
programa
Desarrollo de aplicaciones de IA
21 h
Muchos científicos de datos e ingenieros de aprendizaje automático se enfrentan a retos con herramientas como Docker, Kubernetes y Terraform, así como con la construcción de infraestructuras seguras para modelos de IA.
BentoML simplifica este proceso, permitiéndote construir, servir y desplegar aplicaciones de IA con sólo unas pocas líneas de código Python.
Este tutorial es una guía paso a paso para quienes deseen desplegar su propia aplicación de IA, accesible desde cualquier lugar mediante un simple comando CURL. Aprenderás sobre el marco BentoML, a crear localmente una aplicación de IA de respuesta a preguntas y a desplegar el modelo Phi 3 mini en BentoCloud.
BentoML es un marco de servicio y despliegue de aprendizaje automático que agiliza el despliegue y escalado de modelos de IA. Automatiza tareas como la creación de imágenes Docker, la configuración de instancias, la gestión de la infraestructura y la seguridad, y las funciones esenciales necesarias para un servidor listo para producción.
Con BentoML, puedes desarrollar y desplegar modelos de IA personalizados, modelos preentrenados o soluciones afinadas en pocos minutos con un sencillo código Python. Proporciona la flexibilidad necesaria para escalar eficientemente dentro de tu entorno de nube, al tiempo que garantiza que mantienes un control total sobre la seguridad y el cumplimiento.
BentoML forma parte del conjunto de herramientas MLOps. Descubre otras herramientas LLMOps de primer nivel para formar, seguir, desplegar, orquestar, probar, supervisar y gestionar la infraestructura leyendo el blog Las 15 mejores herramientas LLMOps para crear aplicaciones de IA en 2024.
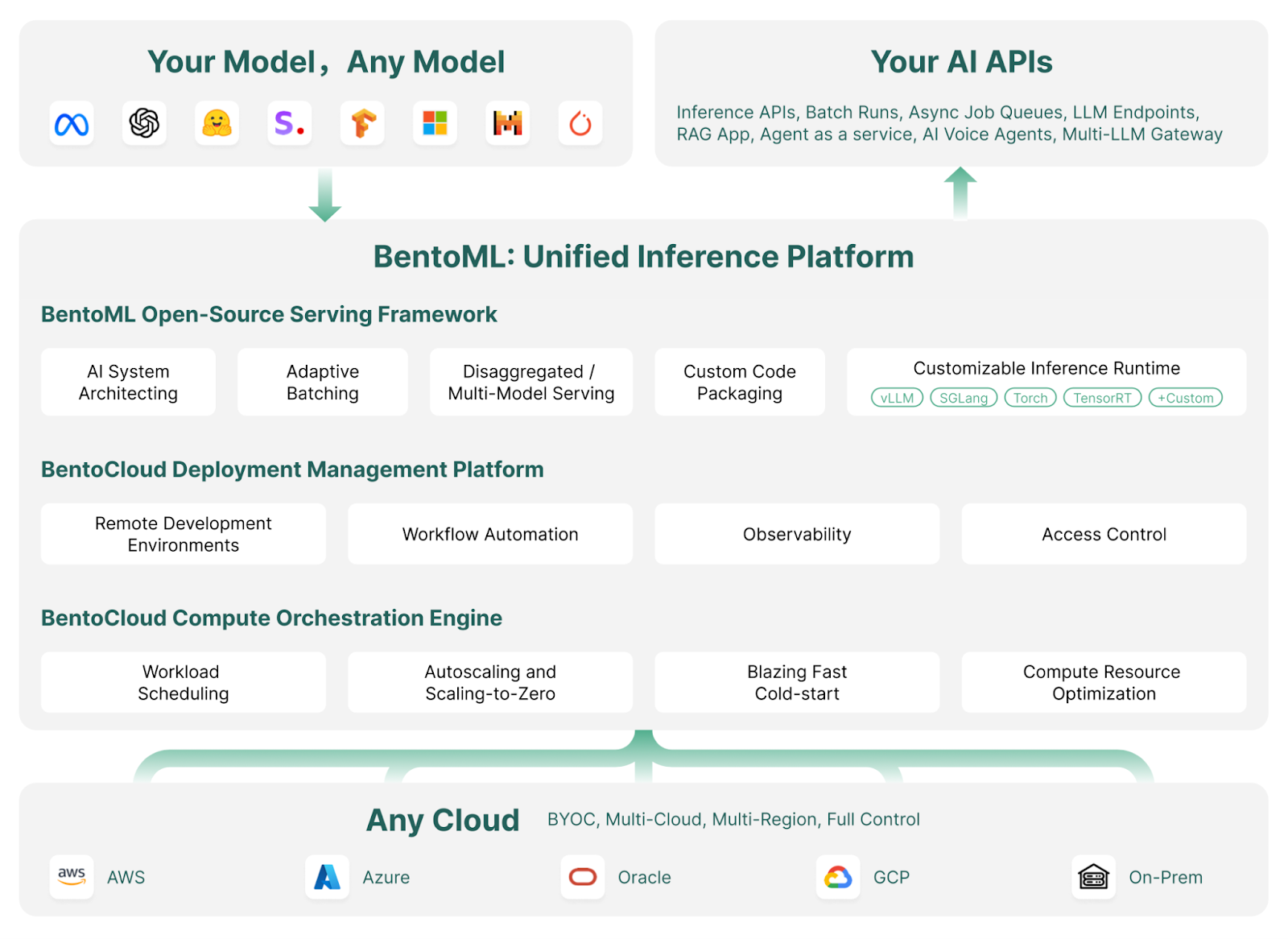
Cómo funciona BentoML | Fuente de la imagen: BentoML
La estrella brillante del ecosistema Bento es su nube: BentoCloud es una extensión del marco de BentoML, que ofrece herramientas y servicios adicionales para facilitar aún más el despliegue, la supervisión y el escalado de los modelos de IA.
