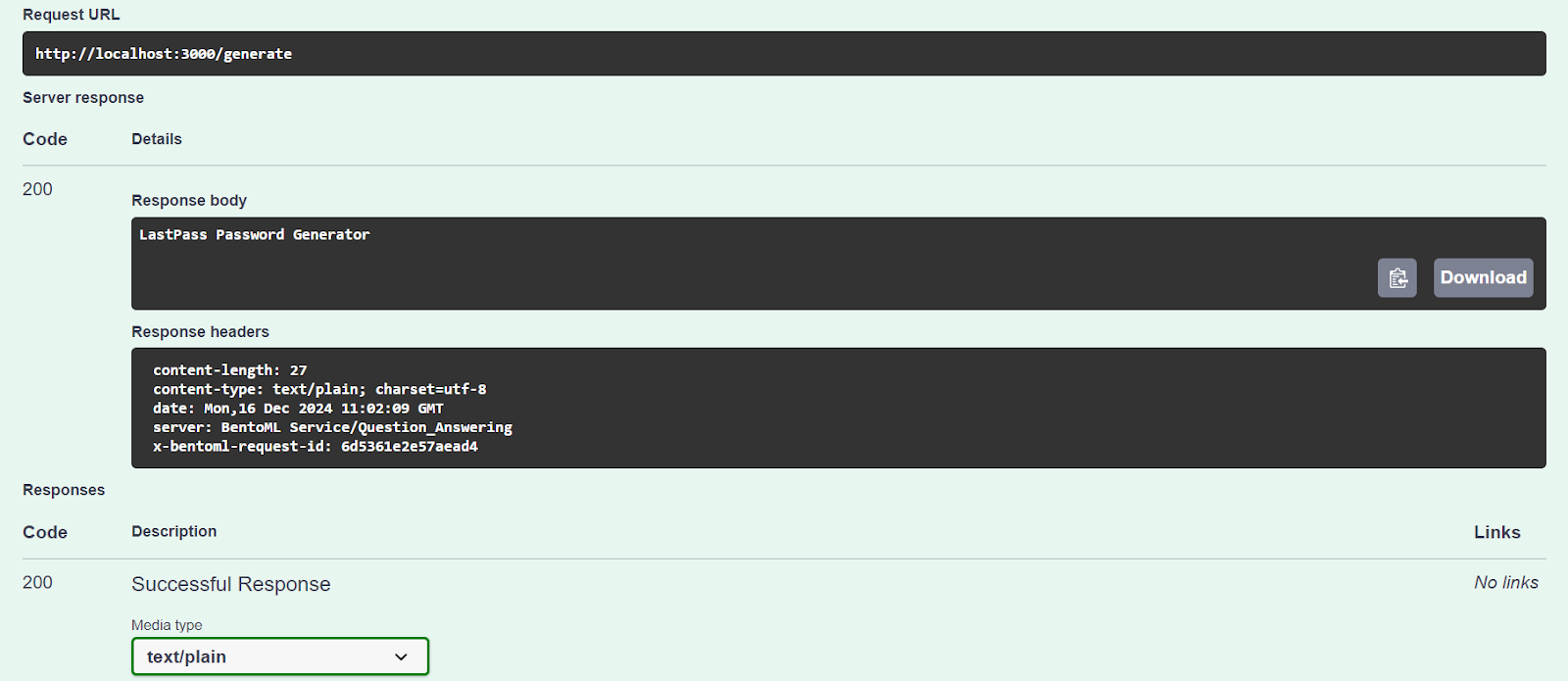
Nous pouvons également accéder au serveur AI à l'aide de la commande CURL. Posons une autre question et replaçons-la dans son contexte :
curl -X 'POST' \
'http://localhost:3000/generate' \
-H 'accept: text/plain' \
-H 'Content-Type: application/json' \
-d '{
"text": "How can I buy a cheap car?",
"doc": "Start by setting a budget and exploring sources like online marketplaces (Craigslist, Facebook Marketplace, Cars.com), local dealerships, or government auctions. Inspect the car thoroughly for issues like rust or mechanical problems, and consider bringing a trusted mechanic to avoid future repair costs. Research the reliability of specific brands and models using tools like Kelley Blue Book or Consumer Reports. Finally, negotiate the price to secure the best deal. Following these steps can help you find a dependable car within your budget."
