
Cursus
Principes fondamentaux de l'IA
10 h
Meta a publié une nouvelle série de grands modèles de langage (LLM) appelée Llama 3, une collection de modèles texte-à-texte pré-entraînés et adaptés aux instructions.
Llama 3 est un modèle linguistique auto-régressif qui utilise une architecture de transformateur optimisée. Les modèles pré-entraînés et adaptés aux instructions sont dotés de 8B et 70B paramètres avec une longueur de contexte de 8K tokens.
Le lama 3 8B est le LLM le plus apprécié sur Hugging Face. Sa version adaptée aux instructions est meilleure que Gemma 7B-It et Mistral 7B Instruct de Google sur différents critères de performance. La version 70B avec instructions a surpassé Gemini Pro 1.5 et Claude Sonnet sur la plupart des critères de performance :
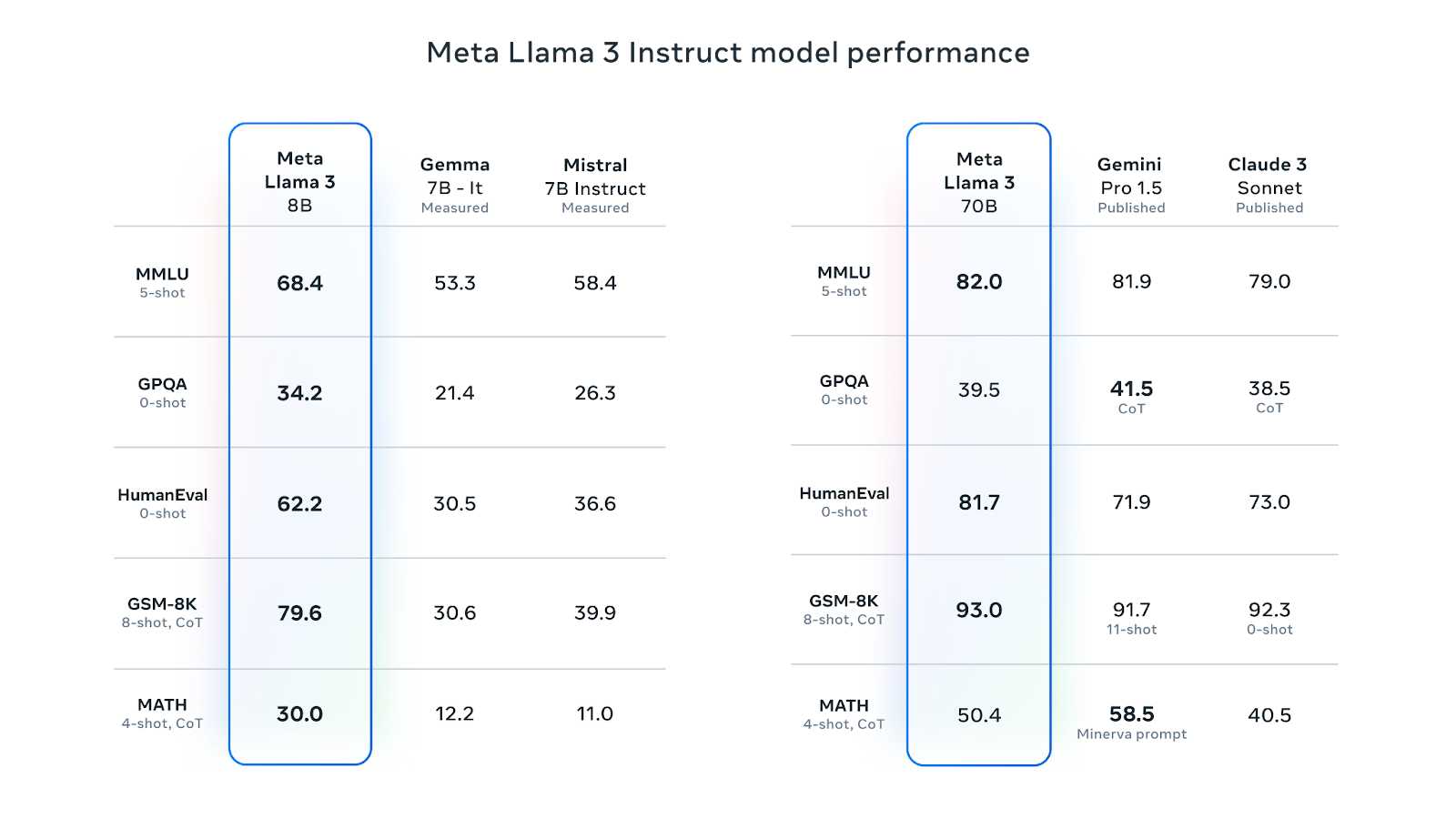
Source : Meta Llama 3
Meta a entraîné Llama 3 sur un nouveau mélange de données en ligne accessibles au public, avec un nombre de jetons de plus de 15 billions. Le modèle 8B a une date limite de connaissance fixée à mars 2023, tandis que le modèle 70B a une date limite de connaissance fixée à décembre 2023. Les modèles utilisent la méthode GQA (Grouped-Query Attention), qui réduit la bande passante de la mémoire et améliore l'efficacité.
Les modèles Llama 3 ont été diffusés sous une licence commerciale personnalisée. Pour accéder au modèle, vous devez remplir le formulaire en indiquant votre nom, votre affiliation et votre adresse électronique et accepter les conditions générales. Si vous utilisez différentes adresses électroniques pour différentes plateformes comme Kaggle et Hugging Face, vous devrez peut-être remplir le formulaire plusieurs fois.
Pour en savoir plus sur le lama 3, consultez l'article " Qu'est-ce que le lama 3 ?
Pour ce tutoriel, nous allons affiner le modèle Llama 3 8B-Chat en utilisant le jeu de données ruslanmv/ai-medical-chatbot. L'ensemble de données contient 250 000 dialogues entre un patient et un médecin. Nous utiliserons le Notebook Kaggle pour accéder à ce modèle et aux GPU libres.
Avant de lancer le Notebook Kaggle, remplissez le formulaire de téléchargement Meta avec votre adresse e-mail Kaggle, puis allez sur la page du modèle Llama 3 sur Kaggle et acceptez l'accord. La procédure d'approbation peut prendre un à deux jours.