Al registrarse, los usuarios pueden acceder a créditos gratuitos para empezar, lo que lo convierte en una opción atractiva para desarrolladores y empresas.
Si eres una persona sin conocimientos técnicos que busca una solución de no-código a bajo-código para desarrollar una aplicación LLM, te recomiendo que sigas la guía Local AI with Docker, n8n, Qdrant, and Ollama.
En esta sección, serviremos una sencilla aplicación de IA que toma las preguntas y el contexto del usuario y genera la respuesta.
Empezaremos instalando BentoML, PyTorch y la biblioteca Transformers mediante pip. Ejecuta los siguientes comandos en tu terminal:
$ pip install bentoml
$ pip install torch
$ pip install transformersA continuación, crearemos un archivo service.py para definir el servidor de IA.
Utilizando comandos BentoML, importaremos la canalización Transformers, que nos permite cargar el modelo y realizar la inferencia con sólo 2 líneas de código.
Configuraremos entradas de texto y contexto de ejemplo, configuraremos el servicio BentoML con parámetros como el número de CPUs y el tiempo de espera del tráfico, e inicializaremos la clase Question_Answering utilizando la canalización Transformers.
Por último, crearemos una API llamada generate(), que toma entradas y salidas y devuelve la respuesta generada.
from __future__ import annotations
import bentoml
with bentoml.importing():
from transformers import pipeline
EXAMPLE_INPUT = "How can I generate a secure password?"
EXAMPLE_CONTEXT = """
To generate a secure password, you can use tools like the LastPass Password Generator.
These tools create strong, random passwords that help prevent security threats by ensuring your accounts are protected against hacking attempts.
A secure password typically includes a mix of uppercase and lowercase letters, numbers, and special characters. Avoid using easily guessable information like names or birthdays.
Using a password manager like LastPass can also help you store and manage these secure passwords effectively.
"""
@bentoml.service(
resources={"cpu": "4"},
traffic={"timeout": 10},
)
class Question_Answering:
def __init__(self) -> None:
# Load model into pipeline
self.pipe = pipeline(
"question-answering",
model="deepset/roberta-base-squad2",
)
@bentoml.api
def generate(
self,
text: str =EXAMPLE_INPUT,
doc: str = EXAMPLE_CONTEXT,
) -> str:
result = self.pipe(question=text, context=doc)
return result["answer"]Sirve el servicio AI localmente escribiendo el siguiente comando en el terminal:
$ bentoml serve service:Question_Answering Como puedes ver, hemos proporcionado al comando anterior el nombre del archivo (service) y el nombre de la clase Python (Question_Answering ) para la inferencia del modelo de IA.
En unos segundos, generará una URL que podrás copiar y pegar en el navegador para acceder al servidor BentoML:
[cli] Starting production HTTP BentoServer from "app:Question_Answering" listening on http://localhost:3000 (Press CTRL+C to quit)El servidor BentoML es bastante similar a la interfaz de usuario swagger de FastAPI.
Vamos a probar nuestro servidor utilizando la opción "Probar".
