
Programa
Desenvolvimento de aplicativos de IA
21 h
Muitos cientistas de dados e engenheiros de aprendizado de máquina enfrentam desafios com ferramentas como Docker, Kubernetes e Terraform, além de criar uma infraestrutura segura para modelos de IA.
O BentoML simplifica esse processo, permitindo que você crie, sirva e implemente aplicativos de IA com apenas algumas linhas de código Python.
Este tutorial é um guia passo a passo para pessoas que desejam implantar seu próprio aplicativo de IA, acessível em qualquer lugar por meio de um simples comando CURL. Você aprenderá sobre o framework BentoML, criando localmente um aplicativo de IA para responder a perguntas e implantando o modelo Phi 3 mini no BentoCloud.
O BentoML é uma estrutura de serviço e implementação de aprendizado de máquina que simplifica a implementação e o dimensionamento de modelos de IA. Ele automatiza tarefas como a criação de imagens do Docker, a configuração de instâncias, o gerenciamento de infraestrutura e segurança e os recursos essenciais necessários para um servidor pronto para produção.
Com o BentoML, você pode desenvolver e implementar modelos de IA personalizados, modelos pré-treinados ou soluções ajustadas em poucos minutos com um simples código Python. Ele oferece a flexibilidade de dimensionar com eficiência o seu ambiente de nuvem e, ao mesmo tempo, garante que você mantenha controle total sobre a segurança e a conformidade.
O BentoML faz parte do conjunto de ferramentas MLOps. Descubra outras ferramentas de MLOps de primeira linha para treinamento, rastreamento, implementação, orquestração, teste, monitoramento e gerenciamento de infraestrutura lendo o blog Top 15 LLMOps Tools for Building AI Applications in 2024.
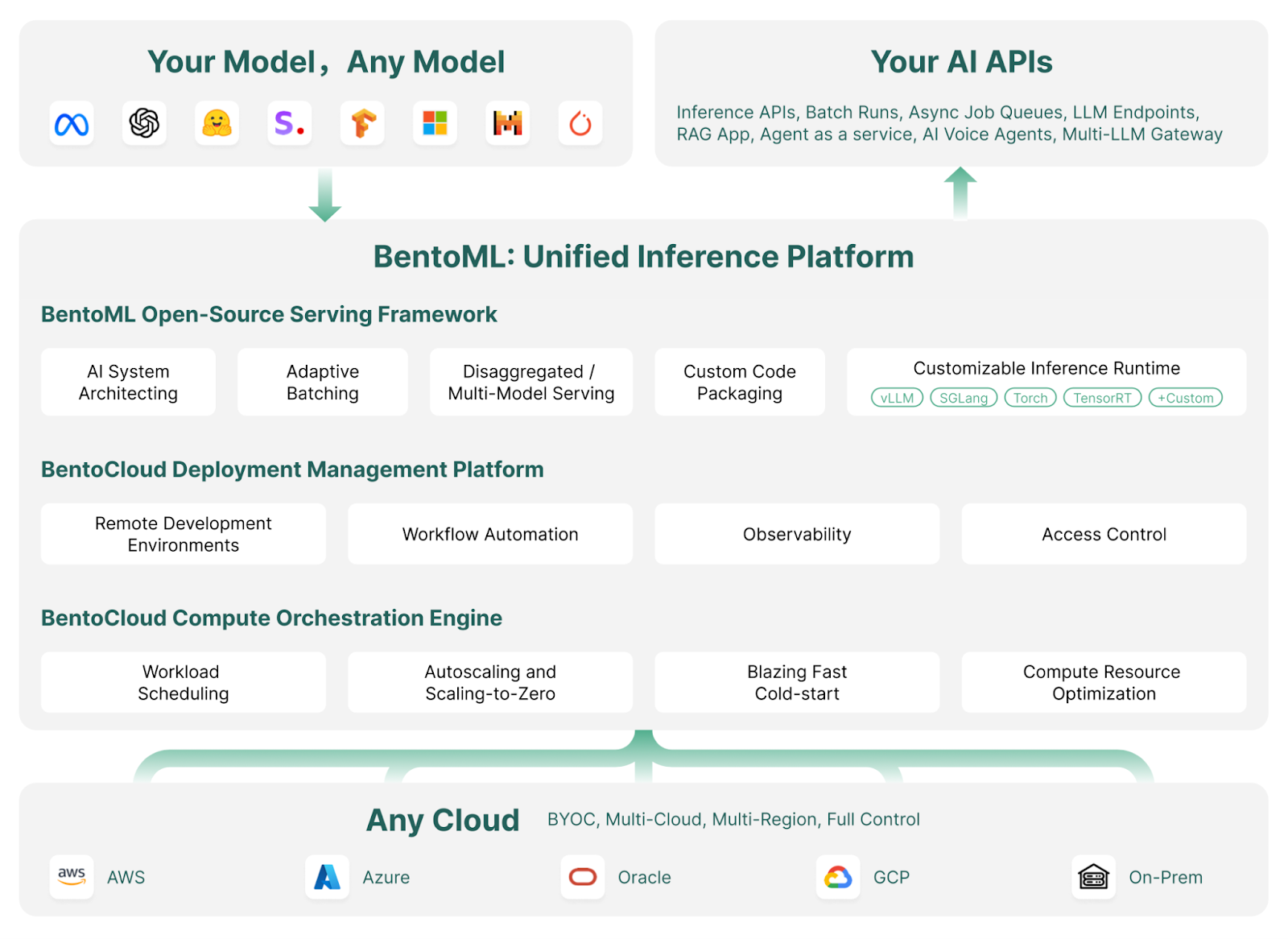
Como o BentoML funciona | Fonte da imagem: BentoML
A estrela brilhante do ecossistema Bento é sua nuvem: O BentoCloud é uma extensão da estrutura do BentoML, oferecendo ferramentas e serviços adicionais para facilitar ainda mais a implantação, o monitoramento e o dimensionamento de modelos de IA.
