
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Viele Datenwissenschaftler und Ingenieure für maschinelles Lernen stehen vor Herausforderungen im Umgang mit Tools wie Docker, Kubernetes und Terraform sowie dem Aufbau einer sicheren Infrastruktur für KI-Modelle.
BentoML vereinfacht diesen Prozess und ermöglicht es dir, KI-Anwendungen mit nur wenigen Zeilen Python-Code zu erstellen, zu bedienen und einzusetzen.
Dieses Tutorial ist eine Schritt-für-Schritt-Anleitung für alle, die ihre eigene KI-App entwickeln wollen, die überall über einen einfachen CURL-Befehl zugänglich ist. Du lernst das BentoML-Framework kennen, erstellst lokal eine KI-App zur Beantwortung von Fragen und setzt das Phi 3 Mini-Modell in der BentoCloud ein.
BentoML ist ein Framework für maschinelles Lernen, das den Einsatz und die Skalierung von KI-Modellen vereinfacht. Sie automatisiert Aufgaben wie die Erstellung von Docker-Images, die Einrichtung von Instanzen, das Infrastruktur- und Sicherheitsmanagement sowie wichtige Funktionen, die für einen produktionsbereiten Server erforderlich sind.
Mit BentoML kannst du in wenigen Minuten mit einfachem Python-Code benutzerdefinierte KI-Modelle, vortrainierte Modelle oder fein abgestimmte Lösungen entwickeln und einsetzen. Sie bietet die Flexibilität, deine Cloud-Umgebung effizient zu skalieren und gleichzeitig die vollständige Kontrolle über Sicherheit und Compliance zu behalten.
BentoML ist Teil des MLOps-Toolsets. Entdecke weitere erstklassige MLOps-Tools zum Trainieren, Verfolgen, Bereitstellen, Orchestrieren, Testen, Überwachen und Verwalten der Infrastruktur, indem du den Blog Top 15 LLMOps Tools for Building AI Applications in 2024 liest.
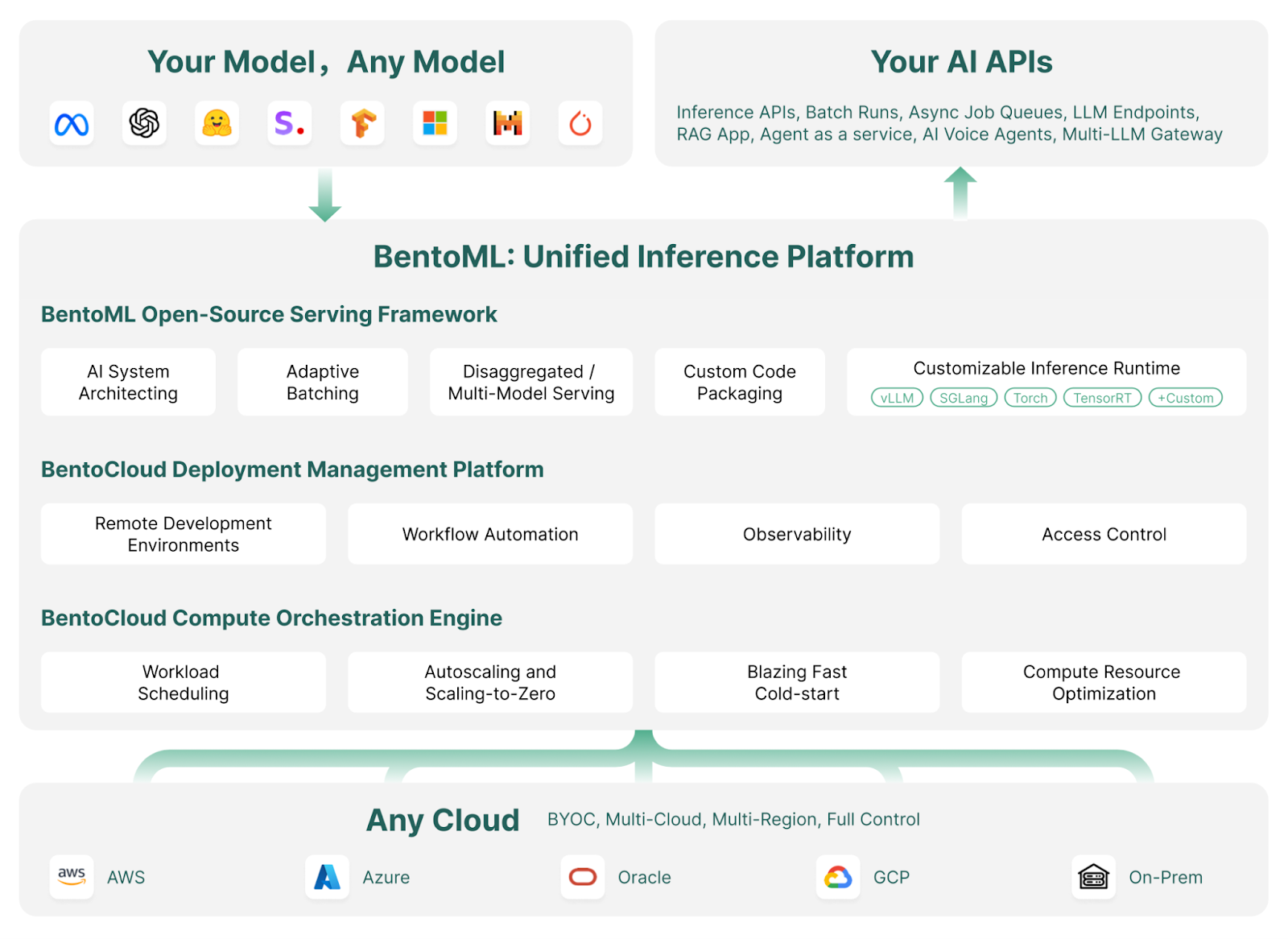
Wie BentoML funktioniert | Bildquelle: BentoML
Der leuchtende Stern des Bento Ökosystems ist seine Cloud: BentoCloud ist eine Erweiterung des BentoML-Frameworks und bietet zusätzliche Tools und Dienste, die die Bereitstellung, Überwachung und Skalierung von KI-Modellen noch einfacher machen.