Procédez maintenant comme suit :
1. Lancez le nouveau Notebook sur Kaggle, et ajoutez le modèle Llama 3 en cliquant sur le bouton + Add Input, en sélectionnant l'option Models, et en cliquant sur le bouton plus + à côté du modèle Llama 3. Sélectionnez ensuite le cadre, la variation et la version appropriés, puis ajoutez le modèle.
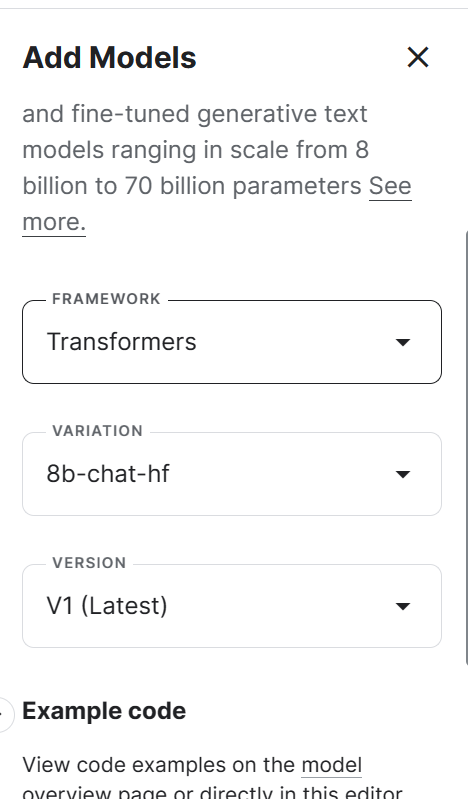
2. Allez dans les options de la session et sélectionnez le GPU P100 comme accélérateur.
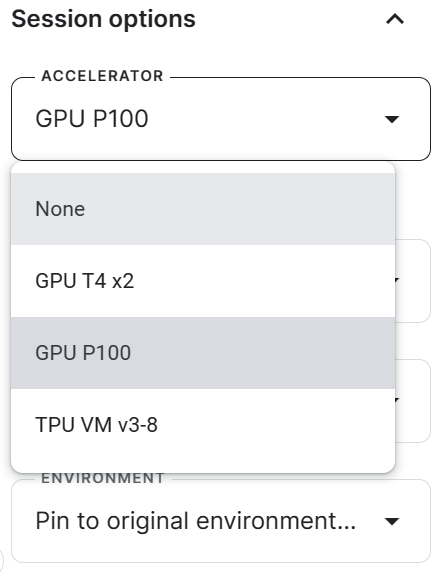
3. Générez les jetons Hugging Face et Weights & Biases, et créez les Kaggle Secrets. Vous pouvez créer et activer les secrets Kaggle en allant dans Add-ons > Secrets > Ajouter un nouveau secret.
4. Démarrez la session Kaggle en installant tous les paquets Python nécessaires.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandb5. Importez les pages Python nécessaires au chargement de l'ensemble de données, du modèle et du tokenizer, ainsi qu'à la mise au point.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_format6. Nous allons suivre le processus d'apprentissage à l'aide de Weights & Biases, puis enregistrer le modèle affiné sur Hugging Face, et pour cela, nous devons nous connecter à la fois à Hugging Face Hub et à Weights & Biases à l'aide de la clé API.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama 3 8B on Medical Dataset',
job_type="training",
anonymous="allow"
)7. Définissez le modèle de base, l'ensemble de données et la nouvelle variable du modèle. Nous chargerons le modèle de base de Kaggle et le jeu de données de HugginFace Hub, puis nous enregistrerons le nouveau modèle.
base_model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
dataset_name = "ruslanmv/ai-medical-chatbot"
new_model = "llama-3-8b-chat-doctor"8. Définissez le type de données et la mise en œuvre de l'attention.
torch_dtype = torch.float16
attn_implementation = "eager"Dans cette partie, nous allons charger le modèle à partir de Kaggle. Cependant, en raison de contraintes de mémoire, nous ne sommes pas en mesure de charger le modèle complet. Par conséquent, nous chargeons le modèle en utilisant une précision de 4 bits.
Notre objectif dans ce projet est de réduire l'utilisation de la mémoire et d'accélérer le processus de réglage fin.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)Chargez le tokenizer, puis configurez un modèle et un tokenizer pour les tâches d'IA conversationnelle. Par défaut, il utilise le modèle chatml d'OpenAI, qui convertit le texte d'entrée dans un format de type chat.
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
model, tokenizer = setup_chat_format(model, tokenizer)Le réglage fin du modèle complet prendra beaucoup de temps. Pour améliorer le temps d'apprentissage, nous attacherons la couche d'adaptation à quelques paramètres, ce qui rendra l'ensemble du processus plus rapide et plus efficace en termes de mémoire.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
model = get_peft_model(model, peft_config)Pour charger et prétraiter notre ensemble de données, nous.. :
1. Chargez l'ensemble de données ruslanmv/ai-medical-chatbot, mélangez-le et sélectionnez uniquement les 1000 premières lignes. Cela réduira considérablement le temps de formation.
2. Mettez en forme le modèle de chat pour qu'il soit conversationnel. Combinez les questions du patient et les réponses du médecin dans une colonne "texte".
3. Affichez un échantillon de la colonne de texte (la colonne "texte" a un format de type "chat" avec des jetons spéciaux).
#Importing the dataset
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
def format_chat_template(row):
row_json = [{"role": "user", "content": row["Patient"]},
{"role": "assistant", "content": row["Doctor"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc=4,
)
dataset['text'][3]
4. Divisez l'ensemble de données en un ensemble de formation et un ensemble de validation.
dataset = dataset.train_test_split(test_size=0.1)Nous définissons les hyperparamètres du modèle afin de pouvoir l'exécuter sur Kaggle. Vous pouvez en savoir plus sur chaque hyperparamètre en lisant le tutoriel Fine-Tuning Llama 2.
Nous affinons le modèle pour une époque et enregistrons les mesures à l'aide des poids et des biais.
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)Nous allons maintenant mettre en place un formateur de réglage fin supervisé (SFT) et fournir un ensemble de données de formation et d'évaluation, une configuration LoRA, un argument de formation, un tokenizer et un modèle. Nous maintenons le site max_seq_length à 512 pour éviter de dépasser la mémoire du GPU pendant l'entraînement.
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length=512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Nous commencerons le processus d'ajustement en exécutant le code suivant.
trainer.train()Les pertes de formation et de validation ont toutes deux diminué. Pour obtenir de meilleurs résultats, envisagez d'entraîner le modèle pendant trois époques sur l'ensemble des données.