Nuestro servicio de IA funciona correctamente y ha generado una respuesta precisa:
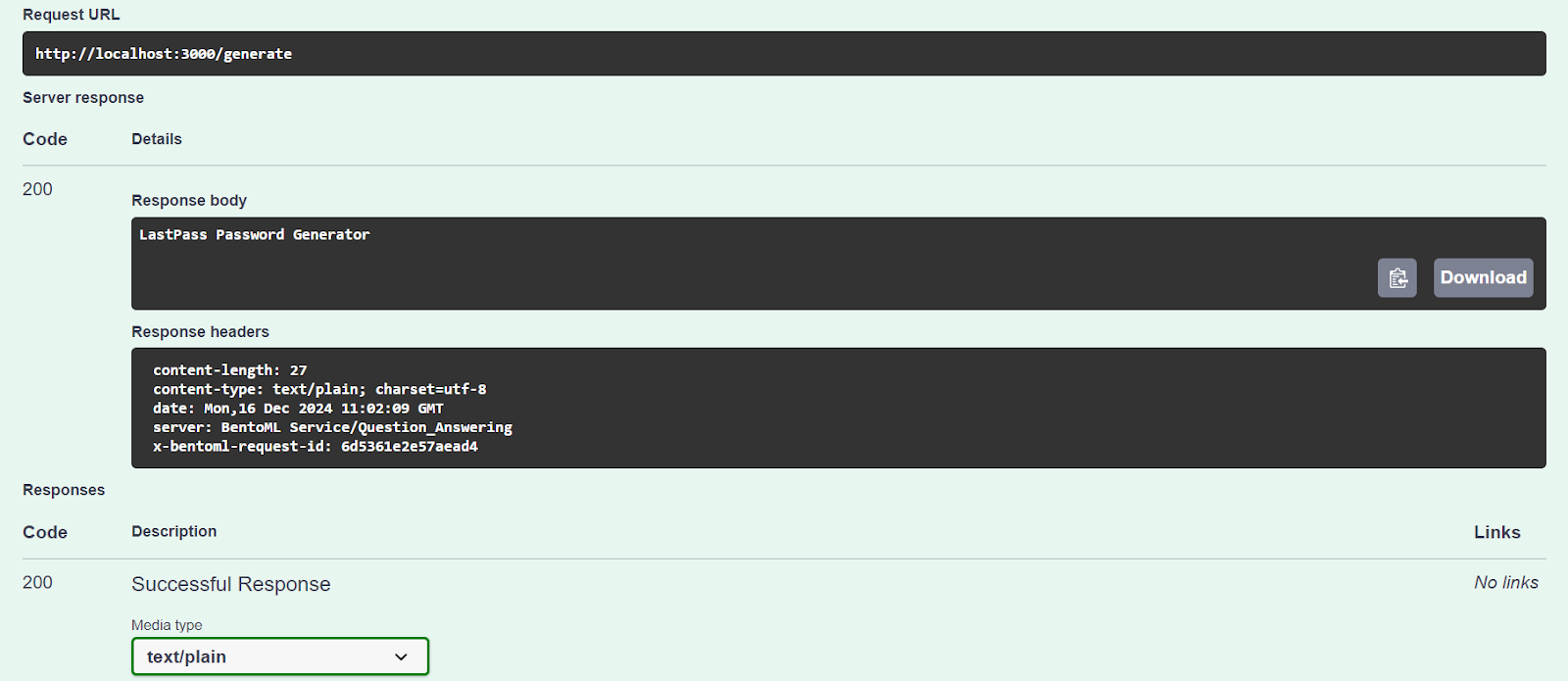
También podemos acceder al servidor de IA utilizando el comando CURL. Hagamos una pregunta diferente y contextualicémosla:
curl -X 'POST' \
'http://localhost:3000/generate' \
-H 'accept: text/plain' \
-H 'Content-Type: application/json' \
-d '{
"text": "How can I buy a cheap car?",
"doc": "Start by setting a budget and exploring sources like online marketplaces (Craigslist, Facebook Marketplace, Cars.com), local dealerships, or government auctions. Inspect the car thoroughly for issues like rust or mechanical problems, and consider bringing a trusted mechanic to avoid future repair costs. Research the reliability of specific brands and models using tools like Kelley Blue Book or Consumer Reports. Finally, negotiate the price to secure the best deal. Following these steps can help you find a dependable car within your budget."
}'Nuestro servicio de IA funciona sin problemas, y tardó 1 segundo en generar una respuesta incluso en la CPU:
negotiate the priceHa llegado el momento de crear una aplicación adecuada de IA de grandes modelos lingüísticos (LLM) y desplegarla en BentoML con el mínimo esfuerzo y recursos.
Utilizaremos el marco vLLM para crear una inferencia LLM de alto rendimiento y desplegarla en una instancia de GPU en BentoCloud. Aunque pueda parecer complejo, BentoCloud se encarga de la mayor parte del trabajo pesado, incluida la configuración de la infraestructura, para que puedas centrarte en crear y desplegar tu servicio.
BentoML ofrece mucho código de ejemplo y recursos para varios proyectos LLM. Para empezar, clonaremos el repositorio BentoVLLM.
Navega hasta el proyecto Phi 3 Mini 4k, e instala todas las librerías Python necesarias:
$ git clone https://github.com/bentoml/BentoVLLM.git
$ cd BentoVLLM/phi-3-mini-4k-instruct
$ pip install -r requirements.txtEste es el aspecto del directorio del proyecto con todos los archivos:
Modificaremos el bentofile.yaml para cambiar los nombres del propietario y del escenario.
bentofile.yaml es más sencillo que Dockerfile y utiliza diferentes comandos para configurar la infraestructura, el entorno y el servidor; puedes aprender todos los comandos en las opciones de compilación de Bento.
service: 'service:VLLM'
labels:
owner: Abid
stage: Guide
include:
- '*.py'
- 'bentovllm_openai/*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"service.py archivoNo modificaremos el archivo service.py, sino que aprenderemos sobre él.