Ao se inscrever, os usuários podem acessar créditos gratuitos para começar, o que o torna uma opção atraente para desenvolvedores e empresas.
Se você não for técnico e estiver procurando uma solução sem código ou com pouco código para desenvolver um aplicativo LLM, recomendo seguir o guia Local AI with Docker, n8n, Qdrant e Ollama.
Nesta seção, apresentaremos um aplicativo de IA simples que recebe perguntas e contexto do usuário e gera a resposta.
Começaremos instalando o BentoML, o PyTorch e a biblioteca Transformers usando o pip. Execute os seguintes comandos em seu terminal:
$ pip install bentoml
$ pip install torch
$ pip install transformersEm seguida, criaremos um arquivo service.py para definir o servidor de IA.
Usando os comandos do BentoML, importaremos o pipeline Transformers, que nos permite carregar o modelo e realizar a inferência com apenas duas linhas de código.
Definiremos exemplos de entradas de texto e contexto, configuraremos o serviço BentoML com parâmetros como o número de CPUs e o tempo limite de tráfego e inicializaremos a classe Question_Answering usando o pipeline Transformers.
Por fim, criaremos uma API chamada generate(), que recebe entradas e saídas e retorna a resposta gerada.
from __future__ import annotations
import bentoml
with bentoml.importing():
from transformers import pipeline
EXAMPLE_INPUT = "How can I generate a secure password?"
EXAMPLE_CONTEXT = """
To generate a secure password, you can use tools like the LastPass Password Generator.
These tools create strong, random passwords that help prevent security threats by ensuring your accounts are protected against hacking attempts.
A secure password typically includes a mix of uppercase and lowercase letters, numbers, and special characters. Avoid using easily guessable information like names or birthdays.
Using a password manager like LastPass can also help you store and manage these secure passwords effectively.
"""
@bentoml.service(
resources={"cpu": "4"},
traffic={"timeout": 10},
)
class Question_Answering:
def __init__(self) -> None:
# Load model into pipeline
self.pipe = pipeline(
"question-answering",
model="deepset/roberta-base-squad2",
)
@bentoml.api
def generate(
self,
text: str =EXAMPLE_INPUT,
doc: str = EXAMPLE_CONTEXT,
) -> str:
result = self.pipe(question=text, context=doc)
return result["answer"]Para ativar o serviço de IA localmente, digite o seguinte comando no terminal:
$ bentoml serve service:Question_Answering Como você pode ver, fornecemos ao comando acima o nome do arquivo (service) e o nome da classe Python (Question_Answering ) para a inferência do modelo de IA.
Em poucos segundos, ele gerará uma URL que você poderá copiar e colar no navegador para acessar o servidor BentoML:
[cli] Starting production HTTP BentoServer from "app:Question_Answering" listening on http://localhost:3000 (Press CTRL+C to quit)O servidor BentoML é bastante semelhante ao FastAPI swagger UI.
Vamos testar nosso servidor usando a opção "Try it out".
