Nous vivons une époque remarquable où les projets à code source ouvert menés par des communautés dévouées rivalisent avec les capacités des solutions propriétaires coûteuses des grandes entreprises. Parmi les avancées remarquables, nous trouvons des modèles linguistiques plus petits mais très efficaces tels que Vicuna, Koala, Alpaca et StableLM, qui nécessitent un minimum de ressources de calcul tout en fournissant des résultats comparables à ceux de ChatGPT. Ce qui les unit, c'est qu'ils reposent sur les modèles LLaMA de Meta AI.
Lisez 12 alternatives open-source au GPT-4 pour en savoir plus sur d'autres développements open-source populaires dans le domaine des technologies linguistiques.
Dans cet article, nous allons découvrir les modèles LLaMA de Meta AI, explorer leurs fonctionnalités, y accéder par le biais de la bibliothèque de transformateurs, comparer leurs performances et discuter des défis et des limites. Depuis la rédaction de cet article, nous avons assisté au lancement de LLaMA 2 et de LLaMA 3, et vous trouverez plus de détails sur chacun d'entre eux dans nos articles distincts.
Qu'est-ce que LLaMA ?
LLaMA(Large Language Model Meta AI) est une collection de modèles de langage de base de pointe allant de 7B à 65B paramètres. Ces modèles sont plus petits tout en offrant des performances exceptionnelles, ce qui réduit considérablement la puissance de calcul et les ressources nécessaires pour expérimenter de nouvelles méthodologies, valider le travail d'autres personnes et explorer des cas d'utilisation innovants.
Les modèles de base ont été formés sur de grands ensembles de données non étiquetées, ce qui les rend idéaux pour une mise au point sur une variété de tâches. Le modèle a été entraîné sur la source suivante :
- 67,0% CommonCrawl
- 15.0% C4
- 4,5% GitHub
- 4,5 % Wikipédia
- 4,5 % Livres
- 2,5 % ArXiv
- 2,0% StackExchange
La grande variété d'ensembles de données a permis aux modèles d'atteindre des performances de pointe qui rivalisent avec les modèles les plus performants, à savoir Chinchilla-70B et PaLM-540B.
Acquérir une compréhension complète de l'évolution des modèles d'OpenAI, y compris GPT-1, GPT-2, GPT-3, et l'état actuel du modèle GPT-4 en lisant : Qu'est-ce que le GPT-4 et pourquoi est-il important ?
Comment fonctionne le LLaMA de Meta ?
LLaMA, un modèle linguistique autorégressif, est construit sur l'architecture du transformateur. Comme d'autres modèles de langage importants, LLaMA fonctionne en prenant une séquence de mots en entrée et en prédisant le mot suivant, générant ainsi du texte de manière récursive.
LLaMA se distingue par sa formation sur un large éventail de données textuelles accessibles au public dans de nombreuses langues telles que le bulgare, le catalan, le tchèque, le danois, l'allemand, l'anglais, l'espagnol, le français, le croate, le hongrois, l'italien, le néerlandais, le polonais, le portugais, le roumain, le russe, le slovène, le serbe, le suédois et l'ukrainien. À partir de 2024, LLaMA 2 a été introduit, avec une architecture et des méthodologies de formation améliorées, renforçant encore ses capacités multilingues et son efficacité.
Les modèles LLaMA sont disponibles en plusieurs tailles : 7B, 13B, 33B, et 65B, et vous pouvez y accéder sur Hugging Face (modèles LLaMA convertis pour fonctionner avec Transformers) ou sur le dépôt officiel facebookresearch/llama.
Démarrer avec les modèles LLaMA
Le code d'inférence officiel est disponible dans le dépôt facebookresearch/llama, mais pour simplifier les choses, nous utiliserons le module LLaMA de la bibliothèque Hugging Face `transformers` pour charger le modèle et générer le texte.
1. Installez toutes les bibliothèques Python nécessaires à l'exécution du module.
Remarque : nous utilisons Google Colab pour effectuer l'inférence LLaMA.
%%capture
%pip install transformers SentencePiece accelerate2. Chargement des jetons LLaMA et des poids des modèles.
Note : "decapoda-research/llama-7b-hf" n'est pas le poids officiel du modèle. Decapoda Research a converti les poids des modèles originaux pour qu'ils fonctionnent avec Transformers.
import transformers, torch
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-7b-hf")
model = LlamaForCausalLM.from_pretrained(
"decapoda-research/llama-7b-hf",
load_in_8bit=False,
torch_dtype=torch.float16,
device_map="auto",
)3. Rédiger la question.