@bentoml.service para gestionar la implantación y los recursos, como la configuración de las GPU y la gestión del tráfico.generate se define mediante el decorador @bentoml.api. Toma como entradas una pregunta del usuario, una pregunta opcional del sistema y un límite máximo de fichas, que se proporcionan al motor de inferencia vLLM para generar la respuesta. generate transmite la salida del modelo en trozos, generando fichas en cuanto están disponibles.import uuid
from typing import AsyncGenerator, Optional
import bentoml
from annotated_types import Ge, Le
from typing_extensions import Annotated
from bentovllm_openai.utils import openai_endpoints
MAX_TOKENS = 1024
PROMPT_TEMPLATE = """<|system|>
{system_prompt}<|end|>
<|user|>
{user_prompt}<|end|>
<|assistant|>
"""
SYSTEM_PROMPT = """You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."""
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
@openai_endpoints(model_id=MODEL_ID)
@bentoml.service(
name="bentovllm-phi-3-mini-4k-instruct-service",
traffic={
"timeout": 300,
"concurrency": 256, # Matches the default max_num_seqs in the VLLM engine
},
resources={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
)
class VLLM:
def __init__(self) -> None:
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_TOKENS,
dtype="half",
enable_prefix_caching=True,
disable_sliding_window=True,
)
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
@bentoml.api
async def generate(
self,
prompt: str = "Explain superconductors in plain English",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
from vllm import SamplingParams
SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens)
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
prompt = PROMPT_TEMPLATE.format(user_prompt=prompt, system_prompt=system_prompt)
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Recomiendo cursar la asignatura Desarrollo de aplicaciones de IA para aprender a crear aplicaciones potenciadas por IA con las últimas herramientas para desarrolladores de IA, como la API OpenAI, Hugging Face y LangChain.
Ve a bentofile.yaml y añade la variable de entorno para el token Cara de Abrazo en la última línea. Esto nos ayudará a cargar el modelo de forma segura y sin problemas desde el servidor de Cara Abrazada:
envs:
- name: HF_TOKENConéctate a BentoCloud utilizando la CLI:
$ bentoml cloud loginTe pedirá que crees la cuenta y luego te pedirá que crees el token de la API.
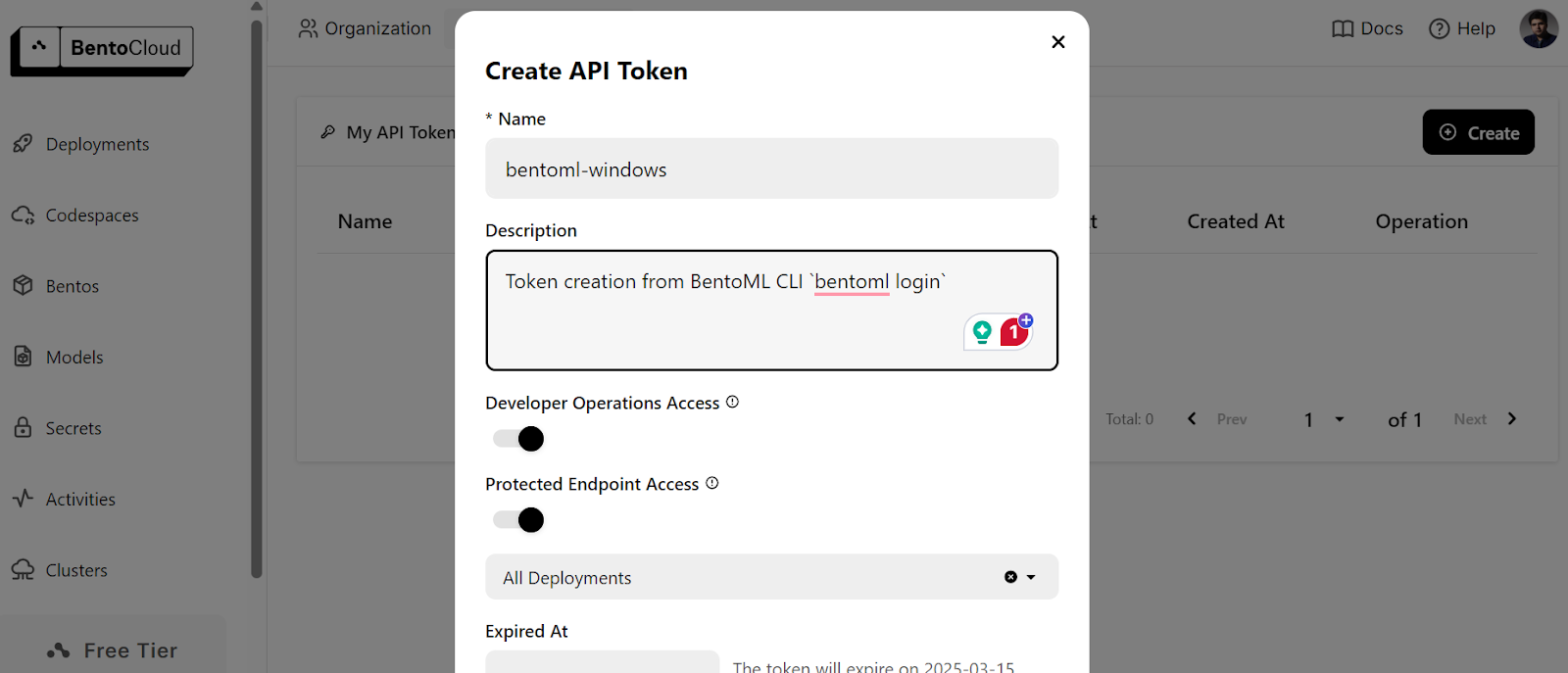
Después de crear con éxito el token API, verás el mensaje de éxito en tu terminal:

Antes de desplegar el servicio de IA en BentoCloud, tenemos que crear una variable de entorno en BentoCloud yendo a la pestaña "Secretos" y proporcionando el nombre de la clave y la clave API de Hugging Face.