}'Notre service d'IA fonctionne sans problème, et il a fallu une seconde pour générer une réponse, même avec l'unité centrale :
negotiate the priceIl est temps de construire une application d'IA à grand modèle de langage (LLM) et de la déployer sur BentoML avec un minimum d'efforts et de ressources.
Nous utiliserons le framework vLLM pour créer une inférence LLM à haut débit et la déployer sur une instance GPU sur BentoCloud. Bien que cela puisse paraître complexe, BentoCloud se charge de la plupart des tâches lourdes, y compris la mise en place de l'infrastructure, afin que vous puissiez vous concentrer sur la création et le déploiement de votre service.
BentoML propose de nombreux exemples de code et de ressources pour divers projets LLM. Pour commencer, nous allons cloner le dépôt BentoVLLM.
Naviguez vers le projet Python 3 Mini 4k, et installez toutes les bibliothèques Python requises :
$ git clone https://github.com/bentoml/BentoVLLM.git
$ cd BentoVLLM/phi-3-mini-4k-instruct
$ pip install -r requirements.txtVoici à quoi ressemble le répertoire du projet avec tous les fichiers :
Nous modifierons le site bentofile.yaml pour changer le nom du propriétaire et le nom de scène.
Le site bentofile.yaml est plus simple que le site Dockerfile et utilise différentes commandes pour configurer l'infrastructure, l'environnement et les configurations du serveur ; vous pouvez apprendre toutes les commandes à partir des options de construction de Bento.
service: 'service:VLLM'
labels:
owner: Abid
stage: Guide
include:
- '*.py'
- 'bentovllm_openai/*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"service.py fichierNous ne modifierons pas le fichier service.py, mais nous apprendrons à le connaître.
@bentoml.service pour gérer le déploiement et la gestion des ressources, comme la configuration des GPU et la gestion du trafic.generate est définie à l'aide du décorateur @bentoml.api. Il prend en entrée une invite de l'utilisateur, une invite facultative du système et une limite maximale de jetons, qui sont ensuite fournies au moteur d'inférence vLLM pour générer la réponse. generate diffuse les résultats du modèle par morceaux, en générant des jetons dès qu'ils sont disponibles.import uuid
from typing import AsyncGenerator, Optional
import bentoml
from annotated_types import Ge, Le
from typing_extensions import Annotated
from bentovllm_openai.utils import openai_endpoints
MAX_TOKENS = 1024
PROMPT_TEMPLATE = """<|system|>
{system_prompt}<|end|>
<|user|>
{user_prompt}<|end|>
<|assistant|>
"""
SYSTEM_PROMPT = """You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."""
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
@openai_endpoints(model_id=MODEL_ID)
@bentoml.service(
name="bentovllm-phi-3-mini-4k-instruct-service",
traffic={
"timeout": 300,
"concurrency": 256, # Matches the default max_num_seqs in the VLLM engine
},
resources={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
)
class VLLM:
def __init__(self) -> None:
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_TOKENS,
dtype="half",
enable_prefix_caching=True,
disable_sliding_window=True,
)
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
@bentoml.api
async def generate(
self,
prompt: str = "Explain superconductors in plain English",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
from vllm import SamplingParams
SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens)
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
prompt = PROMPT_TEMPLATE.format(user_prompt=prompt, system_prompt=system_prompt)
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Je vous recommande de suivre le cursus de compétences Développer des applications d'IA pour apprendre à créer des applications alimentées par l'IA avec les derniers outils de développement d'IA, notamment l'API OpenAI, Hugging Face et LangChain.