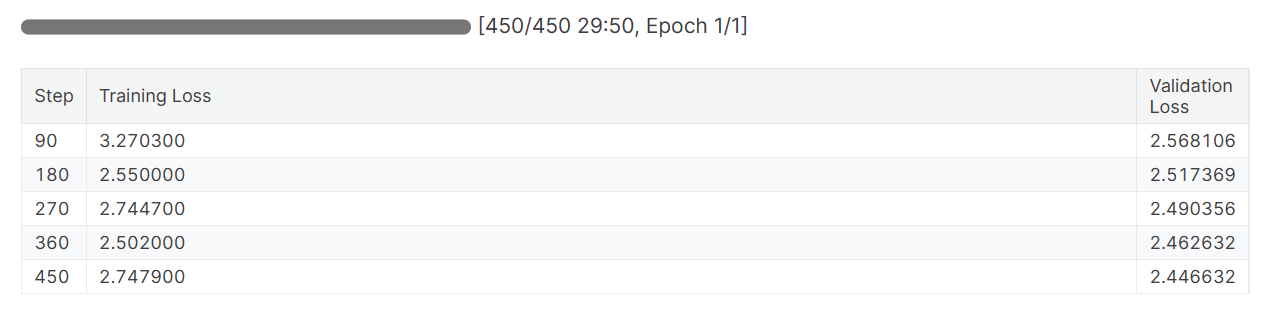
Lorsque vous terminez la session Pondérations et biais, l'historique et le résumé de l'exécution sont générés.
wandb.finish()
model.config.use_cache = True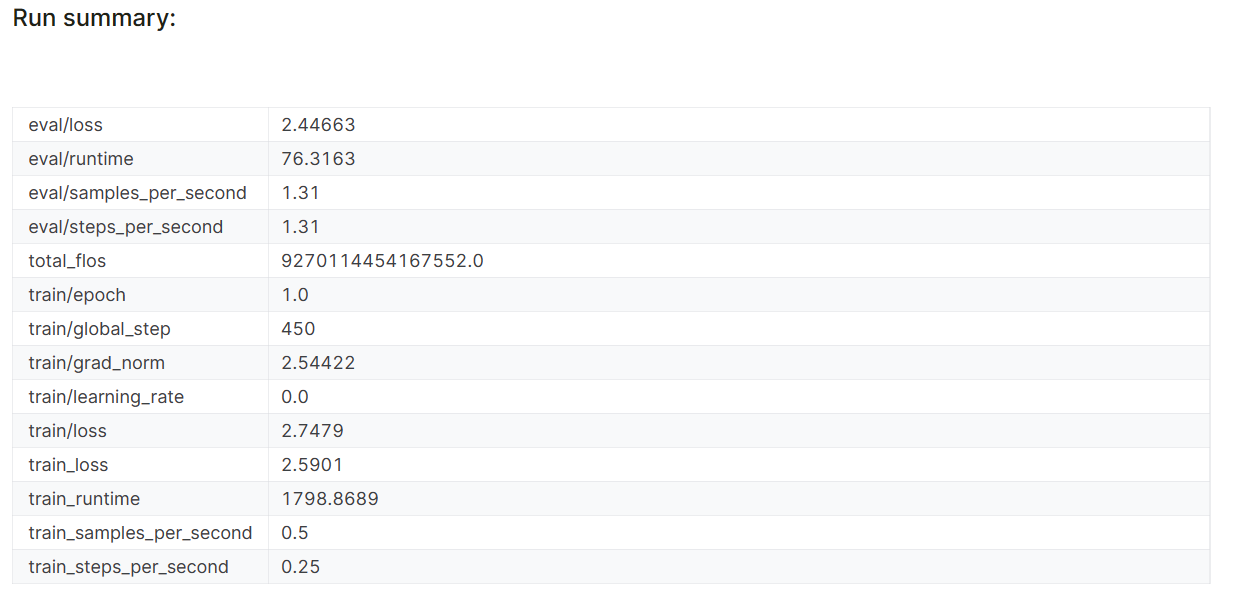
Les mesures de performance du modèle sont également stockées sous le nom du projet spécifique sur votre compte Pondérations et Biais.
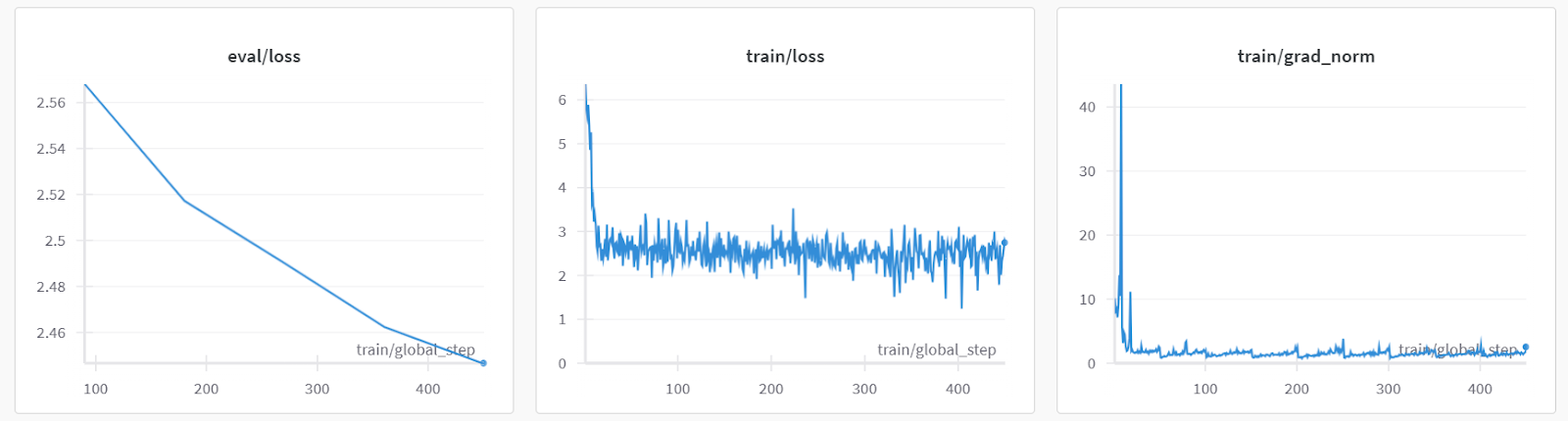
Évaluons le modèle sur un exemple de requête de patient afin de vérifier s'il est correctement ajusté.