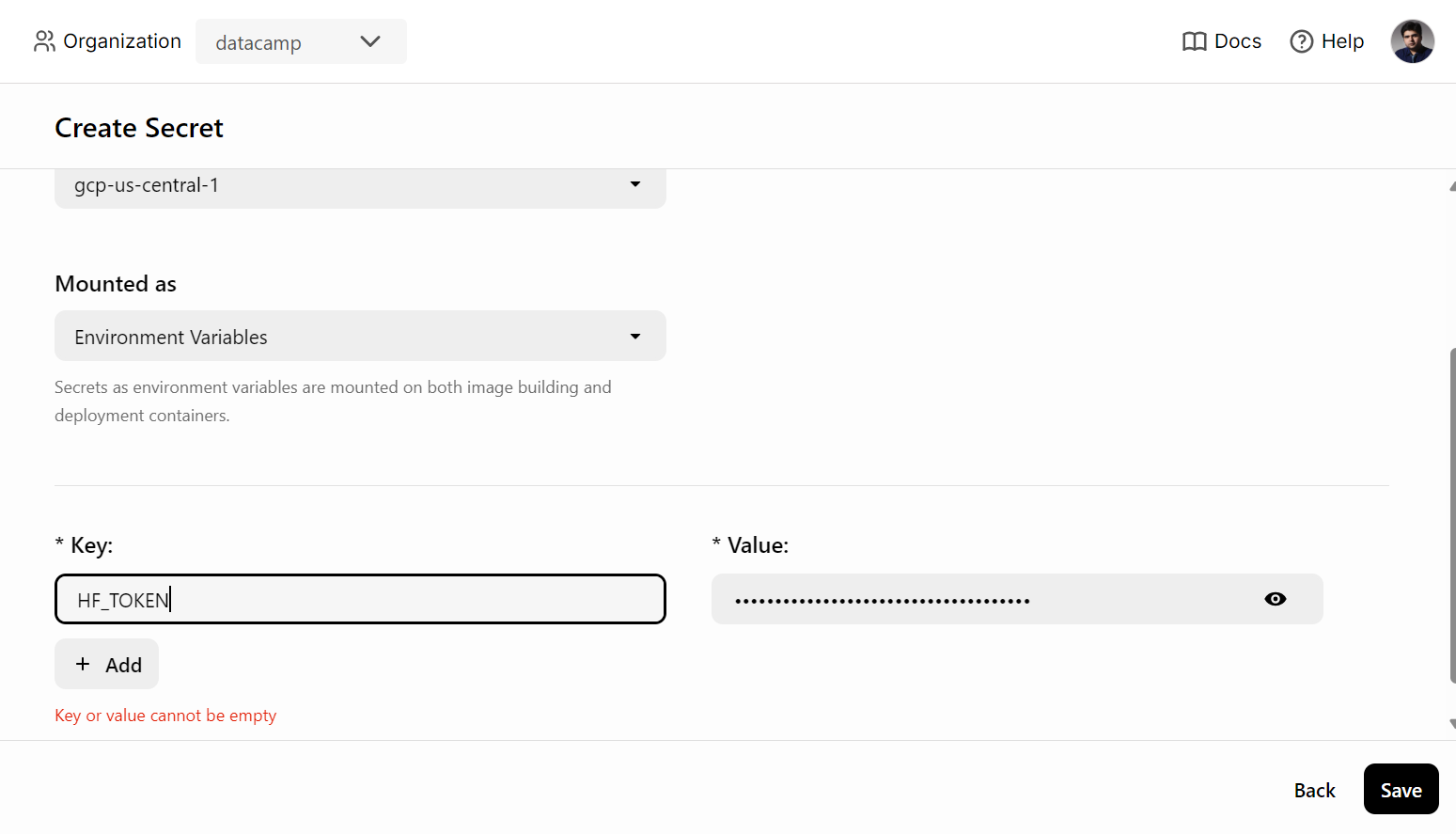
Después, utiliza el siguiente comando para desplegar el servicio de IA:
$ bentoml deploy . --secret huggingfaceTardarás unos minutos en descargar el modelo y configurar el entorno para ejecutar el servidor.

Puedes comprobar el estado de tu servicio de IA yendo a la pestaña "Despliegues".