Wenn du dich anmeldest, erhältst du kostenloses Guthaben für den Einstieg, was es zu einer attraktiven Option für Entwickler und Unternehmen macht.
Wenn du eine nicht-technische Person bist, die nach einer no-code bis low-code Lösung für die Entwicklung einer LLM-Anwendung sucht, empfehle ich dir den Leitfaden Local AI with Docker, n8n, Qdrant und Ollama.
In diesem Abschnitt stellen wir eine einfache KI-Anwendung vor, die die Fragen und den Kontext des Nutzers aufnimmt und die Antwort generiert.
Wir beginnen mit der Installation von BentoML, PyTorch und der Transformers-Bibliothek mit pip. Führe die folgenden Befehle in deinem Terminal aus:
$ pip install bentoml
$ pip install torch
$ pip install transformersAls Nächstes erstellen wir eine service.py Datei, um den AI-Server zu definieren.
Mit den BentoML-Befehlen werden wir die Transformers-Pipeline importieren, die es uns ermöglicht, das Modell zu laden und Inferenzen mit nur 2 Zeilen Code durchzuführen.
Wir werden Beispieltexteingaben und Kontext einrichten, den BentoML-Dienst mit Parametern wie der Anzahl der CPUs und dem Traffic-Timeout konfigurieren und die Klasse Question_Answering mithilfe der Transformers-Pipeline initialisieren.
Schließlich werden wir eine API namens generate() erstellen, die Eingaben und Ausgaben entgegennimmt und die generierte Antwort zurückgibt.
from __future__ import annotations
import bentoml
with bentoml.importing():
from transformers import pipeline
EXAMPLE_INPUT = "How can I generate a secure password?"
EXAMPLE_CONTEXT = """
To generate a secure password, you can use tools like the LastPass Password Generator.
These tools create strong, random passwords that help prevent security threats by ensuring your accounts are protected against hacking attempts.
A secure password typically includes a mix of uppercase and lowercase letters, numbers, and special characters. Avoid using easily guessable information like names or birthdays.
Using a password manager like LastPass can also help you store and manage these secure passwords effectively.
"""
@bentoml.service(
resources={"cpu": "4"},
traffic={"timeout": 10},
)
class Question_Answering:
def __init__(self) -> None:
# Load model into pipeline
self.pipe = pipeline(
"question-answering",
model="deepset/roberta-base-squad2",
)
@bentoml.api
def generate(
self,
text: str =EXAMPLE_INPUT,
doc: str = EXAMPLE_CONTEXT,
) -> str:
result = self.pipe(question=text, context=doc)
return result["answer"]Rufe den AI-Dienst lokal auf, indem du den folgenden Befehl in das Terminal eingibst:
$ bentoml serve service:Question_Answering Wie du siehst, haben wir dem Befehl oben den Dateinamen (service) und den Namen der Python-Klasse (Question_Answering ) für die KI-Modellinferenz angegeben.
Innerhalb weniger Sekunden wird eine URL generiert, die du kopieren und in deinen Browser einfügen kannst, um auf den BentoML-Server zuzugreifen:
[cli] Starting production HTTP BentoServer from "app:Question_Answering" listening on http://localhost:3000 (Press CTRL+C to quit)Der BentoML-Server ist der FastAPI Swagger UI sehr ähnlich.
Lass uns unseren Server mit der Option "Ausprobieren" testen.