Allez sur le site bentofile.yaml et ajoutez la variable d'environnement pour le jeton Hugging Face à la dernière ligne. Cela nous aidera à charger le modèle en toute sécurité sans problème à partir du serveur Hugging Face :
envs:
- name: HF_TOKENConnectez-vous à BentoCloud à l'aide du CLI :
$ bentoml cloud loginIl vous demandera de créer un compte, puis de créer un jeton API.
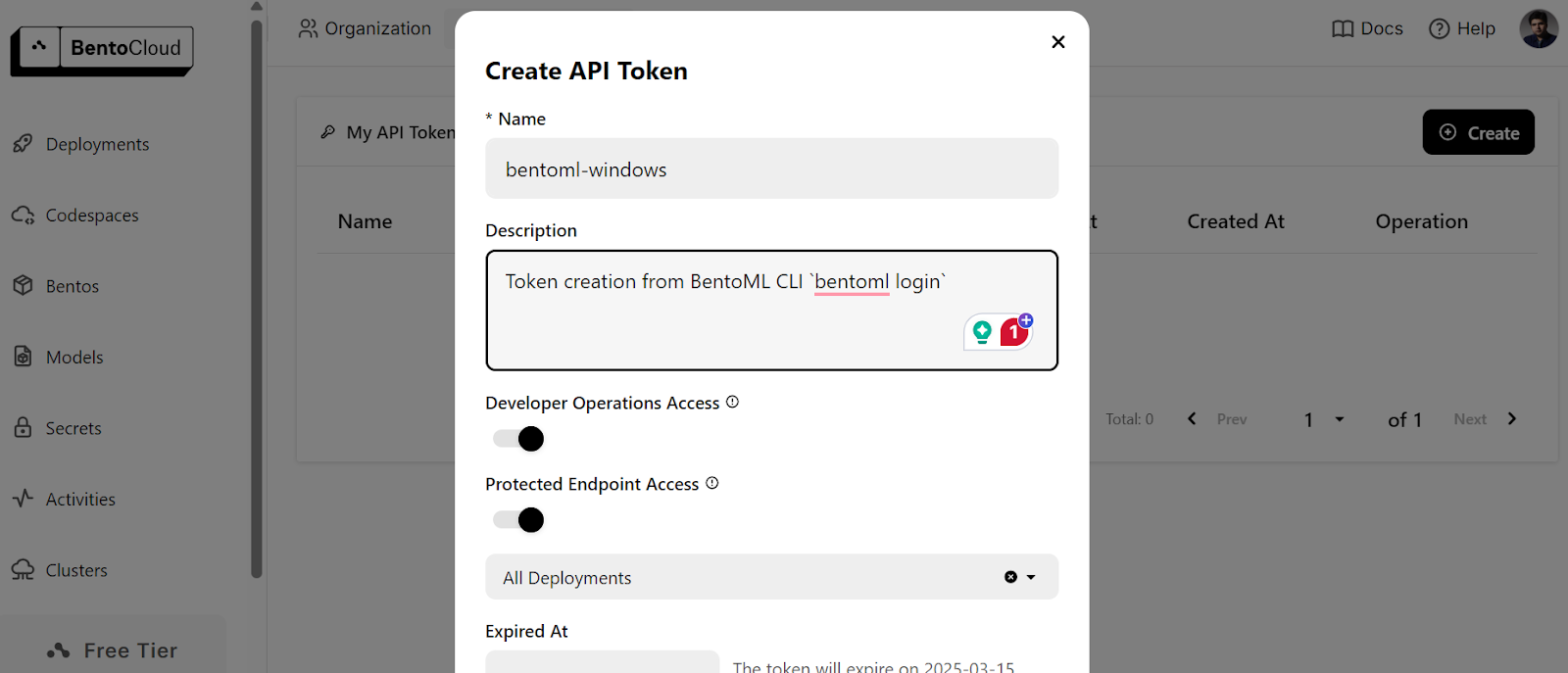
Après avoir créé avec succès le jeton API, vous verrez le message de réussite dans votre terminal :

Avant de déployer le service d'IA sur BentoCloud, nous devons créer une variable d'environnement dans BentoCloud en allant dans l'onglet " Secrets " et en fournissant le nom de la clé et la clé API de Hugging Face.