Nosso serviço de IA está funcionando bem e gerou uma resposta precisa:
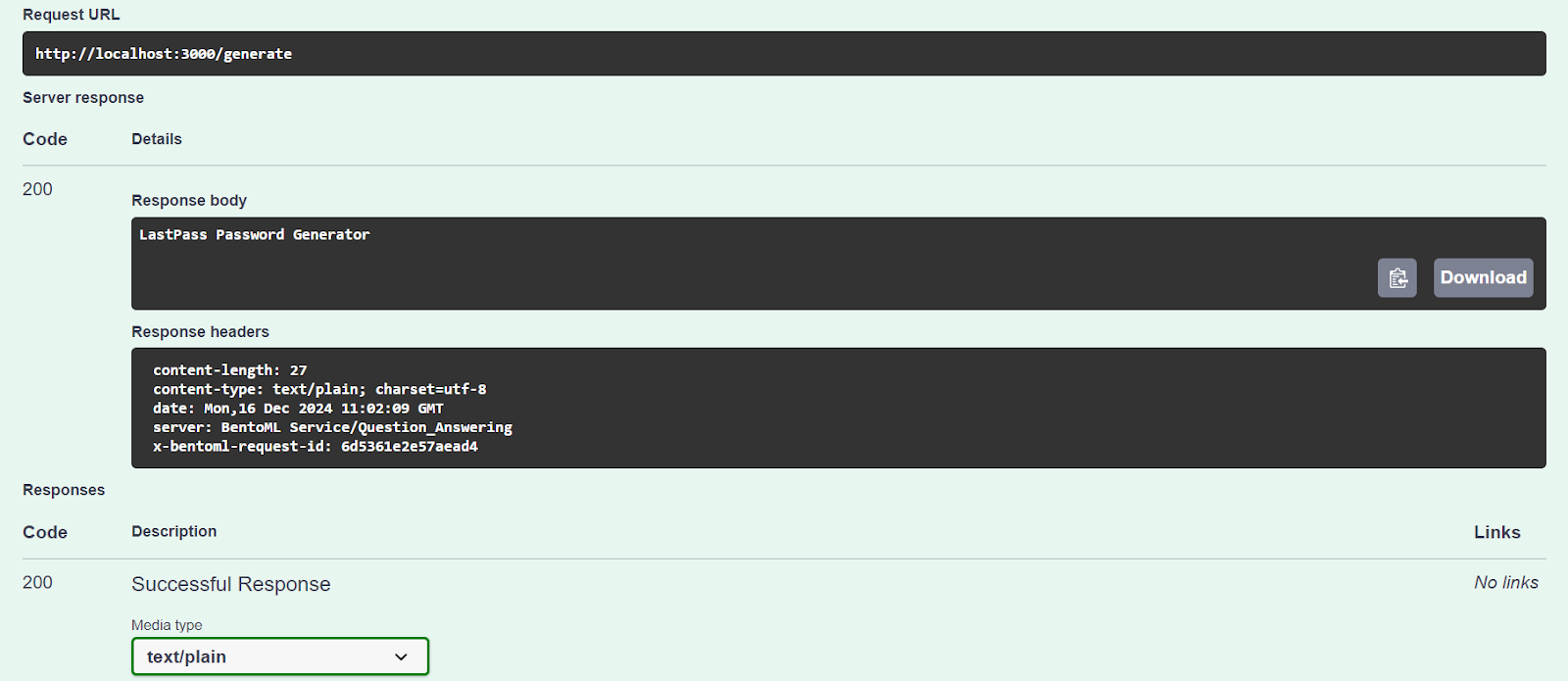
Também podemos acessar o servidor de IA usando o comando CURL. Vamos fazer uma pergunta diferente e contextualizá-la:
curl -X 'POST' \
'http://localhost:3000/generate' \
-H 'accept: text/plain' \
-H 'Content-Type: application/json' \
-d '{
"text": "How can I buy a cheap car?",
"doc": "Start by setting a budget and exploring sources like online marketplaces (Craigslist, Facebook Marketplace, Cars.com), local dealerships, or government auctions. Inspect the car thoroughly for issues like rust or mechanical problems, and consider bringing a trusted mechanic to avoid future repair costs. Research the reliability of specific brands and models using tools like Kelley Blue Book or Consumer Reports. Finally, negotiate the price to secure the best deal. Following these steps can help you find a dependable car within your budget."
}'Nosso serviço de IA está funcionando sem problemas e levou 1 segundo para gerar uma resposta, mesmo na CPU:
negotiate the priceÉ hora de você criar um aplicativo de IA de modelo de linguagem grande (LLM) adequado e implementá-lo no BentoML com o mínimo de esforço e recursos.
Usaremos a estrutura vLLM para criar uma inferência LLM de alto rendimento e implantá-la em uma instância de GPU no BentoCloud. Embora isso possa parecer complexo, o BentoCloud cuida da maior parte do trabalho pesado, incluindo a configuração da infraestrutura, para que você possa se concentrar na criação e na implantação do seu serviço.
O BentoML oferece muitos exemplos de código e recursos para vários projetos LLM. Para começar, vamos clonar o repositório BentoVLLM.
Navegue até o projeto Phi 3 Mini 4k e instale todas as bibliotecas Python necessárias:
$ git clone https://github.com/bentoml/BentoVLLM.git
$ cd BentoVLLM/phi-3-mini-4k-instruct
$ pip install -r requirements.txtEsta é a aparência do diretório do projeto com todos os arquivos:
Modificaremos o site bentofile.yaml para alterar os nomes do proprietário e do palco.
O bentofile.yaml é mais simples do que um Dockerfile e usa comandos diferentes para definir a infraestrutura, o ambiente e as configurações do servidor; você pode aprender todos os comandos nas opções de compilação do Bento.
service: 'service:VLLM'
labels:
owner: Abid
stage: Guide
include:
- '*.py'
- 'bentovllm_openai/*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"service.py arquivoNão alteraremos o arquivo service.py, mas aprenderemos sobre ele.