Unser KI-Dienst funktioniert einwandfrei und hat eine genaue Antwort gegeben:
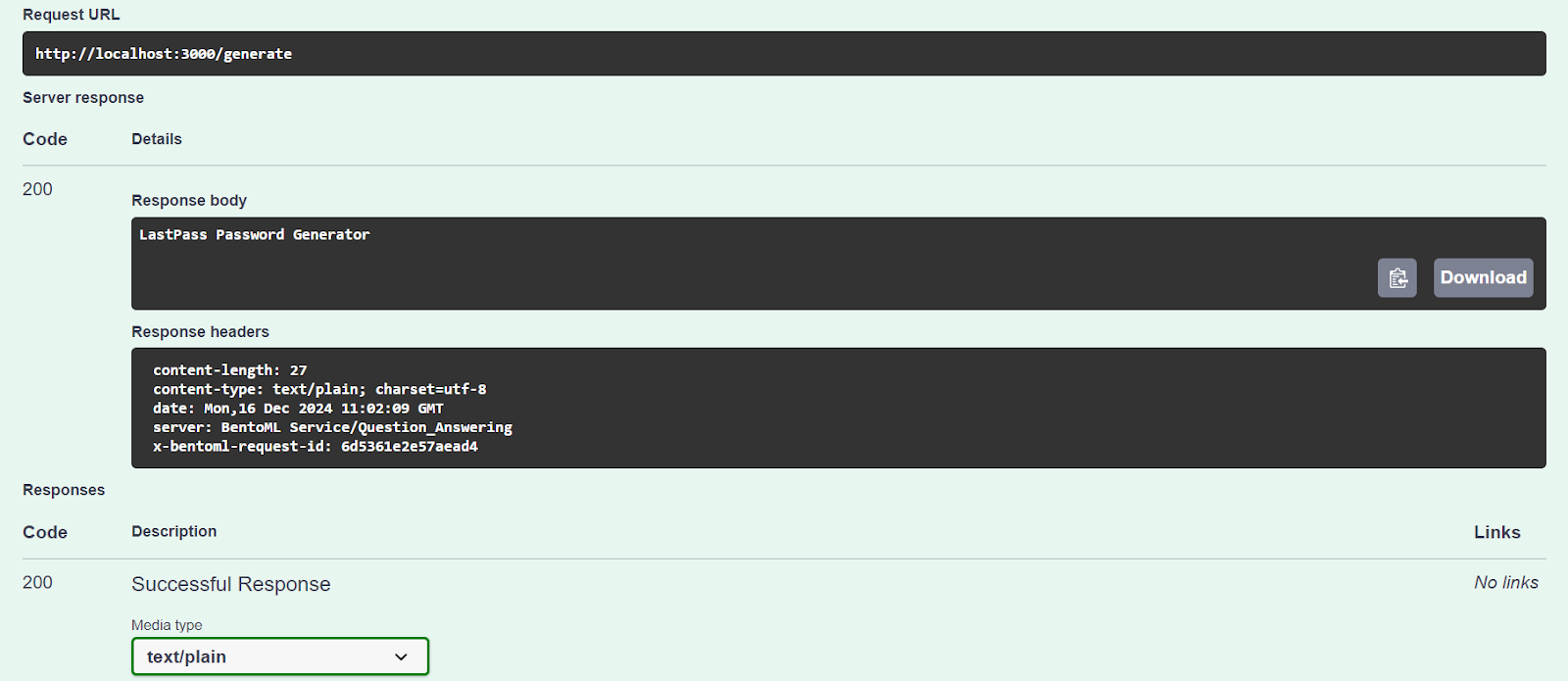
Wir können auch mit dem Befehl CURL auf den AI-Server zugreifen. Lass uns eine andere Frage stellen und sie mit einem Kontext versehen:
curl -X 'POST' \
'http://localhost:3000/generate' \
-H 'accept: text/plain' \
-H 'Content-Type: application/json' \
-d '{
"text": "How can I buy a cheap car?",
"doc": "Start by setting a budget and exploring sources like online marketplaces (Craigslist, Facebook Marketplace, Cars.com), local dealerships, or government auctions. Inspect the car thoroughly for issues like rust or mechanical problems, and consider bringing a trusted mechanic to avoid future repair costs. Research the reliability of specific brands and models using tools like Kelley Blue Book or Consumer Reports. Finally, negotiate the price to secure the best deal. Following these steps can help you find a dependable car within your budget."
}'Unser KI-Dienst funktioniert reibungslos und brauchte sogar auf der CPU 1 Sekunde, um eine Antwort zu generieren:
negotiate the priceEs ist an der Zeit, eine richtige KI-Anwendung mit großen Sprachmodellen (LLM) zu erstellen und sie mit minimalem Aufwand und Ressourcen auf BentoML einzusetzen.
Wir werden das vLLM-Framework verwenden, um eine LLM-Inferenz mit hohem Durchsatz zu erstellen und sie auf einer GPU-Instanz auf BentoCloud einzusetzen. Das hört sich vielleicht kompliziert an, aber BentoCloud nimmt dir die meiste Arbeit ab, einschließlich der Einrichtung der Infrastruktur, sodass du dich auf den Aufbau und die Bereitstellung deines Dienstes konzentrieren kannst.
BentoML bietet jede Menge Beispielcode und Ressourcen für verschiedene LLM-Projekte. Um loszulegen, klonen wir das BentoVLLM-Repository.
Navigiere zum Projekt Phi 3 Mini 4k und installiere alle erforderlichen Python-Bibliotheken:
$ git clone https://github.com/bentoml/BentoVLLM.git
$ cd BentoVLLM/phi-3-mini-4k-instruct
$ pip install -r requirements.txtSo sieht das Projektverzeichnis mit allen Dateien aus:
Wir werden die bentofile.yaml ändern, um den Namen des Besitzers und der Bühne zu ändern.
bentofile.yaml ist einfacher als Dockerfile und verwendet verschiedene Befehle zum Einrichten der Infrastruktur, der Umgebung und der Serverkonfigurationen; du kannst alle Befehle in den Bento-Bauoptionen nachlesen.
service: 'service:VLLM'
labels:
owner: Abid
stage: Guide
include:
- '*.py'
- 'bentovllm_openai/*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"service.py DateiWir werden die Datei service.py nicht ändern, sondern etwas über sie lernen.