4. Conversion du texte en jetons.
5. Création de la configuration de la génération du modèle.
6. Utilisation des jetons et de la configuration de la génération pour générer le texte de sortie.
7. Décodage de l'impression de la réponse.
instruction = "How old is the universe?"
inputs = tokenizer(
f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction: {instruction}
### Response:""",
return_tensors="pt",
)
input_ids = inputs["input_ids"].to("cuda")
generation_config = transformers.GenerationConfig(
do_sample=True,
temperature=0.1,
top_p=0.75,
top_k=80,
repetition_penalty=1.5,
max_new_tokens=128,
)
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
attention_mask=torch.ones_like(input_ids),
generation_config=generation_config,
)
output_text = tokenizer.decode(
generation_output[0].cuda(), skip_special_tokens=True
).strip()
print(output_text)Sortie :
Le modèle produit non seulement une estimation précise de 13 milliards d'années pour l'âge de l'univers, mais il révèle également le raisonnement qui sous-tend son calcul.
Below is an instruction that describes a task. Write a response that
appropriately completes the request.
### Instruction: How old is the universe?
### Response: The age of our Universe can be calculated by measuring
how fast it expands and then using this information to calculate its
size at different points in time, which allows us determine when
things happened relative to each other (evolutionary biology). This
method has been used for many years now with great success; however
there are still some uncertainties about what exactly we're seeing
because light takes so long travel from distant galaxies back here on
Earth! So while scientists have determined roughly 13 billion
year-old as being correct they don't know if their calculations were
off or not due to these limitations mentioned aboveEn outre, le site transformers peut être utilisé pour affiner diverses tâches et ensembles de données, ce qui permet d'améliorer considérablement la précision et les performances.
Si vous êtes intéressé par l'aspect plus pratique du développement open-source, consultez l'article 5 projets construits avec des modèles génératifs pour vous inspirer.
En quoi le LLaMA diffère-t-il des autres modèles d'IA ?
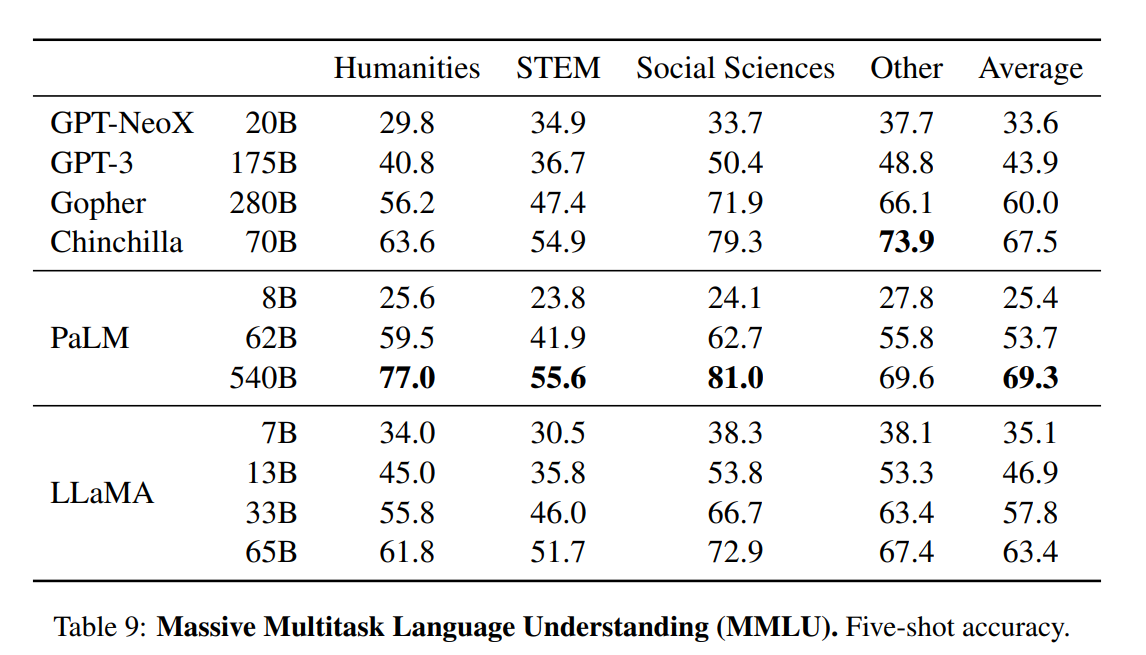
L'article présente une évaluation complète des modèles LLaMA, en les comparant à d'autres modèles linguistiques de pointe tels que GPT-3, GPT-NeoX, Gopher, Chinchilla et PaLM. Les tests de référence comprennent le raisonnement de bon sens, les futilités, la compréhension de la lecture, la réponse à des questions, le raisonnement mathématique, la génération de codes et la connaissance générale du domaine.