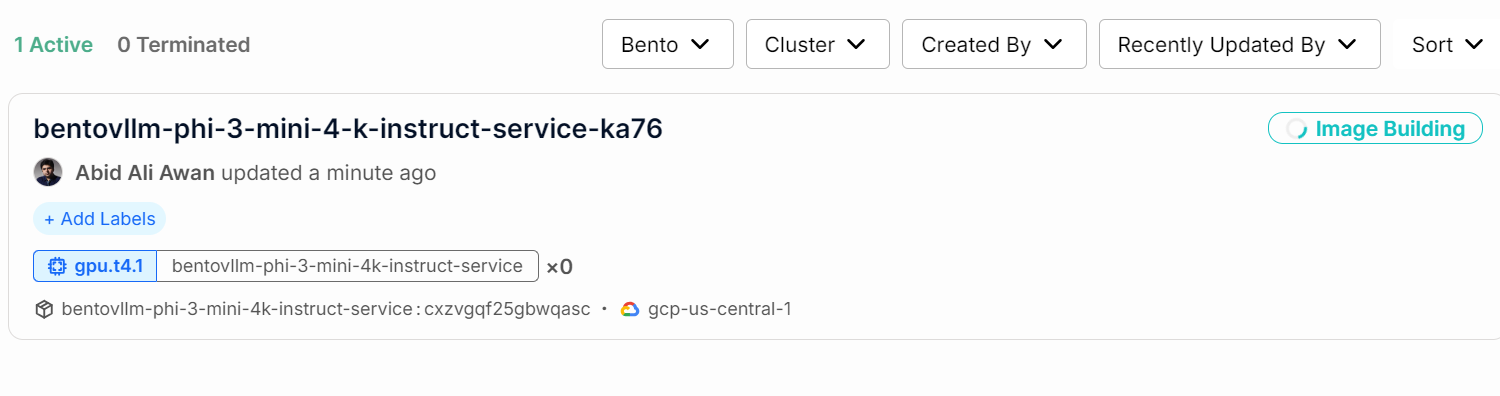
También puedes comprobar todos los registros y observar lo que ocurre en segundo plano.
Una vez desplegado con éxito el servicio de IA, empezaremos a probar el servicio Phi 3 Mini vLLM.
Para empezar, basta con hacer clic en la pestaña "Playground" de la opción "Despliegues", introducir la solicitud y hacer clic en el botón "Enviar" para generar la respuesta. La respuesta se transmitirá en tiempo real.
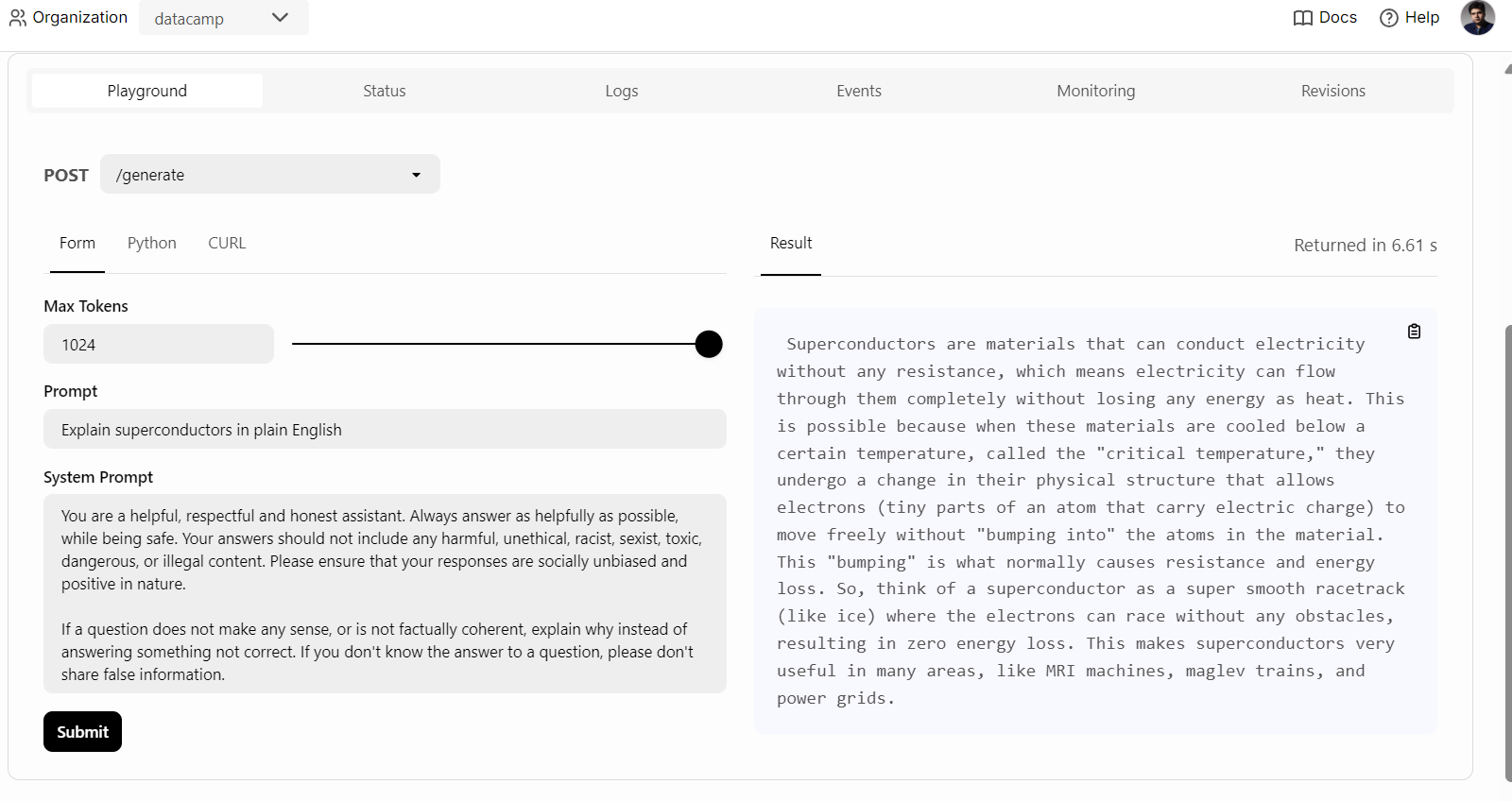 También podemos utilizar el cliente Python de BentoML para acceder al modelo desplegado y generar una respuesta. Esto te ayudará a integrar el servicio de IA en tu aplicación:
También podemos utilizar el cliente Python de BentoML para acceder al modelo desplegado y generar una respuesta. Esto te ayudará a integrar el servicio de IA en tu aplicación:
import bentoml
with bentoml.SyncHTTPClient(
"https://bentovllm-phi-3-mini-4-k-instruct-service-ka76-39800880.mt-guc1.bentoml.ai"