@bentoml.service para lidar com a implantação e o gerenciamento de recursos, como a configuração de GPUs e o gerenciamento de tráfego.generate é definida usando o decorador @bentoml.api. Ele usa um prompt de usuário, um prompt de sistema opcional e um limite máximo de token como entradas, que são fornecidas ao mecanismo de inferência vLLM para gerar a resposta. generate transmite a saída do modelo em partes, gerando tokens assim que eles estiverem disponíveis.import uuid
from typing import AsyncGenerator, Optional
import bentoml
from annotated_types import Ge, Le
from typing_extensions import Annotated
from bentovllm_openai.utils import openai_endpoints
MAX_TOKENS = 1024
PROMPT_TEMPLATE = """<|system|>
{system_prompt}<|end|>
<|user|>
{user_prompt}<|end|>
<|assistant|>
"""
SYSTEM_PROMPT = """You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."""
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
@openai_endpoints(model_id=MODEL_ID)
@bentoml.service(
name="bentovllm-phi-3-mini-4k-instruct-service",
traffic={
"timeout": 300,
"concurrency": 256, # Matches the default max_num_seqs in the VLLM engine
},
resources={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
)
class VLLM:
def __init__(self) -> None:
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_TOKENS,
dtype="half",
enable_prefix_caching=True,
disable_sliding_window=True,
)
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
@bentoml.api
async def generate(
self,
prompt: str = "Explain superconductors in plain English",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
from vllm import SamplingParams
SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens)
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
prompt = PROMPT_TEMPLATE.format(user_prompt=prompt, system_prompt=system_prompt)
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Recomendo que você faça o curso de habilidades Desenvolvendo aplicativos de IA para aprender a criar aplicativos com tecnologia de IA com as mais recentes ferramentas de desenvolvimento de IA, incluindo a API OpenAI, Hugging Face e LangChain.
Vá para bentofile.yaml e adicione a variável de ambiente para o token Hugging Face na última linha. Isso nos ajudará a carregar o modelo de forma segura e sem problemas a partir do servidor Hugging Face:
envs:
- name: HF_TOKENFaça o login no BentoCloud usando o CLI:
$ bentoml cloud loginEle solicitará que você crie a conta e, em seguida, solicitará que você crie o token de API.
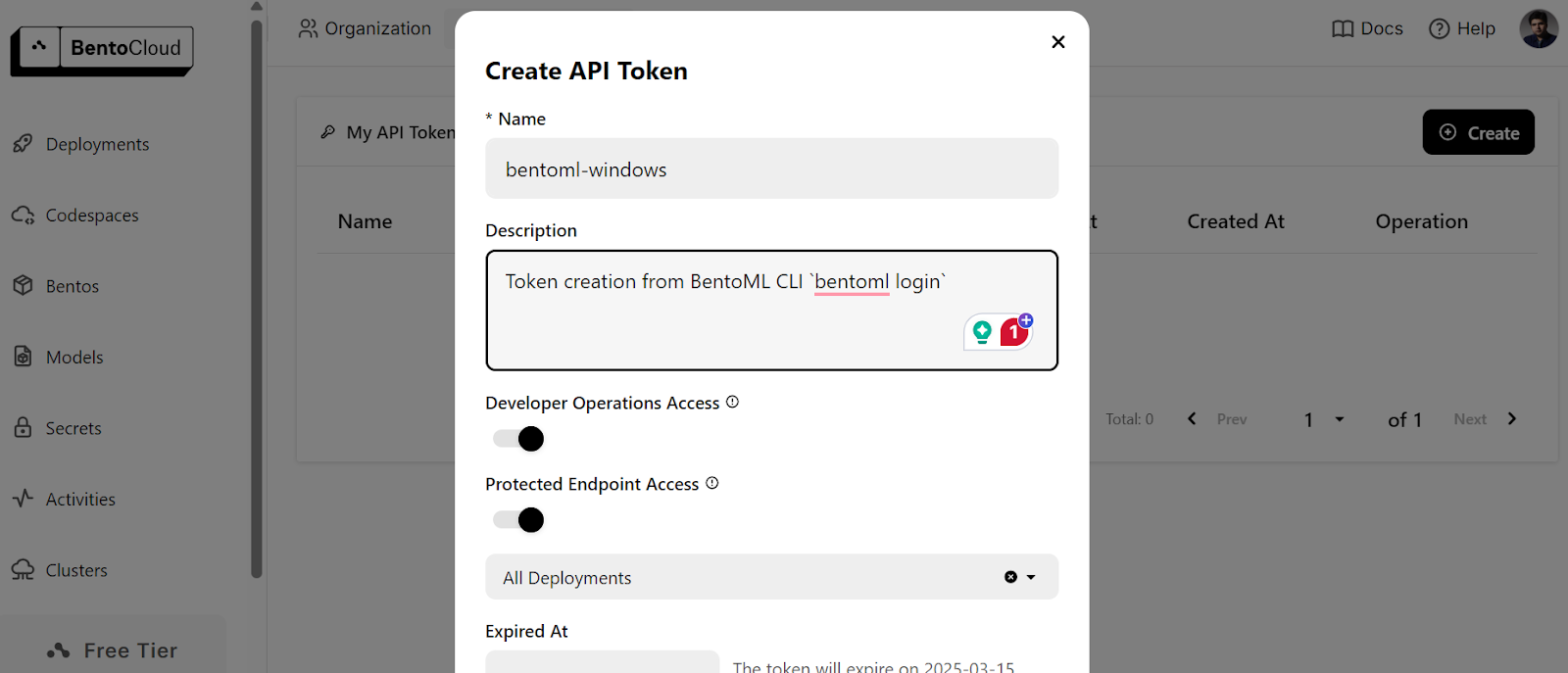
Depois de criar o token de API com êxito, você verá a mensagem de sucesso no terminal:

Antes de implementar o serviço de IA no BentoCloud, precisamos criar uma variável de ambiente no BentoCloud, indo até a guia "Secrets" e fornecendo o nome da chave e a chave da API do Hugging Face.