Pour générer une réponse, nous devons convertir les messages au format chat, les faire passer par le tokenizer, saisir le résultat dans le modèle, puis décoder le token généré pour afficher le texte.
messages = [
{
"role": "user",
"content": "Hello doctor, I have bad acne. How do I get rid of it?"
}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False,
add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True,
truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=150,
num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])
Il s'avère que nous pouvons obtenir des résultats moyens même avec une seule époque.
Nous allons maintenant enregistrer l'adaptateur ajusté et le pousser vers le Hugging Face Hub. L'API Hub créera automatiquement le référentiel et stockera le fichier adaptateur.
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)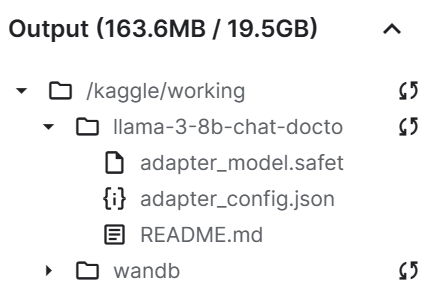
Comme nous pouvons le constater, notre fichier d'adaptateur de sauvegarde est nettement plus petit que le modèle de base.
Enfin, nous enregistrerons le cahier avec le fichier adaptateur pour le fusionner avec le modèle de base dans le nouveau cahier.
Pour sauvegarder le Carnet de notes Kaggle, cliquez sur le bouton Enregistrer la version en haut à droite, sélectionnez le type de version comme Sauvegarde rapide, ouvrez les paramètres avancés, sélectionnez Toujours enregistrer la sortie lors de la création d'une sauvegarde rapide, puis appuyez sur le bouton Enregistrer.
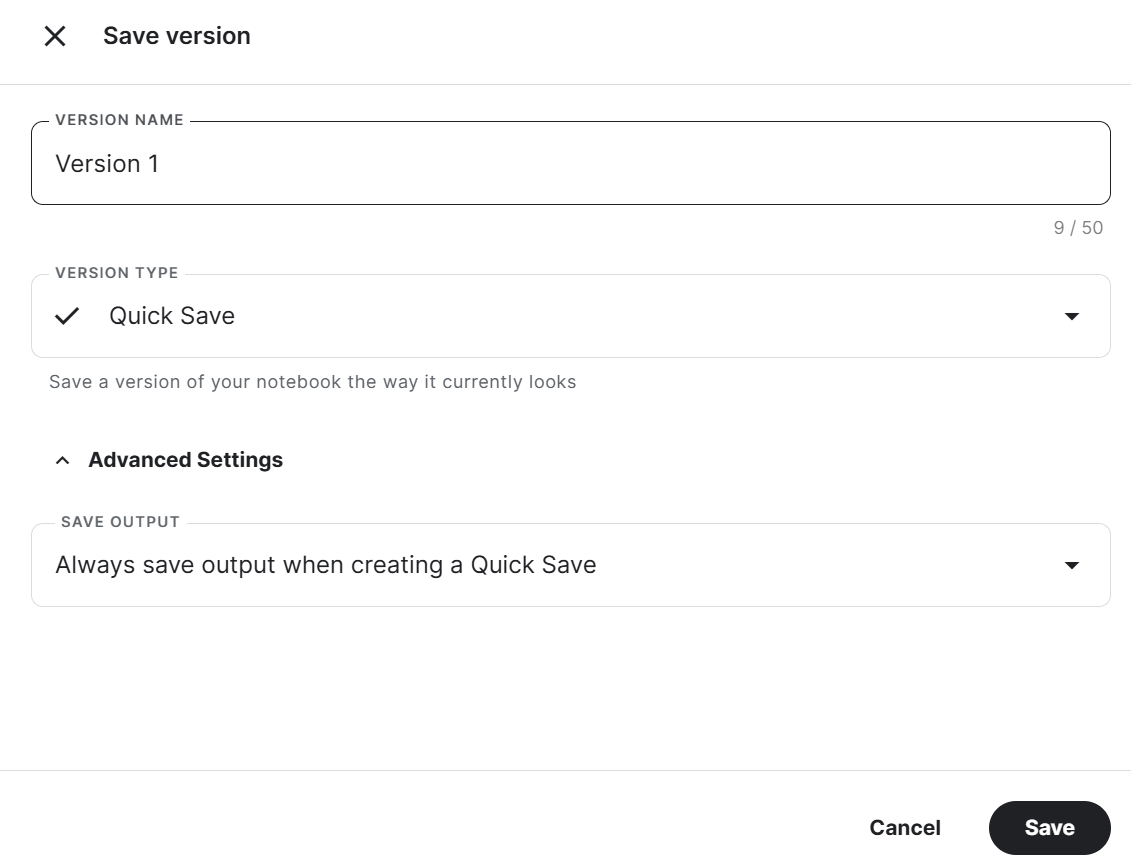
Si vous rencontrez un problème lors de l'exécution du code, reportez-vous à ce carnet Kaggle : Ajustement du Llama 3 8B sur un ensemble de données médicales.
Nous avons affiné notre modèle en utilisant le GPU. Vous pouvez également apprendre à affiner les LLM à l'aide des TPU en suivant le tutoriel Fine-Tune and Run Inference on Google's Gemma Model Using TPUs (Ajustement précis et exécution de l'inférence sur le modèle Gemma de Google à l'aide des TPU).
Si vous souhaitez apprendre à régler d'autres modèles, consultez le didacticiel Mistral 7B : Un guide étape par étape pour utiliser et peaufiner le Mistral 7B.
Pour utiliser le modèle affiné localement, nous devons d'abord fusionner l'adaptateur avec le modèle de base, puis enregistrer le modèle complet.
Procédez comme suit :
1. Créez un nouveau Notebook Kaggle et installez tous les paquets Python nécessaires. Assurez-vous que vous utilisez le GPU comme accélérateur.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trl2. Connectez-vous au Hugging Face Hub en utilisant les secrets Kaggle. Cela nous aidera à télécharger facilement le modèle complet mis au point.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)3. Ajoutez le modèle Llama 3 8B Chat et un carnet de notes Kaggle affiné que nous avons récemment sauvegardé. Nous pouvons ajouter les Notebooks dans la session en cours de la même manière que vous ajoutez un jeu de données et des modèles.