@bentoml.service für die Bereitstellung und das Ressourcenmanagement, wie die Einrichtung von GPUs und die Verwaltung des Datenverkehrs.generate API wird über den @bentoml.api Dekorator definiert. Sie nimmt eine Benutzeraufforderung, eine optionale Systemaufforderung und eine maximale Tokengrenze als Eingaben entgegen, die dann an die vLLM Inferenzmaschine weitergegeben werden, um die Antwort zu generieren. generate streamt den Output des Modells in Chunks und erzeugt Tokens, sobald sie verfügbar sind.import uuid
from typing import AsyncGenerator, Optional
import bentoml
from annotated_types import Ge, Le
from typing_extensions import Annotated
from bentovllm_openai.utils import openai_endpoints
MAX_TOKENS = 1024
PROMPT_TEMPLATE = """<|system|>
{system_prompt}<|end|>
<|user|>
{user_prompt}<|end|>
<|assistant|>
"""
SYSTEM_PROMPT = """You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."""
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
@openai_endpoints(model_id=MODEL_ID)
@bentoml.service(
name="bentovllm-phi-3-mini-4k-instruct-service",
traffic={
"timeout": 300,
"concurrency": 256, # Matches the default max_num_seqs in the VLLM engine
},
resources={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
)
class VLLM:
def __init__(self) -> None:
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_TOKENS,
dtype="half",
enable_prefix_caching=True,
disable_sliding_window=True,
)
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
@bentoml.api
async def generate(
self,
prompt: str = "Explain superconductors in plain English",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
from vllm import SamplingParams
SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens)
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
prompt = PROMPT_TEMPLATE.format(user_prompt=prompt, system_prompt=system_prompt)
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Ich empfehle den Lernpfad Entwicklung von KI-Anwendungen, um zu lernen, wie man KI-gestützte Anwendungen mit den neuesten KI-Entwicklungstools erstellt, darunter die OpenAI API, Hugging Face und LangChain.
Gehe auf bentofile.yaml und füge in der letzten Zeile die Umgebungsvariable für das Hugging Face Token hinzu. So können wir das Modell sicher und ohne Probleme vom Hugging Face-Server laden:
envs:
- name: HF_TOKENMelde dich über die CLI bei BentoCloud an:
$ bentoml cloud loginDu wirst aufgefordert, das Konto zu erstellen und dann das API-Token zu erstellen.
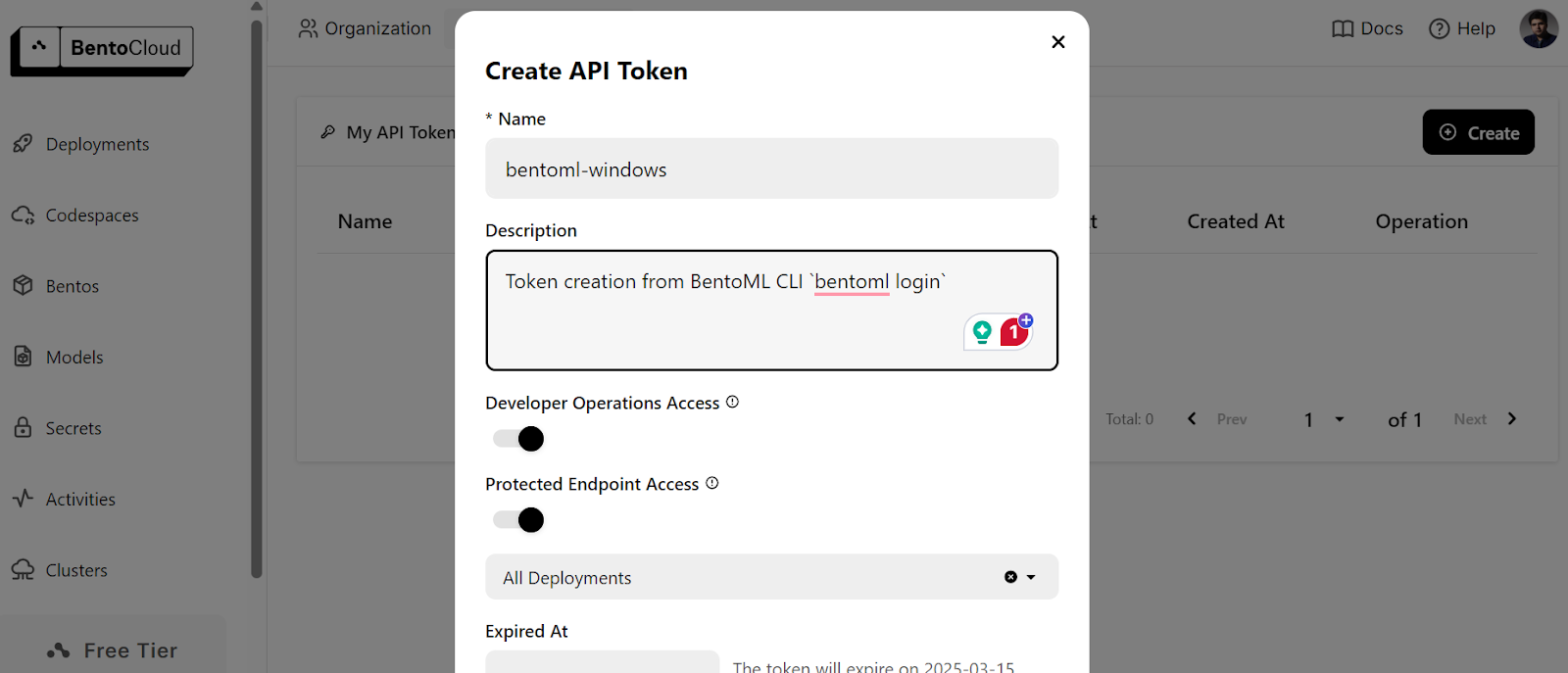
Nachdem du das API-Token erfolgreich erstellt hast, siehst du die Erfolgsmeldung in deinem Terminal:

Bevor wir den KI-Dienst in BentoCloud einsetzen, müssen wir eine Umgebungsvariable in BentoCloud erstellen, indem wir auf die Registerkarte "Geheimnisse" gehen und den Schlüsselnamen und den Hugging Face API-Schlüssel angeben.