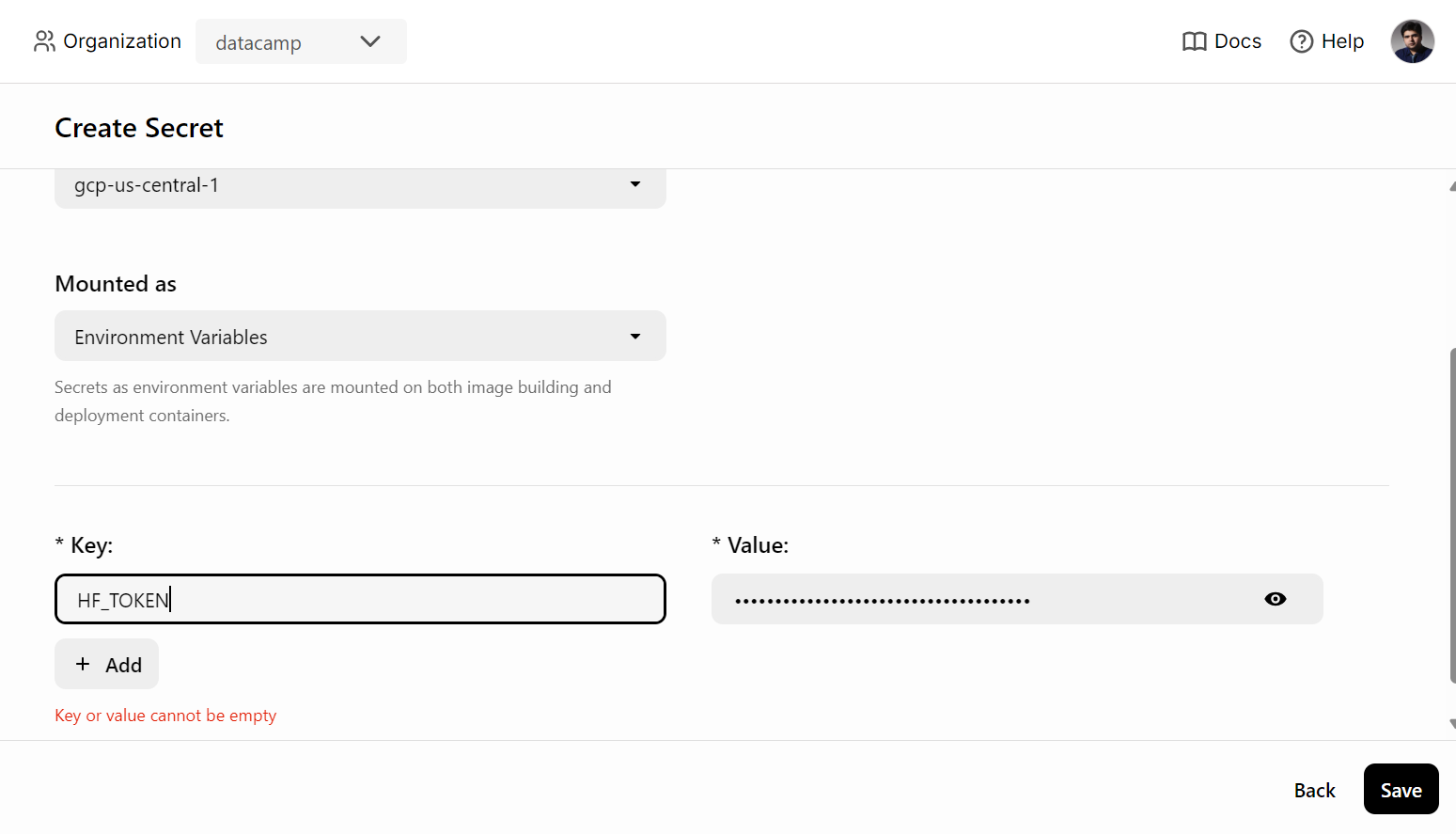
Depois disso, use o seguinte comando para implantar o serviço de IA:
$ bentoml deploy . --secret huggingfaceVocê levará alguns minutos para fazer o download do modelo e configurar o ambiente para executar o servidor.

Você pode verificar o status do seu serviço de IA acessando a guia "Deployments" (Implantações).