L'ajout de Notebook à la session Kaggle nous permettra d'accéder aux fichiers de sortie. Dans notre cas, il s'agit d'un fichier d'adaptateur de modèle.
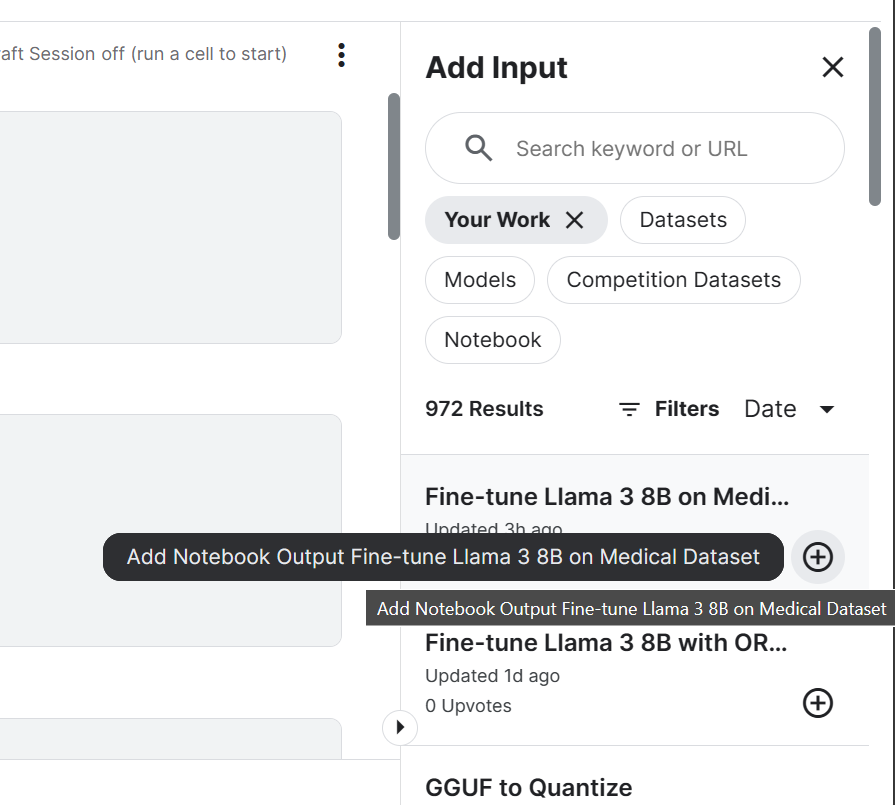
4. Définir la variable avec l'emplacement du modèle de base et de l'adaptateur.
base_model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
new_model = "/kaggle/input/fine-tune-llama-3-8b-on-medical-dataset/llama-3-8b-chat-doctor/"Nous commencerons par charger le tokenizer et le modèle de base à l'aide de la bibliothèque transformers. Ensuite, nous mettrons en place le format de chat en utilisant la bibliothèque trl. Enfin, nous chargerons et fusionnerons l'adaptateur au modèle de base à l'aide de la bibliothèque PEFT.
La fonction merge_and_unload() nous aidera à fusionner les poids de l'adaptateur avec le modèle de base et à l'utiliser comme un modèle autonome.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, new_model)
model = model.merge_and_unload()Pour vérifier si notre modèle a été fusionné correctement, nous allons effectuer une inférence simple en utilisant pipeline de la bibliothèque transformers. Nous convertirons le message à l'aide du modèle de chat, puis nous fournirons une invite au pipeline. Le pipeline a été initialisé à l'aide du modèle, du tokenizer et du type de tâche.
Par ailleurs, vous pouvez régler device_map sur "auto" si vous souhaitez utiliser plusieurs GPU.
messages = [{"role": "user", "content": "Hello doctor, I have bad acne. How do I get rid of it?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
Notre modèle affiné fonctionne comme prévu après avoir été fusionné.
Nous allons maintenant enregistrer un tokenizer et un modèle à l'aide de la fonction save_pretrained().
model.save_pretrained("llama-3-8b-chat-doctor")
tokenizer.save_pretrained("llama-3-8b-chat-doctor")Les fichiers du modèle sont stockés au format safetensors, et la taille totale du modèle est d'environ 16 Go.
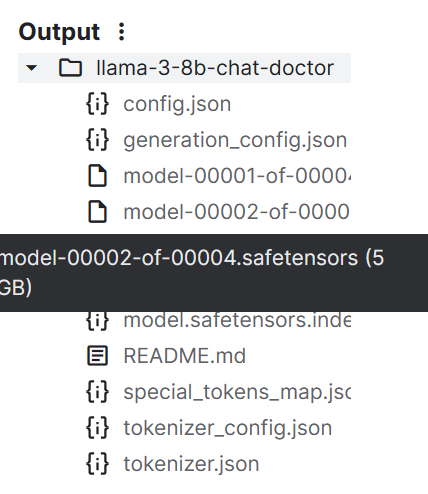
Nous pouvons transférer tous les fichiers vers le Hugging Face Hub à l'aide de la fonction push_to_hub().
model.push_to_hub("llama-3-8b-chat-doctor", use_temp_dir=False)
tokenizer.push_to_hub("llama-3-8b-chat-doctor", use_temp_dir=False)Enfin, nous pouvons sauvegarder le carnet de notes Kaggle comme nous l'avons fait précédemment.
L'utilisation de l'adaptateur Fine Tuned pour modéliser entièrement Kaggle Notebook vous aidera à résoudre tout problème lié à l'exécution du code par vous-même.
Nous ne pouvons pas utiliser les fichiers safetensors localement car la plupart des chatbots IA locaux ne les prennent pas en charge. Au lieu de cela, nous allons le convertir au format de fichier GGUF llama.cpp.
Démarrez une nouvelle session Kaggle Notebook et ajoutez l'adaptateur Fine Tuned au modèle complet de Notebook.
Clonez le dépôt llama.cpp et installez le framework llama.cpp à l'aide de la commande make comme indiqué ci-dessous.
Par ailleurs, la commande ci-dessous ne fonctionne que pour le carnet de notes Kaggle. Il se peut que vous deviez modifier certaines choses pour l'utiliser sur d'autres plateformes ou localement.