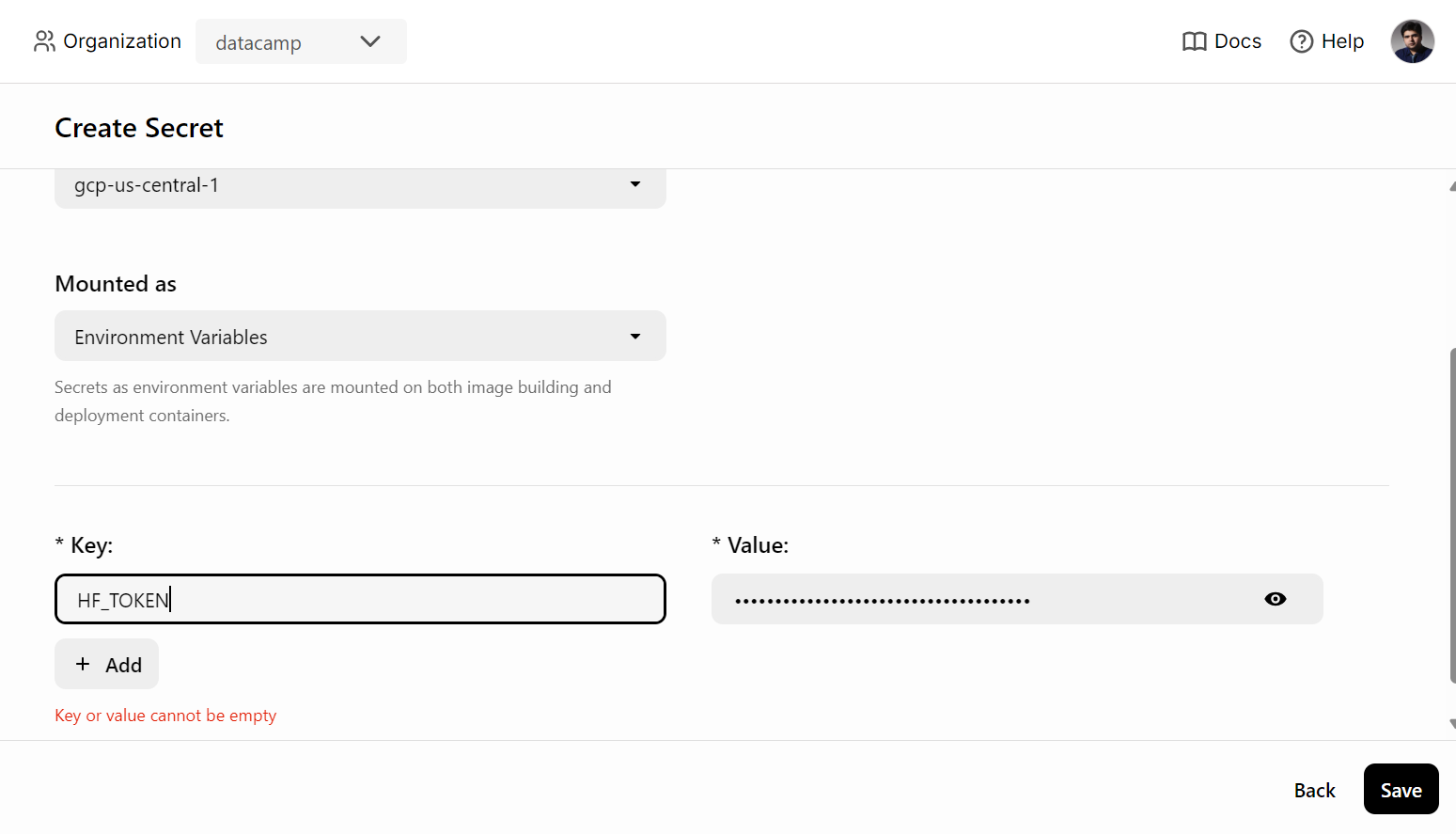
Ensuite, utilisez la commande suivante pour déployer le service AI :
$ bentoml deploy . --secret huggingfaceLe téléchargement du modèle et la mise en place de l'environnement nécessaire à l'exécution du serveur prendront quelques minutes.