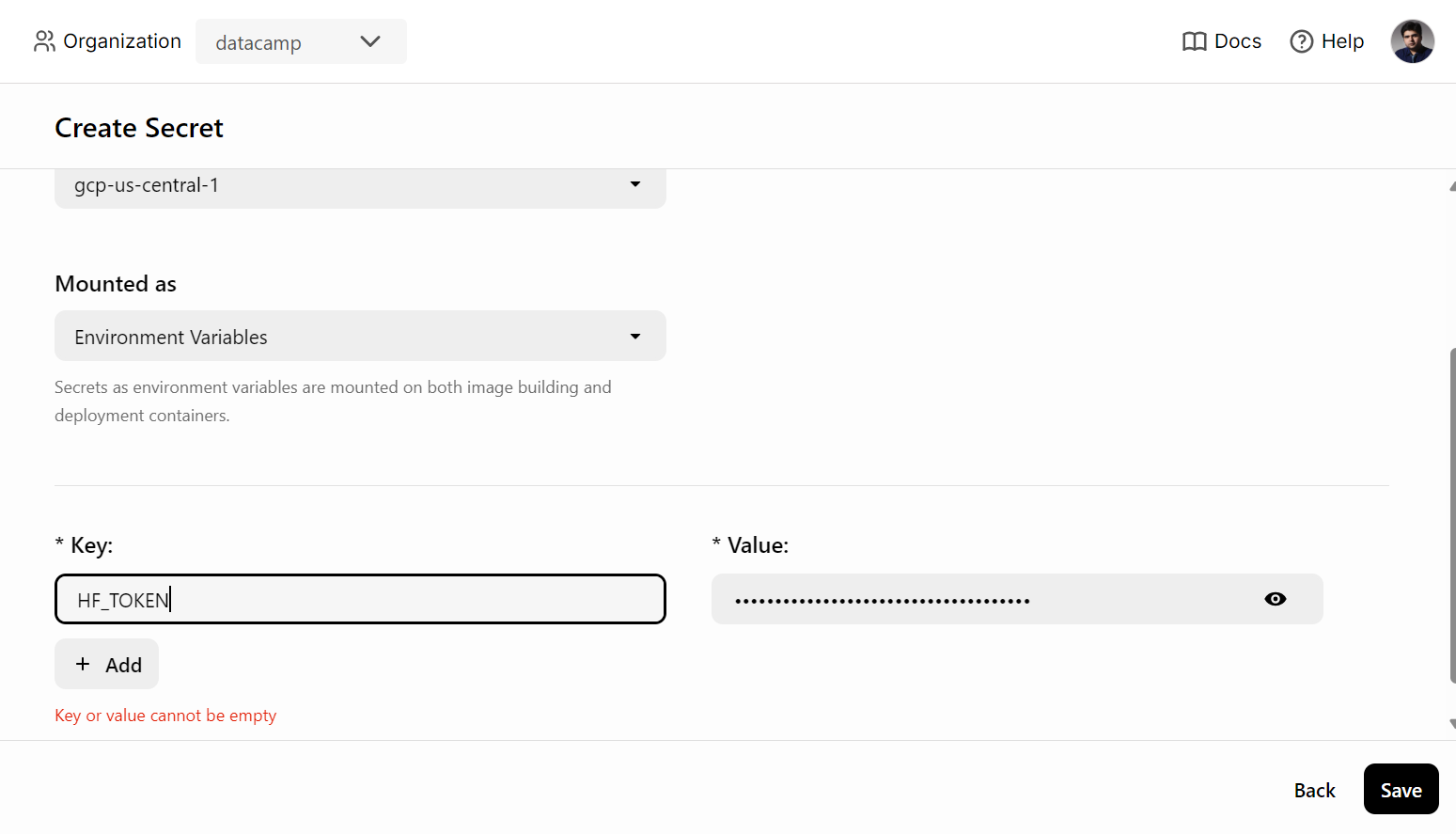
Danach verwendest du den folgenden Befehl, um den KI-Dienst einzusetzen:
$ bentoml deploy . --secret huggingfaceEs dauert ein paar Minuten, um das Modell herunterzuladen und die Umgebung für den Betrieb des Servers einzurichten.