%cd /kaggle/working
!git clone --depth=1 https://github.com/ggerganov/llama.cpp.git
%cd /kaggle/working/llama.cpp
!sed -i 's|MK_LDFLAGS += -lcuda|MK_LDFLAGS += -L/usr/local/nvidia/lib64 -lcuda|' Makefile
!LLAMA_CUDA=1 conda run -n base make -j > /dev/nullExécutez la commande suivante dans la cellule du Notebook Kaggle pour convertir le modèle au format GGUF.
Le site convert-hf-to-gguf.py requiert un répertoire de modèle d'entrée, un répertoire de fichier de sortie et un type de sortie.
!python convert-hf-to-gguf.py /kaggle/input/fine-tuned-adapter-to-full-model/llama-3-8b-chat-doctor/ \
--outfile /kaggle/working/llama-3-8b-chat-doctor.gguf \
--outtype f16En quelques minutes, le modèle est converti et enregistré localement. Nous pouvons ensuite enregistrer le carnet pour sauvegarder le fichier.
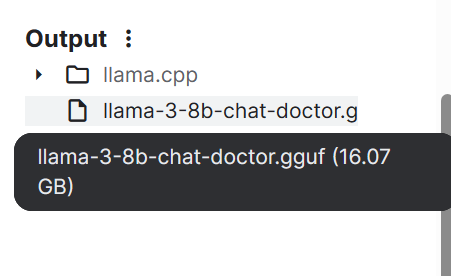
Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, consultez le carnet Kaggle HF LLM to GGUF .
Les ordinateurs portables ordinaires n'ont pas assez de mémoire vive et de mémoire GPU pour charger l'ensemble du modèle. Nous devons donc quantifier le modèle GGUF, en réduisant le modèle de 16 Go à environ 4-5 Go.
Démarrez une nouvelle session Kaggle Notebook et ajoutez le HF LLM au GGUF Notebook.
Ensuite, installez le fichier llama.cpp en exécutant la commande suivante dans la cellule du Notebook Kaggle.
%cd /kaggle/working
!git clone --depth=1 https://github.com/ggerganov/llama.cpp.git
%cd /kaggle/working/llama.cpp
!sed -i 's|MK_LDFLAGS += -lcuda|MK_LDFLAGS += -L/usr/local/nvidia/lib64 -lcuda|' Makefile
!LLAMA_CUDA=1 conda run -n base make -j > /dev/nullLe script de quantification nécessite un répertoire de modèle GGUF, un répertoire de fichier de sortie et une méthode de quantification. Nous convertissons le modèle en utilisant la méthode Q4_K_M.
%cd /kaggle/working/
!./llama.cpp/llama-quantize /kaggle/input/hf-llm-to-gguf/llama-3-8b-chat-doctor.gguf llama-3-8b-chat-doctor-Q4_K_M.gguf Q4_K_M
La taille de notre modèle a considérablement diminué, passant de 15317,05 Mo à 4685,32 Mo.
Pour pousser la file indienne jusqu'au carrefour de l'étreinte, nous allons.. :
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
from huggingface_hub import HfApi
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
api = HfApi()
api.upload_file(
path_or_fileobj="/kaggle/working/llama-3-8b-chat-doctor-Q4_K_M.gguf",
path_in_repo="llama-3-8b-chat-doctor-Q4_K_M.gguf",
repo_id="kingabzpro/llama-3-8b-chat-doctor",
repo_type="model",
)
Notre modèle est poussé avec succès vers le serveur distant, comme le montre le schéma ci-dessous.
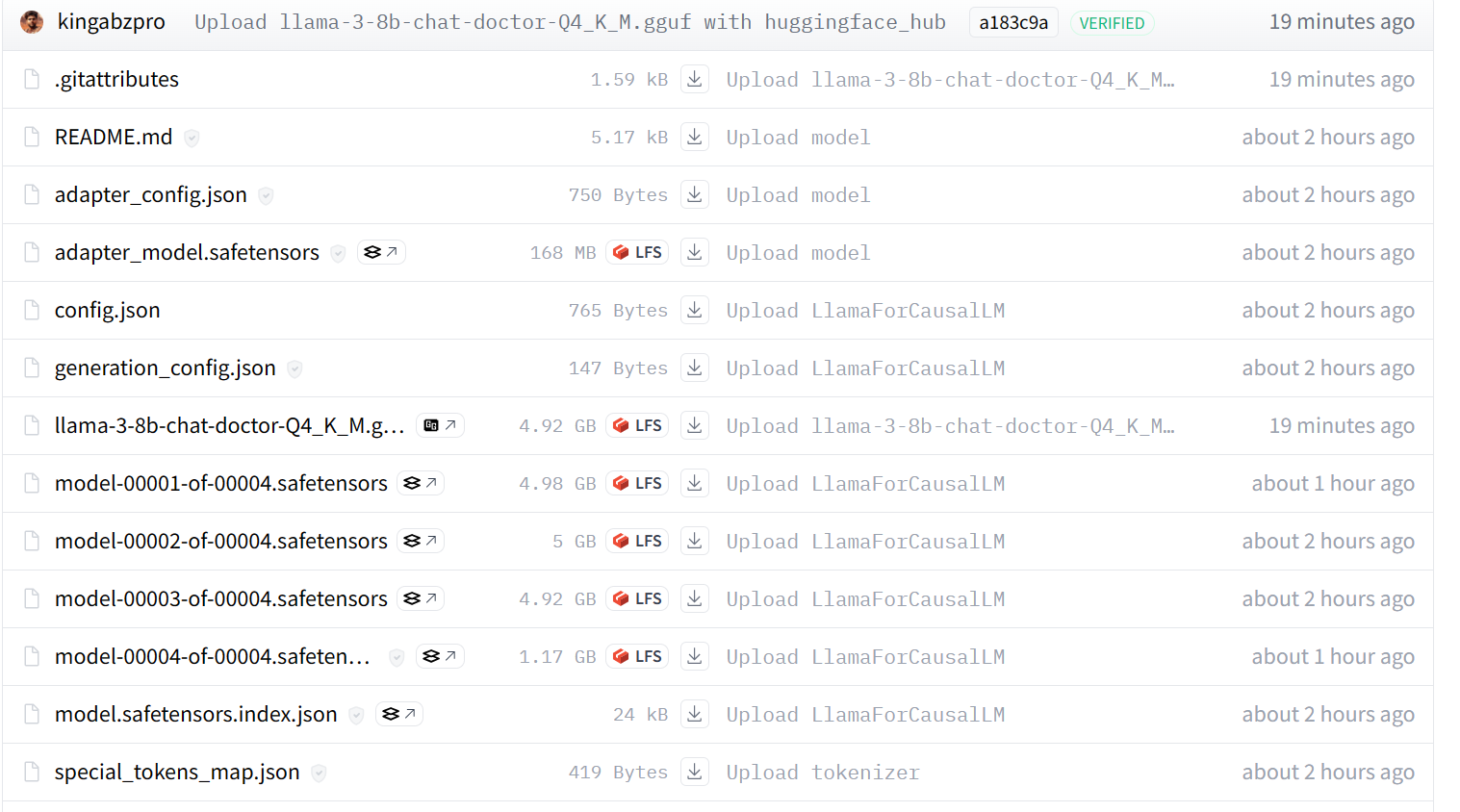
Si vous rencontrez toujours des problèmes, veuillez consulter le carnet Kaggle GGUF to Quantize, qui contient l'ensemble du code et des résultats.