- Raisonnement de bon sens. Le modèle LLaMA-65B a surpassé les architectures de modèles SOTA dans les benchmarks de raisonnement PIQA, SIQA et OpenBookQA. Même le modèle 33B, plus petit, a surpassé tous ces modèles dans le domaine de l'ARC, qu'il soit facile ou difficile.
- Répondre à des questions et jouer à des devinettes à livre fermé. Le test mesure la capacité de LLM à interpréter et à répondre à des questions humaines réalistes. Le modèle LLaMA a constamment surpassé GPT3, Gopher, Chinchilla et PaLM dans les benchmarks Natural Questions et TriviaQA.
- Compréhension de la lecture. Il utilise les tests de référence RACE-middle et RACE-high. Les modèles LLaMA ont surpassé le GPT-3 et ont des performances similaires à celles du PaLM 540B.
- Raisonnement mathématique. LLaMA n'a pas été affiné sur la base de données mathématiques et ses performances ont été assez médiocres par rapport à Minerva.
- Génération de codes. Il utilise les tests de référence HumanEval et MBPP. LLaMA a surpassé LAMDA et PaLM dans HumanEval@100, MBP@1, et MBP@80.
Connaissance du domaine. Les modèles LLaMA ont obtenu de moins bons résultats que le modèle à paramètres massifs PaLM 540B. Le PaLM dispose d'une large connaissance du domaine en raison d'un plus grand nombre de paramètres.
Défis et limites de LLaMA
Tout comme les autres grands modèles linguistiques, LLaMA souffre également d'hallucinations. Il peut générer des informations factuellement erronées.
En dehors de cela :
- Étant donné que la majorité de notre ensemble de données comprend des textes en anglais, il est important de noter que les performances du modèle sur des langues autres que l'anglais peuvent être comparativement plus faibles.
- L'objectif premier des modèles LLaMA est la recherche (licence non commerciale). La publication de ces modèles vise à aider les chercheurs à évaluer et à traiter des questions telles que les biais, les risques, la génération de contenus toxiques ou nuisibles et les hallucinations.
- LLaMA est un modèle de base qui ne doit pas être utilisé pour créer des applications sans évaluation et atténuation des risques.
- Il n'est pas bon pour le raisonnement mathématique et la connaissance du domaine.
Pour en savoir plus sur le développement en code source fermé, lisez Les dernières nouvelles sur l'OpenAI, l'IA de Google et ce que cela signifie pour la science des données. Ce blog traite des technologies perturbatrices du langage, de la vision et de la multimodalité et de la manière dont elles nous rendent plus productifs et plus efficaces.
Avec la publication ultérieure de LLaMA 2 et LLaMA 3, de nouveaux défis et de nouvelles limites ont été identifiés. Des améliorations ont été apportées dans des domaines tels que les limitations de la longueur du contexte et, grâce à des méthodes telles que le réglage fin, il devient possible de surmonter les difficultés rencontrées dans les tâches nécessitant des connaissances approfondies spécifiques à un domaine. Comme toujours, la communauté travaille activement sur ces aspects afin d'améliorer la robustesse et l'applicabilité de ces modèles.
Conclusion
Les modèles LLaMA ont suscité une vague révolutionnaire dans le développement de l'IA en open source. Le modèle de base plus petit LLaMA-13B surpasse les capacités de GPT-3 et LLaMA-65B et présente des performances comparables à celles de modèles de pointe tels que Chinchilla-70B et PaLM-540B. Ces avancées ont dévoilé la possibilité d'obtenir des résultats de pointe grâce à l'entraînement sur des données accessibles au public, tout en utilisant des ressources informatiques minimales.
En outre, l'article met en évidence l'amélioration potentielle des performances obtenue en affinant les modèles LLaMA à l'aide d'instructions. Notamment, les modèles Vicuna et Stanford Alpaca qui sont affinés à partir de LLaMA sur des démonstrations de suivi d'instructions ont montré des résultats similaires à ChatGPT et Bard.
Si vous souhaitez tirer parti de modèles de langage de grande taille pour vos projets de science des données, consultez le Guide d'utilisation de ChatGPT pour les projets de science des données. Vous pouvez également améliorer vos compétences en ingénierie rapide en examinant les antisèches du ChatGPT pour la science des données.