Vous pouvez vérifier l'état de votre service AI en allant dans l'onglet "Déploiements".
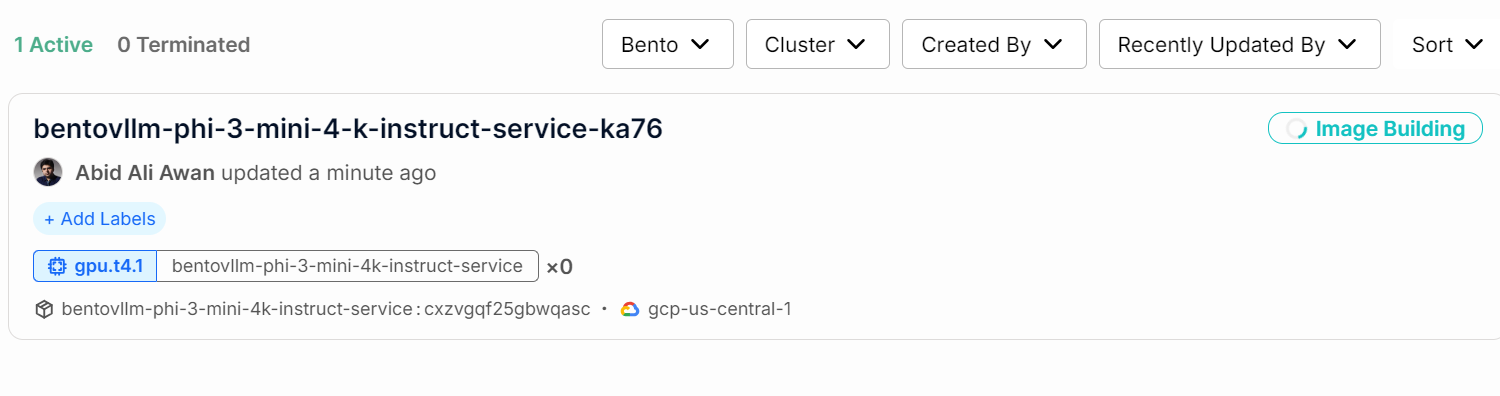
Vous pouvez également consulter tous les journaux et observer ce qui se passe en arrière-plan.
Une fois le service AI déployé avec succès, nous commencerons à tester le service vLLM Phi 3 Mini.
Pour commencer, nous pouvons simplement cliquer sur l'onglet "Playground" sous l'option "Deployments", saisir l'invite et cliquer sur le bouton "submit" pour générer la réponse. La réponse sera diffusée en temps réel.