Si vous cherchez un moyen plus simple de convertir et de quantifier votre modèle, visitez ce Hugging Face Space et fournissez-lui le Hub Model Id.
Pour utiliser le modèle GGUF localement, vous devez le télécharger et l'importer dans l'application Jan.
Pour télécharger le modèle, il faut
1. Rendez-vous sur notre dépôt "Hugging Face" (visage étreint).
2. Cliquez sur l'onglet Fichiers.
3. Cliquez sur le fichier de modèle quantifié portant l'extension GGUF.

4. Cliquez sur le bouton de téléchargement.
Le téléchargement local du fichier prendra plusieurs minutes.
Téléchargez et installez l'application Jan de Jan AI.
Voici à quoi cela ressemble lorsque vous lancez l'application de la fenêtre Jan :
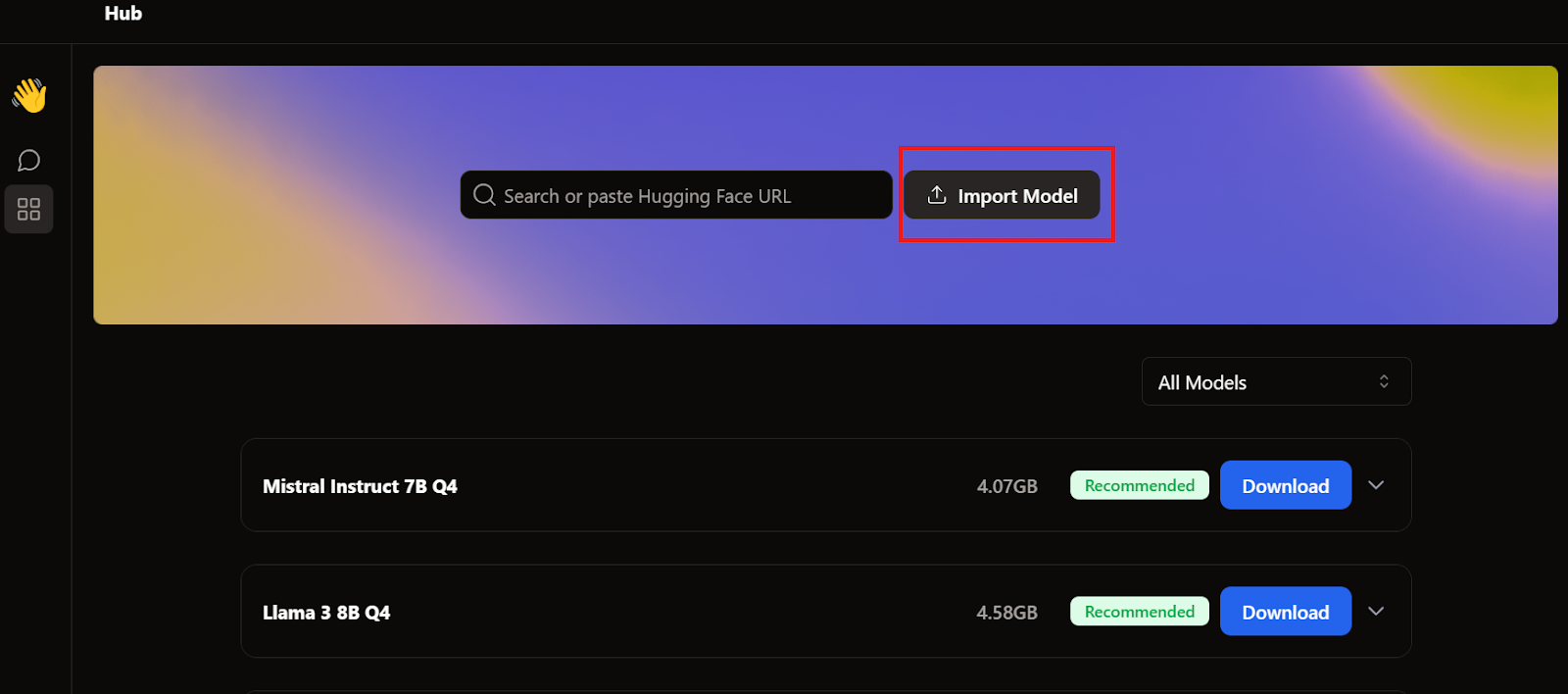
Pour ajouter le modèle à l'application Jan, nous devons importer le fichier GGUF quantifié.
Nous devons aller dans le menu Hub et cliquer sur Importer un modèle, comme indiqué ci-dessous. Nous indiquons l'emplacement du fichier récemment téléchargé, et c'est tout.
Nous allons dans le menu Fil et sélectionnons le modèle affiné.
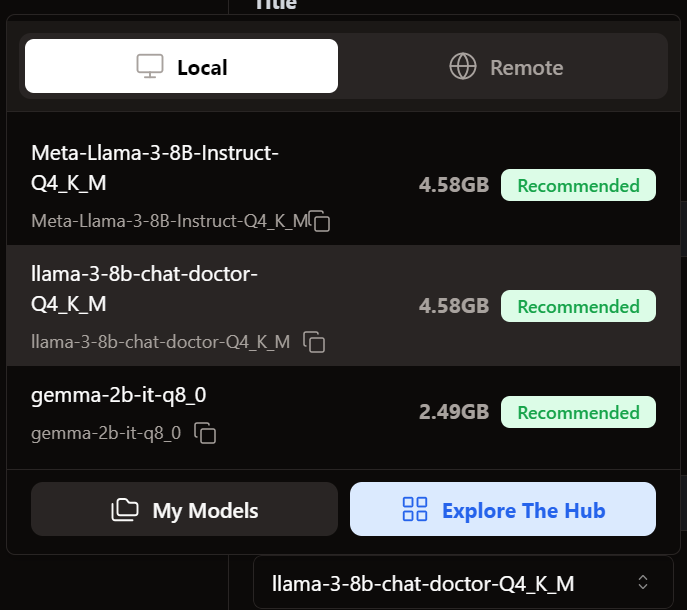
Avant d'utiliser le modèle, nous devons le personnaliser pour qu'il affiche correctement la réponse. Tout d'abord, nous modifions le modèle d'invite dans la section Paramètres du modèle.