) as client:
response = client.generate(
prompt="What is the largest lake in the world?"
)
for chunk in response:
print(chunk, end="", flush=True)
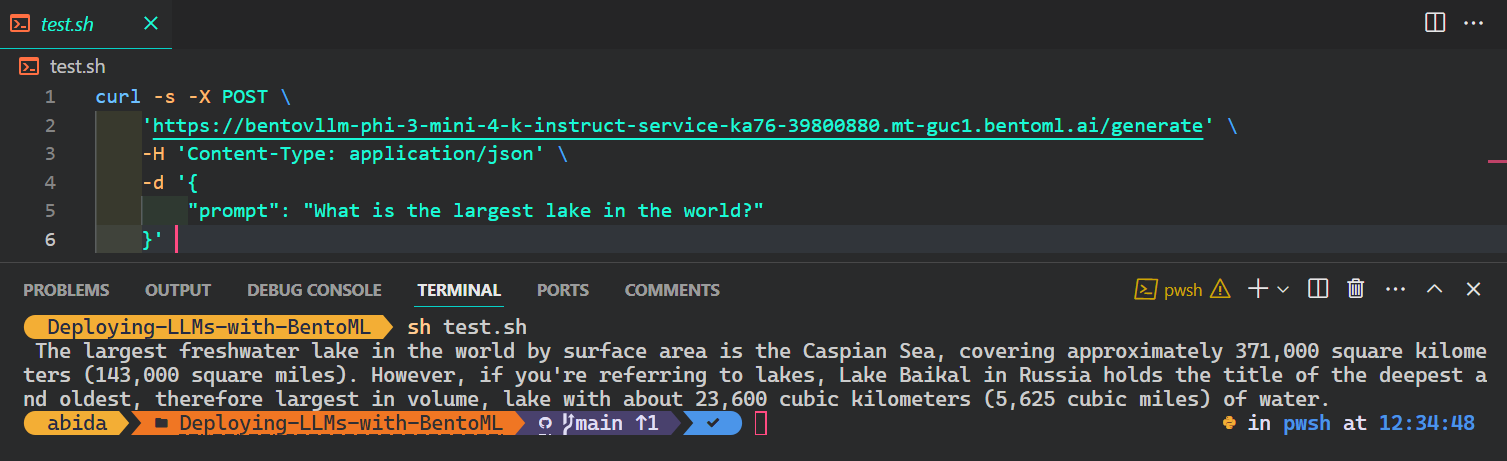
La forma más popular y sencilla de acceder al servicio de IA desde cualquier sistema operativo es utilizar el comando CURL en el terminal:
$ curl -s -X POST \
'https://bentovllm-phi-3-mini-4-k-instruct-service-ka76-39800880.mt-guc1.bentoml.ai/generate' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "What is the largest lake in the world?"
}' 
Ve a la pestaña "Monitorización" y revisa todas las estadísticas relacionadas con los LLM, las peticiones de los usuarios, el hardware y otros análisis de monitorización que te ayudarán a evaluar el rendimiento del servidor de IA.
También puedes consultar la pestaña "Registros" o utilizar la CLI de BentoML para generar registros en tiempo real.