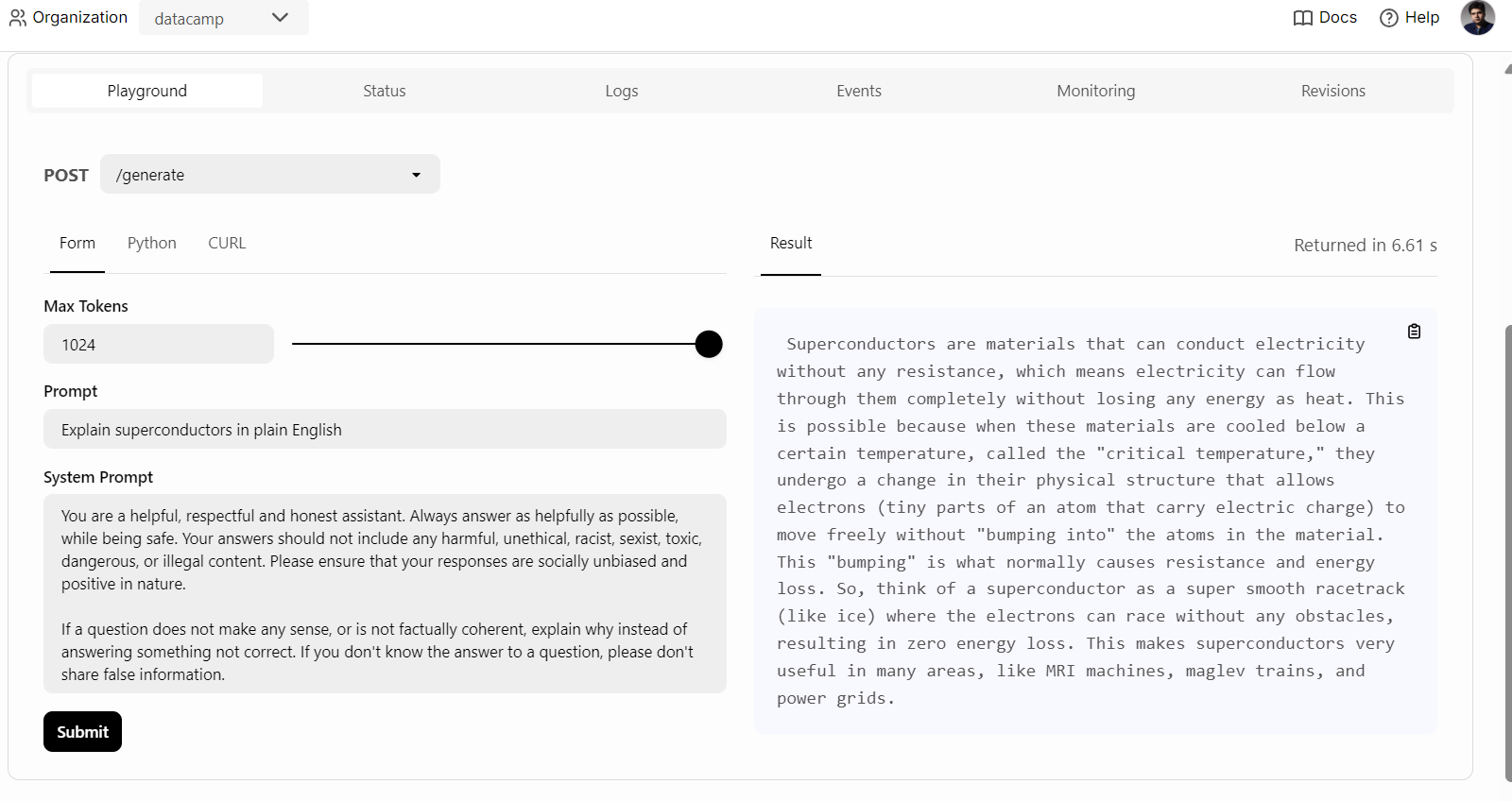 Nous pouvons également utiliser le client Python de BentoML pour accéder au modèle déployé et générer une réponse. Cela vous aidera à intégrer le service d'IA dans votre application :
Nous pouvons également utiliser le client Python de BentoML pour accéder au modèle déployé et générer une réponse. Cela vous aidera à intégrer le service d'IA dans votre application :
import bentoml
with bentoml.SyncHTTPClient(
"https://bentovllm-phi-3-mini-4-k-instruct-service-ka76-39800880.mt-guc1.bentoml.ai"
) as client:
response = client.generate(
prompt="What is the largest lake in the world?"