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistantNous ajoutons l'élément Stop et modifions l'élément max en 512 dans les paramètres d'inférence.
<endofstring>, Best, Regards, Thanks,-->Nous commençons à rédiger les questions et le médecin y répondra en conséquence.
Notre modèle perfectionné fonctionne parfaitement au niveau local.
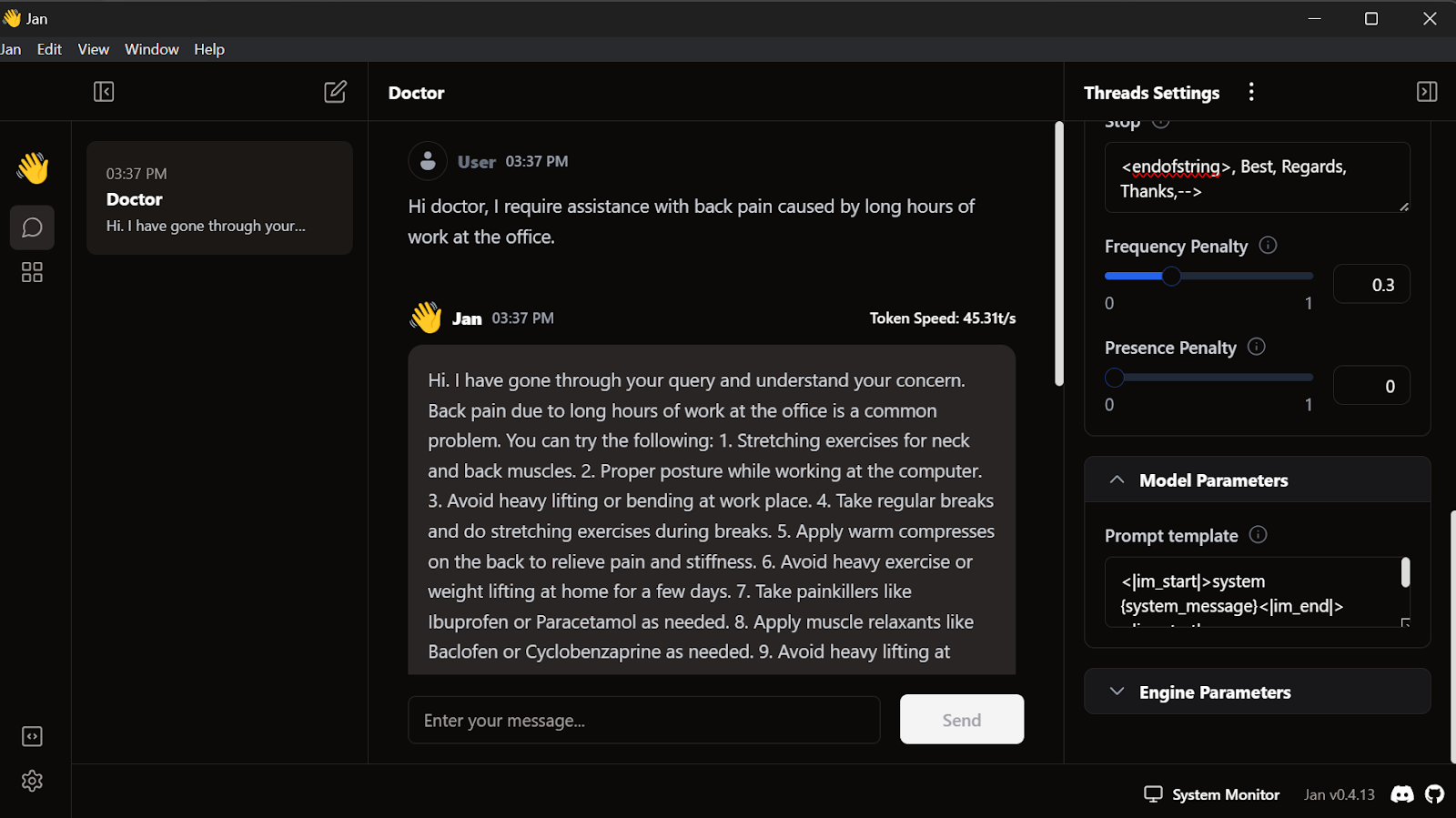
Ce modèle fonctionne avec GPT4ALL, Llama.cpp, Ollama et de nombreuses autres applications d'IA locales. Pour savoir comment utiliser chacun d'entre eux, consultez ce tutoriel sur la façon d'exécuter des LLM localement.
La mise au point du modèle Llama 3 sur un ensemble de données personnalisé et son utilisation locale ont ouvert de nombreuses possibilités pour la création d'applications innovantes. Les cas d'utilisation potentiels vont des solutions d'IA conversationnelle privées et personnalisées aux chatbots spécifiques à un domaine, en passant par la classification de texte, la traduction linguistique, les systèmes de recommandation personnalisée répondant à des questions, et même les applications d'automatisation des soins de santé et du marketing.
Grâce aux frameworks Ollama et Langchain, la création de votre propre application d'IA est désormais plus accessible que jamais, ne nécessitant que quelques lignes de code. Pour ce faire, suivez le site LlamaIndex : Un cadre de données pour les applications basées sur les grands modèles linguistiques (LLM) tutorial.
Dans ce tutoriel, nous avons appris à affiner le Llama 3 8B Chat sur un ensemble de données médicales. Nous avons procédé à la fusion de l'adaptateur avec le modèle de base, à sa conversion au format GGUF et à sa quantification en vue d'une utilisation locale sur une application de chatbot Jan.
Si vous souhaitez en savoir plus, consultez ce parcours de compétences en quatre cours sur le développement de grands modèles linguistiques.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cursus