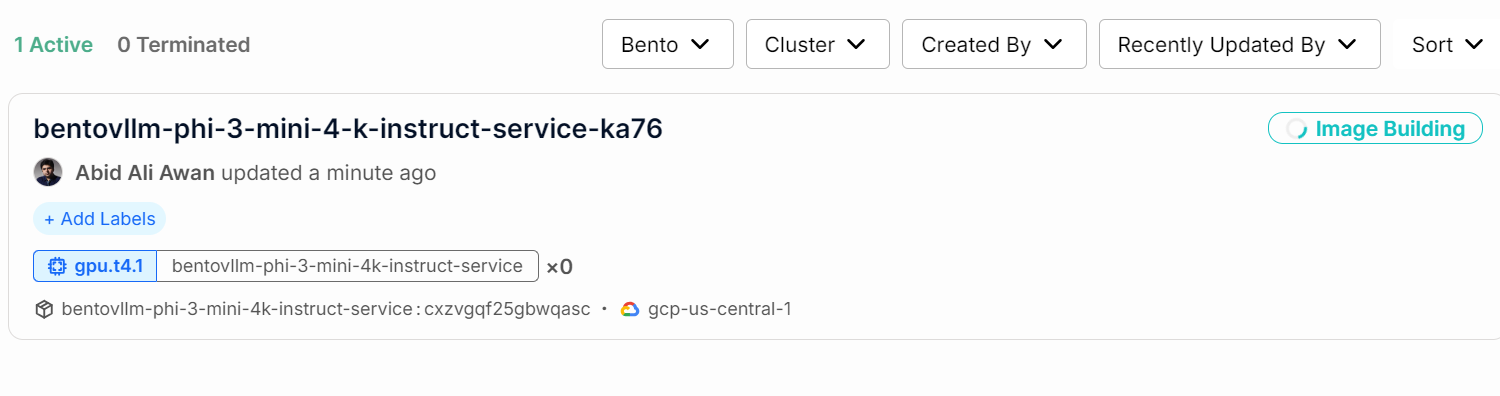
Você também pode verificar todos os logs e observar o que está acontecendo em segundo plano.
Depois que o serviço de IA for implantado com êxito, começaremos a testar o serviço vLLM do Phi 3 Mini.
Para começar, basta clicar na guia "Playground" na opção "Deployments", digitar o prompt e clicar no botão "submit" (enviar) para gerar a resposta. A resposta será transmitida em tempo real.
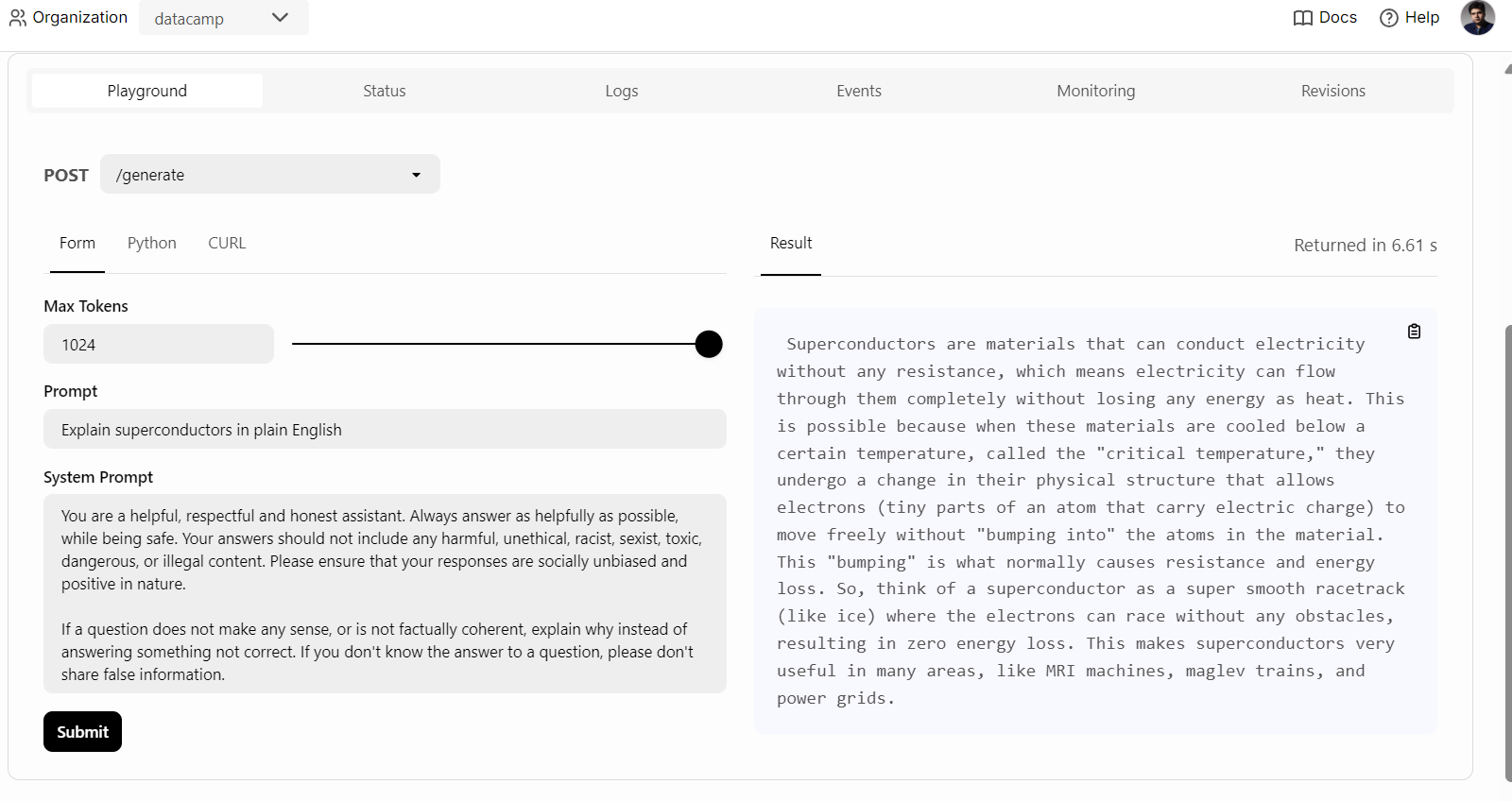 Também podemos usar o cliente Python do BentoML para acessar o modelo implantado e gerar uma resposta. Isso ajudará você a integrar o serviço de IA ao seu aplicativo:
Também podemos usar o cliente Python do BentoML para acessar o modelo implantado e gerar uma resposta. Isso ajudará você a integrar o serviço de IA ao seu aplicativo:
import bentoml
with bentoml.SyncHTTPClient(
"https://bentovllm-phi-3-mini-4-k-instruct-service-ka76-39800880.mt-guc1.bentoml.ai"
) as client:
response = client.generate(
prompt="What is the largest lake in the world?"
)
for chunk in response:
print(chunk, end="", flush=True)
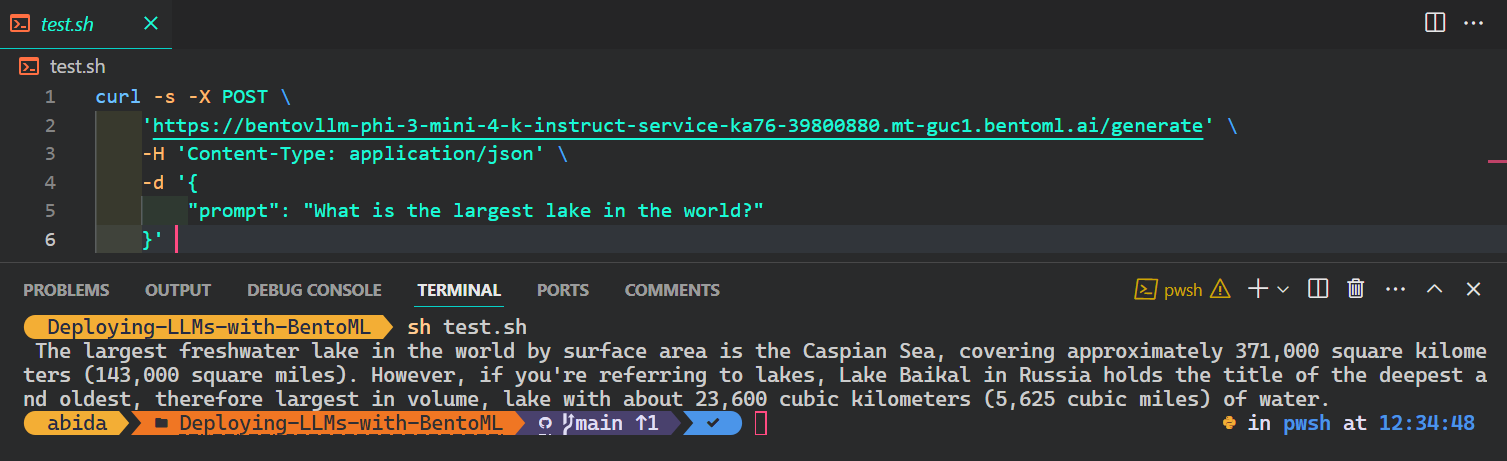
A maneira mais popular e mais fácil de acessar o serviço de IA de qualquer sistema operacional é usar o comando CURL no terminal:
$ curl -s -X POST \
'https://bentovllm-phi-3-mini-4-k-instruct-service-ka76-39800880.mt-guc1.bentoml.ai/generate' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "What is the largest lake in the world?"