)
for chunk in response:
print(chunk, end="", flush=True)
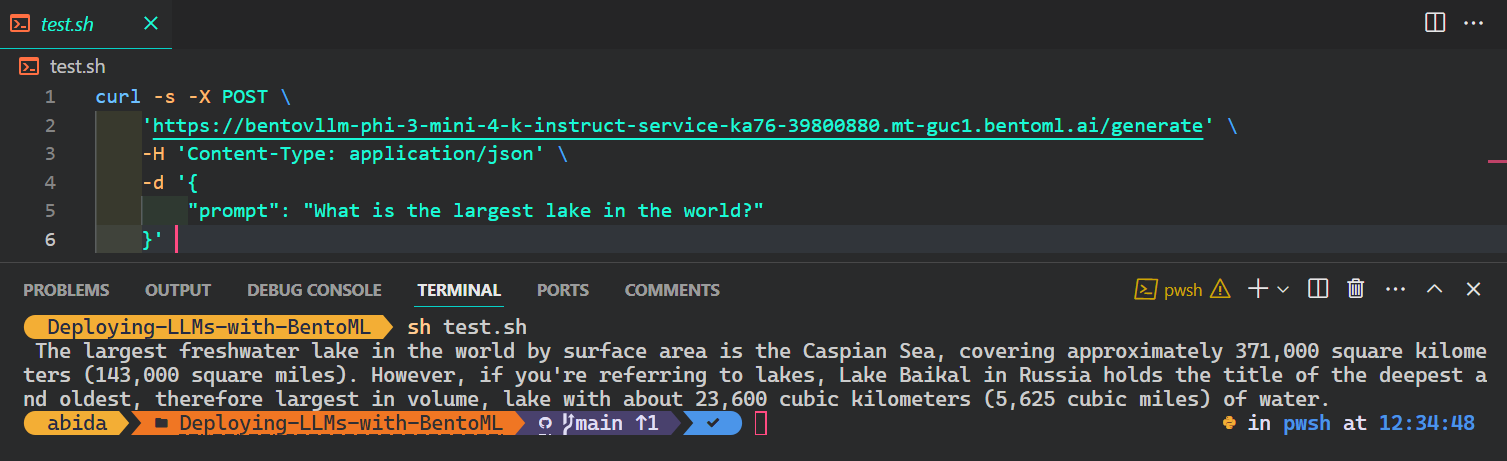
Le moyen le plus courant et le plus simple d'accéder au service AI à partir de n'importe quel système d'exploitation est d'utiliser la commande CURL dans le terminal :
$ curl -s -X POST \
'https://bentovllm-phi-3-mini-4-k-instruct-service-ka76-39800880.mt-guc1.bentoml.ai/generate' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "What is the largest lake in the world?"
}' 
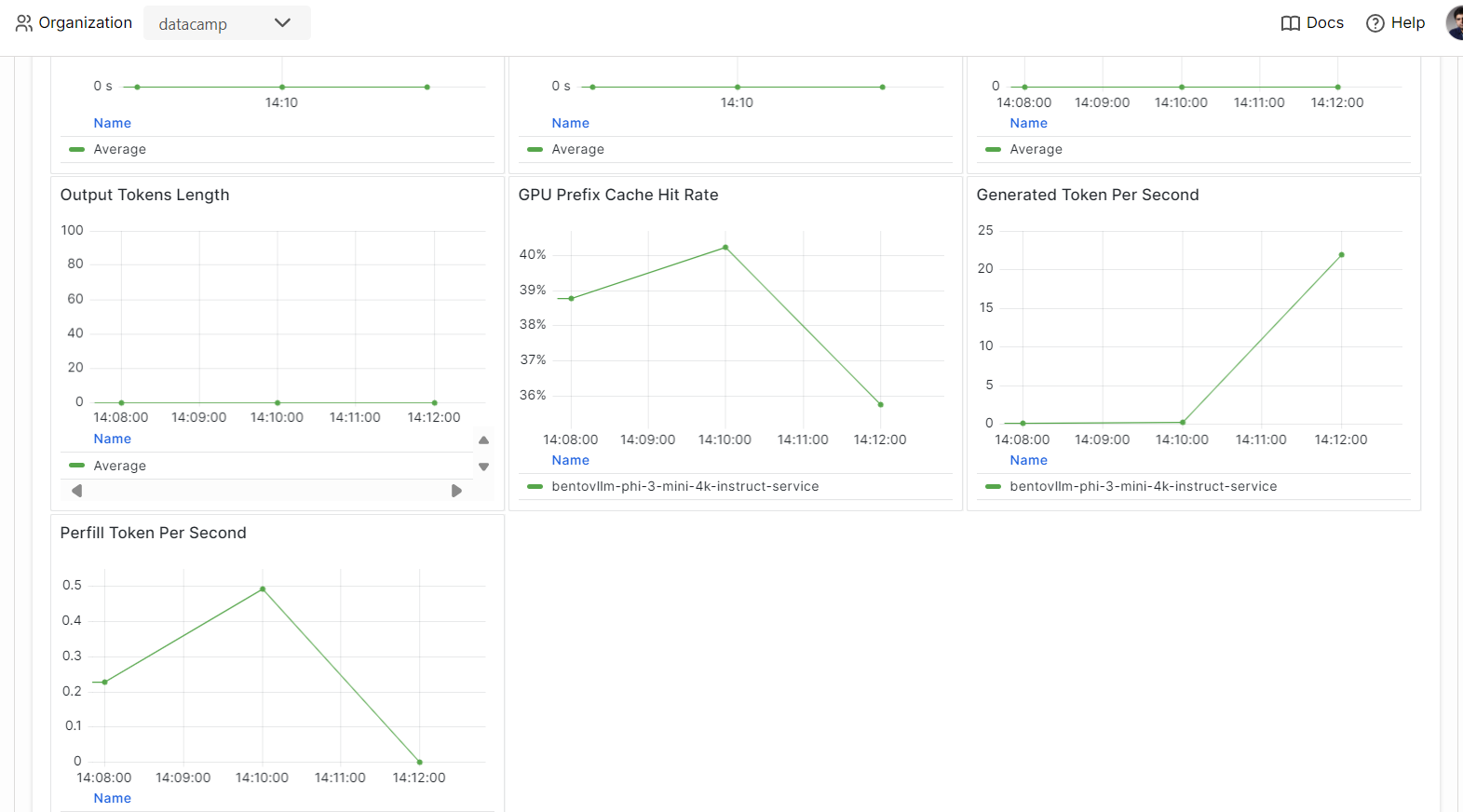
Allez dans l'onglet "Monitoring" et examinez toutes les statistiques relatives aux LLM, aux demandes des utilisateurs, au matériel et à d'autres analyses de surveillance qui vous aideront à évaluer les performances du serveur AI.
Vous pouvez également consulter l'onglet "Logs" ou utiliser le CLI de BentoML pour générer des logs en temps réel.
Les modèles de distribution et de déploiement constituent une partie du pipeline MLOps. En suivant le cours MLOps entièrement automatisé, vous apprendrez à construire une architecture MLOps, des techniques CI/CD/CM/CT et des modèles d'automatisation pour déployer des systèmes ML capables de fournir de la valeur au fil du temps.
Si vous souhaitez en savoir plus sur l'écosystème BentoML, la meilleure approche est de commencer à construire et à déployer votre service d'IA. Vous recevez des crédits gratuits qui vous permettent d'utiliser des GPU et des CPU pour explorer différents services. Il peut s'agir d'une application RAG (Retrieval-Augmented Generation), d'un appel de fonction, de LLM agentiques ou d'une application multimodale qui traite des images et du texte pour générer des réponses.
Dans ce tutoriel pratique, nous avons appris à connaître BentoML et à servir localement n'importe quelle application d'IA avec seulement quelques lignes de code. Nous avons ensuite utilisé le moteur d'inférence vLLM pour créer un service BentoML et l'avons déployé sur BentoCloud en quelques étapes simples.
Envisagez de suivre le cursus d'ingénieur IA associé pour développeurs pour apprendre à intégrer l'IA dans des applications logicielles à l'aide d'API et de bibliothèques open-source.
Apprenez-en plus sur l'IA grâce à ces cours !
Cursus
Cours
Cours