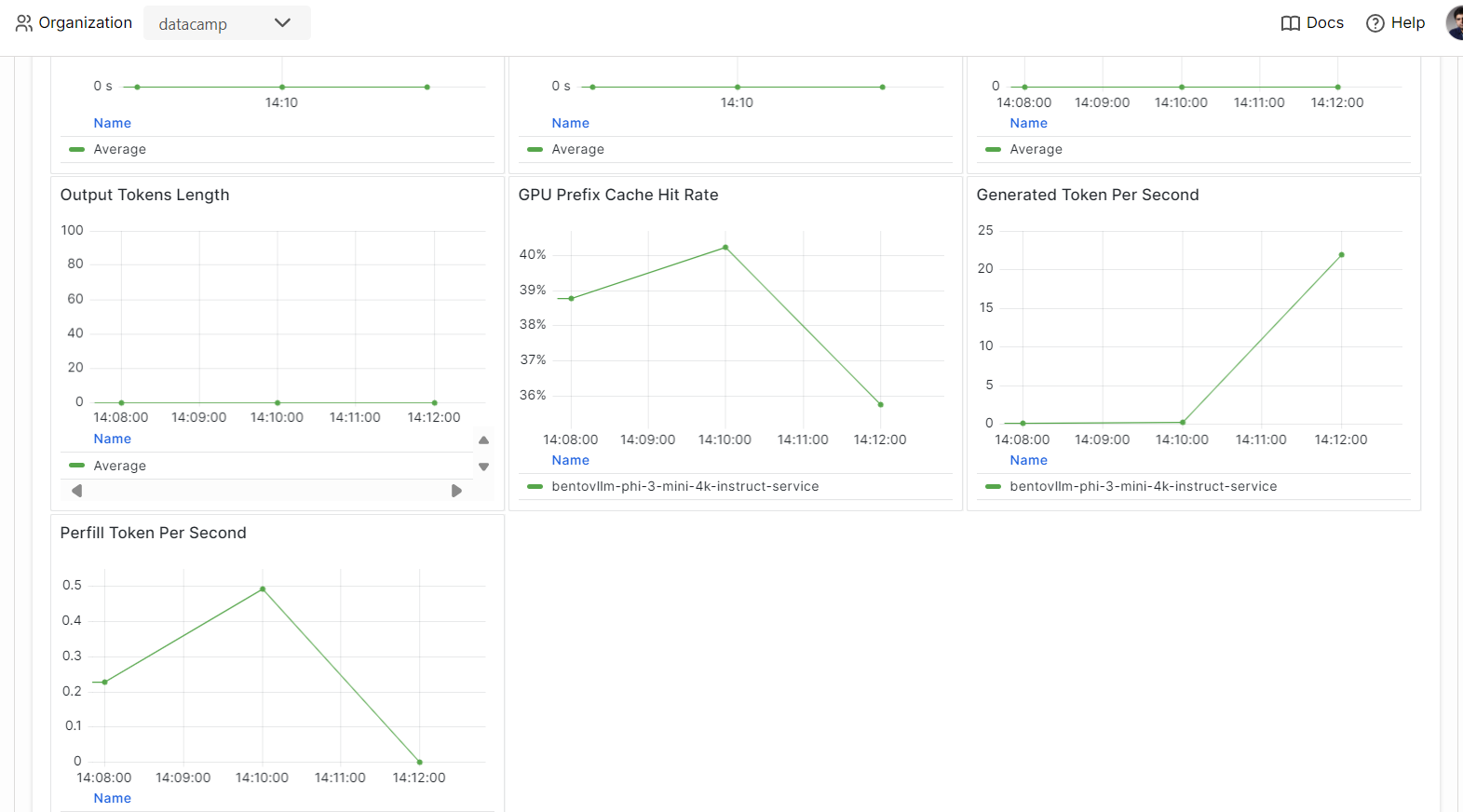
Los modelos de servicio y despliegue son una parte del proceso MLOps. Al completar el curso MLOps Totalmente Automatizados, podrás aprender a construir una arquitectura MLOps, técnicas CI/CD/CM/CT y patrones de automatización para desplegar sistemas ML que puedan aportar valor a lo largo del tiempo.
Si quieres saber más sobre el ecosistema BentoML, lo mejor es que empieces a construir y desplegar tu servicio de IA. Recibes créditos gratuitos que te permiten utilizar GPUs y CPUs para explorar diversos servicios. Esto podría incluir una aplicación de Generación Mejorada por Recuperación (RAG), llamada a funciones, LLMs Agenticos, o una aplicación multimodal que procese imágenes y texto para generar respuestas.
En este tutorial práctico, aprendimos sobre BentoML y cómo servir localmente cualquier aplicación de IA con sólo unas pocas líneas de código. A continuación, utilizamos el motor de inferencia vLLM para construir un servicio BentoML y lo desplegamos en BentoCloud con unos sencillos pasos.
Considera la posibilidad de cursar la carrera de Ingeniero de IA Asociado para Desarrolladores para aprender a integrar la IA en aplicaciones de software utilizando API y bibliotecas de código abierto.
Aprende más sobre IA con estos cursos
programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Ryan Ong
Tutorial
Josep Ferrer