}' 
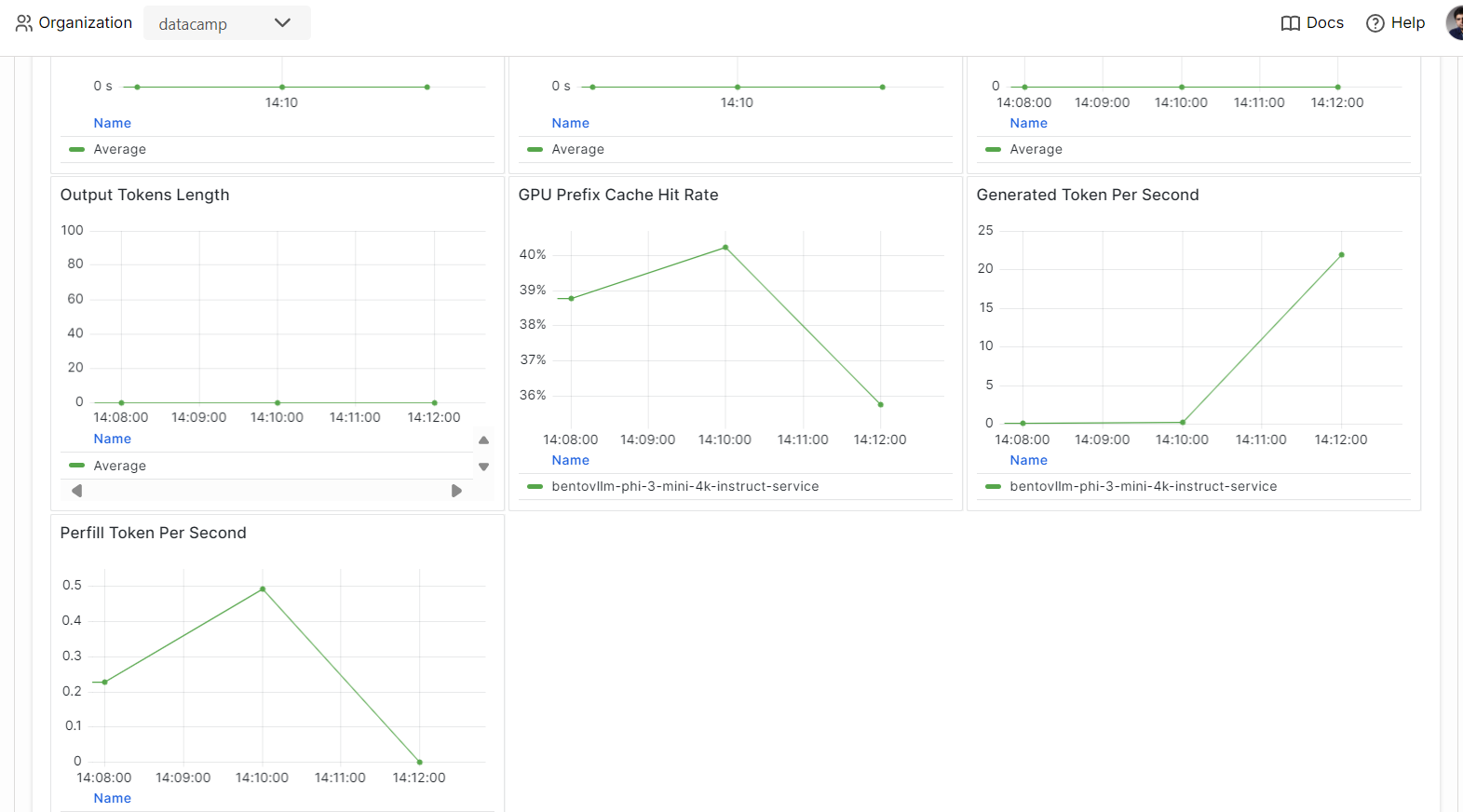
Vá para a guia "Monitoring" (Monitoramento) e examine todas as estatísticas relacionadas a LLMs, solicitações de usuários, hardware e outras análises de monitoramento que ajudarão você a avaliar o desempenho do servidor de IA.
Você também pode verificar a guia "Logs" ou usar o BentoML CLI para gerar logs em tempo real.
Os modelos de atendimento e implantação são uma parte do pipeline de MLOps. Ao concluir o curso MLOps totalmente automatizado, você pode aprender a criar arquitetura de MLOps, técnicas de CI/CD/CM/CT e padrões de automação para implantar sistemas de ML que podem agregar valor ao longo do tempo.
Se você quiser saber mais sobre o ecossistema do BentoML, a melhor abordagem é começar a criar e implantar seu serviço de IA. Você recebe créditos gratuitos, o que lhe permite usar GPUs e CPUs para explorar vários serviços. Isso pode incluir um aplicativo RAG (Retrieval-Augmented Generation), chamada de função, LLMs Agênticos ou um aplicativo multimodal que processa imagens e texto para gerar respostas.
Neste tutorial prático, aprendemos sobre o BentoML e como servir qualquer aplicativo de IA localmente com apenas algumas linhas de código. Em seguida, usamos o mecanismo de inferência vLLM para criar um serviço BentoML e o implantamos no BentoCloud com algumas etapas simples.
Considere fazer o curso de carreira de Engenheiro Associado de IA para Desenvolvedores para aprender a integrar a IA em aplicativos de software usando APIs e bibliotecas de código aberto.
Saiba mais sobre IA com estes cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
8 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Bex Tuychiev