Du kannst den Status deines KI-Dienstes überprüfen, indem du auf die Registerkarte "Einsätze" gehst.
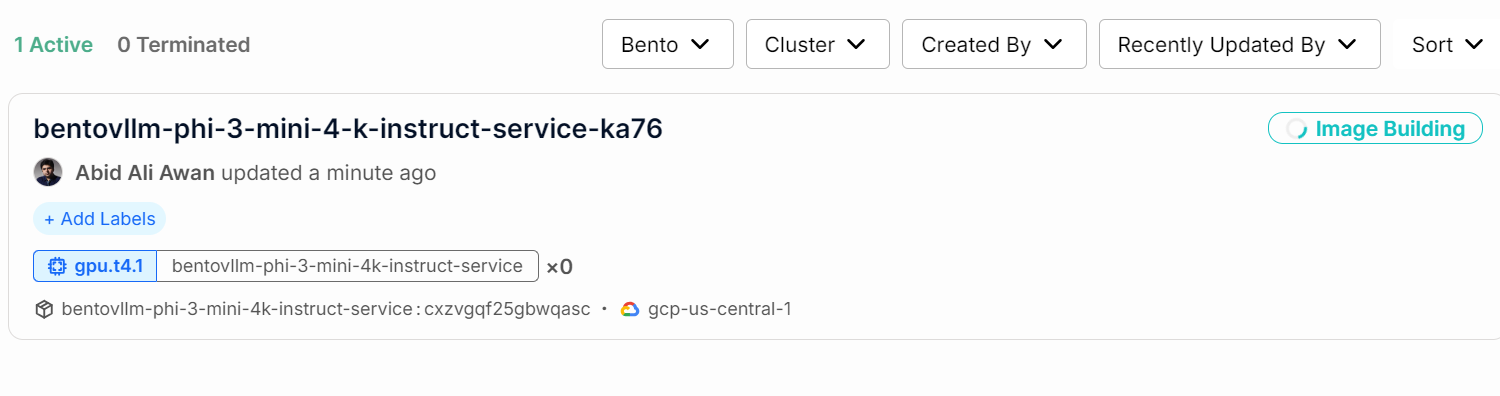
Du kannst auch alle Logs überprüfen und beobachten, was im Hintergrund passiert.
Sobald der KI-Dienst erfolgreich implementiert ist, beginnen wir mit dem Testen des Phi 3 Mini vLLM-Dienstes.
Um zu beginnen, können wir einfach auf die Registerkarte "Spielplatz" unter der Option "Einsätze" klicken, die Aufforderung eingeben und auf die Schaltfläche "Senden" klicken, um die Antwort zu generieren. Die Antwort wird in Echtzeit gestreamt.
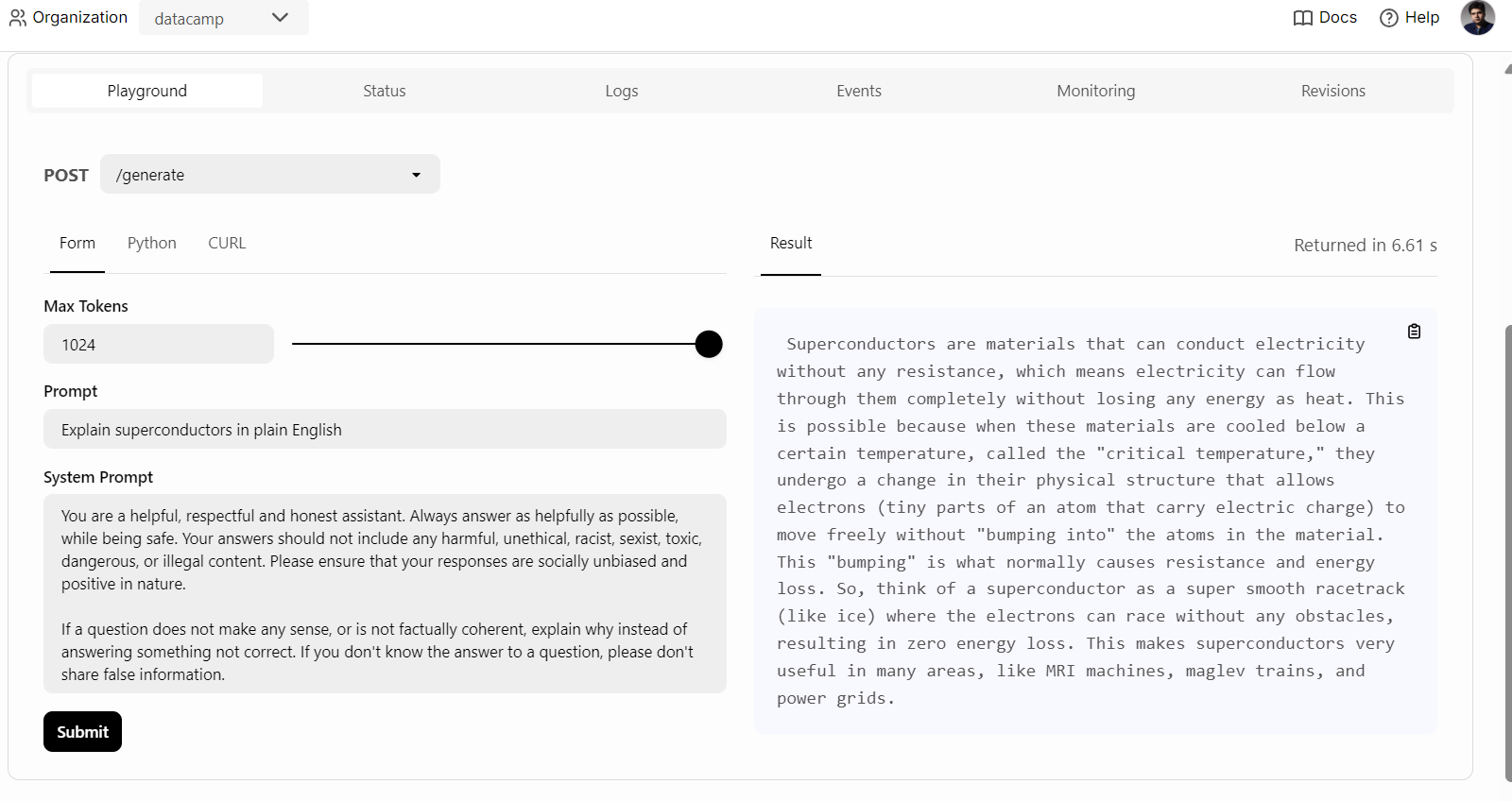 Wir können auch den BentoML-Python-Client verwenden, um auf das bereitgestellte Modell zuzugreifen und eine Antwort zu erzeugen. So kannst du den KI-Dienst in deine Anwendung integrieren:
Wir können auch den BentoML-Python-Client verwenden, um auf das bereitgestellte Modell zuzugreifen und eine Antwort zu erzeugen. So kannst du den KI-Dienst in deine Anwendung integrieren:
import bentoml
with bentoml.SyncHTTPClient(
"https://bentovllm-phi-3-mini-4-k-instruct-service-ka76-39800880.mt-guc1.bentoml.ai"
) as client:
response = client.generate(
prompt="What is the largest lake in the world?"
)
for chunk in response:
print(chunk, end="", flush=True)
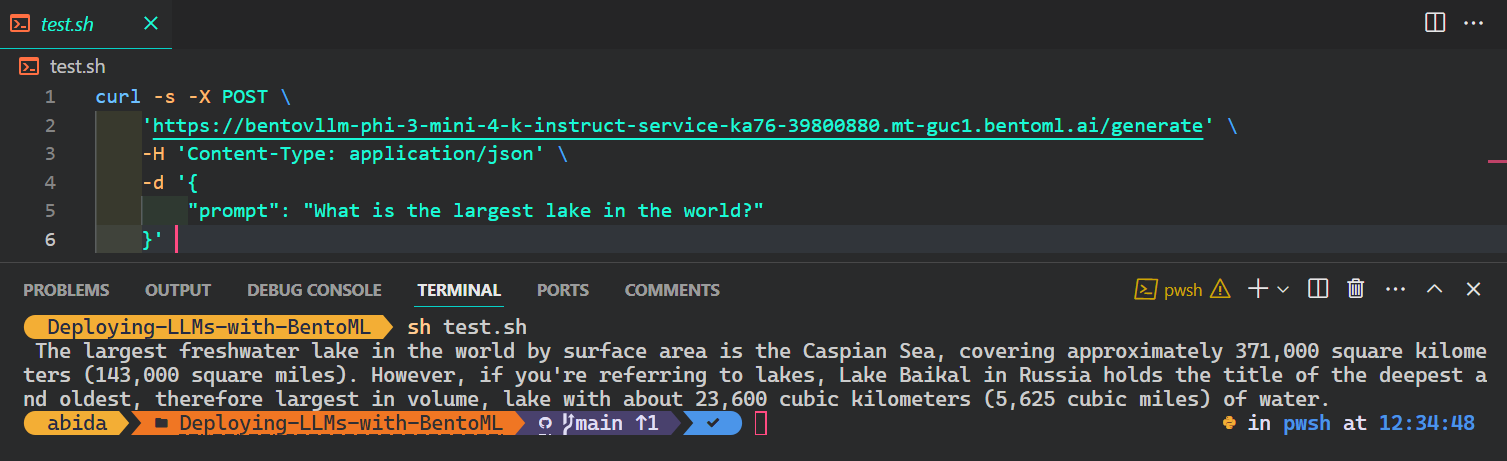
Der beliebteste und einfachste Weg, um von jedem Betriebssystem aus auf den KI-Dienst zuzugreifen, ist die Verwendung des Befehls CURL im Terminal:
$ curl -s -X POST \
'https://bentovllm-phi-3-mini-4-k-instruct-service-ka76-39800880.mt-guc1.bentoml.ai/generate' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "What is the largest lake in the world?"
}' 
Gehe auf die Registerkarte "Überwachung" und überprüfe alle Statistiken zu LLMs, Benutzeranfragen, Hardware und anderen Überwachungsanalysen, die dir helfen, die Leistung des KI-Servers zu beurteilen.
Du kannst auch auf der Registerkarte "Protokolle" nachsehen oder die BentoML CLI verwenden, um Echtzeitprotokolle zu erstellen.
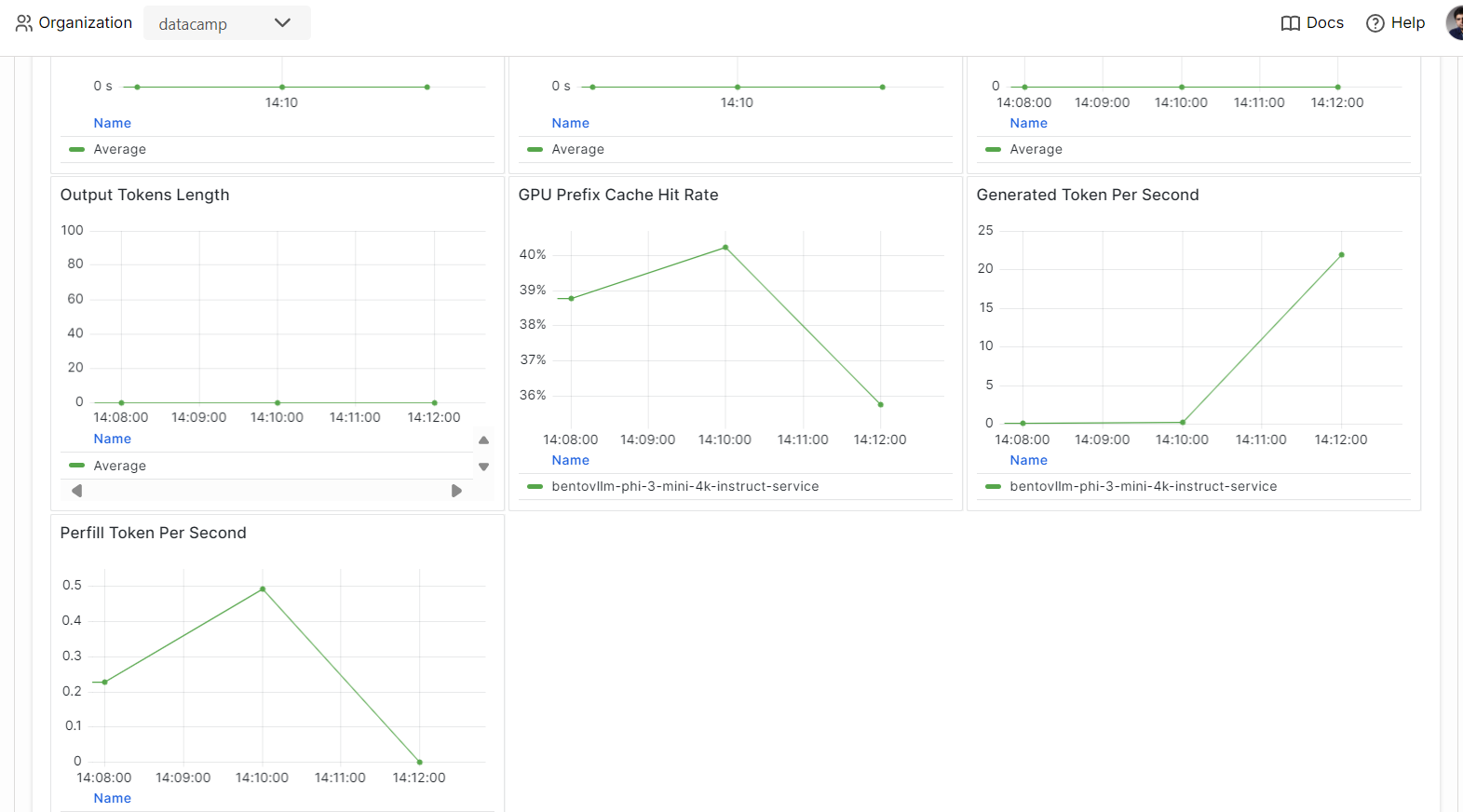
Die Serving- und Deploying-Modelle sind ein Teil der MLOps-Pipeline. Mit dem Abschluss des Kurses Fully Automated MLOps lernst du, eine MLOps-Architektur, CI/CD/CM/CT-Techniken und Automatisierungsmuster aufzubauen, um ML-Systeme bereitzustellen, die im Laufe der Zeit einen Mehrwert liefern können.
Wenn du mehr über das BentoML-Ökosystem erfahren möchtest, ist es am besten, wenn du mit dem Aufbau und Einsatz deines KI-Dienstes beginnst. Du erhältst kostenlose Credits, mit denen du GPUs und CPUs nutzen kannst, um verschiedene Dienste zu erkunden. Dies könnte eine Retrieval-Augmented Generation (RAG) Anwendung, Funktionsaufrufe, Agentic LLMs oder eine multimodale Anwendung sein, die Bilder und Text verarbeitet, um Antworten zu generieren.
In diesem praktischen Tutorial lernen wir BentoML kennen und erfahren, wie wir jede KI-Anwendung mit nur wenigen Zeilen Code lokal bedienen können. Dann haben wir die vLLM-Inferenzmaschine verwendet, um einen BentoML-Dienst zu erstellen und ihn mit ein paar einfachen Schritten auf BentoCloud zu implementieren.
Im Lernpfad "Associate AI Engineer for Developers " lernst du, wie du KI mithilfe von APIs und Open-Source-Bibliotheken in Softwareanwendungen integrieren kannst.
Lerne mehr über KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
